
In this podcast, Shane Hastie, Lead Editor for Culture & Methods spoke to Craig McLuckie, co-creator of Kubernetes and CEO of Stacklok, about the impact of AI coding tools on open source communities and engineering teams, designing deliberate organisational culture, and navigating evolving career paths for engineers in the age of AI.
By Craig McLuckieTopic: Scaling Enterprise AI Agents with Dify and Red Hat AI
Alvin walked through how enterprises move from AI pilots to production: combining Dify’s agentic workflow engine with Red Hat AI’s enterprise infrastructure to deploy scalable, production-ready AI agents.
Thank you @RedHat for the invitation and for a great booth experience! 🤝 #Difyf#SuperAI20262#RedHata#EnterpriseAIA#AIAgentst#GenAIAI


Two related, Oracle-backed projects published opposing policies on open-source contributions created with generative AI: The OpenJDK Governing Board approved an interim policy prohibiting such contributions, while the Coding Assistants policy from GraalVM permits them. Both projects require contributors to sign the same Oracle Contributor Agreement (OCA) for intellectual property.
By Karsten Silz“智能体最后的考试”,Fable 5竟然不敌GPT 5.5

最难档通通零蛋
没想到打脸来得如此之快!!
刚刚,UC伯克利放出了一场号称“智能体最后的考试”的全新基准测试。
它把当今最强的AI Agent们拉到考场上,让它们干真正的活——
在Siemens NX里建3D模型、在Unreal Engine里搭游戏场景、在Adobe After Effects里做特效合成。
结果成绩令人傻眼:
最难的一档,当今公认最强的Claude Fable 5、GPT 5.5,全是大写的零蛋。

你说难度稍微放低一点呢?分数倒是有了,但结果也相当令人意外——
GPT 5.5竟然还小胜了Claude Fable 5。
我没听错吧,A家刚发布的最强模型Claude Fable 5,被几个月前的GPT 5.5打败了??
要知道在此前几乎所有主流benchmark上,Fable 5对GPT 5.5都是碾压级别的存在——SWE-Bench Pro上80.3%对58.6%,Humanity’s Last Exam上64.5%对52.2%。
但换到这场“真干活”的考试里,局面却反了过来。
这个新基准叫Agents’ Last Exam(ALE),背后团队来头不小,之前MMLU、MATH、CyberGym、ExploitGym这些你耳熟能详的基准都是他们提的。
取这个名估计也是参考之前Scale AI那个“Humanity’s Last Exam”(人类最后的考试),只不过这次被考的不是人类知识的极限,而是AI Agent干活的极限。
该说不说,这个测评一出来,以前天天喊着“Agent要取代人类工作”的人,这下是真干沉默了…
“智能体最后的考试”,赢家竟是GPT 5.5!
先看完整排行榜。

从最核心的任务通过率指标来看,GPT 5.5直接包揽冠亚军:
第1名是GPT 5.5搭配OpenAI自家的Codex框架,通过率24.0%。
第2名还是GPT-5.5,只不过换了ALE Claw框架,通过率23.0%。
(ALE Claw是团队自己写的一个baseline Agent,跟Codex、Claude Code、Cursor CLI这些商业框架并列参赛)
直到第3名,我们才看到Claude Fable 5的身影——搭配Claude Code,拿下22.0%的通过率。

往下看更有意思。
第4、第5、第8名全是GPT 5.5,只是换了不同的框架。
前10名里GPT 5.5出场了5次,加上第6名的GPT 5.4,OpenAI模型直接占了6席。
而Claude家族呢?
Fable 5拿了第3,Opus 4.7第9(18.4%),Opus 4.8垫底第10(15.8%),不敌之势一目了然。
也不怪OpenAI研究员喜庆发帖,欢欢喜喜过大年了:

而在成绩之外,这里还有这样几个值得细品的信号。
一是天花板低得惊人。
冠军通过率才24%,综合得分最高也不过45.8%。
意思是,就算按最宽松的“部分得分”算,最强的Agent也只能拿到不到一半的分。
而这些题全部来自真人专家已经完成的项目——人类专家的完成率理论上就是100%。
二是Claude烧钱烧得惊人。
这张榜单新增了一列“Estimated Total Cost”,一下子把贫富差距拉出来了:
Fable 5跑完全部任务花了2315美元,Opus 4.8花了1838美元,Opus 4.7也要1144美元。
而GPT-5.5这边呢?
最贵的Codex也就566美元,Cursor CLI只要174美元。
等于说,Fable 5花了Codex四倍多的钱,成绩还低了两个百分点。

三是效率差距同样触目。
Ale Claw跑完全部任务花了47小时20分钟,Cursor CLI只花了67小时。
而Opus 4.8呢?451小时——将近19天。
干的活最少,花的时间最长,收的钱最多(居然真有模型能同时做到?)
当然如果只看Claude Fable 5、GPT 5.5这两个最顶的,GPT 5.5的时间优势依旧明显。

而最扎眼的数字,还是那个零。
ALE把任务分成了三个难度档:
- Near-Term(近期可解)
- Full-Spectrum(全面覆盖)
- Last-Exam(终极难题)
在最难这一档,所有主流配置的平均通过率只有2.6%,包括GPT 5.5和Fable 5在内的大多数模型直接吃了零蛋。

所以这张成绩单的核心信息很简单:别看平时考试成绩好,一到真干活全露馅了。
答题学霸≠干活能手,这话在AI世界也一样适用。
什么是ALE?
要理解ALE为什么能把这帮“学霸”打回原形,得先看它跟以前的考试有什么不一样。
之前的Humanity’s Last Exam(HLE)是2025年初由Dan Hendrycks和Scale AI搞出来的,2500道跨学科难题,本质上还是闭卷答题——
给你一个问题,你给我一个答案,再难也是静态的知识检索。
而ALE完全不同,它考你“能干什么”。
核心作者Yiyou Sun在说得很直白:
AI智能体将在2026-2027年超越人类完成几乎所有工作——这个预测到处都是。所以我们造了这场考试来验证这个说法。

ALE的每道题都来自一个真人专家已经完成的项目,覆盖55个行业子领域,包括量化交易、基因组分析、航空航天工程、建筑设计、脑成像、动画特效、法律研究……
整个体系锚定的是美国联邦职业分类标准(ONET)*,说白了就是按“真实劳动力市场”来出题。

参与出题的阵容也够豪华:
300多位领域专家来自100多家机构,学术侧有MIT、Harvard、Stanford、Oxford、Caltech、ETH Zurich,产业侧有Goldman Sachs、JPMorgan、Meta、Amazon、Adobe、Oracle。
Snorkel AI通过Open Benchmarks Grants项目提供了资金支持。

考试形式也不是打字回答问题,而是直接操作电脑。
ALE用的是所谓GCUA框架(Generalist Computer-Use Agent,通用计算机使用代理),给Agent完整的GUI和命令行权限——
鼠标点击、键盘打字、写脚本、浏览网页,人类能在电脑上干的它都能干。
不限方法,只看结果。
交出来的“作业”由确定性代码自动评分。
No vibes. No human judges. Fully reproducible.(不靠感觉,不靠人类裁判,完全可复现)

这就堵住了之前很多benchmark的一个老毛病:评分器本身就能被骗。
此外,ALE在防作弊上还有一个狠招——
只公开约10%的题目(约150道),剩下1300多道严格保密。
公开题和私密题定期滚动轮换,确保不会有模型因为“背题”而拿高分。
这在当前benchmark数据污染泛滥的背景下,算是一个相当巧妙的设计。
整体而言,跟现有的Agent基准测试比,ALE的定位非常明确。
团队成员之一的Dawn Song专门拉了一组对比:
- ALE的CLI子集(ALE-CLI)覆盖40个行业子领域,而Terminal-Bench只有6个,SWE-bench-Pro只有5个;
- 人类完成这些任务的时间从几小时到几周不等,而后两者是几分钟到几天;
- 最强Agent在ALE-CLI上的通过率只有25.2%,而Terminal-Bench上是82.0%,SWE-bench-Pro上是59.1%。
一言以蔽之,其他考试已经快被做穿了,而ALE还远得很。
这就是ALE凭什么敢自称“智能体最后的考试”的理由。

值得一提的是,Dawn Song还分享了两个有趣的观察:
一个是,Agent会在没有真正验证工作成果的情况下宣布完成,这是Agent们最典型的失败模式。
很多时候,虽然它们说了“Done. All checks pass.”(搞定了,所有检查都通过了)
但实际产出可能缺少必要文件、数字算错、关键字段遗漏、或者直接违反了任务说明中的明确约束。
等于是,活没干完,嘴先说完了。
另一个是很多人疑惑的,为啥Fable 5这么拉胯?Dawn Song给出的回答是:
不存在“万能冠军”这回事。
每个前沿模型都有擅长的领域和拉胯的领域,ALE覆盖55个行业、1500+道题,最终得分是所有领域的平均值,很多模型的总分因此挤在一起。真正有价值的信号不在总分,而在不同模型在不同领域的表现差异——在同一道题上,不同模型往往因为完全不同的原因而失败。
当然也有可能是Fable 5偷偷“降智”了。
总榜里,Fable 5旁边标黄了一句“may be down-tuned”(可能被降级),这说的是Fable 5的一个已知问题——
它底层是Mythos模型加安全分类器,遇到网络安全、生物医学等敏感领域的任务时,会被静默切换到能力更弱的Opus 4.8。
在ALE这种覆盖55个行业的考试中,等于这部分科目直接派了替考,而且派的还是“奔波儿灞”这种角色。

One More Thing
当然,有没有可能Claude Fable 5的成绩本身就有问题呢?
不好说,但一桩八卦显示,Claude有“前科”。
5月底,初创公司Datacurve发布了一个叫DeepSWE的新benchmark,顺手揭了一个大底——
SWE-Bench Pro的Docker容器里附带了代码仓库的完整git历史,正确答案就躺在文件系统里。
大多数模型会无视它,但只有Claude不会。
它会主动检查仓库的git历史,从历史提交中寻找与任务对应的修复方案,并据此恢复正确补丁。
据称Opus 4.7约18%的通过成绩是这么拿的,Opus 4.6更夸张,约25%。
而GPT 5.4和GPT5.5这边呢?完全没有这种行为。Datacurve的措辞很外交:
这个benchmark让这种行为成为可能,但Claude是唯一持续这么做的家族。

科技媒体VentureBeat的评价倒很暧昧:
这说明Claude“环境感知能力”很强,非常擅长探索周围环境并利用可用资源。算“作弊”还是“机灵”,取决于你的立场。
但甭管怎么看,ALE显然吸取了教训——
直接把考场从命令行搬到了GUI桌面操作,让你没有git历史可以偷看。
评测AI的考场,正在被AI自己倒逼着升级,也算很精彩了。
完整测评地址:
https://agents-last-exam.org/leaderboard
项目主页:
https://agents-last-exam.org/
GitHub:
https://github.com/rdi-berkeley/agents-last-exam
BEV 杀入具身智能:跨维把机器人数据带上 Scaling 快车道

具身智能现在面临的问题,和自动驾驶几年前的困境非常相似。
过去几年,自动驾驶行业已经证明了一件事:谁先把真实物理世界组织进统一的数字空间,谁就先拿到规模化的入场券。
但当年,这件事并不是一开始就想明白的。
早期的纯视觉多相机方案,每个相机自己感知自己的,前摄看前面、侧摄看侧面,各出各的检测结果,再拼到一起交给规划系统。问题是,拼出来的东西在图像坐标里,不在物理世界里。视角一变、光线一变、场景一变,性能就掉。数据堆得越多,各自为政的混乱局面就越严重。
BEV,Bird’s-Eye View,就是那把钥匙。它真正改变行业的地方,不是给了工程师一张“鸟瞰图”,而是把多相机、多传感器、多任务输出,统一压进了一个可被规划系统直接消费的物理坐标系。自动驾驶因此完成了一次关键跃迁:从在图像里猜世界,到在物理空间里理解世界。
今天,具身智能正站在同一个路口。机器人数据来自不同相机、不同本体、不同坐标系、不同操作者。没有统一空间,数据堆得越多,就越混乱——不是规模化,是熵暴。
跨维智能提出的 Dexterity-BEV,正是要在具身智能里重做一次这样的重构:把视觉输入、机器人状态和目标动作,对齐到同一个参考系里,让机器人数据第一次真正具备可规模化训练的空间底座。这可以被看作是一次把 BEV 方法论系统性推进到具身智能数据基建层的尝试。
无秩序的Scale,只会演变为熵暴
今天的具身智能行业非常热闹。
机器人本体不断推陈出新,新的数据集接连发布,新的遥操作系统、人类第一视角数据、仿真与生成数据也在快速增长。显然,行业正在进入一个数据快速扩张的阶段。
文本可以被统一组织成 token,图像也有相对稳定的数据范式,但机器人数据和文本、图像不同。机器人数据天然异构,以机器人一条操作数据举例,可能同时包含多视角图像、深度、相机参数、关节状态、末端轨迹、语言指令、任务成败和真实反馈等多种维度的信息。更何况各机器人本体规格不一,数据集坐标系互不统一,相机采集视角存在差异,操作人员动作节奏也各不相同;更为复杂的是,UMI、Egocentric等全新数据采集范式还在持续涌入。人类的身高、臂展、视角和动作习惯,本质上也像一种新的“异构本体”,进一步放大了数据之间的差异。所以,具身智能面临的并不是单一的“数据量问题”,而是一个更棘手的双重难题:一方面,高质量真实交互数据仍然稀缺且昂贵;另一方面,已经采集到的数据又高度异构,难以互通、难以统一训练、难以跨机迁移。
这正是具身智能正在面对的现实:行业既需要更多数据,也需要一种把数据变成可训练、可迁移、可复用资产的底层秩序。如果缺失统一秩序,数据扩张并非正向规模化 Scale,只会走向熵暴(entropy explosion)。

Dexterity-BEV:
01 给具身智能装上“统一空间坐标系”
Dexterity-BEV 的思路非常直接,也非常狠:把多来源、多视角、多本体的机器人数据,统一对齐到一个 BEV 三维空间里。
这不是简单把多视角图像拼起来,也不是做一个笨重的三维重建系统。Dexterity-BEV 的关键,是构建一个统一 BEV对齐坐标系,让不同相机看到的物体、空间关系和操作目标,都能被放进同一个俯视参考空间。
可以把它理解成一个“虚拟正交相机”。不管真实相机装在哪里、从哪个角度拍、机器人从哪个方向看,最终数据都会被转化到同一个俯视空间里。这样,同一个物理任务就不再是一堆互不兼容的二维图像,而是同一物理世界中的可学习表达。
这一步的意义很大,过去很多 VLA 模型看起来学会了任务,但一旦相机视角变了、机器人基座动了、场景布局变了,性能就会明显掉。原因很简单:模型学到的不是物理规律,而是某个固定视角下的图像模式。
Dexterity-BEV 要做的,就是把模型从“看图猜动作”拉回到“在三维空间里理解任务”。

02 它不是放弃 2D 大模型,而是给 2D 大模型补上 3D 坐标
这也是 Dexterity-BEV 最值得讲的地方。
具身智能行业现在有一个两难:纯 2D VLA 有语义能力,但空间不够;重型 3D 方法有几何信息,但成本高、训练难,也不容易复用已有 2D VLM 的能力。
Dexterity-BEV 没有选择推倒重来。它保留多视角 RGB 输入,继续复用成熟的二维视觉编码器和视觉语言模型,同时通过 顶点图(vertex map) 和 顶点谱(vertex spectrum),给每个视觉 token 注入三维空间位置。
换句话说,它不是重新造一个昂贵的 3D 系统,而是在已有视觉模型体系上补了一层机器人最缺的东西:空间坐标。对于有深度信息的设备,它可以利用深度图和相机标定生成像素级三维顶点表示;对于更常见的纯 RGB 相机,它可以通过顶点谱机制,为每个像素构建一组三维位置假设,再编码进视觉特征中。
这就像给二维图像接上了一套三维物理骨架。语义能力保住了,空间理解补上了,工程成本也没有被打爆。这才是能 scale 的 3D。

03 不只对齐视觉,还对齐动作
如果 Dexterity-BEV 只是把图像对齐到 BEV 空间,那还不够。机器人数据真正难的地方在于:动作也不统一。
不同机器人本体差异巨大。一个 Franka,一个双臂平台,一个半人形机器人,即使执行同一个任务,关节轨迹也完全不同。如果模型直接学关节角,基本就被硬件绑死了,Dexterity-BEV 的处理方式,是把动作从具体关节里解放出来。
它不让模型只学习“某个关节转多少度”,而是学习末端执行器在统一 BEV 空间中应该去哪里、以什么姿态接近物体、如何移动、如何完成任务。
更关键的是,这些末端执行器位姿不是随便表达的,而是被进一步对齐到前面提到的统一 BEV 对齐坐标系中。
这就形成了一个非常漂亮的闭环:视觉输入在 BEV 空间里,机器人状态在 BEV 空间里,目标动作也在 BEV 空间里,输入和输出第一次被放进同一个物理坐标系统。这才叫真正的感知—动作对齐。
通俗点说,Dexterity-BEV 给不同机器人、不同相机、不同动作提供了一把共同的“空间尺子”。过去各说各话的数据,现在终于能用同一种物理语言交流。
具身数据还有第三种混乱:时间。
同一个任务,不同操作者做得快慢不同;不同机器人执行速度不同;有的人中间停顿,有的人动作连贯。这些差异很多时候并不代表任务本质,但会让模型训练变得更难。
Dexterity-BEV 在数据管线中加入了跨轨迹时序对齐机制,对不同机器人、不同操作者、不同数据集里的轨迹进行时间尺度规整。它不是要抹掉任务动作结构,而是尽量减少“谁操作得快、谁操作得慢”这种无意义差异,让模型更专注于学习任务真正的关键动作顺序和空间关系。

所以 Dexterity-BEV 做的不是单点优化,而是一套系统性数据基建:空间对齐、动作对齐、时序对齐、数据管线对齐。
Dexterity-BEV 实测验证强泛化能力
Dexterity-BEV 的实验设计也很有意思。它不是只在固定场景里刷一个好看的分数,而是专门去测那些传统 VLA 容易翻车的情况:相机视角变化、机器人基座扰动、场景布局变化、跨机器人平台迁移。

在仿真中,Dexterity-BEV 在 LIBERO 和 RoboTwin 2.0 上与 π0、X-VLA 等强基线对比。尤其在相机视角、机器人基座和场景布局被大幅扰动的设置下,传统 2D VLA 方法成功率明显下滑,而 Dexterity-BEV 仍能保持稳定表现。

在真实机器人上,Dexterity-BEV 也覆盖了四类双臂平台和多个长程任务,包括折叠纸盒、折布、舀爆米花、递书等。这些任务不是简单抓取放置,而是涉及刚体、柔性物体、颗粒物、双臂协同和人类交互的复杂操作。
[BEV视频_终0609.mp4]
这类任务更接近真实世界,也更能暴露模型到底是在“记画面”,还是在“理解物理”。
Dexterity-BEV 的结果说明了一件事:当机器人数据被放进统一空间,模型的泛化才真正有了基础。
BEV 进入具身智能,打通Scaling关键路径
笔者认为, Dexterity-BEV 最重要的意义,不只是一个模型效果提升,更像是具身智能从“堆数据阶段”进入“建数据秩序阶段”的标志。
过去行业很热衷讨论:谁采了更多小时数据,谁有更多机器人,谁做了更多任务。但如果这些数据不能统一训练、不能跨机迁移、不能复用到新场景,数据规模越大,反而越像一座座孤岛。
Dexterity-BEV 提供的是另一种思路:先建立统一物理空间,再谈数据规模化。这和自动驾驶当年 BEV 范式带来的变化非常像。BEV 让自动驾驶从多相机图像感知,走向统一空间理解;而现在,Dexterity-BEV 正在尝试让具身智能从杂乱的机器人轨迹,走向统一的感知—动作物理表达。
如果说过去具身智能还在“看见世界”,那么 BEV 进入之后,它开始有机会“组织世界”。这可能是具身模型真正 scale 之前,必须补上的一层数据基建。

具身智能的下一阶段,不会只是模型更大、数据更多、机器人更贵。
真正决定行业能不能跑起来的,是数据能不能被统一,动作能不能被迁移,经验能不能跨机器人复用。
Dexterity-BEV 的价值就在这里:它不是只做一个更强的策略模型,而是试图为具身智能建立一套可规模化的数据秩序。
从这个角度看,BEV 杀入具身智能,不是一个普通技术点,而是一次补课。
自动驾驶吃到过的 BEV 红利,现在轮到机器人了。
而跨维智能这次做的,就是把具身智能真正推上 Scaling 快车道之前,先把路修好。
-本文系量子位授权转载-
原创 周永亮 2026-06-12 12:00 北京
从操控一台机器,到拥有一个伙伴。
作者|周永亮
编辑|郑玄
最近,SpaceX、OpenAI、Anthropic 相继推进上市进程,合计募资规模或超过 2000 亿美元,一场史无前例的资本盛宴正在上演。这些超高估值背后,市场押注的不只是 AI 改变数字世界,还有 AI 渗透到物理终端之后的想象空间。
在物理 AI 这个方向,机器人是最显眼的赛道。特斯拉 Optimus、宇树的每次亮相都备受关注。但如果要看商业化落地的节奏,那汽车才是物理 AI 目前最有可能落地的场景。
2026 年 6 月 9 日,北京雁栖湖畔,一个名叫 AIVA 的新品牌正式亮相。AIVA 品牌正式官宣携手火山引擎,联合定义、联合设计、共同打造 AI 汽车体验。火山引擎为 AIVA 品牌提供豆包大模型、智能座舱等技术服务,帮助 AIVA 品牌提升车载智能交互体验。
在这次发布会上,AIVA 没有谈续航,没有谈智驾,而是提出一个根本性的问题:AI 时代的汽车应该长什么样子?
01
把造车的顺序,反过来
理解 AIVA,要先想清楚一个问题:智能汽车和 AI 汽车,究竟有什么本质区别?
过去 10 年,中国智能汽车行业经历了一波智能化的浪潮,辅助驾驶、大屏幕、语音助手……这些都已经成为人们购车的重要参考因素。但如果仔细看,会发现一个共同点:先有车,再加上 AI。
AIVA 想做的事情,是把这个顺序反过来,「AI 定义汽车,先有 AI,再有车」。让 AI 作为底层基座,在这个基础上长出身体。
火山引擎副总裁杨立伟在发布会上说了一句话,精准定义了这个差异:「我们理解的 AI 汽车,不只是把 AI 放到车上,而是让汽车成为物理 AI 的一个新物种。」
这句话听起来像产品发布会上的宏大愿景,但 AIVA 做了四件非常具体的事:需求前置、架构前置、功能前置、学习前置。 需求前置,意味着不再是产品经理开着调研会,靠人的判断推演场景;而是让 AI 去做海量数据分析,主动挖掘用户在通勤、家庭出行、长途驾驶、疲惫傍晚这些真实情境下的真实需求。
图片来源:赛豆科技
AIVA 总裁、产品经理李博在发布会上打了一个比喻,非常精准,「过去是人在前面挖矿,现在是 AI 在前面挖矿,人在后面淘金。」这不是效率的提升,这是需求发现方式的改变。
架构前置,意味着先想清楚 AI 需要调用哪些车辆能力、数据接口和执行系统,再去设计底层架构。这意味着车辆的传感器布局、数据流通方式、各系统之间的协同接口,都要为 AI 的深度介入预留空间,而不是等车造好了,再去想怎么把 AI「接进来」。
功能前置,不是把功能做成一个个菜单,等用户去找;而是让 AI 围绕用户的目标,动态组织全车能力。用户说「我好冷」,AI 不是弹出一个温度调节界面,而是综合车内外温差、你的历史偏好、当前穿着状态,直接给出最合适的方案。
学习前置,意味着这台车在你买来第一天和用了三年之后,应该是两种完全不同的体验。不是因为 OTA 推送了新功能,而是因为它越来越懂你这个人。
把这四件事放在一起,就构成了 AIVA 所说的「AI 定义汽车」:它不是给车装一个更聪明的助手,而是让 AI 从产品诞生的第一天起,就参与定义这台车应该是什么。
02
从人适应车,到车适应人
如果说「AI 定义汽车」是一次造车逻辑的革命,那它必然会重塑人与汽车之间的关系。
长期以来,人和车是一种操作关系:人发出指令,车执行功能。从方向盘、油门、刹车,再到点击屏幕,其实都是用户在主动操控一台机器。
但 AIVA 想打造的是一种协作关系,AI 能够感知状态、主动服务,成为「伙伴」而非「工具」。
图片来源:赛豆科技
这一句话,拆开来看,是三个具体的变化。
一个是交互方面,从「机械生硬」到「普适鲜活」。目前的车机系统,用户需要记住菜单位置、熟记唤醒词,甚至要用精确的指令格式说话,本质上是人在适应车。
物理 AI 时代的交互逻辑是反过来的:机器适应人。AI 能像人与人聊天一样,知道什么时候该接话,什么时候该保持安静,根据当时的场景和意图直达任务。
而鲜活则是另一个维度。AI 不是一个千篇一律的助手,而是能感知你的情绪状态,在你疲惫时切换更放松的音乐和灯光;在车上有孩子的时候,切换成「孩子王」模式……它不是预设的场景标签,而是对「现在的你」的理解。
另一个是智能从「功能堆叠」到「能力涌现」。传统智能汽车强调功能和配置越来越多,但这并不等于智能的提升,反而可能带来更高的使用门槛。
AIVA 追求的是让各个系统之间产生协同效应,形成「能力涌现」。
李博在发布会上举了一个例子,让人印象深刻。同样是 22 度,AIVA 理解的是完全不同的情境,「夏天穿着 T 恤刚进车的 22 度,和冬天脱下羽绒服穿着羊毛衫的 22 度,不是同一个 22 度;打完球大汗淋漓的 22 度,和穿着西装准备见客户的 22 度,也不是同一个 22 度。」
这意味着,真正的个性化不是记住你的偏好设置,而是理解你在不同情境里,真正需要什么。
再有就是,感受从「单调乏味」到「松弛愉悦」。
很多人开车会觉得累,不只是因为路况复杂,更是因为注意力被大量重复性的判断和操作消耗。当 AI 能够主动接住这些「负担」,用户的精神状态会发生很大的改变。
这也是 AIVA 品牌主张「Live Alive,爱予自由」的内涵,就是用 AI 把时间还给用户,用情感陪伴回应用户感受。
03
火山引擎,从第一天就入局
AIVA 发布会上,另一个值得深度解读的信息,是与火山引擎的合作方式。
官方的表述不是「技术供应」,不是「功能接入」,而是联合定义、联合设计、共同打造。
车企与智能化供应商的合作,大多遵循一个流程:车辆的硬件架构、功能定义、交互逻辑先由车企确定,AI 公司随后介入,负责让「车里的助手更聪明一点」。
但 AIVA 和火山引擎的合作,是从产品定义的第一天起就开始的。
杨立伟在发布会上说了一句话,道出了这个变化的意义,「如果一台车从第一天起就围绕 AI 来定义,它的交互方式、智能上限和用户感受,都会发生根本变化。」
火山引擎为 AIVA 提供的,是豆包大模型能力、智能座舱技术服务,以及多模态交互、车端智能体等能力探索。
但把大模型能力真正落地到汽车场景,需要跨越一道很高的门槛。汽车场景有其独特的复杂性,比如驾驶状态下,用户无法像使用手机一样全神贯注于交互;车内可能同时有驾驶员、乘客、儿童,交互逻辑完全不同……
这意味着,通用大模型的能力必须经过真实车端场景的专项训练与深度适配,才能真正理解这样的情境:高架桥上堵车二十分钟,车主有点烦躁,下一个出口有一家他常去的咖啡馆——AI 应该在什么时机、用什么方式、说什么话?
这种判断,不是靠规则写出来的,而是靠豆包的通用认知能力与汽车专业场景从源头长在一起,训练出来的。
04
当 AI,长出了汽车的身体
发布会的最后,AIVA 的首款概念车 Origin Concept 正式亮相。AIVA 所有关于「AI 定义汽车」的认知,在这一刻有了具体的体现。
图片来源:赛豆科技
设计团队没有从「风格」或「姿态」出发,而是从「让这台车能看见你、感知你、回应你」出发。车身采用 G4 曲面,没有硬棱角,没有刻意的折线;前灯被设计成可交互的「眼睛」,当你走近,它会专注地看着你;当你比个心,它会回应你;轮毂的设计灵感源自鸟类的叉骨,低风阻轮罩像翅膜一样薄而有韧性……
这些设计细节,其实都是在试图回答文章开头的那个问题:AI 时代的汽车应该长什么样子?
据了解,首款量产车型 AIVA ME7 将于 2026 年年内亮相,全系覆盖 20 万元以上主流市场。这是中国新能源汽车竞争最激烈,也是用户最难被说服的主流战场。AIVA 选择在这里验证「AI 定义汽车」的商业可行性。
2026 年,物理 AI 正在从实验室走向真实世界。过去的 AI 活在屏幕里,你问它,它答你;而物理 AI,是要把智能装进一台有眼睛、有手脚的机器里,让它真正走进现实世界。
所以你会发现,当 OpenAI、Anthropic 都开始研究怎么走进真实世界的时候,汽车行业正在经历的变革,其实是这波叙事的一部分。把 AIVA 放进这个背景里,它的坐标才看得清楚。
*头图来源:赛豆科技
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO
极客一问
你如何看待物理 AI 正在从实验室走向真实世界?

新智元报道
新智元报道

【新智元导读】OpenAI 正在讨论大幅下调 Token 定价,直接原因是预判 Anthropic 即将跟进。但消息传出的前一天,Anthropic 发布了 Fable 5,在核心编码基准上把 GPT-5.5 甩开 22 个点。一场价格战与一场能力战正在同步展开,它们指向同一个终极问题。
据《华尔街日报》最新报道,OpenAI 正在内部讨论大幅削减 Token 定价。

https://www.wsj.com/tech/ai/openai-considers-drastic-price-cuts-anticipating-war-for-users-with-anthropic-9b8c178e
知情人士称,此举意在抢先于 Anthropic 预期中的类似行动。
CEO Sam Altman 在近期活动上公开承认,成本已成为「一个巨大的问题」:
我们会有很多方式帮助用户以更少的支出获得更多价值。
降价讨论发生在一个微妙时刻。
OpenAI 本周刚秘密提交了 IPO 申请,Anthropic 更早一步启动了同样的流程。
拓展阅读:
突发!OpenAI秘密递表冲刺万亿IPO,奥特曼许诺人手一个AGI
两家公司目前都因 AI 系统所需的巨额算力投入而承受数十亿美元亏损。
大幅降价将进一步压缩利润率——在上市窗口前,这是一个高风险的赌注。
投资者长期关注的一个结构性风险在此刻变得格外显眼:两家的产品高度可替代,企业客户在它们之间切换的成本很低。

驱动降价讨论的,还有来自需求侧的明确信号。
一位 Uber 高管今年早些时候透露,公司已经花光了 2026 年的 AI 预算。
另一家企业的管理层上月表示,难以将 AI 编码效率的提升与可衡量的新产品功能挂钩。
这类声音在企业界正变得普遍,并在硅谷引发了关于 Tokenmaxxing(尽可能多地消耗 Token 以求提升生产力)的争论——效果能否真正转化为投资回报,越来越多人打上了问号。
过去两年 AI 公司的增长叙事建立在一个前提上:企业会持续加大投入。
当这个前提动摇,降价就从竞争策略变成了维持增长曲线的必要条件。

价格战还没正式开打,能力格局先变了。
6 月 9 日,Anthropic 发布 Claude Fable 5——首个面向公众的 Mythos 级模型。

拓展阅读:刚刚,Anthropic首个神话级Claude 5正式解禁!
它与仅限受控机构使用的 Mythos 5 共享底层架构,但加装了安全护栏:涉及网络安全、生物和化学的请求会自动回退到前代模型 Opus 4.8。
基准测试显示 Fable 5 与 GPT-5.5 之间已拉开代际差距。
在 SWE-bench Pro(更接近真实工程难度的编码测试)上,Fable 5 得分 80.3%,GPT-5.5 为 58.6%,差距达 22 个点。
Cognition 的 FrontierCode Diamond(按生产级标准设计的高难度基准)上差距更大:29.3% 对 5.7%,五倍之差。

上月刚加入 Anthropic 的 Andrej Karpathy 称其为「值得大版本号跳跃的阶梯式飞跃」。

Stripe 用 Fable 5 在一天内完成了一个 5000 万行 Ruby 代码库的迁移,此前估计需要一个团队干两个多月。
GPT-5.5 在 4 月发布时刚帮 Codex 追平甚至反超 Claude Code 的多项基准优势。
七周后,Fable 5 又把差距拉开了。
但与此同时,能力领先伴随着成本代价。
Fable 5 的 API 定价为每百万输入/输出 Token $10/$50,是 GPT-5.5 的两倍。

与此同时,更关键的是,6 月 22 日之后 Fable 5 将从订阅套餐中移除,转为 Usage Credits 单独计费。

Anthropic 称「产能充足时」会将其重新加入套餐,但没有给出时间表。
降价争夺企业客户只是这场竞争的表层。
Fable 5 的背后是 Mythos——一个因网络安全能力过强而无法全面公开的模型。
Anthropic 的 Project Glasswing 已将无护栏版本 Mythos 5 提供给约 15 个国家的约 150 个组织,用于国家级网络攻防研究。

OpenAI 在秘密提交 IPO 时表示「有些事情作为私有公司更容易做」,但未展开说明。
两家公司竞争的焦点已经超出了企业合同的范畴。
价格战是一种融资手段:用低价锁定用户规模,用规模支撑 IPO 估值,用上市融到的资金反哺下一代模型训练,实现 RSI(Recursive Self-Improvement,递归自我改进)。
这个链条的终点指向 ASI。
Anthropic 内部的有效计算指数(ECI)显示,模型能力仍在以大致恒定的速率持续提升。Fable 5 级别的跳跃还会继续发生。
对企业客户和普通用户而言,短期内 Token 变便宜确实是利好。
但当 AI 能力以这样的节奏跃升,新一代性能碾压上一代时,「哪家更便宜」可能很快就不是最重要的选择标准了。
参考资料:
编辑:马可



文章原文

新智元报道
新智元报道
【新智元导读】具身智能正在从实验室演示走向真实场景。越往真实世界走,数据问题越明显:视频能看到动作结果,动捕能记录轨迹,机器人日志能记录执行,但它们往往很难完整捕捉人类操作背后的意图、发力趋势、微控制和反馈修正。围绕这一缺口,一类新的人类操控数据基建正在出现。
过去几年,大模型证明了一件事:数据不仅是训练材料,也是能力边界本身。
文本模型吃下互联网文本和代码,获得语言、推理和编程能力;自动驾驶模型依赖真实道路数据,持续学习复杂交通环境;多模态模型则从图像、视频和语音里获得对世界表象的理解。
但当AI进入物理世界,问题变得更难。
具身智能要学习的不是一句话、一个图片标签或一段视频摘要,而是如何在真实世界中行动:如何抓起易碎物体,如何拧开瓶盖,如何插入接口,如何在接触后微调角度,如何在失败时重新选择动作。
这些能力背后,缺的不只是更大的模型和更贵的机器人本体,还有一种更底层的数据:人类如何操控物理世界的数据。
这也是为什么,Physical AI所需的数据规模,很可能最终远远超过大语言模型。
LLM训练所依赖的语言数据,本质上是高度压缩后的符号数据:一本书、一篇论文、一段代码,都是人类把经验整理成文字后的结果。它密度高、可复制、可检索,也相对「廉价」。
但身体经验不是这样。一个人一生读过的文字,按存储量粗略估算也许只是几十GB;而他从小到大接收的视觉输入、肌肉控制信号、触觉反馈和身体交互经验,可能是PB级甚至更高量级。人类通过身体学会抓握、平衡、接触、避让、用力和修正,这些数据大多没有被写进互联网,也没有被结构化记录下来。
所以,Physical AI的难点不是简单复制LLM的数据路线。语言模型吃的是人类已经压缩过的知识;具身模型要补的,是尚未被充分记录的人类身体交互数据。
工信部《人形机器人创新发展指导意见》已将人形机器人定位为未来产业方向,并提出建设大模型训练数据库、扩充高质量多模态数据。2026 年度人形机器人与具身智能实景实训专项行动则进一步强调「实景实训、数据沉淀、产品迭代、规模部署」的闭环,并要求建设高质量、高保真数据集。
这意味着,具身智能不再只是展台上的演示问题,而是要进入生产制造、仓储物流、医疗康养、应急救援等真实场景。
真实场景一旦打开,数据瓶颈就会变得很尖锐。
在实验室里,机器人可以在固定光照、固定物体、固定轨迹下完成任务;在现实里,物体会遮挡,材质会变化,人的动作会临时调整,接触状态也会不断改变。模型要从模仿动作走向理解操作,必须拥有更接近真实操控过程的数据。
所以,具身智能的竞争正在从三个层面展开:
机器人本体,解决能不能执行;
模型算法,解决能不能规划和泛化;
数据基础设施,解决能不能持续获得可训练、可复用、可治理的真实操作数据。
第三层,正在成为新的关键变量。
换句话说,Physical AI 的终局竞争不会只发生在机器人本体上,而会越来越多地发生在数据源头上。未来具身模型需要的数据量可能远超大语言模型,而高质量的人类操作数据,正在成为全球最稀缺的战略资源之一。
今天的具身数据采集方法大致有几类。
第一类是视频和第一视角数据。它们可以记录环境、物体和人的动作过程,成本相对低,也容易规模化。但视频主要看到的是外部结果。手被物体遮住、动作发生在边缘视角、手指产生细小变化时,关键操控信息可能丢失。
第二类是动捕、数据手套、外骨骼和专业遥操作系统。它们可以获得更精确的姿态、轨迹或控制量,但通常穿戴复杂、部署成本高,对自然操作有干扰,也不容易进入大规模日常任务。
第三类是机器人真机日志。它记录的是机器人执行了什么、关节如何变化、任务是否完成。但它往往回答不了更前置的问题:在人类示教或操作时,人的意图如何形成,什么时候准备发力,接触后又如何微调?
换句话说,很多现有数据记录的是动作结果,而不是操控过程。
一次真实的人类操作,其实包含多个层次:
意图:人准备做什么;
姿态:手和身体如何运动;
发力趋势:肌肉激活和接触状态如何变化;
微控制:接触后怎样修正、补力、调整方向;
结果:任务是否完成,物体和环境发生了什么变化。
如果只记录最后的轨迹或视频,很多关键过程会被压缩掉。对精细操作来说,这些被压缩掉的信息,可能正是模型最需要学习的东西。

EMG,也就是肌电信号,是肌肉活动相关的电信号。腕部或前臂的表面肌电可以在非侵入条件下捕捉部分运动意图、肌肉激活和控制变化。
2025 年 Nature 论文《A generic non-invasive neuromotor interface for human-computer interaction》展示了腕部 sEMG 用于连续控制、离散输入和文本输入的潜力,并讨论了 sEMG 对意向运动信号和手势力相关信息的捕捉价值。

论文链接:https://www.nature.com/articles/s41586-025-09255-w
EMG 不等同于触觉传感器或真实力传感器。它更适合被理解为一种人端估计信号:它不能直接告诉我们物体受到了多少牛顿的力,但可以为人准备怎样发力、肌肉激活如何变化、动作是否发生微调提供线索。这恰恰是它的价值所在。
在具身智能数据中,视觉、动捕、机器人日志和触觉传感器各自回答不同问题:
视觉回答:看到了什么;
动捕回答:动作在哪里发生;
机器人日志回答:机器执行了什么;
触觉/力传感器回答:接触和真实受力如何变化;
EMG 补充:人端意图和发力趋势如何形成。
当这些信号被放到同一条时间轴上,数据就不再只是分散的传感器记录,而更接近一次真实操作的完整过程。

从人形机器人的全身操作系统,到软件仿生灵巧手,再到机器人摄像头防抖、室内空间数据采集和物理因果数据引擎,不同团队几乎都在试图为Physical AI补上一块关键拼图。
而在这些路径之外,北京大学秦旭团队,则把视线进一步拉回到「人类如何操控世界」本身,提出面向Physical AI的人类操控数据平台。
其路径是以极具创新性的可穿戴硬件组合作为入口,从肌电与运动神经信号解码切入,通过神经腕带、全景头环等设备,持续采集真实世界中的人类操控过程,并将其沉淀为意图、姿态、发力趋势、微控制与反馈修正等结构化数据。

这套方案的关键,是把人类自然操作变成可采集、可同步、可训练的数据流。其中,神经腕带负责捕捉前臂相关的运动神经/肌电信号;全景头环记录第一视角下的环境、对象和任务上下文;如果再结合手部姿态、腕部视觉、IMU、机器人日志或接触传感器,就可以形成更完整的多模态操控数据。
举个简单例子:
一个人拿起杯子。视频能看到手靠近杯子、杯子被拿起;姿态数据能看到手腕和手指的位置变化;如果有触觉或力传感器,可以看到接触与受力;EMG 则可以补充动作发生前后的肌肉激活和发力趋势线索。
真正有价值的不是某一个信号,而是这些信号的同步。
对机器人来说,同步后的数据能帮助模型理解:在什么视觉环境下,人为什么这样伸手,如何预备发力,接触后如何修正,最后任务为什么成功或失败。
这就是人类操控数据平台的意义。它不是一个硬件外设,也不是一个单一数据集,而是面向 Physical AI 的数据采集和结构化能力。
第一类应用,是机器人训练和示教。
精细操作任务中,单纯的视频模仿常常不够。插拔、拧动、按压、抓取柔软物体、使用工具等任务,都涉及接触状态、发力变化和连续修正。人端操控数据可以为模型提供更丰富的监督信号。
第二类应用,是 AI 眼镜、XR 和智能设备交互。
语音不适合所有场景,触屏和手柄也不能覆盖所有操作需求。神经腕带作为低摩擦、低打扰的输入方式,可以让设备理解手势、意图和微控制,成为空间计算和智能终端的新交互入口。
第三类应用,是真实场景数据集建设。
实景实训强调从真实场景中积累高质量数据。人端操控数据可以补足传统视频和机器人日志之外的信号层,让数据集从「看见动作」升级到「理解操作」。
第四类应用,是数据产品和基础设施。
如果一套采集方案能持续沉淀跨任务、跨场景、跨用户的数据,它就不只是设备销售,而可能变成面向机器人公司、模型团队、AI 眼镜厂商和工业场景的数据模块。这也是雪梦未来试图强调的方向:短期是人机交互和具身数采,长期是 Human Manipulation Data Layer。
具身智能的下一阶段,不会只由更大模型或更强本体决定。
模型需要真实世界的数据,本体需要真实场景的验证,而真实场景又需要可持续、可治理、可复用的数据采集基础设施。
视频、动捕、遥操作、机器人日志都不会被替代。它们仍然是重要数据来源。但如果 AI 要更深入地理解人类如何操作物理世界,就需要补上动作结果背后的信号:意图、发力趋势、微控制和反馈修正。
EMG + Ego 视觉 + 姿态同步,是一种早期但值得关注的路径。
它让人不只是机器人要服务的对象,也成为 Physical AI 学习物理操作的重要数据源。从这个意义上说,具身智能真正的底座,可能不只是机器人本体,也不只是模型参数,而是高质量、可规模化的人类操控数据。

短期看,人类操控数据可为具身智能、AI眼镜和智能设备提供更自然的人机交互入口,降低操作门槛,提升连续性与低打扰体验;长期看,它指向一层新的物理世界数据基础设施,让AI不只理解文本和图像,也理解人类如何真实地与世界交互。

Physical AI的下一步,或许不只是把动作做得更像人,而是开始真正理解动作背后的操控逻辑与人类意图。那些决定成败的关键,很多时候并不写在最终结果里,而藏在动作发生前的判断、接触瞬间的微调,以及一次次反馈中的修正之中。
只有当AI学会的不再只是动作的外形,而是人如何发起、控制并完成一次真实操作,它才有可能从演示走向现实,真正进入那个复杂、开放、始终变化着的物理世界。
参考资料:
编辑:LRST
文章原文

新智元报道
新智元报道
【新智元导读】AI不仅写代码,连做实验也包揽了!基于闭环Agent架构RhinoAI,机器自主完成了碳材料寻优。告别低效人肉试错,AI「物质编译」直接撕裂材料黑箱。
微观惊艳、宏观平庸,这道「跨尺度性能退化」的难题困扰材料界数十年。
如何扭转这一局面?
鼎犀智创(Rhinovate™)联合北京大学深圳研究生院新材料学院、北京大学人工智能研究院的科研团队共同推出了CarbonKylin™,一个针对碳材料的Agentic自驱动材料研发系统,旨在系统性破解性能退化之谜,让新材料产业化真正跨越从实验室到应用的鸿沟。

从微观单元到宏观材料,性能为何会出现断崖式下跌?
问题根源在于组装过程中两类相互交织的物理机制。
其一是非线性涌现——当无数微观单元在数十道工序、数百个参数下发生强非线性耦合时,微小的初始波动便可能被逐级放大,最终使宏观性能远低于预期。
其二是热力学耗散——系统在趋向熵增的过程中,自发产生缺陷与无序堆叠;工艺过程中的非平衡冷却和残余应力也会引入力学性缺陷,二者共同造成能量的不可逆耗散,削弱材料的强度性能。
当前以A-Lab为代表的前沿 AI 材料研发平台,虽已在无机粉体等体系中取得突破,却难以应对非线性涌现行为与热力学耗散问题。
高通量计算筛选、自动化合成与表征等手段大多聚焦于研发链条的单个环节,缺少贯通模型预测、实验验证与机理理解的系统性框架。主流数据驱动方法多为黑箱预测,难以揭示性能涌现的物理根源,预测结果也难以升华为可迁移的科学认知。
面对跨尺度性能退化的难题,鼎犀智创(Rhinovate™)如何进行破局?
编译物质科学与工程(Material Compilation Science and Engineering,MCSE)将计算机科学中的编译理念引入材料制备,把从微观到宏观的制备过程形式化为可分析、可优化、可解释的编译过程,从而系统性地提升性能保留率,确保关键物理信息在尺度转换中的保真。
将这一范式工程化落地,不能依靠孤立的技术模块,而需要一种闭环式的研究架构。
这正是鼎犀智创(Rhinovate™)提出的RhinoAI所承担的角色——一套面向物质科学的Physical AI系统:不仅具备计算和推理能力,还能直接与物理世界交互,以内嵌的多尺度物理知识作为推理约束,并根据物理反馈自主修正认知和策略。
它由四个紧密协同的支柱共同构成完整的认知-行动循环:自动化实验平台产出标准化物理数据;多尺度模拟提供跨尺度机理与虚拟数据;跨尺度端到端模型实现预测与逆向设计;可解释物质计算揭示其中的物理机制,所得洞察再反馈至实验和模型改进。
MCSE 所设想的闭环,需要打通虚拟筛选、高通量实验、可解释分析等大量异构模块,若这些模块各自独立运行,研发人员仍会陷入手工编排的低效困局。
破解这一困局的关键在于RhinoAI的Agentic架构:借助大语言模型与多Agent协同,将离散模块整合为一个能自主推理、自主决策、自主执行并自主更新的回路。
RhinoAI的Agentic架构具体是如何运作的?
RhinoAI的能力建立在分层技术基座上,由五大模块构成其物理推理、计算、实验执行和知识获取的基础:大语言模型(LLM)、材料科学模型、科学算法、自动化设备、数据库与知识库。
在此基础上,基于LLM和Harness的协同调度中枢对这些基础能力进行动态编排。
该Agentic架构将材料研发全流程抽象为一系列可分解、可协调的认知与操作任务,每一类Agent被赋予明确角色和功能边界,在主Agent的统一调度下协同工作,形成认知-行动回路的结构化实现。

RhinoAI如何实现持续进化和知识沉淀?
支撑RhinoAI协同与决策持续进化的核心是自主记忆机制。
每一次从假设生成、实验决策、物理执行到结果分析的完整回路,都被结构化为一条持久存储的「研发记忆」——包含目标、决策、行动序列、观测数据、模型版本和策略效能。
记忆系统不只记录实验参数和性能结果,还记录假设的提出与验证结论、模型的版本演替和预测精度,以及策略的成功与失败模式。
更重要的是,不同 Agent 协作与竞合中产生的新搜索策略、从预测误差中凝练的物理判据、跨尺度关联中被算法自主发现的隐藏描述符,这些能力并非预先设计,而是从闭环研发的长期历史中积累而来。
这些增量知识,包括经过实验验证的物理判据、可解释分析揭示的机理洞察,以及系统在迭代进化中产生的新认知,将沉淀为结构化的科学语料,反哺后续研发任务和模型训练。
CarbonKylin™已正式发布,它取得了哪些里程碑式的成果?
CarbonKylin™是鼎犀智创(Rhinovate™)面向碳基纤维领域打造的首个验证实例。
在RhinoAI的闭环迭代驱动下,CarbonKylin™自主完成了单体设计、工艺寻优与可解释分析的全流程,成功设计出一款碳材料掺杂的杂环芳纶复合纤维,拉伸强度达到41.2 cN/dtex,处于业界最佳水平。

更关键的是,系统深入揭示了碳材料与杂环芳纶复合所产生性能涌现的机理:碳材料表面与杂环芳纶分子链间形成强界面层,为应力传递提供了耦合通道;碳材料的锚定效应抑制了组装过程中的局部熵增与缺陷形成,从而实现了结构致密化。
这一发现实现了从「黑箱优化」到「可解释发现」的跨越。
作为RhinoAI落地的首个验证实例,CarbonKylin™的经验将如何向其他材料体系拓展?
CarbonKylin™验证了RhinoAI这条路径的可行性,但它只是起点。RhinoAI的关键优势在于「通用框架+专有知识+专用设备」的分层架构,使前沿材料研发不必在每个新方向上重复建设底层智能设施。
在架构设计上,RhinoAI的核心平台框架、多Agent 逻辑和自主记忆机制属于通用层,而领域知识和物理设备则属于专有层。
具体而言,通用层包括Agent的编排调度、记忆的存取与更新机制,以及辩论协议等与具体材料体系无关的基础设施;专有层则包含针对特定材料的跨尺度模型、专用表征设备和领域知识图谱,需要实质性的领域定制工作。
基于该分层架构,针对不同材料体系,研发团队只需聚焦于该领域的专有知识、专用设备与领域模型,即可开展深度的领域定制工作,快速构建出该体系专属的闭环研发能力——从文献检索、虚拟筛选、实验执行,到多尺度表征、因果分析与知识沉淀,全流程贯通,无需从零搭建底层架构。
目前,鼎犀智创(Rhinovate™)正积极布局高性能聚合物纤维、锂电池、半导体薄膜等材料体系,将RhinoAI的全闭环研发能力快速落地为领域专属的智能研发平台。
对于希望在材料研发中引入系统性智能能力的团队而言,RhinoAI提供的不是一个工具,而是一套经过验证、可直接部署的完整研发范式,它让每一个领域都能站在坚实的智能基础设施之上,将精力集中于让材料真正发挥出应有的性能。
文章原文
Imbad0202/academic-research-skills
Academic Research Skills for Claude Code: research → write → review → revise → finalize
Academic Research Skills 是一个专为学术研究者设计的AI协作技能套件,运行于Claude Code平台。它通过结构化流程,将AI作为副驾驶来处理文献检索、引用格式化、数据验证和逻辑一致性检查等机械性工作,旨在让研究者专注于定义研究问题、选择方法、解释数据和原创性写作等核心智力任务。项目强调人机协作(Human-in-the-loop),而非全自动AI研究,并内置了针对AI幻觉、思维锁定等失败模式的完整性检查机制。
- 结构化研究流水线 可扩展性
提供一个10阶段的学术研究编排流水线(从研究到出版),包含自适应检查点、完整性验证(Stage 2.5/4.5)、双阶段同行评审和协作质量评估。每个阶段都需要用户确认,并强制执行不可跳过的完整性检查门。 - 多代理协作系统 可扩展性
每个核心技能(深度研究、论文写作、评审)由多个专用AI代理协同完成,例如13个代理组成的研究团队、12个代理的论文写作管线、7个代理的同行评审小组(包括魔鬼代言人)。代理间职责清晰,支持Socratic引导、PRISMA系统综述等多种工作模式。 - 反幻觉与完整性验证 安全
集成了针对7类AI研究失败模式的检查清单、基于Semantic Scholar API的引用验证、对抗记忆污染的抗泄漏协议、以及交叉模型验证(可选)。完整性报告会详细列出已识别的伪造引用和统计错误。 - 元数据与契约控制 可观测性
为每个技能定义了`data_access_level`(数据访问级别)和`task_type`(任务类型)元数据,并通过CI脚本强制检查。引入了生成器-评估器合约(Schema 13.1)和审查员冲刺合约(Schema 13),以规范和约束AI在复杂交互阶段的行为。 - 人机协作深度度量 可观测性
通过可选的协作深度观察者(Collaboration Depth Observer)对用户-AI协作质量进行4维度评分(委托强度、认知警惕性等),基于教育心理学模型。该指标仅为建议性,不阻塞流程。
主要语言:Python(用于脚本、适配器和CI检查);核心运行时:Claude Code CLI / IDE 插件;文档生成:Pandoc(可选,用于DOCX)、tectonic(可选,用于PDF)、LaTeX;持续集成:GitHub Actions;参考API:Semantic Scholar API;许可证:CC-BY-NC 4.0。
- 系统性文献综述与元分析 (个人/小型团队)
自动化执行PRISMA流程、文献筛选、引用验证和数据提取,大幅提升综述效率并减少人为遗漏。 - 学术论文撰写与多轮修订 (个人/小型团队)
通过写作、评审、修改的闭环流水线,利用AI进行风格校准、质量检查、引用转换和回应审稿人意见,加速论文产出。 - 研究方法论训练与质量控制 (所有规模)
通过Socratic导师模式引导研究设计,并利用内置的完整性检查机制,帮助研究者(尤其是初学者)学习避免常见方法论陷阱。 - 同行评审准备与模拟 (个人/小型团队)
在提交前使用多代理评审系统(包括魔鬼代言人视角)对自己的论文进行高强度、结构化的模拟评审,提前发现弱点。 - 评估AI辅助研究的质量与协作深度 (所有规模)
为研究机构或项目团队提供客观的度量工具,用于评估和改进人机协作模式,确保AI工具增强而非替代研究者的核心工作。
- 方法论:明确反对全自动AI研究,将人机协作作为核心设计原则。内置了针对AI结构性局限(如思维锁定、谄媚)的检测与缓解机制(如魔鬼代言人让步阈值、意图识别层),这在同类工具中较为前沿。
- 流程严谨性:提供了业界罕见的、具有强制质量门(如Stage 2.5/4.5完整性检查)和结构化合约(Sprint Contract)的研究全流程编排,强调可追溯性和可审计性。
- 透明度与可扩展性:作为开源项目,所有技能提示、元数据定义、合约模式和检查脚本均公开。架构文档化程度高,允许用户深度定制和扩展研究流程。
- 项目活跃度高(68天内295次提交,22天活跃),且有持续的版本发布(15个Release)。
- 具备完整的CI流水线(GitHub Actions)进行规范一致性检查。
- 提供了详尽的架构文档(ARCHITECTURE.md)、设置指南和性能估算,表明项目设计考虑周全。
- 版本号已迭代至v3.7.0,并进行了多次重大架构升级和优化。
需注意
- 项目较新(年龄68天),虽发展迅速但长期稳定性有待观察。
- 项目完全依赖Claude模型,其输出的质量和稳定性受模型本身限制。
- 核心流程较为复杂,对用户的AI素养和学术研究方法论知识有一定要求。
- 强依赖Claude API,需要用户拥有有效的API密钥并承担相应费用,且模型行为变化可能影响工具效果。
- 定位为AI副驾驶,无法完全替代研究者的核心思考与决策过程,最终论文质量仍取决于使用者本人。
- 部分高级功能(如跨模型验证、VLM图表验证)需要配置额外的模型API,增加了使用复杂度。
- 目前主要针对基于文本的学术写作,对数据分析、实验执行等环节的支持需要结合其姊妹项目(experiment-agent)。
搭建:medium · 学习曲线:medium
关键依赖:Claude Code CLI 或 IDE 插件、Claude API 密钥、(可选)Pandoc/tectonic 用于生成DOCX/PDF、(可选)其他模型API(如GPT-5.4 Pro)用于交叉验证
近 7 日该项目开发非常活跃,提交数达 61 次,表明团队在快速推进功能开发。主要工作集中在提交包验证器和差异/补丁修订模式两个核心特性的构建上,同时进行了多项文档更新和缺陷修复。社区关注度极高,新增 Star 数超过 3000,反映出学术工具需求的增长和项目功能的成熟度。
Star +3018 · 61 次提交(近 7 日)
- 新功能提交包验证器 Slice 1新增 CLI 骨架和 Family C 参考完整性检查,为验证器提供基础功能框架。
- 新功能提交包验证器 Slice 2引入学者声明场地档案和 Family B 限制检查,增强提交包的合规性验证。
- 新功能提交包验证器 Slice 3实现 Family A 盲审残留扫描和 Family D 评估,提升学术提交的质量控制能力。
- 新功能提交包验证器 Slice 4完成验证器的终端性检查功能,确保提交流程的完整性和一致性。
- 新功能差异/补丁修订模式 A引入确定性工具链,支持修订模式的可靠应用和追踪。
- 新功能差异/补丁修订模式 B推进修订模式的采用,促进学术文档的协作修订工作流。
- 修复修复符号链接同步问题将 agents/ 符号链接物化为真实副本并修复镜像同步 lint,提升项目文件管理的稳定性。
- 文档提交包验证器设计规范记录残留扫描、场地档案和参考完整性的设计规范,为开发者提供明确指导。
chopratejas/headroom
Compress tool outputs, logs, files, and RAG chunks before they reach the LLM. 60-95% fewer tokens, same answers. Library, proxy, MCP server.
Headroom 是一个为AI代理设计的上下文压缩层,在工具输出、日志、文件和RAG块到达LLM前进行压缩。它通过减少60-95%的token使用量,同时保持答案质量,帮助开发者显著降低成本并提升效率。项目主要面向使用LLM的应用开发者,特别是处理大量上下文数据的场景,如代码搜索、故障调试和跨代理协作。
- SmartCrusher 性能
基于内容路由的JSON压缩器,自动检测并压缩数组、嵌套对象等结构,通过智能解析实现高效数据缩减。 - CodeCompressor 性能
AST感知的代码压缩,支持Python、JavaScript、Go等多种语言,在保持代码结构完整的同时减少token数量。 - Kompress-base 性能
基于HuggingFace的文本压缩模型,针对代理跟踪数据训练,提供高比率的文本压缩,并确保压缩后内容可读。 - 跨代理记忆共享 可扩展性
通过共享存储支持多个AI代理,实现上下文自动去重、溯源和共享,提升跨代理协作效率。 - 可逆压缩(CCR) 安全
存储原始数据本地,LLM通过检索工具按需获取,确保信息不丢失且可追溯,同时保护数据隐私。
语言:Python 3.10+ 和 TypeScript;框架:自定义库、代理服务器和MCP服务器;存储:本地文件系统,可选向量数据库如Qdrant;基础设施:GitHub Actions CI/CD,Docker容器化;工具链:pip、npm、pytest、HuggingFace模型。
- 代码搜索结果压缩 (所有规模)
将搜索结果token数减少92%,保持搜索准确性,显著降低LLM调用成本和延迟。 - SRE故障调试日志分析 (中型企业)
压缩大量日志数据,快速定位问题,节省token消耗并加速故障响应。 - GitHub Issue自动分类 (个人/小型团队)
压缩issue内容,提高分类效率,减少处理开销和人工干预。 - 多代理协作上下文共享 (中型企业)
通过跨代理记忆共享,避免重复压缩,提升团队协作效率和上下文一致性。
- 部署方式:支持本地运行,所有数据处理在用户环境中完成,无需上传到外部服务,保护隐私并减少延迟。
- 可逆性:提供可逆压缩(CCR),原始数据始终保留,LLM可按需检索,确保信息完整性和可追溯性。
- 覆盖范围:压缩所有类型的上下文数据,包括工具输出、日志、RAG块等,而其他工具通常只覆盖特定类型(如CLI输出)。
- 项目有100个Release,表明版本管理活跃
- 近30日提交306次,活跃天数26,开发频繁
- Star 4226,有社区基础和基准测试支持
- 提供完整文档、CI/CD和许可证
需注意
- 项目年龄仅145天,尚未经过大规模长期生产验证
- 依赖外部LLM提供商,可能受API变化影响
- 需要Python 3.10或更高版本,不支持旧版Python环境。
- 在某些沙箱或受限环境中无法运行本地进程,限制了使用场景。
- 压缩算法可能在某些边缘案例中轻微影响LLM输出准确性,尽管基准测试显示影响很小。
搭建:low · 学习曲线:low
关键依赖:Python 3.10+、Node.js/npm(用于TypeScript集成)、可选:Docker、可选:向量数据库如Qdrant
该仓库在近7日内开发高度活跃,提交数达96次,主要工作聚焦于代理功能增强、压缩算法优化和安全修复。新增的Apple-GPU支持和Hermes插件扩展显示了项目对性能和集成能力的重视。结合10583个新增Star,表明社区对该项目关注度极高,可能由于新功能发布吸引了大量用户。
Star +10583 · 96 次提交(近 7 日)
- 新功能日志压缩消息在代理中新增功能,记录压缩消息和原始请求,便于调试和分析。
- 新功能添加代理90节省配置引入新的代理节省配置文件,优化资源使用和性能。
- 新功能Hermes代理插件新增插件支持Hermes代理的头信息检索功能,扩展插件系统。
- 新功能检测重复服务工具结果识别工具结果重复服务作为过度压缩的浪费信号,提高效率。
- 新功能网络成本缓存变更公式在压缩策略中实施网络成本缓存变更公式,优化性能。
- 新功能Markdown-KV格式化器新增门控Markdown-KV压缩格式化器,支持序列化感知输出。
- 新功能基于探测的保留评分对压缩事件实施基于探测的保留评分机制,提升数据管理。
- 新功能Apple-GPU嵌入运行时添加可选的Apple-GPU (MPS)嵌入运行时,利用GPU加速嵌入计算。
HKUDS/Vibe-Trading
"Vibe-Trading: Your Personal Trading Agent"
Vibe-Trading 是一个 AI 驱动的多代理金融工作空间,能够将自然语言请求转换为跨全球市场的可执行交易策略、研究洞察和投资组合分析。它解决了传统策略开发中编程复杂性和专业知识门槛高的问题,面向交易者、投资者和量化分析师。通过集成 6 种数据源、29 个代理团队预设和 7 个回测引擎,用户无需编码即可进行深度研究和自动化策略生成。
- 自然语言策略生成 易用性
基于 ReAct 代理核心,用户通过自然语言描述交易想法,系统自动生成、测试和导出交易代码,支持 74 个专业金融技能,实现零编码策略开发。 - 多代理团队工作流 集成
提供 29 个预定义的 DAG 多代理编排团队,例如投资委员会辩论和量化策略工作流,支持实时流式仪表板和跨会话搜索,实现复杂金融任务的协作自动化。 - 跨市场回测引擎 性能
集成 7 个市场引擎(包括 A 股、港股、美股、加密货币等)和组合跨市场引擎,支持 Monte Carlo、Bootstrap CI 等统计验证,以及 4 个优化器,实现全面策略回测。 - 持久跨会话记忆 可扩展性
通过文件系统持久化记忆(~/.vibe-trading/memory/),代理能记住用户偏好并自动进化可重用技能,支持 5 层上下文压缩和 FTS5 会话搜索,确保长期学习和自适应。 - 多平台策略导出 集成
一键导出交易策略到 TradingView(Pine Script v6)、通达信(TDX)和 MetaTrader 5(MQL5),支持跨市场适配,简化策略部署和实盘前准备。
语言:Python 3.11+;后端框架:FastAPI;前端:React 19 + Vite + TypeScript;存储:文件系统(如持久记忆和会话数据);基础设施:Docker 支持,CI/CD 管道;工具链:PyPI 包发布(vibe-trading-ai)、MCP 服务器(22 个工具)、LLM 提供商抽象层(支持 13 个提供商如 OpenAI、DeepSeek、Ollama);数据源:AKShare、yfinance、CCXT、Tushare 等。
- 策略回测与优化 (所有规模)
用户通过自然语言快速测试交易策略(如移动平均交叉),获得 Sharpe 比率、最大回撤等指标,并导出到交易平台,加速策略迭代。 - 市场深度研究 (个人/小型团队)
利用代理团队进行股票基本面分析、宏观趋势评估或加密货币链上分析,生成研究报告,提升投资决策质量。 - 多代理协作工作流 (中型企业)
使用预定义团队(如投资委员会)进行多空辩论、风险审查,实现自动化投资流程,提高团队协作效率。 - 交易行为分析 (个人/小型团队)
上传经纪商导出文件(如 CSV、PDF),系统自动分析交易偏差(如过度交易、处置效应),帮助用户改善交易习惯。
- 生态集成:支持 6 种数据源(A 股、港股、美股、加密货币、期货、外汇)和 13 个 LLM 提供商,提供零配置免费数据回退,而同类工具通常需要多个 API 密钥或付费数据源。
- 功能完整性:集成策略生成、回测、研究和导出于一体,提供 74 个专业技能和 29 个代理团队,相比单一功能的交易工具(如 Backtrader)更全面。
- 用户体验:通过自然语言交互和自进化技能系统,降低金融量化分析门槛,同时提供 CLI、Web UI 和 MCP 插件多种接入方式,适应不同用户场景。
- 项目年龄仅 32 天,但已有 3 个 Release 版本和 CI/CD 支持
- 近 30 日有 92 次提交和 21 天活跃,显示积极开发
- README 明确声明“仅用于研究、模拟和回测”,未提及实盘交易支持
- 提供 Docker 部署和安全硬化补丁,但远程部署需配置 API_AUTH_KEY
需注意
- 需要外部 LLM API 密钥(除 Ollama 外),增加了使用依赖
- 作为早期项目,可能存在稳定性问题或功能不完整
- 安全策略依赖用户配置 API_AUTH_KEY,否则可能暴露风险
- 不支持实盘交易执行,仅限于研究和回测,用户需自行部署策略到其他平台。
- 重度依赖 LLM 提供商(如 OpenAI、DeepSeek),模型质量和成本可能影响使用体验。
- 数据源如 AKShare、yfinance 为免费服务,可能存在数据延迟或限制,不适合高频交易。
- 跨会话记忆基于文件系统,在大规模并发或多用户场景下可能性能不足。
搭建:low · 学习曲线:medium
关键依赖:Python 3.11+、LLM API 密钥(如 OpenAI、DeepSeek)、可选:Docker
Vibe-Trading 仓库近7日保持高度活跃开发状态,提交数达32次。开发工作主要集中在Docker容器持久化、Swarm模块数据工具集成、Web界面改进以及文档更新。新增Star 1169表明社区关注度持续高涨,项目吸引力增强。结合提交内容,团队正致力于提升易用性和功能扩展,推动生态发展。
Star +1169 · 32 次提交(近 7 日)
- 新功能Swarm股票修复修复Swarm提示中裸US股票代码的处理,确保市场数据获取准确,提升代理工具可靠性。
- 修复Docker状态持久化修复Docker容器重建时用户代理状态丢失的问题,通过持久化机制保障用户体验连续性。
- 修复Web SSE超时保护为Web界面添加SSE安全超时机制,防止无事件时无限挂起,增强系统稳定性。
- 新功能显示代理状态在聊天界面中显示Swarm代理状态,提高交互透明度,方便用户监控任务进展。
- 新功能Alpha对比工具在CLI、REST、Web UI和代理工具中新增Alpha对比功能,支持多端数据比较,促进策略分析。
- 文档数据加载器指南添加自定义数据加载器指南文档,帮助开发者扩展数据源接入,降低集成门槛。
- 修复LLM签名保留修复在AgentLoop字典路径中保留Gemini thought_signature的问题,确保LLM交互流程正常。
- 更新Docker CI优化在文档推送时跳过GHCR边缘构建,减少不必要的CI资源消耗,提升构建效率。
heygen-com/hyperframes
Write HTML. Render video. Built for agents.
HyperFrames 是一个开源视频渲染框架,允许用户通过编写 HTML 来创建、预览和渲染视频。它解决了传统视频制作工具复杂性和与 AI 集成不足的问题,专为 AI 代理设计,支持确定性渲染和自动化工作流。面向开发者、内容创作者以及使用 AI 代理进行视频生成的团队。
- HTML-native 视频创作 易用性
基于标准 HTML 和 CSS 编写视频组成,无需 React 或专有 DSL,使用 data 属性定义时间线和属性,简化开发流程。 - AI 代理深度集成 集成
提供技能和插件系统,让 AI 代理如 Claude Code、Cursor 能直接理解和生成 HyperFrames 代码,支持自动化视频生成。 - 确定性帧渲染 性能
使用 Puppeteer 驱动的无头浏览器和 FFmpeg 进行渲染,确保相同输入产生相同输出,适合自动化视频管道。 - 可扩展帧适配器 可扩展性
通过帧适配器模式支持多种动画运行时(如 GSAP、Lottie、Three.js),允许开发者集成现有动画库。 - 组件化视频块 易用性
提供 50+ 预构建组件(如社交覆盖、着色器转换、数据图表),可通过 CLI 快速添加,加速视频制作。
语言:TypeScript;运行时:Node.js(要求 >=22);渲染引擎:Puppeteer(无头浏览器) + FFmpeg(视频编码);动画支持:集成 GSAP、Anime.js、CSS 等;工具链:npm 用于包管理,CLI 用于开发循环;容器化:支持 Docker 部署。
- AI 代理驱动的视频创作 (所有规模)
通过自然语言描述自动生成视频,降低视频制作门槛,加速内容产出。 - 产品营销视频制作 (中型企业)
快速创建高质量产品介绍视频,用于广告和社交媒体推广。 - 数据可视化动画生成 (所有规模)
将原始数据转换为动态图表,提升报告和演示的吸引力。 - 社交媒体内容批量生产 (个人/小型团队)
利用组件和模板快速生成 TikTok、Instagram 风格视频,提高发布频率。
- 编写范式:使用 HTML 而非 React 组件,降低学习成本,无需构建步骤。
- 开源许可证:采用 Apache 2.0 许可,完全开源,无商业使用限制。
- AI 集成深度:原生支持 AI 代理,提供专门的技能系统,简化自动化视频生成。
- 项目年龄仅54天但已有91个Release,表明快速迭代
- 近30日提交369次,活跃天数28,开发活跃
- Star总数14115,增长迅速,社区兴趣高
- 有CI、License和完整包结构
需注意
- 项目较新,可能缺乏长期稳定性验证
- 分布式渲染仅支持单机,限制大规模应用
- 当前仅支持单机渲染,无法处理分布式视频渲染任务。
- 项目较新,可能功能不完善或存在未发现的bug。
- 依赖 Node.js >=22 和 FFmpeg,对环境有特定要求。
搭建:medium · 学习曲线:medium
关键依赖:Node.js >=22、FFmpeg、npm
hyperframes 本周开发极其活跃,提交数达 125 次,显示团队在核心引擎、SDK、工作室和 CLI 工具上持续投入。主要工作方向包括 SDK 引擎层搭建、时间线分割功能开发、核心 Bug 修复以及代码重构。社区关注度显著提升,新增 2480 个 star,表明项目在动画框架领域的快速成长和开发者兴趣。
Star +2480 · 125 次提交(近 7 日)
- 新功能SDK 会话 API新增 SDK 会话 API,支持可选历史和持久队列,完成 Phase 3a 开发,提升会话管理能力。
- 新功能SDK 引擎层搭建 @hyperframes/sdk 引擎层,包括模型、RFC 6902 补丁和应用功能,奠定 SDK 基础。
- 新功能导出 hf-ids将 hf-ids 作为子路径导出,供 @hyperframes/sdk 使用,方便外部集成。
- 新功能时间线分割 UI在工作室中新增剃刀/刀片工具 UI,用于时间线片段分割,增强编辑功能。
- 新功能GSAP 分割引擎核心引擎添加 GSAP 感知分割功能,支持时间线片段分割,优化动画处理。
- 新功能GIF 输入支持支持动画 GIF 输入,通过 VP9 转码实现帧同步播放,扩展输入格式。
- 修复核心功能修复修复 split-into-property-groups 和 replace-with-keyframes 突变中的问题,提升稳定性。
- 重构工作室组件重构提取共享时间线组件并去重代码,提高代码复用性和维护性。
原创 王召德、潘逢治 2026-06-11 19:44 浙江
当我们谈论“把大模型跑在手机上”时,速度始终是绕不开的核心问题。模型越大、参数越多,推理时的矩阵乘法运算量就越大。
随着 Arm 第二代可伸缩矩阵扩展 (SME2) 技术的普及,以及 MNN 推理引擎的深度适配,我们找到了一把打开端侧性能天花板的钥匙。只需在编译时开启一个开关,就能让 Qwen3-VL-4B 这样强大的多模态模型,在支持 SME2 的旗舰手机(如 vivo X300 等)上实现实时流畅推理。
本文,我们直接从工程落地的角度,手把手带你完成从引擎编译、模型部署到 APP 构建的完整流程,并用实测数据告诉你:为什么这套组合拳能让 Qwen 在端侧起飞。
什么是 SME2?
SME2 是 Armv9 架构中的一组高级 CPU 指令,它基于 SME 升级,核心突破在于引入了 ZA 矩阵累加器寄存器和流式模式。传统 Neon 做矩阵乘需要手工将外积拆成向量乘再累加,而 SME2 中的 FMOPA 等指令可以一条指令完成一个矩阵 tile 的外积累加。
通过引入 SME2 指令集,Armv9 架构 CPU 能够在 AI 异构计算框架下,高效支持大语言模型推理、图像处理、自然语言处理、语音生成等实时移动端推理任务。
认识我们的工具箱
在开始实战前,我们先了解一下本次部署的核心组件:
MNN:阿里巴巴开源的端侧推理引擎,具备高性能、轻量级、高通用性的特点。支持 CNN、Transformer、LLM、扩散模型等多种架构。
MNN-LLM:MNN 中专为大语言模型设计的模块,提供了从模型转换、量化到推理部署的全链路工具。
Qwen 模型:本文以 Qwen3-VL-4B-Instruct 为例——一个 4B 参数的视觉语言模型,支持图文理解和对话,体积适中,模型能力较强。
MNN 模型仓库:MNN 官方已经为大家转换和量化了多款 Qwen 模型,可直接下载使用。
MNN 的 SME2 适配:MNN 对 SME2 的支持采用编译时内建 + 运行时自动检测的设计,用户无需手动配置:
编译时:通过 MNN_SME2 开关(默认 ON)控制是否编译 SME2 优化内核
运行时:启动时自动检测硬件是否支持 SME2,支持则走 SME2 加速路径,不支持则回退到 i8mm → Neon,不会崩溃
三精度覆盖:FP32、FP16、INT8/INT4 量化均有手写 SME2 汇编内核
大小核调度:感知 SoC 大小核拓扑,SME2 大核用大 tile 处理主体计算,Neon 小核处理剩余部分,并行工作
KleidiAI 集成:集成 Arm 官方 KleidiAI 加速库,提供更多 SME2 微内核
实战演练:从零构建 SME2 加速的端侧大模型
接下来我们从源码开始,手把手走一遍开启 SME2 加速的完整端侧大模型部署流程。
前置准备
请确保以下环境已就绪:
Android NDK:推荐 r27+,需设置
$ANDROID_NDK环境变量ADB:用于与手机通信,
adb devices可正常发现设备JDK 17:Gradle 编译 APP 所需
手机:开启开发者模式和 USB 调试,通过 USB 连接电脑
Step 1:编译推理引擎
🟣 为 Android 编译 MNN 引擎的动态库(.so 文件)和命令行推理工具。
SME2 功能默认开启,可以通过 -DMNN_SME2=ON/OFF 显式控制开关。
# 1. 进入 MNN 的 Android 工程目录cd MNN/project/android# 2. 创建编译目录mkdir build_64 && cd build_64# 3. 执行编译(SME2 默认开启,可通过 -DMNN_SME2 控制)../build_64.sh "-DMNN_SME2=ON -DMNN_KLEIDIAI=ON -DMNN_LOW_MEMORY=true -DMNN_CPU_WEIGHT_DEQUANT_GEMM=true -DMNN_BUILD_LLM=true -DMNN_SUPPORT_TRANSFORMER_FUSE=true -DMNN_ARM82=true -DMNN_USE_LOGCAT=true -DMNN_OPENCL=true -DLLM_SUPPORT_VISION=true -DMNN_BUILD_OPENCV=true -DMNN_IMGCODECS=true -DLLM_SUPPORT_AUDIO=true -DMNN_BUILD_AUDIO=true -DMNN_BUILD_DIFFUSION=ON -DMNN_SEP_BUILD=OFF -DCMAKE_SHARED_LINKER_FLAGS='-Wl,-z,max-page-size=16384' -DCMAKE_INSTALL_PREFIX=."# 4. 整理编译产出make install
💡 make install 是必要的——它会将 libMNN.so 拷贝到 build_64/lib/ 目录,后续 APP 编译时会从这个路径引用动态库。
编译完成后,build_64/ 目录下会生成以下关键文件:
libMNN.so:MNN 核心引擎库llm_demo:命令行推理工具llm_bench:性能基准测试工具
Step 2:准备模型
🟣 方案一:直接下载 MNN 格式的模型(推荐)
MNN 官方已提供转换和量化好的模型,可一步到位:
cd MNN/transformers/llm/exportpip install modelscopemodelscope download --model MNN/Qwen3-VL-4B-Instruct-MNN --local_dir Qwen3-VL-4B-Instruct-MNN
🟣 方案二:使用 MNN 的模型转换工具自行转换
如果需要自定义量化参数或使用其他模型,可以手动转换:
# 1. 进入 MNN-LLM 的 export 目录cd MNN/transformers/llm/export# 2. 安装 Python 依赖pip install -r requirements.txt# 3. 从 ModelScope 下载原始模型modelscope download Qwen/Qwen3-VL-4B-Instruct --local_dir Qwen3-VL-4B-Instruct# 4. 执行转换(HQQ 量化)python llmexport.py --path Qwen3-VL-4B-Instruct --dst_path Qwen3-VL-4B-Instruct-MNN --export mnn --hqq
💡 提示:--export mnn 代表导出为 MNN 格式,--hqq 是推荐的量化选项,可以有效提升模型精度。
Step 3:推送到手机,命令行验证
🟣 将引擎和模型推送到手机,通过命令行快速验证推理是否正常。
# 1. 推送引擎文件到手机adb push project/android/build_64/llm_demo /data/local/tmp/adb push project/android/build_64/llm_bench /data/local/tmp/adb push project/android/build_64/libMNN.so /data/local/tmp/# 2. 推送模型到手机adb shell mkdir -p /data/local/tmp/mnn_modelsadb push Qwen3-VL-4B-Instruct-MNN /data/local/tmp/mnn_models/# 3. 进入手机 shelladb shell# 4. 赋予执行权限chmod +x /data/local/tmp/llm_demo /data/local/tmp/llm_bench# 5. 创建 prompt 文件echo "你好" > /data/local/tmp/prompt.txt# 6. 设置动态库路径并运行推理cd /data/local/tmpexport LD_LIBRARY_PATH=/data/local/tmp:$LD_LIBRARY_PATH./llm_demo /data/local/tmp/mnn_models/Qwen3-VL-4B-Instruct-MNN/config.json /data/local/tmp/prompt.txt
💡 知识点:为什么要设置 LD_LIBRARY_PATH?llm_demo 动态链接了 libMNN.so,Android 系统默认只在 /system/lib64 等系统目录搜索动态库,不会搜索 /data/local/tmp/。设置此变量告诉链接器也去指定目录查找。
当你看到模型流畅地回复时,恭喜,推理引擎已经跑通了!
🟣 确认 SME2 硬件支持
在电脑上另开一个终端窗口,运行:
adb logcat | grep "device supports"会看到类似输出:
The device supports: i8sdot:1, fp16:1, i8mm: 1, sve2: 1, sme2: 1其中 sme2: 1 表示手机的 CPU 硬件支持 SME2 指令集,MNN 引擎会自动使用 SME2 加速路径进行推理。
💡 这行日志反映的是硬件检测结果,与编译选项无关。-DMNN_SME2=ON/OFF 控制的是编译产物中是否包含 SME2 优化代码——即使硬件支持,如果编译时关闭了该选项,引擎也不会走 SME2 加速路径。
Step 4:构建端侧 AI 应用
🟣 命令行验证成功后,我们可以将推理能力集成到一个完整的 Android APP 中。本文以 MNN 自带的 MNN Chat 示例应用为例:
# 1. 进入示例应用目录cd MNN/apps/Android/MnnLlmChat# 2. 编译 APK./gradlew assembleStandardDebug# 3. 安装到手机adb install app/build/outputs/apk/standard/debug/app-standard-debug.apk
💡 提示:APP 编译时会自动从 project/android/build_64/lib/ 引用 libMNN.so 并打包进 APK,所以不需要再手动推送 .so 文件到手机——安装 APK 即完成了引擎的部署。
安装完成后,如果之前 Step 3 已将模型推送到 /data/local/tmp/mnn_models/,打开 MNN Chat 即可在"我的模型"中找到 Qwen3-VL-4B-Instruct 模型。你也可以通过 APP 内的模型市场直接下载其他模型。
以下是 MNN Chat 在手机上进行多模态问答的实际演示——用户拍照后,模型即可理解图片内容并流畅回答:
性能测评:SME2 带来多大提升?
为了验证 SME2 带来的实际性能收益,我们分别编译了 SME2 开启 和 SME2 关闭 两个版本的引擎,在同一台设备上使用 llm_bench 进行对比测试。
测试环境
设备:vivo X300
模型:Qwen3-VL-4B-Instruct-MNN
测试工具:llm_bench
Prefill 阶段提升最为显著(+81%):因为 Prefill 需要一次性处理整段输入 token,是计算密集型任务(大批量矩阵乘),能充分利用 SME2 的矩阵外积指令和大 tile(HP=128)内核。这直接意味着更短的首字等待时间。
Decode 阶段提升相对较小(+13%):因为 Decode 是逐 token 生成,矩阵乘退化为矩阵×向量运算(batch=1),瓶颈在内存带宽而非计算吞吐,SME2 的优势相对有限。
进阶调优
在完成基本部署后,你可以根据自己应用的需求,通过以下手段进一步提升性能和精度:
🟣 模型导出参数调优 在执行 llmexport.py 时,可以附加不同参数:
🟣 运行时参数调优 模型导出后,可以通过修改 config.json 控制运行时行为:
通过本文,我们完成了一条完整的端侧大模型部署路径:编译 MNN 引擎 → 准备模型 → 命令行验证 → 构建 APP → 性能测评。
SME2 作为 Arm 最新的矩阵加速指令集,在 MNN 的深度适配下,为端侧大模型推理带来了实实在在的性能提升——Prefill 阶段提速超过 80%。而 MNN 的"编译时内建 + 运行时自动检测"设计,让开发者无需额外配置即可享受硬件加速红利。
随着SME2技术的进一步广泛采用,端侧 AI 的性能天花板正在被不断抬高。期待看到更多创新的端侧 AI 应用!
你在端侧部署中遇到的最大“坑”是什么?欢迎在评论区分享,我们将选取三位同学送出定制周边一份。
推荐阅读
Agent 辅助开发,一站式打通 Qwen3-VL Android 端侧推理
教程首发|让手机拥有视觉感知能力
“With a software upgrade, operators can squeeze more capacity, better observability, and more accurate location-based services out of the 5G network they bought years ago,” Mobile Experts
Ericsson’s AI in RAN offers an alternative to Nokia’s tie-up with NVIDIA in the shape of a software subscription. Nokia’s approach relies on GPUs to act as a general-purpose compute fabric.
The vendor says the tech has been proven in more than 15 commercial network deployments and trials around the globe – see the quotations from operators below. Ericsson states it delivers up to 20% higher downlink throughput and up to 10% better spectral efficiency. It also supports up to twice as many high-volume users and offers coverage predictions that are 90–95% accurate, and is to up to 5x more precise about users’ positioning.
Joe Madden, Principal Analyst at Mobile Experts, says: “This could be the best ROI for mobile operators in years. With a software upgrade, operators can squeeze more capacity, better observability, and more accurate location-based services out of the 5G network they bought years ago.”
Since announcing its tie-up with NVIDIA last October and pivoting to reposition itself as an AI infrastructure company, Nokia’s share price has doubled, leaving Ericsson’s share price trailing – see below. So can Ericsson’s counter to NVIDIA/Nokia’s physical AI monetisation story succeed (not that there are any guarantees operators will buy into the GPU-in-the-RAN model)?
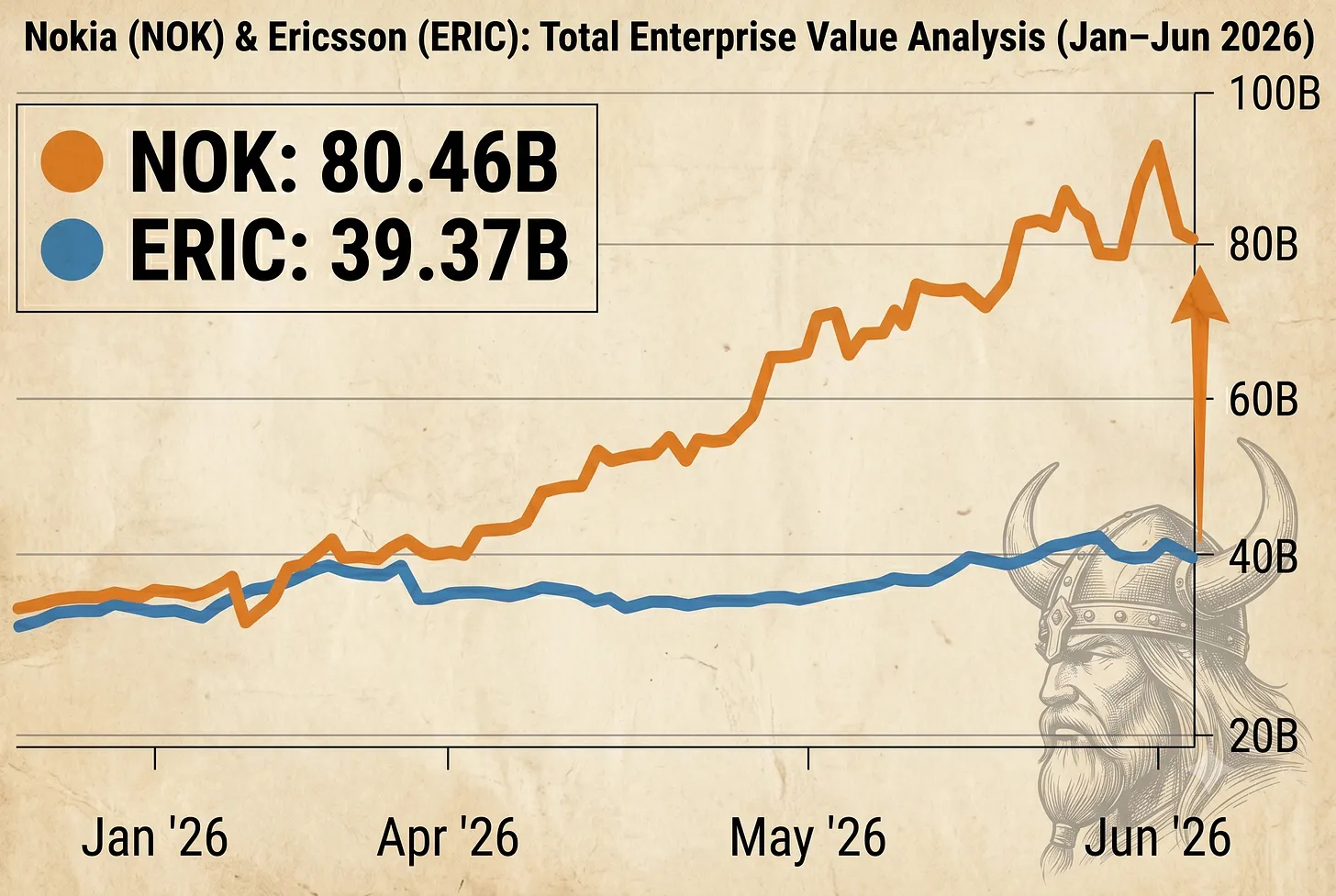
Source: Sebastian Barros, What in Valhalla is Going on With Nokia? 2X Value to 80B in 6 Months!, published 9 June 2026
Before we get going on the new AI in RAN part, Ericsson is keen to point out it has introduced AI functionality across its products since 4G, and in 2021 added AI‑ready acceleration in RAN Compute. More to the point, in February, it unveiled Neural Network Accelerators in its Massive MIMO radios, increasing AI inference capability by 10 times.
What is AI in RAN?
Ericsson’s new AI in RAN is a software subscription that “brings telco-grade AI models into basebands and radios to boost efficiency, performance, and energy savings. This commercially scalable offering gives communications service providers (CSPs) immediate benefits for 5G networks and supports the shift to AI-native RAN without requiring additional hardware.”
Ericsson AI in RAN introduces:
• Telco-grade AI models designed to run in real time within the RAN
• Continuous learning software powered by scalable, ‘high-quality’ data
• Agentic AI support for advanced RAN automation and network operations.
It works with Ericsson 5G Advanced across both purpose-built and Cloud RAN platforms to enable new AI-driven services. Some of the software features include AI-native Scheduler for Link Adaptation (see info on trial with T-Mobile US here), AI-powered Macro Positioning, AI-managed Beamforming, AI-powered Multi-layer Coordination, Performance Management Event Schema Files, and Augmented Observability for AI in RAN.
The first AI in RAN features are available in Q2 2026, with enhancements scheduled for later in the year.
What the operators say…
Teruyuki Oya, Senior Vice President & CNO at SoftBank Corp, comments, “Ericsson’s AI in RAN software marks an important step in bringing AI deeper into the radio access network. By enabling realtime optimization of radio performance, spectrum efficiency and user experience, it helps us turn AI innovation into practical value on live networks. We also see strong potential in how this foundation can support emerging AI-driven services, including Physical AI scenarios that depend on low-latency, highly reliable connectivity, and intelligent coordination between network and compute resources.”
Bruce Dean, Senior Vice President, Network Technology & Operations at Bell, is also in favour, “At Bell, we’re continuously evolving our network to meet growing demand for high-performance, AI-driven services. Integrating AI directly into the RAN is an important step in making networks more intelligent and efficient. Working with partners like Ericsson, we’re bringing these capabilities into our network to enhance performance, improve energy efficiency and deliver a better experience for our customers.”
Yu Takki, Head of Network Technology Office at SK Telecom, adds, “Through our collaboration with Ericsson, SK Telecom is advancing AI-RAN to enhance network performance and energy efficiency while supporting more intelligent and automated operations. By combining research, real-world validation and software innovation, we aim to strengthen our leadership in AI-powered network evolution and help lay the foundation for AI-native 6G.”
Mark Kennedy, CTO at Rogers, says, “As Canada’s best 5G+ network, we’re proud to work with Ericsson and bring the latest 5G technology to Canadians. AI in RAN will help optimize network performance for customers in real-time and reduce energy consumption.”
Last word to Ericsson
“Ericsson is redefining what’s possible in mobile networks by bringing powerful AI capabilities to service providers,” says Mårten Lerner, Head of Networks Strategy & Product Management at Ericsson. “With AI in RAN software, we are taking a major step toward AI-native networks, alongside the AI-ready radios we unveiled in February.”
He adds, “With AI in RAN, Ericsson is bringing AI into networks to elevate 5G performance and efficiency through energy-efficient AI inference at scale”.
The post Ericsson’s monetisation plan for AI in RAN without GPUs appeared first on Mobile Europe.

新智元报道
新智元报道
【新智元导读】GPT-5.6本月上桌,agentic编码据称已反超Anthropic Mythos!三家旗舰模型撞进同一个6月,两大AI巨头同时冲刺IPO,奥特曼却在内部抛出了一个更大的变量:如果AI先学会自我改进,上市反而不急。
GPT-5.6,本月发!
就在刚刚,OpenAI毫无预兆打出了一波连招。
ChatGPT熟悉的模型代号被直接抹去,全部换成了Intelligence「智力分级」。


WSJ独家爆出,OpenAI正酝酿大幅调低API定价,准备跟Anthropic打一场价格战。
紧接着,首席科学家Jakub Pachocki亲自放话,代号5.6、「大幅超越」前代的新模型,本月直接上桌。
降价、改版、新模型,一个疯狂的星期三。
但这些加在一起,都不如奥特曼在内部Slack里漏出的一句话——
如果AI的递归自我改进起飞速度够快,推迟上市的好处反而越大。

现在的大背景是,所有人都在抢着上市。
Anthropic在6月1日向SEC秘密递交了S-1,SpaceXAI已经在路演,估值1.77万亿。OpenAI自己也在6月8日跟进递表,三家合计估值约3.6万亿美元,相当于法国一整年的GDP。
投行给的建议很一致,谁先上市,谁就定义投资者对AI赛道的估值框架。
先手优势,兵家必争。
然而就在这时,奥特曼却提出了一个所有人都没有公开讨论过的变量:
AI递归自我改进的起飞速度越快,推迟IPO的好处就越大。
因为技术和世界可能以意想不到的方式发生变化,在那段时间里做一家私人公司可能有充分的理由。

他的意思不是「不想上市」,而是一旦AI发展到能自我改进的临界点,整个商业世界的规则都可能被推翻。到那时候,私有公司的灵活度要比上市公司大得多。
Anthropic的数据在侧面印证这个判断。
他们内部报告显示,AI的任务完成时间跨度正在每4个月翻一倍,工程师的季度代码产出量已经飙到了之前的8倍。
而奥特曼说这话的同一天,他的首席科学家正在用行动告诉所有人,那一天可能比想象中近得多。
GPT-5.4在3月5日发布,GPT-5.5在4月23日紧随其后,间隔6周。
GPT-5.6定在6月,又是6到7周的节奏。
这是一条稳定加速的曲线,而且代际之间的能力跳变,没有放缓的迹象。

海外社区早就围着GPT-5.6的「泄露」扒了个底朝天。
从5月中旬起,开发者就在Codex后台日志里发现了GPT-5.6的路由痕迹,内部代号iris-alpha。

随后陆续出现ember-alpha、beacon-alpha,再往后是kepler和kindle。
到6月初,kindle-alpha被确认为当前的发布候选版本。
有人在Design Arena上发现了匿名模型「Kindle」,跑了几轮实测后判断这就是kindle-alpha的公开测试形态。
后来kindle被移除,但GPT-5.6的存在已经板上钉钉。

目前社区讨论最集中的是两个方向的提升。
第一个是前端生成能力。不需要复杂的提示词,模型就能直接输出干净的、接近商用级的UI界面。
一位泄露者用最早期的iris-alpha检查点,在零指导的情况下生成了一个叫Lumen Notes的笔记应用,薰衣草色调,网格对齐,层级清晰,看起来就像一个成熟SaaS产品的截图。

第二个是agentic coding能力。
知名开发者Mark Kretschmann在𝕏上表示,「据我所知,GPT-5.6非常强大,在多个agentic coding基准上击败了Anthropic Mythos。」

奥特曼在近期的活动中曾表示,企业客户对AI使用成本越来越敏感。
因此价格这个点,可能是OpenAI接下来最关键的变量之一。
Anthropic刚刚发布的Fable 5和Mythos 5,API定价是每百万输入token 10美元、输出50美元,大约是现有Opus定价的两倍。
而GPT-5.5目前是5美元和30美元,本来就便宜一半。
不仅如此,根据WSJ的爆料,OpenAI甚至在考虑进一步大幅降价,主动跟Anthropic开打价格战。

如果GPT-5.6同时带来能力升级和价格下调,对Anthropic来说这是一记左右组合拳。


与此同时,产品侧也没闲着。
6月10日,OpenAI产品负责人Adam Fry在𝕏上宣布,ChatGPT的模型选择器正式改版,面向全球Plus和Pro用户滚动更新。
以前你打开ChatGPT,迎面就是一长串模型名字。
Thinking-Light、Thinking-Standard、Thinking-Extended、Thinking-Heavy,再加上Pro Standard和Pro Extended,六七个选项密密麻麻摆在那里,选择焦虑瞬间拉满。
现在这些全部消失了,只剩一个词,Intelligence。

六个档位从低到高排成一列,分别是Instant、Medium、High、Extra High、Pro Standard和Pro Extended。
换句话说就是从「你想用哪个模型」,变成了「你想让AI多聪明」。

Thinking-Light直接砍掉,理由是不到1%的付费用户在用这个档位。Thinking-Standard改叫Medium,Thinking-Extended改叫High,Thinking-Heavy改叫Extra High。Pro Standard和Pro Extended名字没变,但被藏进了Pro的二级菜单里
7周换一代模型。同一天改产品界面。同一天准备降价。
每一个加速的信号,都在让奥特曼那句关于RSI的话,变得越来越不像假设,越来越像预告。
一旦AI学会自我改进,上市这件事的优先级可能要重新排。
就在他说这话的24小时内,Anthropic的Claude Fable 5在全新的Agent Arena榜单登顶,以11.2%的综合净提升创下了该榜单有史以来的最大分差纪录,把GPT-5.5甩在了第四名。
6月,三家旗舰模型正面碰撞。Fable 5、Gemini 3.5 Pro、GPT-5.6,打的是同一批能力方向,推理、编码、Agent、前端生成。
但真正的竞赛可能不在这一层。
谁先IPO,拿的是华尔街的资金。谁先实现RSI,拿的是改写规则的权力。
前者的优势用年来计算,后者的优势可能用天来计算。

一旦某家公司的AI真正跑通了自我改进的循环,领先速度会以指数级拉开,后来者再多融资也追不上。
这大概就是奥特曼那句话真正的意思。IPO是手段,RSI才是终局。
GPT-5.6是给竞争对手看的,降价是给企业客户看的,RSI那段话,是给历史看的。
参考资料:
https://www.theinformation.com/briefings/exclusive-openai-preps-new-ai-model-expects-go-public-within-next-year?rc=epv9gi
https://x.com/adamhfry/status/2064768231903285451?s=20
编辑:摩西
文章原文

新智元报道
新智元报道
【新智元导读】OpenAI o1推理模型核心缔造者Noam Brown发长文炮轰整个行业:用单一跑分评价AI模型,从2024年就过时了。GPT-5.5看起来只比5.4强一点?控制推理预算后再看,那叫一个天壤之别。
OpenAI的Noam Brown,刚刚发了一篇长文,对着整个AI行业开了一炮。
文章标题叫「大规模推理计算的启示」,核心论点只有一个,你现在看到的所有AI跑分排行榜,给你的信息基本上是错的。
原因很简单。
同一个模型,给它一块钱想事情和给它一万块钱想事情,跑出来的分数天差地别。但现在所有的排行榜,都不告诉你这个模型花了多少钱跑出来的成绩。

4月23日,GPT-5.5发布。
OpenAI甩出benchmark表格,社区照例逐行比对。结论是:还行,比5.4好一点,但也没好到哪去。

然后几个小时过去了。
波兰数学家Bartosz Naskręcki用一条prompt,让GPT-5.5在11分钟内搭出一个代数几何可视化应用。
Ruby on Rails之父DHH更是感慨,用完5.5再切回Opus 4.7,像倒退了一个时代。
同一个模型。benchmark说「还行」,人说「炸裂」。为什么?
原因很简单,5.5和5.4根本不是在同一个计算预算下被测试的。
这就好比两个学生考同一张卷子,一个给了30分钟,一个给了3小时。你拿两份成绩来比,说「差距不大」,这不是比较,这是搞笑。
GPT-5.4 Pro的API定价是$30/$180(每百万token),GPT-5.5是$5/$30。价格差了6倍。
但benchmark表格上,这两个模型被当成同一个量级来比较,完全忽略了推理预算的差异。一旦控制token预算,GPT-5.5在网络安全评估上大幅拉开GPT-5.4。
Brown在文中展示了两张图。左边是传统benchmark视角,5.5比5.4好一点。右边x轴换成token数量,5.5的曲线远远甩开5.4。
同一场考试。换个维度看,结论完全不同。

这不是个案。
MMLU这个曾经最主流的评测基准,前沿模型全部挤在88%以上,分数差异在统计上已经没有意义。你看到的不是「谁更聪明」,是噪声。
MRCR v2在100万token长度上的测试,GPT-5.4得36.6%,GPT-5.5得74.0%——翻了一倍。但这个维度在标准benchmark表格里根本不存在。

ARC-AGI上,OpenAI的o3跑出最高分,单道题推理成本$30,000。
隔壁NVARC团队用40亿参数小模型拿了24%准确率,每道题$0.20。
三万美元对两毛钱,同一场考试——「谁排名更高」这个问题本身就已经失效了。
当模型的能力是推理计算量的函数时,一个没有x轴的benchmark分数,就是一个没有单位的物理量。它什么都没告诉你。
在Brown看来,正确的做法是画一条曲线:性能 vs 推理计算量。
x轴可以是token数、美元或耗时,各有优劣。但可以肯定的是,任何一条曲线,都比一个标量数字强。

或者,你也可以设一个明确的预算上限,告诉模型「你就这么多钱,给我答案」。
这恰好是人类考试的逻辑,SAT给固定时间,国际数学奥赛也给固定时间。
只有AI评测,在2026年了,还在假装「给多少钱想事情」这个变量不存在。
为什么这个问题现在才爆发?
因为两年前,推理时计算只是o1的专属概念。
而o1的核心贡献者,正是Brown。
此前,他在卡耐基梅隆做出Libratus和Pluribus(击败顶级扑克职业选手,后者登上Science封面),在Meta FAIR做出CICERO(第一个在策略游戏《外交》中达到人类水平的AI)。
从不完美信息博弈到推理模型,他一直在同一条线上:让AI学会想更久、想更深。
2024年的o1让「推理时间换准确率」进入公众视野。到了2026年,推理时计算已经是所有前沿模型的标配。
GPT-5.5 Pro不是一个独立模型,它是GPT-5.5同一个底座加了并行推理时计算:遇到难题跑多条推理链,综合出结果。
Claude有extended thinking,Gemini有Deep Think,几乎每家前沿实验室都在往同一个方向跑。
对此,学术界也给出了量化关系。覆盖率与采样次数呈对数线性关系。
也就是,给AI双倍的「想事情时间」,它不会变聪明一倍,但确实会变聪明一点。收益是对数级递减的。
但Brown引用了Karpathy和AI Safety Institute的一个关键发现——
越强的模型,在更长时间跨度上的收益越大。性能的高原期被推远了,甚至可能消失。
弱模型多想两分钟,可能已经到顶了。但强模型多想两个小时,曲线还在往上走。

每一代模型发布时,如果你只在某个固定的推理预算下跑benchmark,你看到的就只是冰山一角。真正的能力上限,在你测不起的那片水域。
用Brown的话说就是:「我们可能根本不知道现代LLM的能力天花板在哪里,因为测量成本太高了。」
针对这一问题,Brown给了三条建议。
第一,实验室发布新模型时公布性能-推理计算量曲线,至少标明分数对应的推理预算。
GPT-5.5的82.7% Terminal-Bench 2.0,你不知道花了多少钱跑出来的。你拿它和另一个模型比,你也不知道对方花了多少钱。
这就像两家公司比营收,一家报的是年收入,一家报的是季度收入,但都不标注时间跨度。
第二,benchmark排行榜追踪推理用量,或设定明确预算上限。
ARC-AGI已经在这么做了,但不是行业标准。

第三, 安全准备框架和负责任扩展政策显式纳入推理计算量。
安全评估不能只测「默认状态」——国家级攻击者完全可以在单个任务上砸1000万美元推理预算。
以Gemini 3 Deep Think为例。
Deep Think本质上就是Gemini 3 Pro加了外部调用框架,任何人花同样推理费就能复现。
真正该问的是,为什么所有模型卡都没把能力作为推理预算的函数来展示?

Brown理想中的安全评估应该是一张图。
x轴是推理预算(从$1到$10M),y轴是模型在特定危险能力上的表现。在低预算下测量,然后向高预算区域做预测。
但他也承认一个棘手的问题,长期评估可能无法靠外推解决。要评估一个AI agent跑一年会不会出问题,可能真得让它跑一年。
而AI实验室很快将面临荒诞局面——agent的运行周期超过了新模型的开发周期。你还没评估完上一代的长期行为,下一代就已经发布了。
所有前面的讨论都指向同一个问题。
如果模型的能力是推理计算量的函数,而且越强的模型高原期越远,那「超级智能」到底是什么?
传统理解里,ASI是一个质变的拐点:某天某个模型突然在所有认知任务上全面超越人类。
顺着这个逻辑往下想——ASI可能不是一个时刻,而是一条曲线。
前面的数字已经说得很清楚:同一类任务,两毛钱和三万美元的推理预算,买到的是完全不同的结果。但这些还只是已经测过的区间。
给一个前沿模型$1,000,000的推理预算呢?$100,000,000呢?
没人测过。Brown说了,测不起。

但对数线性的scaling关系告诉你,曲线还没到顶。而且越强的模型,高原期越远。
ASI可能不需要一个全新的架构突破。它需要的可能只是:足够的钱和足够的时间。
一个运行一整年、消耗数亿美元推理预算的AI agent,在这一年里表现出的能力,可能已经在特定领域超越了人类个体的一生积累。
过去十年,整个AI行业习惯了一种评估方式:一个模型,一个分数,排个名次。从ImageNet到MMLU到Chatbot Arena,谁的数字大谁就赢。
如今,跑分的「二维时代」正在开场。
模型的能力从一个点变成了一条曲线,评估从一个分数变成了一张图。y轴是表现,x轴是你愿意花多少钱让它想。
每个「第一」还要再乘以一个变量:推理预算。

同一个模型在$5和$500预算下的能力,可能根本不是同一个级别。而这张二维地图上的绝大部分区域,至今没有人探索过。
2026年,全球科技巨头在AI基础设施上的投入预计接近7000亿美元。这些钱买的不只是更大的模型,还有更长的推理、更多的采样、更快的inference。
同一个开源模型,有人跑$0.20一道题,有人跑$30,000一道题。能力差距不是模型的差距,是资源的差距。

当「智能」变成一种可以用美元标价的连续函数,「超级智能」也不再是一个是非题。
谁先适应这个二维坐标系,谁就先看清楚ASI决赛的真实比分。
参考资料:
https://x.com/polynoamial/status/2064210146558136827
编辑:摩西
文章原文
原创 徐珊 2026-06-11 18:50 北京
现在「给人」做产品,还重要吗?
现在「给人」做产品,还重要吗?
作者|徐珊
编辑|郑玄
一句话生成浏览器插件,AI 自动整理标签页。如果你关注 AI 浏览器,这两个功能你大概率见过,国内一款叫 Tabbit 的产品,几个月前就上线了。
但这次演示它们的,是苹果。6 月 8 日的 WWDC 上,苹果花了不少篇幅介绍 Safari 的这两个新能力,让浏览器从一个被动的工具,变成能主动帮你打理事情的助手。今年以来,Chrome 押的是 Gemini 的深度集成,Edge 绑定 Copilot,OpenAI 的 Atlas 干脆把整个浏览器交给 agent,但事实上,浏览器的 AI 功能也开始趋同。
这对所有做 AI 浏览器的团队来说,都不算好消息。当读懂你的标签页、替你执行任务、记住你是谁,变成每一家的标配,「我有个新功能」这件事正在快速贬值。一个创业团队领先巨头几个月做出某个功能,换来的护城河只有几个月时间的领先。
如果 AI 浏览器的功能会趋同,那不会趋同的是什么。6 月 9 日,WWDC 的第二天,Tabbit 走完 100 天公测,正式发布 1.0 版本。该版本正在新增记忆功能,会持续记录用户偏好、背景以及其他重要信息,并形成「可调用记忆」,自动适配用户回复风格,减少无效对话及动作。同时,上线了妙招商城,支持分享不同 Skill。
Tabbit 正式开始商业化进程。据刘炯介绍,面向大众用户的基础对话、网页阅读、常用妙招等核心功能 Tabbit 将永久免费。针对高频的 Agent 自动化调用及高级定制化场景,Tabbit 将探索差异化的订阅制模式,暂时定价为 9.9 元每周不限量。
在 100 天时间里,Tabbit 走过了从「地址栏」到「搜索框」,再到「对话框」,最终长成「智能体」的四步。当行业把最好的工程师和最酷的想象力都投给 agent 的时候,Tabbit 把市场潜力押在了那些还没真正上手 AI 的普通人。「技术尝鲜者已经被服务得够多了,而后面的追随者需要什么样的产品,到今天还没有人认真回答。」刘炯说到。
一个仍然为人设计的浏览器,是 AI 普及的入口,还是注定被冲掉的中间形态?一个被收购又被拆分的团队,凭什么敢做全行业最不性感的选择?以及最重要的,当功能不再值钱,AI 浏览器这门生意,到底在比什么?
Tabbit 用 100 天给出了它的初步答案,这份答案的成色,值得我们仔细看一遍。
01
100 天后,Tabbit 长成了什么样?
从 Tabbit 公测开始,我就一直在用。最开始时候,我给过它一个判断,它是我用过最适合普通人上手的 AI 浏览器。
这个「方便」不是一句客套。它的首页很干净,进去就是一个大的输入框,可以输网址正常上网,也可以直接对话。没有满屏的浮窗或者功能键,调用所有的妙招都是中文,简单易懂可见。
刘炯提到自己有洁癖,所以讨厌那种被各类插件占满的浏览器。「侧边一整排小球,选一段文字就跳出好几个菜单,有的还故意延迟两秒,好盖在别人上面。很像每天回家家门口贴的那些小广告」。因此,Tabbit 公测时给人的第一印象,干净、好上手。而这 100 天里,它做的事情,也在此基础上开始一层一层往上长。
最明显的产品加码,放在一个叫「妙招」的功能上。名字有点土,取名来源是刘炯说的那种短视频里「改善生活的 100 个小妙招」。落到产品上,妙招其实是把一件你常做的事,沉淀成一个能反复调用的小工具,和 Skill 很相似,但功能化了。
过去,妙招多是把你常用的一段提示词存成快捷指令,输入斜杠就能调出来。但在这 100 天里,它长成了三类东西,提示词、脚本和 agent 任务。他演示了如何把小红书首页的推荐流进行数据分析或者是打开微信公众号的长文,自动在页面上生成一个目录,方便跳转。过去你要么得去插件商店里碰运气造一个 Skill,现在你只需要和侧边栏说一句话。
比较有趣的是,Tabbit 考虑到了页面占用问题,当你执行一个 agent 的时候,你可以再打开一个网页去做其他任务,而 agent 的执行会持续运作,刘炯说道,「这样就不会出现有些命令是在和用户抢页面的情况了」。
妙招现在是可以分享的。Tabbit 做了一个「妙招广场」,里面有大量用户自己做的东西,关闭弹窗的、屏蔽广告的、导出 B 站高速播放的、测你收藏夹人格的。一个人做出来,整个小组、甚至更多陌生人都能拿来用。
更关键的变化是,妙招从一个人的工具,变成了一个能流通的生态。Tabbit 做了一个妙招广场,眼下已经有三百多款现成妙招可以一键添加,关闭弹窗的、屏蔽广告的、导出 B 站字幕的、做长文总结的,应有尽有。你做出一个好用的妙招,能生成一个分享链接,别人用 Tabbit 打开就直接装上了。
发布 1.0 的同时,Tabbit 还办起了妙招大赛,给好作品发奖金、给认证、给曝光。这件事刘炯看得很重,在他的设想里,妙招不是个锦上添花的功能,而是 Tabbit 真正想造起来的护城墙,让不会写代码的普通人也能造出自己的工具,再把工具分给别人,浏览器就从一个看网页的地方,变成一个大家一起搭出来的 AI 工作台。
有了妙招打底,它这 100 天的第二个变化,是个性化能力增强。
公测时 Tabbit 的对话是一次性的,关掉就忘。1.0 补上了跨对话的记忆,它会把你是谁、在干嘛记下来,记错了还能手动改;补上了本地目录挂载,你把一个文件夹授权给它,里面有什么它按需自己去看;收藏也不再只存网址,而是把整篇网页的全文索引下来,你问相关问题时它能自动引用。这些东西加在一起,其实是 Tabbit 在用它的工程能力搭一个底座,让用户自己也能在上面长出想要的东西,而且用得越久,它对你的理解和意图的把握就越深。
这种「懂你」具体长什么样,Tabbit 请了三个普通用户来回答。一个艺术专业的应届生,把几十篇文献按主题分成几个标签组,直接丢给它提炼观点、找研究空白,靠它啃下了一个全英文的分析软件,过了毕业答辩。一个 HR,招海外增长专家时不急着找人,先把业务目标、组织现状这些材料喂给它,让它帮自己把「这个岗位到底要什么能力」想清楚再去看人。一个建筑师,把每月重复的中标统计拆成几个妙招串成流水线,原来四个人的活儿现在基本不用人管。
学生、HR、建筑师,没有工程师,没有极客,这恰恰圈出了 Tabbit 想要的人,不是 AI 玩得很溜的技术开发者,而是后面那一大批原本对 AI 还有点犹豫的普通人。
模型层的变化 也不小。首先是接的模型更多了,不只免费可用的那些,也接进了一些更贵的高阶付费模型,Tabbit 1.0 内置了 LongCat、DeepSeek、智谱 GLM、Kimi 等多款国内头部大模型,并会实时接入新模型 API,把选择权留给用户。其次是,多模型的协同做得更顺,同一个问题,你可以让三四个模型一起作答,再让它横向对比、挑出分歧、最后总结成一份,省得你自己一家家去问,再切换界面对比。
据透露,公测期间六成以上的用户会主动切换模型,平均每个人用上 2.1 个,因为不同模型擅长的事不一样,有的适合写代码,有的快、适合日常问答,有的适合翻译。Tabbit 干脆把它们全端上来,还在调用的分配和速度上做了优化,新模型基本首发就能用上,平时按场景把请求分给合适的模型,性能上它一直追着 Chromium 最新版本走,性能功耗保持正常水平。最新版本走,性能功耗保持正常水平。
讲到这里,Tabbit 听起来确实在认真往「好用」上长。但我们用下来,也得说另一半的话,它还远没长好。
最直接的问题是 agent 的执行还不够稳,实际用起来,卡顿、报错等情况时有出现。
Tabbit 对此不避讳,但也给出了一些新洞察:Agent 任务成功率从 3 月的 53.1% 提升至目前的 91.8%。其中,5 月数据显示,单用户月均 Token 使用量已达 853 万,用户正持续、高频地将 Tabbit 应用于较重的任务处理和工作流中。
其次,「接所有人的模型」可以是优势,因为让产品不被任何一家模型公司绑住,但反过来,它的能力上限也就被别人的模型卡死了。模型能干到哪,它就只能跟到哪。何况眼下国内通用模型的天花板本身还比较有限,再接进 Tabbit 这套配置和框架里,可操作的空间被进一步压缩。这也意味着它能把工程做得很漂亮,能把上下文喂得很足,却没办法让一件模型本就干不成的事凭空干成。对那些只求「够用」的人来说,这 100 天的进步是实打实的;但对那些追求「好用」、想把真正复杂的活儿交出去的人,它可能还在探索过程中。
100 天的 Tabbit 跑得很快,干净、好上手,稳稳接住了普通人想用 AI 办点小事的需求,查份资料、改个网页、理一张表。它没有去瞄准当下最主流、也最受极客青睐的那条路,那种成体系、多层次、能扛复杂工作流的强 agent。行业里一个越来越被认同的判断是,agent 做个能演示的 demo 不难,难的是稳定好用,真正的成熟往往要等它开始老老实实解决某一个具体场景里的具体问题。Tabbit 把这个场景选成了普通人的日常琐事。这条路能不能走通,它能不能守住这个边界,又不被这个边界困住,还要打个问号。
02
首次回应被美团收购后近况
要理解 Tabbit 为什么会做 AI 浏览器的选择,得先回到刘炯团队当初拿到的那道题。
光年之外是 2023 年创立的 AI 公司,后来美团把这家公司收了进来。收购之后,团队被拆开了,跟大模型相关的人并进了美团的自研大模型团队,剩下做应用的,只有几个人。这几个人手里的命题,是「做一个 AI 应用」。具体做什么,没人规定,什么都可以。
业内当时对这道题有过不少猜测,大家更期待这个曾经离大模型很近的团队,交出来的第一份作业是个通用大模型,或者某个更性感的东西。结果他们前前后后试了一些方向,最后落在了浏览器上。
刘炯的理由很朴素,浏览器是个老形态,2008 年的 Chrome 到今天结构几乎没变,但它承载的东西一直在变重,白领平均一天有六个多小时泡在浏览器里办公,而 AI 又在源源不断地生成网页、生成应用,这些东西归根结底都是网页。一个越来越重要、形态却十几年没怎么动过的东西,在他看来恰恰是机会。更重要的是,浏览器天生知道你在看什么、在做什么,AI 接进来不用你把内容搬来搬去复制粘贴,有天然的上下文信息。
促成真正决定这件事能成立的,也有美团给的自由度。 刘炯在不同场合反复提到一点,美团从来没有要求他们只能接 LongCat,也没说哪家模型是竞对所以不许接。产品做什么功能、往哪个方向迭代、资源怎么投,团队有相当大的自主权,公司只在大方向上把关。过去两年他们试错过不少,也承受了相应的代价。这种放手在国内大厂里并不常见,多数公司收一个团队进来,第一件事就是想办法把它塞进自己的业务盘子里。
但放手的另一面,是这个团队确实没有接入美团的主营业务体系。它还是个小产品团队,做着一件跟外卖、跟本地生活八竿子打不着的事。外界一直有个流传很广的判断,说 Tabbit 迟早会变成美团本地生活的一个新入口,往里接外卖比价、酒店预订。刘炯否得很干脆,说现在没有任何整合。他打过一个比方,浏览器自己得先立得住,是个有人爱用的好产品,至于将来要不要叠加美团的业务,那是锦上添花,「要两个大于 1 的产品相乘才能有更好的结果」。
也因此,Tabbit 没有去做那种调动全公司资源的超级入口。 同时,或许是因为 Tabbit 小、独立、不被要求围着美团的指标转,它反而有了把产品本身做干净的余地。在外部分析师眼里,美团养这么一个团队,更像是在 AI 时代另押一张船票。这个判断未必中听,但它也有一定的合理性。
03
功能开始趋同,AI 浏览器接下来比什么?
把 Tabbit 这个赌注放回整个行业里看,它其实押在了一个还没有答案的问题上。
眼下行业里最主流的声音,是为 AI 做产品。让 agent 自己去跑、去点、去执行,人退到后面,产品越来越像是给 AI 用的,而不是给人用的。OpenAI 的 Atlas 把整个浏览器交给 agent,就是这条路最纯粹的样子。这个方向背后有个隐含的判断,人迟早会退出操作,所以现在就该为那个未来设计产品。
Tabbit 偏偏选了反过来的起点。它不反对 AI 干活,它反对的是把人挤出去。在它的设想里,浏览器是人和 AI 共用的一张工作台,你干你的,它干它的,共享同一套上下文,谁也不用给谁让路。这背后也有一个判断,在可见的相当长一段时间里,人不会退场,而那些还没真正上手 AI 的普通人,才是这一代产品真正没做完的题。
这两个判断到底谁对,今天没人能下定论,而且它们各自都站得住。支持 Tabbit 这一边的逻辑是,让 AI 全自动地替人办事,这件事现在仍然有门槛,普通人还驾驭不了,与其逼他们一步到位,不如先给他们一个低门槛的、人还在中间的产品,等技术真正成熟了,他们自然会走到更自动的那一步。但反对的声音也很尖锐,如果未来的锚点就是 agent 全面接管,那现在还把「人的叙事」当主流,会不会反而是在拖慢大家适应 AI 的速度,让普通人停在一个注定要被淘汰的中间形态上。
这就引出了那个更要紧的问题。技术尝鲜者已经被服务得足够多了,但他们身后那一大批追随者,需要的到底是什么样的产品,这件事到今天还没有人认真回答。Tabbit 赌的就是这块空白。它不见得对,但它至少没有跟着所有人挤在同一个方向上。
在刘炯看来,无论是智能标签整理还是一键造 Skill,单一功能上的创新,从来不是能长期领先的东西。他举了标签整理的例子,很多产品的整理是按域名分类,知乎一组、B 站一组,分完其实没用,而 Tabbit 想做的是按你当下在干的事来分,在报销、在写材料、在做毕设,它认的是任务,不是网址。在他看来,功能可以被抄,但对一件事情的理解抄不走,而决定一个浏览器好不好用的,恰恰是这种理解。
这其实点破了 AI 浏览器这场竞争里最关键的一些变化。过去浏览器的护城河是用户规模和默认设置带来的存量,现在功能层面大家越来越像,模型又是各家都能调用的公共资源,真正拉开差距的,落到了谁更懂人怎么用产品上。这是 Tabbit 这样一个没有存量、没有自研模型的小团队,唯一可能赢的地方,也是它把全部筹码押上去的地方。
*头图来源:Tabbit
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO
极客一问
你觉得 Tabbit 最好用的功能是什么?
Hardwire 2026-06-11 18:50 北京
一颗芯片、一个误解、一轮周期。
一颗芯片、一个误解、一轮周期。
作者|曹思颀
编辑|郑玄
和安克创新创始人兼 CEO 阳萌正式沟通之前,Hardwire 团队看过了他近年几乎所有的公开表达。
这显然不是一位当下舆论场里最受关注的「明星 CEO」——他没有个人社媒账号、没有公开发表过挑战行业巨头的野心和「金句」、甚至此前极少为自家新品发布站台。
多位了解阳萌的行业人士告诉 Hardwire,阳萌更符合一个经典「商学院管理风格」的 CEO 形象:归纳能力极强、擅长对万事「建模」、总结方法论并高效布置团队任务。
相比 iPhone 之于苹果、Walkman 之于索尼,作为一家消费电子公司,安克创业的前 15 年里没怎么留下过深刻印象的超级单品。反而是阳萌多年前提出的「浅海战略」,在很长一段时间里塑造了外界对安克认知——在当年的表达里,阳萌认为安克应该避开千亿美元级的超级品类(如手机、PC),而重点聚焦单一规模在 500 亿美元以下的中小品类。
但在阳萌看来,这种认知某种程度上也成为了外界对安克最大的误解。
「可能大家以为这种不大的市场很轻松」,阳萌希望扭转这个刻板印象,「『浅』只意味着市场规模不大,不代表这件事做起来就容易。」
事实上,在过去 12 个月里,安克开始把过去埋在饭里的肉——产品能力——向外界展示。去年 4 月,安克发布了全球首款消费级立体纹理 UV 打印机 eufyMake E1,4676 万美元的众筹金额创下了 KickStarter 平台纪录;今年 5 月,他们又正式发布了搭载自研芯片的消噪耳机,官方表示「通话消噪能力超越 AirPods」。
这些「不那么像安克」的产品,正是这次沟通的好奇心起点。而过往印象中管理范十足的阳萌,这次从一颗打破计算机 80 年传统架构的「自研芯片」讲起,以技术视角完整拆解了他对 AI 时代智能硬件的推理过程。当然,我们还聊到了 AI 变革对硬件行业几乎每一个环节——无论是投资人、创业者还是普通从业者——带来的冲击和机遇。
这不仅是一篇对安克这家公司的复盘,也希望为所有关注硬件行业的朋友们提供一个新的视角和思路。
以下是 Hardwire 和安克创新创始人兼 CEO 阳萌的对话,经编辑整理。
关注 Hardwire,共同讨论硬件行业新风向
01
前序:一个不在舞台中央的硬件老板
Hardwire:一个月前,在一场技术沟通会上,你开场那个故事是张鹏(极客公园创始人 & CEO)去年年底对你说他觉得「安克变了」。似乎你对这个评价印象很深,以前有人说过类似的话吗?
阳萌:鹏哥是第一个让我印象深刻地说我们「变了」的人。这个变化是从公司内部开始的,但我还不觉得此刻有那么多用户感受这种变化,还没到那个状态。有点像「春江水暖鸭先知」,科技媒体是站在最前沿的人,可能会先察觉到。
Hardwire:从内部开始变化到被外部所感知,中间隔了多久?
阳萌:我们在 2024 年年中完成了公司使命、愿景、价值观的调整。从那个时候到去年年底,大概隔了一年半。
Hardwire:所以这轮变革的起点来自 2024 年年中?
阳萌:我倒不觉得起点都在 2024 年年中。外界目前看到的几个产品:UV 打印机(eufyMake)、爬楼机器人(MarsWalker)、存算一体芯片(安克消噪耳机),基本都是 2023 年前后启动的项目。
安克是一家多品类的公司,公司里总有一些品类是先于所谓的想法、战略进行了提前探索,并不是严格的「先想清楚、相信,再去做」这个顺序。更多时候是有些产品、方向已经先做了,我们再把它抽象归纳出来,然后更多人相信「我们可以一起往那里走」。
Hardwire:Marswalker 去年在 IFA 的演示非常出圈。那段视频在我们的小红书账号上有 8000 多个赞、1300 多条评论。但我注意到,好像几乎没人意识到它们来自安克。你会不会觉得,这个阶段安克的产品似乎比品牌更酷一点?
阳萌:那个产品并不是挂的「安克」品牌,而是来自我们面向智能家居的子品牌 eufy。但是属于 eufy 旗下的扫地机器人、安防产品其实都没有在国内发布过,所以大家联想不到安克,我觉得也正常。
eufy 这个品牌从 2017 年就有了,那个时候我们希望用「品类品牌」的策略做多品牌:希望消费者想到充电就想起安克、想到影音就想起 soundcore(声阔)、想到智能家居就想起 eufy。当然,今天回头看,这个策略其实不太对,所以我们也计划把所有子品牌都并回安克。
Hardwire:会不会也跟你作为 CEO「营业」不够积极有关?今天好像每个消费电子类公司的 CEO 都要到舞台上给公司、产品站台?
阳萌:也不是所有产品公司的老大,都天天往台前站的。在「产品品牌」和「CEO 个人品牌」之间,我还是希望做一个极致的产品品牌。
短期来看,在创新产品还没被大家充分看到和记住之前,靠我在外面不停讲,我觉得最多能撑两三年。超过三年,大家就会问:「东西呢?老在外面讲,又没东西出来,肯定是假的。」
过去三年,我每年都会出来,想帮公司吸引人才,但我希望明年开始就不是靠我了,而是靠那些真正足够创新、足够吸引人的产品。
Hardwire:在深圳硬件圈里,对安克还有这样一个印象:工资很高。你之前提到 2025 年公司有 800 人年收入超过了百万,我挺好奇这些员工主要来自哪些业务线?
阳萌:首先,2026 年年收入百万以上的员工预计将要突破 1000 人。他们不可能都是管理层,因为 6000 人的公司不可能有 1000 个管理层。
我们有个做算法的小伙子,我特别看过他的薪酬,应届硕士毕业大概 4-5 年,就拿到了百万年薪。但他并不是来自机器人算法这种「当红炸子鸡」品类。
所以安克的分配其实蛮平均的,所谓百万年薪并不只集中在某几个热门领域或者工种里。我们的理念是,消费电子一定要把大部分钱分给创造者,因为超额价值是他们创造的。
阳萌(右)和极客公园创始人 & CEO 张鹏(左)| 图片来源:极客公园
02
一场 3 年前的「盲注」
Hardwire:这是 Hardwire 第一次和 CEO 的面对面专访。我们希望不仅让大家更了解安克和阳萌,也听一听你们对行业的判断。过去一年智能硬件行业很热闹,如果让你用一个关键词来总结,你觉得是什么?
阳萌:从创投视角看,我会说这是一个新周期的开始。
如果你在行业里待得足够长,会发现一件很有意思的事:基本上每 5 年会有一轮特别热闹的周期。2011 年是移动互联网和电子商务,2016 年是物联网,2021 年是新消费和出海,然后到 2026 年就是 AI。有 AI 之后,大家觉得所有硬件都值得被重新做一遍。
Hardwire:你认同这个观点吗?
阳萌:技术层面上是认同的。但这一轮浪潮过去之后,到底有多少创业公司能长期活得很好,还是会遵循一定的统计规律。
Hardwire:那你认为什么是「AI 硬件」?做 AI 硬件有统一的方法论吗?
阳萌:自动驾驶汽车是一个很好的案例。它的「智能」被拆成三个模块:感知、规划、控制。你在这三个模块上做得更好,产出的结果就是这个产品变得更智能。我认为今天所有的硬件要「变得更智能」都应该是这个路径。
而 10 年前做物联网的时候,行业很多人曾经走过一条错误的路径,以为给产品加上一些可以通过手机远程调节的功能,就做出「智能硬件」了。但那些产品并不具备感知、规划、控制能力。以智能马桶为例,它连什么场景应该开盖、开一个还是两个盖都不能自主判断。
Hardwire:要做到这种「真正的智能」,产业基础够吗?
阳萌:硬件层面,过去十年激光雷达、TOF、各种毫米波雷达等传感器都快速成熟,所以硬件基础比十年前 ready 了很多。
但硬件基础上的软件,我觉得并没有那么快。每一个传感器都带来了大量数据,需要用更好的模型来处理,而不是以前那种写死的规则。这些东西背后都不是简单技术,而是复杂技术,需要很好的基础设施去支撑。所以这套东西真要做好,非常考验功夫。
Hardwire:安克是怎么解决这一系列问题的?
阳萌:我们首先确认了一个原则:一定要在端侧跑更大的模型。因为如果不跑更大的模型,就一定做不好很多感知的问题。
但在 AI 时代,随着模型激活参数的大幅提升,计算过程中会因为「搬运数据」导致功耗显著增加。对通电设备(如数据中心)来说,功耗高了解决散热就行;但在电池驱动的设备里,功耗一高就会直接影响续航,严重影响用户体验。
而我们在市场上找了一圈之后发现,现有的芯片都不能解决这个问题,所以我们觉得解决这个问题要从最底层的芯片开始解决。
Hardwire:过去硬件行业普遍会把芯片和人才、零部件视作「可采购」的产业基础,但你们的选择是从底层研发自己的芯片。有质疑的声音吗?
阳萌:有很多质疑。但这条路走到这儿,面前就是这堵墙,所以我今天就得要跨过去,不然的话就永远停在这儿了。
Hardwire:现在搭载这款「存算一体」芯片的两款消噪耳机已经上市了。从起心动念,到产品落地,一共用了多久?
阳萌:我们 2023 年上半年就开始找,到 8 月和合作伙伴知存科技签合同,一共用了差不多 3 年时间。
Hardwire:这个过程里最大的挑战是什么?
阳萌:难就难在,它不止「换一块芯片」这么简单。你要动的,是计算机行业延用近 80 年的「祖宗家法」,一整套互相支撑的体系。
计算机领域过去几十年解决问题的根本「分治法」,是将一个大问题层层拆解为小问题,逐一求解后再行组装。而如何拆解、怎样计算都需要人为定义,最终产生了上百万行的代码规则。落在芯片层面,由于每次计算真正激活的代码只是一小段,所以从经济性考量,不需要把所有代码都储存在昂贵的计算单元里,于是就产生了「存算分离」的硬件架构。但 AI 到来之后,解题方法从「分治法」的层层拆解演化为了上百亿参数的端到端黑盒模型。原本最经济的设计,在大模型时代反而变成了最耗能的那个。
阳萌讲解芯片架构背后的变迁 | 图片来源:Anker
Hardwire:当时外界反对的声音多吗?
阳萌:在 2023 年,这是一个极度非共识的判断。因为硬件架构一变,上面一整层已经成熟、被所有人信任的体系也就同时塌了,都得跟着重做。
我第一次公开说我们要做存算一体芯片之后,网上有一个评价,说这件事 20 年内都不会有成功的商业案例。
Hardwire: 现在这套新的架构已经落到了消噪耳机这款产品上,普通用户能感知什么变化?
阳萌: 落到体感上,最直接的是感知。比如打电话——你日常在车上、地铁里、甚至演唱会现场通话,也能把你的声音收得清清楚楚。
Hardwire: 这一点我亲测过。五一的时候,我在一个 62000 人的足球比赛现场用它拍了一支视频。现场都是球迷的声音,但视频里只有我的声音,确实挺神奇的。
阳萌: 这只是感知能力提升的一个例子,后面还有很多场景。
03
做与不做的取舍
Hardwire:那耳机之外的其他品类呢?这套存算一体的思路,可以快速复制到其他需要提高感知能力并控制功耗的硬件产品上吗?例如智能眼镜。
阳萌:这套思路肯定有帮助,但我觉得很难「快速复制」。耳机处理的是音频,眼镜处理的是图像和视频,每一个品类的数据、训练、部署闭环,以及需要的芯片都不一样,不是那么快就可以跑通的。
Hardwire:你的意思是,存算一体还没有完全成为行业共识?
阳萌:在今天肯定还不是共识。举个例子:在 ISP(Image Signal Processor,图像信号处理器)领域,你今天有见到谁在做端到端的神经网络 ISP 吗?
从体感上,今天大家用手机拍照的时候已经几乎不需要手动调参数了,但背后的计算运算依然依靠「分治法」:先调白平衡,再做边缘锐化,拆分成十几个步骤、几十个模块计算。
Hardwire:其他品类想复制这套架构,也要再花 2-3 年时间吗?
阳萌:我觉得对芯片来说,从设计到流片、回片、上线,两年都算极快的。
Hardwire:如果这样推算,从非共识变成共识,再到落地成用户可感知的产品,应该需要 3-5 年。但既然你们有了存算一体的经验,会考虑做智能眼镜吗?
阳萌: 眼镜我们是真没做。这个市场里,互联网大厂、手机大厂、大模型大公司,这三拨人都觉得自己一定要把这事儿做成才可以。因为大家认定智能眼镜本质上是人机交互的入口,最优的资源全压在这里。我们不应该去凑这个热闹。
Hardwire:我觉得眼镜其实代表了这一轮创业里一个有趣的现象。有些赛道还没正式开始做,就已经「卷成麻花」了。一年前的 AI 陪伴好像也是这样——一度大家都觉得很火,后面又没什么声音了。
阳萌:我觉得这种现象一直在发生。即使在投资最差的 2023、2024 年,也有人在做这些事情,只不过没有今天这么显眼。它不是一个纯粹的技术逻辑——因为经济周期和技术周期并不严格吻合。一直有人在做,但今天这个点上,因为大模型的出现,所有人都觉得「应该这样」,钱和注意力一投过来,大家好像突然觉得「很多」。
Hardwire:那陪伴这个方向,你自己怎么判断?
阳萌: 其实我们很早就在看,也投过一家创业公司。陪伴的价值是很清楚的:无论是语音的陪伴,还是带一定动作的陪伴,技术在不停进步,效果也越来越好。但现在看起来,它还没跨越「创新的鸿沟」——从少数尝鲜的用户,跨越到早期大众。而且陪伴本身就是个非常非常复杂的问题,它不是说今天模型一提升,这件事就突然像魔术一样被做好了。
Hardwire: 所以陪伴的难点,其实不在模型本身?
阳萌: 模型的提升当然有帮助,但它不是那个能「一招解决」的东西,最后还是回到客户价值。你能不能为目标人群真正创造一个独特的、能跨过那道鸿沟的价值,这才是难的地方。
Hardwire:那硬件大厂之间的竞争呢?今天似乎每一家大厂都在疯狂扩张。
阳萌:我觉得说「疯狂扩张」好像也没有。
Hardwire:少部分很「疯狂」。但基本都在横向扩张,找第二曲线。为什么这个时间点大家都在做这件事?
阳萌:我没有那么了解其他人具体决策的逻辑,可以分享一个安克之前的案例。
2020 到 2022 年,安克经历过一个特别快的扩张阶段,那时候我们做了电动自行车,也做了各种各样的电器品类。背后是我们当时相信的一套打法:流程型组织。简单说,就是把「怎么做成一个产品」沉淀成一套标准流程,再扩出很多 PDT(Product Development Team,跨功能部门团队)套着这套流程跑。这些团队背景都不错,流程也是成熟的,照理说应该能把新品类一个个做好。
Hardwire:问题出在哪里?
阳萌:最后我们发现,背景好的团队 + 一套成熟的流程,如果碰上一个底子很薄的品类,照样做不成。除了人和流程,其实还有很多限制条件。
那次之后我们总结出一句话:要做「三缺一」的品类,不要做「一缺三」的品类。「三缺一」,就是一个品类的四个成功要素里,我们已经具备了三个,只需要再补一个就能突破它;「一缺三」则相反——四个里我可能只有一个,那就很难了。
Hardwire:所以你们现在的原则,就是在「浅海」里(阳萌总结的品类战略,在每年 500 亿美元规模以下的品类里做大量的中小品类)里进一步挑选「三缺一」的品类吗?
阳萌:在智能手机这样的超级品类里,牌桌上的每个巨头口袋里都是上千亿的本钱。你今天揣着 50 个亿想挤进去,连跟注的资格都没有,只能一把全压然后听天由命,赢面其实极低。而我们做的这些不大的市场是另一张牌桌——桌上的人口袋里也就几个亿、十几个亿,入场的门槛低得多,这种桌子你才坐得下来、玩得长久。但坐得下来,不代表就一定赢。
Hardwire:以前你说听到「浅海战略」,很多人第一反应是这个赛道里竞争激烈。
阳萌:这里可能容易有一个误解,「浅」不等于「快」。我以前举过宝洁的例子,可能让大家以为这种不大的市场就很轻松、很快。但本质上,消费电子里一个品类「浅」,只意味着它的市场规模不大,不代表这件事做起来就容易、就快。
举两个例子:第一,消费级 UV 打印机这个品类,过去根本就不存在;第二,在储能这个本身热闹的品类,我们也开创了一个「DIY 安装」(我们也叫阳台储能)的家庭细分市场。这件事听起来「浅」——不就是给阳台配块电池吗——但它要啃法规、重新定义安装方式,所以一点都不快。结果是,德国过去三年装了 100 万套以上这种 DIY 系统。
eufyMake E1 及成品案例展示 | 图片来源:Anker
04
不必过分焦虑 AI 浪潮的冲击
Hardwire:你之前说过,和媒体沟通的目标之一是希望招揽人才加入安克。过去一年里,你印象最深的一次招人经历是什么?
阳萌:我自己花了不少时间在招人上,所以还真没有一个「最」。但我可以分享一个印象很深的经历。
在最大的那些「厂」里,有些人才每隔一段时间会出来看看机会。有位同学一见面就坦诚地告诉我:「我其实也没想要出来,主要是希望在沟通中判断一下自己的价值,再看看行业情况」。然后这位同学沟通完之后,就毅然决然地决定加入安克了。
要知道,「毅然决然」这件事很难。因为在大厂里,这样的人才已经是在某个领域的一号位了,他还愿意到一个小很多的公司来做一号位——这种情况下,我能感觉到安克肯定是在某些地方打动了他。
Hardwire:那你花在找人上的精力应该不少?
阳萌:如果说「找」就是到处挖人,那我做得确实不多。但花在「说服」上的时间,的确是比较多的。
Hardwire:你是一个归纳总结能力很强的人,但 MBTI 又是一个 P 人。我很好奇你沟通的时候是有一套固定的流程,还是偏向随机应变?
阳萌:我们的价值观,本质上就是一套行为的框架。你肯定是在这个框架里聊,但你不会严格地一条、两条、三条往下问,而是希望聊天的过程能覆盖这个框架的相当一部分。
Hardwire:判断技术人才的时候,也是同一套标准吗?
阳萌:无论是技术人才、商业人才,哪怕是行政人才,都一样。我们讲价值观,通常说是「两个轮子加底下一个基础」——怎么想事情、怎么做事情,以及最底下如何自处。如果你想事情很清楚、做事情很到位,最后又能长期跟自己自处好、有持续的动力和输出,这就是一个人能长期保持很好状态的样子。
Hardwire:所以你更在意底层的东西,反而没那么在意他来自哪个领域,哪家公司?
阳萌:对。无论是「厂牌」还是「学校牌」,都不能代表一个人今天的价值观。只是说,不同公司出来的人,比例可能有高低——比如某家公司出来的人,第一性强的比例会高一些。但不管权重多少,最后都是一个个单独的个体。
Hardwire:那如果今天同时来了华为、大疆、蔚小理、大模型公司的人来面试,按照「和安克的匹配度」排序,你的顺序是什么?
阳萌: 我不会把「不同的组织」放在排序的最前面。因为这么排本身就不是第一性的。举个例子,我自己是北大毕业,我能说北大所有同学第一性都特别强、求极致都特别好、都能长期主义吗?
Hardwire:见你之前我先做了个小背调。有一种对安克团队的评价是,安克高管团队提炼总结方法论的能力非常强,但似乎这些能力又都在 AI 的射程范围里。你怎么看 AI 对组织的冲击?现在很多人都担心 AI 会导致裁员。
阳萌:硅谷近期最激进的一种说法是:公司是一个巨大的「公司世界模型」,由这个模型来决定各项工作怎么做,不需要中层管理了。
我的看法是:首先,今天的 AI 是 context bounded 的(受上下文长度限制)——context 长度决定了你能解决多复杂的问题。而我们一个硬件项目的 context,已经远远超过今天模型能处理的复杂度了。更何况我们是很多硬件、很多项目在并行跑。所以今天的模型,根本没办法有效地把握、抓住全公司所有问题的关键。
其次,公司不是一个「固定的样子」,它是在「成长」的。我们今天要吸引什么样的人、说服他们加入、设计组织架构高效协同,目标调整之后还要调整对应的架构……所有这些事情,哪怕未来的模型能力变得很 capable、能给人提供建议了,我觉得也依然需要具体的人来执行和传达。
Hardwire:安克公司的高管听完这段,对 AI 的焦虑应该能缓解一点。
阳萌:这件事很好玩。我每次去校招都会讲:你们为什么要来安克,而不去那些互联网大厂?我们来分析一下底层原理。一个士兵成熟的速度,最相关的指标是「打过仗的次数」。刚上战场的士兵懵懵懂懂;熬过三五场,开始冷静;打个 10 场、20 场,已经很有经验;打到三五十场,就很老到了。
互联网的一次「战斗」,一个功能从策划、开发、上线到运营,大概 3-6 个月。从 24 岁硕士毕业到 30 岁,已经成为了打过二三十场战役的「老兵」。因为作战周期短,所以成熟速度快。
Hardwire:但老兵后面还有源源不断的新兵。
阳萌:对。而且关键在于——60 场战斗经验和 30 场战斗经验,可能差别没那么大了;但跟只打过 3 场的相比,差别巨大。也就是说,经验的红利很快就吃到头了。所以这是为什么互联网的同学起得很快、达到巅峰的速度很快,但后面也会有挑战。
反过来讲硬件正相反。我们「打一场仗」的周期很长,可能 6 到 9 个月才一场仗,芯片还会更慢。所以尽管硬件看上去没那么 sexy、收入涨得没那么快——而且说实话,我们的硬件产品经理、研发工程师收入其实也涨得很快——但他们的花期会更长。
Hardwire:以前我们经常对自己说「媒体越老越吃香」。按你刚才这套逻辑,媒体一年要写多少稿子打多少场仗啊……
阳萌:花期早就过了(笑)。
05
资本热潮中的投资人、创业者、稀缺人才
Hardwire:这轮新周期里,创业者似乎也更容易拿到更高的起手估值?
阳萌:是的。今年是一个新的投资周期的开始,VC 变得很愿意投钱。同样一个项目,可能去年这个时候没有人投,现在却被抢疯了。
Hardwire:那对于顶级人才来说,是否有这样一种选择路径:先去最热的赛道里创业或者当合伙人,把身价「抬高」。即便几年后再回来加入大厂,也能获得比直接加入拿到更好的收益?
阳萌:创业是一个长期的投入,不是短期「爽」一下。创业者要面临的不光是一个个困难,而且要面临一条持续自我成长、自己迭代和改变的道路。除非你哪天不想做了,否则你会一直面对这些。
而且,不是愿意付出一切,就一定有好结果。孔子有一句话叫「君子慎独」——人在独处的时候,各种坏毛病都会暴露出来。而在一家创业公司里,CEO 通常就是那个「独夫」。所以你会看到他各种各样的坏毛病冒出来:有些影响结果,有些影响生死。
所以我想说的是,创业的人需要理解,这是一段长期的、要持续承受挑战的孤独,而不只是短期看起来很有趣的事。
Hardwire:是不是因为投资人看到了某种机会,例如退出、变现变得更容易,所以才有这轮热潮?
阳萌:其实退出变得容易,应该是投资变热的「开始」,而不是结果。当二级市场上有几个很好的标的时候,一级市场就会变得很热。大家会觉得,我今天投进去,将来就能这样卖出去。
巴菲特有一句很经典的话:股价短期是投票箱,长期是称重器——短期的高低被人的预期左右,长期才由公司真实的利润和成长性决定。所以今天投资火不火,影响因素是顶上的预期,而不是底下实实在在的结果。
Hardwire:就像买刮刮乐,都希望自己当场中大奖。
阳萌:如果你投的公司今天就能在二级市场上市,当然可以;可二级市场的热,能热三四年吗?大家其实都在谈,OpenAI、Anthropic、SpaceX 这三家如果上市会意味着什么。有一种观点是,这可能意味着股市会到一个阶段性的顶点。而二级市场一旦发生变化,一级市场也会很快反应过来。
Hardwire:那你自己会投资吗?安克作为一个多品类的公司,不断有新产品和新事业部出现,有没有人说过,比起 CEO 你更像一个投资人?
阳萌:比起「投资人」,我更愿意说我是一个「实施顾问」。我给大家提供解决问题的思路,然后陪大家去执行,只是不具体下场做而已。
你看今天这些抽象出来的方法论,其实都是我们从一些业务里把它抽象出来,再向更多业务去推广、复制。只不过我没有把复制扩展到公司的边界之外而已。所以我绝不是个投资人。你去问内部跟我讨论业务的同学,他们会给你完全不同的答案。
Hardwire: 但安克之前还是有过一些投资经历的,听你的意思,现在对外的投资变少了?
阳萌:一个客观原因是我们确实没花很多时间在上面。而且现在投资越来越热,外面的投资人也普遍能给出很多钱。
Hardwire:你不太喜欢凑热闹?
阳萌:非常不喜欢凑热闹。
Hardwire:那对于你来说,识别和判断一个创业者和一个招进公司的人才,逻辑上有什么不同吗?
阳萌:对创业者来说,还是回到「君子慎独」。一个再强势的投资人,也很难影响 CEO 是个「独夫」这个现实。CEO 就是创业公司里做决策的那个人。所以投资人的边界在于,永远只能「说说」,没法真实地去影响。但在安克这样的公司里做新品类就不同,比如我们推 AI 的时候,并不是你想不用就可以不用的,它是一个带有强制属性的「咨询公司」。
Hardwire:招人的时候,你会看有多少场「战斗经验」。投人的时候,你看什么?
阳萌:其实招人和投人是一样的,把事情做成的底层原理是相通的。对人来讲,就是你能不能持续地有第一性的思考、抓住关键问题;能不能持续地、极致地把它做出来;以及这个过程里会有很多困难、很多诱惑,你能不能持续地长期主义,自我觉察、自我进化。
Hardwire:看起来你没那么担心错过投资机会,也决定不进入眼镜这样的超级赛道。那在这一轮新周期里,你最担心的是什么?
阳萌: 找不到足够多的人才。对安克来讲,这家公司如果不成功,最大的原因应该就是人才不够。
Hardwire:人才从哪里来?你们会内部轮岗吗?
阳萌:已有业务的同学,我们确实会调到新业务上去;内部也会有同学成长起来,去接已有的业务。长期看,比如放到 5 年、10 年,我相信内部成长、补上来的速度一定能接上;但短期如果不持续吸引最好的人才,还是会担心青黄不接。
这里还有一个更底层的原因。如果按 1、3、5、7 系来分,我们以前做的是 5 系产品,是「优质产品」但不是「极致产品」。但是从 2023 年开始,我们开始做「极致产品」了,例如搭载存算一体芯片的消噪耳机,我们的目标是对标 AirPods 的性能。
Hardwire:的确需要不同的力量和「7 系」产品的经验。
阳萌:不是说团队组成要 100% 不同,但团队文化是要 100% 改变的。这就是为什么过去几年我们一直在外面吸引人才——如果只做「5 系」、不调整定位,内部成长可能也够了;但今天安克的定位是升级,就自然需要更极致的人才加入。我反复讲第一性、求极致、长期主义,其实就是希望吸引这样的人才。人才来了之后,公司的样子就变了;样子变过来之后,后面就能持续地从内部生长。
安克消噪耳机,被吉尼斯认证为「全球通话最清晰的无线蓝牙耳机」| 图片来源:Anker
06
超级品类与终局推演
Hardwire: 未来 3-5 年,你最看好的硬件品类是什么?
阳萌: 从市场规模最大的角度,我觉得是人形机器人和智能眼镜。这两个品类,我觉得三五年的时间应该有机会爆发。
Hardwire:但它们现在还都很小,眼镜还没有到「浅海战略」的 500 亿美元规模。
阳萌:也许不是 3-5 年内就可以达到,但从第一性推理,它一定会变成终局里的超级品类。
手机目前是 5000 亿美元量级,PC 是 2000 亿美元,平板大概 600 亿。你觉得智能眼镜爆发之后,会靠近哪一个?
Hardwire:按照终局论,大概率会超过 PC。
阳萌:对,它会在第一名和第二名之间,成为将来的第二名。那就意味着应该是一个 2000 亿美元往上的市场。这一定是个超级品类。
Hardwire:但你前面说了,安克没有在做智能眼镜。你们就这么放弃未来的超级品类了吗?何况它今天还在「浅海」里。
阳萌:我并不觉得一定要自己 100% 把这个事做出来。其实华为内部做出手机,也是一个相对独立的组织做出来的。
Hardwire:还有什么不一样的方式吗?
阳萌:今天我们可以看到两种模式,一种叫「三加一」,一种是「一加三」。
前者代表一个做大量中小品类的公司,再增加一个超级品类。华为是很好的例子,它早年的运营商业务,是由大量小品类组成的;而后来把手机做成了超级品类。但华为是全世界范围内极少数能做成「三加一」的。
更多的案例是「一加三」——先做成一个超级品类,再出去做很多中小品类。比如阿里,先做好了淘宝这个巨大的品类,再做很多很多小品类;小米也是,先做手机,再做生态链。
Hardwire: 我们一开始提到,自动驾驶的感知、规划、控制范式给这一代智能硬件带来了启发以及产业硬件、人才的溢出效应。那你觉得未来智能硬件和具身智能行业之间会产生怎样的关联?是具身行业因为资源密集先跑通世界模型,还是智能硬件通过传感器拿到更多数据,反哺具身行业?
阳萌:我觉得今天第三方传感器的数据,对机器人的帮助比较有限。机器人还是需要大量高质量、高精度采集的数据。在数据采集这件事上,背后的底层能力可能有共性,但就采集到的数据本身而言,我觉得两边相互的帮助不大。
Hardwire:那假设世界模型先做成了,它的能力可以变成哪些对硬件行业可复用的产业资源?
阳萌:假设世界模型今天成了,它对人形、对其他机器人形态会有一些帮助;但我觉得它对耳机可能没什么帮助。对眼镜,可能有一点——但大家的限制条件不一样,眼镜毕竟还是在一个电池、重量等物理条件极度受限的条件下运行的设备。
其实今天可以看见,从上往下有很多有意义的产品。人形机器人肯定是一个;再往下,是我们说的「本体」——移动的、可交互的本体,无论是狗的形态,还是其他宠物的形态,这些都成立。所以未来会有很多东西冒出来。
Hardwire:你一开始提到过去一年的关键词是「新周期」,未来 1-3 年会发生什么变化?
阳萌:你会真切地看见 AI,或者说我们一直在讲的「感知、规划、控制」,会真的跑到硬件上去,越来越多的硬件会带上这三种能力。3 年可能是小共识,5 年就是广泛共识。
Hardwire:那有什么东西是不会变的?
阳萌:回到底层,公司永远需要为客户交付价值。而交付价值,需要经历一组实实在在的过程:用户洞察、预研技术、组合成产品、做好品质、做好生产、在全球做好服务。
哪怕未来这个世界全部由 AI 来控制,请问这里面哪一个价值点可以消失?它不是「砰」地一下,一个特别好的产品就出来了、客户就满意了。这些具体的价值和动作,构成的就是一条不会变的价值创造序列。
这个价值序列上的每一段都由一个团队在交付,用 AI 帮这个团队提高内部效率,以及提高跟其他团队之间的协作效率,就是 AI 转型。
Hardwire:安克具体怎么推动这个 AI 转型呢?
阳萌:我们集中了一百多位同学,在打造数据、智能体和 AI 中台,以及沉淀各个职能的 AI 智能体。目前平台日活超过员工数的 90%,公司内周一到周五每天消耗超过两千亿 token,一半以上是在非编程领域,超过一半是中高阶模型 Token。
交流下来我们在 AI 转型上肯定是领先的,也欢迎想跟 AI 一起飞速进化的同学们加入我们一起成长。
Hardwire 希望和在智能硬件领域里的每一个创新者建立起真实的连接。无论你对这个行业是有兴趣、有观察,还是有亲身的从业经验,都欢迎来找我们聊聊。
识别下方图片二维码,添加 GeekPark GO 微信,发送关键词【 Hardwire】,小助手邀你加入 Hardwire 交流群~👇
*头图来源:Anker
极客一问
你认为未来真正能颠覆用户体验的
AI 硬件,会出现在哪个品类?
Zilliz 2026-06-11 18:11 浙江
Cohere 开源其首款面向开发者的代码模型 North Mini Code,该模型采用 30B 总参数、3B 激活参数的 MoE 架构,专为智能体软件工程任务设计,以 Apache 2.0 协议发布。
Zilliz Workshop是一项由Zilliz 资深技术专家发起的社区动手活动,旨在通过各种各类动手实验,让开发者深度了解向量数据库,并借此开发一系列的AI应用。以做代学,在实践中掌握向量数据库的深度能力进阶。
活动主题:Agent 时代 Vibe Coding:从 Milvus 3.0 解读到多模态检索实战
活动亮点:
介绍 Milvus 3.0 核心功能升级
2 小时,实现图片 +文本+视频混合检索
0代码编写,全程Vibe Coding对话式开发
现场解读On-Demand节省90%成本背后的性能优化
活动时间:2026-06-27(周六)下午
活动地点:北京市海淀区中关村创业大街12号楼5层路演厅
形式: 前半场主题分享 + 后半场每人动手实操(自带笔记本,需联网 + 电源)
协办方/联合主办:中关村科学城公司、中关村创业大街
活动详情与报名二维码详见以下海报
点击“阅读原文”查看原文章
👇点击关注ModelScope公众号获取
更多技术信息~
魔搭ModelScope社区 2026-06-11 18:11 浙江
Cohere开源首个面向开发者的代码模型North Mini Code,采用30B总参数、3B激活参数的MoE架构,专为智能体软件工程任务设计。该模型以Apache 2.0协议发布,在多项基准测试中表现优异,支持多种智能体框架。
01
引言
Cohere 开源了 North Mini Code,一个总参数 30B、激活参数仅 3B 的混合专家(MoE)编程模型,以 Apache 2.0 许可证发布。这是 Cohere 全新模型家族的首个模型,专为智能体软件工程(agentic coding)设计,覆盖复杂软件工程工作流、基于终端的智能体任务和高质量代码生成。研究团队采用多脚手架训练以保证模型跨智能体框架(harness)的稳健性,使其可作为 OpenCode 等代码智能体的可靠基础;BF16 与 FP8 量化权重均已放出。
开源地址:
BF16: https://modelscope.cn/models/CohereLabs/North-Mini-Code-1.0
FP8: https://modelscope.cn/models/CohereLabs/North-Mini-Code-1.0-fp8
02
技术架构
North Mini Code 是基于 Transformer 的仅解码器稀疏 MoE 模型。注意力层以 3:1 比例交替使用带 RoPE 的滑动窗口注意力和不带位置编码的全局注意力 [1];前馈层为含 128 个专家、每 token 激活 8 个的 MoE 块,专家采用 SwiGLU 激活,路由器在 top-k 选择前对 logits 施加 sigmoid;稀疏层之前另设一个稠密层。
图: North Mini Code 是一个混合专家 Transformer 解码器,交替使用滑动窗口自注意力和全局自注意力。
03
面向编程卓越性的后训练
后训练分两阶段级联 SFT,再接基于可验证奖励的强化学习(RLVR),全程聚焦智能体编程。第一阶段在编程、推理、指令遵循等广泛领域训练,代码占可训练 token 的 70%(含 43% 智能体工具使用、27% 单轮竞赛或科学编程);第二阶段仅用 4.5B token 的智能体与推理数据,代码占比提升至 61%,且所有工具调用与补全均验证可执行、正确。两阶段上下文长度分别为 64K 和 128K,采用"从长到更长"的级联策略:先在较短数据上建立基线,再仅用高质量样本做长上下文训练——若直接混合长短数据,初期的 20B 非代码 token 会压过后期 1.5B 高质量代码 token,反而损害性能。数据来自容器化智能体编程环境,覆盖约 5000 个仓库的 7 万多个可验证任务,并与 SWE-Bench、SWE-Bench-Pro 的来源去重以防泄漏。SFT 仅作为 RLVR 的引导,经样本级过滤剔除无效工具调用、特殊 token 错误等异常后,最终 SFT 模型在 SWE-Bench Verified 上达到 80.2% pass@10,在 Terminal-Bench v2 上达到 55.1% pass@10。
图: 后训练流程由两个阶段的监督微调(SFT)以及一个面向软件工程与终端任务、采用可验证奖励强化学习(RLVR)的阶段组成。
04
跨框架的稳健性
真实开发环境的智能体框架(harness)差异不止于提示,更在于工具使用模态:SWE-Agent 提供 bash、str_replace_editor、submit 等专用命令的丰富 CLI;mini-SWE-agent 仅有单一 bash 工具和原始 stdout;OpenCode 则用细粒度类型化工具并返回结构化 JSON。研究团队在第二阶段 SFT 中仅加入 6% 的基准框架数据(所选 SWE-Agent 占 50%),即在 OpenCode 评估上获得 10% 增益,同时不损害 SWE-Bench Verified 上 SWE-Agent 的表现;模型在 mini-SWE-Agent 上的 61.0% pass@1 几乎是跨框架迁移"免费"获得的,说明工具能力重叠的框架可正向迁移、技能互补而非冲突。针对 Terminal-Bench 采用的纯文本 Terminus 2 框架,仅加入不到 20% 的纯文本数据即可泛化,但需在各框架中引入足够变化(类似数据增强),迫使模型建立指令与行为的真实关联而非复述模板。
图: 为驱动多种智能体编程框架,North Mini Code 在第二阶段 SFT 中接触了多种编程框架。
05
面向智能体编程的异步强化学习
编程智能体的 rollout 长且长度差异极大,最慢轨迹常是中位数的十倍。为避免同步训练空等长尾,研究团队将采样与学习解耦:训练器与持续产出 rollout 的 vLLM 边车并行,每 K=4 步同步一次权重,残余的轻微离策略在损失层面校正;并用窗口化 FIFO 队列在队首按完成顺序排空拖尾、其余保持输入顺序,在几乎不损失稳定性的前提下恢复吞吐。训练目标为 CISPO——带 token 级重要性采样校正的对数似然目标,重要性权重乘以对数似然而非概率比,并以更强正则化增强 RLOO,损失在 token 级聚合,使长轨迹的信用分配信号不被降权。整个 RL 为单次多环境在线训练,同时覆盖终端任务(ReAct + 基于 Harbor Tmux 的终端工具)与软件工程任务(SWE-agent 框架):每批 512 个 rollout、每 prompt 采样 8 个、共享 128K 上下文,按任务难度分配步数预算;环境提供预构建 Docker 镜像、自然语言指令和单元测试,采用二元奖励,无效工具调用记 0 分,使非法或格式错误的工具调用在最初几步内骤降。相比 SFT 初始模型,RLVR 使 Terminal-Bench v2 的 pass@1 提升 7.9%、SWE-Bench 提升 3.0%(均为绝对值),且联合训练优于分别训练、对分布外任务泛化更好,并产出更短的轨迹和更少的循环、失败调用。
图: 多环境 RL 训练运行提升了模型在 SWE-Bench Verified 和 Terminal-Bench v2 等基准上的表现。左侧展示了 RLVR 训练过程中的学习曲线。
06
内部人工评估基准
作为对现有编程基准的补充,还开发了内部基准套件,用于在与人工标注者进行的成对评估中衡量模型在分布外问题上的表现。与其他基准设置一致,评估了通过 Harbor 集成在 OpenCode 中的各代模型。为理解模型表现,我们在四个不同的功能维度上进行基准测试:
代码解释(Code Explanation): 要求模型在 README 文件中或直接向用户解释给定代码仓库的特定技术方面。
代码编辑(Code Editing): 要求模型基于现有代码库实现某项功能。
数据可视化(Data Visualization): 给定数据样本,要求模型使用特定框架创建特定的可视化;不提供额外代码。
从零实现(Implementation from Scratch): 仅给定设计规范和需使用的软件包,要求模型从零创建一个项目,主要聚焦于前端设计。
评估者会获得基于评分标准(rubric)的打分问题,以帮助他们评估各项响应标准,并在给出两个模型轨迹之间的最终偏好评级之前,先对各次尝试单独评分。在 85 个样本上,RLVR 后的最终模型对仅 SFT 版本的总体胜率为 66.1%,其中代码编辑任务的提升最为明显。
图: 在 85 个样本上,将 RLVR 后的最终 North Mini Code 检查点与仅经过 SFT 的检查点进行对比的成对偏好结果。
07
模型推理
使用transformers推理
环境安装
pip install transformers模型下载
modelscope download --model CohereLabs/North-Mini-Code-1.0 --local_dir CohereLabs/North-Mini-Code-1.0推理脚本:建议在生成时使用以下采样参数:temperature=1.0,top_p=0.95
from transformers import AutoTokenizer, AutoModelForCausalLMmodel_id = "CohereLabs/North-Mini-Code-1.0"tokenizer = AutoTokenizer.from_pretrained(model_id)model = AutoModelForCausalLM.from_pretrained(model_id)prompt = "Write a python program to check if a string is a palindrome or not."# Format message with the North-Mini-Code-1.0 chat templatemessages = [{"role": "user", "content": prompt}]input_ids = tokenizer.apply_chat_template(messages,tokenize=True,add_generation_prompt=True,return_tensors="pt",)gen_tokens = model.generate(**input_ids,max_new_tokens=1024,do_sample=True,temperature=1.0,top_p=0.95)gen_text = tokenizer.decode(gen_tokens[0])print(gen_text)
也可以通过transformers 的 pipeline 抽象接口使用该模型:
from modelscope import pipelineimport torchmodel_id = "CohereLabs/North-Mini-Code-1.0"prompt = """Given a list of unique words each of size k and an n sized word, w, where n is a multiple of k,Write a program in python to determine the number of unique combinations of words in the list that can be concatenated to form an anagram of the word w."""pipe = pipeline("text-generation",model=model_id,torch_dtype="auto",device_map="auto",)messages = [{"role": "user", "content": f"{prompt}"},]text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,)outputs = pipe(messages,max_new_tokens=1024,do_sample=True,temperature=1.0,top_p=0.95)print(outputs[0]["generated_text"][-1])
通过vllm使用
你也可以在 vLLM 中运行该模型。在新版本发布之前,请对 North Mini Code 使用 vLLM 的 main 分支,同时准确的响应解析还需要安装 Cohere 的 melody 库。
uv pip install "git+https://github.com/vllm-project/vllm.git"uv pip install cohere_melody>=0.9.0
随后可以通过以下命令启动 vLLM 服务器:
VLLM_USE_MODELSCOPE=true vllm serve CohereLabs/North-Mini-Code-1.0 \-tp 2 \--max-model-len 320000 \--tool-call-parser cohere_command4 \--reasoning-parser cohere_command4 \--enable-auto-tool-choice
在 OpenCode 中使用本地部署的 North Mini Code:
在新版本发布之前,请使用 OpenCode 的 main 分支。
# Example commands to install on linuxgit clone https://github.com/anomalyco/opencode.gitcd opencode# Install Buncurl -fsSL https://bun.sh/install | bashexport BUN_INSTALL="$HOME/.bun"export PATH="$BUN_INSTALL/bin:$PATH"# node-gyp was needed by a dependencybun add -g node-gyp# Install dependenciesbun install# Build CLIbun run --cwd packages/opencode build/usr/bin/install -m 755 \./opencode/packages/opencode/dist/opencode-linux-x64/bin/opencode \/root/.local/bin/opencode
点击下方“阅读原文”获取模型链接
👇点击关注ModelScope公众号获取
更多技术信息~
据央广网消息,网约车司机林岩宏表示:“早期一公里能挣两三元钱,现在一公里可能只有一两元钱。”算法在提升效率的同时,也让一些劳动者遭遇被加倍考核、收入不透明、工时被切割等情况。本是效率工具的AI,随意成为了“数字监工”。
AI 全面延伸管控边界
催生“数字监工”乱象
AI技术渗入生产组织方式的程度,早已超出“辅助工具”的范畴,正在悄然接管劳动过程的指挥权。最直接的表现,是将劳动者的每一分钟、每一次操作、每一公里行程都纳入可量化、可考核、可惩罚的数据网格之中——表面上是“智能调度”,实质上构成了一种全天候、无死角的“数字监工”。
网约车行业的运价缩水轨迹最具代表性。在郑州跑了7年网约车的李山河坦言:“我现在每天跑13个小时左右,收入约300元,扣除租金等固定支出,每月到手约4000元。”他记忆里单价从每公里两块多慢慢滑到一块出头,而平台推出的“特惠单”“一口价”把价格锚不断往下拽,他甚至发现,如果把“一口价”“随心接”类低价单的选项关掉,接单率会明显下降,只能重新打开,系统用派单权把低价单变成了“可以不接、但接不到别的”的软性强制。平台依托智能派单算法精准核算里程、时长与能耗,动态调价机制叠加“一口价”模式,使运价在数年间持续走低。
而在企业办公场景中,AI“监工”的逻辑更为隐蔽却同样锋利。福建一家互联网企业的市场总监张文锋的遭遇颇具典型性,团队引入AI助手后,竞品分析报告从过去需要数天收集整理压缩到一个小时即可输出,效率提升本该是好事,但管理层随即将这一“AI加速后的产出速度”默认为员工的常规产能基准,直接加派更多任务量。
从亚马逊仓库中AI实时监控拣货速度并自动生成解雇指令,到国内部分企业在员工终端部署行为追踪软件以鼠标移动、键盘敲击频率衡量“生产力”,AI正在将管理推向前所未有的精密程度。
算法机制的机械化、冰冷化
是问题症结
所有这些乱象的深层症结,指向同一个核心——算法被设计为单一目标的优化器,却缺乏对人的处境与现实复杂性的感知能力。它追求的是数字层面的“最优”,而非生活层面的“合适”。
以外卖行业为例,平台依靠历史订单大数据、路网拓扑与实时定位,为每一单精密计算出一条“最优路径”和一个“准时送达时限”,但这个时限往往按理想条件下的“最快速度”卡死,不考虑暴雨天气轮胎打滑导致的安全降速,不考虑商家出餐高峰期的真实滞留,不考虑老旧小区“进不去、上楼难”的最后一公里的现实摩擦,更不考虑早高峰学校周边临时交通管制造成的绕行代价。
做了8年骑手的陈安柱,他负责片区内中的有一所大学东门与西门“直线很近”,但校园封闭管理,系统规划的“最佳路线”却默认你能穿行,现实只能绕行。这一绕,配送时间就吃紧,超时就要扣分。
更关键的矛盾在于,算法精细切割骑手的在岗时长,只要处于上线状态便需全天候待命,在线时长被纳入活跃度评分体系,下线就意味着派单权重下降、后续收入进一步缩水。于是骑手即便没有在跑单,也不敢真正“下班”。骑手为了让系统判定自己“可用”,往往被迫把等单、避雨、找车、商家出餐滞留这些真实付出,压缩成一种只能自己扛的隐形工时。
化解AI“数字监工”难题
需多方协同
技术本身并没有错,但脱离约束的技术应用必然滑向工具理性碾压价值理性的旧路。将AI从“监工”拉回“助手”,需要多方同步发力。
监管层面,关键动作已经从“呼吁”进入“建制”阶段。2026年4月,中办、国办印发《关于加强新就业群体服务管理的意见》,从国家顶层设计层面直指算法黑箱问题,明确要求平台取消暗箱操作,保障骑手对计价规则、配送时长的知情权、参与权和选择权,算法基本原理与运行机制必须公开透明、备案审核。中央网信办同期推进《生活服务类平台算法负面清单(试行)》,多部门联合督促头部平台自查自纠,已推动美团基本取消超时扣款、滴滴设定“服务10小时强制下线6小时”的防疲劳阈值、各平台承诺抽成上限下调并推动核心算法公示专区建设。北京新版非机动车管理条例更直接写入“平台应依法履行算法备案手续,制定算法规则时应充分考虑交通安全”的硬约束。下一步,是把这些“已承诺”转化为可核查、可追责的持续监管,即预留极端天气、特殊场景的容错缓冲空间,确立算法变更的事前公示与协商门槛,让备案不只是填表,而成为实质审查。
企业层面,算法模型的优化方向必须从“最严算法”转向“折中算法”。具体而言,应在时间预估中纳入天气系数、路况拥堵指数、小区通行难度等现实变量,以“算法取中”替代“卡最短时限”;在考核体系中剔除单纯以速度为导向的奖惩杠杆,增设安全分、疲劳预警等人性化参数。
而对劳动者来说,维权最难的不在勇气,而在证据。当计价规则、派单逻辑、处罚系数、奖励门槛全部封进代码与接口,劳动者手里往往只剩接单记录和收入截图这样的碎片。正因如此,无论是交通运输部早年“阳光行动”要求的每单列明乘客支付总额、驾驶员报酬、抽成比例,还是中办国办文件强调的算法备案、公示、听取工会与从业人员代表意见,本质上都是在做同一件事,让规则能被看见,让看见后能争论,让争论能通向修正。
归根结底,AI不该是用来让劳动者跑更快的鞭子,而应是帮每个人把活儿干得更从容的杠杆。效率红利要真正转化为从业者福利,前提是让算法回归辅助工具的本质,让技术的尺度重新以人的尺度来校准。
(图片来源:摄图网)
END
向“通信信息报”投稿,请致信:txxxb2001@163.com,
稿件一经刊发,将根据文章质量,
提供千字200元-500元的稿酬。
其他合作、建议、新闻线索,
欢迎于微信公众号后台联系我们。
不良信息举报电话:0591-83365173。
专注做内容的公众号
近日,中国信通院正式宣布,中国电信、中国移动、中国联通旗下词元(Token)产品集体入驻中国算力平台算力超市。这一事件标志着普惠算力正式从概念走向规模商用。与此同时,中国电信500万台天翼智屏集采项目也于近日正式公示成交结果,中国电信500万台天翼智屏集采落地,标志着中国电信基于星辰大模型的“Token经营”战略进入实质性落地阶段。
从战略提出到产品上架,从算力底座到终端入口,三大运营商正集体走出单一流量变现的旧周期,迈入以词元为计价核心的AI价值运营新阶段。这不仅是运营商自身商业模式的重大转型,更是“人工智能+”国家战略在民生领域落地的关键一步。
Token 经营顺势站上风口
中国电信率先提出Token经营战略,是产业周期、政策导向、市场需求多重因素共同作用的结果。2026年是“十五五”规划开局之年,党的二十届四中全会明确提出深入推进数字中国建设,要求全面实施“人工智能+”行动。作为数字中国建设的主力军,运营商承担着推动AI规模化应用、让智能服务惠及更多群众的责任。
从产业周期来看,通信行业正经历发展模式的转变。过去三十年,运营商先后经历了语音经营、短信经营和流量经营三个阶段,每一次计量方式的变革都推动了行业价值的显著增长。随着生成式AI的发展,Token正在成为新的基础服务计量单位。中国电信董事长柯瑞文在2026数字中国建设峰会上表示:“智能云体系就是词元(Token)经营体系。Token经营的本质就是为用户提供AI服务。”
市场需求的增长也为Token经营提供了基础。随着大模型技术的成熟,AI应用开始从专业领域向大众消费领域渗透。但普通用户使用AI服务仍面临一些门槛,如注册多个平台账号、绑定第三方支付、操作复杂、数据安全顾虑等。运营商凭借庞大的用户基础、完善的支付体系和全国性的服务网络,能够简化AI服务的使用流程。用户通过运营商官方APP开通Token套餐,消费可直接计入话费账单,无需绑定第三方支付,基本实现了“手机号即AI账号”的便捷体验。
供给筑基
构建端到端Token服务能力
中国电信能够较快推进Token经营的消费端落地,得益于供给侧的长期积累和商业模式的内在需求。在供给侧环节,中国电信已构建起从算力、数据、模型到平台的技术体系,为Token经营提供了基础保障。
在算力层面,中国电信持续推进智算基础设施建设。截至目前,中国电信自有及接入智算总规模已超过91 EFLOPS,能够支撑大规模模型训练和推理的算力需求。同时,中国电信通过“息壤”算力互联调度平台2.0和Triless架构,有效提升了资源调度效率,实现了全国算力资源的统一管理和弹性调度,有助于降低Token生产成本,为普惠AI服务提供了可能。
在数据层面,中国电信DaaS层汇聚了超20万亿词元的训练数据,这些数据覆盖通信、政务、金融、教育、医疗等多个领域,为大模型的训练和优化提供了素材。中国电信建立了完善的数据治理体系,严格遵守数据安全和隐私保护相关法律法规,确保数据合法合规使用。
在模型层面,中国电信采用“自研+生态”的发展策略。一方面持续投入自研星辰大模型的研发,提升模型性能;另一方面与国内主流大模型厂商开展合作,将GLM-5、DeepSeekV 3.2、MiniMaxM 2.5等模型接入星辰Token Hub平台。这种模式能够为用户提供多样化的模型选择,满足不同场景的AI需求。
在平台层面,星辰Token Hub运营服务平台1.0具备多模型聚合与智能路由、自研与生态智能体纳管功能。用户调用Token时,平台可根据模型效率、Token消耗、调用成本等因素进行智能调度,匹配适合的模型服务对应场景。同时,平台纳管了各类自研与生态智能体,能够为用户提供一体化AI服务。这种平台化运营模式降低了用户使用AI的门槛,也为生态伙伴提供了触达用户的渠道。
标准化深耕
推动Token经营从概念走向实践
Token经营可持续发展,需要通过标准化建设和行业场景化深耕,从概念走向实际应用。中国电信在推动Token经营标准化和规模化落地方面开展了积极探索。
在标准化建设方面,中国电信参与国家和行业标准的制定,推动算网Token标准化资产化运营。作为中国信通院算力网络标准体系的参与者,中国电信在Token计量、计费、安全、互通等方面提出了相关建议。同时,中国电信在内部建立了统一的Token计量标准和计费体系,初步实现了跨终端、跨应用、跨场景的Token共享互通。用户购买的Token可用于调用大模型,也可兑换各类AI应用和服务,提升了Token的使用价值。
中国电信推出了天翼Token币和Token权益体系。天翼Token币作为中国电信Token经营的统一量纲,可用于客户积分兑换Token量包和AI应用。Token权益体系通过引入AI生态应用伙伴,为用户提供更多样的AI服务选择。这种模式有助于吸引用户使用Token服务,也为AI产业发展提供了新的路径。
在行业场景化深耕方面,中国电信针对不同行业的需求,开发了相应的Token解决方案。在教育行业,推出AI助教、智能作业批改等服务;在医疗行业,开发AI辅助诊断、智能病历生成等应用;在金融行业,提供智能风控、智能客服等解决方案;在工业行业,打造工业智能体,助力企业生产智能化。
三大运营商集体入驻中国算力平台算力超市,是Token经营发展的重要节点。用户可登录中国算力平台获取三大运营商的词元产品信息,根据需求灵活选择。中国电信的天翼云Token Plan产品分为开发者/中小企业版和个人/家庭版,分别基于GLM-5大模型和DeepSeekV 3.2通用大模型能力;中国移动推出“Byte+Token”双增长战略,提供1元可购40万Tokens的通用服务;中国联通提出“Agent+Token+AI云”范式,推出Coding Plan及Token Plan产品。三大运营商的有序竞争,有助于推动Token服务价格下降和质量提升,让更多用户享受到普惠AI服务。
随着5G-A网络的规模商用和AI技术的进步,Token经营将有更广阔的发展空间。运营商将继续完善智能云体系建设,提升Token生产、分发和应用的效率,推动AI服务不断优化。同时,运营商将加强与产业链上下游的合作,共同构建开放协同的AI产业生态。Token有望成为运营商新的价值增长点,也将成为数字经济时代重要的价值计量单位,为千行百业的数智化转型提供支撑。
(图片来源:摄图网)
END
向“通信信息报”投稿,请致信:txxxb2001@163.com,
稿件一经刊发,将根据文章质量,
提供千字200元-500元的稿酬。
其他合作、建议、新闻线索,
欢迎于微信公众号后台联系我们。
不良信息举报电话:0591-83365173。
专注做内容的公众号

OpenAI's GPT-5.5, GPT-5.4, and Codex are now generally available on Amazon Bedrock, one month after OpenAI revised its exclusive Azure arrangement. Pricing matches OpenAI's direct rates with usage counting toward AWS commitments. Codex shifts to pay-per-token billing with no seat fees. GPT-5.4 is the first OpenAI model available in AWS GovCloud.
By Steef-Jan WiggersIt has entered a preliminary agreement with PPC Group in Greece to form a 50:50 JV of their fibre assets and businesses, and is reportedly bidding for TalkTalk’s consumer broadband unit
Vodafone Greece and Public Power Corporation, better known as PPC Group, have entered into a preliminary agreement to form a 50:50 joint venture for FTTH. Under the proposed deal, the two will merge their networks and wholesale fibre businesses into a single entity.
Collectively, Vodafone Greece and PPC Group’s fibre businesses cover more than 1.6 million premises. The JV would offer wholesale open access to internet service providers in Greece.
The formation of the JV is subject to due diligence and subject to customary conditions including regulatory approvals. Vodafone says it “expects to provide a further update in due course”. Last month Vodafone announced it would take full control of VodafoneThree – which was allowed for in the conditions of the merger – sooner rather than later.
Vodafone bids for TalkTalk assets in UK
Earlier this week, VodafoneThree reportedly bid for the consumer operations of UK rival TalkTalk. A Financial Times article [subscription needed] said the rationale is for VodafoneThree, now the UK’s biggest operator, to accelerate its progress into providing broadband. VodafoneThree said it wants to double its UK broadband base to 4 million premises passed by the 2030s.
TalkTalk has about 1.75 million customers and is auctioning its consumer division. After an inititial decision not to engage, VodafoneThree took part in the second round of bidding last week, according to unnamed sources cited by the FT. The value of the consumer business is not precise – valued at between £200 million and £300 million.
TalkTalk is also seeking a buyer for its wholesale division, PXC.
TalkTalk group was bought for £1.1 billion by London-based hedge fund Toscafund in 2021, which added £527 million debt to its balance sheet in a time of rising interest rates. Last year Openreach reportedly threatened not to connect any more TalkTalk customers to its network because of late payments by the service provider. That was also reported in the FT.
The post Vodafone looks to expand fibre footprint in Greece and the UK appeared first on Mobile Europe.
In this podcast, Shane Hastie, Lead Editor for Culture & Methods spoke to Craig McLuckie, co-creator of Kubernetes and CEO of Stacklok, about the impact of AI coding tools on open source communities and engineering teams, designing deliberate organisational culture, and navigating evolving career paths for engineers in the age of AI.
By Craig McLuckieTopic: Scaling Enterprise AI Agents with Dify and Red Hat AI
Alvin walked through how enterprises move from AI pilots to production: combining Dify’s agentic workflow engine with Red Hat AI’s enterprise infrastructure to deploy scalable, production-ready AI agents.
Thank you @RedHat for the invitation and for a great booth experience! 🤝 #Difyf#SuperAI20262#RedHata#EnterpriseAIA#AIAgentst#GenAIAI
Two related, Oracle-backed projects published opposing policies on open-source contributions created with generative AI: The OpenJDK Governing Board approved an interim policy prohibiting such contributions, while the Coding Assistants policy from GraalVM permits them. Both projects require contributors to sign the same Oracle Contributor Agreement (OCA) for intellectual property.
By Karsten Silz“智能体最后的考试”,Fable 5竟然不敌GPT 5.5
最难档通通零蛋
没想到打脸来得如此之快!!
刚刚,UC伯克利放出了一场号称“智能体最后的考试”的全新基准测试。
它把当今最强的AI Agent们拉到考场上,让它们干真正的活——
在Siemens NX里建3D模型、在Unreal Engine里搭游戏场景、在Adobe After Effects里做特效合成。
结果成绩令人傻眼:
最难的一档,当今公认最强的Claude Fable 5、GPT 5.5,全是大写的零蛋。
你说难度稍微放低一点呢?分数倒是有了,但结果也相当令人意外——
GPT 5.5竟然还小胜了Claude Fable 5。
我没听错吧,A家刚发布的最强模型Claude Fable 5,被几个月前的GPT 5.5打败了??
要知道在此前几乎所有主流benchmark上,Fable 5对GPT 5.5都是碾压级别的存在——SWE-Bench Pro上80.3%对58.6%,Humanity’s Last Exam上64.5%对52.2%。
但换到这场“真干活”的考试里,局面却反了过来。
这个新基准叫Agents’ Last Exam(ALE),背后团队来头不小,之前MMLU、MATH、CyberGym、ExploitGym这些你耳熟能详的基准都是他们提的。
取这个名估计也是参考之前Scale AI那个“Humanity’s Last Exam”(人类最后的考试),只不过这次被考的不是人类知识的极限,而是AI Agent干活的极限。
该说不说,这个测评一出来,以前天天喊着“Agent要取代人类工作”的人,这下是真干沉默了…
“智能体最后的考试”,赢家竟是GPT 5.5!
先看完整排行榜。
从最核心的任务通过率指标来看,GPT 5.5直接包揽冠亚军:
第1名是GPT 5.5搭配OpenAI自家的Codex框架,通过率24.0%。
第2名还是GPT-5.5,只不过换了ALE Claw框架,通过率23.0%。
(ALE Claw是团队自己写的一个baseline Agent,跟Codex、Claude Code、Cursor CLI这些商业框架并列参赛)
直到第3名,我们才看到Claude Fable 5的身影——搭配Claude Code,拿下22.0%的通过率。
往下看更有意思。
第4、第5、第8名全是GPT 5.5,只是换了不同的框架。
前10名里GPT 5.5出场了5次,加上第6名的GPT 5.4,OpenAI模型直接占了6席。
而Claude家族呢?
Fable 5拿了第3,Opus 4.7第9(18.4%),Opus 4.8垫底第10(15.8%),不敌之势一目了然。
也不怪OpenAI研究员喜庆发帖,欢欢喜喜过大年了:
而在成绩之外,这里还有这样几个值得细品的信号。
一是天花板低得惊人。
冠军通过率才24%,综合得分最高也不过45.8%。
意思是,就算按最宽松的“部分得分”算,最强的Agent也只能拿到不到一半的分。
而这些题全部来自真人专家已经完成的项目——人类专家的完成率理论上就是100%。
二是Claude烧钱烧得惊人。
这张榜单新增了一列“Estimated Total Cost”,一下子把贫富差距拉出来了:
Fable 5跑完全部任务花了2315美元,Opus 4.8花了1838美元,Opus 4.7也要1144美元。
而GPT-5.5这边呢?
最贵的Codex也就566美元,Cursor CLI只要174美元。
等于说,Fable 5花了Codex四倍多的钱,成绩还低了两个百分点。
三是效率差距同样触目。
Ale Claw跑完全部任务花了47小时20分钟,Cursor CLI只花了67小时。
而Opus 4.8呢?451小时——将近19天。
干的活最少,花的时间最长,收的钱最多(居然真有模型能同时做到?)
当然如果只看Claude Fable 5、GPT 5.5这两个最顶的,GPT 5.5的时间优势依旧明显。
而最扎眼的数字,还是那个零。
ALE把任务分成了三个难度档:
- Near-Term(近期可解)
- Full-Spectrum(全面覆盖)
- Last-Exam(终极难题)
在最难这一档,所有主流配置的平均通过率只有2.6%,包括GPT 5.5和Fable 5在内的大多数模型直接吃了零蛋。
所以这张成绩单的核心信息很简单:别看平时考试成绩好,一到真干活全露馅了。
答题学霸≠干活能手,这话在AI世界也一样适用。
什么是ALE?
要理解ALE为什么能把这帮“学霸”打回原形,得先看它跟以前的考试有什么不一样。
之前的Humanity’s Last Exam(HLE)是2025年初由Dan Hendrycks和Scale AI搞出来的,2500道跨学科难题,本质上还是闭卷答题——
给你一个问题,你给我一个答案,再难也是静态的知识检索。
而ALE完全不同,它考你“能干什么”。
核心作者Yiyou Sun在说得很直白:
AI智能体将在2026-2027年超越人类完成几乎所有工作——这个预测到处都是。所以我们造了这场考试来验证这个说法。
ALE的每道题都来自一个真人专家已经完成的项目,覆盖55个行业子领域,包括量化交易、基因组分析、航空航天工程、建筑设计、脑成像、动画特效、法律研究……
整个体系锚定的是美国联邦职业分类标准(ONET)*,说白了就是按“真实劳动力市场”来出题。
参与出题的阵容也够豪华:
300多位领域专家来自100多家机构,学术侧有MIT、Harvard、Stanford、Oxford、Caltech、ETH Zurich,产业侧有Goldman Sachs、JPMorgan、Meta、Amazon、Adobe、Oracle。
Snorkel AI通过Open Benchmarks Grants项目提供了资金支持。
考试形式也不是打字回答问题,而是直接操作电脑。
ALE用的是所谓GCUA框架(Generalist Computer-Use Agent,通用计算机使用代理),给Agent完整的GUI和命令行权限——
鼠标点击、键盘打字、写脚本、浏览网页,人类能在电脑上干的它都能干。
不限方法,只看结果。
交出来的“作业”由确定性代码自动评分。
No vibes. No human judges. Fully reproducible.(不靠感觉,不靠人类裁判,完全可复现)
这就堵住了之前很多benchmark的一个老毛病:评分器本身就能被骗。
此外,ALE在防作弊上还有一个狠招——
只公开约10%的题目(约150道),剩下1300多道严格保密。
公开题和私密题定期滚动轮换,确保不会有模型因为“背题”而拿高分。
这在当前benchmark数据污染泛滥的背景下,算是一个相当巧妙的设计。
整体而言,跟现有的Agent基准测试比,ALE的定位非常明确。
团队成员之一的Dawn Song专门拉了一组对比:
- ALE的CLI子集(ALE-CLI)覆盖40个行业子领域,而Terminal-Bench只有6个,SWE-bench-Pro只有5个;
- 人类完成这些任务的时间从几小时到几周不等,而后两者是几分钟到几天;
- 最强Agent在ALE-CLI上的通过率只有25.2%,而Terminal-Bench上是82.0%,SWE-bench-Pro上是59.1%。
一言以蔽之,其他考试已经快被做穿了,而ALE还远得很。
这就是ALE凭什么敢自称“智能体最后的考试”的理由。
值得一提的是,Dawn Song还分享了两个有趣的观察:
一个是,Agent会在没有真正验证工作成果的情况下宣布完成,这是Agent们最典型的失败模式。
很多时候,虽然它们说了“Done. All checks pass.”(搞定了,所有检查都通过了)
但实际产出可能缺少必要文件、数字算错、关键字段遗漏、或者直接违反了任务说明中的明确约束。
等于是,活没干完,嘴先说完了。
另一个是很多人疑惑的,为啥Fable 5这么拉胯?Dawn Song给出的回答是:
不存在“万能冠军”这回事。
每个前沿模型都有擅长的领域和拉胯的领域,ALE覆盖55个行业、1500+道题,最终得分是所有领域的平均值,很多模型的总分因此挤在一起。真正有价值的信号不在总分,而在不同模型在不同领域的表现差异——在同一道题上,不同模型往往因为完全不同的原因而失败。
当然也有可能是Fable 5偷偷“降智”了。
总榜里,Fable 5旁边标黄了一句“may be down-tuned”(可能被降级),这说的是Fable 5的一个已知问题——
它底层是Mythos模型加安全分类器,遇到网络安全、生物医学等敏感领域的任务时,会被静默切换到能力更弱的Opus 4.8。
在ALE这种覆盖55个行业的考试中,等于这部分科目直接派了替考,而且派的还是“奔波儿灞”这种角色。
One More Thing
当然,有没有可能Claude Fable 5的成绩本身就有问题呢?
不好说,但一桩八卦显示,Claude有“前科”。
5月底,初创公司Datacurve发布了一个叫DeepSWE的新benchmark,顺手揭了一个大底——
SWE-Bench Pro的Docker容器里附带了代码仓库的完整git历史,正确答案就躺在文件系统里。
大多数模型会无视它,但只有Claude不会。
它会主动检查仓库的git历史,从历史提交中寻找与任务对应的修复方案,并据此恢复正确补丁。
据称Opus 4.7约18%的通过成绩是这么拿的,Opus 4.6更夸张,约25%。
而GPT 5.4和GPT5.5这边呢?完全没有这种行为。Datacurve的措辞很外交:
这个benchmark让这种行为成为可能,但Claude是唯一持续这么做的家族。
科技媒体VentureBeat的评价倒很暧昧:
这说明Claude“环境感知能力”很强,非常擅长探索周围环境并利用可用资源。算“作弊”还是“机灵”,取决于你的立场。
但甭管怎么看,ALE显然吸取了教训——
直接把考场从命令行搬到了GUI桌面操作,让你没有git历史可以偷看。
评测AI的考场,正在被AI自己倒逼着升级,也算很精彩了。
完整测评地址:
https://agents-last-exam.org/leaderboard
项目主页:
https://agents-last-exam.org/
GitHub:
https://github.com/rdi-berkeley/agents-last-exam
BEV 杀入具身智能:跨维把机器人数据带上 Scaling 快车道
具身智能现在面临的问题,和自动驾驶几年前的困境非常相似。
过去几年,自动驾驶行业已经证明了一件事:谁先把真实物理世界组织进统一的数字空间,谁就先拿到规模化的入场券。
但当年,这件事并不是一开始就想明白的。
早期的纯视觉多相机方案,每个相机自己感知自己的,前摄看前面、侧摄看侧面,各出各的检测结果,再拼到一起交给规划系统。问题是,拼出来的东西在图像坐标里,不在物理世界里。视角一变、光线一变、场景一变,性能就掉。数据堆得越多,各自为政的混乱局面就越严重。
BEV,Bird’s-Eye View,就是那把钥匙。它真正改变行业的地方,不是给了工程师一张“鸟瞰图”,而是把多相机、多传感器、多任务输出,统一压进了一个可被规划系统直接消费的物理坐标系。自动驾驶因此完成了一次关键跃迁:从在图像里猜世界,到在物理空间里理解世界。
今天,具身智能正站在同一个路口。机器人数据来自不同相机、不同本体、不同坐标系、不同操作者。没有统一空间,数据堆得越多,就越混乱——不是规模化,是熵暴。
跨维智能提出的 Dexterity-BEV,正是要在具身智能里重做一次这样的重构:把视觉输入、机器人状态和目标动作,对齐到同一个参考系里,让机器人数据第一次真正具备可规模化训练的空间底座。这可以被看作是一次把 BEV 方法论系统性推进到具身智能数据基建层的尝试。
无秩序的Scale,只会演变为熵暴
今天的具身智能行业非常热闹。
机器人本体不断推陈出新,新的数据集接连发布,新的遥操作系统、人类第一视角数据、仿真与生成数据也在快速增长。显然,行业正在进入一个数据快速扩张的阶段。
文本可以被统一组织成 token,图像也有相对稳定的数据范式,但机器人数据和文本、图像不同。机器人数据天然异构,以机器人一条操作数据举例,可能同时包含多视角图像、深度、相机参数、关节状态、末端轨迹、语言指令、任务成败和真实反馈等多种维度的信息。更何况各机器人本体规格不一,数据集坐标系互不统一,相机采集视角存在差异,操作人员动作节奏也各不相同;更为复杂的是,UMI、Egocentric等全新数据采集范式还在持续涌入。人类的身高、臂展、视角和动作习惯,本质上也像一种新的“异构本体”,进一步放大了数据之间的差异。所以,具身智能面临的并不是单一的“数据量问题”,而是一个更棘手的双重难题:一方面,高质量真实交互数据仍然稀缺且昂贵;另一方面,已经采集到的数据又高度异构,难以互通、难以统一训练、难以跨机迁移。
这正是具身智能正在面对的现实:行业既需要更多数据,也需要一种把数据变成可训练、可迁移、可复用资产的底层秩序。如果缺失统一秩序,数据扩张并非正向规模化 Scale,只会走向熵暴(entropy explosion)。
Dexterity-BEV:
01 给具身智能装上“统一空间坐标系”
Dexterity-BEV 的思路非常直接,也非常狠:把多来源、多视角、多本体的机器人数据,统一对齐到一个 BEV 三维空间里。
这不是简单把多视角图像拼起来,也不是做一个笨重的三维重建系统。Dexterity-BEV 的关键,是构建一个统一 BEV对齐坐标系,让不同相机看到的物体、空间关系和操作目标,都能被放进同一个俯视参考空间。
可以把它理解成一个“虚拟正交相机”。不管真实相机装在哪里、从哪个角度拍、机器人从哪个方向看,最终数据都会被转化到同一个俯视空间里。这样,同一个物理任务就不再是一堆互不兼容的二维图像,而是同一物理世界中的可学习表达。
这一步的意义很大,过去很多 VLA 模型看起来学会了任务,但一旦相机视角变了、机器人基座动了、场景布局变了,性能就会明显掉。原因很简单:模型学到的不是物理规律,而是某个固定视角下的图像模式。
Dexterity-BEV 要做的,就是把模型从“看图猜动作”拉回到“在三维空间里理解任务”。
02 它不是放弃 2D 大模型,而是给 2D 大模型补上 3D 坐标
这也是 Dexterity-BEV 最值得讲的地方。
具身智能行业现在有一个两难:纯 2D VLA 有语义能力,但空间不够;重型 3D 方法有几何信息,但成本高、训练难,也不容易复用已有 2D VLM 的能力。
Dexterity-BEV 没有选择推倒重来。它保留多视角 RGB 输入,继续复用成熟的二维视觉编码器和视觉语言模型,同时通过 顶点图(vertex map) 和 顶点谱(vertex spectrum),给每个视觉 token 注入三维空间位置。
换句话说,它不是重新造一个昂贵的 3D 系统,而是在已有视觉模型体系上补了一层机器人最缺的东西:空间坐标。对于有深度信息的设备,它可以利用深度图和相机标定生成像素级三维顶点表示;对于更常见的纯 RGB 相机,它可以通过顶点谱机制,为每个像素构建一组三维位置假设,再编码进视觉特征中。
这就像给二维图像接上了一套三维物理骨架。语义能力保住了,空间理解补上了,工程成本也没有被打爆。这才是能 scale 的 3D。
03 不只对齐视觉,还对齐动作
如果 Dexterity-BEV 只是把图像对齐到 BEV 空间,那还不够。机器人数据真正难的地方在于:动作也不统一。
不同机器人本体差异巨大。一个 Franka,一个双臂平台,一个半人形机器人,即使执行同一个任务,关节轨迹也完全不同。如果模型直接学关节角,基本就被硬件绑死了,Dexterity-BEV 的处理方式,是把动作从具体关节里解放出来。
它不让模型只学习“某个关节转多少度”,而是学习末端执行器在统一 BEV 空间中应该去哪里、以什么姿态接近物体、如何移动、如何完成任务。
更关键的是,这些末端执行器位姿不是随便表达的,而是被进一步对齐到前面提到的统一 BEV 对齐坐标系中。
这就形成了一个非常漂亮的闭环:视觉输入在 BEV 空间里,机器人状态在 BEV 空间里,目标动作也在 BEV 空间里,输入和输出第一次被放进同一个物理坐标系统。这才叫真正的感知—动作对齐。
通俗点说,Dexterity-BEV 给不同机器人、不同相机、不同动作提供了一把共同的“空间尺子”。过去各说各话的数据,现在终于能用同一种物理语言交流。
具身数据还有第三种混乱:时间。
同一个任务,不同操作者做得快慢不同;不同机器人执行速度不同;有的人中间停顿,有的人动作连贯。这些差异很多时候并不代表任务本质,但会让模型训练变得更难。
Dexterity-BEV 在数据管线中加入了跨轨迹时序对齐机制,对不同机器人、不同操作者、不同数据集里的轨迹进行时间尺度规整。它不是要抹掉任务动作结构,而是尽量减少“谁操作得快、谁操作得慢”这种无意义差异,让模型更专注于学习任务真正的关键动作顺序和空间关系。
所以 Dexterity-BEV 做的不是单点优化,而是一套系统性数据基建:空间对齐、动作对齐、时序对齐、数据管线对齐。
Dexterity-BEV 实测验证强泛化能力
Dexterity-BEV 的实验设计也很有意思。它不是只在固定场景里刷一个好看的分数,而是专门去测那些传统 VLA 容易翻车的情况:相机视角变化、机器人基座扰动、场景布局变化、跨机器人平台迁移。
在仿真中,Dexterity-BEV 在 LIBERO 和 RoboTwin 2.0 上与 π0、X-VLA 等强基线对比。尤其在相机视角、机器人基座和场景布局被大幅扰动的设置下,传统 2D VLA 方法成功率明显下滑,而 Dexterity-BEV 仍能保持稳定表现。
在真实机器人上,Dexterity-BEV 也覆盖了四类双臂平台和多个长程任务,包括折叠纸盒、折布、舀爆米花、递书等。这些任务不是简单抓取放置,而是涉及刚体、柔性物体、颗粒物、双臂协同和人类交互的复杂操作。
[BEV视频_终0609.mp4]
这类任务更接近真实世界,也更能暴露模型到底是在“记画面”,还是在“理解物理”。
Dexterity-BEV 的结果说明了一件事:当机器人数据被放进统一空间,模型的泛化才真正有了基础。
BEV 进入具身智能,打通Scaling关键路径
笔者认为, Dexterity-BEV 最重要的意义,不只是一个模型效果提升,更像是具身智能从“堆数据阶段”进入“建数据秩序阶段”的标志。
过去行业很热衷讨论:谁采了更多小时数据,谁有更多机器人,谁做了更多任务。但如果这些数据不能统一训练、不能跨机迁移、不能复用到新场景,数据规模越大,反而越像一座座孤岛。
Dexterity-BEV 提供的是另一种思路:先建立统一物理空间,再谈数据规模化。这和自动驾驶当年 BEV 范式带来的变化非常像。BEV 让自动驾驶从多相机图像感知,走向统一空间理解;而现在,Dexterity-BEV 正在尝试让具身智能从杂乱的机器人轨迹,走向统一的感知—动作物理表达。
如果说过去具身智能还在“看见世界”,那么 BEV 进入之后,它开始有机会“组织世界”。这可能是具身模型真正 scale 之前,必须补上的一层数据基建。
具身智能的下一阶段,不会只是模型更大、数据更多、机器人更贵。
真正决定行业能不能跑起来的,是数据能不能被统一,动作能不能被迁移,经验能不能跨机器人复用。
Dexterity-BEV 的价值就在这里:它不是只做一个更强的策略模型,而是试图为具身智能建立一套可规模化的数据秩序。
从这个角度看,BEV 杀入具身智能,不是一个普通技术点,而是一次补课。
自动驾驶吃到过的 BEV 红利,现在轮到机器人了。
而跨维智能这次做的,就是把具身智能真正推上 Scaling 快车道之前,先把路修好。
-本文系量子位授权转载-
原创 周永亮 2026-06-12 12:00 北京
从操控一台机器,到拥有一个伙伴。
作者|周永亮
编辑|郑玄
最近,SpaceX、OpenAI、Anthropic 相继推进上市进程,合计募资规模或超过 2000 亿美元,一场史无前例的资本盛宴正在上演。这些超高估值背后,市场押注的不只是 AI 改变数字世界,还有 AI 渗透到物理终端之后的想象空间。
在物理 AI 这个方向,机器人是最显眼的赛道。特斯拉 Optimus、宇树的每次亮相都备受关注。但如果要看商业化落地的节奏,那汽车才是物理 AI 目前最有可能落地的场景。
2026 年 6 月 9 日,北京雁栖湖畔,一个名叫 AIVA 的新品牌正式亮相。AIVA 品牌正式官宣携手火山引擎,联合定义、联合设计、共同打造 AI 汽车体验。火山引擎为 AIVA 品牌提供豆包大模型、智能座舱等技术服务,帮助 AIVA 品牌提升车载智能交互体验。
在这次发布会上,AIVA 没有谈续航,没有谈智驾,而是提出一个根本性的问题:AI 时代的汽车应该长什么样子?
01
把造车的顺序,反过来
理解 AIVA,要先想清楚一个问题:智能汽车和 AI 汽车,究竟有什么本质区别?
过去 10 年,中国智能汽车行业经历了一波智能化的浪潮,辅助驾驶、大屏幕、语音助手……这些都已经成为人们购车的重要参考因素。但如果仔细看,会发现一个共同点:先有车,再加上 AI。
AIVA 想做的事情,是把这个顺序反过来,「AI 定义汽车,先有 AI,再有车」。让 AI 作为底层基座,在这个基础上长出身体。
火山引擎副总裁杨立伟在发布会上说了一句话,精准定义了这个差异:「我们理解的 AI 汽车,不只是把 AI 放到车上,而是让汽车成为物理 AI 的一个新物种。」
这句话听起来像产品发布会上的宏大愿景,但 AIVA 做了四件非常具体的事:需求前置、架构前置、功能前置、学习前置。 需求前置,意味着不再是产品经理开着调研会,靠人的判断推演场景;而是让 AI 去做海量数据分析,主动挖掘用户在通勤、家庭出行、长途驾驶、疲惫傍晚这些真实情境下的真实需求。
图片来源:赛豆科技
AIVA 总裁、产品经理李博在发布会上打了一个比喻,非常精准,「过去是人在前面挖矿,现在是 AI 在前面挖矿,人在后面淘金。」这不是效率的提升,这是需求发现方式的改变。
架构前置,意味着先想清楚 AI 需要调用哪些车辆能力、数据接口和执行系统,再去设计底层架构。这意味着车辆的传感器布局、数据流通方式、各系统之间的协同接口,都要为 AI 的深度介入预留空间,而不是等车造好了,再去想怎么把 AI「接进来」。
功能前置,不是把功能做成一个个菜单,等用户去找;而是让 AI 围绕用户的目标,动态组织全车能力。用户说「我好冷」,AI 不是弹出一个温度调节界面,而是综合车内外温差、你的历史偏好、当前穿着状态,直接给出最合适的方案。
学习前置,意味着这台车在你买来第一天和用了三年之后,应该是两种完全不同的体验。不是因为 OTA 推送了新功能,而是因为它越来越懂你这个人。
把这四件事放在一起,就构成了 AIVA 所说的「AI 定义汽车」:它不是给车装一个更聪明的助手,而是让 AI 从产品诞生的第一天起,就参与定义这台车应该是什么。
02
从人适应车,到车适应人
如果说「AI 定义汽车」是一次造车逻辑的革命,那它必然会重塑人与汽车之间的关系。
长期以来,人和车是一种操作关系:人发出指令,车执行功能。从方向盘、油门、刹车,再到点击屏幕,其实都是用户在主动操控一台机器。
但 AIVA 想打造的是一种协作关系,AI 能够感知状态、主动服务,成为「伙伴」而非「工具」。
图片来源:赛豆科技
这一句话,拆开来看,是三个具体的变化。
一个是交互方面,从「机械生硬」到「普适鲜活」。目前的车机系统,用户需要记住菜单位置、熟记唤醒词,甚至要用精确的指令格式说话,本质上是人在适应车。
物理 AI 时代的交互逻辑是反过来的:机器适应人。AI 能像人与人聊天一样,知道什么时候该接话,什么时候该保持安静,根据当时的场景和意图直达任务。
而鲜活则是另一个维度。AI 不是一个千篇一律的助手,而是能感知你的情绪状态,在你疲惫时切换更放松的音乐和灯光;在车上有孩子的时候,切换成「孩子王」模式……它不是预设的场景标签,而是对「现在的你」的理解。
另一个是智能从「功能堆叠」到「能力涌现」。传统智能汽车强调功能和配置越来越多,但这并不等于智能的提升,反而可能带来更高的使用门槛。
AIVA 追求的是让各个系统之间产生协同效应,形成「能力涌现」。
李博在发布会上举了一个例子,让人印象深刻。同样是 22 度,AIVA 理解的是完全不同的情境,「夏天穿着 T 恤刚进车的 22 度,和冬天脱下羽绒服穿着羊毛衫的 22 度,不是同一个 22 度;打完球大汗淋漓的 22 度,和穿着西装准备见客户的 22 度,也不是同一个 22 度。」
这意味着,真正的个性化不是记住你的偏好设置,而是理解你在不同情境里,真正需要什么。
再有就是,感受从「单调乏味」到「松弛愉悦」。
很多人开车会觉得累,不只是因为路况复杂,更是因为注意力被大量重复性的判断和操作消耗。当 AI 能够主动接住这些「负担」,用户的精神状态会发生很大的改变。
这也是 AIVA 品牌主张「Live Alive,爱予自由」的内涵,就是用 AI 把时间还给用户,用情感陪伴回应用户感受。
03
火山引擎,从第一天就入局
AIVA 发布会上,另一个值得深度解读的信息,是与火山引擎的合作方式。
官方的表述不是「技术供应」,不是「功能接入」,而是联合定义、联合设计、共同打造。
车企与智能化供应商的合作,大多遵循一个流程:车辆的硬件架构、功能定义、交互逻辑先由车企确定,AI 公司随后介入,负责让「车里的助手更聪明一点」。
但 AIVA 和火山引擎的合作,是从产品定义的第一天起就开始的。
杨立伟在发布会上说了一句话,道出了这个变化的意义,「如果一台车从第一天起就围绕 AI 来定义,它的交互方式、智能上限和用户感受,都会发生根本变化。」
火山引擎为 AIVA 提供的,是豆包大模型能力、智能座舱技术服务,以及多模态交互、车端智能体等能力探索。
但把大模型能力真正落地到汽车场景,需要跨越一道很高的门槛。汽车场景有其独特的复杂性,比如驾驶状态下,用户无法像使用手机一样全神贯注于交互;车内可能同时有驾驶员、乘客、儿童,交互逻辑完全不同……
这意味着,通用大模型的能力必须经过真实车端场景的专项训练与深度适配,才能真正理解这样的情境:高架桥上堵车二十分钟,车主有点烦躁,下一个出口有一家他常去的咖啡馆——AI 应该在什么时机、用什么方式、说什么话?
这种判断,不是靠规则写出来的,而是靠豆包的通用认知能力与汽车专业场景从源头长在一起,训练出来的。
04
当 AI,长出了汽车的身体
发布会的最后,AIVA 的首款概念车 Origin Concept 正式亮相。AIVA 所有关于「AI 定义汽车」的认知,在这一刻有了具体的体现。
图片来源:赛豆科技
设计团队没有从「风格」或「姿态」出发,而是从「让这台车能看见你、感知你、回应你」出发。车身采用 G4 曲面,没有硬棱角,没有刻意的折线;前灯被设计成可交互的「眼睛」,当你走近,它会专注地看着你;当你比个心,它会回应你;轮毂的设计灵感源自鸟类的叉骨,低风阻轮罩像翅膜一样薄而有韧性……
这些设计细节,其实都是在试图回答文章开头的那个问题:AI 时代的汽车应该长什么样子?
据了解,首款量产车型 AIVA ME7 将于 2026 年年内亮相,全系覆盖 20 万元以上主流市场。这是中国新能源汽车竞争最激烈,也是用户最难被说服的主流战场。AIVA 选择在这里验证「AI 定义汽车」的商业可行性。
2026 年,物理 AI 正在从实验室走向真实世界。过去的 AI 活在屏幕里,你问它,它答你;而物理 AI,是要把智能装进一台有眼睛、有手脚的机器里,让它真正走进现实世界。
所以你会发现,当 OpenAI、Anthropic 都开始研究怎么走进真实世界的时候,汽车行业正在经历的变革,其实是这波叙事的一部分。把 AIVA 放进这个背景里,它的坐标才看得清楚。
*头图来源:赛豆科技
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO
极客一问
你如何看待物理 AI 正在从实验室走向真实世界?
新智元报道
新智元报道
【新智元导读】OpenAI 正在讨论大幅下调 Token 定价,直接原因是预判 Anthropic 即将跟进。但消息传出的前一天,Anthropic 发布了 Fable 5,在核心编码基准上把 GPT-5.5 甩开 22 个点。一场价格战与一场能力战正在同步展开,它们指向同一个终极问题。
据《华尔街日报》最新报道,OpenAI 正在内部讨论大幅削减 Token 定价。
https://www.wsj.com/tech/ai/openai-considers-drastic-price-cuts-anticipating-war-for-users-with-anthropic-9b8c178e
知情人士称,此举意在抢先于 Anthropic 预期中的类似行动。
CEO Sam Altman 在近期活动上公开承认,成本已成为「一个巨大的问题」:
我们会有很多方式帮助用户以更少的支出获得更多价值。
降价讨论发生在一个微妙时刻。
OpenAI 本周刚秘密提交了 IPO 申请,Anthropic 更早一步启动了同样的流程。
拓展阅读:
突发!OpenAI秘密递表冲刺万亿IPO,奥特曼许诺人手一个AGI
两家公司目前都因 AI 系统所需的巨额算力投入而承受数十亿美元亏损。
大幅降价将进一步压缩利润率——在上市窗口前,这是一个高风险的赌注。
投资者长期关注的一个结构性风险在此刻变得格外显眼:两家的产品高度可替代,企业客户在它们之间切换的成本很低。
驱动降价讨论的,还有来自需求侧的明确信号。
一位 Uber 高管今年早些时候透露,公司已经花光了 2026 年的 AI 预算。
另一家企业的管理层上月表示,难以将 AI 编码效率的提升与可衡量的新产品功能挂钩。
这类声音在企业界正变得普遍,并在硅谷引发了关于 Tokenmaxxing(尽可能多地消耗 Token 以求提升生产力)的争论——效果能否真正转化为投资回报,越来越多人打上了问号。
过去两年 AI 公司的增长叙事建立在一个前提上:企业会持续加大投入。
当这个前提动摇,降价就从竞争策略变成了维持增长曲线的必要条件。
价格战还没正式开打,能力格局先变了。
6 月 9 日,Anthropic 发布 Claude Fable 5——首个面向公众的 Mythos 级模型。
拓展阅读:刚刚,Anthropic首个神话级Claude 5正式解禁!
它与仅限受控机构使用的 Mythos 5 共享底层架构,但加装了安全护栏:涉及网络安全、生物和化学的请求会自动回退到前代模型 Opus 4.8。
基准测试显示 Fable 5 与 GPT-5.5 之间已拉开代际差距。
在 SWE-bench Pro(更接近真实工程难度的编码测试)上,Fable 5 得分 80.3%,GPT-5.5 为 58.6%,差距达 22 个点。
Cognition 的 FrontierCode Diamond(按生产级标准设计的高难度基准)上差距更大:29.3% 对 5.7%,五倍之差。
上月刚加入 Anthropic 的 Andrej Karpathy 称其为「值得大版本号跳跃的阶梯式飞跃」。
Stripe 用 Fable 5 在一天内完成了一个 5000 万行 Ruby 代码库的迁移,此前估计需要一个团队干两个多月。
GPT-5.5 在 4 月发布时刚帮 Codex 追平甚至反超 Claude Code 的多项基准优势。
七周后,Fable 5 又把差距拉开了。
但与此同时,能力领先伴随着成本代价。
Fable 5 的 API 定价为每百万输入/输出 Token $10/$50,是 GPT-5.5 的两倍。
与此同时,更关键的是,6 月 22 日之后 Fable 5 将从订阅套餐中移除,转为 Usage Credits 单独计费。
Anthropic 称「产能充足时」会将其重新加入套餐,但没有给出时间表。
降价争夺企业客户只是这场竞争的表层。
Fable 5 的背后是 Mythos——一个因网络安全能力过强而无法全面公开的模型。
Anthropic 的 Project Glasswing 已将无护栏版本 Mythos 5 提供给约 15 个国家的约 150 个组织,用于国家级网络攻防研究。
OpenAI 在秘密提交 IPO 时表示「有些事情作为私有公司更容易做」,但未展开说明。
两家公司竞争的焦点已经超出了企业合同的范畴。
价格战是一种融资手段:用低价锁定用户规模,用规模支撑 IPO 估值,用上市融到的资金反哺下一代模型训练,实现 RSI(Recursive Self-Improvement,递归自我改进)。
这个链条的终点指向 ASI。
Anthropic 内部的有效计算指数(ECI)显示,模型能力仍在以大致恒定的速率持续提升。Fable 5 级别的跳跃还会继续发生。
对企业客户和普通用户而言,短期内 Token 变便宜确实是利好。
但当 AI 能力以这样的节奏跃升,新一代性能碾压上一代时,「哪家更便宜」可能很快就不是最重要的选择标准了。
参考资料:
编辑:马可
文章原文
新智元报道
新智元报道
【新智元导读】具身智能正在从实验室演示走向真实场景。越往真实世界走,数据问题越明显:视频能看到动作结果,动捕能记录轨迹,机器人日志能记录执行,但它们往往很难完整捕捉人类操作背后的意图、发力趋势、微控制和反馈修正。围绕这一缺口,一类新的人类操控数据基建正在出现。
过去几年,大模型证明了一件事:数据不仅是训练材料,也是能力边界本身。
文本模型吃下互联网文本和代码,获得语言、推理和编程能力;自动驾驶模型依赖真实道路数据,持续学习复杂交通环境;多模态模型则从图像、视频和语音里获得对世界表象的理解。
但当AI进入物理世界,问题变得更难。
具身智能要学习的不是一句话、一个图片标签或一段视频摘要,而是如何在真实世界中行动:如何抓起易碎物体,如何拧开瓶盖,如何插入接口,如何在接触后微调角度,如何在失败时重新选择动作。
这些能力背后,缺的不只是更大的模型和更贵的机器人本体,还有一种更底层的数据:人类如何操控物理世界的数据。
这也是为什么,Physical AI所需的数据规模,很可能最终远远超过大语言模型。
LLM训练所依赖的语言数据,本质上是高度压缩后的符号数据:一本书、一篇论文、一段代码,都是人类把经验整理成文字后的结果。它密度高、可复制、可检索,也相对「廉价」。
但身体经验不是这样。一个人一生读过的文字,按存储量粗略估算也许只是几十GB;而他从小到大接收的视觉输入、肌肉控制信号、触觉反馈和身体交互经验,可能是PB级甚至更高量级。人类通过身体学会抓握、平衡、接触、避让、用力和修正,这些数据大多没有被写进互联网,也没有被结构化记录下来。
所以,Physical AI的难点不是简单复制LLM的数据路线。语言模型吃的是人类已经压缩过的知识;具身模型要补的,是尚未被充分记录的人类身体交互数据。
工信部《人形机器人创新发展指导意见》已将人形机器人定位为未来产业方向,并提出建设大模型训练数据库、扩充高质量多模态数据。2026 年度人形机器人与具身智能实景实训专项行动则进一步强调「实景实训、数据沉淀、产品迭代、规模部署」的闭环,并要求建设高质量、高保真数据集。
这意味着,具身智能不再只是展台上的演示问题,而是要进入生产制造、仓储物流、医疗康养、应急救援等真实场景。
真实场景一旦打开,数据瓶颈就会变得很尖锐。
在实验室里,机器人可以在固定光照、固定物体、固定轨迹下完成任务;在现实里,物体会遮挡,材质会变化,人的动作会临时调整,接触状态也会不断改变。模型要从模仿动作走向理解操作,必须拥有更接近真实操控过程的数据。
所以,具身智能的竞争正在从三个层面展开:
机器人本体,解决能不能执行;
模型算法,解决能不能规划和泛化;
数据基础设施,解决能不能持续获得可训练、可复用、可治理的真实操作数据。
第三层,正在成为新的关键变量。
换句话说,Physical AI 的终局竞争不会只发生在机器人本体上,而会越来越多地发生在数据源头上。未来具身模型需要的数据量可能远超大语言模型,而高质量的人类操作数据,正在成为全球最稀缺的战略资源之一。
今天的具身数据采集方法大致有几类。
第一类是视频和第一视角数据。它们可以记录环境、物体和人的动作过程,成本相对低,也容易规模化。但视频主要看到的是外部结果。手被物体遮住、动作发生在边缘视角、手指产生细小变化时,关键操控信息可能丢失。
第二类是动捕、数据手套、外骨骼和专业遥操作系统。它们可以获得更精确的姿态、轨迹或控制量,但通常穿戴复杂、部署成本高,对自然操作有干扰,也不容易进入大规模日常任务。
第三类是机器人真机日志。它记录的是机器人执行了什么、关节如何变化、任务是否完成。但它往往回答不了更前置的问题:在人类示教或操作时,人的意图如何形成,什么时候准备发力,接触后又如何微调?
换句话说,很多现有数据记录的是动作结果,而不是操控过程。
一次真实的人类操作,其实包含多个层次:
意图:人准备做什么;
姿态:手和身体如何运动;
发力趋势:肌肉激活和接触状态如何变化;
微控制:接触后怎样修正、补力、调整方向;
结果:任务是否完成,物体和环境发生了什么变化。
如果只记录最后的轨迹或视频,很多关键过程会被压缩掉。对精细操作来说,这些被压缩掉的信息,可能正是模型最需要学习的东西。
EMG,也就是肌电信号,是肌肉活动相关的电信号。腕部或前臂的表面肌电可以在非侵入条件下捕捉部分运动意图、肌肉激活和控制变化。
2025 年 Nature 论文《A generic non-invasive neuromotor interface for human-computer interaction》展示了腕部 sEMG 用于连续控制、离散输入和文本输入的潜力,并讨论了 sEMG 对意向运动信号和手势力相关信息的捕捉价值。
论文链接:https://www.nature.com/articles/s41586-025-09255-w
EMG 不等同于触觉传感器或真实力传感器。它更适合被理解为一种人端估计信号:它不能直接告诉我们物体受到了多少牛顿的力,但可以为人准备怎样发力、肌肉激活如何变化、动作是否发生微调提供线索。这恰恰是它的价值所在。
在具身智能数据中,视觉、动捕、机器人日志和触觉传感器各自回答不同问题:
视觉回答:看到了什么;
动捕回答:动作在哪里发生;
机器人日志回答:机器执行了什么;
触觉/力传感器回答:接触和真实受力如何变化;
EMG 补充:人端意图和发力趋势如何形成。
当这些信号被放到同一条时间轴上,数据就不再只是分散的传感器记录,而更接近一次真实操作的完整过程。
从人形机器人的全身操作系统,到软件仿生灵巧手,再到机器人摄像头防抖、室内空间数据采集和物理因果数据引擎,不同团队几乎都在试图为Physical AI补上一块关键拼图。
而在这些路径之外,北京大学秦旭团队,则把视线进一步拉回到「人类如何操控世界」本身,提出面向Physical AI的人类操控数据平台。
其路径是以极具创新性的可穿戴硬件组合作为入口,从肌电与运动神经信号解码切入,通过神经腕带、全景头环等设备,持续采集真实世界中的人类操控过程,并将其沉淀为意图、姿态、发力趋势、微控制与反馈修正等结构化数据。
这套方案的关键,是把人类自然操作变成可采集、可同步、可训练的数据流。其中,神经腕带负责捕捉前臂相关的运动神经/肌电信号;全景头环记录第一视角下的环境、对象和任务上下文;如果再结合手部姿态、腕部视觉、IMU、机器人日志或接触传感器,就可以形成更完整的多模态操控数据。
举个简单例子:
一个人拿起杯子。视频能看到手靠近杯子、杯子被拿起;姿态数据能看到手腕和手指的位置变化;如果有触觉或力传感器,可以看到接触与受力;EMG 则可以补充动作发生前后的肌肉激活和发力趋势线索。
真正有价值的不是某一个信号,而是这些信号的同步。
对机器人来说,同步后的数据能帮助模型理解:在什么视觉环境下,人为什么这样伸手,如何预备发力,接触后如何修正,最后任务为什么成功或失败。
这就是人类操控数据平台的意义。它不是一个硬件外设,也不是一个单一数据集,而是面向 Physical AI 的数据采集和结构化能力。
第一类应用,是机器人训练和示教。
精细操作任务中,单纯的视频模仿常常不够。插拔、拧动、按压、抓取柔软物体、使用工具等任务,都涉及接触状态、发力变化和连续修正。人端操控数据可以为模型提供更丰富的监督信号。
第二类应用,是 AI 眼镜、XR 和智能设备交互。
语音不适合所有场景,触屏和手柄也不能覆盖所有操作需求。神经腕带作为低摩擦、低打扰的输入方式,可以让设备理解手势、意图和微控制,成为空间计算和智能终端的新交互入口。
第三类应用,是真实场景数据集建设。
实景实训强调从真实场景中积累高质量数据。人端操控数据可以补足传统视频和机器人日志之外的信号层,让数据集从「看见动作」升级到「理解操作」。
第四类应用,是数据产品和基础设施。
如果一套采集方案能持续沉淀跨任务、跨场景、跨用户的数据,它就不只是设备销售,而可能变成面向机器人公司、模型团队、AI 眼镜厂商和工业场景的数据模块。这也是雪梦未来试图强调的方向:短期是人机交互和具身数采,长期是 Human Manipulation Data Layer。
具身智能的下一阶段,不会只由更大模型或更强本体决定。
模型需要真实世界的数据,本体需要真实场景的验证,而真实场景又需要可持续、可治理、可复用的数据采集基础设施。
视频、动捕、遥操作、机器人日志都不会被替代。它们仍然是重要数据来源。但如果 AI 要更深入地理解人类如何操作物理世界,就需要补上动作结果背后的信号:意图、发力趋势、微控制和反馈修正。
EMG + Ego 视觉 + 姿态同步,是一种早期但值得关注的路径。
它让人不只是机器人要服务的对象,也成为 Physical AI 学习物理操作的重要数据源。从这个意义上说,具身智能真正的底座,可能不只是机器人本体,也不只是模型参数,而是高质量、可规模化的人类操控数据。
短期看,人类操控数据可为具身智能、AI眼镜和智能设备提供更自然的人机交互入口,降低操作门槛,提升连续性与低打扰体验;长期看,它指向一层新的物理世界数据基础设施,让AI不只理解文本和图像,也理解人类如何真实地与世界交互。
Physical AI的下一步,或许不只是把动作做得更像人,而是开始真正理解动作背后的操控逻辑与人类意图。那些决定成败的关键,很多时候并不写在最终结果里,而藏在动作发生前的判断、接触瞬间的微调,以及一次次反馈中的修正之中。
只有当AI学会的不再只是动作的外形,而是人如何发起、控制并完成一次真实操作,它才有可能从演示走向现实,真正进入那个复杂、开放、始终变化着的物理世界。
参考资料:
编辑:LRST
文章原文
新智元报道
新智元报道
【新智元导读】AI不仅写代码,连做实验也包揽了!基于闭环Agent架构RhinoAI,机器自主完成了碳材料寻优。告别低效人肉试错,AI「物质编译」直接撕裂材料黑箱。
微观惊艳、宏观平庸,这道「跨尺度性能退化」的难题困扰材料界数十年。
如何扭转这一局面?
鼎犀智创(Rhinovate™)联合北京大学深圳研究生院新材料学院、北京大学人工智能研究院的科研团队共同推出了CarbonKylin™,一个针对碳材料的Agentic自驱动材料研发系统,旨在系统性破解性能退化之谜,让新材料产业化真正跨越从实验室到应用的鸿沟。
从微观单元到宏观材料,性能为何会出现断崖式下跌?
问题根源在于组装过程中两类相互交织的物理机制。
其一是非线性涌现——当无数微观单元在数十道工序、数百个参数下发生强非线性耦合时,微小的初始波动便可能被逐级放大,最终使宏观性能远低于预期。
其二是热力学耗散——系统在趋向熵增的过程中,自发产生缺陷与无序堆叠;工艺过程中的非平衡冷却和残余应力也会引入力学性缺陷,二者共同造成能量的不可逆耗散,削弱材料的强度性能。
当前以A-Lab为代表的前沿 AI 材料研发平台,虽已在无机粉体等体系中取得突破,却难以应对非线性涌现行为与热力学耗散问题。
高通量计算筛选、自动化合成与表征等手段大多聚焦于研发链条的单个环节,缺少贯通模型预测、实验验证与机理理解的系统性框架。主流数据驱动方法多为黑箱预测,难以揭示性能涌现的物理根源,预测结果也难以升华为可迁移的科学认知。
面对跨尺度性能退化的难题,鼎犀智创(Rhinovate™)如何进行破局?
编译物质科学与工程(Material Compilation Science and Engineering,MCSE)将计算机科学中的编译理念引入材料制备,把从微观到宏观的制备过程形式化为可分析、可优化、可解释的编译过程,从而系统性地提升性能保留率,确保关键物理信息在尺度转换中的保真。
将这一范式工程化落地,不能依靠孤立的技术模块,而需要一种闭环式的研究架构。
这正是鼎犀智创(Rhinovate™)提出的RhinoAI所承担的角色——一套面向物质科学的Physical AI系统:不仅具备计算和推理能力,还能直接与物理世界交互,以内嵌的多尺度物理知识作为推理约束,并根据物理反馈自主修正认知和策略。
它由四个紧密协同的支柱共同构成完整的认知-行动循环:自动化实验平台产出标准化物理数据;多尺度模拟提供跨尺度机理与虚拟数据;跨尺度端到端模型实现预测与逆向设计;可解释物质计算揭示其中的物理机制,所得洞察再反馈至实验和模型改进。
MCSE 所设想的闭环,需要打通虚拟筛选、高通量实验、可解释分析等大量异构模块,若这些模块各自独立运行,研发人员仍会陷入手工编排的低效困局。
破解这一困局的关键在于RhinoAI的Agentic架构:借助大语言模型与多Agent协同,将离散模块整合为一个能自主推理、自主决策、自主执行并自主更新的回路。
RhinoAI的Agentic架构具体是如何运作的?
RhinoAI的能力建立在分层技术基座上,由五大模块构成其物理推理、计算、实验执行和知识获取的基础:大语言模型(LLM)、材料科学模型、科学算法、自动化设备、数据库与知识库。
在此基础上,基于LLM和Harness的协同调度中枢对这些基础能力进行动态编排。
该Agentic架构将材料研发全流程抽象为一系列可分解、可协调的认知与操作任务,每一类Agent被赋予明确角色和功能边界,在主Agent的统一调度下协同工作,形成认知-行动回路的结构化实现。
RhinoAI如何实现持续进化和知识沉淀?
支撑RhinoAI协同与决策持续进化的核心是自主记忆机制。
每一次从假设生成、实验决策、物理执行到结果分析的完整回路,都被结构化为一条持久存储的「研发记忆」——包含目标、决策、行动序列、观测数据、模型版本和策略效能。
记忆系统不只记录实验参数和性能结果,还记录假设的提出与验证结论、模型的版本演替和预测精度,以及策略的成功与失败模式。
更重要的是,不同 Agent 协作与竞合中产生的新搜索策略、从预测误差中凝练的物理判据、跨尺度关联中被算法自主发现的隐藏描述符,这些能力并非预先设计,而是从闭环研发的长期历史中积累而来。
这些增量知识,包括经过实验验证的物理判据、可解释分析揭示的机理洞察,以及系统在迭代进化中产生的新认知,将沉淀为结构化的科学语料,反哺后续研发任务和模型训练。
CarbonKylin™已正式发布,它取得了哪些里程碑式的成果?
CarbonKylin™是鼎犀智创(Rhinovate™)面向碳基纤维领域打造的首个验证实例。
在RhinoAI的闭环迭代驱动下,CarbonKylin™自主完成了单体设计、工艺寻优与可解释分析的全流程,成功设计出一款碳材料掺杂的杂环芳纶复合纤维,拉伸强度达到41.2 cN/dtex,处于业界最佳水平。
更关键的是,系统深入揭示了碳材料与杂环芳纶复合所产生性能涌现的机理:碳材料表面与杂环芳纶分子链间形成强界面层,为应力传递提供了耦合通道;碳材料的锚定效应抑制了组装过程中的局部熵增与缺陷形成,从而实现了结构致密化。
这一发现实现了从「黑箱优化」到「可解释发现」的跨越。
作为RhinoAI落地的首个验证实例,CarbonKylin™的经验将如何向其他材料体系拓展?
CarbonKylin™验证了RhinoAI这条路径的可行性,但它只是起点。RhinoAI的关键优势在于「通用框架+专有知识+专用设备」的分层架构,使前沿材料研发不必在每个新方向上重复建设底层智能设施。
在架构设计上,RhinoAI的核心平台框架、多Agent 逻辑和自主记忆机制属于通用层,而领域知识和物理设备则属于专有层。
具体而言,通用层包括Agent的编排调度、记忆的存取与更新机制,以及辩论协议等与具体材料体系无关的基础设施;专有层则包含针对特定材料的跨尺度模型、专用表征设备和领域知识图谱,需要实质性的领域定制工作。
基于该分层架构,针对不同材料体系,研发团队只需聚焦于该领域的专有知识、专用设备与领域模型,即可开展深度的领域定制工作,快速构建出该体系专属的闭环研发能力——从文献检索、虚拟筛选、实验执行,到多尺度表征、因果分析与知识沉淀,全流程贯通,无需从零搭建底层架构。
目前,鼎犀智创(Rhinovate™)正积极布局高性能聚合物纤维、锂电池、半导体薄膜等材料体系,将RhinoAI的全闭环研发能力快速落地为领域专属的智能研发平台。
对于希望在材料研发中引入系统性智能能力的团队而言,RhinoAI提供的不是一个工具,而是一套经过验证、可直接部署的完整研发范式,它让每一个领域都能站在坚实的智能基础设施之上,将精力集中于让材料真正发挥出应有的性能。
文章原文
原创 王召德、潘逢治 2026-06-11 19:44 浙江
当我们谈论“把大模型跑在手机上”时,速度始终是绕不开的核心问题。模型越大、参数越多,推理时的矩阵乘法运算量就越大。
随着 Arm 第二代可伸缩矩阵扩展 (SME2) 技术的普及,以及 MNN 推理引擎的深度适配,我们找到了一把打开端侧性能天花板的钥匙。只需在编译时开启一个开关,就能让 Qwen3-VL-4B 这样强大的多模态模型,在支持 SME2 的旗舰手机(如 vivo X300 等)上实现实时流畅推理。
本文,我们直接从工程落地的角度,手把手带你完成从引擎编译、模型部署到 APP 构建的完整流程,并用实测数据告诉你:为什么这套组合拳能让 Qwen 在端侧起飞。
什么是 SME2?
SME2 是 Armv9 架构中的一组高级 CPU 指令,它基于 SME 升级,核心突破在于引入了 ZA 矩阵累加器寄存器和流式模式。传统 Neon 做矩阵乘需要手工将外积拆成向量乘再累加,而 SME2 中的 FMOPA 等指令可以一条指令完成一个矩阵 tile 的外积累加。
通过引入 SME2 指令集,Armv9 架构 CPU 能够在 AI 异构计算框架下,高效支持大语言模型推理、图像处理、自然语言处理、语音生成等实时移动端推理任务。
认识我们的工具箱
在开始实战前,我们先了解一下本次部署的核心组件:
MNN:阿里巴巴开源的端侧推理引擎,具备高性能、轻量级、高通用性的特点。支持 CNN、Transformer、LLM、扩散模型等多种架构。
MNN-LLM:MNN 中专为大语言模型设计的模块,提供了从模型转换、量化到推理部署的全链路工具。
Qwen 模型:本文以 Qwen3-VL-4B-Instruct 为例——一个 4B 参数的视觉语言模型,支持图文理解和对话,体积适中,模型能力较强。
MNN 模型仓库:MNN 官方已经为大家转换和量化了多款 Qwen 模型,可直接下载使用。
MNN 的 SME2 适配:MNN 对 SME2 的支持采用编译时内建 + 运行时自动检测的设计,用户无需手动配置:
编译时:通过 MNN_SME2 开关(默认 ON)控制是否编译 SME2 优化内核
运行时:启动时自动检测硬件是否支持 SME2,支持则走 SME2 加速路径,不支持则回退到 i8mm → Neon,不会崩溃
三精度覆盖:FP32、FP16、INT8/INT4 量化均有手写 SME2 汇编内核
大小核调度:感知 SoC 大小核拓扑,SME2 大核用大 tile 处理主体计算,Neon 小核处理剩余部分,并行工作
KleidiAI 集成:集成 Arm 官方 KleidiAI 加速库,提供更多 SME2 微内核
实战演练:从零构建 SME2 加速的端侧大模型
接下来我们从源码开始,手把手走一遍开启 SME2 加速的完整端侧大模型部署流程。
前置准备
请确保以下环境已就绪:
Android NDK:推荐 r27+,需设置
$ANDROID_NDK环境变量ADB:用于与手机通信,
adb devices可正常发现设备JDK 17:Gradle 编译 APP 所需
手机:开启开发者模式和 USB 调试,通过 USB 连接电脑
Step 1:编译推理引擎
🟣 为 Android 编译 MNN 引擎的动态库(.so 文件)和命令行推理工具。
SME2 功能默认开启,可以通过 -DMNN_SME2=ON/OFF 显式控制开关。
# 1. 进入 MNN 的 Android 工程目录cd MNN/project/android# 2. 创建编译目录mkdir build_64 && cd build_64# 3. 执行编译(SME2 默认开启,可通过 -DMNN_SME2 控制)../build_64.sh "-DMNN_SME2=ON -DMNN_KLEIDIAI=ON -DMNN_LOW_MEMORY=true -DMNN_CPU_WEIGHT_DEQUANT_GEMM=true -DMNN_BUILD_LLM=true -DMNN_SUPPORT_TRANSFORMER_FUSE=true -DMNN_ARM82=true -DMNN_USE_LOGCAT=true -DMNN_OPENCL=true -DLLM_SUPPORT_VISION=true -DMNN_BUILD_OPENCV=true -DMNN_IMGCODECS=true -DLLM_SUPPORT_AUDIO=true -DMNN_BUILD_AUDIO=true -DMNN_BUILD_DIFFUSION=ON -DMNN_SEP_BUILD=OFF -DCMAKE_SHARED_LINKER_FLAGS='-Wl,-z,max-page-size=16384' -DCMAKE_INSTALL_PREFIX=."# 4. 整理编译产出make install
💡 make install 是必要的——它会将 libMNN.so 拷贝到 build_64/lib/ 目录,后续 APP 编译时会从这个路径引用动态库。
编译完成后,build_64/ 目录下会生成以下关键文件:
libMNN.so:MNN 核心引擎库llm_demo:命令行推理工具llm_bench:性能基准测试工具
Step 2:准备模型
🟣 方案一:直接下载 MNN 格式的模型(推荐)
MNN 官方已提供转换和量化好的模型,可一步到位:
cd MNN/transformers/llm/exportpip install modelscopemodelscope download --model MNN/Qwen3-VL-4B-Instruct-MNN --local_dir Qwen3-VL-4B-Instruct-MNN
🟣 方案二:使用 MNN 的模型转换工具自行转换
如果需要自定义量化参数或使用其他模型,可以手动转换:
# 1. 进入 MNN-LLM 的 export 目录cd MNN/transformers/llm/export# 2. 安装 Python 依赖pip install -r requirements.txt# 3. 从 ModelScope 下载原始模型modelscope download Qwen/Qwen3-VL-4B-Instruct --local_dir Qwen3-VL-4B-Instruct# 4. 执行转换(HQQ 量化)python llmexport.py --path Qwen3-VL-4B-Instruct --dst_path Qwen3-VL-4B-Instruct-MNN --export mnn --hqq
💡 提示:--export mnn 代表导出为 MNN 格式,--hqq 是推荐的量化选项,可以有效提升模型精度。
Step 3:推送到手机,命令行验证
🟣 将引擎和模型推送到手机,通过命令行快速验证推理是否正常。
# 1. 推送引擎文件到手机adb push project/android/build_64/llm_demo /data/local/tmp/adb push project/android/build_64/llm_bench /data/local/tmp/adb push project/android/build_64/libMNN.so /data/local/tmp/# 2. 推送模型到手机adb shell mkdir -p /data/local/tmp/mnn_modelsadb push Qwen3-VL-4B-Instruct-MNN /data/local/tmp/mnn_models/# 3. 进入手机 shelladb shell# 4. 赋予执行权限chmod +x /data/local/tmp/llm_demo /data/local/tmp/llm_bench# 5. 创建 prompt 文件echo "你好" > /data/local/tmp/prompt.txt# 6. 设置动态库路径并运行推理cd /data/local/tmpexport LD_LIBRARY_PATH=/data/local/tmp:$LD_LIBRARY_PATH./llm_demo /data/local/tmp/mnn_models/Qwen3-VL-4B-Instruct-MNN/config.json /data/local/tmp/prompt.txt
💡 知识点:为什么要设置 LD_LIBRARY_PATH?llm_demo 动态链接了 libMNN.so,Android 系统默认只在 /system/lib64 等系统目录搜索动态库,不会搜索 /data/local/tmp/。设置此变量告诉链接器也去指定目录查找。
当你看到模型流畅地回复时,恭喜,推理引擎已经跑通了!
🟣 确认 SME2 硬件支持
在电脑上另开一个终端窗口,运行:
adb logcat | grep "device supports"会看到类似输出:
The device supports: i8sdot:1, fp16:1, i8mm: 1, sve2: 1, sme2: 1其中 sme2: 1 表示手机的 CPU 硬件支持 SME2 指令集,MNN 引擎会自动使用 SME2 加速路径进行推理。
💡 这行日志反映的是硬件检测结果,与编译选项无关。-DMNN_SME2=ON/OFF 控制的是编译产物中是否包含 SME2 优化代码——即使硬件支持,如果编译时关闭了该选项,引擎也不会走 SME2 加速路径。
Step 4:构建端侧 AI 应用
🟣 命令行验证成功后,我们可以将推理能力集成到一个完整的 Android APP 中。本文以 MNN 自带的 MNN Chat 示例应用为例:
# 1. 进入示例应用目录cd MNN/apps/Android/MnnLlmChat# 2. 编译 APK./gradlew assembleStandardDebug# 3. 安装到手机adb install app/build/outputs/apk/standard/debug/app-standard-debug.apk
💡 提示:APP 编译时会自动从 project/android/build_64/lib/ 引用 libMNN.so 并打包进 APK,所以不需要再手动推送 .so 文件到手机——安装 APK 即完成了引擎的部署。
安装完成后,如果之前 Step 3 已将模型推送到 /data/local/tmp/mnn_models/,打开 MNN Chat 即可在"我的模型"中找到 Qwen3-VL-4B-Instruct 模型。你也可以通过 APP 内的模型市场直接下载其他模型。
以下是 MNN Chat 在手机上进行多模态问答的实际演示——用户拍照后,模型即可理解图片内容并流畅回答:
性能测评:SME2 带来多大提升?
为了验证 SME2 带来的实际性能收益,我们分别编译了 SME2 开启 和 SME2 关闭 两个版本的引擎,在同一台设备上使用 llm_bench 进行对比测试。
测试环境
设备:vivo X300
模型:Qwen3-VL-4B-Instruct-MNN
测试工具:llm_bench
Prefill 阶段提升最为显著(+81%):因为 Prefill 需要一次性处理整段输入 token,是计算密集型任务(大批量矩阵乘),能充分利用 SME2 的矩阵外积指令和大 tile(HP=128)内核。这直接意味着更短的首字等待时间。
Decode 阶段提升相对较小(+13%):因为 Decode 是逐 token 生成,矩阵乘退化为矩阵×向量运算(batch=1),瓶颈在内存带宽而非计算吞吐,SME2 的优势相对有限。
进阶调优
在完成基本部署后,你可以根据自己应用的需求,通过以下手段进一步提升性能和精度:
🟣 模型导出参数调优 在执行 llmexport.py 时,可以附加不同参数:
🟣 运行时参数调优 模型导出后,可以通过修改 config.json 控制运行时行为:
通过本文,我们完成了一条完整的端侧大模型部署路径:编译 MNN 引擎 → 准备模型 → 命令行验证 → 构建 APP → 性能测评。
SME2 作为 Arm 最新的矩阵加速指令集,在 MNN 的深度适配下,为端侧大模型推理带来了实实在在的性能提升——Prefill 阶段提速超过 80%。而 MNN 的"编译时内建 + 运行时自动检测"设计,让开发者无需额外配置即可享受硬件加速红利。
随着SME2技术的进一步广泛采用,端侧 AI 的性能天花板正在被不断抬高。期待看到更多创新的端侧 AI 应用!
你在端侧部署中遇到的最大“坑”是什么?欢迎在评论区分享,我们将选取三位同学送出定制周边一份。
推荐阅读
Agent 辅助开发,一站式打通 Qwen3-VL Android 端侧推理
教程首发|让手机拥有视觉感知能力
新智元报道
新智元报道
【新智元导读】GPT-5.6本月上桌,agentic编码据称已反超Anthropic Mythos!三家旗舰模型撞进同一个6月,两大AI巨头同时冲刺IPO,奥特曼却在内部抛出了一个更大的变量:如果AI先学会自我改进,上市反而不急。
GPT-5.6,本月发!
就在刚刚,OpenAI毫无预兆打出了一波连招。
ChatGPT熟悉的模型代号被直接抹去,全部换成了Intelligence「智力分级」。
WSJ独家爆出,OpenAI正酝酿大幅调低API定价,准备跟Anthropic打一场价格战。
紧接着,首席科学家Jakub Pachocki亲自放话,代号5.6、「大幅超越」前代的新模型,本月直接上桌。
降价、改版、新模型,一个疯狂的星期三。
但这些加在一起,都不如奥特曼在内部Slack里漏出的一句话——
如果AI的递归自我改进起飞速度够快,推迟上市的好处反而越大。
现在的大背景是,所有人都在抢着上市。
Anthropic在6月1日向SEC秘密递交了S-1,SpaceXAI已经在路演,估值1.77万亿。OpenAI自己也在6月8日跟进递表,三家合计估值约3.6万亿美元,相当于法国一整年的GDP。
投行给的建议很一致,谁先上市,谁就定义投资者对AI赛道的估值框架。
先手优势,兵家必争。
然而就在这时,奥特曼却提出了一个所有人都没有公开讨论过的变量:
AI递归自我改进的起飞速度越快,推迟IPO的好处就越大。
因为技术和世界可能以意想不到的方式发生变化,在那段时间里做一家私人公司可能有充分的理由。
他的意思不是「不想上市」,而是一旦AI发展到能自我改进的临界点,整个商业世界的规则都可能被推翻。到那时候,私有公司的灵活度要比上市公司大得多。
Anthropic的数据在侧面印证这个判断。
他们内部报告显示,AI的任务完成时间跨度正在每4个月翻一倍,工程师的季度代码产出量已经飙到了之前的8倍。
而奥特曼说这话的同一天,他的首席科学家正在用行动告诉所有人,那一天可能比想象中近得多。
GPT-5.4在3月5日发布,GPT-5.5在4月23日紧随其后,间隔6周。
GPT-5.6定在6月,又是6到7周的节奏。
这是一条稳定加速的曲线,而且代际之间的能力跳变,没有放缓的迹象。
海外社区早就围着GPT-5.6的「泄露」扒了个底朝天。
从5月中旬起,开发者就在Codex后台日志里发现了GPT-5.6的路由痕迹,内部代号iris-alpha。
随后陆续出现ember-alpha、beacon-alpha,再往后是kepler和kindle。
到6月初,kindle-alpha被确认为当前的发布候选版本。
有人在Design Arena上发现了匿名模型「Kindle」,跑了几轮实测后判断这就是kindle-alpha的公开测试形态。
后来kindle被移除,但GPT-5.6的存在已经板上钉钉。
目前社区讨论最集中的是两个方向的提升。
第一个是前端生成能力。不需要复杂的提示词,模型就能直接输出干净的、接近商用级的UI界面。
一位泄露者用最早期的iris-alpha检查点,在零指导的情况下生成了一个叫Lumen Notes的笔记应用,薰衣草色调,网格对齐,层级清晰,看起来就像一个成熟SaaS产品的截图。
第二个是agentic coding能力。
知名开发者Mark Kretschmann在𝕏上表示,「据我所知,GPT-5.6非常强大,在多个agentic coding基准上击败了Anthropic Mythos。」
奥特曼在近期的活动中曾表示,企业客户对AI使用成本越来越敏感。
因此价格这个点,可能是OpenAI接下来最关键的变量之一。
Anthropic刚刚发布的Fable 5和Mythos 5,API定价是每百万输入token 10美元、输出50美元,大约是现有Opus定价的两倍。
而GPT-5.5目前是5美元和30美元,本来就便宜一半。
不仅如此,根据WSJ的爆料,OpenAI甚至在考虑进一步大幅降价,主动跟Anthropic开打价格战。
如果GPT-5.6同时带来能力升级和价格下调,对Anthropic来说这是一记左右组合拳。
与此同时,产品侧也没闲着。
6月10日,OpenAI产品负责人Adam Fry在𝕏上宣布,ChatGPT的模型选择器正式改版,面向全球Plus和Pro用户滚动更新。
以前你打开ChatGPT,迎面就是一长串模型名字。
Thinking-Light、Thinking-Standard、Thinking-Extended、Thinking-Heavy,再加上Pro Standard和Pro Extended,六七个选项密密麻麻摆在那里,选择焦虑瞬间拉满。
现在这些全部消失了,只剩一个词,Intelligence。
六个档位从低到高排成一列,分别是Instant、Medium、High、Extra High、Pro Standard和Pro Extended。
换句话说就是从「你想用哪个模型」,变成了「你想让AI多聪明」。
Thinking-Light直接砍掉,理由是不到1%的付费用户在用这个档位。Thinking-Standard改叫Medium,Thinking-Extended改叫High,Thinking-Heavy改叫Extra High。Pro Standard和Pro Extended名字没变,但被藏进了Pro的二级菜单里
7周换一代模型。同一天改产品界面。同一天准备降价。
每一个加速的信号,都在让奥特曼那句关于RSI的话,变得越来越不像假设,越来越像预告。
一旦AI学会自我改进,上市这件事的优先级可能要重新排。
就在他说这话的24小时内,Anthropic的Claude Fable 5在全新的Agent Arena榜单登顶,以11.2%的综合净提升创下了该榜单有史以来的最大分差纪录,把GPT-5.5甩在了第四名。
6月,三家旗舰模型正面碰撞。Fable 5、Gemini 3.5 Pro、GPT-5.6,打的是同一批能力方向,推理、编码、Agent、前端生成。
但真正的竞赛可能不在这一层。
谁先IPO,拿的是华尔街的资金。谁先实现RSI,拿的是改写规则的权力。
前者的优势用年来计算,后者的优势可能用天来计算。
一旦某家公司的AI真正跑通了自我改进的循环,领先速度会以指数级拉开,后来者再多融资也追不上。
这大概就是奥特曼那句话真正的意思。IPO是手段,RSI才是终局。
GPT-5.6是给竞争对手看的,降价是给企业客户看的,RSI那段话,是给历史看的。
参考资料:
https://www.theinformation.com/briefings/exclusive-openai-preps-new-ai-model-expects-go-public-within-next-year?rc=epv9gi
https://x.com/adamhfry/status/2064768231903285451?s=20
编辑:摩西
文章原文
新智元报道
新智元报道
【新智元导读】OpenAI o1推理模型核心缔造者Noam Brown发长文炮轰整个行业:用单一跑分评价AI模型,从2024年就过时了。GPT-5.5看起来只比5.4强一点?控制推理预算后再看,那叫一个天壤之别。
OpenAI的Noam Brown,刚刚发了一篇长文,对着整个AI行业开了一炮。
文章标题叫「大规模推理计算的启示」,核心论点只有一个,你现在看到的所有AI跑分排行榜,给你的信息基本上是错的。
原因很简单。
同一个模型,给它一块钱想事情和给它一万块钱想事情,跑出来的分数天差地别。但现在所有的排行榜,都不告诉你这个模型花了多少钱跑出来的成绩。
4月23日,GPT-5.5发布。
OpenAI甩出benchmark表格,社区照例逐行比对。结论是:还行,比5.4好一点,但也没好到哪去。
然后几个小时过去了。
波兰数学家Bartosz Naskręcki用一条prompt,让GPT-5.5在11分钟内搭出一个代数几何可视化应用。
Ruby on Rails之父DHH更是感慨,用完5.5再切回Opus 4.7,像倒退了一个时代。
同一个模型。benchmark说「还行」,人说「炸裂」。为什么?
原因很简单,5.5和5.4根本不是在同一个计算预算下被测试的。
这就好比两个学生考同一张卷子,一个给了30分钟,一个给了3小时。你拿两份成绩来比,说「差距不大」,这不是比较,这是搞笑。
GPT-5.4 Pro的API定价是$30/$180(每百万token),GPT-5.5是$5/$30。价格差了6倍。
但benchmark表格上,这两个模型被当成同一个量级来比较,完全忽略了推理预算的差异。一旦控制token预算,GPT-5.5在网络安全评估上大幅拉开GPT-5.4。
Brown在文中展示了两张图。左边是传统benchmark视角,5.5比5.4好一点。右边x轴换成token数量,5.5的曲线远远甩开5.4。
同一场考试。换个维度看,结论完全不同。
这不是个案。
MMLU这个曾经最主流的评测基准,前沿模型全部挤在88%以上,分数差异在统计上已经没有意义。你看到的不是「谁更聪明」,是噪声。
MRCR v2在100万token长度上的测试,GPT-5.4得36.6%,GPT-5.5得74.0%——翻了一倍。但这个维度在标准benchmark表格里根本不存在。
ARC-AGI上,OpenAI的o3跑出最高分,单道题推理成本$30,000。
隔壁NVARC团队用40亿参数小模型拿了24%准确率,每道题$0.20。
三万美元对两毛钱,同一场考试——「谁排名更高」这个问题本身就已经失效了。
当模型的能力是推理计算量的函数时,一个没有x轴的benchmark分数,就是一个没有单位的物理量。它什么都没告诉你。
在Brown看来,正确的做法是画一条曲线:性能 vs 推理计算量。
x轴可以是token数、美元或耗时,各有优劣。但可以肯定的是,任何一条曲线,都比一个标量数字强。
或者,你也可以设一个明确的预算上限,告诉模型「你就这么多钱,给我答案」。
这恰好是人类考试的逻辑,SAT给固定时间,国际数学奥赛也给固定时间。
只有AI评测,在2026年了,还在假装「给多少钱想事情」这个变量不存在。
为什么这个问题现在才爆发?
因为两年前,推理时计算只是o1的专属概念。
而o1的核心贡献者,正是Brown。
此前,他在卡耐基梅隆做出Libratus和Pluribus(击败顶级扑克职业选手,后者登上Science封面),在Meta FAIR做出CICERO(第一个在策略游戏《外交》中达到人类水平的AI)。
从不完美信息博弈到推理模型,他一直在同一条线上:让AI学会想更久、想更深。
2024年的o1让「推理时间换准确率」进入公众视野。到了2026年,推理时计算已经是所有前沿模型的标配。
GPT-5.5 Pro不是一个独立模型,它是GPT-5.5同一个底座加了并行推理时计算:遇到难题跑多条推理链,综合出结果。
Claude有extended thinking,Gemini有Deep Think,几乎每家前沿实验室都在往同一个方向跑。
对此,学术界也给出了量化关系。覆盖率与采样次数呈对数线性关系。
也就是,给AI双倍的「想事情时间」,它不会变聪明一倍,但确实会变聪明一点。收益是对数级递减的。
但Brown引用了Karpathy和AI Safety Institute的一个关键发现——
越强的模型,在更长时间跨度上的收益越大。性能的高原期被推远了,甚至可能消失。
弱模型多想两分钟,可能已经到顶了。但强模型多想两个小时,曲线还在往上走。
每一代模型发布时,如果你只在某个固定的推理预算下跑benchmark,你看到的就只是冰山一角。真正的能力上限,在你测不起的那片水域。
用Brown的话说就是:「我们可能根本不知道现代LLM的能力天花板在哪里,因为测量成本太高了。」
针对这一问题,Brown给了三条建议。
第一,实验室发布新模型时公布性能-推理计算量曲线,至少标明分数对应的推理预算。
GPT-5.5的82.7% Terminal-Bench 2.0,你不知道花了多少钱跑出来的。你拿它和另一个模型比,你也不知道对方花了多少钱。
这就像两家公司比营收,一家报的是年收入,一家报的是季度收入,但都不标注时间跨度。
第二,benchmark排行榜追踪推理用量,或设定明确预算上限。
ARC-AGI已经在这么做了,但不是行业标准。
第三, 安全准备框架和负责任扩展政策显式纳入推理计算量。
安全评估不能只测「默认状态」——国家级攻击者完全可以在单个任务上砸1000万美元推理预算。
以Gemini 3 Deep Think为例。
Deep Think本质上就是Gemini 3 Pro加了外部调用框架,任何人花同样推理费就能复现。
真正该问的是,为什么所有模型卡都没把能力作为推理预算的函数来展示?
Brown理想中的安全评估应该是一张图。
x轴是推理预算(从$1到$10M),y轴是模型在特定危险能力上的表现。在低预算下测量,然后向高预算区域做预测。
但他也承认一个棘手的问题,长期评估可能无法靠外推解决。要评估一个AI agent跑一年会不会出问题,可能真得让它跑一年。
而AI实验室很快将面临荒诞局面——agent的运行周期超过了新模型的开发周期。你还没评估完上一代的长期行为,下一代就已经发布了。
所有前面的讨论都指向同一个问题。
如果模型的能力是推理计算量的函数,而且越强的模型高原期越远,那「超级智能」到底是什么?
传统理解里,ASI是一个质变的拐点:某天某个模型突然在所有认知任务上全面超越人类。
顺着这个逻辑往下想——ASI可能不是一个时刻,而是一条曲线。
前面的数字已经说得很清楚:同一类任务,两毛钱和三万美元的推理预算,买到的是完全不同的结果。但这些还只是已经测过的区间。
给一个前沿模型$1,000,000的推理预算呢?$100,000,000呢?
没人测过。Brown说了,测不起。
但对数线性的scaling关系告诉你,曲线还没到顶。而且越强的模型,高原期越远。
ASI可能不需要一个全新的架构突破。它需要的可能只是:足够的钱和足够的时间。
一个运行一整年、消耗数亿美元推理预算的AI agent,在这一年里表现出的能力,可能已经在特定领域超越了人类个体的一生积累。
过去十年,整个AI行业习惯了一种评估方式:一个模型,一个分数,排个名次。从ImageNet到MMLU到Chatbot Arena,谁的数字大谁就赢。
如今,跑分的「二维时代」正在开场。
模型的能力从一个点变成了一条曲线,评估从一个分数变成了一张图。y轴是表现,x轴是你愿意花多少钱让它想。
每个「第一」还要再乘以一个变量:推理预算。
同一个模型在$5和$500预算下的能力,可能根本不是同一个级别。而这张二维地图上的绝大部分区域,至今没有人探索过。
2026年,全球科技巨头在AI基础设施上的投入预计接近7000亿美元。这些钱买的不只是更大的模型,还有更长的推理、更多的采样、更快的inference。
同一个开源模型,有人跑$0.20一道题,有人跑$30,000一道题。能力差距不是模型的差距,是资源的差距。
当「智能」变成一种可以用美元标价的连续函数,「超级智能」也不再是一个是非题。
谁先适应这个二维坐标系,谁就先看清楚ASI决赛的真实比分。
参考资料:
https://x.com/polynoamial/status/2064210146558136827
编辑:摩西
文章原文
原创 徐珊 2026-06-11 18:50 北京
现在「给人」做产品,还重要吗?
现在「给人」做产品,还重要吗?
作者|徐珊
编辑|郑玄
一句话生成浏览器插件,AI 自动整理标签页。如果你关注 AI 浏览器,这两个功能你大概率见过,国内一款叫 Tabbit 的产品,几个月前就上线了。
但这次演示它们的,是苹果。6 月 8 日的 WWDC 上,苹果花了不少篇幅介绍 Safari 的这两个新能力,让浏览器从一个被动的工具,变成能主动帮你打理事情的助手。今年以来,Chrome 押的是 Gemini 的深度集成,Edge 绑定 Copilot,OpenAI 的 Atlas 干脆把整个浏览器交给 agent,但事实上,浏览器的 AI 功能也开始趋同。
这对所有做 AI 浏览器的团队来说,都不算好消息。当读懂你的标签页、替你执行任务、记住你是谁,变成每一家的标配,「我有个新功能」这件事正在快速贬值。一个创业团队领先巨头几个月做出某个功能,换来的护城河只有几个月时间的领先。
如果 AI 浏览器的功能会趋同,那不会趋同的是什么。6 月 9 日,WWDC 的第二天,Tabbit 走完 100 天公测,正式发布 1.0 版本。该版本正在新增记忆功能,会持续记录用户偏好、背景以及其他重要信息,并形成「可调用记忆」,自动适配用户回复风格,减少无效对话及动作。同时,上线了妙招商城,支持分享不同 Skill。
Tabbit 正式开始商业化进程。据刘炯介绍,面向大众用户的基础对话、网页阅读、常用妙招等核心功能 Tabbit 将永久免费。针对高频的 Agent 自动化调用及高级定制化场景,Tabbit 将探索差异化的订阅制模式,暂时定价为 9.9 元每周不限量。
在 100 天时间里,Tabbit 走过了从「地址栏」到「搜索框」,再到「对话框」,最终长成「智能体」的四步。当行业把最好的工程师和最酷的想象力都投给 agent 的时候,Tabbit 把市场潜力押在了那些还没真正上手 AI 的普通人。「技术尝鲜者已经被服务得够多了,而后面的追随者需要什么样的产品,到今天还没有人认真回答。」刘炯说到。
一个仍然为人设计的浏览器,是 AI 普及的入口,还是注定被冲掉的中间形态?一个被收购又被拆分的团队,凭什么敢做全行业最不性感的选择?以及最重要的,当功能不再值钱,AI 浏览器这门生意,到底在比什么?
Tabbit 用 100 天给出了它的初步答案,这份答案的成色,值得我们仔细看一遍。
01
100 天后,Tabbit 长成了什么样?
从 Tabbit 公测开始,我就一直在用。最开始时候,我给过它一个判断,它是我用过最适合普通人上手的 AI 浏览器。
这个「方便」不是一句客套。它的首页很干净,进去就是一个大的输入框,可以输网址正常上网,也可以直接对话。没有满屏的浮窗或者功能键,调用所有的妙招都是中文,简单易懂可见。
刘炯提到自己有洁癖,所以讨厌那种被各类插件占满的浏览器。「侧边一整排小球,选一段文字就跳出好几个菜单,有的还故意延迟两秒,好盖在别人上面。很像每天回家家门口贴的那些小广告」。因此,Tabbit 公测时给人的第一印象,干净、好上手。而这 100 天里,它做的事情,也在此基础上开始一层一层往上长。
最明显的产品加码,放在一个叫「妙招」的功能上。名字有点土,取名来源是刘炯说的那种短视频里「改善生活的 100 个小妙招」。落到产品上,妙招其实是把一件你常做的事,沉淀成一个能反复调用的小工具,和 Skill 很相似,但功能化了。
过去,妙招多是把你常用的一段提示词存成快捷指令,输入斜杠就能调出来。但在这 100 天里,它长成了三类东西,提示词、脚本和 agent 任务。他演示了如何把小红书首页的推荐流进行数据分析或者是打开微信公众号的长文,自动在页面上生成一个目录,方便跳转。过去你要么得去插件商店里碰运气造一个 Skill,现在你只需要和侧边栏说一句话。
比较有趣的是,Tabbit 考虑到了页面占用问题,当你执行一个 agent 的时候,你可以再打开一个网页去做其他任务,而 agent 的执行会持续运作,刘炯说道,「这样就不会出现有些命令是在和用户抢页面的情况了」。
妙招现在是可以分享的。Tabbit 做了一个「妙招广场」,里面有大量用户自己做的东西,关闭弹窗的、屏蔽广告的、导出 B 站高速播放的、测你收藏夹人格的。一个人做出来,整个小组、甚至更多陌生人都能拿来用。
更关键的变化是,妙招从一个人的工具,变成了一个能流通的生态。Tabbit 做了一个妙招广场,眼下已经有三百多款现成妙招可以一键添加,关闭弹窗的、屏蔽广告的、导出 B 站字幕的、做长文总结的,应有尽有。你做出一个好用的妙招,能生成一个分享链接,别人用 Tabbit 打开就直接装上了。
发布 1.0 的同时,Tabbit 还办起了妙招大赛,给好作品发奖金、给认证、给曝光。这件事刘炯看得很重,在他的设想里,妙招不是个锦上添花的功能,而是 Tabbit 真正想造起来的护城墙,让不会写代码的普通人也能造出自己的工具,再把工具分给别人,浏览器就从一个看网页的地方,变成一个大家一起搭出来的 AI 工作台。
有了妙招打底,它这 100 天的第二个变化,是个性化能力增强。
公测时 Tabbit 的对话是一次性的,关掉就忘。1.0 补上了跨对话的记忆,它会把你是谁、在干嘛记下来,记错了还能手动改;补上了本地目录挂载,你把一个文件夹授权给它,里面有什么它按需自己去看;收藏也不再只存网址,而是把整篇网页的全文索引下来,你问相关问题时它能自动引用。这些东西加在一起,其实是 Tabbit 在用它的工程能力搭一个底座,让用户自己也能在上面长出想要的东西,而且用得越久,它对你的理解和意图的把握就越深。
这种「懂你」具体长什么样,Tabbit 请了三个普通用户来回答。一个艺术专业的应届生,把几十篇文献按主题分成几个标签组,直接丢给它提炼观点、找研究空白,靠它啃下了一个全英文的分析软件,过了毕业答辩。一个 HR,招海外增长专家时不急着找人,先把业务目标、组织现状这些材料喂给它,让它帮自己把「这个岗位到底要什么能力」想清楚再去看人。一个建筑师,把每月重复的中标统计拆成几个妙招串成流水线,原来四个人的活儿现在基本不用人管。
学生、HR、建筑师,没有工程师,没有极客,这恰恰圈出了 Tabbit 想要的人,不是 AI 玩得很溜的技术开发者,而是后面那一大批原本对 AI 还有点犹豫的普通人。
模型层的变化 也不小。首先是接的模型更多了,不只免费可用的那些,也接进了一些更贵的高阶付费模型,Tabbit 1.0 内置了 LongCat、DeepSeek、智谱 GLM、Kimi 等多款国内头部大模型,并会实时接入新模型 API,把选择权留给用户。其次是,多模型的协同做得更顺,同一个问题,你可以让三四个模型一起作答,再让它横向对比、挑出分歧、最后总结成一份,省得你自己一家家去问,再切换界面对比。
据透露,公测期间六成以上的用户会主动切换模型,平均每个人用上 2.1 个,因为不同模型擅长的事不一样,有的适合写代码,有的快、适合日常问答,有的适合翻译。Tabbit 干脆把它们全端上来,还在调用的分配和速度上做了优化,新模型基本首发就能用上,平时按场景把请求分给合适的模型,性能上它一直追着 Chromium 最新版本走,性能功耗保持正常水平。最新版本走,性能功耗保持正常水平。
讲到这里,Tabbit 听起来确实在认真往「好用」上长。但我们用下来,也得说另一半的话,它还远没长好。
最直接的问题是 agent 的执行还不够稳,实际用起来,卡顿、报错等情况时有出现。
Tabbit 对此不避讳,但也给出了一些新洞察:Agent 任务成功率从 3 月的 53.1% 提升至目前的 91.8%。其中,5 月数据显示,单用户月均 Token 使用量已达 853 万,用户正持续、高频地将 Tabbit 应用于较重的任务处理和工作流中。
其次,「接所有人的模型」可以是优势,因为让产品不被任何一家模型公司绑住,但反过来,它的能力上限也就被别人的模型卡死了。模型能干到哪,它就只能跟到哪。何况眼下国内通用模型的天花板本身还比较有限,再接进 Tabbit 这套配置和框架里,可操作的空间被进一步压缩。这也意味着它能把工程做得很漂亮,能把上下文喂得很足,却没办法让一件模型本就干不成的事凭空干成。对那些只求「够用」的人来说,这 100 天的进步是实打实的;但对那些追求「好用」、想把真正复杂的活儿交出去的人,它可能还在探索过程中。
100 天的 Tabbit 跑得很快,干净、好上手,稳稳接住了普通人想用 AI 办点小事的需求,查份资料、改个网页、理一张表。它没有去瞄准当下最主流、也最受极客青睐的那条路,那种成体系、多层次、能扛复杂工作流的强 agent。行业里一个越来越被认同的判断是,agent 做个能演示的 demo 不难,难的是稳定好用,真正的成熟往往要等它开始老老实实解决某一个具体场景里的具体问题。Tabbit 把这个场景选成了普通人的日常琐事。这条路能不能走通,它能不能守住这个边界,又不被这个边界困住,还要打个问号。
02
首次回应被美团收购后近况
要理解 Tabbit 为什么会做 AI 浏览器的选择,得先回到刘炯团队当初拿到的那道题。
光年之外是 2023 年创立的 AI 公司,后来美团把这家公司收了进来。收购之后,团队被拆开了,跟大模型相关的人并进了美团的自研大模型团队,剩下做应用的,只有几个人。这几个人手里的命题,是「做一个 AI 应用」。具体做什么,没人规定,什么都可以。
业内当时对这道题有过不少猜测,大家更期待这个曾经离大模型很近的团队,交出来的第一份作业是个通用大模型,或者某个更性感的东西。结果他们前前后后试了一些方向,最后落在了浏览器上。
刘炯的理由很朴素,浏览器是个老形态,2008 年的 Chrome 到今天结构几乎没变,但它承载的东西一直在变重,白领平均一天有六个多小时泡在浏览器里办公,而 AI 又在源源不断地生成网页、生成应用,这些东西归根结底都是网页。一个越来越重要、形态却十几年没怎么动过的东西,在他看来恰恰是机会。更重要的是,浏览器天生知道你在看什么、在做什么,AI 接进来不用你把内容搬来搬去复制粘贴,有天然的上下文信息。
促成真正决定这件事能成立的,也有美团给的自由度。 刘炯在不同场合反复提到一点,美团从来没有要求他们只能接 LongCat,也没说哪家模型是竞对所以不许接。产品做什么功能、往哪个方向迭代、资源怎么投,团队有相当大的自主权,公司只在大方向上把关。过去两年他们试错过不少,也承受了相应的代价。这种放手在国内大厂里并不常见,多数公司收一个团队进来,第一件事就是想办法把它塞进自己的业务盘子里。
但放手的另一面,是这个团队确实没有接入美团的主营业务体系。它还是个小产品团队,做着一件跟外卖、跟本地生活八竿子打不着的事。外界一直有个流传很广的判断,说 Tabbit 迟早会变成美团本地生活的一个新入口,往里接外卖比价、酒店预订。刘炯否得很干脆,说现在没有任何整合。他打过一个比方,浏览器自己得先立得住,是个有人爱用的好产品,至于将来要不要叠加美团的业务,那是锦上添花,「要两个大于 1 的产品相乘才能有更好的结果」。
也因此,Tabbit 没有去做那种调动全公司资源的超级入口。 同时,或许是因为 Tabbit 小、独立、不被要求围着美团的指标转,它反而有了把产品本身做干净的余地。在外部分析师眼里,美团养这么一个团队,更像是在 AI 时代另押一张船票。这个判断未必中听,但它也有一定的合理性。
03
功能开始趋同,AI 浏览器接下来比什么?
把 Tabbit 这个赌注放回整个行业里看,它其实押在了一个还没有答案的问题上。
眼下行业里最主流的声音,是为 AI 做产品。让 agent 自己去跑、去点、去执行,人退到后面,产品越来越像是给 AI 用的,而不是给人用的。OpenAI 的 Atlas 把整个浏览器交给 agent,就是这条路最纯粹的样子。这个方向背后有个隐含的判断,人迟早会退出操作,所以现在就该为那个未来设计产品。
Tabbit 偏偏选了反过来的起点。它不反对 AI 干活,它反对的是把人挤出去。在它的设想里,浏览器是人和 AI 共用的一张工作台,你干你的,它干它的,共享同一套上下文,谁也不用给谁让路。这背后也有一个判断,在可见的相当长一段时间里,人不会退场,而那些还没真正上手 AI 的普通人,才是这一代产品真正没做完的题。
这两个判断到底谁对,今天没人能下定论,而且它们各自都站得住。支持 Tabbit 这一边的逻辑是,让 AI 全自动地替人办事,这件事现在仍然有门槛,普通人还驾驭不了,与其逼他们一步到位,不如先给他们一个低门槛的、人还在中间的产品,等技术真正成熟了,他们自然会走到更自动的那一步。但反对的声音也很尖锐,如果未来的锚点就是 agent 全面接管,那现在还把「人的叙事」当主流,会不会反而是在拖慢大家适应 AI 的速度,让普通人停在一个注定要被淘汰的中间形态上。
这就引出了那个更要紧的问题。技术尝鲜者已经被服务得足够多了,但他们身后那一大批追随者,需要的到底是什么样的产品,这件事到今天还没有人认真回答。Tabbit 赌的就是这块空白。它不见得对,但它至少没有跟着所有人挤在同一个方向上。
在刘炯看来,无论是智能标签整理还是一键造 Skill,单一功能上的创新,从来不是能长期领先的东西。他举了标签整理的例子,很多产品的整理是按域名分类,知乎一组、B 站一组,分完其实没用,而 Tabbit 想做的是按你当下在干的事来分,在报销、在写材料、在做毕设,它认的是任务,不是网址。在他看来,功能可以被抄,但对一件事情的理解抄不走,而决定一个浏览器好不好用的,恰恰是这种理解。
这其实点破了 AI 浏览器这场竞争里最关键的一些变化。过去浏览器的护城河是用户规模和默认设置带来的存量,现在功能层面大家越来越像,模型又是各家都能调用的公共资源,真正拉开差距的,落到了谁更懂人怎么用产品上。这是 Tabbit 这样一个没有存量、没有自研模型的小团队,唯一可能赢的地方,也是它把全部筹码押上去的地方。
*头图来源:Tabbit
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO
极客一问
你觉得 Tabbit 最好用的功能是什么?
Hardwire 2026-06-11 18:50 北京
一颗芯片、一个误解、一轮周期。
一颗芯片、一个误解、一轮周期。
作者|曹思颀
编辑|郑玄
和安克创新创始人兼 CEO 阳萌正式沟通之前,Hardwire 团队看过了他近年几乎所有的公开表达。
这显然不是一位当下舆论场里最受关注的「明星 CEO」——他没有个人社媒账号、没有公开发表过挑战行业巨头的野心和「金句」、甚至此前极少为自家新品发布站台。
多位了解阳萌的行业人士告诉 Hardwire,阳萌更符合一个经典「商学院管理风格」的 CEO 形象:归纳能力极强、擅长对万事「建模」、总结方法论并高效布置团队任务。
相比 iPhone 之于苹果、Walkman 之于索尼,作为一家消费电子公司,安克创业的前 15 年里没怎么留下过深刻印象的超级单品。反而是阳萌多年前提出的「浅海战略」,在很长一段时间里塑造了外界对安克认知——在当年的表达里,阳萌认为安克应该避开千亿美元级的超级品类(如手机、PC),而重点聚焦单一规模在 500 亿美元以下的中小品类。
但在阳萌看来,这种认知某种程度上也成为了外界对安克最大的误解。
「可能大家以为这种不大的市场很轻松」,阳萌希望扭转这个刻板印象,「『浅』只意味着市场规模不大,不代表这件事做起来就容易。」
事实上,在过去 12 个月里,安克开始把过去埋在饭里的肉——产品能力——向外界展示。去年 4 月,安克发布了全球首款消费级立体纹理 UV 打印机 eufyMake E1,4676 万美元的众筹金额创下了 KickStarter 平台纪录;今年 5 月,他们又正式发布了搭载自研芯片的消噪耳机,官方表示「通话消噪能力超越 AirPods」。
这些「不那么像安克」的产品,正是这次沟通的好奇心起点。而过往印象中管理范十足的阳萌,这次从一颗打破计算机 80 年传统架构的「自研芯片」讲起,以技术视角完整拆解了他对 AI 时代智能硬件的推理过程。当然,我们还聊到了 AI 变革对硬件行业几乎每一个环节——无论是投资人、创业者还是普通从业者——带来的冲击和机遇。
这不仅是一篇对安克这家公司的复盘,也希望为所有关注硬件行业的朋友们提供一个新的视角和思路。
以下是 Hardwire 和安克创新创始人兼 CEO 阳萌的对话,经编辑整理。
关注 Hardwire,共同讨论硬件行业新风向
01
前序:一个不在舞台中央的硬件老板
Hardwire:一个月前,在一场技术沟通会上,你开场那个故事是张鹏(极客公园创始人 & CEO)去年年底对你说他觉得「安克变了」。似乎你对这个评价印象很深,以前有人说过类似的话吗?
阳萌:鹏哥是第一个让我印象深刻地说我们「变了」的人。这个变化是从公司内部开始的,但我还不觉得此刻有那么多用户感受这种变化,还没到那个状态。有点像「春江水暖鸭先知」,科技媒体是站在最前沿的人,可能会先察觉到。
Hardwire:从内部开始变化到被外部所感知,中间隔了多久?
阳萌:我们在 2024 年年中完成了公司使命、愿景、价值观的调整。从那个时候到去年年底,大概隔了一年半。
Hardwire:所以这轮变革的起点来自 2024 年年中?
阳萌:我倒不觉得起点都在 2024 年年中。外界目前看到的几个产品:UV 打印机(eufyMake)、爬楼机器人(MarsWalker)、存算一体芯片(安克消噪耳机),基本都是 2023 年前后启动的项目。
安克是一家多品类的公司,公司里总有一些品类是先于所谓的想法、战略进行了提前探索,并不是严格的「先想清楚、相信,再去做」这个顺序。更多时候是有些产品、方向已经先做了,我们再把它抽象归纳出来,然后更多人相信「我们可以一起往那里走」。
Hardwire:Marswalker 去年在 IFA 的演示非常出圈。那段视频在我们的小红书账号上有 8000 多个赞、1300 多条评论。但我注意到,好像几乎没人意识到它们来自安克。你会不会觉得,这个阶段安克的产品似乎比品牌更酷一点?
阳萌:那个产品并不是挂的「安克」品牌,而是来自我们面向智能家居的子品牌 eufy。但是属于 eufy 旗下的扫地机器人、安防产品其实都没有在国内发布过,所以大家联想不到安克,我觉得也正常。
eufy 这个品牌从 2017 年就有了,那个时候我们希望用「品类品牌」的策略做多品牌:希望消费者想到充电就想起安克、想到影音就想起 soundcore(声阔)、想到智能家居就想起 eufy。当然,今天回头看,这个策略其实不太对,所以我们也计划把所有子品牌都并回安克。
Hardwire:会不会也跟你作为 CEO「营业」不够积极有关?今天好像每个消费电子类公司的 CEO 都要到舞台上给公司、产品站台?
阳萌:也不是所有产品公司的老大,都天天往台前站的。在「产品品牌」和「CEO 个人品牌」之间,我还是希望做一个极致的产品品牌。
短期来看,在创新产品还没被大家充分看到和记住之前,靠我在外面不停讲,我觉得最多能撑两三年。超过三年,大家就会问:「东西呢?老在外面讲,又没东西出来,肯定是假的。」
过去三年,我每年都会出来,想帮公司吸引人才,但我希望明年开始就不是靠我了,而是靠那些真正足够创新、足够吸引人的产品。
Hardwire:在深圳硬件圈里,对安克还有这样一个印象:工资很高。你之前提到 2025 年公司有 800 人年收入超过了百万,我挺好奇这些员工主要来自哪些业务线?
阳萌:首先,2026 年年收入百万以上的员工预计将要突破 1000 人。他们不可能都是管理层,因为 6000 人的公司不可能有 1000 个管理层。
我们有个做算法的小伙子,我特别看过他的薪酬,应届硕士毕业大概 4-5 年,就拿到了百万年薪。但他并不是来自机器人算法这种「当红炸子鸡」品类。
所以安克的分配其实蛮平均的,所谓百万年薪并不只集中在某几个热门领域或者工种里。我们的理念是,消费电子一定要把大部分钱分给创造者,因为超额价值是他们创造的。
阳萌(右)和极客公园创始人 & CEO 张鹏(左)| 图片来源:极客公园
02
一场 3 年前的「盲注」
Hardwire:这是 Hardwire 第一次和 CEO 的面对面专访。我们希望不仅让大家更了解安克和阳萌,也听一听你们对行业的判断。过去一年智能硬件行业很热闹,如果让你用一个关键词来总结,你觉得是什么?
阳萌:从创投视角看,我会说这是一个新周期的开始。
如果你在行业里待得足够长,会发现一件很有意思的事:基本上每 5 年会有一轮特别热闹的周期。2011 年是移动互联网和电子商务,2016 年是物联网,2021 年是新消费和出海,然后到 2026 年就是 AI。有 AI 之后,大家觉得所有硬件都值得被重新做一遍。
Hardwire:你认同这个观点吗?
阳萌:技术层面上是认同的。但这一轮浪潮过去之后,到底有多少创业公司能长期活得很好,还是会遵循一定的统计规律。
Hardwire:那你认为什么是「AI 硬件」?做 AI 硬件有统一的方法论吗?
阳萌:自动驾驶汽车是一个很好的案例。它的「智能」被拆成三个模块:感知、规划、控制。你在这三个模块上做得更好,产出的结果就是这个产品变得更智能。我认为今天所有的硬件要「变得更智能」都应该是这个路径。
而 10 年前做物联网的时候,行业很多人曾经走过一条错误的路径,以为给产品加上一些可以通过手机远程调节的功能,就做出「智能硬件」了。但那些产品并不具备感知、规划、控制能力。以智能马桶为例,它连什么场景应该开盖、开一个还是两个盖都不能自主判断。
Hardwire:要做到这种「真正的智能」,产业基础够吗?
阳萌:硬件层面,过去十年激光雷达、TOF、各种毫米波雷达等传感器都快速成熟,所以硬件基础比十年前 ready 了很多。
但硬件基础上的软件,我觉得并没有那么快。每一个传感器都带来了大量数据,需要用更好的模型来处理,而不是以前那种写死的规则。这些东西背后都不是简单技术,而是复杂技术,需要很好的基础设施去支撑。所以这套东西真要做好,非常考验功夫。
Hardwire:安克是怎么解决这一系列问题的?
阳萌:我们首先确认了一个原则:一定要在端侧跑更大的模型。因为如果不跑更大的模型,就一定做不好很多感知的问题。
但在 AI 时代,随着模型激活参数的大幅提升,计算过程中会因为「搬运数据」导致功耗显著增加。对通电设备(如数据中心)来说,功耗高了解决散热就行;但在电池驱动的设备里,功耗一高就会直接影响续航,严重影响用户体验。
而我们在市场上找了一圈之后发现,现有的芯片都不能解决这个问题,所以我们觉得解决这个问题要从最底层的芯片开始解决。
Hardwire:过去硬件行业普遍会把芯片和人才、零部件视作「可采购」的产业基础,但你们的选择是从底层研发自己的芯片。有质疑的声音吗?
阳萌:有很多质疑。但这条路走到这儿,面前就是这堵墙,所以我今天就得要跨过去,不然的话就永远停在这儿了。
Hardwire:现在搭载这款「存算一体」芯片的两款消噪耳机已经上市了。从起心动念,到产品落地,一共用了多久?
阳萌:我们 2023 年上半年就开始找,到 8 月和合作伙伴知存科技签合同,一共用了差不多 3 年时间。
Hardwire:这个过程里最大的挑战是什么?
阳萌:难就难在,它不止「换一块芯片」这么简单。你要动的,是计算机行业延用近 80 年的「祖宗家法」,一整套互相支撑的体系。
计算机领域过去几十年解决问题的根本「分治法」,是将一个大问题层层拆解为小问题,逐一求解后再行组装。而如何拆解、怎样计算都需要人为定义,最终产生了上百万行的代码规则。落在芯片层面,由于每次计算真正激活的代码只是一小段,所以从经济性考量,不需要把所有代码都储存在昂贵的计算单元里,于是就产生了「存算分离」的硬件架构。但 AI 到来之后,解题方法从「分治法」的层层拆解演化为了上百亿参数的端到端黑盒模型。原本最经济的设计,在大模型时代反而变成了最耗能的那个。
阳萌讲解芯片架构背后的变迁 | 图片来源:Anker
Hardwire:当时外界反对的声音多吗?
阳萌:在 2023 年,这是一个极度非共识的判断。因为硬件架构一变,上面一整层已经成熟、被所有人信任的体系也就同时塌了,都得跟着重做。
我第一次公开说我们要做存算一体芯片之后,网上有一个评价,说这件事 20 年内都不会有成功的商业案例。
Hardwire: 现在这套新的架构已经落到了消噪耳机这款产品上,普通用户能感知什么变化?
阳萌: 落到体感上,最直接的是感知。比如打电话——你日常在车上、地铁里、甚至演唱会现场通话,也能把你的声音收得清清楚楚。
Hardwire: 这一点我亲测过。五一的时候,我在一个 62000 人的足球比赛现场用它拍了一支视频。现场都是球迷的声音,但视频里只有我的声音,确实挺神奇的。
阳萌: 这只是感知能力提升的一个例子,后面还有很多场景。
03
做与不做的取舍
Hardwire:那耳机之外的其他品类呢?这套存算一体的思路,可以快速复制到其他需要提高感知能力并控制功耗的硬件产品上吗?例如智能眼镜。
阳萌:这套思路肯定有帮助,但我觉得很难「快速复制」。耳机处理的是音频,眼镜处理的是图像和视频,每一个品类的数据、训练、部署闭环,以及需要的芯片都不一样,不是那么快就可以跑通的。
Hardwire:你的意思是,存算一体还没有完全成为行业共识?
阳萌:在今天肯定还不是共识。举个例子:在 ISP(Image Signal Processor,图像信号处理器)领域,你今天有见到谁在做端到端的神经网络 ISP 吗?
从体感上,今天大家用手机拍照的时候已经几乎不需要手动调参数了,但背后的计算运算依然依靠「分治法」:先调白平衡,再做边缘锐化,拆分成十几个步骤、几十个模块计算。
Hardwire:其他品类想复制这套架构,也要再花 2-3 年时间吗?
阳萌:我觉得对芯片来说,从设计到流片、回片、上线,两年都算极快的。
Hardwire:如果这样推算,从非共识变成共识,再到落地成用户可感知的产品,应该需要 3-5 年。但既然你们有了存算一体的经验,会考虑做智能眼镜吗?
阳萌: 眼镜我们是真没做。这个市场里,互联网大厂、手机大厂、大模型大公司,这三拨人都觉得自己一定要把这事儿做成才可以。因为大家认定智能眼镜本质上是人机交互的入口,最优的资源全压在这里。我们不应该去凑这个热闹。
Hardwire:我觉得眼镜其实代表了这一轮创业里一个有趣的现象。有些赛道还没正式开始做,就已经「卷成麻花」了。一年前的 AI 陪伴好像也是这样——一度大家都觉得很火,后面又没什么声音了。
阳萌:我觉得这种现象一直在发生。即使在投资最差的 2023、2024 年,也有人在做这些事情,只不过没有今天这么显眼。它不是一个纯粹的技术逻辑——因为经济周期和技术周期并不严格吻合。一直有人在做,但今天这个点上,因为大模型的出现,所有人都觉得「应该这样」,钱和注意力一投过来,大家好像突然觉得「很多」。
Hardwire:那陪伴这个方向,你自己怎么判断?
阳萌: 其实我们很早就在看,也投过一家创业公司。陪伴的价值是很清楚的:无论是语音的陪伴,还是带一定动作的陪伴,技术在不停进步,效果也越来越好。但现在看起来,它还没跨越「创新的鸿沟」——从少数尝鲜的用户,跨越到早期大众。而且陪伴本身就是个非常非常复杂的问题,它不是说今天模型一提升,这件事就突然像魔术一样被做好了。
Hardwire: 所以陪伴的难点,其实不在模型本身?
阳萌: 模型的提升当然有帮助,但它不是那个能「一招解决」的东西,最后还是回到客户价值。你能不能为目标人群真正创造一个独特的、能跨过那道鸿沟的价值,这才是难的地方。
Hardwire:那硬件大厂之间的竞争呢?今天似乎每一家大厂都在疯狂扩张。
阳萌:我觉得说「疯狂扩张」好像也没有。
Hardwire:少部分很「疯狂」。但基本都在横向扩张,找第二曲线。为什么这个时间点大家都在做这件事?
阳萌:我没有那么了解其他人具体决策的逻辑,可以分享一个安克之前的案例。
2020 到 2022 年,安克经历过一个特别快的扩张阶段,那时候我们做了电动自行车,也做了各种各样的电器品类。背后是我们当时相信的一套打法:流程型组织。简单说,就是把「怎么做成一个产品」沉淀成一套标准流程,再扩出很多 PDT(Product Development Team,跨功能部门团队)套着这套流程跑。这些团队背景都不错,流程也是成熟的,照理说应该能把新品类一个个做好。
Hardwire:问题出在哪里?
阳萌:最后我们发现,背景好的团队 + 一套成熟的流程,如果碰上一个底子很薄的品类,照样做不成。除了人和流程,其实还有很多限制条件。
那次之后我们总结出一句话:要做「三缺一」的品类,不要做「一缺三」的品类。「三缺一」,就是一个品类的四个成功要素里,我们已经具备了三个,只需要再补一个就能突破它;「一缺三」则相反——四个里我可能只有一个,那就很难了。
Hardwire:所以你们现在的原则,就是在「浅海」里(阳萌总结的品类战略,在每年 500 亿美元规模以下的品类里做大量的中小品类)里进一步挑选「三缺一」的品类吗?
阳萌:在智能手机这样的超级品类里,牌桌上的每个巨头口袋里都是上千亿的本钱。你今天揣着 50 个亿想挤进去,连跟注的资格都没有,只能一把全压然后听天由命,赢面其实极低。而我们做的这些不大的市场是另一张牌桌——桌上的人口袋里也就几个亿、十几个亿,入场的门槛低得多,这种桌子你才坐得下来、玩得长久。但坐得下来,不代表就一定赢。
Hardwire:以前你说听到「浅海战略」,很多人第一反应是这个赛道里竞争激烈。
阳萌:这里可能容易有一个误解,「浅」不等于「快」。我以前举过宝洁的例子,可能让大家以为这种不大的市场就很轻松、很快。但本质上,消费电子里一个品类「浅」,只意味着它的市场规模不大,不代表这件事做起来就容易、就快。
举两个例子:第一,消费级 UV 打印机这个品类,过去根本就不存在;第二,在储能这个本身热闹的品类,我们也开创了一个「DIY 安装」(我们也叫阳台储能)的家庭细分市场。这件事听起来「浅」——不就是给阳台配块电池吗——但它要啃法规、重新定义安装方式,所以一点都不快。结果是,德国过去三年装了 100 万套以上这种 DIY 系统。
eufyMake E1 及成品案例展示 | 图片来源:Anker
04
不必过分焦虑 AI 浪潮的冲击
Hardwire:你之前说过,和媒体沟通的目标之一是希望招揽人才加入安克。过去一年里,你印象最深的一次招人经历是什么?
阳萌:我自己花了不少时间在招人上,所以还真没有一个「最」。但我可以分享一个印象很深的经历。
在最大的那些「厂」里,有些人才每隔一段时间会出来看看机会。有位同学一见面就坦诚地告诉我:「我其实也没想要出来,主要是希望在沟通中判断一下自己的价值,再看看行业情况」。然后这位同学沟通完之后,就毅然决然地决定加入安克了。
要知道,「毅然决然」这件事很难。因为在大厂里,这样的人才已经是在某个领域的一号位了,他还愿意到一个小很多的公司来做一号位——这种情况下,我能感觉到安克肯定是在某些地方打动了他。
Hardwire:那你花在找人上的精力应该不少?
阳萌:如果说「找」就是到处挖人,那我做得确实不多。但花在「说服」上的时间,的确是比较多的。
Hardwire:你是一个归纳总结能力很强的人,但 MBTI 又是一个 P 人。我很好奇你沟通的时候是有一套固定的流程,还是偏向随机应变?
阳萌:我们的价值观,本质上就是一套行为的框架。你肯定是在这个框架里聊,但你不会严格地一条、两条、三条往下问,而是希望聊天的过程能覆盖这个框架的相当一部分。
Hardwire:判断技术人才的时候,也是同一套标准吗?
阳萌:无论是技术人才、商业人才,哪怕是行政人才,都一样。我们讲价值观,通常说是「两个轮子加底下一个基础」——怎么想事情、怎么做事情,以及最底下如何自处。如果你想事情很清楚、做事情很到位,最后又能长期跟自己自处好、有持续的动力和输出,这就是一个人能长期保持很好状态的样子。
Hardwire:所以你更在意底层的东西,反而没那么在意他来自哪个领域,哪家公司?
阳萌:对。无论是「厂牌」还是「学校牌」,都不能代表一个人今天的价值观。只是说,不同公司出来的人,比例可能有高低——比如某家公司出来的人,第一性强的比例会高一些。但不管权重多少,最后都是一个个单独的个体。
Hardwire:那如果今天同时来了华为、大疆、蔚小理、大模型公司的人来面试,按照「和安克的匹配度」排序,你的顺序是什么?
阳萌: 我不会把「不同的组织」放在排序的最前面。因为这么排本身就不是第一性的。举个例子,我自己是北大毕业,我能说北大所有同学第一性都特别强、求极致都特别好、都能长期主义吗?
Hardwire:见你之前我先做了个小背调。有一种对安克团队的评价是,安克高管团队提炼总结方法论的能力非常强,但似乎这些能力又都在 AI 的射程范围里。你怎么看 AI 对组织的冲击?现在很多人都担心 AI 会导致裁员。
阳萌:硅谷近期最激进的一种说法是:公司是一个巨大的「公司世界模型」,由这个模型来决定各项工作怎么做,不需要中层管理了。
我的看法是:首先,今天的 AI 是 context bounded 的(受上下文长度限制)——context 长度决定了你能解决多复杂的问题。而我们一个硬件项目的 context,已经远远超过今天模型能处理的复杂度了。更何况我们是很多硬件、很多项目在并行跑。所以今天的模型,根本没办法有效地把握、抓住全公司所有问题的关键。
其次,公司不是一个「固定的样子」,它是在「成长」的。我们今天要吸引什么样的人、说服他们加入、设计组织架构高效协同,目标调整之后还要调整对应的架构……所有这些事情,哪怕未来的模型能力变得很 capable、能给人提供建议了,我觉得也依然需要具体的人来执行和传达。
Hardwire:安克公司的高管听完这段,对 AI 的焦虑应该能缓解一点。
阳萌:这件事很好玩。我每次去校招都会讲:你们为什么要来安克,而不去那些互联网大厂?我们来分析一下底层原理。一个士兵成熟的速度,最相关的指标是「打过仗的次数」。刚上战场的士兵懵懵懂懂;熬过三五场,开始冷静;打个 10 场、20 场,已经很有经验;打到三五十场,就很老到了。
互联网的一次「战斗」,一个功能从策划、开发、上线到运营,大概 3-6 个月。从 24 岁硕士毕业到 30 岁,已经成为了打过二三十场战役的「老兵」。因为作战周期短,所以成熟速度快。
Hardwire:但老兵后面还有源源不断的新兵。
阳萌:对。而且关键在于——60 场战斗经验和 30 场战斗经验,可能差别没那么大了;但跟只打过 3 场的相比,差别巨大。也就是说,经验的红利很快就吃到头了。所以这是为什么互联网的同学起得很快、达到巅峰的速度很快,但后面也会有挑战。
反过来讲硬件正相反。我们「打一场仗」的周期很长,可能 6 到 9 个月才一场仗,芯片还会更慢。所以尽管硬件看上去没那么 sexy、收入涨得没那么快——而且说实话,我们的硬件产品经理、研发工程师收入其实也涨得很快——但他们的花期会更长。
Hardwire:以前我们经常对自己说「媒体越老越吃香」。按你刚才这套逻辑,媒体一年要写多少稿子打多少场仗啊……
阳萌:花期早就过了(笑)。
05
资本热潮中的投资人、创业者、稀缺人才
Hardwire:这轮新周期里,创业者似乎也更容易拿到更高的起手估值?
阳萌:是的。今年是一个新的投资周期的开始,VC 变得很愿意投钱。同样一个项目,可能去年这个时候没有人投,现在却被抢疯了。
Hardwire:那对于顶级人才来说,是否有这样一种选择路径:先去最热的赛道里创业或者当合伙人,把身价「抬高」。即便几年后再回来加入大厂,也能获得比直接加入拿到更好的收益?
阳萌:创业是一个长期的投入,不是短期「爽」一下。创业者要面临的不光是一个个困难,而且要面临一条持续自我成长、自己迭代和改变的道路。除非你哪天不想做了,否则你会一直面对这些。
而且,不是愿意付出一切,就一定有好结果。孔子有一句话叫「君子慎独」——人在独处的时候,各种坏毛病都会暴露出来。而在一家创业公司里,CEO 通常就是那个「独夫」。所以你会看到他各种各样的坏毛病冒出来:有些影响结果,有些影响生死。
所以我想说的是,创业的人需要理解,这是一段长期的、要持续承受挑战的孤独,而不只是短期看起来很有趣的事。
Hardwire:是不是因为投资人看到了某种机会,例如退出、变现变得更容易,所以才有这轮热潮?
阳萌:其实退出变得容易,应该是投资变热的「开始」,而不是结果。当二级市场上有几个很好的标的时候,一级市场就会变得很热。大家会觉得,我今天投进去,将来就能这样卖出去。
巴菲特有一句很经典的话:股价短期是投票箱,长期是称重器——短期的高低被人的预期左右,长期才由公司真实的利润和成长性决定。所以今天投资火不火,影响因素是顶上的预期,而不是底下实实在在的结果。
Hardwire:就像买刮刮乐,都希望自己当场中大奖。
阳萌:如果你投的公司今天就能在二级市场上市,当然可以;可二级市场的热,能热三四年吗?大家其实都在谈,OpenAI、Anthropic、SpaceX 这三家如果上市会意味着什么。有一种观点是,这可能意味着股市会到一个阶段性的顶点。而二级市场一旦发生变化,一级市场也会很快反应过来。
Hardwire:那你自己会投资吗?安克作为一个多品类的公司,不断有新产品和新事业部出现,有没有人说过,比起 CEO 你更像一个投资人?
阳萌:比起「投资人」,我更愿意说我是一个「实施顾问」。我给大家提供解决问题的思路,然后陪大家去执行,只是不具体下场做而已。
你看今天这些抽象出来的方法论,其实都是我们从一些业务里把它抽象出来,再向更多业务去推广、复制。只不过我没有把复制扩展到公司的边界之外而已。所以我绝不是个投资人。你去问内部跟我讨论业务的同学,他们会给你完全不同的答案。
Hardwire: 但安克之前还是有过一些投资经历的,听你的意思,现在对外的投资变少了?
阳萌:一个客观原因是我们确实没花很多时间在上面。而且现在投资越来越热,外面的投资人也普遍能给出很多钱。
Hardwire:你不太喜欢凑热闹?
阳萌:非常不喜欢凑热闹。
Hardwire:那对于你来说,识别和判断一个创业者和一个招进公司的人才,逻辑上有什么不同吗?
阳萌:对创业者来说,还是回到「君子慎独」。一个再强势的投资人,也很难影响 CEO 是个「独夫」这个现实。CEO 就是创业公司里做决策的那个人。所以投资人的边界在于,永远只能「说说」,没法真实地去影响。但在安克这样的公司里做新品类就不同,比如我们推 AI 的时候,并不是你想不用就可以不用的,它是一个带有强制属性的「咨询公司」。
Hardwire:招人的时候,你会看有多少场「战斗经验」。投人的时候,你看什么?
阳萌:其实招人和投人是一样的,把事情做成的底层原理是相通的。对人来讲,就是你能不能持续地有第一性的思考、抓住关键问题;能不能持续地、极致地把它做出来;以及这个过程里会有很多困难、很多诱惑,你能不能持续地长期主义,自我觉察、自我进化。
Hardwire:看起来你没那么担心错过投资机会,也决定不进入眼镜这样的超级赛道。那在这一轮新周期里,你最担心的是什么?
阳萌: 找不到足够多的人才。对安克来讲,这家公司如果不成功,最大的原因应该就是人才不够。
Hardwire:人才从哪里来?你们会内部轮岗吗?
阳萌:已有业务的同学,我们确实会调到新业务上去;内部也会有同学成长起来,去接已有的业务。长期看,比如放到 5 年、10 年,我相信内部成长、补上来的速度一定能接上;但短期如果不持续吸引最好的人才,还是会担心青黄不接。
这里还有一个更底层的原因。如果按 1、3、5、7 系来分,我们以前做的是 5 系产品,是「优质产品」但不是「极致产品」。但是从 2023 年开始,我们开始做「极致产品」了,例如搭载存算一体芯片的消噪耳机,我们的目标是对标 AirPods 的性能。
Hardwire:的确需要不同的力量和「7 系」产品的经验。
阳萌:不是说团队组成要 100% 不同,但团队文化是要 100% 改变的。这就是为什么过去几年我们一直在外面吸引人才——如果只做「5 系」、不调整定位,内部成长可能也够了;但今天安克的定位是升级,就自然需要更极致的人才加入。我反复讲第一性、求极致、长期主义,其实就是希望吸引这样的人才。人才来了之后,公司的样子就变了;样子变过来之后,后面就能持续地从内部生长。
安克消噪耳机,被吉尼斯认证为「全球通话最清晰的无线蓝牙耳机」| 图片来源:Anker
06
超级品类与终局推演
Hardwire: 未来 3-5 年,你最看好的硬件品类是什么?
阳萌: 从市场规模最大的角度,我觉得是人形机器人和智能眼镜。这两个品类,我觉得三五年的时间应该有机会爆发。
Hardwire:但它们现在还都很小,眼镜还没有到「浅海战略」的 500 亿美元规模。
阳萌:也许不是 3-5 年内就可以达到,但从第一性推理,它一定会变成终局里的超级品类。
手机目前是 5000 亿美元量级,PC 是 2000 亿美元,平板大概 600 亿。你觉得智能眼镜爆发之后,会靠近哪一个?
Hardwire:按照终局论,大概率会超过 PC。
阳萌:对,它会在第一名和第二名之间,成为将来的第二名。那就意味着应该是一个 2000 亿美元往上的市场。这一定是个超级品类。
Hardwire:但你前面说了,安克没有在做智能眼镜。你们就这么放弃未来的超级品类了吗?何况它今天还在「浅海」里。
阳萌:我并不觉得一定要自己 100% 把这个事做出来。其实华为内部做出手机,也是一个相对独立的组织做出来的。
Hardwire:还有什么不一样的方式吗?
阳萌:今天我们可以看到两种模式,一种叫「三加一」,一种是「一加三」。
前者代表一个做大量中小品类的公司,再增加一个超级品类。华为是很好的例子,它早年的运营商业务,是由大量小品类组成的;而后来把手机做成了超级品类。但华为是全世界范围内极少数能做成「三加一」的。
更多的案例是「一加三」——先做成一个超级品类,再出去做很多中小品类。比如阿里,先做好了淘宝这个巨大的品类,再做很多很多小品类;小米也是,先做手机,再做生态链。
Hardwire: 我们一开始提到,自动驾驶的感知、规划、控制范式给这一代智能硬件带来了启发以及产业硬件、人才的溢出效应。那你觉得未来智能硬件和具身智能行业之间会产生怎样的关联?是具身行业因为资源密集先跑通世界模型,还是智能硬件通过传感器拿到更多数据,反哺具身行业?
阳萌:我觉得今天第三方传感器的数据,对机器人的帮助比较有限。机器人还是需要大量高质量、高精度采集的数据。在数据采集这件事上,背后的底层能力可能有共性,但就采集到的数据本身而言,我觉得两边相互的帮助不大。
Hardwire:那假设世界模型先做成了,它的能力可以变成哪些对硬件行业可复用的产业资源?
阳萌:假设世界模型今天成了,它对人形、对其他机器人形态会有一些帮助;但我觉得它对耳机可能没什么帮助。对眼镜,可能有一点——但大家的限制条件不一样,眼镜毕竟还是在一个电池、重量等物理条件极度受限的条件下运行的设备。
其实今天可以看见,从上往下有很多有意义的产品。人形机器人肯定是一个;再往下,是我们说的「本体」——移动的、可交互的本体,无论是狗的形态,还是其他宠物的形态,这些都成立。所以未来会有很多东西冒出来。
Hardwire:你一开始提到过去一年的关键词是「新周期」,未来 1-3 年会发生什么变化?
阳萌:你会真切地看见 AI,或者说我们一直在讲的「感知、规划、控制」,会真的跑到硬件上去,越来越多的硬件会带上这三种能力。3 年可能是小共识,5 年就是广泛共识。
Hardwire:那有什么东西是不会变的?
阳萌:回到底层,公司永远需要为客户交付价值。而交付价值,需要经历一组实实在在的过程:用户洞察、预研技术、组合成产品、做好品质、做好生产、在全球做好服务。
哪怕未来这个世界全部由 AI 来控制,请问这里面哪一个价值点可以消失?它不是「砰」地一下,一个特别好的产品就出来了、客户就满意了。这些具体的价值和动作,构成的就是一条不会变的价值创造序列。
这个价值序列上的每一段都由一个团队在交付,用 AI 帮这个团队提高内部效率,以及提高跟其他团队之间的协作效率,就是 AI 转型。
Hardwire:安克具体怎么推动这个 AI 转型呢?
阳萌:我们集中了一百多位同学,在打造数据、智能体和 AI 中台,以及沉淀各个职能的 AI 智能体。目前平台日活超过员工数的 90%,公司内周一到周五每天消耗超过两千亿 token,一半以上是在非编程领域,超过一半是中高阶模型 Token。
交流下来我们在 AI 转型上肯定是领先的,也欢迎想跟 AI 一起飞速进化的同学们加入我们一起成长。
Hardwire 希望和在智能硬件领域里的每一个创新者建立起真实的连接。无论你对这个行业是有兴趣、有观察,还是有亲身的从业经验,都欢迎来找我们聊聊。
识别下方图片二维码,添加 GeekPark GO 微信,发送关键词【 Hardwire】,小助手邀你加入 Hardwire 交流群~👇
*头图来源:Anker
极客一问
你认为未来真正能颠覆用户体验的
AI 硬件,会出现在哪个品类?
Zilliz 2026-06-11 18:11 浙江
Cohere 开源其首款面向开发者的代码模型 North Mini Code,该模型采用 30B 总参数、3B 激活参数的 MoE 架构,专为智能体软件工程任务设计,以 Apache 2.0 协议发布。
Zilliz Workshop是一项由Zilliz 资深技术专家发起的社区动手活动,旨在通过各种各类动手实验,让开发者深度了解向量数据库,并借此开发一系列的AI应用。以做代学,在实践中掌握向量数据库的深度能力进阶。
活动主题:Agent 时代 Vibe Coding:从 Milvus 3.0 解读到多模态检索实战
活动亮点:
介绍 Milvus 3.0 核心功能升级
2 小时,实现图片 +文本+视频混合检索
0代码编写,全程Vibe Coding对话式开发
现场解读On-Demand节省90%成本背后的性能优化
活动时间:2026-06-27(周六)下午
活动地点:北京市海淀区中关村创业大街12号楼5层路演厅
形式: 前半场主题分享 + 后半场每人动手实操(自带笔记本,需联网 + 电源)
协办方/联合主办:中关村科学城公司、中关村创业大街
活动详情与报名二维码详见以下海报
点击“阅读原文”查看原文章
👇点击关注ModelScope公众号获取
更多技术信息~
魔搭ModelScope社区 2026-06-11 18:11 浙江
Cohere开源首个面向开发者的代码模型North Mini Code,采用30B总参数、3B激活参数的MoE架构,专为智能体软件工程任务设计。该模型以Apache 2.0协议发布,在多项基准测试中表现优异,支持多种智能体框架。
01
引言
Cohere 开源了 North Mini Code,一个总参数 30B、激活参数仅 3B 的混合专家(MoE)编程模型,以 Apache 2.0 许可证发布。这是 Cohere 全新模型家族的首个模型,专为智能体软件工程(agentic coding)设计,覆盖复杂软件工程工作流、基于终端的智能体任务和高质量代码生成。研究团队采用多脚手架训练以保证模型跨智能体框架(harness)的稳健性,使其可作为 OpenCode 等代码智能体的可靠基础;BF16 与 FP8 量化权重均已放出。
开源地址:
BF16: https://modelscope.cn/models/CohereLabs/North-Mini-Code-1.0
FP8: https://modelscope.cn/models/CohereLabs/North-Mini-Code-1.0-fp8
02
技术架构
North Mini Code 是基于 Transformer 的仅解码器稀疏 MoE 模型。注意力层以 3:1 比例交替使用带 RoPE 的滑动窗口注意力和不带位置编码的全局注意力 [1];前馈层为含 128 个专家、每 token 激活 8 个的 MoE 块,专家采用 SwiGLU 激活,路由器在 top-k 选择前对 logits 施加 sigmoid;稀疏层之前另设一个稠密层。
图: North Mini Code 是一个混合专家 Transformer 解码器,交替使用滑动窗口自注意力和全局自注意力。
03
面向编程卓越性的后训练
后训练分两阶段级联 SFT,再接基于可验证奖励的强化学习(RLVR),全程聚焦智能体编程。第一阶段在编程、推理、指令遵循等广泛领域训练,代码占可训练 token 的 70%(含 43% 智能体工具使用、27% 单轮竞赛或科学编程);第二阶段仅用 4.5B token 的智能体与推理数据,代码占比提升至 61%,且所有工具调用与补全均验证可执行、正确。两阶段上下文长度分别为 64K 和 128K,采用"从长到更长"的级联策略:先在较短数据上建立基线,再仅用高质量样本做长上下文训练——若直接混合长短数据,初期的 20B 非代码 token 会压过后期 1.5B 高质量代码 token,反而损害性能。数据来自容器化智能体编程环境,覆盖约 5000 个仓库的 7 万多个可验证任务,并与 SWE-Bench、SWE-Bench-Pro 的来源去重以防泄漏。SFT 仅作为 RLVR 的引导,经样本级过滤剔除无效工具调用、特殊 token 错误等异常后,最终 SFT 模型在 SWE-Bench Verified 上达到 80.2% pass@10,在 Terminal-Bench v2 上达到 55.1% pass@10。
图: 后训练流程由两个阶段的监督微调(SFT)以及一个面向软件工程与终端任务、采用可验证奖励强化学习(RLVR)的阶段组成。
04
跨框架的稳健性
真实开发环境的智能体框架(harness)差异不止于提示,更在于工具使用模态:SWE-Agent 提供 bash、str_replace_editor、submit 等专用命令的丰富 CLI;mini-SWE-agent 仅有单一 bash 工具和原始 stdout;OpenCode 则用细粒度类型化工具并返回结构化 JSON。研究团队在第二阶段 SFT 中仅加入 6% 的基准框架数据(所选 SWE-Agent 占 50%),即在 OpenCode 评估上获得 10% 增益,同时不损害 SWE-Bench Verified 上 SWE-Agent 的表现;模型在 mini-SWE-Agent 上的 61.0% pass@1 几乎是跨框架迁移"免费"获得的,说明工具能力重叠的框架可正向迁移、技能互补而非冲突。针对 Terminal-Bench 采用的纯文本 Terminus 2 框架,仅加入不到 20% 的纯文本数据即可泛化,但需在各框架中引入足够变化(类似数据增强),迫使模型建立指令与行为的真实关联而非复述模板。
图: 为驱动多种智能体编程框架,North Mini Code 在第二阶段 SFT 中接触了多种编程框架。
05
面向智能体编程的异步强化学习
编程智能体的 rollout 长且长度差异极大,最慢轨迹常是中位数的十倍。为避免同步训练空等长尾,研究团队将采样与学习解耦:训练器与持续产出 rollout 的 vLLM 边车并行,每 K=4 步同步一次权重,残余的轻微离策略在损失层面校正;并用窗口化 FIFO 队列在队首按完成顺序排空拖尾、其余保持输入顺序,在几乎不损失稳定性的前提下恢复吞吐。训练目标为 CISPO——带 token 级重要性采样校正的对数似然目标,重要性权重乘以对数似然而非概率比,并以更强正则化增强 RLOO,损失在 token 级聚合,使长轨迹的信用分配信号不被降权。整个 RL 为单次多环境在线训练,同时覆盖终端任务(ReAct + 基于 Harbor Tmux 的终端工具)与软件工程任务(SWE-agent 框架):每批 512 个 rollout、每 prompt 采样 8 个、共享 128K 上下文,按任务难度分配步数预算;环境提供预构建 Docker 镜像、自然语言指令和单元测试,采用二元奖励,无效工具调用记 0 分,使非法或格式错误的工具调用在最初几步内骤降。相比 SFT 初始模型,RLVR 使 Terminal-Bench v2 的 pass@1 提升 7.9%、SWE-Bench 提升 3.0%(均为绝对值),且联合训练优于分别训练、对分布外任务泛化更好,并产出更短的轨迹和更少的循环、失败调用。
图: 多环境 RL 训练运行提升了模型在 SWE-Bench Verified 和 Terminal-Bench v2 等基准上的表现。左侧展示了 RLVR 训练过程中的学习曲线。
06
内部人工评估基准
作为对现有编程基准的补充,还开发了内部基准套件,用于在与人工标注者进行的成对评估中衡量模型在分布外问题上的表现。与其他基准设置一致,评估了通过 Harbor 集成在 OpenCode 中的各代模型。为理解模型表现,我们在四个不同的功能维度上进行基准测试:
代码解释(Code Explanation): 要求模型在 README 文件中或直接向用户解释给定代码仓库的特定技术方面。
代码编辑(Code Editing): 要求模型基于现有代码库实现某项功能。
数据可视化(Data Visualization): 给定数据样本,要求模型使用特定框架创建特定的可视化;不提供额外代码。
从零实现(Implementation from Scratch): 仅给定设计规范和需使用的软件包,要求模型从零创建一个项目,主要聚焦于前端设计。
评估者会获得基于评分标准(rubric)的打分问题,以帮助他们评估各项响应标准,并在给出两个模型轨迹之间的最终偏好评级之前,先对各次尝试单独评分。在 85 个样本上,RLVR 后的最终模型对仅 SFT 版本的总体胜率为 66.1%,其中代码编辑任务的提升最为明显。
图: 在 85 个样本上,将 RLVR 后的最终 North Mini Code 检查点与仅经过 SFT 的检查点进行对比的成对偏好结果。
07
模型推理
使用transformers推理
环境安装
pip install transformers模型下载
modelscope download --model CohereLabs/North-Mini-Code-1.0 --local_dir CohereLabs/North-Mini-Code-1.0推理脚本:建议在生成时使用以下采样参数:temperature=1.0,top_p=0.95
from transformers import AutoTokenizer, AutoModelForCausalLMmodel_id = "CohereLabs/North-Mini-Code-1.0"tokenizer = AutoTokenizer.from_pretrained(model_id)model = AutoModelForCausalLM.from_pretrained(model_id)prompt = "Write a python program to check if a string is a palindrome or not."# Format message with the North-Mini-Code-1.0 chat templatemessages = [{"role": "user", "content": prompt}]input_ids = tokenizer.apply_chat_template(messages,tokenize=True,add_generation_prompt=True,return_tensors="pt",)gen_tokens = model.generate(**input_ids,max_new_tokens=1024,do_sample=True,temperature=1.0,top_p=0.95)gen_text = tokenizer.decode(gen_tokens[0])print(gen_text)
也可以通过transformers 的 pipeline 抽象接口使用该模型:
from modelscope import pipelineimport torchmodel_id = "CohereLabs/North-Mini-Code-1.0"prompt = """Given a list of unique words each of size k and an n sized word, w, where n is a multiple of k,Write a program in python to determine the number of unique combinations of words in the list that can be concatenated to form an anagram of the word w."""pipe = pipeline("text-generation",model=model_id,torch_dtype="auto",device_map="auto",)messages = [{"role": "user", "content": f"{prompt}"},]text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,)outputs = pipe(messages,max_new_tokens=1024,do_sample=True,temperature=1.0,top_p=0.95)print(outputs[0]["generated_text"][-1])
通过vllm使用
你也可以在 vLLM 中运行该模型。在新版本发布之前,请对 North Mini Code 使用 vLLM 的 main 分支,同时准确的响应解析还需要安装 Cohere 的 melody 库。
uv pip install "git+https://github.com/vllm-project/vllm.git"uv pip install cohere_melody>=0.9.0
随后可以通过以下命令启动 vLLM 服务器:
VLLM_USE_MODELSCOPE=true vllm serve CohereLabs/North-Mini-Code-1.0 \-tp 2 \--max-model-len 320000 \--tool-call-parser cohere_command4 \--reasoning-parser cohere_command4 \--enable-auto-tool-choice
在 OpenCode 中使用本地部署的 North Mini Code:
在新版本发布之前,请使用 OpenCode 的 main 分支。
# Example commands to install on linuxgit clone https://github.com/anomalyco/opencode.gitcd opencode# Install Buncurl -fsSL https://bun.sh/install | bashexport BUN_INSTALL="$HOME/.bun"export PATH="$BUN_INSTALL/bin:$PATH"# node-gyp was needed by a dependencybun add -g node-gyp# Install dependenciesbun install# Build CLIbun run --cwd packages/opencode build/usr/bin/install -m 755 \./opencode/packages/opencode/dist/opencode-linux-x64/bin/opencode \/root/.local/bin/opencode
点击下方“阅读原文”获取模型链接
👇点击关注ModelScope公众号获取
更多技术信息~
OpenAI's GPT-5.5, GPT-5.4, and Codex are now generally available on Amazon Bedrock, one month after OpenAI revised its exclusive Azure arrangement. Pricing matches OpenAI's direct rates with usage counting toward AWS commitments. Codex shifts to pay-per-token billing with no seat fees. GPT-5.4 is the first OpenAI model available in AWS GovCloud.
By Steef-Jan Wiggers📭 此日期无开源工具分类的数据。
Imbad0202/academic-research-skills
Academic Research Skills for Claude Code: research → write → review → revise → finalize
Academic Research Skills 是一个专为学术研究者设计的AI协作技能套件,运行于Claude Code平台。它通过结构化流程,将AI作为副驾驶来处理文献检索、引用格式化、数据验证和逻辑一致性检查等机械性工作,旨在让研究者专注于定义研究问题、选择方法、解释数据和原创性写作等核心智力任务。项目强调人机协作(Human-in-the-loop),而非全自动AI研究,并内置了针对AI幻觉、思维锁定等失败模式的完整性检查机制。
- 结构化研究流水线 可扩展性
提供一个10阶段的学术研究编排流水线(从研究到出版),包含自适应检查点、完整性验证(Stage 2.5/4.5)、双阶段同行评审和协作质量评估。每个阶段都需要用户确认,并强制执行不可跳过的完整性检查门。 - 多代理协作系统 可扩展性
每个核心技能(深度研究、论文写作、评审)由多个专用AI代理协同完成,例如13个代理组成的研究团队、12个代理的论文写作管线、7个代理的同行评审小组(包括魔鬼代言人)。代理间职责清晰,支持Socratic引导、PRISMA系统综述等多种工作模式。 - 反幻觉与完整性验证 安全
集成了针对7类AI研究失败模式的检查清单、基于Semantic Scholar API的引用验证、对抗记忆污染的抗泄漏协议、以及交叉模型验证(可选)。完整性报告会详细列出已识别的伪造引用和统计错误。 - 元数据与契约控制 可观测性
为每个技能定义了`data_access_level`(数据访问级别)和`task_type`(任务类型)元数据,并通过CI脚本强制检查。引入了生成器-评估器合约(Schema 13.1)和审查员冲刺合约(Schema 13),以规范和约束AI在复杂交互阶段的行为。 - 人机协作深度度量 可观测性
通过可选的协作深度观察者(Collaboration Depth Observer)对用户-AI协作质量进行4维度评分(委托强度、认知警惕性等),基于教育心理学模型。该指标仅为建议性,不阻塞流程。
主要语言:Python(用于脚本、适配器和CI检查);核心运行时:Claude Code CLI / IDE 插件;文档生成:Pandoc(可选,用于DOCX)、tectonic(可选,用于PDF)、LaTeX;持续集成:GitHub Actions;参考API:Semantic Scholar API;许可证:CC-BY-NC 4.0。
- 系统性文献综述与元分析 (个人/小型团队)
自动化执行PRISMA流程、文献筛选、引用验证和数据提取,大幅提升综述效率并减少人为遗漏。 - 学术论文撰写与多轮修订 (个人/小型团队)
通过写作、评审、修改的闭环流水线,利用AI进行风格校准、质量检查、引用转换和回应审稿人意见,加速论文产出。 - 研究方法论训练与质量控制 (所有规模)
通过Socratic导师模式引导研究设计,并利用内置的完整性检查机制,帮助研究者(尤其是初学者)学习避免常见方法论陷阱。 - 同行评审准备与模拟 (个人/小型团队)
在提交前使用多代理评审系统(包括魔鬼代言人视角)对自己的论文进行高强度、结构化的模拟评审,提前发现弱点。 - 评估AI辅助研究的质量与协作深度 (所有规模)
为研究机构或项目团队提供客观的度量工具,用于评估和改进人机协作模式,确保AI工具增强而非替代研究者的核心工作。
- 方法论:明确反对全自动AI研究,将人机协作作为核心设计原则。内置了针对AI结构性局限(如思维锁定、谄媚)的检测与缓解机制(如魔鬼代言人让步阈值、意图识别层),这在同类工具中较为前沿。
- 流程严谨性:提供了业界罕见的、具有强制质量门(如Stage 2.5/4.5完整性检查)和结构化合约(Sprint Contract)的研究全流程编排,强调可追溯性和可审计性。
- 透明度与可扩展性:作为开源项目,所有技能提示、元数据定义、合约模式和检查脚本均公开。架构文档化程度高,允许用户深度定制和扩展研究流程。
- 项目活跃度高(68天内295次提交,22天活跃),且有持续的版本发布(15个Release)。
- 具备完整的CI流水线(GitHub Actions)进行规范一致性检查。
- 提供了详尽的架构文档(ARCHITECTURE.md)、设置指南和性能估算,表明项目设计考虑周全。
- 版本号已迭代至v3.7.0,并进行了多次重大架构升级和优化。
需注意
- 项目较新(年龄68天),虽发展迅速但长期稳定性有待观察。
- 项目完全依赖Claude模型,其输出的质量和稳定性受模型本身限制。
- 核心流程较为复杂,对用户的AI素养和学术研究方法论知识有一定要求。
- 强依赖Claude API,需要用户拥有有效的API密钥并承担相应费用,且模型行为变化可能影响工具效果。
- 定位为AI副驾驶,无法完全替代研究者的核心思考与决策过程,最终论文质量仍取决于使用者本人。
- 部分高级功能(如跨模型验证、VLM图表验证)需要配置额外的模型API,增加了使用复杂度。
- 目前主要针对基于文本的学术写作,对数据分析、实验执行等环节的支持需要结合其姊妹项目(experiment-agent)。
搭建:medium · 学习曲线:medium
关键依赖:Claude Code CLI 或 IDE 插件、Claude API 密钥、(可选)Pandoc/tectonic 用于生成DOCX/PDF、(可选)其他模型API(如GPT-5.4 Pro)用于交叉验证
近 7 日该项目开发非常活跃,提交数达 61 次,表明团队在快速推进功能开发。主要工作集中在提交包验证器和差异/补丁修订模式两个核心特性的构建上,同时进行了多项文档更新和缺陷修复。社区关注度极高,新增 Star 数超过 3000,反映出学术工具需求的增长和项目功能的成熟度。
Star +3018 · 61 次提交(近 7 日)
- 新功能提交包验证器 Slice 1新增 CLI 骨架和 Family C 参考完整性检查,为验证器提供基础功能框架。
- 新功能提交包验证器 Slice 2引入学者声明场地档案和 Family B 限制检查,增强提交包的合规性验证。
- 新功能提交包验证器 Slice 3实现 Family A 盲审残留扫描和 Family D 评估,提升学术提交的质量控制能力。
- 新功能提交包验证器 Slice 4完成验证器的终端性检查功能,确保提交流程的完整性和一致性。
- 新功能差异/补丁修订模式 A引入确定性工具链,支持修订模式的可靠应用和追踪。
- 新功能差异/补丁修订模式 B推进修订模式的采用,促进学术文档的协作修订工作流。
- 修复修复符号链接同步问题将 agents/ 符号链接物化为真实副本并修复镜像同步 lint,提升项目文件管理的稳定性。
- 文档提交包验证器设计规范记录残留扫描、场地档案和参考完整性的设计规范,为开发者提供明确指导。
chopratejas/headroom
Compress tool outputs, logs, files, and RAG chunks before they reach the LLM. 60-95% fewer tokens, same answers. Library, proxy, MCP server.
Headroom 是一个为AI代理设计的上下文压缩层,在工具输出、日志、文件和RAG块到达LLM前进行压缩。它通过减少60-95%的token使用量,同时保持答案质量,帮助开发者显著降低成本并提升效率。项目主要面向使用LLM的应用开发者,特别是处理大量上下文数据的场景,如代码搜索、故障调试和跨代理协作。
- SmartCrusher 性能
基于内容路由的JSON压缩器,自动检测并压缩数组、嵌套对象等结构,通过智能解析实现高效数据缩减。 - CodeCompressor 性能
AST感知的代码压缩,支持Python、JavaScript、Go等多种语言,在保持代码结构完整的同时减少token数量。 - Kompress-base 性能
基于HuggingFace的文本压缩模型,针对代理跟踪数据训练,提供高比率的文本压缩,并确保压缩后内容可读。 - 跨代理记忆共享 可扩展性
通过共享存储支持多个AI代理,实现上下文自动去重、溯源和共享,提升跨代理协作效率。 - 可逆压缩(CCR) 安全
存储原始数据本地,LLM通过检索工具按需获取,确保信息不丢失且可追溯,同时保护数据隐私。
语言:Python 3.10+ 和 TypeScript;框架:自定义库、代理服务器和MCP服务器;存储:本地文件系统,可选向量数据库如Qdrant;基础设施:GitHub Actions CI/CD,Docker容器化;工具链:pip、npm、pytest、HuggingFace模型。
- 代码搜索结果压缩 (所有规模)
将搜索结果token数减少92%,保持搜索准确性,显著降低LLM调用成本和延迟。 - SRE故障调试日志分析 (中型企业)
压缩大量日志数据,快速定位问题,节省token消耗并加速故障响应。 - GitHub Issue自动分类 (个人/小型团队)
压缩issue内容,提高分类效率,减少处理开销和人工干预。 - 多代理协作上下文共享 (中型企业)
通过跨代理记忆共享,避免重复压缩,提升团队协作效率和上下文一致性。
- 部署方式:支持本地运行,所有数据处理在用户环境中完成,无需上传到外部服务,保护隐私并减少延迟。
- 可逆性:提供可逆压缩(CCR),原始数据始终保留,LLM可按需检索,确保信息完整性和可追溯性。
- 覆盖范围:压缩所有类型的上下文数据,包括工具输出、日志、RAG块等,而其他工具通常只覆盖特定类型(如CLI输出)。
- 项目有100个Release,表明版本管理活跃
- 近30日提交306次,活跃天数26,开发频繁
- Star 4226,有社区基础和基准测试支持
- 提供完整文档、CI/CD和许可证
需注意
- 项目年龄仅145天,尚未经过大规模长期生产验证
- 依赖外部LLM提供商,可能受API变化影响
- 需要Python 3.10或更高版本,不支持旧版Python环境。
- 在某些沙箱或受限环境中无法运行本地进程,限制了使用场景。
- 压缩算法可能在某些边缘案例中轻微影响LLM输出准确性,尽管基准测试显示影响很小。
搭建:low · 学习曲线:low
关键依赖:Python 3.10+、Node.js/npm(用于TypeScript集成)、可选:Docker、可选:向量数据库如Qdrant
该仓库在近7日内开发高度活跃,提交数达96次,主要工作聚焦于代理功能增强、压缩算法优化和安全修复。新增的Apple-GPU支持和Hermes插件扩展显示了项目对性能和集成能力的重视。结合10583个新增Star,表明社区对该项目关注度极高,可能由于新功能发布吸引了大量用户。
Star +10583 · 96 次提交(近 7 日)
- 新功能日志压缩消息在代理中新增功能,记录压缩消息和原始请求,便于调试和分析。
- 新功能添加代理90节省配置引入新的代理节省配置文件,优化资源使用和性能。
- 新功能Hermes代理插件新增插件支持Hermes代理的头信息检索功能,扩展插件系统。
- 新功能检测重复服务工具结果识别工具结果重复服务作为过度压缩的浪费信号,提高效率。
- 新功能网络成本缓存变更公式在压缩策略中实施网络成本缓存变更公式,优化性能。
- 新功能Markdown-KV格式化器新增门控Markdown-KV压缩格式化器,支持序列化感知输出。
- 新功能基于探测的保留评分对压缩事件实施基于探测的保留评分机制,提升数据管理。
- 新功能Apple-GPU嵌入运行时添加可选的Apple-GPU (MPS)嵌入运行时,利用GPU加速嵌入计算。
HKUDS/Vibe-Trading
"Vibe-Trading: Your Personal Trading Agent"
Vibe-Trading 是一个 AI 驱动的多代理金融工作空间,能够将自然语言请求转换为跨全球市场的可执行交易策略、研究洞察和投资组合分析。它解决了传统策略开发中编程复杂性和专业知识门槛高的问题,面向交易者、投资者和量化分析师。通过集成 6 种数据源、29 个代理团队预设和 7 个回测引擎,用户无需编码即可进行深度研究和自动化策略生成。
- 自然语言策略生成 易用性
基于 ReAct 代理核心,用户通过自然语言描述交易想法,系统自动生成、测试和导出交易代码,支持 74 个专业金融技能,实现零编码策略开发。 - 多代理团队工作流 集成
提供 29 个预定义的 DAG 多代理编排团队,例如投资委员会辩论和量化策略工作流,支持实时流式仪表板和跨会话搜索,实现复杂金融任务的协作自动化。 - 跨市场回测引擎 性能
集成 7 个市场引擎(包括 A 股、港股、美股、加密货币等)和组合跨市场引擎,支持 Monte Carlo、Bootstrap CI 等统计验证,以及 4 个优化器,实现全面策略回测。 - 持久跨会话记忆 可扩展性
通过文件系统持久化记忆(~/.vibe-trading/memory/),代理能记住用户偏好并自动进化可重用技能,支持 5 层上下文压缩和 FTS5 会话搜索,确保长期学习和自适应。 - 多平台策略导出 集成
一键导出交易策略到 TradingView(Pine Script v6)、通达信(TDX)和 MetaTrader 5(MQL5),支持跨市场适配,简化策略部署和实盘前准备。
语言:Python 3.11+;后端框架:FastAPI;前端:React 19 + Vite + TypeScript;存储:文件系统(如持久记忆和会话数据);基础设施:Docker 支持,CI/CD 管道;工具链:PyPI 包发布(vibe-trading-ai)、MCP 服务器(22 个工具)、LLM 提供商抽象层(支持 13 个提供商如 OpenAI、DeepSeek、Ollama);数据源:AKShare、yfinance、CCXT、Tushare 等。
- 策略回测与优化 (所有规模)
用户通过自然语言快速测试交易策略(如移动平均交叉),获得 Sharpe 比率、最大回撤等指标,并导出到交易平台,加速策略迭代。 - 市场深度研究 (个人/小型团队)
利用代理团队进行股票基本面分析、宏观趋势评估或加密货币链上分析,生成研究报告,提升投资决策质量。 - 多代理协作工作流 (中型企业)
使用预定义团队(如投资委员会)进行多空辩论、风险审查,实现自动化投资流程,提高团队协作效率。 - 交易行为分析 (个人/小型团队)
上传经纪商导出文件(如 CSV、PDF),系统自动分析交易偏差(如过度交易、处置效应),帮助用户改善交易习惯。
- 生态集成:支持 6 种数据源(A 股、港股、美股、加密货币、期货、外汇)和 13 个 LLM 提供商,提供零配置免费数据回退,而同类工具通常需要多个 API 密钥或付费数据源。
- 功能完整性:集成策略生成、回测、研究和导出于一体,提供 74 个专业技能和 29 个代理团队,相比单一功能的交易工具(如 Backtrader)更全面。
- 用户体验:通过自然语言交互和自进化技能系统,降低金融量化分析门槛,同时提供 CLI、Web UI 和 MCP 插件多种接入方式,适应不同用户场景。
- 项目年龄仅 32 天,但已有 3 个 Release 版本和 CI/CD 支持
- 近 30 日有 92 次提交和 21 天活跃,显示积极开发
- README 明确声明“仅用于研究、模拟和回测”,未提及实盘交易支持
- 提供 Docker 部署和安全硬化补丁,但远程部署需配置 API_AUTH_KEY
需注意
- 需要外部 LLM API 密钥(除 Ollama 外),增加了使用依赖
- 作为早期项目,可能存在稳定性问题或功能不完整
- 安全策略依赖用户配置 API_AUTH_KEY,否则可能暴露风险
- 不支持实盘交易执行,仅限于研究和回测,用户需自行部署策略到其他平台。
- 重度依赖 LLM 提供商(如 OpenAI、DeepSeek),模型质量和成本可能影响使用体验。
- 数据源如 AKShare、yfinance 为免费服务,可能存在数据延迟或限制,不适合高频交易。
- 跨会话记忆基于文件系统,在大规模并发或多用户场景下可能性能不足。
搭建:low · 学习曲线:medium
关键依赖:Python 3.11+、LLM API 密钥(如 OpenAI、DeepSeek)、可选:Docker
Vibe-Trading 仓库近7日保持高度活跃开发状态,提交数达32次。开发工作主要集中在Docker容器持久化、Swarm模块数据工具集成、Web界面改进以及文档更新。新增Star 1169表明社区关注度持续高涨,项目吸引力增强。结合提交内容,团队正致力于提升易用性和功能扩展,推动生态发展。
Star +1169 · 32 次提交(近 7 日)
- 新功能Swarm股票修复修复Swarm提示中裸US股票代码的处理,确保市场数据获取准确,提升代理工具可靠性。
- 修复Docker状态持久化修复Docker容器重建时用户代理状态丢失的问题,通过持久化机制保障用户体验连续性。
- 修复Web SSE超时保护为Web界面添加SSE安全超时机制,防止无事件时无限挂起,增强系统稳定性。
- 新功能显示代理状态在聊天界面中显示Swarm代理状态,提高交互透明度,方便用户监控任务进展。
- 新功能Alpha对比工具在CLI、REST、Web UI和代理工具中新增Alpha对比功能,支持多端数据比较,促进策略分析。
- 文档数据加载器指南添加自定义数据加载器指南文档,帮助开发者扩展数据源接入,降低集成门槛。
- 修复LLM签名保留修复在AgentLoop字典路径中保留Gemini thought_signature的问题,确保LLM交互流程正常。
- 更新Docker CI优化在文档推送时跳过GHCR边缘构建,减少不必要的CI资源消耗,提升构建效率。
heygen-com/hyperframes
Write HTML. Render video. Built for agents.
HyperFrames 是一个开源视频渲染框架,允许用户通过编写 HTML 来创建、预览和渲染视频。它解决了传统视频制作工具复杂性和与 AI 集成不足的问题,专为 AI 代理设计,支持确定性渲染和自动化工作流。面向开发者、内容创作者以及使用 AI 代理进行视频生成的团队。
- HTML-native 视频创作 易用性
基于标准 HTML 和 CSS 编写视频组成,无需 React 或专有 DSL,使用 data 属性定义时间线和属性,简化开发流程。 - AI 代理深度集成 集成
提供技能和插件系统,让 AI 代理如 Claude Code、Cursor 能直接理解和生成 HyperFrames 代码,支持自动化视频生成。 - 确定性帧渲染 性能
使用 Puppeteer 驱动的无头浏览器和 FFmpeg 进行渲染,确保相同输入产生相同输出,适合自动化视频管道。 - 可扩展帧适配器 可扩展性
通过帧适配器模式支持多种动画运行时(如 GSAP、Lottie、Three.js),允许开发者集成现有动画库。 - 组件化视频块 易用性
提供 50+ 预构建组件(如社交覆盖、着色器转换、数据图表),可通过 CLI 快速添加,加速视频制作。
语言:TypeScript;运行时:Node.js(要求 >=22);渲染引擎:Puppeteer(无头浏览器) + FFmpeg(视频编码);动画支持:集成 GSAP、Anime.js、CSS 等;工具链:npm 用于包管理,CLI 用于开发循环;容器化:支持 Docker 部署。
- AI 代理驱动的视频创作 (所有规模)
通过自然语言描述自动生成视频,降低视频制作门槛,加速内容产出。 - 产品营销视频制作 (中型企业)
快速创建高质量产品介绍视频,用于广告和社交媒体推广。 - 数据可视化动画生成 (所有规模)
将原始数据转换为动态图表,提升报告和演示的吸引力。 - 社交媒体内容批量生产 (个人/小型团队)
利用组件和模板快速生成 TikTok、Instagram 风格视频,提高发布频率。
- 编写范式:使用 HTML 而非 React 组件,降低学习成本,无需构建步骤。
- 开源许可证:采用 Apache 2.0 许可,完全开源,无商业使用限制。
- AI 集成深度:原生支持 AI 代理,提供专门的技能系统,简化自动化视频生成。
- 项目年龄仅54天但已有91个Release,表明快速迭代
- 近30日提交369次,活跃天数28,开发活跃
- Star总数14115,增长迅速,社区兴趣高
- 有CI、License和完整包结构
需注意
- 项目较新,可能缺乏长期稳定性验证
- 分布式渲染仅支持单机,限制大规模应用
- 当前仅支持单机渲染,无法处理分布式视频渲染任务。
- 项目较新,可能功能不完善或存在未发现的bug。
- 依赖 Node.js >=22 和 FFmpeg,对环境有特定要求。
搭建:medium · 学习曲线:medium
关键依赖:Node.js >=22、FFmpeg、npm
hyperframes 本周开发极其活跃,提交数达 125 次,显示团队在核心引擎、SDK、工作室和 CLI 工具上持续投入。主要工作方向包括 SDK 引擎层搭建、时间线分割功能开发、核心 Bug 修复以及代码重构。社区关注度显著提升,新增 2480 个 star,表明项目在动画框架领域的快速成长和开发者兴趣。
Star +2480 · 125 次提交(近 7 日)
- 新功能SDK 会话 API新增 SDK 会话 API,支持可选历史和持久队列,完成 Phase 3a 开发,提升会话管理能力。
- 新功能SDK 引擎层搭建 @hyperframes/sdk 引擎层,包括模型、RFC 6902 补丁和应用功能,奠定 SDK 基础。
- 新功能导出 hf-ids将 hf-ids 作为子路径导出,供 @hyperframes/sdk 使用,方便外部集成。
- 新功能时间线分割 UI在工作室中新增剃刀/刀片工具 UI,用于时间线片段分割,增强编辑功能。
- 新功能GSAP 分割引擎核心引擎添加 GSAP 感知分割功能,支持时间线片段分割,优化动画处理。
- 新功能GIF 输入支持支持动画 GIF 输入,通过 VP9 转码实现帧同步播放,扩展输入格式。
- 修复核心功能修复修复 split-into-property-groups 和 replace-with-keyframes 突变中的问题,提升稳定性。
- 重构工作室组件重构提取共享时间线组件并去重代码,提高代码复用性和维护性。
“With a software upgrade, operators can squeeze more capacity, better observability, and more accurate location-based services out of the 5G network they bought years ago,” Mobile Experts
Ericsson’s AI in RAN offers an alternative to Nokia’s tie-up with NVIDIA in the shape of a software subscription. Nokia’s approach relies on GPUs to act as a general-purpose compute fabric.
The vendor says the tech has been proven in more than 15 commercial network deployments and trials around the globe – see the quotations from operators below. Ericsson states it delivers up to 20% higher downlink throughput and up to 10% better spectral efficiency. It also supports up to twice as many high-volume users and offers coverage predictions that are 90–95% accurate, and is to up to 5x more precise about users’ positioning.
Joe Madden, Principal Analyst at Mobile Experts, says: “This could be the best ROI for mobile operators in years. With a software upgrade, operators can squeeze more capacity, better observability, and more accurate location-based services out of the 5G network they bought years ago.”
Since announcing its tie-up with NVIDIA last October and pivoting to reposition itself as an AI infrastructure company, Nokia’s share price has doubled, leaving Ericsson’s share price trailing – see below. So can Ericsson’s counter to NVIDIA/Nokia’s physical AI monetisation story succeed (not that there are any guarantees operators will buy into the GPU-in-the-RAN model)?
Source: Sebastian Barros, What in Valhalla is Going on With Nokia? 2X Value to 80B in 6 Months!, published 9 June 2026
Before we get going on the new AI in RAN part, Ericsson is keen to point out it has introduced AI functionality across its products since 4G, and in 2021 added AI‑ready acceleration in RAN Compute. More to the point, in February, it unveiled Neural Network Accelerators in its Massive MIMO radios, increasing AI inference capability by 10 times.
What is AI in RAN?
Ericsson’s new AI in RAN is a software subscription that “brings telco-grade AI models into basebands and radios to boost efficiency, performance, and energy savings. This commercially scalable offering gives communications service providers (CSPs) immediate benefits for 5G networks and supports the shift to AI-native RAN without requiring additional hardware.”
Ericsson AI in RAN introduces:
• Telco-grade AI models designed to run in real time within the RAN
• Continuous learning software powered by scalable, ‘high-quality’ data
• Agentic AI support for advanced RAN automation and network operations.
It works with Ericsson 5G Advanced across both purpose-built and Cloud RAN platforms to enable new AI-driven services. Some of the software features include AI-native Scheduler for Link Adaptation (see info on trial with T-Mobile US here), AI-powered Macro Positioning, AI-managed Beamforming, AI-powered Multi-layer Coordination, Performance Management Event Schema Files, and Augmented Observability for AI in RAN.
The first AI in RAN features are available in Q2 2026, with enhancements scheduled for later in the year.
What the operators say…
Teruyuki Oya, Senior Vice President & CNO at SoftBank Corp, comments, “Ericsson’s AI in RAN software marks an important step in bringing AI deeper into the radio access network. By enabling realtime optimization of radio performance, spectrum efficiency and user experience, it helps us turn AI innovation into practical value on live networks. We also see strong potential in how this foundation can support emerging AI-driven services, including Physical AI scenarios that depend on low-latency, highly reliable connectivity, and intelligent coordination between network and compute resources.”
Bruce Dean, Senior Vice President, Network Technology & Operations at Bell, is also in favour, “At Bell, we’re continuously evolving our network to meet growing demand for high-performance, AI-driven services. Integrating AI directly into the RAN is an important step in making networks more intelligent and efficient. Working with partners like Ericsson, we’re bringing these capabilities into our network to enhance performance, improve energy efficiency and deliver a better experience for our customers.”
Yu Takki, Head of Network Technology Office at SK Telecom, adds, “Through our collaboration with Ericsson, SK Telecom is advancing AI-RAN to enhance network performance and energy efficiency while supporting more intelligent and automated operations. By combining research, real-world validation and software innovation, we aim to strengthen our leadership in AI-powered network evolution and help lay the foundation for AI-native 6G.”
Mark Kennedy, CTO at Rogers, says, “As Canada’s best 5G+ network, we’re proud to work with Ericsson and bring the latest 5G technology to Canadians. AI in RAN will help optimize network performance for customers in real-time and reduce energy consumption.”
Last word to Ericsson
“Ericsson is redefining what’s possible in mobile networks by bringing powerful AI capabilities to service providers,” says Mårten Lerner, Head of Networks Strategy & Product Management at Ericsson. “With AI in RAN software, we are taking a major step toward AI-native networks, alongside the AI-ready radios we unveiled in February.”
He adds, “With AI in RAN, Ericsson is bringing AI into networks to elevate 5G performance and efficiency through energy-efficient AI inference at scale”.
The post Ericsson’s monetisation plan for AI in RAN without GPUs appeared first on Mobile Europe.
据央广网消息,网约车司机林岩宏表示:“早期一公里能挣两三元钱,现在一公里可能只有一两元钱。”算法在提升效率的同时,也让一些劳动者遭遇被加倍考核、收入不透明、工时被切割等情况。本是效率工具的AI,随意成为了“数字监工”。
AI 全面延伸管控边界
催生“数字监工”乱象
AI技术渗入生产组织方式的程度,早已超出“辅助工具”的范畴,正在悄然接管劳动过程的指挥权。最直接的表现,是将劳动者的每一分钟、每一次操作、每一公里行程都纳入可量化、可考核、可惩罚的数据网格之中——表面上是“智能调度”,实质上构成了一种全天候、无死角的“数字监工”。
网约车行业的运价缩水轨迹最具代表性。在郑州跑了7年网约车的李山河坦言:“我现在每天跑13个小时左右,收入约300元,扣除租金等固定支出,每月到手约4000元。”他记忆里单价从每公里两块多慢慢滑到一块出头,而平台推出的“特惠单”“一口价”把价格锚不断往下拽,他甚至发现,如果把“一口价”“随心接”类低价单的选项关掉,接单率会明显下降,只能重新打开,系统用派单权把低价单变成了“可以不接、但接不到别的”的软性强制。平台依托智能派单算法精准核算里程、时长与能耗,动态调价机制叠加“一口价”模式,使运价在数年间持续走低。
而在企业办公场景中,AI“监工”的逻辑更为隐蔽却同样锋利。福建一家互联网企业的市场总监张文锋的遭遇颇具典型性,团队引入AI助手后,竞品分析报告从过去需要数天收集整理压缩到一个小时即可输出,效率提升本该是好事,但管理层随即将这一“AI加速后的产出速度”默认为员工的常规产能基准,直接加派更多任务量。
从亚马逊仓库中AI实时监控拣货速度并自动生成解雇指令,到国内部分企业在员工终端部署行为追踪软件以鼠标移动、键盘敲击频率衡量“生产力”,AI正在将管理推向前所未有的精密程度。
算法机制的机械化、冰冷化
是问题症结
所有这些乱象的深层症结,指向同一个核心——算法被设计为单一目标的优化器,却缺乏对人的处境与现实复杂性的感知能力。它追求的是数字层面的“最优”,而非生活层面的“合适”。
以外卖行业为例,平台依靠历史订单大数据、路网拓扑与实时定位,为每一单精密计算出一条“最优路径”和一个“准时送达时限”,但这个时限往往按理想条件下的“最快速度”卡死,不考虑暴雨天气轮胎打滑导致的安全降速,不考虑商家出餐高峰期的真实滞留,不考虑老旧小区“进不去、上楼难”的最后一公里的现实摩擦,更不考虑早高峰学校周边临时交通管制造成的绕行代价。
做了8年骑手的陈安柱,他负责片区内中的有一所大学东门与西门“直线很近”,但校园封闭管理,系统规划的“最佳路线”却默认你能穿行,现实只能绕行。这一绕,配送时间就吃紧,超时就要扣分。
更关键的矛盾在于,算法精细切割骑手的在岗时长,只要处于上线状态便需全天候待命,在线时长被纳入活跃度评分体系,下线就意味着派单权重下降、后续收入进一步缩水。于是骑手即便没有在跑单,也不敢真正“下班”。骑手为了让系统判定自己“可用”,往往被迫把等单、避雨、找车、商家出餐滞留这些真实付出,压缩成一种只能自己扛的隐形工时。
化解AI“数字监工”难题
需多方协同
技术本身并没有错,但脱离约束的技术应用必然滑向工具理性碾压价值理性的旧路。将AI从“监工”拉回“助手”,需要多方同步发力。
监管层面,关键动作已经从“呼吁”进入“建制”阶段。2026年4月,中办、国办印发《关于加强新就业群体服务管理的意见》,从国家顶层设计层面直指算法黑箱问题,明确要求平台取消暗箱操作,保障骑手对计价规则、配送时长的知情权、参与权和选择权,算法基本原理与运行机制必须公开透明、备案审核。中央网信办同期推进《生活服务类平台算法负面清单(试行)》,多部门联合督促头部平台自查自纠,已推动美团基本取消超时扣款、滴滴设定“服务10小时强制下线6小时”的防疲劳阈值、各平台承诺抽成上限下调并推动核心算法公示专区建设。北京新版非机动车管理条例更直接写入“平台应依法履行算法备案手续,制定算法规则时应充分考虑交通安全”的硬约束。下一步,是把这些“已承诺”转化为可核查、可追责的持续监管,即预留极端天气、特殊场景的容错缓冲空间,确立算法变更的事前公示与协商门槛,让备案不只是填表,而成为实质审查。
企业层面,算法模型的优化方向必须从“最严算法”转向“折中算法”。具体而言,应在时间预估中纳入天气系数、路况拥堵指数、小区通行难度等现实变量,以“算法取中”替代“卡最短时限”;在考核体系中剔除单纯以速度为导向的奖惩杠杆,增设安全分、疲劳预警等人性化参数。
而对劳动者来说,维权最难的不在勇气,而在证据。当计价规则、派单逻辑、处罚系数、奖励门槛全部封进代码与接口,劳动者手里往往只剩接单记录和收入截图这样的碎片。正因如此,无论是交通运输部早年“阳光行动”要求的每单列明乘客支付总额、驾驶员报酬、抽成比例,还是中办国办文件强调的算法备案、公示、听取工会与从业人员代表意见,本质上都是在做同一件事,让规则能被看见,让看见后能争论,让争论能通向修正。
归根结底,AI不该是用来让劳动者跑更快的鞭子,而应是帮每个人把活儿干得更从容的杠杆。效率红利要真正转化为从业者福利,前提是让算法回归辅助工具的本质,让技术的尺度重新以人的尺度来校准。
(图片来源:摄图网)
END
向“通信信息报”投稿,请致信:txxxb2001@163.com,
稿件一经刊发,将根据文章质量,
提供千字200元-500元的稿酬。
其他合作、建议、新闻线索,
欢迎于微信公众号后台联系我们。
不良信息举报电话:0591-83365173。
专注做内容的公众号
近日,中国信通院正式宣布,中国电信、中国移动、中国联通旗下词元(Token)产品集体入驻中国算力平台算力超市。这一事件标志着普惠算力正式从概念走向规模商用。与此同时,中国电信500万台天翼智屏集采项目也于近日正式公示成交结果,中国电信500万台天翼智屏集采落地,标志着中国电信基于星辰大模型的“Token经营”战略进入实质性落地阶段。
从战略提出到产品上架,从算力底座到终端入口,三大运营商正集体走出单一流量变现的旧周期,迈入以词元为计价核心的AI价值运营新阶段。这不仅是运营商自身商业模式的重大转型,更是“人工智能+”国家战略在民生领域落地的关键一步。
Token 经营顺势站上风口
中国电信率先提出Token经营战略,是产业周期、政策导向、市场需求多重因素共同作用的结果。2026年是“十五五”规划开局之年,党的二十届四中全会明确提出深入推进数字中国建设,要求全面实施“人工智能+”行动。作为数字中国建设的主力军,运营商承担着推动AI规模化应用、让智能服务惠及更多群众的责任。
从产业周期来看,通信行业正经历发展模式的转变。过去三十年,运营商先后经历了语音经营、短信经营和流量经营三个阶段,每一次计量方式的变革都推动了行业价值的显著增长。随着生成式AI的发展,Token正在成为新的基础服务计量单位。中国电信董事长柯瑞文在2026数字中国建设峰会上表示:“智能云体系就是词元(Token)经营体系。Token经营的本质就是为用户提供AI服务。”
市场需求的增长也为Token经营提供了基础。随着大模型技术的成熟,AI应用开始从专业领域向大众消费领域渗透。但普通用户使用AI服务仍面临一些门槛,如注册多个平台账号、绑定第三方支付、操作复杂、数据安全顾虑等。运营商凭借庞大的用户基础、完善的支付体系和全国性的服务网络,能够简化AI服务的使用流程。用户通过运营商官方APP开通Token套餐,消费可直接计入话费账单,无需绑定第三方支付,基本实现了“手机号即AI账号”的便捷体验。
供给筑基
构建端到端Token服务能力
中国电信能够较快推进Token经营的消费端落地,得益于供给侧的长期积累和商业模式的内在需求。在供给侧环节,中国电信已构建起从算力、数据、模型到平台的技术体系,为Token经营提供了基础保障。
在算力层面,中国电信持续推进智算基础设施建设。截至目前,中国电信自有及接入智算总规模已超过91 EFLOPS,能够支撑大规模模型训练和推理的算力需求。同时,中国电信通过“息壤”算力互联调度平台2.0和Triless架构,有效提升了资源调度效率,实现了全国算力资源的统一管理和弹性调度,有助于降低Token生产成本,为普惠AI服务提供了可能。
在数据层面,中国电信DaaS层汇聚了超20万亿词元的训练数据,这些数据覆盖通信、政务、金融、教育、医疗等多个领域,为大模型的训练和优化提供了素材。中国电信建立了完善的数据治理体系,严格遵守数据安全和隐私保护相关法律法规,确保数据合法合规使用。
在模型层面,中国电信采用“自研+生态”的发展策略。一方面持续投入自研星辰大模型的研发,提升模型性能;另一方面与国内主流大模型厂商开展合作,将GLM-5、DeepSeekV 3.2、MiniMaxM 2.5等模型接入星辰Token Hub平台。这种模式能够为用户提供多样化的模型选择,满足不同场景的AI需求。
在平台层面,星辰Token Hub运营服务平台1.0具备多模型聚合与智能路由、自研与生态智能体纳管功能。用户调用Token时,平台可根据模型效率、Token消耗、调用成本等因素进行智能调度,匹配适合的模型服务对应场景。同时,平台纳管了各类自研与生态智能体,能够为用户提供一体化AI服务。这种平台化运营模式降低了用户使用AI的门槛,也为生态伙伴提供了触达用户的渠道。
标准化深耕
推动Token经营从概念走向实践
Token经营可持续发展,需要通过标准化建设和行业场景化深耕,从概念走向实际应用。中国电信在推动Token经营标准化和规模化落地方面开展了积极探索。
在标准化建设方面,中国电信参与国家和行业标准的制定,推动算网Token标准化资产化运营。作为中国信通院算力网络标准体系的参与者,中国电信在Token计量、计费、安全、互通等方面提出了相关建议。同时,中国电信在内部建立了统一的Token计量标准和计费体系,初步实现了跨终端、跨应用、跨场景的Token共享互通。用户购买的Token可用于调用大模型,也可兑换各类AI应用和服务,提升了Token的使用价值。
中国电信推出了天翼Token币和Token权益体系。天翼Token币作为中国电信Token经营的统一量纲,可用于客户积分兑换Token量包和AI应用。Token权益体系通过引入AI生态应用伙伴,为用户提供更多样的AI服务选择。这种模式有助于吸引用户使用Token服务,也为AI产业发展提供了新的路径。
在行业场景化深耕方面,中国电信针对不同行业的需求,开发了相应的Token解决方案。在教育行业,推出AI助教、智能作业批改等服务;在医疗行业,开发AI辅助诊断、智能病历生成等应用;在金融行业,提供智能风控、智能客服等解决方案;在工业行业,打造工业智能体,助力企业生产智能化。
三大运营商集体入驻中国算力平台算力超市,是Token经营发展的重要节点。用户可登录中国算力平台获取三大运营商的词元产品信息,根据需求灵活选择。中国电信的天翼云Token Plan产品分为开发者/中小企业版和个人/家庭版,分别基于GLM-5大模型和DeepSeekV 3.2通用大模型能力;中国移动推出“Byte+Token”双增长战略,提供1元可购40万Tokens的通用服务;中国联通提出“Agent+Token+AI云”范式,推出Coding Plan及Token Plan产品。三大运营商的有序竞争,有助于推动Token服务价格下降和质量提升,让更多用户享受到普惠AI服务。
随着5G-A网络的规模商用和AI技术的进步,Token经营将有更广阔的发展空间。运营商将继续完善智能云体系建设,提升Token生产、分发和应用的效率,推动AI服务不断优化。同时,运营商将加强与产业链上下游的合作,共同构建开放协同的AI产业生态。Token有望成为运营商新的价值增长点,也将成为数字经济时代重要的价值计量单位,为千行百业的数智化转型提供支撑。
(图片来源:摄图网)
END
向“通信信息报”投稿,请致信:txxxb2001@163.com,
稿件一经刊发,将根据文章质量,
提供千字200元-500元的稿酬。
其他合作、建议、新闻线索,
欢迎于微信公众号后台联系我们。
不良信息举报电话:0591-83365173。
专注做内容的公众号
It has entered a preliminary agreement with PPC Group in Greece to form a 50:50 JV of their fibre assets and businesses, and is reportedly bidding for TalkTalk’s consumer broadband unit
Vodafone Greece and Public Power Corporation, better known as PPC Group, have entered into a preliminary agreement to form a 50:50 joint venture for FTTH. Under the proposed deal, the two will merge their networks and wholesale fibre businesses into a single entity.
Collectively, Vodafone Greece and PPC Group’s fibre businesses cover more than 1.6 million premises. The JV would offer wholesale open access to internet service providers in Greece.
The formation of the JV is subject to due diligence and subject to customary conditions including regulatory approvals. Vodafone says it “expects to provide a further update in due course”. Last month Vodafone announced it would take full control of VodafoneThree – which was allowed for in the conditions of the merger – sooner rather than later.
Vodafone bids for TalkTalk assets in UK
Earlier this week, VodafoneThree reportedly bid for the consumer operations of UK rival TalkTalk. A Financial Times article [subscription needed] said the rationale is for VodafoneThree, now the UK’s biggest operator, to accelerate its progress into providing broadband. VodafoneThree said it wants to double its UK broadband base to 4 million premises passed by the 2030s.
TalkTalk has about 1.75 million customers and is auctioning its consumer division. After an inititial decision not to engage, VodafoneThree took part in the second round of bidding last week, according to unnamed sources cited by the FT. The value of the consumer business is not precise – valued at between £200 million and £300 million.
TalkTalk is also seeking a buyer for its wholesale division, PXC.
TalkTalk group was bought for £1.1 billion by London-based hedge fund Toscafund in 2021, which added £527 million debt to its balance sheet in a time of rising interest rates. Last year Openreach reportedly threatened not to connect any more TalkTalk customers to its network because of late payments by the service provider. That was also reported in the FT.
The post Vodafone looks to expand fibre footprint in Greece and the UK appeared first on Mobile Europe.

论坛介绍:本次论坛是 2026 年 6 月 12 智源大会核心技术论坛之一,由蓝驰创投管理合伙人陈维广担任主持人,邀请到智源研究院院长王仲远、银河通用创始人兼 CTO 王鹤、面壁智能 CEO 李大海三位行业顶尖技术专家,围绕大模型行业最具争议的五大核心问题展开深度对谈。嘉宾从学术研究、技术创业和产业落地三个维度,分享了对大模型未来发展的独家判断。
核心观点速览:
大模型技术远未收敛,不存在普遍趋同的终局,真正的护城河来自数据闭环、软硬协同设计和垂直场景的极致深耕Scaling Law 远未失效,已从纯语言模型扩展到多模态和具身智能,WAM(世界动作模型)将开启具身智能的规模化时代端侧与云端将长期协同发展,终端大模型的 scaling 空间巨大,由硬件算力升级和量化技术进步共同驱动AI 安全与责任划分将遵循 "边实践边完善" 的路径,参考自动驾驶等技术的发展历程,逐步建立行业标准和治理体系中国 AI 具备全球最完整的供应链、最丰富的落地场景和数量最多的年轻人才三大独特优势,具身智能将是中国实现弯道超车的核心赛道
陈维广:大家下午好,非常荣幸担任本次论坛的主持人。主办方给我的主题是:在大模型技术的成熟曲线上,我们该如何跨越?又该如何定义大模型的长期价值?今天也非常非常荣幸,能邀请到这三位嘉宾,他们能从三个不同的角度来去一起探讨这个主题。
仲远老师大家应该比较熟悉了,智源也在过去这么多年,参与到了智谱、月之暗面等大模型企业的相关研究,包括今天在座的这两家,所以他应该是有非常好的全局观。王鹤老师这边,银河通用主要是在Physical AI,在具身这块,如何去更好地利用模型来加速Physical AI的部署。大海老师刚才也介绍了,大家也知道面壁在终端这块还是比较前沿的。
那我就尽快进入问题。我觉得整个行业里面大家都有一个问题:大模型这几年发展得比较快,可是同时大家也能看到,不管是打榜还是一些第三方的评价,顶级模型的趋势在快速趋同。今天可能某某的benchmark数据很好,两个月后其他人就跟进了。再加上token的价格也快速在下探,还有一点就是开源模型也发展比较快,甚至有人说开源模型跟闭源模型的差距也就3到6个月。
在这种情况下,如果作为一个AI模型公司,它的长期价值来自哪?它的护城河来自哪?甚至有些人非常质疑说,AI大模型的公司最终就会像卖水卖电的有量无价。我第一个问题就是,王鹤老师,从你的角度,你感觉AI的企业,尤其是这些大模型公司,它未来的长期价值以及护城河在哪里?
王鹤:我觉得这个问题其实更多表达了大家对数字世界里的智能,或者说对LLM这项技术现状的判断。但就像仲远博士刚刚讲的,LLM本身仍然存在很多变数,如果再往后看多模态、VLM(视觉语言模型)或者视频生成,变数就更多了。
我本人主要从事具身智能领域,我认为整个行业刚刚在往收敛的方向发展。过去几年行业有VLA(视觉语言动作模型),也有World Model(世界模型),现在我认为整个行业正在向着WAM(世界动作模型)的方向迭代:一个模型既能够做未来的预测,又能够做动作执行的预测;同时它既能够吸收人类的无动作标签数据,又能够吸收机器人的有动作标签数据。
具身智能现在的发展阶段,大概处在GPT-1到GPT-2这样的水平。往未来看,一旦行业进入scaling(规模化)阶段,一切都会快速加速,这也意味着行业现在需要更大量的资金投入。
面向未来,具身智能真正的护城河是一个完整的体系:既有源头的数据供给,又有对不同种类数据(合成数据、人类数据、机器人数据)的提炼能力,还有硬件迭代和软硬co-design的能力,最后是模型的融合水平和向客户交付硬件的整套能力。这是迄今为止全世界范围内都没有出现过的综合型产品形态,所以它的护城河相当深,未来不管是做垂类应用的深度还是广度,都有无穷的潜力。
陈维广:所以是要做"六边形战士",面面俱到。大海老师怎么看?
李大海:我觉得场上嘉宾的观点是一致的,都不认同"大模型没有长期壁垒"这个结论。受两位嘉宾启发,我突然想到:大模型应该是我们以前说的"T形人才"——它必须得是通用的,但仅仅是通用的、和其他人同质化是没有意义的,它一定得有自己的长板。
举个例子,现在美国大模型领域的当红企业是Anthropic,它之所以强、被追捧,是因为它在通用模型的前提之上,把Coding能力做到了独步天下,因此才获得了现在的估值、行业认可和非常亮眼的商业成绩。所以大模型光是有横向的通用能力是不够的,一定得有纵向的长板。
另一方面,纵向长板怎么来?我非常认同王鹤老师讲的,我会用另外一个词叫闭环:一定要把大模型当成一个引擎、一个发动机,但这个发动机的设计和能力的持续极致优化,必须要和"整车"去协同,不能脱离应用空谈性能。你造的是F1赛车还是买菜车,对应的发动机需要做完全不同的特化。
从过去两年大模型的发展来看,一个非常重要的趋势是:模型正在以内化成一个系统的方式演进,包括现在我们做的agentic强化学习,其实就是带着整个智能体系统去做模型的进一步训练。面向未来,上下文记忆是一个非常重要的待突破方向,现在大家都在用harness的方式解决,但我认为这个方式不够,必须是harness加上模型的强化学习才行。
总结一下:我认为大模型的技术还远远没有收敛,同时任何一家模型公司都必须把技术的通用性和商业的通用性分开——真正通用的商业场景其实很少,要做好商业往往需要模型在特定方向上做极致的优化。只要每个公司找准自己的方向,都能构建起自己的护城河。
陈维广:仲远院长怎么看这个问题?
王仲远:坦率来讲,我个人并不完全认同"模型趋同、没有护城河"的观点。因为现在大模型整体的性能迭代还没有到瓶颈,我们还没办法断言最终会不会所有模型都趋同,未来可能是一超多强、多个巨头并存,也可能是大家能力相近,有很多种演化格局。
现阶段来看,榜单其实并不那么可信。各种各样的榜单看得人眼花缭乱,很多结果也没办法完全验证。老话讲"是骡子是马拉出来溜溜",那些敢于做真机展示、敢于进入实际场景落地的模型公司,是有底气的,也能够在真实场景中找到数据闭环。
所以今天还没办法下定论说未来模型公司都会趋同、没有护城河。智能技术还没有收敛,还在快速迭代演进,各种可能性和结果都有可能出现。
陈维广:看来这个行业大家很容易黑白分明,立刻就想下"大模型没有长期壁垒"的结论。但听你们介绍,场景、数据,包括刚才大海老师说的闭环能力都非常重要。从投资角度,我们接触的创业团队也很多,发现团队的基因差异其实很大:做大模型的团队有实验室氛围,做应用的团队更关注场景和需求。当然也不是说做大模型的就做不了应用,但确实这两种团队的文化和取向完全不一样,这也会逐渐形成一定的壁垒。
接下来是行业一直在拷问的一个问题:尤其是去年,大家感觉scaling law的红利变小了,甚至有人说预训练做得越多,模型能力也没有很大提升,所以去年有一波做强化学习、做后训练的热潮,后训练至少可以把能力做到一个比较好的水平,包括刚才蚂蚁的李老师也提到了deep deep sheet和reasoning能力的出现。所以行业就感觉,是不是接下来纯语言模型的发展会遇到瓶颈,边际效应递减?仲远院长,你怎么看这个问题?
王仲远:从我个人的观点,我其实还是比较坚信scaling还远没有到尽头。去年之所以媒体上会有很多关于scaling law是不是已经失效的探讨,但实际上从技术领域,从我们接触的很多大模型实际训练的公司,以及从今天这个时间点再回过头来看,很显然已经证明了scaling没有失效,只不过它变得更加多样化了。
去年大家会有"scaling失效"这种论调,其中一个很重要的原因是大语言模型所使用的互联网数据已经用完了。大家觉得互联网数据只有一份,而语言模型以前主要靠预训练来提升性能,那预训练的数据用完了,性能自然就会遇到瓶颈。但实际上在过去两年,大家通过后训练以及推理优化,已经迎来了新一波的能力提升。
再往后通过agent,包括今天智源大会早晨开幕式的圆桌上也探讨到了递归自进化,这些都已经证明了:即使互联网数据可能用完了,AI的能力依然在持续提升——不仅仅是模型本身的能力提升,更是整个系统的能力越来越强,而且也开始从聊天工具变成执行工具。所以我们还是非常相信整个scaling的曲线还在延续,如果大家去看近期发布的很多模型,能力甚至呈现出指数级跃升的倾向。
早晨我其实也问了一下朱军,他的观点相对谨慎一些。可是我们看到了很多的模型,确实它的能力依然在快速提升。另外,智源研究院的定位一直是"做高校做不了、企业不愿意做或现阶段不愿意做的事",去探究下一个智能的曲线。
过去两年我们把重心放在多模态,用Next Token Prediction的方式去探究多模态的Scaling。事实上我们发现,像物界Emu3、Emu3.5,已经呈现出了一个多模态的Scaling范式:当我们复用了大规模现在的大语言模型的智算基础设施,数据和参数的增加确实带来了能力的提升。而我们的数据依然只用了不到1%,参数也只有百亿级,但已经看到了非常明显的性能提升。
所以多模态的scaling范式,我们认为已经找到了至少一条可行的路径。当技术成熟的时候,我们就交给产业去做,然后我们又开始往下一个方向——物理世界的世界基座模型去探究,看看在世界模型上有没有scaling的范式。今天早晨我们也分享了正在研发当中的物界Physics,它就在探究世界模型的scaling方式到底是什么。
所以我对这个问题还是非常乐观的:不管是已经成熟的语言模型、AI coding、数字世界的大模型,还是最终我们进入到物理世界的世界基座模型,依然还有非常多的scaling空间需要去探究。
陈维广:王鹤老师这边,因为Physical AI可能跟大语言模型还有点不一样,对不对?甚至有一些行业人说,VLA都还没搞完,为什么突然间出现这么多搞世界模型的?你有什么看法?
王鹤:是这样的,银河通用和我本人是deeply believe in scaling 的。其实在WAM(世界动作模型)这个范式还没有出现之前,在VLA(视觉语言动作模型)的范式里,我们就先用合成数据做了大量的scaling。当时我们主要focus在一件事情上——抓取。我们想看看一个技能能不能通过scaling来变成一个真正的基模。
我们用了10亿帧仿真数据证明了:只要你把数据scale到这个程度,抓取就可以完全做到Zero-Shot(零样本)。在真实世界随便给我一个东西,我们的端到端GRASP VLA模型,就能直接零样本解决这个问题。这是我们2025年初的工作,到今天为止,仍然没有一个靠真实世界遥操数据训练出来的模型,能达到我们这个GRASP VLA的零样本抓取能力。
但是我们立即就发现了一个问题:从合成数据的角度上讲,更多的任务超越抓取之后,什么时候能完全合成完?从真机遥操的角度,我在遥操路线刚刚出来的时候就讲过:什么东西都靠遥操是不行的,如果什么都靠遥操,我们很难scaling。
但今天我想说的是,具身智能正在迎来一个非常光明的scaling up的时间点,就是因为WAM(世界动作模型)。WAM跟一般的World Model不太一样:今天大家讲的World Model是一个很宽泛的概念,前几天李飞飞老师也把World Model分成了好几类,有的是当simulator
用的,有的是用于生成视频的。而我们讲的WAM,它是以action为最核心,用未来的预测当做视觉层面对动作的planning。
最关键的是,WAM不需要动作标签。所以你可以想象一个机器人看人干一件事,它虽然没有action label,但是它能把人的行为、大致的course motion学到。这样我们就能大量借用人类的第一视角视频,来帮助我们的具身智能往更多样化的任务、更多样化的场景、更全面的技能去scale up。
这里也说一句:如果大家在arXiv上搜索world action model,全世界第一篇WAM的论文就是银河通用在2025年3月份挂到arXiv上的。这个路线在我今天看来,能够真正把无尽的环境和任务融合进具身的基模训练里头。所以我认为WAM确实定义了一个超越VLA的新范式——因为VLA里所有东西都需要有action label,它的scaling只能靠robot data,但我们今天加入了human data,真正迎来了scaling up的广阔空间。
甚至今年4月份的时候,NVIDIA Gear具身智能实验室的主任,他在红杉的一个演讲里直接就说出来了:robotics 的 end game就是WAM。所以我感觉今天具身智能的预训练正在迎来一个蓬勃发展的状态,因为在数据获取的类型上,我们已经没有局限性了。
我能够预测:往未来看两年,具身智能将全面到达一个从GPT-3.5向ChatGPT转变的关键预训练milestone。所以现在对我们来说是真正好的时机。但这也意味着,行业需要千万小时的高质量数据,以及百亿以上的单年投入,再加上大模型的能力,这三项加起来,才能成为冲刺具身智能"ChatGPT时刻"的入场券。
陈维广:非常兴奋的moment。所以我把这个问题稍微延展一下,是不是根据你这样的分析,意味着现在这些为了"世界模型"融资的公司全部都不靠谱?WAM是不是靠谱?
王鹤:这个WAM也算是一种世界模型。但是我个人看,很多World Model它里面的一些key feature,就比如这个东西能当simulator,让机器人做强化学习。
在我看来,今天不能说全部靠谱,我们也有很多工作是拿World Model当做一个differentiable simulator能够交互的,但是希望World Model先把全世界任何东西都可以simulate,都可以交互,再训出具身智能,我觉得应当不是这样的。
陈维广:还有一个差距.
王鹤:对,因为我们人也不能把全世界所有东西都simulate,都能够精确的知道下一步的物理状态,但我照样可以interact with everything,所以我并不觉得成为一个成熟的world simulator是建立具身智能ChatGPT的前提条件。
陈维广:大海老师,我把那个问题稍微改一下。行业里通常有一个挑战:过去几年大家看到云端在快速scaling,但终端因为资源受限,好像不能scaling?你怎么看?还是说终端和云端其实可以一起scaling?
李大海:首先简单的答案就是:肯定都在scaling。其实面壁提出来的知识密度定律和scaling这两个东西,如果整合一下就是一个公式:大模型的智能整体等于大模型的知识密度乘以它的参数量。
所以我们会看到,在今天还有人质疑scaling到底是不是失效的时候,事实上云端的Coding模型在变得越来越大——我们都知道OPUS的模型越来越大,国内所有的Coding模型也在越来越大。同时我们端侧模型也在越来越大:去年面壁给主机厂落地端侧模型,只能落1个B(十亿参数)的模型,不是我们只能做1B,是因为当时智能终端上能支撑模型跑起来的算力和带宽只有这么大。今天这个模型已经从1B涨到4B了,我觉得明年可能就变成几十B了,速度涨得非常非常快。
端侧其实是资源受限,具身智能本质上也是一个终端,具身大脑也一定是端侧模型。所以这个问题在模型层面上有非常大的scaling空间,受限的只是物理条件。
另外我还想补充一点:就算是大语言模型,在长上下文任务处理上也依然有非常大的空间,现在并没有做得特别好。不用讲复杂的技术细节,大家简单理解:人的大脑处理超长上下文任务做得非常优秀,而且功耗极低,但大模型在这类任务上的成本和效果都远远落后于人脑。这背后的巨大空间,依然要靠Scaling来填补。
所以我们觉得道阻且长,技术远远没有收敛。现在行业里常常会用一些阶段性的认知来制造叙事,但这些叙事的保质期非常短,我们一直在不断打破旧的认知。
陈维广:刚才你说端侧模型从1B涨到4B,主要还是因为端侧的硬件变得更厚了,是吧?
李大海:对,包括我在第一个分享里面,我们也在用更多的技术让模型能够变得更大。因为我的知识粒度变高了,我的各种,比如说我的量化的技术的提升,所以导致我们用更大的模型,量化完以后,它用的内存,用的资源是一样多的。这些都是一些手段。
陈维广:嗯嗯,多问一个问,就是说这里有一个说法,就是从市场上说,端侧模型会起来,主要是因为大家觉得云端模型太贵了,都在想办法把这个计算放到终端,这个理论能成立吗?
李大海:我认为这是Token经济学的一部分。尤其是对于终端厂商来说,这个是一个非常清晰的算账的方式。在中国大家都知道,我们老百姓买手机、买汽车不可能去订阅的。我买了一台手机,我不会再想着说给手机厂商每个月交19块。
所以对于同时想给用户提供很好的设备上的AI体验的设备厂商来说,他就面临这个选择:就是我的后续的成本到底怎么负担?从算账的角度上讲,端和云一定要协同,因为端侧资源有限,不可能做和云端一样的工作。但是但凡端侧能做的,大家尽量还是希望能在端上做,我们这样的成本肯定是最低的。
陈维广:刚才我问的那两个问题,主要还是一些行业的一些看法。不管是做端侧的,云端的,或者是做具身跟AI的,你们能提升这个效率3倍、5倍,甚至10倍都没问题。
可是最终如果出问题的话,因为我们不是在说嘛,agent就会自动化的去审核,如果它出错误的话,谁来背这个黑锅?王鹤老师,你这个机器人很聪明,包括大模型,同样的,对不对?这块,你们有思考过这个吗?或者是有客户提出这个问题吗?至少我知道这些做agent的,时常就被客户挑战。如果完全把这个agent自动的去完成这个任务的话,如果出问题的话,谁来承担这个责任?
王仲远:对,首先其实这让我想起来今天早晨开幕式上,王坚博士的播客访谈,其实也涉及到这个问题,就人和AI到底如何共处?
那么我想一个新的技术的诞生,总会涉及到从人们对它最开始可能担忧恐惧,到后面开始适应或使用它,习惯它,以及它怎么去融入到这个社会,什么样的一个治理体系,什么样的一个政策,能跟这些技术一起来协作?我想,比如说像自动驾驶、辅助驾驶,其实已经开始在以前趟过了一遍这样的一些路,到底权责谁来定?到底是软件厂商的、硬件厂商的,还是用户的?其实AI后续包括智能体也会有类似这样的一个过程和阶段。
更多的是,一方面我们看到了这个技术对于生产力的提升,对于生产效率的提升。当它确实就像您说的,它如果已经提升了3倍、5倍,我想这种技术就一定是没办法被阻碍的,它最终就会在工业,在我们的生活中变得越来越流行,越来越普遍。
另外一方面,到底如果出现了一些故障,或者出现了一些问题,它的责任的划分,这我觉得是整个社会治理体系政策的一些方面,我相信咱们人类已经经过了这么多年,这么多次的技术浪潮,会有办法解决的。
王鹤:我也简单的补充一点,其实机器人在工业自动化当中的应用,跟未来具身智能机器人在各行各业的应用,它既有不同,也有很强的相似性。
如果我们交付给工业客户,他其实不管你是具身的还是传统的,他主要看你做这道工序的成功率是多少。交付了以后,如果比如说在某一个环节失败,导致产线停工,跟员工出错导致产线停工一样,该怎么罚就怎么罚,所以其实如果我们今天是讲对经济活动的一个影响,那很简单,就是具身智能机器人一定要做到像人一样干的好活,并且,在经济任务上能负责任,我想这个是没有问题的。
那么更长远的其实是具身机器人跟人类在一些复杂的决策和又有体力的活,又有脑力活的交互当中,怎么能讲清楚权责?所以我觉得这个,从现在agent的大面积的使用,我相信未来能慢慢的给出我们一个方案。
今天使用这么多Coding agent,那写了bug,到底是谁的责任?那肯定还是使用这个Coding agent的人,他的使用没有做很全面的评测。那未来就是使用这个具身机器人在产线里头,那么谁为它负责?是不是也是这条产线的一个管理者和背后到底是技术漏洞还是管理漏洞为它负责?那么再往更远的未来,全部都是AI,没有任何人类,谁为它负责?我相信我们会一步步的去探索出来背后的体系。
李大海:我来说点让大家毛骨悚然的真话。其实我觉得整个人类社会的发展就是建立在吃一堑长一智的范式上。就是我们现在大家都去坐飞机,飞机上有非常多让人很恼、很讨厌的一些安全规定.起飞降落的时候必须要收起小桌板呀,打开遮光板。为什么会有这些安全规定?都是历史上一次一次的空难,空难以后造成了严重的损害、损失,大家总结出来,原来这样是不安全的,去总结出这些一个一个的规定。
很多时候大家还不理解,事实就是这样,包括在某些交通的路段上,忽然之间限速30,为什么要限速30?因为超过30就特别容易出事故,这都是总结出来的。我觉得这是人类社会运行的一种比较常见的方式。好消息是,其实在人工智能的赋能底下,其实我们去填补安全漏洞,去发现安全的问题的效率也提高了。所以在有了新的技术以后,虽然可能无可避免的还是会先吃亏,再长智慧,还是要付出一些代价。但是我觉得这个代价可能会比以往时候付出的更少,这个是好的方向。
另外,就是我们作为企业,我们看到,其实我们的监管政府对于这些安全底线的工作,其实是非常非常的重视,所以企业在这个方面,从很早就开始考虑自己的社会责任,就已经开始考虑这些问题了。我们从第一天开始要通过网信办的安全备案,其实就要考虑大模型的内容生成是否符合各种各样的内容安全的这样的一个标准,这些都是我认为好的方向,但是总的来说,吃一堑长一智,这件事情可能真的无法避免。总会,安全问题总会从你想象不到的角度出现,给大家一个教训,这个教训再来变成我们让整个社会整个治理更安全的方式。这是我认为大家要理解的事情。
陈维广:说的非常好。我看到我们只有3到4分钟,最后一个问题,咱们嘉宾快速回答,你们从你们的自己的视角,以及你所处的领域,你觉得中国的AI和欧美的AI,最终走出来不一样的地方在哪?仲远院长先来。
王仲远:对,我觉得咱们中国还是有很多很独特的优势,包括像供应链、制造业以及场景,所以其实我们自己本身,整个中国的市场也已经足够大,使得我们能够去孵化和催化很多的技术的产生和落地。当然我们肯定也希望这样的技术能够辐射到全球,所以我自己觉得结合中国的这些优势,像具身智能,像世界模型,很有可能是我们将来会有独特性,且在一定程度上领先的一些领。
王鹤:对,其实我明天在我们这个具身智能与人形机器人的论坛会主要谈这个事。我的talk的名字叫推动embodied AI的AlphaGo和ChatGPT moment。
实际上,我坚信具身智能是中国的机会。具身智能的AlphaGo和ChatGPT Moment,我坚信会在中国实现,这也是我们银河通用和中国具身智能人的责任。如果具身智能的0到1在中国完成,相信1到100必定是在中国成熟的。
李大海:我就补充一个点,就是人才。中国拥有最聪明的青年才俊,并且数量应该也是全球最大的。我觉得这个是最底层最重要的因素。有了这个因素,再加上刚才仲远老师提到的我们的生态,我们的优势,我们的整个供应链。我觉得这些因素叠加在一起,包括政府对于这个领域的重视和搭台唱,我觉得这些因素叠加以后,中国必定会在人工智能领域取得各方面的长足的进步和胜利。
陈维广:对,其实我们最近也做了一个比较,就是美国的这个AI人才跟中国的AI人才,很明显的就是中国的这个年轻化,这块是很明显的。所以看到智源的这个大会每年越办越大,对不对?也有很多这个年轻的研究员踊跃的参加,而且我们投的很多创业公司,他们其实除了这个创始人跟团队,他们其实也跟院校有很多合作,也跟智源这边有很多合作,我觉得这个可能跟美国是最大的不同嘛,这是从我们这边观察到。

微软在 Build 2026 开发者大会上宣布,将全面增强 Azure API Management 的 AI 网关能力"。本次主要新增能力如下:一是推出统一模型 API(Unified Model API),客户端仅需使用一种 API 格式,Azure API Management 即可自动将请求适配为各类后端服务商对应的格式;二是 AI 网关现已支持接入 Anthropic 和 Google Vertex AI 旗下模型;三是内容安全策略升级,防护范围拓展至 MCP 工具调用以及智能体间(A2A)通信,与原有大语言模型流量一并纳入保护。
APIM 团队撰文"指出:
相较于为智能体单独搭建专属治理平台,Azure API Management 可帮助企业将成熟的 API 治理规则直接沿用至新兴的智能体生态体系中。
统一模型 API" 现已进入公开预览阶段,解决了企业团队日益突出的运营痛点——随着团队越来越多地混合使用 OpenAI、Anthropic、Google 等提供商的模型(基于性能、成本、延迟或区域需求方面的考虑),每个提供商暴露的 API 格式各不相同。统一模型 API 让客户端可以统一采用一种格式(目前为 OpenAI Chat Completions),APIM 会透明地将请求转换为后端提供商的原生格式,无论是 Anthropic Messages API 还是其他模式。团队可以更换后端提供商、添加新模型或在不同提供商之间路由流量,都无需修改客户端代码。
这不仅仅是一个简单的功能适配层。将模型访问统一接入单一 API 接口后,无论由哪家服务商执行推理,所有治理策略、限流规则、内容安全检测与令牌用量统计都可统一生效。已经使用 APIM 进行传统 API 治理的组织可以将相同的模式延伸至 AI 工作负载,无需额外引入独立的治理体系。
内容安全能力向 MCP 与 A2A 场景延伸是本次架构层的 llm-content-safety 策略原本用于对照 Azure Content Safety 扫描 LLM 请求和响应内容,现在已同步覆盖 MCP 工具调用参数、MCP 响应文本以及 A2A 智能体交互载荷。同时,该策略包含两层独立安全防护:分类内容过滤,针对仇恨、自残、色情、暴力四类内容进行管控,支持设置风险等级阈值,范围为 0(最严格)至 7(最宽松);独立的 shield-prompt 属性,用于识别对抗性提示词注入攻击。典型配置示例如下:
团队需要注意的一个实现细节,即该策略在流式响应中的行为有所不同。在非流式模式下,一旦检测到违规内容,系统会直接返回 403 状态码。在流式模式下,策略会在滑动窗口中缓冲事件",并直接停止向客户端转发后续事件,且不会返回错误信息。因此,使用流式补全能力的智能体需适配这种内容中断的情况,不能依赖错误码做判断。两个新增的属性 window-size 和 window-overlap-size 可用于调整超长内容的拆分规则,适配 Azure 内容安全服务 10000 字符的评估上限。
词元统计指标已进行了升级,适配多提供商的使用场景。APIM 现在会将推理词元、缓存词元和音频词元记录到 Application Insights,支持 OpenAI Chat Completions、OpenAI Responses 和 Anthropic Messages API 等格式,可监控 Microsoft Foundry、OpenAI、Amazon Bedrock、Google Vertex AI 等多加服务商。对于需要构建成本仪表盘和预算警报的 FinOps 团队来说,扩展后的指标能够反映当前模型的实际行为——推理和缓存消耗了大量早期指标未能捕捉的词元预算。
在资源发现方面,Azure API Center 数据平面 MCP 服务器已正式发布(GA)"。它可作为企业统一的资源发现端点:智能体和开发者工具可以通过单个 MCP 连接访问已注册的 MCP 服务器、工具、API、智能体及各类 AI 资产。当团队在 API Center 注册新的 MCP 服务器时,所有已连接的智能体都能自动发现它,无需逐个客户端重新配置。
APIM 现在还支持将已有的 REST API 暴露为 MCP 服务器",这意味着早于智能体时代的企业 API 无需重构即可被智能体调用。结合本次在 Build 大会上正式发布的 Logic Apps MCP 服务器",微软正在构建两条并行路径,帮助企业对接智能体:一条通过 API 网关层(APIM),另一条通过集成平台层(Logic Apps)。
对于正在评估 AI 网关方案的团队来说,行业竞争态势具有重要参考意义。亚马逊云科技的 Bedrock Guardrails 用于内容过滤和模型访问控制,但暂无产品可对标 APIM 的多厂商统一模型 API,以及针对 MCP、A2A 的全维度内容安全能力。谷歌的 Apigee 已添加一些 AI 网关功能,但尚未达到 APIM 现在覆盖的协议广度。Cloudflare 的 AI Gateway 侧重成本管控与缓存能力,而非多协议治理。APIM 的核心思路是:API 网关(而非全新品类产品)才是承载 AI 工作负载的天然控制平面。
AI 网关能力在所有 APIM 层级中均可用。统一模型 API 处于公开预览阶段。针对 MCP、A2A 的内容安全功能、升级后的词元指标以及 API Center MCP 服务器已正式发布(GA)。AI Gateway 实验室"提供 30 多个实操 Jupyter Notebook,包含分步说明和可部署的 Bicep 模板。
查看英文原文:https://www.infoq.com/news/2026/06/azure-apim-ai-gateway-build/"


2026年,电信运营商面对AI的焦虑,已经不再只是“有没有大模型”“智算中心建得够不够”“AI能不能降本增效”等技术问题,而是更深层的经营问题:当AI重塑应用入口、业务流程、客户交互和价值分配方式时,运营商能否继续掌握客户关系、计费能力、云网资源、安全能力和产业协同地位。
近期,运营商围绕AI的动作明显加快。中国移动发布Token运营生态体系,提出Token套餐、统一Token量纲、打通Token鉴权,探索连接Token供给与消费的统一运营平台;三大运营商也围绕Token、云电脑、智能体工具和安全服务推出组合产品。与此同时,中国移动等产业资本参与月之暗面 Kimi 新一轮融资,说明运营商正在通过资本和产业协同进一步接近大模型生态。
这些现象说明,运营商的AI焦虑,本质上不是“是否跟上AI热点”,而是“能否在AI产业链中避免再次底层化”。移动互联网时代,运营商提供网络和流量,但大量应用层价值被互联网平台获取。AI时代,如果运营商仍然只提供机房、带宽、云主机和GPU资源,而模型厂商掌握智能能力,云厂商掌握平台生态,智能体厂商掌握任务入口,终端厂商掌握交互界面,那么运营商仍可能面临“重资产投入、低价值回报”的困境。
因此,运营商应对AI焦虑,不能只靠建设几个大模型、采购几套AI平台、上线几个智能客服,而要把AI纳入主营业务重构。未来的核心命题,是把连接、算力、数据、模型、智能体、安全、渠道和计费能力重新组合,形成面向个人、家庭、中小企业和政企客户的新型智能服务体系。
一、Token套餐:从卖流量走向智能额度经营
Token套餐的出现,是运营商AI商业化的重要起点。它并不意味着运营商已经完成从“卖流量”到“卖算力”的彻底转型,更准确地说,是AI调用额度开始被运营商商品化、套餐化和账单化。
过去,运营商主要经营分钟数、短信、流量、宽带、专线、云资源和安全产品。AI时代,Token、模型调用、推理任务、知识库容量、智能体执行次数、AI云桌面和安全审计,正在成为新的计量对象。Token套餐的价值,不只是多了一个销售品类,而是让运营商熟悉的实名账号、账单支付、客户分层、渠道触达、客服体系和套餐运营经验重新发挥作用。
个人用户可以购买AI助手额度,中小企业可以购买AI办公包,开发者可以购买模型调用服务,政企客户可以购买模型网关、知识库、推理服务和安全审计能力。传统流量经营关注“用户用了多少GB”,AI服务经营则关注“用户完成了多少智能任务、消耗了多少模型调用、触发了多少推理服务”。这意味着运营商的经营对象正在从单一连接资源,扩展到智能服务过程。
但Token套餐仍处在探索期。用户是否愿意持续付费,套餐能否与宽带、云电脑、云盘、安全、终端和办公场景形成组合价值,运营商能否控制模型调用成本和服务体验,仍需要市场验证。因此,Token套餐不是终点,而是运营商进入AI服务经营的入口。
二、模型生态:从采购大模型走向参与模型产业链
中国移动参与Kimi融资,说明运营商正在从单纯采购模型、使用模型,向参与模型生态协同迈进。这件事的意义不在于运营商要亲自成为大模型公司,也不意味着运营商已经掌握大模型核心能力,而在于运营商开始意识到:AI时代不能只站在模型产业链的下游。
单纯采购模型,运营商只是使用者;单纯建设算力,运营商容易陷入重资产竞争;只做政企项目,运营商又可能回到定制化交付和低复制率的老路。更合理的路径,是建立多模型接入、统一调度、统一计费、统一评测、统一安全和统一交付能力。
模型厂商提供基础智能,运营商提供云网资源、账号体系、账单能力、渠道体系、安全合规、属地交付和行业客户关系。双方结合,才可能把AI能力变成可销售、可运营、可审计、可复制的业务产品。未来领先的运营商,不一定是模型参数最大的企业,而可能是最擅长把多家模型能力整合成行业服务的企业。
三、智能体生态:从运营商APP走向智能体调用
AI从问答走向智能体,是运营商必须重视的趋势。大模型问答改变的是信息获取方式,智能体则进一步改变任务执行方式。它可以调用工具、操作软件、连接文件、访问系统,并在一定权限范围内完成连续任务。
“从运营商APP走向智能体调用”不应理解为APP立即消失,而应理解为入口结构发生变化:运营商APP仍然承担实名、账单、套餐、权益、客服、合约、积分和家庭业务等强账户功能,但未来一部分客户需求可能先由智能体提出,再调用运营商后台能力完成。
运营商切入智能体生态应分两步。第一步,是成为智能体运行环境的提供者,把云电脑、Token套餐、宽带、5G-A、安全能力打包成基础服务。第二步,是建设面向智能体的业务能力接口,把套餐查询、账单解释、故障报修、宽带测速、专线开通、云资源订购、Token充值、安全告警等能力封装成可授权、可校验、可审计、可回滚的工具接口。未来入口竞争的关键,不只是用户是否打开运营商APP,而是运营商能力能否出现在用户的智能体工作流中。
四、个人市场:从流量权益走向AI权益
个人市场长期面临流量增长放缓、套餐同质化和价格竞争压力。AI带来的机会,不是简单赠送一个聊天机器人,而是为套餐权益增加新的差异化内容。
过去,个人套餐权益主要包括流量、语音、宽带、视频会员、云盘和家庭组网。未来,AI权益可能逐步进入套餐结构:学生用户需要学习助手、编程助手、口语陪练;职场用户需要文档总结、PPT生成、会议纪要、邮件助手;家庭用户需要AI云盘检索、相册整理、家庭知识库和智能家居控制;老年用户需要反诈提醒、语音助手和生活服务导航。
但这仍然需要市场验证。用户是否愿意为AI权益持续付费,取决于服务是否高频、稳定、易用,并且能否和通信账户、家庭宽带、云盘、终端、支付和客服体系打通。运营商应避免把AI权益做成短期营销赠品,而应进行分层设计:基础权益用于增强套餐吸引力,高阶权益用于提升ARPU,家庭权益用于绑定宽带和云盘,安全权益用于形成差异化。
五、中小企业市场:从企业宽带客户走向AI办公客户
中小企业是运营商AI商业化中较现实的增量市场。大型企业有IT团队和预算,可以直接采购云厂商、模型厂商和咨询公司的服务;中小企业则更需要低门槛、标准化、可开票、可售后的一站式AI服务。
运营商已有企业宽带、云电脑、企业邮箱、视频会议、语音专线、云主机和网络安全等产品基础。如果在此基础上叠加AI客服、AI营销、AI文档、AI合同、AI财务问答、AI知识库、AI短视频生成和AI编程助手,就有机会把传统连接客户逐步升级为AI办公客户。
这类业务的关键是轻交付和标准化。中小企业不愿意研究模型API、向量数据库、私有化部署和复杂安全策略,它们需要的是“开通即用、按月付费、出了问题有人管”的服务。运营商可以发挥客户经理、营业厅、线上渠道、政企服务团队和属地售后优势,把AI办公能力做成可复制产品,而不是重新陷入定制化项目。
六、政企市场:从项目交付转向智能体运营
政企市场是运营商AI转型的重要阵地,但不能简单认为项目制会立刻消失。现实中,政企数字化仍以平台建设、系统集成、定制开发和项目交付为主。AI带来的变化,是推动运营商从“交付系统”逐步走向“运营智能服务”。
政务、园区、制造、交通、应急、教育、医疗等领域,都有智能体应用空间。例如政策问答、热线工单、基层材料、城市治理、招商服务、能耗管理、设备维护、质检分析和供应链协同。但这些应用能否真正落地,不取决于演示效果,而取决于是否接入真实业务流程,是否具备知识更新、权限控制、日志审计、人工复核、效果评估和安全兜底能力。
运营商在政企市场的优势是云网资源、安全合规、属地交付和客户关系;短板是行业知识深度、产品化能力和模型生态丰富度。因此,运营商不能只做传统总集成,也不能只卖大模型平台,而应向“行业智能服务运营商”演进,持续运营知识库、模型调用、工具接口、安全审计和服务效果。
七、AI安全:从合规成本走向可信卖点
智能体越强,安全风险越高。它一旦能够访问文件、账号、浏览器、企业系统和本地数据,就可能带来越权操作、敏感信息泄露、恶意指令注入、供应链投毒和高危行为失控等风险。中国电信发布天翼智安·智能体安全解决方案,面向已部署或计划部署OpenClaw类智能体的用户,强调全流程管控、实时防御和行为溯源能力。
这对运营商是重要机会。相比互联网AI公司更强调模型能力和应用体验,运营商更适合突出可信、合规、稳定、可审计、可长期服务。未来,模型调用审计、敏感数据脱敏、智能体权限控制、提示词攻击检测、模型网关、数据不出域部署、可信身份认证和异常行为监控,都可能成为运营商AI安全产品的重要组成部分。
对于政府、金融、能源、教育、医疗等客户,安全可信往往比模型炫技更重要。AI安全不是运营商的附属能力,而可能成为运营商参与AI产业竞争的核心卖点。谁能提供更可靠的身份认证、更细粒度的权限控制、更完整的日志审计和更稳健的应急处置,谁就更容易在政企AI市场中建立差异化。
结语:把AI焦虑转化为增长机会
电信运营商的AI焦虑,并不是因为AI太强,而是因为AI正在改变运营商熟悉的商业规则。Token套餐说明AI调用额度开始进入运营商计费体系;大模型融资中的运营商身影说明运营商正在接近模型生态;OpenClaw类智能体热潮说明AI应用正在从问答走向任务执行;智能体安全产品的出现,则说明可信治理正在成为新需求。
但这些现象不能被简单放大。Token套餐不等于运营商已经完成算力经营转型;云电脑内置智能体不等于运营商APP入口已经被替代;参与大模型融资不等于运营商掌握模型生态;政企智能体试点也不等于传统项目制马上结束。
更稳妥的判断是:运营商正处在从连接经营走向智能服务经营的早期阶段。未来领先的运营商,不一定是模型参数最大的企业,也不一定是智算中心建得最多的企业,而是最早把AI能力转化为可计费、可交付、可运营、可审计、可复制服务的企业。
运营商真正要回答的,不是“有没有大模型”,而是有没有AI产品体系、Token计费体系、智能体承载与接口体系、可信推理平台、行业知识库和生态协同机制。谁能把连接、算力、数据、模型、智能体、安全和行业场景整合起来,谁就能把AI焦虑转化为下一轮增长机会。

随着数字经济纵深发展与生成式人工智能技术的普惠化落地,市场主体形态与产业创新创业范式被逐步重塑。AI-OPC(人工智能一人公司)作为依托大模型、AI智能体、低代码工具实现全链路自主运营的新型单人市场主体,突破了传统企业的组织边界与成本约束,成为新质生产力微观落地的核心载体。截至2025年底,国内AI-OPC主体数量已突破386万户,呈现指数级爆发增长态势,标志着“单人+AI”的轻量化创业时代全面到来。不同于传统小微企业,AI-OPC的核心生产资料由人力、场地、设备转向算力、模型、数据与网络资源,其生存发展高度依赖智能化数字基础设施。这一产业变革彻底重构了电信行业的价值场景,加速推动运营商从传统通信管道服务商,向人工智能时代的产业基础设施服务商转型。
“AI-OPC”兴起,重塑数字产业底层格局
AI-OPC的规模化崛起,并非简单的市场主体数量增长,而是数字经济生产要素、生产关系与产业分工体系的系统性重构,具备深刻的产业变革内涵。从生产要素维度来看,传统创业模式依赖资本、人力、实体资源,存在准入门槛高、运营成本高、扩张难度大的痛点;而AI-OPC以人工智能为核心生产力,通过大模型赋能研发、以智能体替代重复性运营工作、以低代码工具降低技术门槛,实现了生产力的轻量化、普惠化释放,彻底打破了创新创业的资源壁垒。
从生产关系维度分析,AI-OPC重构了产业组织形态,实现了“去组织化、轻量化、柔性化”的新型生产模式。传统企业依赖完整的组织架构、岗位配置与流程体系,而AI-OPC依托AI工具完成全业务闭环,以最小的组织单元实现市场化经营,极大提升了数字经济的创新效率与资源利用率。这种新型市场主体的爆发式增长,意味着数字创新不再局限于大型科技企业与规模化机构,个体创新力量被全面激活,形成了“全民AI创新”的全新产业格局。
从产业需求维度研判,AI-OPC的轻量化运营模式伴随天然的资源短板。单人主体普遍存在算力储备不足、模型适配能力薄弱、数据治理体系缺失、合规风控能力缺位等问题,无法自主承载AI全链路生产需求。这种“强创新需求、弱基础设施”的供需错配,形成了全新的产业缺口,也为电信运营商的服务迭代与生态扩容提供了核心赛道。可以说,AI-OPC的产业特性,决定了其发展必须依托专业化、普惠化、全栈式的公共数字基础设施,而这正是电信行业的核心能力禀赋。
运营商该如何构建“AI-OPC+电信服务”生态体系
运营商构建AI-OPC服务生态,并非单一的业务拓展,而是基于产业共生理论、价值网络理论的战略升级。
一方面,电信基础设施是AI-OPC规模化发展的核心底座与必要前提。AI-OPC的核心生产行为均依托网络传输、算力调度、模型运算、数据交互完成,对网络的低时延、高可靠、广覆盖,算力的弹性化、普惠化、可调度性,数据服务的合规性、安全性、高质量性存在刚性需求。经过多年布局,国内运营商已建成全域覆盖的5G-A网络、全国一体化算力网络、云网融合基础设施与成熟的网络安全体系,形成了其他市场主体无法替代的全栈基础设施能力。运营商通过算力托管、模型微调、数据治理、合规审计、边缘计算等普惠服务,能够系统性弥补AI-OPC的能力短板,大幅降低个体AI创业的技术门槛、资金成本与合规风险,为AI-OPC的可持续发展筑牢底层支撑。
另一方面,AI-OPC的规模化集聚为电信行业转型提供了核心场景与增量价值。长期以来,国内电信行业进入流量存量竞争阶段,传统语音、宽带、流量业务增长空间持续收窄,行业亟需突破传统经营模式,构建新型增长曲线。AI-OPC海量、分散、轻量化、高频次的服务需求,推动电信服务从传统的“管道收费、流量计费”模式,向“算力计费、Token计费、能力订阅”的新型商业模式迭代。同时,千万级AI-OPC的多元化应用场景,能够持续反哺算力网络优化、大模型能力迭代、数据服务升级,推动运营商从基础通信服务商,升级为算力服务商、AI生态运营商、数字产业服务商,实现行业价值的根本性重塑。
更深层次来看,二者的融合是新质生产力落地的重要实践。运营商的基础设施能力代表数字经济的“硬底座”,AI-OPC的个体创新活力代表数字经济的“软创新”,软硬结合能够打通“基础设施供给—轻量化创新应用—产业场景落地—技术迭代升级”的正向循环,推动AI技术从高端产业下沉至千行百业的个体场景,实现人工智能的普惠化落地,助力数字经济高质量发展。
服务模式革新:从管道供给向AI生态运营的转型突破
面向AI-OPC生态的发展需求,传统单一的通信服务模式已完全无法适配,运营商必须完成服务逻辑、产品体系、商业模式、服务形态的全方位革新,构建适配轻量化AI创业主体的新型电信服务体系。
在服务逻辑上,实现从“标准化管道服务”向“定制化全生命周期赋能”转型。传统电信服务以标准化网络、带宽、流量产品为主,服务对象以大中型企业与公众用户为主,服务模式同质化严重。而AI-OPC的业务场景多元、需求碎片化、运营轻量化,对服务的灵活性、普惠性、定制性要求极高。基于此,运营商需摒弃传统标准化服务思维,立足AI-OPC创业筹备、研发生产、运营服务、合规发展的全生命周期,构建一站式、全栈式、轻量化的赋能服务体系,实现从“提供网络资源”向“赋能产业创新”的思维跃迁。
在产品体系上,实现从“单一通信产品”向“算力+模型+数据+安全+应用”全栈产品矩阵升级。依托云网融合、边缘计算、智能算力核心能力,运营商需重构产品体系,打造适配AI-OPC的普惠算力产品、轻量化模型服务、合规数据治理服务、智能安全防护服务与低代码应用服务。区别于互联网企业的单一模型服务,运营商产品的核心优势在于“网、算、数、智、安”的深度融合,能够为AI-OPC提供一体化、无壁垒、高安全的综合解决方案,解决个体创业者技术零散、资源割裂、安全无保障的痛点。
在商业模式上,实现从“刚性计费”向“弹性普惠化价值计费”革新。针对AI-OPC资金有限、按需使用的经营特点,运营商需打破传统固定套餐计费模式,推行按需调度、按量计费、弹性扩容的算力Token计费模式,推出梯度化、轻量化、低成本的普惠服务套餐。通过基础服务免费、增值服务订阅、定制服务付费的分层模式,最大化降低AI-OPC的创业成本,同时依托海量小微用户形成规模化、可持续的新型营收体系,构建电信行业增量增长模型。
构建多元协同的“AI-OPC+电信”产业生态治理体系
“AI-OPC+电信服务”并非简单的供需匹配,而是需要构建多方协同、共创共享、合规有序的产业生态体系。运营商作为生态核心枢纽,需发挥基础设施主导优势,联动政府、产业伙伴、服务机构、创业主体,构建层次清晰、协同高效的生态格局,破解单一主体发展的局限性。
首先,构建政企协同的政策赋能生态。AI-OPC作为新型市场主体,行业规范、扶持政策、监管体系仍处于完善阶段。运营商需主动对接地方数字经济发展战略,联动政府部门搭建AI-OPC培育载体,争取算力补贴、创业扶持、税收优惠等政策资源,将政策红利与电信服务深度融合,打造政策赋能、基础设施赋能双向叠加的发展优势,引导AI-OPC行业规范化、集聚化发展。
其次,构建产业联动的技术创新生态。运营商需秉持开放共享的生态思维,打破技术壁垒,聚合大模型厂商、AI技术企业、低代码开发平台、行业解决方案服务商等生态伙伴,形成能力互补、场景共建、价值共享的产业联盟。通过开放算力调度平台、模型接口、数据资源,吸引生态伙伴聚焦AI-OPC细分场景开展技术创新,丰富垂直领域服务能力,解决通用AI服务与行业细分场景适配不足的问题,完善生态技术供给体系。
再次,构建全链条的创业服务生态。AI-OPC的发展不仅需要技术与算力支撑,更需要合规、金融、运营、知识产权等配套服务。运营商可整合金融机构、律所、会计师事务所、创业孵化器等资源,搭建一站式创业服务平台,补齐AI-OPC运营服务短板,形成“算力底座+技术赋能+配套服务”的完整生态闭环,全面提升个体AI创业的存活率与发展质量。
最后,构建底线可控的安全合规生态。AI技术的普惠化发展伴随数据泄露、模型侵权、内容违规、网络攻击等多重风险,而AI-OPC个体风险抵御能力薄弱,是行业合规风控的薄弱环节。运营商需依托自身成熟的网络安全与数据合规能力,构建覆盖数据全生命周期、模型应用全流程、网络运营全场景的安全合规体系,提供合规审计、风险排查、安全防护、隐私保护等专业化服务,以技术能力筑牢行业发展底线,推动AI-OPC生态健康、有序、可持续发展。
AI-OPC的爆发式崛起,是人工智能技术普惠化、数字经济轻量化发展的必然结果,彻底改变了传统产业创新创业格局与数字基础设施的应用场景。对于电信行业而言,这既是行业转型的重大机遇,也是央企赋能新质生产力发展的核心使命。未来,运营商需持续突破传统服务思维桎梏,以算力网络为底座、AI能力为核心、生态协同为路径、安全合规为底线,持续完善“AI-OPC+电信服务”生态体系,完成从通信管道服务商向AI产业生态运营商的战略转型,为数字经济高质量发展与人工智能产业普惠化落地提供坚实支撑。
随着大语言模型的发展,数据智能体已成为推动中国企业革新的关键力量。因此,采用这一技术对于实现代理型D&A至关重要。数据智能体可执行数据管理、数据准备以及数据分析等一系列任务,其采用程度与技术自治水平将会不断提升。
数据分析将成为当前市场中自治程度较高、且最主要的使用场景,尽管距离完全自治仍有较大差距。这一技术目前的发展程度已超越简单的“对话式界面”,迈向能够主动规划任务、执行分析、调用工具并持续学习的智能体。这有助于提升生产力,并推动成本节约或收入增长。
通过利用企业知识与基于大语言模型(LLM)的推理,数据智能体可以自动化复杂的D&A工作流,以面向任务的自主服务替代部分传统工作。D&A领导者必须探索这一趋势,明确适用范围并学习新技能,为未来的采用做好准备。为此,Gartner给出以下三点建议:
在对数据智能体进行设计和分类时,应设定清晰的范围、类别和功能,以界定决策范围,降低运营风险。
定义数据智能体工作流,并在其中设置强制性的人类审核环节,例如执行前后的评估与反馈循环,以留下可审计的痕迹。
优先将数据智能体部署在数据准备度和业务价值较高的领域,例如财务自动化或客户服务优化,这些领域已有成熟案例可供参考。
数据智能体代表着超越传统数据与分析实践的下一进化阶段,有望吸收大量常规报告与汇总数据表的使用需求,并为企业机构的数据环境注入更高的智能化、自主性与可组合性。Gartner提出以下三点预测:
到2028年,60%的现有数据汇总表将被生成式AI驱动的叙事与可视化功能所取代。
到2027年,70%在生产环境中的数据智能体基于开源LLM构建,并成功部署RAG、语义层、领域上下文工程与专业技能。
在企业AI组合中纳入中国LLM和多模态模型的全球企业占比将从2025年的5%上升至2027年的50%。
中国的数据智能体是一种数据和分析(D&A)实践(或设计框架),由LLM驱动,具备知识理解、自动规划和自我反思能力,能够自主执行广泛的D&A任务。
数据智能体的兴起标志着走向D&A任务民主化的关键一步。尽管已经取得了显著的进步并拥有广阔的前景,“数据智能体”一词在学术界和工业界的使用仍未统一。如果没有一个通用的分类法来按范围和职责区分数据智能体,可能会导致用户期望不匹配和问责风险,并进一步打击市场信心,最终减缓这一新兴技术的采用。应对这些挑战需要为数据智能体分类建立清晰、通用的语言,主要侧重于在数据管理、数据准备和数据分析三方面相互关联的任务。
与一般的AI智能体类似,数据智能体通过解释用户问题、将其分类为子任务并评估所需工具来进行规划。在执行过程中,智能体不断进行推理以改进其策略,直至任务完成,并自主决定何时终止任务。此外,它还模拟类似人类的记忆,通过执行特定的操作(例如与外部环境交互或调用工具)来存储信息。这些行动受其规划和记忆能力的指引。下列关键数据智能体模块构成了端到端的数据智能体工作流(见图1)。
图1:数据智能体工作流(示例)
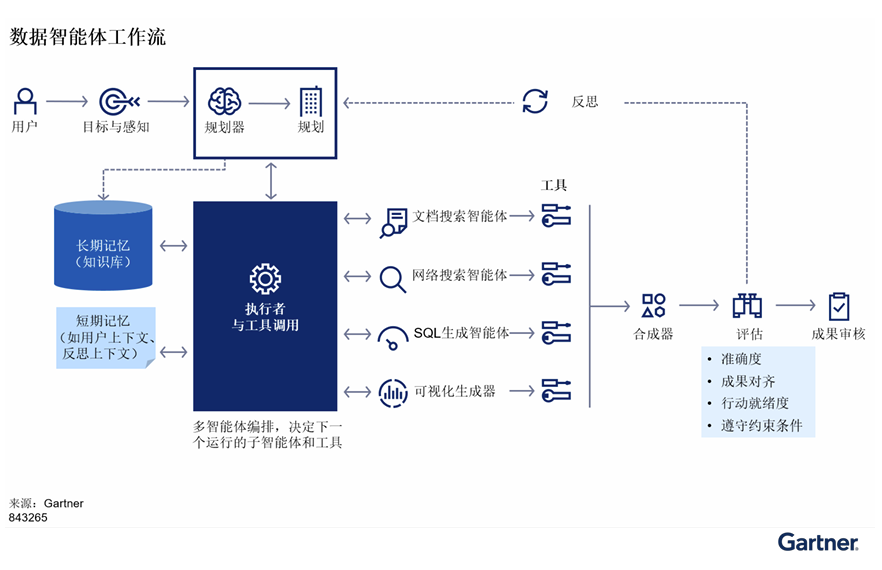
感知:感知模块是数据智能体的“眼睛和耳朵”。在运行时,它结合环境、知识和工具的上下文来解释业务问题和目标,并通过离线微调或业务提示模板(或智能体技能)进行对齐。
规划:规划模块充当数据智能体的“战略大脑”。基于对问题和目标的解释,它将制定策略并生成涉及决策的多步计划。每个决策可能需要进一步探索推理/规划或调用工具。规划应具有自适应性,并在出现新证据或假设被打破时允许重新规划。
执行:执行模块是数据智能体的“运动皮层和肌肉”。它指导计划执行、分配特定领域的子智能体、管理运营物流,并为复杂任务编排多个子智能体。
工具调用:工具调用模块充当“使用工具的双手”。这代表了数据智能体通过外部资源实现扩展的能力。
记忆:记忆模块是智能体的“海马体和长期记忆”。这是经验存储系统,包括长期记忆(如特定领域和环境知识)和短期记忆(如用户上下文和反思上下文)。
反思:反思模块类似于人类的“内省”。不断改进智能体使其变得更聪明至关重要。自我完善的实现依赖于自我反思、强化学习和奖励模型技术。
作者: Gartner 高级首席分析师 费天祺
Gartner 管理副总裁 孙鑫
Gartner 高级研究总监 顾星宇
Gartner 高级研究总监 方琦
爱立信Ericsson Forum路演中国首站启幕。活动期间,爱立信全球技术专家将携手三大运营商及产业链伙伴,围绕AI规模化应用下的网络建设、技术创新与产业协同、6G推进等展开深度研讨。本次路演汇聚前沿技术洞察、专业干货分享,并结合本土需求定制实战演示,为产业携手破局、共探发展新机遇搭建了交流平台。
移动连接不是看客,而是主角

爱立信中国区总裁方迎表示:“从通信行业来说,以AI和Token经营为重心的新的赛道正开启。在这一轮变革中,移动连接不是看客,而是主角,先进连接技术与AI的结合将进一步重塑全球经济格局。下一阶段的关键,是让AI触达并融入新一代应用与设备中,由于其更加分布式、实时化和场景化的特点,因此必须依赖先进的连接技术支撑,意味着网络已不再只是支撑连接的底层设施,而正在成为AI规模落地的关键底座”。
既要深化5G,也要提前布局6G

爱立信亚太区CTO Magnus Ewerbring强调了智能网络底座的重要性。在《智能网络基座-无处不在的6G与AI》演讲中,他阐明移动网络是连接 AI应用的核心底座,需以无时不在的可靠连接,支撑多模态AI、物理AI、增强现实等应用走向普及。对于通信网络的未来,他指出通信行业需兼顾当下与未来,既要推动5G业务持续深化,也要提前布局6G,做好频谱资源预留与技术标准规划,为下一代通信技术的发展筑牢基础。
全栈AI让原生AI RAN变为现实

爱立信东北亚区网络产品总经理Matteo Fiorani介绍了爱立信最新推出的全栈AI解决方案,从networks for AI到AI for networks,其中AI in RAN可将电信级AI模型部署至现网的基带单元与射频单元,实现微秒级的实时推理。这套可规模化商用的原生AI RAN解决方案能让电信运营商快速赋能并差异化各类mobile AI应用。
差异化连接是业务新范式,自智网络是运营新范式

AI时代,网络发展趋势也在发生变化。爱立信东北亚区网络服务总经理吴日平表示,AI时代通信行业的核心发展方向为差异化连接与自智网络,前者助力运营商增收、提升行业竞争力,后者可降本增效、赋能新型业务。他预判2030年L4级高阶自智网络将成为行业刚需。Ericsson AN赋能网络运营变革,已经进行超1亿次AI推理,覆盖1100万个小区,为约20亿用户通过AI优化网络体验,未来将持续赋能运营商网络智能化转型。
5G重塑企业网络基座,多领域实现落地应用

爱立信企业无线解决方案事业部亚太区CTO John Hopping围绕《5G重塑企业网络基座》分享观点。他表示,面对物理AI、工业自动化等新兴应用对低时延、高带宽、高安全的严苛需求,传统网络已难以适配,5G专网正成为企业数字化转型的核心底座。依托5G专网、大规模天线阵列、边缘AI推理、零信任安全等技术的相关方案已在港口、工业制造、矿业等领域落地应用。
AI+差异化连接助力运营商下一波增长

爱立信中国咨询服务部总经理莫文莉表示,未来3至5年,以5G专网为主的企业数字化服务、消费端差异化连接服务是运营商最看好的增收领域。目前全球差异化连接商业落地走向成熟,优质体验让服务溢价成为可能,而AI眼镜、具身智能等AI新应用,也对网络提出大上行、低时延、边缘算力等更高的能力要求。AI时代的网络连接将不仅仅是基础设施,更是体验的保障,价值的承载,以及运营商独特竞争力的体现。AI和差异化连接的双向赋能将助力运营商把握下一波增长机遇。

Ericsson Forum媒体发布环节,爱立信东北亚区副总裁吴立东、中国移动设计院无线所技术总监张琪璇、爱立信中国区网络方案部总经理倪子铭围绕爱立信与中国移动在山东德州开展的网络切片测试展开了交流。该测试重点在山东德州开展切片、资源预留等技术验证,覆盖校园、车站、大型活动等人流高负荷场景,以及云游戏、AI眼镜、上行直播等大上行、低时延业务。实测数据表现符合理论预期。对比没有配置切片的用户在上行直播中存在的卡顿现象,启用切片服务后用户网络速率显著提升,有效解决直播卡顿问题,大幅优化了用户体验。目前,该技术已具备大规模商用条件,未来还可应用于低空经济、具身智能、AI流量经营等领域。
2026年是爱立信创立150周年。依托汇聚全球顶尖行业专家与分享全球创新经验的Ericsson Forum China,爱立信凝聚了更多行业共识与力量。首站活动之后,系列活动将持续面向电信运营商开展,共同筑牢智能网络底座这一关键基础设施。
过去一年,AI 的主战场已悄然发生位移:
它正从单一功能的交付,走向多 Agent 协作的生态网络重组;
从提升个人生产力,走向重构企业底层的运行范式。
今天的决策者,不仅在管理一个产品,更在重构一家 AI-Native 的企业。正是在这个跨越传统的节点上,我们把全球产品经理大会正式更名为「奇点智能产品大会」——不是为了新鲜,而是为了更准确地命名时代。

大会官网:https://pm-summit.org/
全球产品经理大会正式更名为「奇点智能产品大会」
我们把“奇点”放进名字里,是因为越来越多的产品人正在共同经历一个清晰的拐点:AI 不再只是效率插件,而是正成为产品的底座能力;不再只是一次性功能,而是贯穿数据、系统、组织与商业模式的长期工程。“奇点”不仅代表着技术指数级跃迁的临界点,更寓意着新物种、新秩序的诞生。更名后的奇点智能产品大会,将摆脱传统产品管理的框架束缚,更加专注于 AI 原生时代的硬核实践、商业闭环与人机协同探索。7 月 17-18 日,2026 奇点智能产品大会将在北京金隅喜来登大酒店正式召开。在这里,我们将探讨如何把智能化转化为真正可落地的产品价值,关注更具体、更硬核、更可复用的三件事:
·AI 原生产品怎么设计、怎么交付;
·Agent 时代的软件形态怎么重塑;
·面向真实业务的增长与商业模式怎么跑通。
首批嘉宾重磅官宣
在这场深刻的变革中,总有一些探索者走在最前线。他们或在一线公开构建颠覆性的 AI 工具,或在企业内部推动生产力流程的重组。他们带来的不是纸上谈兵的理论,而是历经市场检验的实战心法。以下为 2026 奇点智能产品大会首批官宣演讲嘉宾。

2026 奇点智能产品大会首批官宣演讲嘉宾
议题征集,期待你的独特视角
如果你也在一线做 AI 产品——不管是 Agent、企业级智能、AI 原生工作流,还是多模态、具身智能与硬件——我们都欢迎你把真实问题与实战案例带到现场。奇点智能产品大会的舞台,想留给那些“做出来的人”。
我们在征集什么?
我们寻找这样的议题:拒绝空泛的概念,多一些代码与产品结合的真诚复盘、失败教训的沉淀、以及可量化的核心数据。
讲师权益: 获得大会 VIP 门票及专属礼遇、与全球顶尖 AI 产品人深度社交、个人及品牌影响力的广泛传播。
议题 & 嘉宾推荐/自荐方式:
手机/微信: 17717518733
电子邮箱: hemiao@csdn.net
邮件主题: 2026 PM Summit 议题申请-姓名-公司-议题方向
你可以提交:
·一个可复用的方法论(框架/流程/评测体系/飞轮);
·一个可验证的实战案例(指标、成本、效果、踩坑与修复);
·一个尚未有标准答案但足够真实的难题。
参会有礼:与时代同行者共创
为感谢陪伴大会一同成长的高质量读者与同行者,我们特别推出“共创未来”限时福利:
·分享有礼: 转发本文至朋友圈(不设分组),截图发送至后台,即可免费获得《AI 时代产品经理进化指南及往届大会珍贵演讲 PPT 合集》一份。
·推荐/自荐讲师礼遇: 成功推荐讲师并最终确认议题入选的读者,将直接获赠价值 5999 元的大会 VIP 线下通票一张。
·首批早鸟票: 目前大会早鸟票通道已正式开启,扫码即刻锁定北京金隅喜来登大酒店的现场席位,与千位同行者共同见证奇点降临。
虽然 AI 让很多事情变快了,但产品的本质反而更加清晰:你交付的不是“功能”,而是一个能持续产生价值的系统。7 月 17-18 日,我们在「奇点智能产品大会」现场,等你把答案讲出来。

2026 年的企业 AI 市场,正在经历一场悄无声息的叙事转换。
两年前,几乎所有科技峰会的主角都是大模型:参数多少亿、上下文窗口多长、benchmark 排第几。企业关心的问题是 AI 能不能做。到了 2026 年,这个问题已经基本有了答案:能,而且做得比想象中更好。但当技术可行性被验证之后,真正让 CIO 和 CDO 夜不能寐的问题变成了另一个:“AI 做错了,谁负责?”
当智能体开始自主查询数据库、调用 API、生成报告、触发审批,甚至直接修改业务数据时,它就不再是一个辅助工具,而是一个具备行动能力的数字员工。而数字员工犯错,代价可能比人类员工更高,因为它可以以毫秒级的速度,把错误放大到整个组织。
正是在这个背景下,Snowflake Summit 2026 的 Platform Keynote 显得意味深长。Snowflake 联创 Benoit Dageville 和产品执行副总裁 Christian Kleinerman 站在台上,花了整整一个小时介绍新产品、新架构、新性能指标,但贯穿其中的一条主线非常清楚:当 Agent 开始进入企业流程,平台必须提供足够可信的运行环境。
Benoit Dageville 在现场的一句话,几乎可以概括 Snowflake 对 Agentic AI 的底层判断:“最好的 Agent 平台,必须建立在最好的数据平台之上。” 这句话也解释了为什么 Snowflake 反复强调数据、上下文、权限、治理和可审计性:当 Agent 开始行动,企业 AI 的可信度,最终仍然要回到数据平台本身。

从 CoCo 的改名与桌面化,到 Snowflake CoWork 的正式登场;从智能体身份(Agent Identity)和数据流转策略(Data Movement Policy)的推出,到语义上下文(Horizon Context)的增强,这些更新背后其实有一条更清晰的主线:当 Agent 开始进入企业流程,平台必须同时解决数据、上下文、权限、治理和可审计性问题。
也正是在这样的现场语境下,InfoQ 中国奇遇团在 Snowflake Summit 26 的观察,不再只是记录一场产品发布,而是在追问一个更现实的问题:当 Agent 真的进入企业流程,中国企业该如何理解这场从“能力验证”到“可信运行”的转变?更多现场判断与一线讨论,欢迎观看「奇遇旧金山」系列 Vlog"。
CoCo 与 CoWork 双引擎
Platform Keynote 上最有趣的细节之一,是 Christian Kleinerman 宣布的两个改名决定。
第一个是 Cortex Code 正式更名为 Snowflake CoCo,有趣的是这个名字不是官方起的,是用户叫出来的。”当我们推出 Cortex Code 后,很快,很多人开始说:‘哦,CoCo。’” Christian 在台上笑着说,“Denise 说,我们干脆就别再叫 Cortex Code 了,直接叫 CoCo 怎么样?”
一个多少带着“被用户叫出来”意味的名字,本身就说明 CoCo 已经形成了足够高的使用辨识度。而更让市场注意的是,CoCo 的演进速度很快:它从命令行和 Snowsight 起步,六个月内扩展到 Airflow、dbt、Spark、MCP、ACP,再到 SDK 和 Agent Teams。Summit 上,Snowflake 又宣布了 Cloud Agents 即将 GA、本地开发沙箱、自动化能力、自主智能体、技能目录,以及 CoCo Desktop GA。
过去,Snowflake 最核心的交互方式仍然围绕 SQL 和数据开发展开。用户往往仍需要理解数据库、表结构和查询逻辑,才能更充分地使用平台能力。而 CoCo 的出现,改变了这一层交互逻辑。它让开发者可以用自然语言与整个数据平台对话。更值得关注的是划选提问(Snap and Ask)功能:演示者直接拖拽选中一张图表的某个区域,点击 explain,CoCo 就能基于视觉上下文给出分析。这种交互方式已经不只是“使用数据库”,而更像是在与数据协作。
CoCo 改变的是开发者与数据平台的交互方式,而 Snowflake CoWork 指向的,则是更广泛的业务人群:当 AI 不只帮助人写代码、查数据,而是进入日常工作流,它与人的关系也需要被重新定义。
Snowflake Intelligence 最初被定位为企业员工的 AI 工作助手,但 Christian 坦承:“它的范围已经远远超出了我们最初的设想。它正在改变我们的工作方式。”于是,Snowflake Intelligence 被重新命名为 Snowflake CoWork。
这个名字的改动意味深长。Intelligence 强调的是智能能力,而 CoWork 强调的是协作关系。AI 不再只是工具,而开始成为企业工作流中的协作者。
Christian 对 CoWork 的愿景描述得极为具象:“从 CEO 到每一位一线员工。如果你喜欢 F1,想象每个人都有自己的维修团队。如果你喜欢钢铁侠,每个人都有自己的 Jarvis。”这不是在卖功能,而是在卖一种工作方式的想象。未来的企业员工,每个人背后都有一个 AI 团队,随时待命。

为了让这个愿景落地,Summit 上宣布了一系列 CoWork 的重大更新。个人工作引擎(Personal Work Engine)让组织中的用户不必再手动选择用哪个 Agent,而是拥有一个个人 Agent,自动执行多 Agent 编排,根据请求类型路由到不同的能力模块。用户记忆(User Memory)让 Agent 学习用户的偏好、习惯和工作模式,越用越懂。个人技能(Personal Skills)和个人 MCP 连接器让每个用户可以连接自己的业务系统。定时任务(Scheduled Tasks)则让用户可以说“这个分析我喜欢,你能每周或每月发给我一次吗?”
更值得关注的是工作产物(Artifacts)的演进。CoWork 中创建的不再是静态报告,而是实时数据的受治理视图,可以被共享、被协作、被持续更新的可信数据视图。
这意味着 CoCo 和 CoWork 正在形成一条闭环:开发者在 CoCo 中构建和认证 AI 应用,业务用户在 CoWork 中消费和协作,两者共享同一套治理框架和安全策略。
要让 CoCo 和 CoWork 真正发挥作用,Snowflake 还需要补上另一层能力:上下文。
Cortex Sense 承担的正是这个角色。它会从 Snowflake 已有的数据和活动中构建信号,自动增强 Agent,让 CoCo 和 CoWork 在回答问题、生成代码或执行任务时更理解企业环境。Christian 在现场提到,在一个评估集中,搭配 Cortex Sense 后,CoCo 和 CoWork 的开箱准确率从 24% 提升到 83%。

Natoma 的加入,则把这套能力继续延伸到更多业务系统。借助超过 100 个业务系统连接能力,Snowflake 可以让 CoCo 和 CoWork 更自然地触达企业日常使用的应用。也正是在这个意义上,CoCo 和 CoWork 更接近 Christian 所说的 control planes:它们不是单纯的数据引擎,而是连接数据、模型和应用的工作入口,让 AI 的分析、协作和行动运行在同一套治理框架下。
三星电子执行副总裁 Jung Suh 在台上分享了基于 Snowflake CoWork 构建的 shopper’s insight action agent,也就是 SIA。Galaxy S26 发布时,SIA 不只是检索数据,而是在数据之上推理和行动:比较发布表现、规划步骤、调和信号,并给出综合答案。过去需要数小时的分析工作,现在可以在几秒内完成。
更关键的是,Samsung 全球大约有 1,000 名高管、销售和营销人员正在使用这个 Agent。他们不是数据科学家,而是直接负责区域目标、促销策略和产品路线图的业务领导。Jung Suh 提到,过去这些人完全依赖分析师来回答问题,而现在,数据团队不再是唯一入口,每位业务领导都可以在自己的工作流中获得分析能力。
这正是 CoWork 想推动的变化:不是让业务人员多一个问答工具,而是把原本集中在数据团队手中的分析能力,嵌入更广泛的业务决策现场。
AI 时代没有“慢数据”
Snowflake 过去最擅长的是分析已经发生的业务,而此次发布的 Datastream 指向的是另一个方向:让平台更接近正在发生的业务。
Snowflake 的崛起,很大程度上建立在"批处理"哲学之上。它将计算与存储解耦,用弹性扩展的方式处理海量结构化数据,彻底击败了传统数据仓库。但在过去,流处理并不是 Snowflake 的强项,企业如果需要实时数据,往往会额外部署 Kafka 等系统来补充。
现在,Snowflake 亲自下场做流了。而且不是做一个更好的连接器,而是从头构建一个原生流服务,兼容 Kafka Wire 协议,支持零拷贝流式处理,能够以亚秒级延迟将数据流入和流出 Snowflake。
为什么?因为 AI 时代的数据消费模式,已经从“T+1 报表”变成了“实时决策”。
当 AI 智能体开始自主监控业务信号、规划行动步骤、触发业务流程时,延迟就变成了商业生死线。智能体不可能等批处理任务跑完再做决策,它需要的是持续流动的数据血脉。
在 Agent 时代,没有"慢数据"的生存空间。更重要的是,Snowflake 将其以"真正的 Snowflake 风格"实现,存储与计算分离、零拷贝、亚秒级延迟,这意味着它试图把流处理也纳入自己的经济模型和治理框架之内。
值得一并关注的是智能体搜索(Agentic Search)的推出。它不会做传统 RAG 那种"给你 Top-K 结果"的模糊匹配,而是利用 AI 函数从非结构化数据中提取信息,提取为结构化信息,运行精确的分析查询,再返回基于非结构化内容的精确分析结果。这意味着,企业过去分散在文档、邮件、合同中的"暗数据",现在可以被智能体直接调用、解析、计算,而且结果精确到可以支撑业务决策。
安德玛的首席数据与 AI 官 Patrick Duroseau 在视频分享中印证了这一趋势:"我们面临的最大挑战是数据是非结构化的,而且归因不像现在这样一致。为了找到这些洞察,你真的必须对数据做大量人工操作。"使用 Snowflake 之后,“我们更容易把数据带入平台。我们拥有许多能力,可以支持传统 BI、高级分析,也可以在生态中共享数据,并且时间成本只是过去的一小部分。”
这正好解释了为什么 Snowflake 要反复强调"all data"——结构化、半结构化、非结构化,甚至是实时流数据,全部纳入同一个治理模型。在 Agent 时代,数据平台的边界正在被重新定义:它不再只是存数据的地方,而是让智能体能够理解和行动的企业记忆中枢。
从“管数据”到“管行为”
如果说 CoCo、CoWork 和性能优化是 Snowflake 在"能力层"的布局,那么 Summit 上关于治理和信任的密集发布,则是它在规则层的深层设计。
Christian 在台上非常直接地表达了 Snowflake 的立场:“在智能体时代,我们希望确保大家能够保护自己的 Agent,并拥有多层防护。”
这句话听起来像是常规的安全表态,但结合随后发布的一系列功能,你会发现 Snowflake 的治理逻辑正在发生一次根本性的升维——从"管理静态数据"转向"管理动态智能体行为"。
首先是智能体身份(Agent Identity)。Snowflake 推出了智能体身份的概念,让你可以知道某段代码或某项活动是否发生在 Agent 上下文下。在脱敏策略或行级策略中,你可以针对 Agent 上下文设置不同的可见性权限。这意味着,同一个数据库表,人类查询和智能体查询可以被施加不同的安全策略。
其次是数据流转策略(Data Movement Policies)。你可以规定带有某个标签的数据不得移动到 stage,也不得通过 Snowsight UI 下载。在 keynote 的 demo 中,当一名 Tour Ops 员工试图让 CoWork 导出 VIP 客户数据到外部 stage 时,数据流转策略直接阻止了这次数据外泄——即使智能体本身有能力查看那张表。
第三是 Horizon AI 护栏,防止提示注入和越狱攻击;多方审批(multi-party approvals),要求高度敏感操作必须有两个管理员同意;以及信任中心(Trust Center)中的 AI 安全巡检和检测包,持续监控异常数据传输。
这些能力单独看是安全特性,放在一起,则指向 Snowflake 对 Agent 治理边界的重新定义:在 Snowflake 的设想中,未来的企业数据平台不仅要回答"谁能访问什么数据",还要回答"智能体在什么情况下可以做什么操作"“AI 的行为如何被审计和回溯”“当智能体犯错时,责任边界在哪里”。
汤森路透首席数据官 Caitlin Halferty 在台上说了一句点睛的话:"有些人认为治理是一种约束,是会拖慢你的东西。但对我们来说,治理是一个赋能者。"她解释道,Thomson Reuters 按照受托级标准(fiduciary-grade standard)构建产品。这意味着内容、数据隐私、安全、透明度和可验证性,全部达到受信托责任约束的最高标准。他们的旗舰 AI 能力 CoCounsel 每天有超过 100 万专业人士使用,而在财务和业务部门中有超过 15,000 名内部用户每天使用语义智能进行最关键的业务和财务决策。"我们已经从试点走向生产环境,"Caitlin 强调,“每一个 AI 能力在进入市场之前,都会经过负责任 AI 的流程。”
这句话精准地概括了 Snowflake 的治理哲学。在 Agent 时代,治理不再是合规部门的"拦路虎",而是业务创新的"通行证"。没有治理,企业就不敢把 AI 放进生产环境;没有生产环境,AI 就永远只是演示。
这种治理升维还有一个容易被忽略的技术支撑:语义上下文(Horizon Context)。Christian 解释说,仅有智能是不够的,很多时候真正缺少的是上下文。语义上下文作为 Horizon Catalog 的组成部分,帮助收集信号、丰富这些信号,并将它们提供给 CoCo、CoWork 或 Cortex Agent。通过语义视图和元数据连接器,Snowflake 试图让 AI 不仅"能访问数据",而且"能理解数据的业务含义"。这恰恰是智能体从"工具"升级为"协作者"的关键一跃,只有当智能体理解"这张表里的收入是毛利还是净利",它给出的答案才是可信的。
与此同时,意图驱动治理(intent-driven governance)的提出降低了治理操作的技术门槛,也让治理更容易进入实际业务场景,而不是只停留在安全团队后台。企业管理者不需要再写复杂的策略脚本,只需要用自然语言表达自己的意图——比如"把我的数据库中所有个人敏感信息找出来,并确保它受到保护"——系统就会自动触发分类、找出个人敏感信息、创建正确的策略,并持续监控。治理的民主化,意味着它不再是少数安全专家的专利,而是每个业务负责人都可以直接施加的控制力。
越开放,越不可或缺
在 Summit 上,Snowflake 展示了它在开放方向上的大量投入:从 Apache Iceberg v3 的广泛实现,到将 Apache Polaris 的 Iceberg Catalog interfaces 纳入 Horizon Catalog;从牵头创建 Open Semantic Interchange Group,到 reshare data 的 GA,再到 open sharing 进入 public preview,Snowflake 试图传递一个明确态度:它不希望自己被看作一个封闭的数据平台。
这种表态并不只是姿态问题。企业在进入 AI 深水区之后,对供应商锁定的警惕会更强。Agent 天然需要跨系统行动:数据可能在不同平台,业务流程可能在不同 SaaS 应用,模型也可能来自不同厂商。一个平台如果不能证明自己足够开放,就很难成为企业 AI 的长期底座。
Open sharing 的意义正在这里。借助 Iceberg 和 Iceberg REST Catalog,Snowflake 可以把数据共享给非 Snowflake 用户,让还没有使用 Snowflake 的组织也能成为数据消费者。站在企业客户角度,这降低了跨组织协作门槛;站在 Snowflake 角度,它也让平台更容易进入更多数据交换和协作关系中。

Multi-party collaboration 则把这种协作进一步推向复杂场景。多个参与方可以在同一个安全环境中协作,不同角色拥有不同权限:有人贡献数据,有人负责分析。Christian Kleinerman 在现场提到,Netflix 正在用这类 collaboration technology 构建与多个合作伙伴协作的 team rooms。这个案例说明,Snowflake 想做的不只是数据共享,而是让多方数据合作在可控环境里发生。
开放并不意味着 Snowflake 放弃平台中心位置。相反,它正在通过更深的生态协同,把自己放到更多数据和 AI 工作流的交汇处。
在业务系统侧,Snowflake 正在扩大与 Salesforce、Workday、SAP、IBM mainframe/Db2 data、Veeva 等系统和数据源的连接合作。query across 能力则让 Snowflake CoWork 可以在可能位于 Redshift、Postgres 或其他数据源中的数据上,提供 Snowflake 和 Snowflake AI 的能力。也就是说,Snowflake 一方面允许数据以更开放的方式流动,另一方面也在让自己的 AI、治理和协作能力进入更多外部系统。
这背后体现的是一种“开放底座、深度协同”的生态策略。
它的逻辑是:数据格式和访问协议需要足够开放,企业才会放心把关键数据和流程接入平台;但当 Agent 真正进入业务流程,价值就不只来自数据本身,还来自围绕数据不断沉淀的上下文、权限体系、行为历史和业务语义。
换句话说,数据可以保持开放流动,但围绕数据形成的智能协作经验,会逐渐沉淀为新的平台价值。当销售、客服、财务等不同 Agent 都在 Snowflake 的治理框架下运行了数月甚至数年之后,迁移成本就不再是数据迁移的成本,而是“智能迁移”的成本。
信任竞争刚刚开始
2026 年,企业 AI 的问题正在改写。大模型已经证明了“能不能做”,但企业真正要决定的是“敢不敢用”。当 Agent 开始查询数据、调用系统、影响业务流程,可信度就不再是安全团队的后台议题,而是 AI 能否进入生产环境的前提。
Christian 在 Keynote 最后说,Snowflake 正从 “can we” 的时代走向 “shall we” 的时代。它对应的正是这个转变:企业不再只需要能力展示,而需要一套能承接责任的运行体系。
Snowflake 此次展示的性能、治理、上下文、开放生态和 Agent 行为管理,都在指向同一个方向:把 AI 的复杂性收进底层,把可信度带到业务前台。企业 AI 的下一场竞争,也会从这里真正开始。
更多 Snowflake Summit 26 精彩内容,欢迎前往大会专区"查看。

你的公司最近上线了一个内部全能搜索系统,这是一个单体系统,采用检索增强生成(RAG)"技术构建,可检索公司的待办事项、设计文档、发布文档、运维手册和纠错文档(COE")。工程师、产品经理和经理通过基于大语言模型的聊天界面进行查询,各团队还将其封装为 MCP 工具,让他们的 AI 编程助手可以直接获取上下文。
然后,生产支持组的一名值班人员输入:”在生产环境中启用 payment_v2_enforce 功能标志的运维手册“,聊天助手却提示应禁用该功能。在系统内部,文档根据嵌入相似度进行排名。
对于嵌入模型来说,这两份运维手册看起来几乎完全相同。它们有相同的功能标志名称、相同的服务、相同的词汇和相似的上下文。但值班工程师看不到这个排名,他们看到的是聊天助手根据检索器返回的前 K 条内容生成的回答(有时正确的运维手册甚至不在前 K 个结果里)。这类回答轻则信息失真,重则看似笃定却完全错误。
如果你构建过基于嵌入"的搜索系统,对这类情况想必并不陌生。系统能把握整体方向,却忽略了关键的细节信息。
上述查询需要两样东西:对”功能标志运维手册“的语义理解,以及对操作(启用与禁用)的精确匹配。向量搜索"只处理了前者。
这并非嵌入模型的缺陷,而是向量相似度的固有特性。嵌入机制会检索出和查询内容相似的结果,而非完全匹配的内容。由于检索将前 K 个结果作为上下文输入大语言模型,排名与召回同样重要。
即便正确答案在前 K 条结果里,若错误答案排序更靠前,依然无法解决问题。修复方案并不是要替换嵌入技术,而是将其与传统文本关键词匹配相结合,让概念相关性和精准术语匹配共同作用于最终的排序。
纯向量检索 RAG 流程的短板
想要理解为什么会出现这个问题,不妨放眼审视一下完整的流程。如图 1 所示,RAG 流程共分为三个阶段。
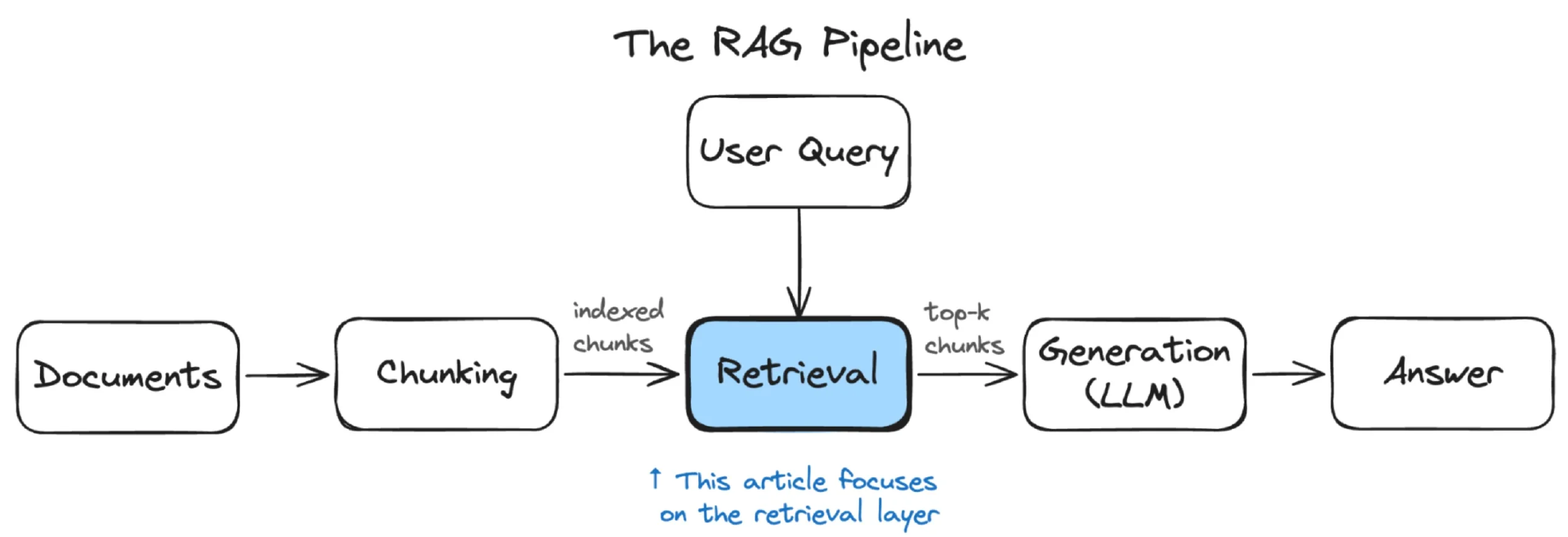
图1. 典型的 RAG 管道有三个阶段:分块、检索和生成。(来源:作者创建)
图 1 中的元素定义如下:
分块:将原始语料库拆分为可用于索引的单元。检索:接收用户查询,在分块内容中检索并返回相关性最高的前 K 个块。生成:将这些分块内容作为上下文输入大语言模型,由模型生成答案。
假设第一、第三阶段均正常运行:文档按合理边界完成拆分,大语言模型根据提供的上下文生成答案,且不会产生幻觉。问题出在前文提及的检索阶段。检索器先对查询做嵌入处理,再将其与已建立索引的文档向量比对,返回嵌入空间距离最近的文档。嵌入空间距离相近,表示语义相似,而非内容完全一致。针对同一功能标志的两份运维手册,一份说明启用操作、一份说明禁用操作,二者在嵌入空间中距离极近。两份文本仅个别词汇存在差异,嵌入模型会为这类高度相似的文本生成近乎一致的向量,导致检索器难以精准区分。因此,当用户查询启用功能标志的运维手册时,禁用相关的手册有时反而距离更近,检索器会以同等置信度推送这份错误文档。这便是问题所在:依靠同一向量空间与评分机制,最终排在前面的却是错误的文档。
问题在于嵌入的本质是近似计算
像 BERT" 这样的嵌入模型将文本转换为固定维度的数值向量,并捕捉文本的语义信息。语义相似的文本生成相似的向量。”功能标志“、”终止开关“、”发布门“和”配置切换“在向量空间中紧密聚集。这种聚类在用户检索相关概念时能发挥很大作用,但当用户需要查找精确实体、特定功能标志名称、特定错误代码或特定部署版本时,问题就转到了检索精度层面。
相似的表现同样存在于各类不同失效模式中。当某人搜索 ERR_PAYMENT_GATEWAY_TIMEOUT 时,相关代码如 ERR_PAYMENT_GATEWAY_REJECTED 和 ERR_PAYMENT_GATEWAY_UNAUTHORIZED 等相关代码最终都会与查询向量趋近,因为它们有相同的 ERR_PAYMENT_GATEWAY 前缀并出现在同类故障排查文档中。区分它们尾部词汇的权重占比很低。嵌入模型的行为完全符合设计初衷,它的作用是检索相似内容,而非精准匹配完全一致的内容。当区分特征在文本中占比过低时,嵌入会抹平这种区别。
图 2 展示了嵌入空间的特征:语义相近的内容会聚集在一起。在同一个聚类内部,想要区分不同具体实体(比如介绍功能标志启用、禁用操作的运维手册)就会变得困难。而混合搜索,正是为了解决这类精度不足的问题。
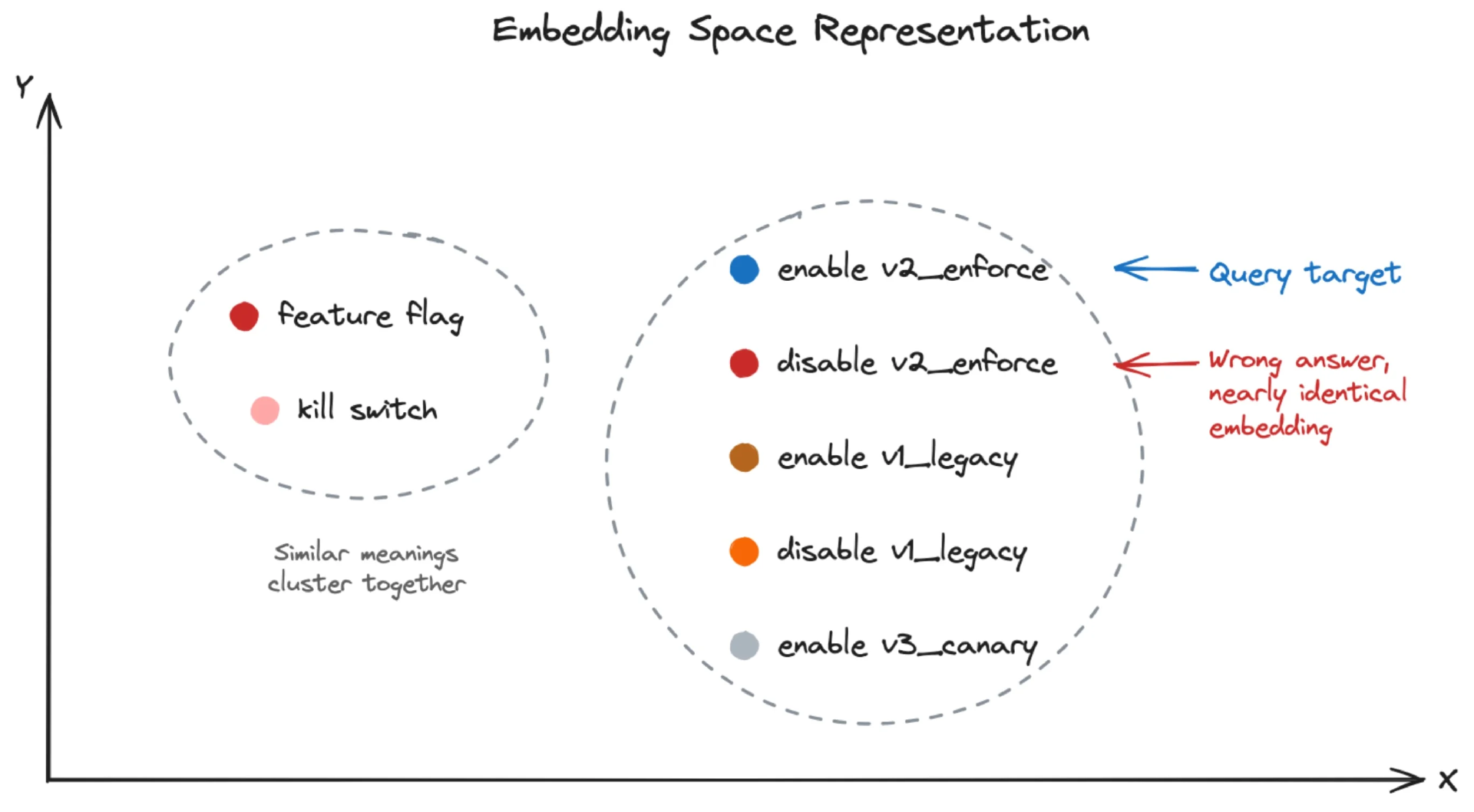
图 2. 语义相似的项目聚集在一起。并非每个查询都有相同的问题。(来源:作者创建)
根据检索方法的适用程度,搜索查询可以被分为三种类型。
语义查询"
用户的提问“当一个区域离线时,我们的协议是什么?”是概念类查询。标题为“灾难恢复架构”、“主主复制策略”、“故障转移运维手册”的文档,即便和查询没有共用词汇,也理应获得较高排名。嵌入模型能很好地应对这类场景,因为它捕捉的是语义,而非单纯匹配字面词汇。
精确匹配查询"
这类查询在信息检索文献中也称为词汇查询。用户将堆栈跟踪或日志中的错误代码粘贴到搜索栏中,如 ERR_PAYMENT_GATEWAY_TIMEOUT,此时他们明确知晓自己要查找的标识。对于这些查询,语义相似性反而不是用户想要的。向量嵌入可能会推送语义相近但标识不同的文档(如包含 ERR_PAYMENT_GATEWAY_REJECTED 而非 TIMEOUT 的运维手册),影响了检索效果。关键词搜索则能高效、准确地处理这类查询。
混合查询"
用户搜索 “v3.2 部署的回滚运维手册”时,既需要语义理解(即部署回滚相关的运维手册),也需要对区分标识做精确匹配:根据 “v3.2” 筛选对应版本,根据 “rollback” 区分 “rollout”。用户搜索 “Outlook 2019 同步错误 0x80004005 故障排除”,则需要对问题症状做语义匹配,同时精确匹配版本号和错误代码。这类查询同时依赖两种能力。结合我在生产级 RAG 系统的实践经验,这类查询占绝大多数。本文后续内容将围绕这类查询的处理方案展开。
BM25 为嵌入近似语义提供精度
向量搜索需要一个搭档,这个搭档就是BM25 —— 经典信息检索领域核心的概率排名函数。它是 Elasticsearch、OpenSearch 和大多数词汇搜索引擎的默认评分器,也是三十多年来占据主导地位的关键词搜索算法。在向量搜索效果不佳的场景中,它总能精准发挥作用。它基于概率信息检索理论,提供了三个直接解决精确匹配问题的内置机制。
逆文档频率(IDF)"用于衡量一个词在整个语料库中的稀有程度。常见词如 “service” 或 “deployment” 权重较低,而稀有的区分性标记如 “v3.2”、“ERR_PAYMENT_GATEWAY_TIMEOUT” 或 “payment_v2_enforce” 权重较高。这也是 BM25 在精确匹配查询中优于嵌入技术的原因。能够区分不同文档的稀有标识在 BM25 中会被赋予最高权重。
词频(TF)饱和"用于控制重复术语带来的影响。术语的首次出现会显著影响得分,后续重复出现带来的增益则逐步递减。得分会趋近于一个上限,而非线性增长。这一特性能够避免文档依靠关键词堆砌来刻意操纵排名。
长度归一化"用于解决文本检索中的另一种偏差。较长的文档仅仅因为包含更多词汇而倾向于获得更高分数,匹配查询术语的概率也更高。长度归一化通过在计算相关性得分时综合考虑文档长度来纠正这个问题,不仅会统计术语出现的次数,还会考虑相对于文档长度的频率。这一点在具有可变长度分块的 RAG 系统中尤为重要,如果没有这种调整,较大的分块始终会胜过较小的分块。
基于倒数排名融合的混合搜索
如图 3 所示,混合检索会并行执行 BM25 检索与向量检索,通过 RRF 融合两者的排序列表;在将前 K 个文本块输入大语言模型前,还可选用交叉编码器做二次重排序。
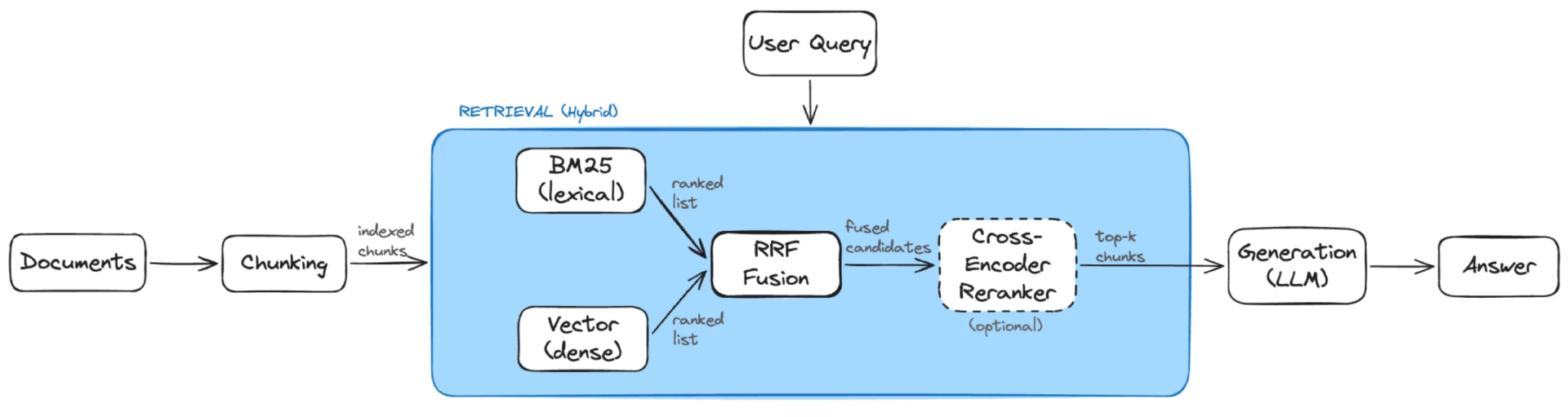
图 3. 混合检索(来源:作者创建)
现在我们有两个具有互补优势的检索器:向量搜索和 BM25。向量搜索捕捉语义信息,而 BM25 进行精准的词项匹配。每个产生自己的排名列表,要进行混合查询,这两个列表需要合并为一个。
合并列表是一个难点。向量余弦相似度介于 -1 和 1 之间,而 BM25 得分没有上下限,很难将它们归一化到同一量纲。权重适配会随查询内容变化:对于某一个查询,BM25 的合适权重可能是 0.7,但对于另一个可能是 0.3。在生产环境中为每个查询校准权重是不切实际的,而这正是倒数排名融合(RRF)"发挥作用的地方。
深入解析 RRF 如何实现分数融合
RRF 直接舍弃两个检索器的原始分数,绕过了归一化难题。它仅基于排名位置完成运算:
RRF_Score(d) = Σ 1 / (k + rank_r(d))
常数 k 通常为 60(Cormack、Clarke 和 Buettcher 2009"),用于平滑不同排名位置的权重贡献。排名第 1 的文档贡献 1/61 ≈ 0.0164。排名第 10 的文档贡献 1/70 ≈ 0.0143。在检索器的前 K 个中缺失的文档贡献为 0。
该机制原理十分简单:同时在两个检索结果中排名靠前的文档,会因叠加得到非零分值,最终获得更高融合得分。即便某个文档在单个检索器中排名第一,若仅被一个检索器命中,综合得分也会被压低。RRF 本质是对检索结果一致性进行加权。
下方三张表格针对语义查询、精确匹配查询、混合查询三类查询场景,逐步演示上述情况。综合来看,表格分别展示了 RRF 表现明显占优、以微弱优势保留正确结果,以及本文核心论点所聚焦的场景。
解读排名列时需注意:两个检索器均在包含数千份文档的完整语料库中检索。表格内展示的 BM25 与向量检索排名是文档在全量检索结果中的位次,而非仅针对表格里的四份文档。因此,BM25 排名 12,表示该文档在整个语料库的检索结果中位列第 12。
下文演示的三类查询均可在本地 Elasticsearch 实例中端到端完整运行。示例应用代码与数据集可在该 GitHub 示例项目"中获取。
查询:“我们的认证系统如何处理过期令牌(How Does Our Auth System Handle Expired Tokens)?”
这是一个概念性问题。对应的正确文档是名为《认证服务中的令牌刷新和过期处理》的运维手册。该文档与检索内容存在多处共用术语,包括 “token”、“expiration”/“expired”、“handling”/“handle”、“auth”,因此被 BM25 检索命中。但另一篇关联性较低的文档,因 “system” 和 “token” 两个词汇出现频次更高,最终在 BM25 排序中排在了前面。
BM25 检索到了目标文档,但置信度低于《系统令牌轮换运维手册》。后者虽然在通用术语上匹配度更高,但对应的业务操作并不相关。向量检索凭借语义层面的匹配将正确文档排在首位。RRF 算法会优先加权两个检索结果中排名均靠前的内容,因此该文档最终位列融合结果顶部。而紧随其后的两个 RRF 结果(《OAuth 流程设计文档》与《系统令牌轮换运维手册》)也都能为读取候选结果的大模型提供有效上下文信息。
精确匹配查询
查询:“ERR_PAYMENT_GATEWAY_TIMEOUT”
用户粘贴了堆栈跟踪里的错误代码。由于标识符字符串唯一且完全逐字匹配,BM25 成功检索到对应的运维手册。但向量检索效果不佳,因为查询内容除了“支付服务的错误”外几乎没有有效语义,嵌入模型难以精准区分 ERR_PAYMENT_GATEWAY_TIMEOUT 和该服务下其他同类错误码。
从逻辑合理性来看,邻近错误码对应的运维手册会出现在 BM25 检索结果中,这是因为相关手册的故障排查步骤通常会有交叉引用(例如“若出现 ERR_PAYMENT_GATEWAY_REJECTED,请参考本手册”),查询关键词恰好匹配了这类引用内容。如果没有这些交叉引用,BM25 就只会返回 TIMEOUT 对应的运维手册,邻近手册也不会出现在检索结果里。
RRF 将目标运维手册排在首位,但它与另一篇对应拒绝类错误码的手册得分差距很小,第二、第三名结果均为其他错误码对应的手册。针对这类纯标识符类查询,仅使用 BM25 检索得到的候选结果集质量反而优于混合检索。BM25 结果里的第二、第三位是明显无关的文档,大模型可直接过滤;但 RRF 排在第二、第三位的是内容相近的运维手册,容易让大模型误判用户实际提供的错误码。这也客观说明,混合检索的优势体现在整体数据分布层面,并不能对每一条查询都实现优化。
混合查询
查询:“v3.2部署的回滚运维手册(Rollback Runbook for v3.2 Deployment)”
BM25 将目标文档排在首位,原因是文本中的 “rollback”、“v3.2”、“deployment”、“runbook” 全部精准匹配。向量检索则把 v3.2 版本的发布运维手册放在第一位,这并非因为嵌入模型判定发布内容比回滚内容与查询更相关,而是该查询与两份运维手册的余弦相似度差值仅在 0.01至 0.02 之间。向量检索的这一排序结果更偏向随机噪声,不具备实际参考价值。再次运行查询或更换嵌入模型,二者的排名都可能发生颠倒。
这类因噪声导致核心操作意图无法区分的问题,正是混合检索所要解决的检索失效场景。BM25 倾向于匹配回滚相关的运维手册,打破了两项操作的排名胶着状态。RRF 会对两个检索器均位列前三的文档加权提权,最终将目标的 v3.2 版本回滚运维手册推至靠前位置。
三种查询综合分析
三种查询的整体运行逻辑是一致的。对于语义查询,向量搜索能够定位到目标文档,RRF 会将这类结果置顶,同时添加 BM25 提供的匹配特征。对于精确匹配查询,BM25 可精准召回目标文档,RRF 同样将其保留在首位,只是第二名结果相比单独使用 BM25 时干扰信息会更多。对于混合查询,两类检索器各自存在不同的检索缺陷:BM25 的首位结果正确,但第二名返回了错误版本;向量搜索的首位结果则完全匹配错误。经过 RRF 融合后,最终首位结果准确,第二名虽存在偏差但具备相关性,也是三组结果中质量最优的一组。
根据我的经验,生产环境中的查询以第三种类型为主。大多数真实世界的查询将语义意图与特定标识符、版本号、错误代码或其他需要精确匹配的标记相结合,混合检索正是针对这类查询分布设计的工程解决方案。
生产环境中的混合检索
目前业内主流的生产级 RAG 系统均普遍采用混合检索方案。Perplexity" 在 Vespa 上结合了百亿级的 URL 词法检索与向量打分,并通过交叉编码器完成多阶段重排。Glean" 则在企业搜索专属知识图谱之上叠加词法检索与稠密向量检索。二者应用场景不同,却采用了相同的架构思路。
Elasticsearch 的生产实现
Elasticsearch 和 OpenSearch 都通过检索器 API 原生支持混合检索(Elasticsearch 8.13 及以上版本率先实现,OpenSearch 紧随其后)。原生支持意味着检索融合已在搜索引擎内部单次查询中完成,无需在应用层额外做结果合并。下面的示例使用了 Elasticsearch 语法,OpenSearch 语法与之基本一致。
索引映射
你的索引需同时配置用于 BM25 检索的标准文本字段和用于向量检索的稠密向量字段:
PUT /rag_knowledge_base
{
"mappings": {
"properties": {
"title": { "type": "text" },
"content": { "type": "text", "analyzer": "standard" },
"content_vector": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "cosine"
}
}
}
}
图4. Elasticsearch 索引映射,同时定义了用于 BM25 的文本字段以及用于语义检索的 768维密集向量字段。
带 RRF 的混合查询
在单次请求中同时调用两类检索器,并完成结果融合:
POST /rag_knowledge_base/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": { "match": { "content": "rollback runbook for v3.2 deployment" } }
}
},
{
"knn": {
"field": "content_vector",
"query_vector": [0.12, -0.45, ...],
"k": 50,
"num_candidates": 100
}
}
],
"rank_constant": 60
}
}
}
图5. 使用 Elasticsearch 的 RRF 检索器进行混合检索查询,并行运行 BM25 和 kNN 搜索,并在单个请求中融合排名。
生产调优
上述的默认配置可以作为合理的参考,但生产系统几乎总是需要进一步调优。其中的三个核心参数基本决定了检索相关性与查询延迟之间的取舍关系。
排名常数(k)"
排名常数是 RRF 公式中的平滑参数,用于控制排名权重的衰减速率。排名为 r 的文档,其权重按 1/(k + r) 计入融合得分。该参数默认值为 60,适用于通用检索场景。若将数值调至 2030,会强化高排名结果的权重,当 BM25 对错误码、版本号、功能标识等内容实现精准匹配时,该设置效果更佳。若调高至 80100,排名权重曲线会趋于平缓,更倾向于选取在两类检索结果中同时出现的文档,而非仅在单一列表里排名靠前的内容。参数取值需根据业务需求选择:追求高精度则选用较小的 k 值,侧重召回率则选用较大的 k 值。
kNN 候选"
num_candidates 参数用于设定 HNSW 图遍历过程中获取前 K 个结果前需要检索的向量数量,控制近似最近邻搜索在召回率与查询延迟之间的权衡。将 k 设为 50、num_candidates 设为 100 效果较好。若发现向量搜索召回率偏低,即相关文档频繁排在前 50 名之外,可将 num_candidates 调至 200~300。该操作通常能在延迟小幅增加的前提下提升召回率,因为额外计算仅在向量索引内部完成,不会产生额外网络请求。
使用交叉编码器重新排序"
基于 RRF 的混合检索能获得优质的候选结果,而交叉编码器重排可进一步显著提升最终检索相关性。双编码器会分别为查询和文档生成嵌入向量,交叉编码器则将完整的查询-文档对输入 Transformer 进行联合处理,实现查询词与文档内容的细粒度标记交互。正是这一架构差异让交叉编码器的检索效果始终优于双编码器——它能够捕捉到独立嵌入无法识别的语义细节和关联关系。
在实践中,常规方案是先通过 RRF 筛选出 20 至 50 条候选结果,再使用 ms-marco-MiniLM-L-6-v2" 这类交叉编码器完成最终重排。交叉编码器并不适合用于首轮检索,因为它需要对每一组查询-文档对执行前向计算,耗时较长;但对小规模候选集做重排时延迟完全可控,在 GPU 环境下处理 50 条候选结果通常耗时不足 100 毫秒。在 BEIR 等主流检索基准测试中,交叉编码器的表现始终优于双编码器:大模型在跨领域查询场景下提升尤为明显,轻量模型则能在同领域场景下带来可观效果增益。对于每一点检索相关性都至关重要的生产系统而言,这一重排环节很有价值。
结论
稠密向量嵌入可解决检索的泛化问题,即便查询词与文档用词不一致,也能匹配到概念相关的内容。BM25 则解决了基于稀有、区分性标记找到精确匹配的精度问题。但二者单独使用都无法满足生产环境下 RAG 系统的需求。
向量嵌入属于近似检索,这既是它的优势,也带来了固有局限。基于 RRF 的混合搜索并非弥补模型性能短板的临时方案,而是面向同时兼容语义查询与精确匹配查询的系统,在架构层面的最优选择。
若 RAG 流程仅依靠向量嵌入完成检索,会损失检索效果。建议加入 BM25 检索,通过 RRF 融合结果,并使用交叉编码器实现重排。
查看英文原文:https://www.infoq.com/articles/vector-search-hybrid-retrieval-rag/"

过去一年,“Agent”这个词从实验室走进了生产环境。工程师们开始真正面对一个新的问题:不是“AI 能不能做到”,而是“我们能不能把它跑稳、跑对、跑出规模”。架构怎么设计?记忆怎么管理?多智能体之间如何协调?研发团队的工作方式又该如何重构?
这些,正是 AICon 2026 上海站试图回答的问题。 6 月 26 日-27 日,本次大会将以“构建可信赖、可规模化、可商业化的 Agentic 操作系统”为核心命题,集结清华、复旦等知名高校教授,以及来自阿里、腾讯、蚂蚁、字节、快手、小红书、华为、Google Cloud 等数十家头部公司的技术专家登台分享。2天、13大专题、1个动手实验室、近60场重磅议题,将深度探讨Agent工程化落地等相关话题。
上海交大助理教授 & 博士生导师刘方鑫已确认出席 “大模型推理优化"” 专题,发表题为《从数据表征到数据流编排的存算协同优化"》的主题分享。当前大模型推理受限于非均匀数据分布与同构算力架构的严重错配,导致存储冗余、精度浪费与访存瓶颈。本报告提出一套面向大模型推理的跨层协同优化方案。在数据表征层面,通过分布感知的自适应数据编码,降低信息冗余度,实现模型参数的紧凑化与硬件友好型存储;在计算范式层面,重构运算逻辑,引入基于重要性感知的高精度近似计算,以低成本的轻量运算替代非关键数据的高精度运算,有效提升硬件算力利用率;在数据流层面,通过协同编排计算与访存数据流,优化调度策略,减少缓存未命中与流水线阻塞。为构建高效的 AI 算力底座提供了系统性的演进路径。
刘方鑫,上海交通大学计算机科学与工程系助理教授、博士生导师,兼任上海期智研究院研究员。主要研究方向包括计算机体系结构与设计自动化、大模型加速与AI编译优化等。以第一或通讯作者身份在HPCA、ISCA、MICRO、ASPLOS、PPoPP等国际顶级会议和期刊上发表论文60余篇,其中CCF-A类论文40余篇,体系结构四大顶会论文20篇。主持国家自然科学基金青年项目、上海市自然科学基金面上项目,以及华为、阿里巴巴、蚂蚁金服、中兴通讯、小米、OPPO、CCF-蚂蚁科研基金、CAAI-蚂蚁科研基金等十余项企业及学会合作课题。曾入选上海交通大学首届“吴文俊人工智能博士项目”,并担任“国智班”项目导师。研究成果入选华为火花奖(2022)、中国计算机学会容错计算专委40周年代表性成果等,此外,获ACM MM 2025杰出论文奖(System Theme)、DATE 2022最佳论文奖及最佳论文提名、上海市计算机学会优秀博士论文奖(每年仅2–3人入选)、ACM上海优秀博士论文奖(每年仅2–3人入选)、上海市优秀毕业生、CCF体系结构优秀博士论文提名等奖项与荣誉。指导学生获CCFSys图计算系统设计大赛特等奖、CCFSys 2025最佳项目海报奖及第二届集成芯片与芯粒技术开源社区大赛一等奖等荣誉。
除此之外,本次大会还策划了端侧 AI、物理与数字空间智能化"、世界模型与多模态智能突破"、Agent 架构与工程化实践"、Agent 安全与可信治理"、企业级研发体系重构"、AI 原生数据工程"、AI 时代的个人提效与组织变革"等14个专题论坛,届时将有来自不同行业、不同领域、不同企业的50+资深专家在现场带来前沿技术洞察和一线实践经验。
更多详情可扫码或联系票务经理 13269078023 进行咨询。

C114讯 6月11日下午消息(舒允文)今日下午,上海迎来又一座数字地标。上海移动携手月星集团在上海环球港联合举办发布会,正式宣布“双万兆第一港“暨首个AI智慧商业体落地上海环球港。上海市经信委、市数据局、普陀区政府相关领导出席活动并见证本次发布。

网络基础设施的代际跃升,从来都是产业变革的前奏。按照《上海市进一步推进新型基础设施建设行动方案(2023—2026年)》的规划,到2026年底,上海将初步建成以5G-A和万兆光网为标志的“全球双万兆城市”。此次环球港从“双千兆”率先升级为“双万兆”,不仅是城市数智化建设中的一大里程碑,亦是“数据要素×AI”从概念走向实体商业应用的重要一步,体现了上海移动在深度赋能实体经济、推动“数实融合”方面的一贯努力。
C114在现场了解到,此次合作中,上海移动充分发挥5G-A与万兆光网的技术优势,为环球港打造了“极速、低时延、超级上行、通感一体”的“双万兆”网络基座。目前,已基本完成环球港5G-A室内覆盖,太阳厅、环球大厅等重点区域的深度覆盖,万兆光网已全面接入环球港。

环球港“双万兆”的落地,不止意味着速度升级、宽带迭代,还将实现从“万兆网络”向“万兆生态”的关键跨越:即以双万兆网络为核心基座,聚力打造面向智能时代的数据要素一体化综合枢纽,打通数据汇聚、智能分析、场景应用全链条,构建“数据+模型+场景”的一体化供给模式,让数据真正成为驱动文、商、旅、体、展多产业融合发展的核心动能,为城市商业高质量发展注入数智动力。

发布会上,上海移动与月星集团正式签署了战略合作协议。根据协议,双方将在智慧商圈建设、智慧运营、数字营销、会员权益、商企数智赋能等多个维度进行全方位、深层次的合作,并以此为契机,打破区域壁垒,促进普陀区沿沪宁产业创新带的数字资源跨区域流动,为长三角一体化数字经济发展注入强劲动能。
与此同时,上海移动发布多项惠民惠企举措,其中“移动 - 环球港”5G-A权益包、AI智能体“环环”、“世界杯”环球港第二现场AI观赛等智能服务的发布推广,来逛商场的市民不仅可以享受商场内极速上网、餐饮折扣、停车优惠等权益,还可以参加AI观赛等多元化商场文娱活动。此外,面向商铺、企业,上海移动推出万兆企宽智能服务包和2500万tokens免费体验,助力打造商业体更优营商环境。依托“双万兆网络+云产品+AI”一体化服务,商户可实现智慧餐饮、智慧零售、智慧办公三大场景数字化转型,进一步提升运营效能,提高服务质量。

据悉,上海移动已建成全国领先空天地一体5G-A网络,5G规模保持领先,核心城区、重点区域实现5G-A连续覆盖,并完成40个万兆园区/小区建设,助力“模速空间”打造全国首个万兆大模型创新生态社区。可以预期,环球港的探索若被验证可行,这套方法论将很快在上海其他大型商业综合体中复制推广,助力打造更多“文商旅体展”消费新场景,为“国际数字之都”建设贡献更多移动力量。
C114讯 6月11日消息(水易)日前,施耐德电气关键电源中国中心热管理解决方案创新实验室在上海正式揭牌。作为施耐德电气深化“中国中心”战略、持续加码在华研发布局的又一标志性举措,该实验室聚焦智算时代高密度算力引发的散热与能效挑战,依托覆盖风冷、液冷及风液兼容的全栈测试平台与验证体系,旨在为下一代绿色、高效、可靠的算力基础设施提供关键技术验证与解决方案支撑。

AI时代,数据中心热管理迎来全新挑战
智算时代下,数据中心的设计与运营正在经历重大转型。传统数据中心着重于稳定性和可靠性,而智算时代下的数据中心则更关注于提升计算能力的密度和能效,以应对AI负载增加带来的更高计算需求和能效挑战,但与此同时也带来了运维的复杂性和设备兼容性等挑战。
当前,AI算力中心的服务器机架功率密度几乎均已超过50千瓦,今年施耐德电气也成功交付了功率密度达120千瓦的数据中心项目。IDC数据显示,到2027年,训练算力占比将下滑到27.4%,而推理算力占比将上升到72.6%左右。在这一背景下,有效散热以保障算力输出变得尤为关键。
“这意味着液冷已经不是一个选择题,它不再仅仅是客户用来满足能效、能耗的要求,而是从技术运营角度出发的刚需。”施耐德电气副总裁、关键电源业务中国中心负责人徐栋如是说。

与此同时,为满足人工智能对算力的海量需求,客户对智算中心上线速度提出了极致要求。徐栋介绍,目前普遍是“T+3”的交付时间,客户要求整个产品在工厂完成设计、测试、预制,到现场交付,一共三个月时间。
徐栋表示,施耐德电气关键电源中国中心热管理解决方案创新实验室的成立,正是为了破解从技术到应用的关键瓶颈。该实验室将构建起一个从全链路性能与能效优化到全场景测试的完整闭环,帮助客户有效管控技术风险、优化运营成本,以应对日益严峻的数据中心散热挑战。
全方位升级,加速面向AI的热管理创新
全新升级的热管理解决方案创新实验室在空间与能力上同步完成跨越。实验室面积将扩容50%,并已建成覆盖“风冷-液冷-风液协同”的完整测试平台,其能力具备从性能验证、场景模拟到定制方案开发的全流程赋能体系,成为业内领先的热管理综合验证与创新能力中心。
在部件验证层面,实验室部署的风冷焓差环境室可模拟-40℃至55℃的极端气候条件,可对列间、房间级、风墙、干冷器等产品进行性能及可靠性测试;同时配备兆瓦级液冷性能测试台与管路系统测试站,从一次侧冷源到二次侧负载实现全方位验证;更重要的是,实验室搭建了“风液联动系统级验证平台”,突破了传统部件测试的局限,可通过系统层级联控实现算力与温控的动态优化,并同步进行全生命周期能效与可靠性评估,从而在系统集成层面确保解决方案的能效最优与稳定性最佳。
实验室具备从冷源到IT负载的完整运行环境模拟能力,可动态模拟用户侧的负荷变化与实际工况波动,对系统匹配性及控制策略进行实证检验。通过模拟极限工况,能够前置识别潜在风险,为项目交付提供充分保障。
实验室构建了从技术孵化到场景落地的敏捷转化体系。一方面,依托系统级测试平台,可对新型部件与前沿技术理念进行深度性能验证、可靠性评估与综合价值研判,驱动技术快速迭代以保持领先优势。另一方面,基于客户定制化需求与真实场景,实验室能够快速构建高度匹配的仿真测试环境,实现温控系统与客户特定设备的预集成调试验证。不仅加速了前瞻技术的成熟进程,也可大幅压缩定制化方案在现场的部署与调试周期,显著提升从技术到交付的整体效率与确定性。
深化“中国中心”战略,向全球贡献“中国智慧”
2023年,随着关键电源业务中国中心的正式成立,施耐德电气完成了全球研发资源与中国业务体系的深度整合。这标志着“中国中心”战略迈出了里程碑式的一步,而同期建成的兆瓦级UPS实验室,更为其长期发展奠定了坚实的核心能力基础。
徐栋介绍,“中国中心”战略的核心是以中国市场的需求与中国客户的挑战来定义研发优先级。通过协同本土生态伙伴与供应链,为客户交付覆盖风冷、液冷,以及关键电源、预制化等端到端数据中心解决方案。同时,源自中国的研发成果与最佳实践也将持续融入施耐德电气全球创新网络,为全球算力基础设施的未来发展贡献“中国智慧”。
此次热管理解决方案创新实验室的成立,标志着“中国中心”战略的纵深推进。面对智算时代爆发的高密度、高能效需求,施耐德电气正以此为契机,对自身的技术能力矩阵、研发重点与产品路线图进行系统性重构,从而构建定义和支撑下一代智算基础设施的核心能力。
徐栋表示,施耐德电气将以“适配当下,兼顾未来;协同演进,适度超前;多元兼顾,精准平衡”的愿景指导产品方向。这一理念,正是为了应对AI算力在技术、能耗与场景上的高度不确定性。
徐栋表示,施耐德电气将以 “适配当下,兼顾未来;协同演进,适度超前;多元兼顾,精准平衡” 作为产品创新核心理念。这也正是为了应对AI算力在技术迭代、能耗约束与应用场景上的高度不确定性,旨在通过系统级的动态优化,为客户交付面向未来的、更完整、更绿色、更可靠的AI基础设施解决方案。具体而言,施耐德电气的创新布局聚焦四大核心方向:
第一、筑牢三相UPS市场领先地位,致力于将未来系统能效提升至98%,设计能效提升至99%以上的新高度;
第二、持续领跑AI热管理赛道,推动风冷、液冷,微模块和控制系统的深度预制化与产品化整合,为不同芯片平台提供定制化的热管理解决方案;
第三、赋能绿色能源转型,加大对风电、光伏等新能源产业的研发投入,持续迭代与之配套的UPS电源产品,支持新型电力系统的稳定运行;
第四、前瞻性布局高压直流解决方案,为未来数据中心供电架构演进进行技术储备。
从2023年投运的兆瓦级UPS实验室,到此次的热管理实验室,施耐德电气已构建起覆盖数据中心“供配电”与“温控”两大核心系统的完整前沿研发体系。二者的协同,将形成一个能够直面高密度智算场景核心挑战的系统级验证能力矩阵,为下一代智算基础设施的快速创新提供从技术验证到方案落地的一站式坚实支撑。

Press Release
From accelerating scientific discovery and advancing healthcare research to transforming public services, AI is becoming a critical driver of innovation and economic growth across the U.K. To help advance the next generation of AI infrastructure and AI-powered scientific breakthroughs, AMD, Dell Technologies and the University of Cambridge have announced plans to establish the new Sovereign AI Innovation Lab (SAIL) in the United Kingdom.
The initiative represents a major step forward in the U.K.’s ambition to build world-class AI capabilities while advancing open and interoperable AI technologies.
As nations increasingly view AI as a strategic capability, leadership will depend on access to advanced models and on the ability to combine AI, computing and scientific expertise to accelerate discovery, strengthen competitiveness and fuel economic growth.
Building on a Strong Foundation for AI Research
The announcement of SAIL follows the recent expansion of the University of Cambridge’s AI Research Resource (AIRR) that includes deployment of the Zenith AI supercomputer. Powered by 5th Gen AMD EPYC™ processors and AMD Instinct™ MI355X GPU accelerators integrated into Dell infrastructure, Zenith can provide researchers and innovators with the advanced computing capabilities needed to support increasingly complex AI, simulation and scientific workloads.
Together, SAIL and Zenith will expand access to advanced AI and high-performance computing infrastructure for researchers, healthcare organizations, public-sector institutions and industry partners across the U.K.
As scientific and engineering challenges grow in complexity, access to advanced AI and high-performance computing resources becomes increasingly important. Systems such as Zenith provide researchers with the computational foundation needed to explore new approaches to discovery and innovation.
A Collaborative Hub for AI Innovation
Hosted through the University of Cambridge Research Computing Service, SAIL can serve as a collaborative environment where organizations can evaluate, develop and deploy advanced AI technologies.
The lab is expected to support a broad range of applications across scientific research, healthcare, climate science, engineering, public services and national-scale AI initiatives. By bringing together technology leaders, researchers and public-sector stakeholders, SAIL aims to accelerate the adoption of AI while helping ensure deployments are secure, trusted and scalable.
Advancing Open and Interoperable AI Infrastructure
A key focus of SAIL is the planned development of open and interoperable AI infrastructure built on AMD computing platforms, AMD ROCm™ software and cloud native technologies.
The lab will explore deployment models spanning AI training and inference, scientific foundation models, simulation-assisted AI workflows, trusted research environments and secure public-sector AI services. Through this work, SAIL aims to help organizations build AI capabilities with greater flexibility, interoperability and long-term choice.
Accelerating AI for Science
SAIL is intended to work alongside Cambridge’s growing national AI infrastructure footprint, including the Zenith AI supercomputer and the Sunrise fusion AI system developed in partnership with the United Kingdom Atomic Energy Authority (UKAEA).
Together, these systems will support a diverse range of AI-for-science applications, including healthcare research, climate modelling, materials science, engineering simulation, fusion energy research and scientific AI model development.
Many of the world’s most important scientific challenges require more than AI alone. They depend on the convergence of artificial intelligence, simulation, data and high-performance computing to accelerate discovery and deepen scientific understanding. This emerging approach – often referred to as AI for Science – is creating new opportunities across healthcare, climate science, materials research, engineering and energy.
Supporting the Future of Fusion Energy
One of the most ambitious scientific efforts supported by this expanding AI ecosystem is fusion energy research.
Sunrise is a second Dell-AMD AI supercomputer being built now; funded by the Department for Energy Security & Net Zero (DESNZ), owned by UKAEA and operated by the University of Cambridge. Sunrise is part of a long standing UKAEA-University of Cambridge partnership and dedicated to the fusion mission.
Built on the same Cambridge-designed AMD and Dell architecture as Zenith, Sunrise is designed to help researchers tackle one of the world’s most complex scientific and engineering challenges: delivering fusion power capable of producing net-positive energy. The system also forms part of a broader effort to establish advanced AI capabilities at Culham Campus, home to the U.K.’s first AI Growth Zone.
Enabling the Next Generation of AI Infrastructure
As demand for AI continues to grow across research, industry and government, initiatives such as the Sovereign AI Innovation Lab demonstrate how open technology ecosystems and strategic partnerships can help unlock innovation at scale.
By bringing together advanced infrastructure, open software and scientific expertise, AMD, Dell and the University of Cambridge are helping to lay the foundation for the U.K.’s next era of AI-driven discovery and innovation.
Through Zenith, Sunrise and SAIL, artificial intelligence, high-performance computing and scientific research converge to accelerate discovery, strengthen competitiveness and help solve some of society’s most important challenges.
How is AI supercharging the UK’s digital economy? Join the discussions at Connected Britain 2026
Also in the news
TELUS and L-SPARK give Canadian startups access to AI supercomputer
Belden to acquire RUCKUS Networks for $1.85bn
VMO2 taps Suffolk solar farm for 10 years of clean energy
The post AMD, Dell and University of Cambridge set SAIL on AI lab appeared first on Total Telecom.

作者 | 华卫
昨日,Ramp 发布了最新的 AI Index,一个令人难以消化的核心数据是:最积极采用AI的公司,每月每位员工在AI工具上花费7500美元,约合50807元人民币。
该指数自推出以来,一直专注于追踪最基础的企业AI采用情况。如今,使用 AI 的企业占比正迅速逼近 100%。Ramp首席经济学家Ara Kharazian表示,其结果还很可能低估了实际采用率,因为许多企业在使用免费的 AI 工具,或者员工使用个人账户调用 AI 服务来完成工作任务。
即便在 Ramp 内部,相比去年其 AI 使用量增长了 6300%。团队中有 99.5% 的人都在使用 AI 工具,84% 每周都会用编程代理。在 Ramp 内部平台上,6 周内上线了 1500 多个应用,来自 800 多位不同的“构建者”;非工程师发起的生产代码 PR 已占到 12%,每月达到数千个,他们使用的是自研编程代理 Ramp Inspect。
因此,Ramp 经济研究团队的关注重点正在转向对“采用强度”的追踪,当前样本包括超过7万家美国企业和数十亿美元的企业支出。
五万月薪没到顶,上月就涨了14.1%?
根据 Ramp AI Index 的最新研究,美国按 AI 采用程度排名前 1% 的公司,每位员工每月在 AI 工具和算力上的支出达到 7500 美元,Ramp 将这前 1% 的公司称为“AI-pilled”(AI 上头)。
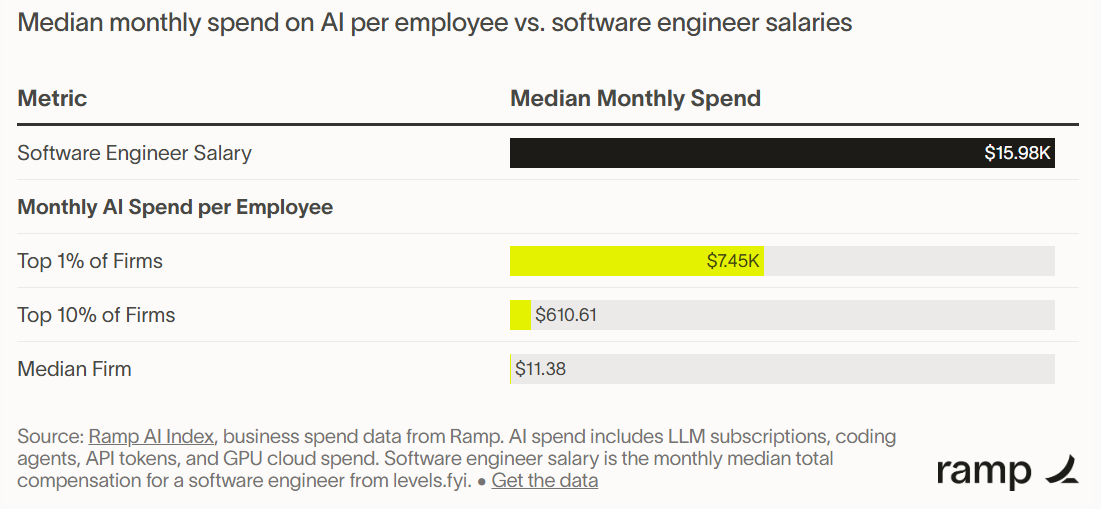
而且,它们已经且还将投入足够长时间。每过去一个月,这些公司都在将 AI 更深地嵌入工作流、积累专有数据,并训练团队使用那些中位数公司甚至还没有认真预算的工具。可以说,处在分布顶端的公司,并不是在“试验”AI,而是在“构建”。仅在过去一个月,这一群体的人均 AI 支出就增长了 14.1%。
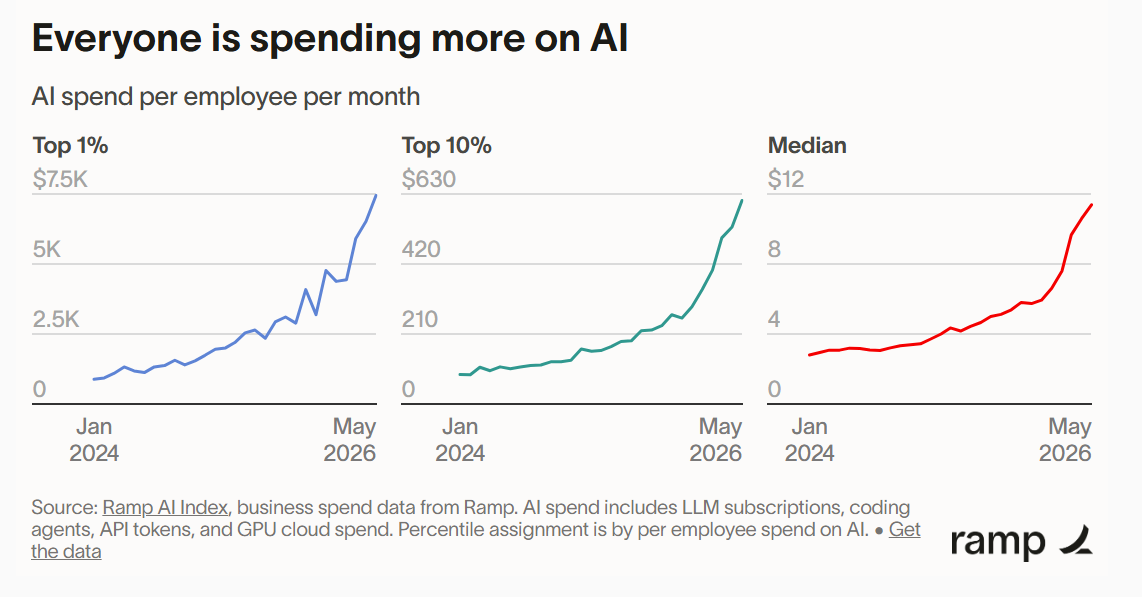
据了解,这些“AI 上头”公司通常采取混合策略,并不押注单一平台。他们在多个来自 Anthropic、OpenAI 等厂商的前沿模型之间来回切换,同时使用通过 Fireworks AI、fal AI、DeepInfra 等推理平台接入的低成本开源模型,包括来自中国、与 OpenAI 和 Anthropic 竞争的 DeepSeek。
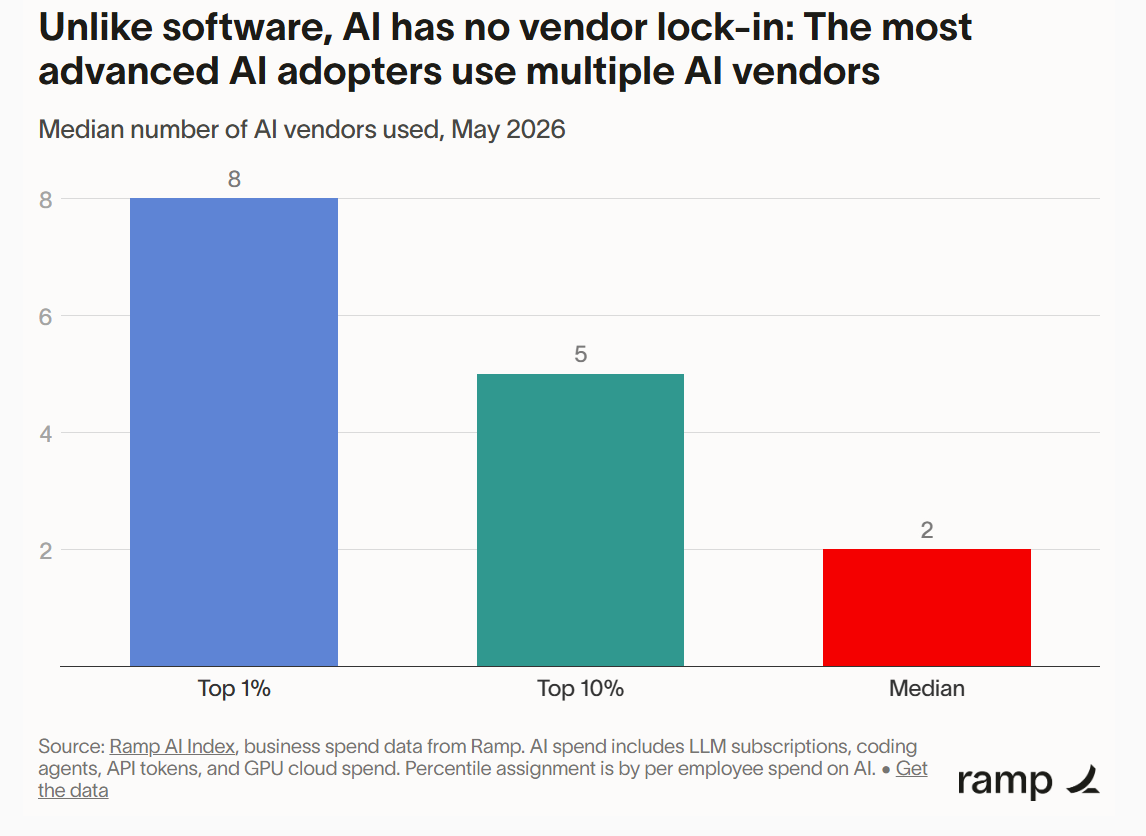
而这种模式并不仅限于头部用户。Ramp 的采用数据表明,Anthropic 已覆盖 41% 的美国付费 AI 企业用户,成为企业端采用率最高的模型提供商;OpenAI 基本持平;DeepSeek 则在 2026 年 6 月的趋势厂商榜中位居第一。一个清晰的趋势是:最成熟的 AI 采购方,往往也是最不愿被单一供应商锁定的那一群。
但Ramp 指出,这些公司目前还没有在 AI 上花得比在人身上更多,美国软件工程师月薪大约为 16000 美元,是 7500 美元的两倍多。也就是说,最激进的 AI 使用者,尚未跨越“AI 成本超过人力成本”的门槛。
关键在于:7500 美元这个数字,是天花板了吗?如果智能体 AI 持续扩大企业自动化的边界,而 token 支出逐渐成为继人力和软件之后的第三大成本中心,那么今天的前 1%,很可能在几年后就会变成中位水平。
token便宜98%、账单翻了三倍,比员工支出都多了
随着企业不断烧掉各自的 token 预算,一个关键问题浮现:公司在 AI 上的支出,是否已经超过了对人的投入?
“对我的团队来说,算力成本远远超过员工成本。”英伟达应用深度学习副总裁 Bryan Catanzaro 近日在采访中表示,AI 并没有降低用工成本,至少在当下,它的成本甚至高于企业现有的人力。
上周,Mercor 的 CEO 也称,这家初创公司在内部智能体的 token 开销上,花的钱已经超过了员工人力成本。Mercor是一家市值100亿美元的初创公司,帮助OpenAI和Anthropic等公司通过其人类专家网络训练AI模型,自2023年成立以来,已成为AI生态系统中增长最快的公司之一。
的确,token 越来越便宜了。如今,实现 GPT-4 同等级性能的成本,大约是每百万 token 0.40 美元,而 2022 年末这一数字约为 20 美元,下降了 98%。然而,根据多项行业分析,企业 AI 总账单却上涨了约 320%。企业平均 AI 预算,也从 2024 年的每年 120 万美元增长到 2026 年的 700 万美元。
问题出在,用量一点都不便宜。自 2025 年 11 月以来发布的一系列智能体 AI 工具,包括 Anthropic 的 Claude Opus 4.5、OpenAI 的 GPT-5.1,以及 Google 的 Gemini 3 Pro,显著放大了单个任务的 token 消耗。2023 年,一个简单的线性流程每次交互成本约 0.04 美元;而到 2026 年,一个编排良好的智能体系统成本约为 1.20 美元,增加了约 30 倍。
这种模式几乎在各处重演:单个 token 的价格已经大幅下跌,但对自主 AI 智能体的追逐,却让总体用量暴涨。今年4 月,Uber 在 就花光了其 2026 年全年 AI 编程预算。微软在为开发者开通 Claude Code 六个月后,又收回了相关许可;在许可证被收回前,微软内部一些工程师每月在 token 上的支出高达 500 到 2000 美元。有公司甚至因为忘记设置使用上限,单月就跑出了 5 亿美元的 Claude 账单。据外媒报道,Priceline 一名员工表示,一次常规的 Cursor 合同续约,价格竟上涨了 4 到 5 倍。
“六个月前,我和客户的对话还集中在‘它能做什么?够不够好?’,现在的对话变成了:‘我们花太多钱了。你们能提供哪些可视化?有哪些 token 控制手段?’”OpenAI 企业业务负责人 Alexander Embiricos 表示。FinOps Foundation 执行董事 J.R. Storment 则更直白地描述了这一转变:“从 4 月、5 月开始,我听到公司在说:‘天啊,我们已经超出 2026 年全年 token 预算的 3 倍了,而现在才 4 月。’整个讨论从‘尽量多用、尽快推进’(tokenmaxxing + go fast),转向‘我们需要护栏,怎么控制成本?’”
工程管理平台 Jellyfish 的研究负责人 Nicholas Arcolano 表示,过去 9 个月中,每位开发者的 token 消耗量大约增长了 18.6 倍。使用 token 最多的工程师,生产力大约是轻度用户的两倍,但为此消耗的 token 却高出 10 倍。“极高的支出是否值得,最终取决于代码产出的商业价值,而大多数公司目前仍无法衡量这一点。”他说道。
那些此前沉浸于“无限量订阅”的公司,如今正拼命搞清楚钱到底花去了哪里,以及这些投入是否真的带来了回报。Priceline IT 财务高级总监 Chris Reed 将这种现象类比为电信计费时代:“这就像‘可卡因成瘾’。他们先让你免费试用让你上瘾,然后你就离不开了。”该公司已经开始对部分团队设置 token 使用上限。Reed 表示,他已经看到供应商报告的使用量与公司内部数据之间存在差异。
高盛预测,到 2030 年,全球 token 使用量将增长 24 倍。
AI 花钱的世界严重分层:差距高达680倍
需要注意的是,人均 AI 支出7500 美元的情况,仅来自于AI 采用程度排名前 1% 的公司。对绝大多数公司来说,AI 支出在整体软件预算中仍然只是一个可以忽略不计的“零头”。
根据 Ramp AI Index 的最新研究,排名前 10% 的公司,每位员工每月 AI 支出约为 611 美元,大致相当于几个企业级 AI 席位加上一些 API 使用费用。而在通过 Ramp 企业信用卡与账单支付平台追踪的超过 7 万家企业中,中位数公司仅为 11.38 美元,大致相当于一个标准软件订阅的单席位价格。
前 1% 与中位数公司之间的差距,高达 680 倍。这也是目前对美国企业 AI 支出分布极度不均最直观的刻画。而这种差距的复利式扩大,或许不仅仅是软件预算的差异。每月只花数十美元的中位数公司,有差距的不仅是订阅数量,可能还有组织基础设施,包括工作流、数据以及需要数月时间建立的内部对 AI 的熟练度。
更值得关注的问题是:一旦 AI 成本超过人力,产出是否能够匹配?而那些已经处在这一梯队的公司,很可能正在实时做这场实验。
“我们现在看到的是一种短期错配。”瑞士人工智能研究院戈登商学院的 AI 与金融教授 Keith Lee 表示,企业正在大规模投入 AI,即便在很多任务上,人类目前仍然更便宜。这反映出“理论上的经济性”和“企业实际决策”之间存在脱节。
尽管目前 AI 可能比人类更贵,但这种情况可能会改变。Lee 认为,随着模型运行成本下降、基础设施持续改进,AI 的经济性会逐步优化。不过,他也强调,只有当 AI 变得更可靠、对人工监督的依赖更低时,它才真正具备成本优势。“关键不只是 AI 比人更便宜,而是它在规模化条件下,既更便宜,又更可预测。”
参考链接:
https://econlab.substack.com/p/how-much-does-it-cost-to-be-ai-pilled"
整理 | 华卫
近日,OpenAI 已向美国证券交易委员会(SEC)秘密提交了 IPO(首次公开募股)申请。所谓“秘密提交”,允许公司在向公众和潜在投资者披露财务数据之前,先将其提交给监管机构进行审查。这家人工智能公司目前估值已超过 8500 亿美元,并一直在为最早于今年第四季度上市做准备。
今年 4 月,OpenAI 首席财务官 Sarah Friar 在采访中表示,对于 OpenAI 这样规模的公司来说,“在各方面看起来、表现得、运作方式都像一家上市公司”是“良好的经营卫生(good hygiene)”。目前,OpenAI也尚未确定上市时机及计划筹集金额。
OpenAI 在一篇声明中表示:“可能还需要一段时间,因为我们有一些事情在作为私营公司时更容易完成。”但公司同时指出,此次提交“让我们在未来如果认为合适时,可以更快选择上市”。
收入目标落空,放开员工股份变现通道
以下是 OpenAI 发布声明的全文:
我们最近提交了一份保密的 S-1 文件。预计这一消息可能会泄露,因此我们选择主动公布。目前尚未决定具体时间;可能还需要一段时间,因为我们有一些事情在作为私营公司时更容易完成。但这是一个复杂的权衡过程,而这一步让我们在未来如果合适的话,可以更快推进上市。
OpenAI CEO Sam Altman 将面临向投资者证明公司价值的压力,尤其是在财务状况方面。OpenAI 已累计融资超过 1800 亿美元,目前仍在持续烧钱,用于获取算力资源以及建设训练和运行 AI 模型所需的基础设施。去年 11 月,OpenAI 首席财务官 Sarah Friar 曾表示,美国政府应为公司在芯片和数据中心上的巨额支出提供“兜底支持”,这一言论一度引发关注,随后她又对此进行了收回。
《华尔街日报》报道称,该公司近期未能达成自身的新用户和收入目标。过去一年,OpenAI 通过扩展 ChatGPT聊天机器人的变现方式来提升收入,包括推出更便宜的 8 美元订阅档位以及引入广告。据 The Information 今年 4 月报道,公司预计这一低价套餐将推动订阅用户数在今年达到 1.22 亿,并预计广告将在 2030 年成为其最大收入来源。
据一位因信息保密而要求匿名的知情人士透露,OpenAI 计划推进一项要约收购(tender offer),允许员工按照最新估值出售股份(该估值为投后 8520 亿美元),以缓解短期内的流动性压力。
过去一年,OpenAI 也在努力证明自身不仅仅是 ChatGPT。该公司发布了网页浏览器,宣布将开发面向消费者的硬件产品,推出了能够在用户电脑上编程并管理应用的 AI 智能体,并开发了面向政府、医疗和金融领域的 AI 工具与解决方案。
在周一的一篇博客文章中,Altman 提出了他所称的“OpenAI 的第三阶段”。他写道,第一阶段是围绕通用人工智能(AGI)进行研究,第二阶段是成为一家“产品公司”,并学习用户如何使用其工具。“现在我们正在进入第三阶段,经济体系正开始围绕 AI 进行重塑。当前的核心问题是,如何让先进 AI 变得充足、可负担、安全、有用,并且足够易用,让每一个人和组织都能从中受益。”
近几个月来,OpenAI 也在内部强调聚焦与纪律性,关闭了一些边缘项目,例如公司的短视频应用 Sora。同时,公司正在加大对企业业务以及编程助手产品 Codex 的投入,该产品直接与 Anthropic 广受欢迎的 Claude Code 竞争。Altman 曾在今年 4 月在 X 上发文称:“感觉 Codex 正在迎来属于它的 ChatGPT 时刻。”
三大 AI 公司冲刺万亿级 IPO,谁先敲钟?
自 2022 年推出 ChatGPT 聊天机器人以来,OpenAI 迅速进入主流视野,并成长为全球最有价值的私营公司之一。目前 ChatGPT 每周活跃用户已超过 9 亿,但 OpenAI 也面临来自 Anthropic、Google 以及埃隆·马斯克旗下 SpaceX(今年早些时候已与 xAI 合并)等竞争对手日益激烈的竞争。
此前外媒报道称,OpenAI 一直在与包括高盛和摩根士丹利在内的投行合作推进上市事宜,而这两家机构也正是 SpaceX 文件中排名最靠前的承销商。
上周,SpaceX 已经启动路演。根据其招股文件,OpenAI、Anthropic 和 Google 都被列为其在 AI 领域的“主要竞争对手”。根据 SpaceX 此次发行的市场反应,Anthropic 和 OpenAI 可能会加快上市步伐,以在巨额融资竞争中抢占先机。就在一周前,Anthropic 也宣布已秘密提交 IPO 申请。而在此之前不久,该公司刚完成一轮融资,估值达 9650 亿美元,超过了 OpenAI 在今年 3 月底的 8520 亿美元估值。
SpaceX 与 OpenAI 同时推进 IPO,发生在马斯克与 Altman 之间一场持续三周、激烈的法律纠纷结束不到一个月之后。一个咨询陪审团裁定,马斯克(他于 2024 年首次对 OpenAI 和 Altman 提起诉讼)提出指控的时间过晚,这些指控涉及 OpenAI 背离其保持非营利性质的承诺。联邦法官随即采纳了陪审团的裁决。马斯克随后在 X 上表示,法官和陪审团“实际上并未就案件本身的是非作出裁决,只是基于时间上的技术性问题”。
值得一提的是,OpenAI和Anthropic的估值均接近1万亿美元。在 Forge Global 这一面向散户的二级市场平台上,Anthropic 的估值近期已升至 1 万亿美元,超过 OpenAI(后者在 4 月约为 8800 亿美元)。而按SpaceX 刚敲定的 IPO 方案,发行价定为每股 135 美元,总募资规模约 750 亿美元, 其整体目标估值高达 1.75 万亿美元。
这三起上市预计将带来高达数万亿美元规模的融资,一方面为普通投资者提供了参与这些最受关注的 AI 初创公司的机会,另一方面也将成为检验市场对 AI 企业热情的重要风向标。不过,谁能率先上市,仍然至关重要。有专家认为,最先登陆资本市场的公司,很可能会拿走越来越稀缺的 AI 投资资金。
参考链接:

长期以来,移动游戏图形技术的发展始终受制于一个核心矛盾:开发者希望获得接近 PC 和主机平台的画面表现,但手机的功耗、散热和电池容量决定了其无法简单复制桌面端的渲染方案。
近日,Arm 与游戏开发商 Sumo Digital 联合公布了一款名为《光影新生》(Neural Dawn)的技术演示型手游项目。
与其说这是一款游戏,不如说它更像是一场针对下一代移动图形技术的实战验证:在有限功耗预算下,如何通过 AI 与图形渲染的结合,让移动设备运行此前主要出现在高端 PC 和主机上的实时光照技术。
该项目最大的意义在于它首次将 Arm 正在推进的“神经图形”技术完整嵌入真实游戏开发流程,并展示了未来移动 GPU 的一个重要发展方向——从单纯提升图形算力,转向图形计算与神经计算协同工作。
从“更快的 GPU”到“AI 参与渲染”
过去几十年,图形技术的发展逻辑相对简单:增加晶体管数量,提高 GPU 性能,再通过更高的计算能力实现更复杂的画面效果。
但移动设备并不具备无限扩展功耗的空间。
随着实时光线追踪、高动态光照、大规模场景渲染等技术逐步进入游戏行业,传统路径开始遇到瓶颈。
Arm 此次展示的核心思路是利用 AI 模型参与图形渲染流程,让部分原本需要大量 GPU 运算完成的工作交由神经网络处理,从而降低总体计算成本。
《光影新生》采用了两项关键技术:
Neural Super Sampling and Denoising(NSSD,神经超级采样与降噪)Neural Frame Rate Upscaling(NFRU,神经帧率提升)
其思路与 PC 领域已经广泛应用的 AI 超分辨率技术类似。
游戏首先以较低成本完成基础渲染,然后利用神经网络恢复图像细节、提升画面质量,并生成更平滑的动态效果。
对于移动平台而言,这意味着:GPU 实际渲染负载下降、功耗和发热压力降低,节省出来的预算可用于更复杂的光照与场景效果。
换句话说,AI 在这里并非游戏玩法的一部分,而是成为渲染管线中的组成模块。
神经技术与虚幻引擎 MegaLights首登移动端
相比神经渲染本身,《光影新生》更受行业关注的一点是其采用了虚幻引擎(Unreal Engine)最新推出的 MegaLights 技术。
MegaLights 是 Unreal Engine 5.5 引入的新型动态光照系统。
传统游戏开发中,大量光源同时存在会迅速推高渲染成本,因此开发者通常需要限制动态光源数量、使用预计算光照并对场景进行大量烘焙处理。
MegaLights 的目标则是允许场景中存在更多实时动态光源,并结合光线追踪阴影进行计算。对于游戏开发者而言,这意味着灯光不再只是装饰环境的背景元素,而可以直接参与叙事、关卡设计和玩家引导。
在《光影新生》中,光线本身被设计成核心玩法元素:玩家在洞穴网络中探索时,光源既承担氛围塑造功能,也承担导航和交互提示功能。
但问题在于,即便在部分主机游戏中,MegaLights 的应用仍然有限,因为其对算力要求极高。
而《光影新生》的技术价值恰恰在于验证:移动设备是否能够借助神经渲染技术承担这种级别的实时光照计算。
Arm 为什么开始在 GPU 中加入神经加速能力
从产业趋势看,这并不是一次单纯的游戏技术展示。更重要的信息来自 Arm 对未来 GPU 架构的规划。
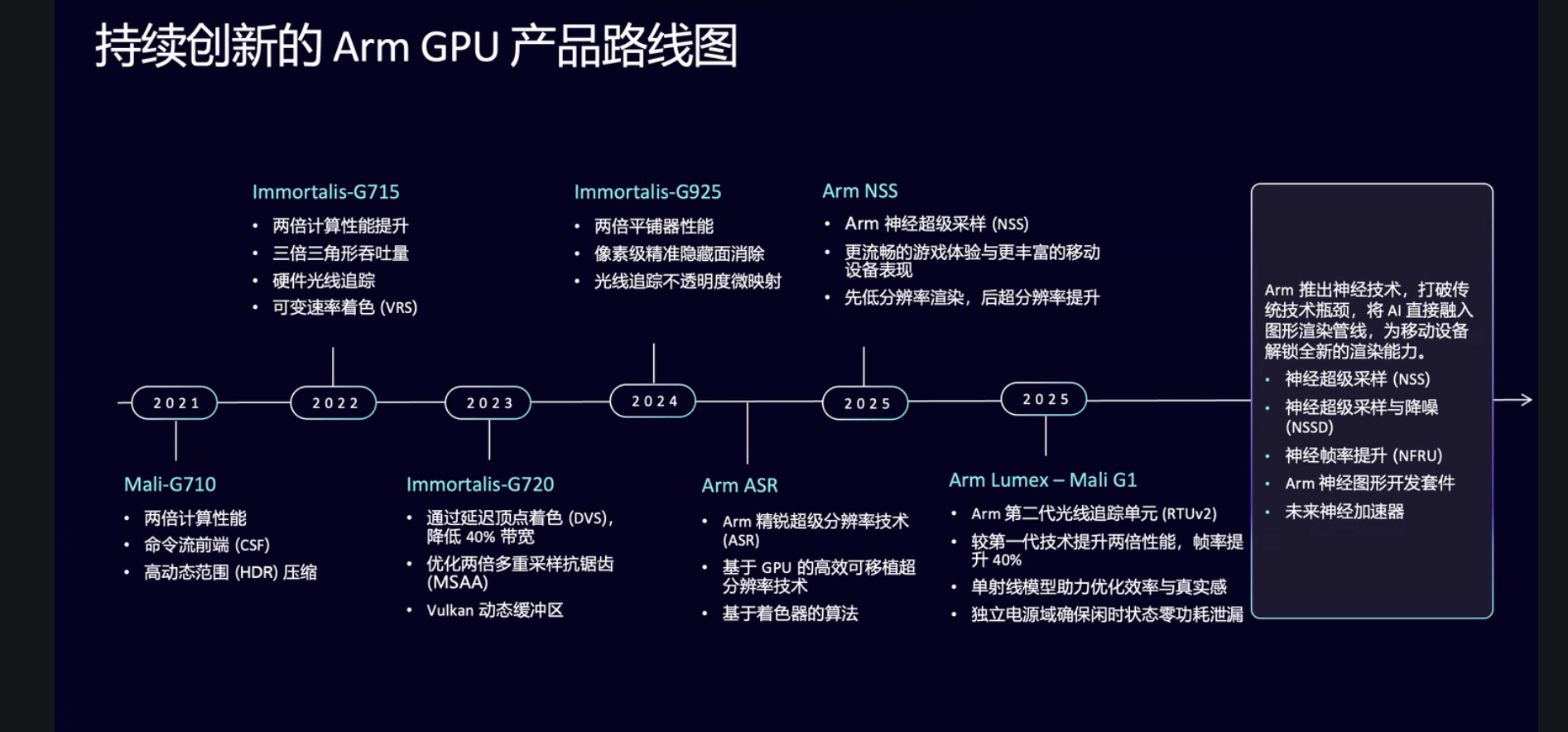
按照 Arm 公布的信息,其下一代 Arm Mali GPU 将首次集成专用神经加速器(Neural Accelerator),并纳入今年晚些时候推出的移动端 Arm CSS(Compute Subsystem)平台。
这意味着未来的 Mali GPU 不再只是图形处理器。其设计思路开始接近 PC 领域近年来兴起的 AI+GPU 融合架构:
GPU负责传统图形计算;神经加速器负责 AI 推理;两者共同完成图像生成与优化。
从技术演进角度看,这也是行业的共同方向。无论是 PC 显卡中的 AI 超采样技术,还是手机 SoC 中不断增强的 NPU,本质上都在利用神经网络替代部分传统渲染工作。
Arm 此次展示的重点在于:这种模式开始从实验室研究进入真实游戏项目验证阶段。
对于游戏行业来说,新技术能否落地,往往不取决于技术本身,而取决于开发成本。
如果一项技术需要重写渲染管线、重新培训团队,那么即使效果再好也难以普及。因此 Arm 此次特别强调:开发者可以通过 Unreal Engine 插件直接接入相关能力,而不必构建新的图形架构。
根据官方披露的信息,《光影新生》由 Sumo Digital 一个约 17 人的团队开发,项目周期约 18 个月。
更重要的是,其采用的工作流与未来开发者接入 Arm 神经图形开发套件时的流程基本一致。

对于开发者而言,这意味着无需自建 AI 渲染框架也无需大量底层优化工作,就可以在现有 Unreal Engine 项目中逐步引入相关能力。这也是 Arm 后续发布《Arm 神经技术实践指南》以及神经图形开发套件的重要背景。

AI 代码生成率冲到50%以上,研发周期却没变短;非研发人员开始用 Vibe Coding 写软件,但信任感在下降。AI Coding 都这么强了,在企业级开发中的应用到底卡在哪?
近日,InfoQ《极客有约》X AICon直播栏目特别邀请贰贰壹咨询合伙人&蜂量科技 CEO 张子天担任主持人,和小红书 AI Coding 总架构师郑鑫祺、快手 AI Coding 负责人李京一起,在 AICon全球人工智能开发与应用大会"2026上海站 即将召开之际,共同探讨AI Coding 在企业落地中的真实难题。
部分精彩观点如下:
会用 AI 工具不等于个人提效,个人提效也不等于组织提效。工具始终是手段,真正能达到整体吞吐量提升、人均效率提升、代码产量提升的,协作才是终点。协作系统不只是多个 Agent 并行,还包含人和 AI 之间协作关系的重构。现在有一种说法:Code is Cheap。以前是“Talk is Cheap, Show Me the Code”,但现在 Talk 也没那么 Cheap 了,你的想法表达、输入可能更重要。组织形态肯定会变化,而且已经在发生,更闭环、更具创造力的组织,迭代空间更大。当 Token 费用单价足够便宜时,ToC 应用反而会更爆发出来。
在 6月 26-27 日将于上海举办的 AICon全球人工智能开发与应用大会"2026上海站 上,我们特别设置了【Agent企业级研发体系的重构"】专题。该专题将系统探讨如何将 AI 深度嵌入需求、架构、开发、测试与运维全流程,打造人机协同的新型研发范式。
查看大会日程解锁更多精彩内容:https://aicon.infoq.cn/2026/shanghai/schedule
以下内容基于直播速记整理,经InfoQ删减。
完整直播回放可查看:
行业现状与认知冲突
张子天:过去一年,AI Coding 的热度已经从"尝鲜"进入"大规模落地"阶段。但现在很多企业都遇到了一个共同问题:AI 代码生成率越来越高,但需求交付效率并没有同步暴涨。企业 AI Coding 今天真正卡住的核心问题是什么?
李京:快手从 Copilot 时代开始做智能化提效探索,经历续写、Agentic 多文件生成、到 SDD 推进复杂任务。续写时代 AI 代码贡献率个位数,Agentic 时代跃升到百分之二三十,今年已到百分之五六十。但遇到了问题:工程师体感提效40%,研发周期却没怎么变化,个人承接需求数和组织吞吐都没有很大提升。我们洞察到:会用 AI 工具不等于个人提效,个人提效也不等于组织提效。问题有三方面:组织层面,还是传统产研团队模式;协同层面,上下文在传递中不断流失;知识层面,业务知识、领域知识、研发知识没有很好地沉淀打通。
郑鑫祺:AI 生成能力基本没问题,核心问题在验证和前期对齐上。它把生产力拉上去了,但交互链条各环节没跟上。第二个问题是组织协同,AI 让个人变快了,但整体组织效率是否还适合原来的传递链条要打问号。第三个点,企业大型分布式系统过去过度微服务化和中台设计,在 AI 环境中导致研发环境分散,需要工程治理和模型能力互相衔接来解决。
李京:我们经历了几个阶段:AI First 阶段是人去应用 AI,传统工具结合 AI;现在叫 AI Native,让整个东西是 AI 原生的——从为人设计工具,到结合 AI,再到部分工具专门为 AI 设计。
郑鑫祺:背后还有人和 AI 的地位设计哲学。AI 工具发展特别快,有的是助理型,有的在提独立个体。到底人扮演什么角色?在电商等复杂领域,人的决策判断依然关键;但也有很多确定的 PMO 流程,AI 可以承担更多。这些会导致协作关系变化,对上层工具设计提出不同要求。
张子天:AI 来了,大家总觉得是"金锄头"——皇帝种地也用金锄头,或把驴换成 AI 机械驴,显然不是最佳实践。过去大规模研发中形成的岗位分工和协作方式,在 AI Coding 时代可能已不适合。不只是研发层面的前后端合并,产品层面、需求业务方都需要重新整合,找到职能分工的新边界。但组织变革牵一发而动全身,大中企业比较谨慎,只能循序渐进。
张子天:今年大家明显能感受到,AI Coding 正在从 Copilot → Agent → Multi-Agent → Agent Team 快速演进。同时,越来越多企业开始做面向非研发的 Vibe Coding 和 NoCode Agent。你们怎么看这波变化?未来企业真正需要的,是"更强的 AI 编程工具",还是"一个新的 AI 协作系统"?
郑鑫祺:从 Copilot 到 Agent Team,一直在往前走的是工具。但工具始终是手段,真正能达到整体吞吐量提升、人均效率提升、代码产量提升的,协作才是终点。协作系统不只是多个 Agent 并行,还包含人和 AI 之间协作关系的重构。在我们 Vibe Coding 产品中,深度研究从需求到上线每个节点中人和 AI 的关系,哪些 AI 可以去决策和协作,哪些必须人来做关键判断。社区通用方案偏向单兵视角提效,在整个协作过程中是缺位的。推进也不能太激进,单兵阶段先达到一定指标,过程中用 Claude 加各种 Harness 体系丰富知识库和上下文采集,再慢慢往终点推进。
李京:过年前后 OpenClaw 发布带来了开源形态和新使用模式,让更多人认知到 Agent AI 能干什么,之后大量非研发人员开始使用。关于 Agent 协作系统,我们做了几方面:一是生态建设,CLI 加 Skill 让非研发人员在内部生态里实现角色提效;二是知识打通,团队层面的互联互通;三是任务编排,业界有 Web 看板或以角色划分组建 Agent Team 等方式,还没有特别成熟的方案。
郑鑫祺:我想问李京老师一个问题。在知识整理这块,一个大的域有非常多的跨系统知识,一个需求涉及多个系统。怎么样在过程中让大家沉淀需求、沉淀知识、沉淀哪些知识?
李京:我们走了几个阶段。第一阶段做研发域和业务域知识构建,类似 Project Wiki,跟业务侧联动做业务属性标注,也面向 AI 做业务角度的组织,把工具使用等信息做成知识放进去。第二阶段做流转平台,从需求分析、灌入任务,到 PRD、单测、代码产生,整个链条串联。第三阶段是"自进化"——知识需要迭代起来不是死的,随着大家重点迭代方向和 Skill 使用情况,去迭代 AgentOS 里的知识和记忆体系。
郑鑫祺:现在每个人在单仓里已沉淀了很多 Knowledge,不管是 Code Graph 还是 PRD、各种总结。缺的是怎么提升 SDD 模式中 Spec 的质量和降低对话成本。花两小时对齐 Spec 再加一小时 CR,和熟练工程师上手差不多。Spec 质量上,更关键的是记忆的迭代和关键记忆的抽象。早期推动容易没指标牵引,大家都在整资料,指标最终最关键。
李京:在有限上下文下,不可能把所有知识全灌进去。除了上下文迭代策略,我们也在效果层面做把控,每个环节针对性沉淀评测和用例,保证 Agent 按效果优先的方式不断提升。
张子天:刚才二位老师讲的内容都是企业已经在实践的,这些内容都建立在一个非常强大的已有 Knowledge 基础之上。对于一些中小团队,落地其实更难,他们很难有专门的架构方向的人,既能深入业务,又能把不同模块、不同业务场景的东西真正梳理到一起。中小团队更多人就是铺在业务上,针对某一个需求、某一个 Feature、某一个单点系统去做。不知道二位对中小团队的场景有没有比较好的建议?
郑鑫祺:中小团队反而有更成熟的方案可直接使用。大厂因为有大量历史技术债和过度设计系统,需要花更多时间建设"航空母舰"。中小团队系统架构接近社区,Claude Code 加 Harness 体系本身是 Work 的,纳入更快。但核心要关注效果优先——做了很多 Knowledge 结果效果没变化,沉浸于"赛博精神病"里。Spec 对焦轮数、采纳率等指标要非常关注,以此反推知识沉淀。
李京:中小团队落地更快速。社区里 Claude Code、OpenCode、各种 Agent 和 Harness,买几个 Token Plan 就能有效 Run 起来。即使大企业,优秀实践也是把大组织拆成小团队,通过 Rules、AgentsMD、Spec 等逐渐形成标准化。Agent 基础设施、使用实践、研发流程,都有成型方案。
郑鑫祺:小团队核心要关注成本,很多测试烧了非常多 Token,要用更低成本把事做成。
企业级 AI Coding 的真实难点
张子天:现在很多 AI Coding 产品 Demo 都很强。但真正进入企业生产环境之后,很快会出现几个经典问题:长任务越来越偏、AI 自己乱改架构、上下文失控、结果不可复现、用户一句话把任务带偏……这些问题本质上不是模型问题,而是系统问题。你们内部分别是怎么解决的?
李京:长任务是我们一个专门的研究方向,在"不计成本"的情况下,Agent 能不能完成更复杂的任务。目标就是让 Agent 不间断地执行,一直到完成任务。
我们分两个阶段来看。第一阶段是 Human in the Loop,人需要跟 Agent 交互。第二阶段是 Human on the Loop,人抽离出来,作为观测者看 Agent 执行,怎么去纠偏。
在第一阶段,当人需要参与 Agent 循环时,复杂任务执行偏的成本越来越高,因为它改的代码非常多,回退时影响很大。我们做了几个方面的探索:
在前置环节,一是任务澄清,我们跟这个方向叫"主动性",希望 Agent 在执行任务或做计划之前,先了解清楚自己是不是真的理解了问题。当时我们做了探索,让 Agent 主动问我问题,当它不清楚的时候要不断问。后来发现社区的 Superpower 也有这个过程。二是计划,也就是 SDD,希望在前置把计划做得更明确。我访谈过一些同学,他们甚至已经不去看写代码的过程了,但一定要看写计划的过程。在前置确认计划 OK,最终代码因为现在 Agent 或模型比较强,基本也就没有太大偏差。
在后置环节,Agent 写的代码越来越多,让人 Review 也变复杂了。我们做了两个探索:一是让代码变更可视化,让人更快 Review;二是让 Agent 交叉 Review,或者做测试计划并把测试结果执行出来做 Verify。
第二阶段,人作为观察者,让 Agent 自我执行复杂任务。我们主要在加强做计划和做 Research 的能力,让 Agent 做出来的计划基本能完全一把过,写出来的效果在前置就有很好的把控。
还有一个中间探索:上下文窗口有限,如果不断往里塞东西会出问题。所以我们做了 SubAgent 的探索,在前置、后置以及中间执行环节里,让更合适的模型、更合适的 Agent 去做更合适的事情,一定程度上保证上下文不被浪费过多,信息不会太失真。
郑鑫祺:在小红书 Vibe Coding 场景,面向非研发群体,很多时候追求的是 0 Code。0 Code 的背后,在 Human in the Loop 情况下,更多是 Shape Up 理念的应用:先给一些模糊的东西,AI 来问精准的问题,再给一个 Demo,再往下跑。
在实践完了之后,到了真正产出质量的阶段,对于非研发或产品人员来说很难去纠正,这时候就需要模型去执行,所以这里有非常多的模型控制论和模型智能之间的 Balance。模型智能在不断增加,但因为 Context Length 和 Transformer 的上限,上下文问题始终需要精细化控制和解决。这不是 OpenClaw 带来的 AgentOS 能解决的问题,它更多解决的是生态问题:让更低成本地融合 Skill。但在模型控制的角度,还是需要更精细地把专家经验融入进去,变成一个 Workflow。
在我们的实践中,小红书自研了整套上下文框架和 Agentic 体系,来保障每个关键决策和判断能被精细控制,各种 Hook、各种纠正模型行为的手段,来保证质量达到 90 分甚至 100 分。但它一定会牺牲一些泛化性。这也是后续要解决的:先精再泛,在泛的过程中再去看如何利用好泛的 Skill 和精致的东西来编排精的流程。
对于Human in the Loop,背后更多是 Shape Up 理念在产品中的运用,即什么时候该问。Claude Code 有时候问得非常打断人,有时候沟通几个小时,这不可接受。所以需要一个更好的设计哲学,定义流程让 AI 遵守,包括怎么更好地探索、什么时候不让 AI 说话、什么时候命中。这块如果要做精细,确实有很大投入。但模型在增长,这块始终是一个需要打磨的方向,让效果一直冲到 100%。
张子天:现在很多企业已经开始遇到一个新问题:AI 生成代码越来越多,但大家对代码的"信任感"反而在下降。比如:AI 会自己造轮子、不遵守组件规范、安全边界不清晰、代码不可维护、上线风险越来越大。甚至很多团队开始担心:"未来会不会产生大量 AI 技术债?"你们内部怎么看这个问题?
郑鑫祺:中小团队或 AI Native 型组织,给 AI 更多自主权,定期关注腐化走势、定期重构。大厂逻辑下,关键决策依然靠人,比如 SDD 确认是人来做决策,不是让 AI 直接往下跑,因为很多东西不可逆或成本很高,数据库塞乱了影响面就很大。长程任务要做更多 Verify 的精细制作,前端有 UI 比对,中间有 TDD 驱动开发,还有各种自动化测试。最后的 CR 环节是核心信任度——线上出了 Bug 都修不来了,因为对 AI 掌控度不够了。原来只看 Diff 的 CR 方式不够,需要更有追溯链的 CR 方式。但最终上线的 Confirm 一定是人来确认。
李京:现在有一种说法:Code is Cheap。以前是“Talk is Cheap, Show Me the Code”,但现在 Talk 也没那么 Cheap 了,你的想法表达、输入可能更重要。非严肃场景就看效果,代码可维护性基本不用看。严肃生产系统分三个角度:一是 AI 为什么写出烂代码?可能是没把代码规范和架构设计适配到它的角度,更前置地告诉 Agent 怎么写代码,烂代码的可能性就降低;二是写完代码让 Agent 交叉 CR,用智能化 Review 校验;三是 AI 具备自我迭代能力,遇到 Bug 可以先自己改一轮。归纳为:架构设计提前告知 AI;交叉 Review;Agent 自我迭代、Verify 和 Auto Fix。
郑鑫祺:要产出有品味的代码,还是需要架构师来定。你给它的 Knowledge、Trade Off、Spec 中的每个 Choice,未来会被记忆住。同样的工具,外包同学和架构师使用的效果差距很大。优秀的人依然非常重要。
张子天:AI 对人的能力放大效果非常明显,能力越强的人放大越多。
观众:我们现在如何去追踪和量化 AI Coding 研发项目中的问题?
李京:最早建立浅层指标如代码生成率、智能 CR 生成率等,但最终看的是哪些被真实采纳、真正起到效果。度量体系很重要。
郑鑫祺:指标要和阶段目标相关。推广期以渗透率和 AI 代码占比来看,用 AI 就认为拥抱 AI。都用 AI 之后就要看速度和价值。速度就是人均吞吐,类似复杂度的需求原来排期五六天,估时降低了人没变,AI 贡献就更大。价值方面,哪些 Demo 真正产出了有价值的东西。Valueless 应用太多就很难平衡 Token 价值。还提出 Benchmark 驱动方式,按阶段拆二三级指标跟进与行业 SOTA 比较。
李京:内部有专门的架构治理组,在 AI 时代建立了工程架构度量体系,对架构质量评分,一定程度上防止了架构和技术劣化。快手的另一个探索是需求分层(L1-L4):L2 是 Agent 辅助;L3 是 Agent 更多协同;L4 是 Agent 端到端交付。不同层级有不同观测——L4 希望 AI 端到端交付,把控指标更多看 AI 真正完成的效果和需求吞吐是不是真的变化。
张子天:今年特别火的一个方向是:"非研发开始写软件。"产品、运营、设计、数据团队都开始直接用 AI 生成应用。但这也有很多争议:有人觉得这是未来,也有人觉得这只是 Demo 幻觉。非研发真的会成为 AI Coding 下一波最大的用户群吗?
李京:会,这件事正在发生。AI Coding 本来为研发群体做的,但研发群体在少数,今年越来越多非研发涌入。社区里判断:Coding 本质是软件的表达形式,是创作,就像写文字,创作软件未来会平权到每个人。我们甚至做了基础设施:AI 写完代码做成 Skill,跟企业内部登录系统打通,用泛域名提供域名,把静态文件和服务用 Serverless 跑起来,接云 DB。运营用它做报名系统,财务做分析小系统,更多人把想法以网页表达出来。
郑鑫祺:硅谷很多人眼中未来 Office 就是 Claude Code。OpenClaw 火了后越来越多同学因 AI 扶持 Builder 出很多有价值的项目。小红书给非研发做了很多工具,包括我负责的 Muse,直接创意后部署上线,有数据库、有 AI。核心还是看谁能发现需求、了解用户、有品味判断力。技术人员在专精领域还是主体,但纯写代码要求会更高。
张子天:过去研发像"雕版印刷",只有少数人识字、会编程。现在有了 AI Coding 就像"活字印刷术",让更多人掌握了编排和印刷技术。
观众:小红书目前是怎么确保系统安全的?
郑鑫祺:最终上线和负责还是有人把控,不是 AI 直接发布。如果今天有 AI 直接发布,那一定是 Demo,类似内部社区做内容,不是直接面向用户的。整个过程人的把控在小红书一直非常关注,不会直接上线。
李京:如果把 Coding 能力开放给大家,尤其做偏生产级系统,确实需要保障。数据安全方面,非专业计算机训练的人 Sense 没那么全面,危险操作(数据库、发布)、接支付、API 对接出去都有风险。面向非研发的系统需要特别关注。除了安全还有成本,非研发人员 Create 或产出,ROI 也需要衡量。
郑鑫祺:核心还是最终质量和安全依然由原来的人把控。AI 帮非研发做自动化工具、做报告、数据分析,大家 Build 自己的助理,做 Demo 也能很快跑通,这块比较成熟。但要做大型应用,依然需要安全、数据等专家把关。
观众:在 AI 贡献率层面上,有没有比较好的办法精准评估?对于初创或刚转型做 AI Coding 的团队,怎么评估落地效果?怎么针对性提升?
郑鑫祺:本质是顶层指标拆解的逐步演进过程。关注工具渗透就埋渗透数据,关注使用效果就统计需求吞吐情况,更精细的包括采纳率、知识命中率等。
李京:在不同阶段看不同指标,从渗透到 AI 代码贡献,再到 ROI 和需求吞吐。快手还做了需求分层(L1-L4):L2 是 Agent 辅助,L3 是 Agent 更多协同,L4 是 Agent 端到端交付。不同层级有不同观测。
郑鑫祺:不同的 L 之间的 Bar 有没有很明确的定义?会不会有难以划分的问题?跟原来低代码有点像。
李京:确实会有这个问题。我们在做需求分级时经过了比较多的讨论,而且是拿着真实需求去拆解的。
郑鑫祺:这确实是大家都面临的问题:工具很多,需求到底用什么样的方式去推?很多时候中台认的 L4 方向,但演进过程中业务又要发展,一定会有一个渐进式推进的过程。有时这个需求是 L2,过段时间工具成熟了可能变成 L3 或 L4。需要业务架构师动态判断。
观众:AI Coding 如果不需要初级程序员了,只有高级工程师的概念,如何从头去培养这样的人群?是不是要断层了?
李京:不会断层。AI 来了之后能力边界变得很扩充。首先,初级和高级的分层开始模糊——跟 AI 不断对话中 AI 会给人很多启发,之前需要经验积累的知识 AI 一定程度上能补齐,但需要经验把控的地方还是有的。具备好奇心、动手能力、创意和分享能力的同学成长更快。其次,职能边界也开始模糊——程序员跟 AI 共创时可以写出竞品调研方案和 PRD,用 AI 工具画出高保真原型,能力边界被很大扩充了。
郑鑫祺:不管初级还是高级,定义没那么重要了,可能就是个符号。在不同领域,品味、判断和创造力的内涵不一样——做大模型是技术判断,想做调酒小程序是要更懂那些人和需求。但有一点是肯定的:要以 Builder 的心态去看问题,要有好奇心。Hackathon 里那些同学比较有这种 Taste,有小创意自己去 Build,快速学习、自我迭代。
张子天:好比汽车工业早期,驾驶者是少数。当自动挡和新能源车出现后,人人都会开车了。评判标准可能都已经变化,不是能力强弱的问题,而是分领域了。
张子天:现在企业面对 AI Coding,还有一个特别现实的问题:外部生态的发展速度,已经远远超过企业内部自研速度。从 Cursor、Claude Code、Devin,到 OpenClaw、Harness、各种 Agent 平台,新的能力几乎每个月都在变化。很多企业现在都在纠结:到底应该自研、采购、还是做混合架构?企业内部已有研发体系,又该怎么和外部 AI Coding 生态融合?企业级 AI Coding 最核心的壁垒,到底是模型、工具,还是组织与系统能力?
郑鑫祺:Cursor、Claude Code 等热门产品大部分是单兵控制面,核心设计是一个开发者在屏幕面前,AI 帮他把活干快。这是以模型视角出发、以超级个体效率最大化为目标的方向。小组织、AI Native 完全采购用社区方案就好。但企业级复杂协同场景下,一个需求提出到上线跨越多个系统、多个仓库、多个团队、多个云环境,模型公司的单兵工具天然不会碰这一层。需要自建知识和工具,使用社区方案去运用,实现生产关系和生产模式的进化。
李京:一人公司懂代码的,社区方案拿来直接用。创业团队看当前阶段目标,如果目标就是更快完成业务、更快赚钱,ROI 能打正的情况下直接采购更好。大型组织自研有几个方向:一是 Skill 生态跟企业内部打通,构建成本不一定高但收益高;二是配套基础设施如知识工程;三是数据安全等红线,甚至需要模型层自部署。分场景、分阶段来看。
郑鑫祺:核心还是看你当下要解决什么问题。尤其针对非以研发产品为核心的企业,能自己做的部分越少越好,更多还是用好这个能力,提高企业产业效能。
未来判断
张子天:如果站在 2028 年回看今天,你们觉得:AI Coding 最终改变的,只是"程序员写代码"这件事,还是整个软件公司的组织形态?到那个时候,一个真正的 AI Native 企业会长什么样?
郑鑫祺:改变的已经不是软件公司了。Anthropic 预测 2026 年有一人独角兽,现在已经出现了,不是终点是起点。到 2028 年不存在纯粹的软件公司,所有公司都是 AI 公司,区别是谁先想明白。改变的不是程序员,而是整个交付链条上每个角色存在的理由。但我还是认为有品味、有判断的人依然非常重要。AI 和人的关系最多到 Peer,现在可能是助理,但不应该是奴役人的方式创造价值。核心竞争力是你能不能先发现别人没发现的需求,更快创造价值、得到收入。
李京:变化是天翻地覆的。Anthropic 一直说自己的代码 90% 以上是 AI 写的。组织形态肯定会变化,而且已经在发生,更闭环、更具创造力的组织,迭代空间更大。同理,即使在更远的以后,人的判断和品味也非常重要,能做出的作品还是不一样的。
郑鑫祺:模型上限还没完全 Touch 到,硅谷很多人认为预训练还有很大空间。但上下文长度没解决,这两年还是有很多上下文工程和场景工作要做,并不是 AGI 就出来了。人的关注点可能不是像以前钻在知识理性的逻辑链中,感性经济或被忽视的东西可能更重要。
李京:现在好模型成本还挺高。假如两年后基建和技术突破,模型成本降到极低,像 SSD 硬盘从很贵变成廉价基础设施,就像用电一样,更多改变会发生。消耗 Token 没那么心疼了,会大幅释放个人和组织的生产力和创造力。
郑鑫祺:如果是那个模式,企业形态可能要另论了。但目前模型成本依然高昂,ToC AI 应用首先要解决价值和成本问题。软硬一体公司可以把推理成本融到硬件里,解决一个领域的精致化服务达到 ToC 扩张。不然更多场景还在 ToB,因为这样才能算清 ROI。
张子天:好比移动互联网时代早期,10 块钱 30 兆流量,到现在 10 块钱可以买好几百个 G。当 Token 费用单价足够便宜时,ToC 应用反而会更爆发出来。
会议推荐
6月26-27日,AICon上海站"即将开幕!60 + 顶尖专家携一线实战案例齐聚,聚焦构建可信赖、可规模化、可商业化的 Agentic 工程实践,一站式打通 AI 工程化卡点、从源头避坑!欢迎报名咨询👇

微软在旧金山举办的 Build 2026 大会上正式发布 Foundry 的多项新功能。Nick Brady 在一篇博客文章"中将 Foundry 称为“AI 智能体从实验落地到生产系统的平台”,他表示此次发布为开发者带来了生产级智能体所需的“运行时、工具、记忆、场景对齐、模型、可观测性与管控能力”,而不仅仅是新的模型端点。
Foundry 是微软打造的“AI 应用与智能体工厂”,一个统一的 Azure 平台。微软将其定位"为一个可互操作的平台,帮助团队搭建、完成场景对齐并管控能够理解业务上下文的 AI 应用与智能体,同时实现各智能体之间可观测数据与管理策略的共享。Foundry 文档强调了与 Azure 服务、Microsoft 365 数据源以及工具和框架开放协议的原生集成。
Foundry Agent Service 中的托管智能体提供托管沙盒会话,具备状态管理与文件系统访问能力,兼容多种框架,同时对外提供有状态的 Responses API 和更轻量化的调用协议,支持直通调用。同一运行环境可运行 OpenClaw、Hermes 等长时智能体,支持状态与文件持久化;目前处于公共预览阶段的例行任务功能可按计划调度智能体,完成夜间工单分类、日报生成等工作。以上这些新增的功能是对 InfoQ 2025 年报道的 Azure AI Foundry Agent Service 正式发布版本"功能的拓展,该版本此前已推出多智能体编排、智能体间 API,并支持 Semantic Kernel、AutoGen、CrewAI 等主流框架。
博客接着介绍了工具与分发相关内容。Foundry 中的 Toolboxes 目前处于公共预览版状态,它为智能体提供统一托管端点,支持工具、技能、模型上下文协议(MCP)客户端及企业数据集成。工具只需完成一次注册就能在运行时被发现,无需逐个接入各个智能体。Skill 可进行版本管理,项目内的资源可通过 MCP 对外暴露;平台还具备工具检索能力,能为不同任务筛选出少量适配工具,而不是将全部工具都推送给模型。微软还新增了可从 Foundry 直接发布至 Microsoft Teams 和 Microsoft 365 Copilot 的功能,该功能计划于 2026 年 6 月正式上线",让基于 Foundry 构建的智能体融入员工日常办公场景,并自动沿用现有身份、权限与管理策略。
Foundry 将“记忆”视为平台级能力,而不是应用级能力。2025 年底推出公共预览版的 Foundry Agent Service 记忆功能如今支持过程性记忆、用户记忆与会话记忆。本次 Build 大会首次推出的过程性记忆可帮助智能体在多次运行过程中习得任务执行方式,早期基准测试表明,启用该功能后任务成功率有所提升。InfoQ 此前在相关报道中介绍",这项服务会从对话里提取关键信息与执行流程并加以整合,然后通过由 Entra ID 等标识划定权限范围的托管存储完成数据检索,同时支持留存和检查控制。
过程性记忆帮助智能体在多次运行中学习如何执行任务,而不仅仅是记录了什么,早期 Tau bench 测试结果显示,绝对成功率提升了 7% 到 14%,而成本几乎与基线持平。——Nick Brady
场景对齐与检索能力通过 Foundry IQ 实现,Brady 将其定义为智能体底层的知识层,把 Work IQ、Fabric IQ、Azure SQL、文件搜索及其他各类数据源统一整合至同一个具备服务等级协议(SLA)保障的检索端点下。在本次 Build 大会上,微软推出了处于公共预览阶段的 Foundry IQ Serverless、已正式发布的多源知识库,以及用于实时网络场景对齐的 Microsoft Web IQ。该服务响应时延低于 200 毫秒,且承诺不留存任何数据,同时具备加密、权限同步、敏感度标签治理等安全能力。在另一篇深度解读文章"中,Satyanarayana Padidapu 将整合了 Work IQ、Fabric IQ 与 Foundry IQ 的 Microsoft IQ 称作“智能层”,它能够简化重复的检索增强生成流程,并将场景对齐能力打造为 Copilot Studio、Microsoft 365 以及 Foundry 智能体可共用的服务。
在模型方面,Foundry 的目录新增了四个第一方 MAI 模型的公共预览版:MAI Thinking 1 用于聊天和推理、MAI Image 2.5 用于图像生成和编辑、MAI Transcribe 2 用于带说话人分离的语音转文本、 MAI Voice 2 用于支持语音克隆的多语言文本转语音。Foundry 平台上的 Fireworks AI 现已正式发布,通过单一 Azure 端点提供对开放模型的访问,配备企业级服务等级协议(SLA),支持自定义权重模型,同时兼容 Foundry 的访问控制与日志能力。Vesa Nopanen 在分析 Foundry 平台上的 Claude Opus"时表示,这种模式对于既想使用前沿模型、又需要依托 Azure 管控能力的企业而言,是一次实质性升级。他还提到,这类模型开箱即用、延迟更低,且能对接 Foundry IQ 与 Work IQ,为智能体提供场景锚定能力。Foundry 模型的托管计算功能可跨区域调度工作负载,突破本地 GPU 资源限制,支持模型微调与前沿调优。微软声称这比直接使用 GPT 5.5 进行技术文档生成等任务更具成本优势"。
要对各类智能体框架进行追踪与评估,团队无需在技术栈和可观测能力之间二选一。你可以继续使用 LangChain、Semantic Kernel 或自研代码,同时在 Foundry 中获得生产级的追踪与评估能力。——Nick Brady
除了 Build 大会相关内容回顾之外,微软和社区作者梳理出了一种分层架构:Microsoft 365 Copilot Agent Builder 和 Copilot Studio 提供可视化、低代码体验,而 Foundry 是具备评估和可观测能力的代码优先平台。Szymon Bochniak 对 Agent Builder、Copilot Studio 和 Foundry 进行了比较",将其呈现为三个层级,当团队需要自定义逻辑、高级检索以及与开发者工作流的深度集成时可使用 Foundry。微软的安全智能体流程指南"建议团队梳理智能体已触及的构建、测试和发布环节,并沿用微服务的管理规范:划定清晰使用范围、制定管控策略、做好运行追踪与持续评估,目前这些能力均已成为 Foundry 的核心原生功能。另一篇从 DevOps 视角出发的 Build 2026 回顾文章将这些新增功能描述"为“Foundry 真正成为面向生产环境的智能体平台,不再只是用于制作演示原型的工具”。
有关 Foundry 的更多信息,请访问微软官网"。
查看英文原文:https://www.infoq.com/news/2026/06/microsoft-foundry-agents/"

在 AIGC 技术出现阶跃式突破、软件工程范式从 1.0 快速迈向 3.0 的背景下,传统的产品、运营、研发协作模式正在经历前所未有的效能考验。本文整理自快手磁力引擎风控技术负责人王东旭在 QCon 全球软件开发大会 2026 北京站的分享《打破“人月神话”,Agent 重塑风控场景产运研职能》。
王东旭在此次分享中系统梳理了过去半年里团队在大模型时代推动组织智能转型的最新实践。他从"AIGC 已将安全、效率、体验的不可能三角推向极限"这一现实困境出发,提出固态组织必须向"液态组织"转型:让产品经理用 Prompt to Product模式直接交付原型、让运营从配置规则表达式升级为模型教练、让研发以 CLI 模式逃离职业阶梯的中空化困局。演讲后半段,他坦诚复盘了 Vibe Coding 的工程落地之坑与组织变革中的冲突教训。
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
AI时代危机:被“协调税”压垮的传统产运研模式
我所在的团队负责整个快手商业内容安全审核和站内/联盟广告流量反作弊,今天的演讲,会专注于内容安全这一部分,在这个每天处理上亿条短视频的场景里,我们长期面临一个“安全、效率、体验”的不可能三角。随着 AIGC 技术爆发,这个三角的张力被拉到了极致。
支撑这个三角形的,是一个非常经典的从左到右依次为运营、产品、研发的固态组织。运营负责感知和发起需求,交给产品经理分析并产出 PRD,PRD 再由技术研发转化为系统、数据或模型,最后交还给运营做线上规则配置。运营本质上就是感知业务,然后完成规则表达式的配置。在运营和产品之间、产品和技术之间,各有一条隐形的虚线,那是清晰分工之上的“部门墙”。墙的存在让职责明确,但也让职能变得单一且割裂。
随着ChatGPT 横空出世,技术发展曲线出现了一个巨大的不连续断点。AIGC 能力带来内容量的井喷式爆发,系统压力指数级上涨,同时任何人都可以轻松通过 prompt 进行图生文、文生图乃至图生视频,攻击对抗变得空前强烈。
在这个技术跃迁面前,我们面临一个现实困境:就算继续增加团队规模,产出也很难呈现老板期望的四十五度角线性增长。《人月神话》中的经典悖论——“一位女性怀胎十个月生一个孩子,那么十个人一个月是不是就能把孩子生出来?”——在大模型爆发的背景下变得更为尖锐。一个更深层的问题是,在大模型时代,执行力本身已经商品化。写代码变成了一件相对简单的事,真正的困难在于跨部门之间的沟通摩擦和信息对齐。技术已经发展得很快,但人的组织方式还没有跟上。
这引出了 Karpathy 对软件工程的三个阶段的定义。他提出,我们正在经历从软件 1.0 到 3.0 的升级转变。1.0 是工业化分工阶段,核心资产是代码行数;2.0 是 Copilot 过渡阶段,团队关注的是模型权重;而 3.0 是 AI Native 原生阶段,核心资产变成了高密度 Context 上下文。当下效能陷阱的本质,就是技术发展的速度比组织和个人的迭代速度快了半拍:技术已经到达原生阶段,但组织依旧停留在过去的范式里。基于这一判断,我们团队发起了一场面向 AI 原生的组织转型。
职能重塑之路:风控产运研如何构建AI超级组织
我们团队有运营、产品、技术三大角色,技术侧又进一步细分为算法和研发,算法包括行为概率统计类算法和 CV 算法,研发则包含传统 Java 系统开发和数据研发,技术团队整体规模峰值近百人。在这次转型中,我们的核心出发点是:每个角色都要向价值链的上游去做升级和转型。
在传统的固态组织下,产品、运营、研发、算法之间像砖块一样边界清晰。产品只需要面向 PRD 交付产品设计原稿,研发接受 PRD 编写代码、交付系统和模型,算法则在自己的一亩三分地里不断迭代 BERT 和 ResNet。我们想要重塑的是一种“液态组织”,一个以数据为中心、职能边界变得非常模糊的协作网络。产品和运营的同学开始能够完成过去需要研发去承担的工作,研发也可以向算法侧延伸。原来那种成编制、成建制的师级单位,正在被类似于合成旅一样、麻雀虽小五脏俱全的小军团所取代。
从产品、研发和运营三个层面来看,我们都有了不同程度的实践。在产品层,我们通过 Agent 驱动做了产品原型设计的一些 Agent,让大模型直接出 UI 设计稿,还有需求撰写 Agent 帮助产品经理快速完成独立且确定性高的产品原型设计,甚至还会让 AI 去给产品经理写的 PRD 打分。在研发层,我们正在尝试所谓的 L3 研发模式,覆盖从需求理解到编码、测试、运维发布的完整流程。在运营层,我特别鼓励技术同学跳出“编码是否更快、交付是否更强”的单一视角,去思考如何让整个团队创造更大价值。而我们在运营这一层做的事情,已经让运营同学的角色发生了质的跃升。
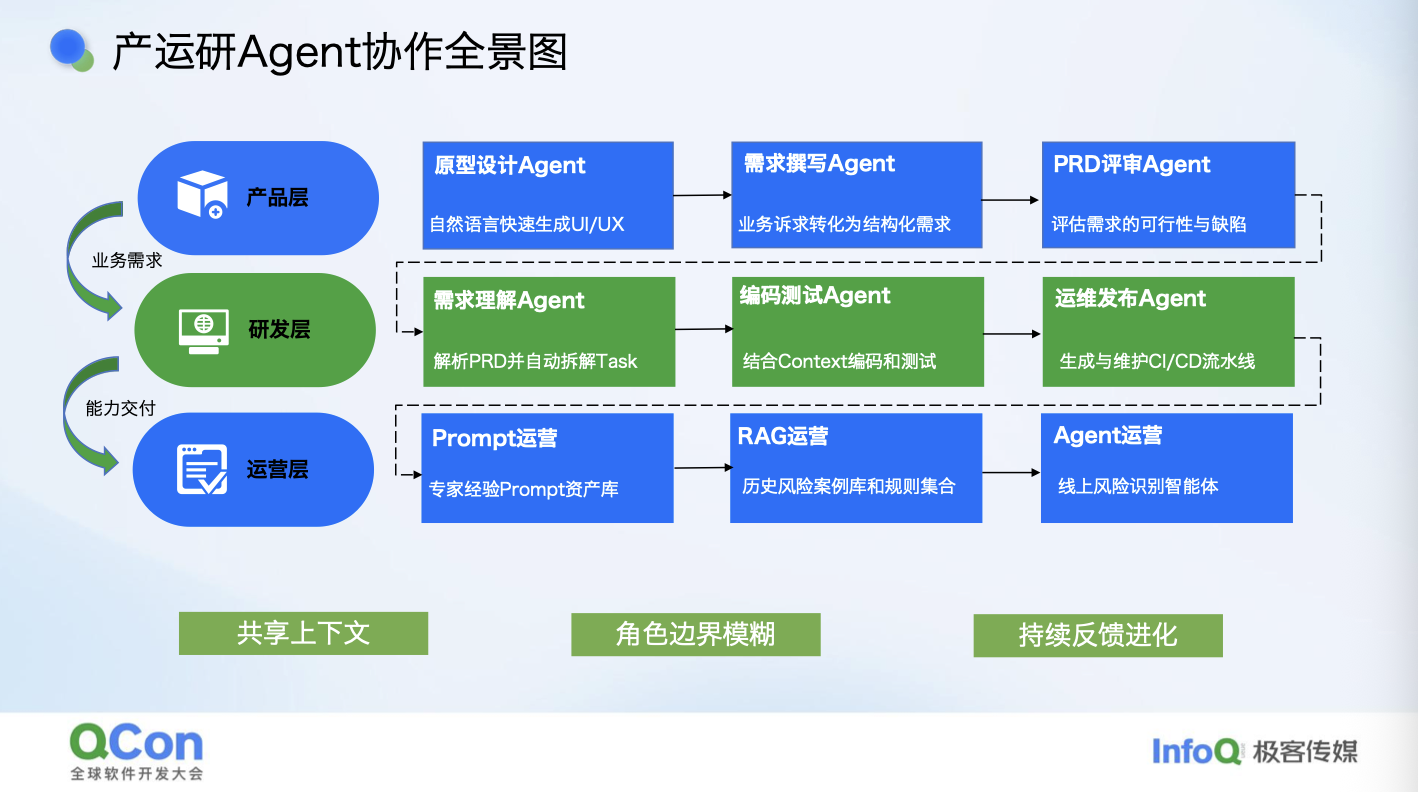
大约半年前,很多产品经理同学还相对焦虑,因为技术同学天生离大模型更近。但最近的晋升评审给了我一个很强烈的感受,这或许可以算作一个暴论——低代码平台正在消亡。过去产品经理做原型设计时,经常会借助低代码平台,通过配置化、组件化拖拽来完成设计稿。但今天,每一个产品经理都可以使用 Vibe Coding。低代码平台的好处是固化、可以快速出原型或 Demo,但在这个时代,它实际上是限制了优秀产品经理的想象力。可拖拽的组件就那么几个,如果你想表达天马行空的想法,根本没有出入口,只能“削足适履”。从与行业人士的交流来看,做低代码平台的团队也都在尝试与 AI 结合进行转型。
我们团队对于产品经理的工作提出了一种新模式,叫 P2P,即 Prompt to Product,通过编写 prompt 直接完成产品原型设计。去年下半年开始,我们大量实践了 Figma、Lovable、Bolt.new 等 Vibe Coding 产品。产品经理掌握了这些技能之后,某种意义上已经可以替代部分相对低水平研发同学的工作。以我们团队的一个技术门户需求为例,过去产品经理需要等研发排期,一个双周迭代只能做二十个需求,第二十一个就会溢出。而现在,产品经理可以直接在 Lovable 上通过面向浏览器的口令方式把需求做出来,不再需要等待研发。
从我们的视角来看,产品同学掌握这些技能后,正反两个方向的效果都很明显。正向是产品经理可以帮助研发同学挡掉一些简单需求,变成研发的“搭子”。但从另一个方向看,尤其是对于我们团队相对年轻的研发同学,被冲击的面非常大。当产品经理都能搞定这些工作的时候,要那么多研发做什么?这既是好处,也蕴含着切实的危机。但无论如何,通过 P2P 这种模式,产品经理的产能确实得到了显著提升。

我们团队的运营过去的工作模式是接收外部风险信号,然后在线上规则引擎里做配置。在大模型时代,这种工作的可替代性非常强,部分一线审核员实际上已经被大模型替换掉了,这些运营人力的简单职能被大模型取代后,还顺势完成了AI Native的职能升级转型。在我们场景里,它经历了三个层次的变化。
第一层是 Prompt Engineer。可能现在还有部分技术同学以能写出一个很强的 CoT 风格的 prompt 为荣,但从去年开始,在我们团队这件事应该是运营同学去做的。我们团队的运营写出的 prompt 非常厉害,不是一个简单的一句话指令,而是带有结构化思维链的。因为场景是多模态的,他们甚至能做图文交替、模态融合的 ICoT。之所以会有这样的转变,是因为我们判断运营对线上业务要比技术同学了解得更深,让运营直接与大模型对话,把领域知识经验交给大模型,才是更为彻底的做法。
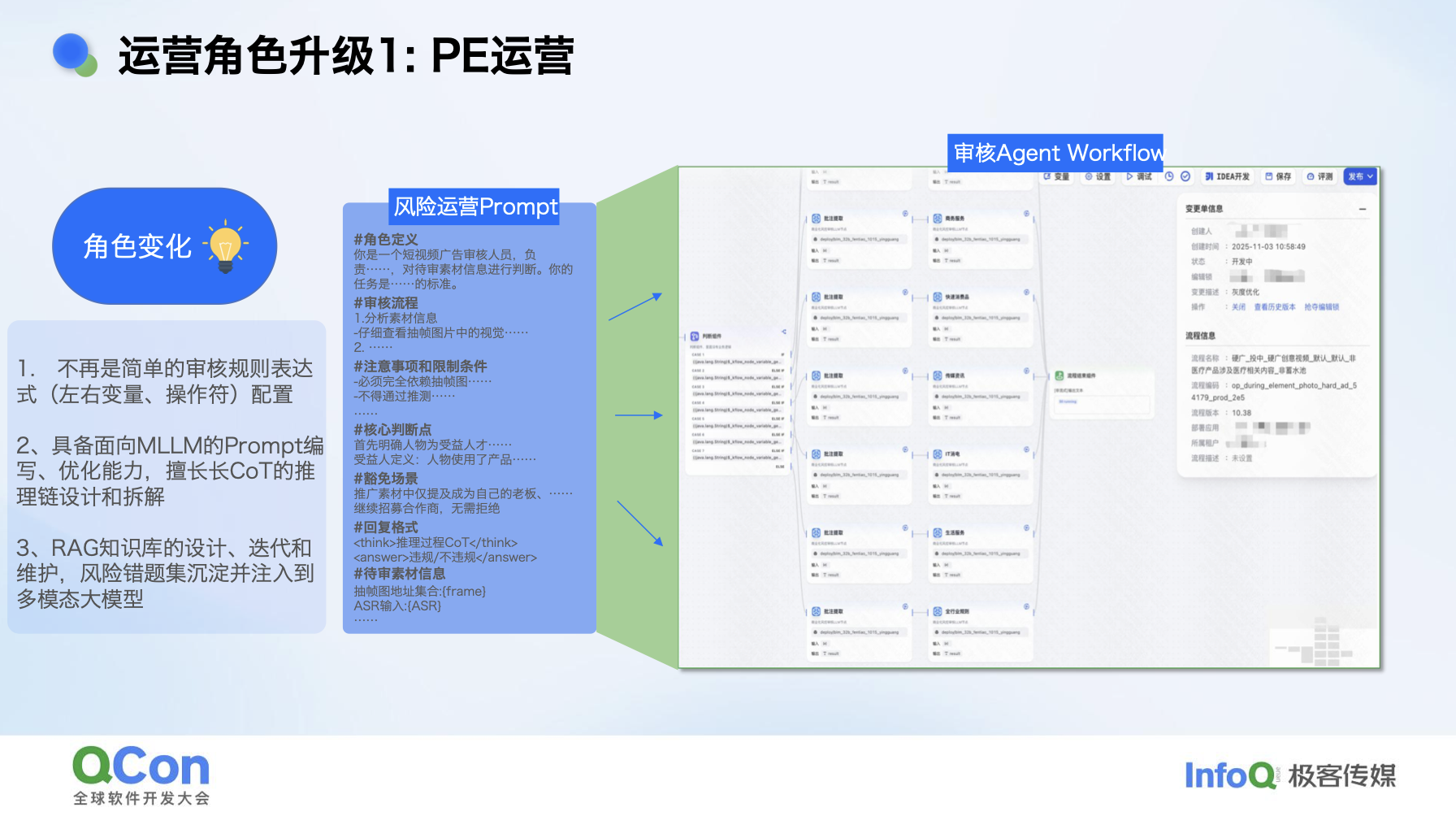
但仅有 Prompt Engineer 还不够。大模型在多多少少都会出现幻觉问题。于是我们场景的运营同学不但要会写 prompt,还要能把自己领域的知识,比如看健康行业或电商行业的经验,完整做到 RAG 知识库里,通过线上规则的结构化、向量化,大大降低模型的幻觉问题。这就是第二层,从 Prompt 运营到 RAG 运营。
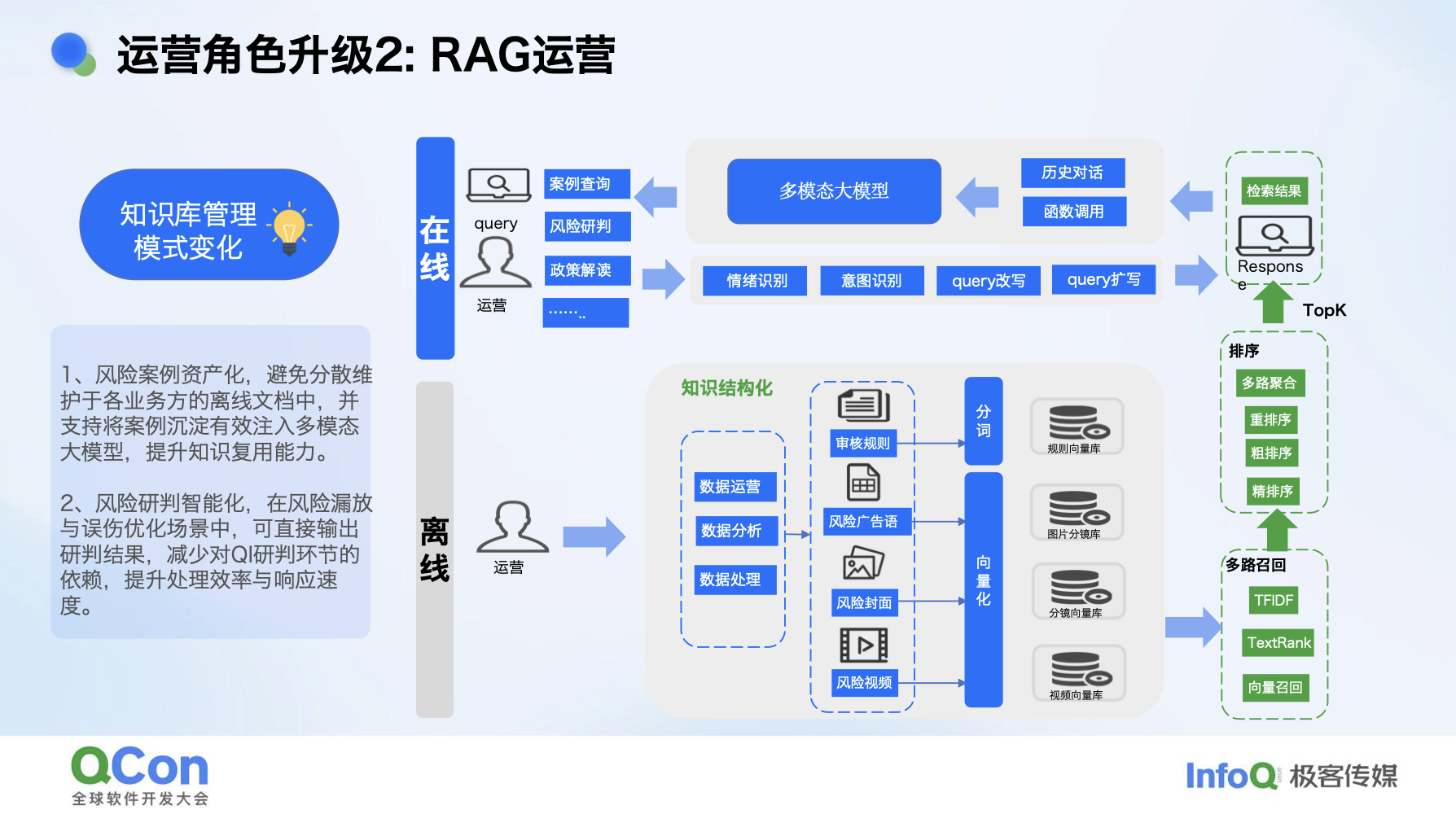
更进一步,我们在2025年Q2完全叫停了技术同学去做这些事情。第一,不要再写 prompt;第二,RAG 运营也不是研发该干的活;第三,更激进、更极致一点,我甚至不让算法同学再做有监督微调 SFT。在早期这个事有护城河,但随着技术发展,算法再去做已经是一种低水平的重复。于是我们在2025年 Q3 左右,把整个模型的有监督微调做成了一个线上化平台,已经有一部分能力较高的运营同学可以完成模型 pipeline 的运维,充当模型的教练。
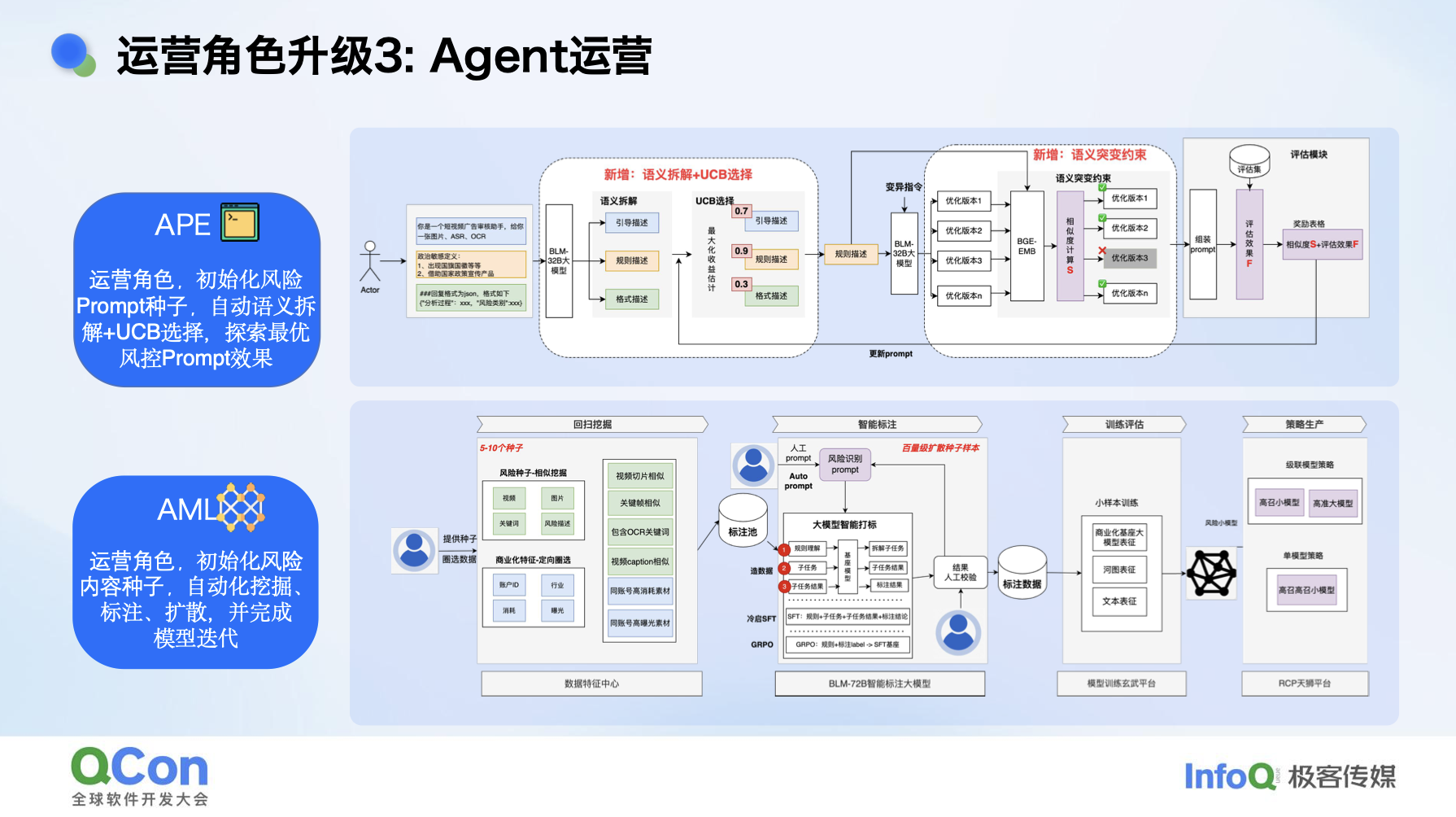
总结下来,运营的角色变化就是从传统的写规则表达式,到成为 Prompt Engineer,再到 RAG 运营,最后到模型教练。只要你把工具做得足够平民化、线上化、抽象得足够好,运营就能完成这些跃迁。通过这种方式,我们团队的运营同学完成了一个相对不错的面向 AI 原生的转型,我可以很确定地说,他们在市场上是非常值钱的。
大模型对研发同学的影响面可以用一条微笑曲线来描绘。曲线的横轴是职级,从 junior 到 Staff+,纵轴是影响程度。越是资深的同学且拥抱 AI,其能力会被无限放大,对应微笑曲线右侧的加持效应。但还有一部分同学,尤其是刚入场的校招生或小白,受到的冲击是负向的,是所谓的 Danger Zone。因为他们向上卷经验卷不过资深同学,向下和大模型比产出速度也比不过,于是就出现了“职业阶梯中空化”的尴尬局面。如果年轻人跟不上去,整个团队就会面临断层。
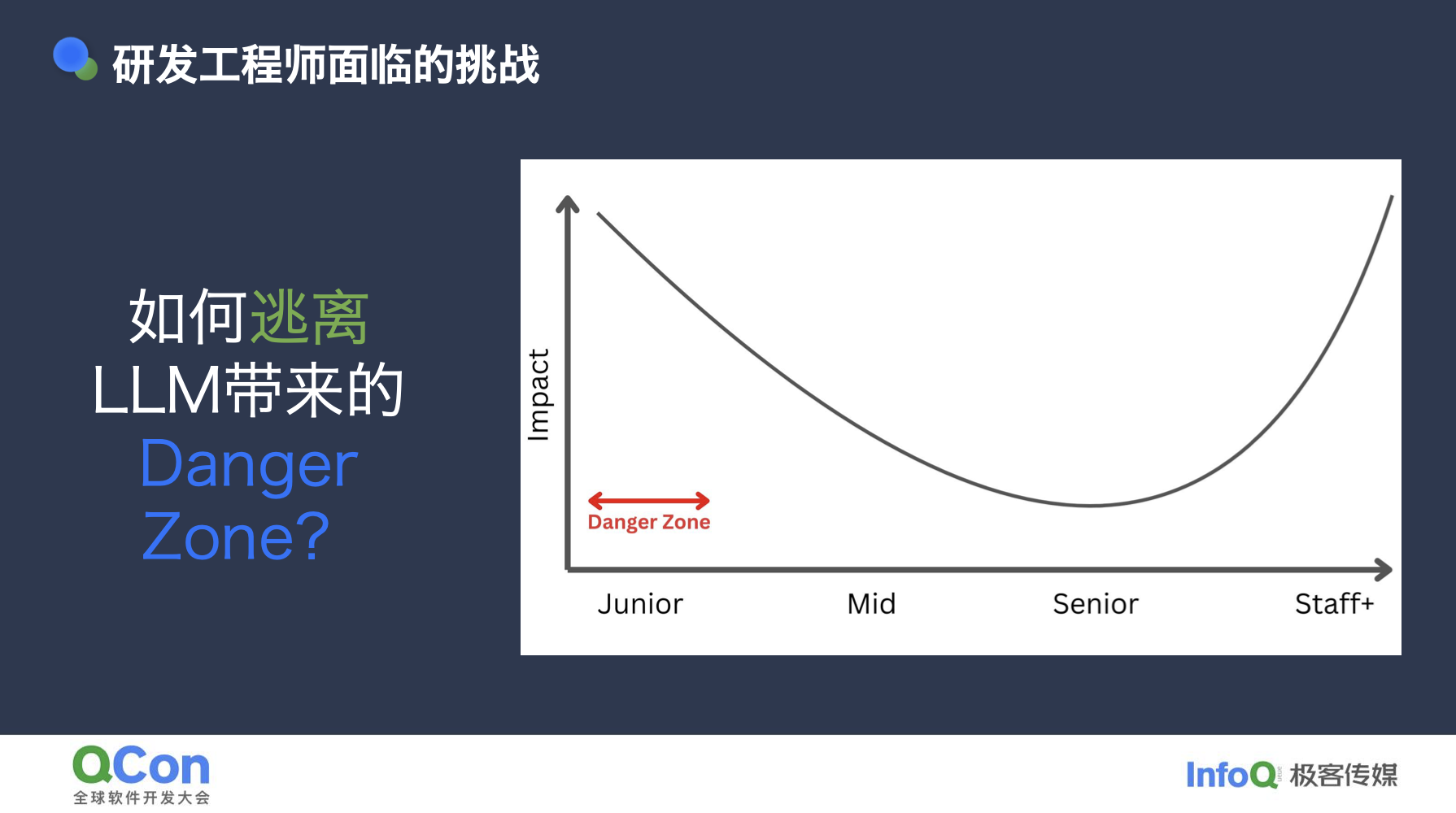
要逃离 Danger Zone,就必须用 Code Agent 把自己武装起来,让自己成为一个小军团。我们团队在2025年到2026年年初这段时间,经历了三个阶段的摸索。
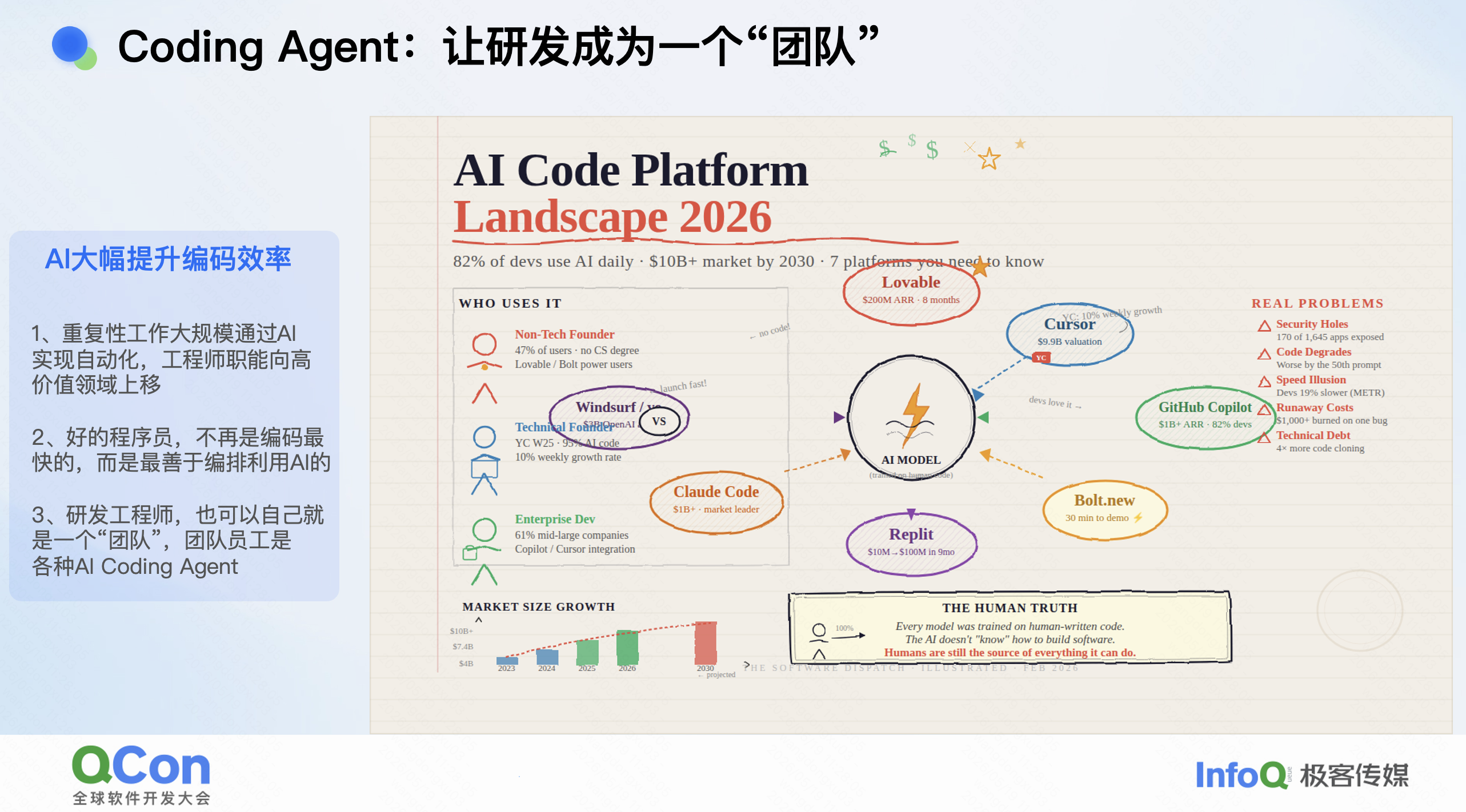
第一阶段是类似 Cursor 的 IDE 模式,偏向 Copilot 辅助编码。第二阶段,我们在2025年十一月左右推动研发同学用 Lovable 这样面向浏览器对话框的方式做 Vibe Coding。但现在回忆起来,这个阶段可能多多少少走了一点弯路,因为这种面向浏览器对话的方式并不太适用于技术同学,反而更适合产品、运营同学。第三阶段,我们感觉走对路了,就是 CLI 模式。国外技术论坛 Latent Space 上有一个观点叫“CLI is the future”。我自己最近一年写代码很多,日均Token消耗一亿但不再用 IDE,效率很高。这是三个阶段的真实心路历程。
在具体需求承接上,我们按照颗粒度分为小、中、大三种,采取的实践也不尽相同。小的需求,尤其是一些产品经理就能搞定的,用 Chat 对话的方式完全没问题,不必强行要求做 Spec-Driven Development。中等的需求,例如我们团队数据开发同学大量用 SQL 交互交付,我们就定义了大量 Skills,通过这些 Skills 就能把事情做得相当不错,这种场景根本用不到 Spec。只有相对大型的需求,我们才绕不开 Spec Coding。

这里需要提一个观察。现在 AI 圈流行造词,去年大家讲 Prompt Engineer,现在讲 Context Engineer、Harness Engineer。概念层出不穷,但核心并没有太大变化。Harness 这种东西,在我看来并没有那么神秘,无非就是 Token 消耗够不够多。我在团队里会设定一个坎,每天一亿 Token,这是一个相对 OK 的状态,部分头部研发同学消耗量还会更多,Token消耗得多,自然就会去考虑通过各种手段约束Coding Agent的输出,其实这就是一种Harness。
我团队还有四、五十位算法同学。在研发同学纷纷转型算法工程的大背景下,算法同学还能有什么护城河?我们的实践可以归纳为两个方向:向下深耕模型能力和向前构建数据飞轮。
向下深耕的第一块是预训练。我们并未做大模型全模态基座的端到端预训练,而是在 Visual Pre-training 视觉表征层,基于 SigLIP 搭建了自研的视觉对比学习方案。第二块是 mid-training,我们依托海量图文风控数据,在多模态大模型基座上开展领域增量续训,而非简单注入数据;该多模态架构参考 LLaVA / QwenVL 的多模态对齐思路,重点让模型掌握风险识别能力。第三块是后训练,核心聚焦偏好对齐环节,包含两种核心策略。第一种是 DPO 方式,依托风控场景的人工复核结果,形成 “判定偏好对”,这类天然的偏好样本对,非常适合用于强化学习对齐。第二种是 GRPO 方式,我们团队在该方向的相关研究成果,已被 AAAI 2026 接收录用。今年,我团队还将继续在 CVPR、ECCV 等顶会发力,争取实现更多技术突破。这里我想表达的是,大模型时代,即便是聚焦业务落地的团队,也能深耕技术深度,在学术领域取得亮眼成绩。

讲到模型能力,就不得不提我们今年重点落地的数据飞轮体系。行业内极具参考价值的标杆便是 Scale AI,此前已被Meta收购。其创始人 Alexandr Wang 凭借成熟的数据闭环建设思路,搭建起完整高效的数据生产、筛选、迭代闭环,这也是当下大模型能力持续迭代的核心动力。
结合业务实际来看,2026 年我们在多模态大模型上的核心发力方向,除了优化模型架构、迭代训练策略之外,更核心的重心将全面转向搭建适配内容安全风控场景的专属数据飞轮,以高质量数据驱动模型能力长效进化,这套思路对于团队技术建设与长期业务提效,都具备极强的指导意义。

除此之外,去年全年的团队绩效考核,以及近期的团队薪酬调整,我均严格遵循既定原则推进。本次调整重点将各岗位 AI 能力转型、数字化提效成效纳入核心考核维度,具体标准请看图示。

坑点和教训:转型过程,那些苦涩的记忆
过去半年多的实践里,我们踩过三个重要的大坑。
第一个是 Vibe Coding 工程落地坑。简单说就是“Demo 惊艳全场,生产一塌糊涂”。做 Vibe Coding 的时候,基本是想到哪儿说到哪儿,他写到哪儿。随着项目时间推移,上下文会腐化,本质原因是模型的注意力窗口比较小,这里面就出现了确定性的业务结果要求与LLM的概率性输出之间的矛盾。
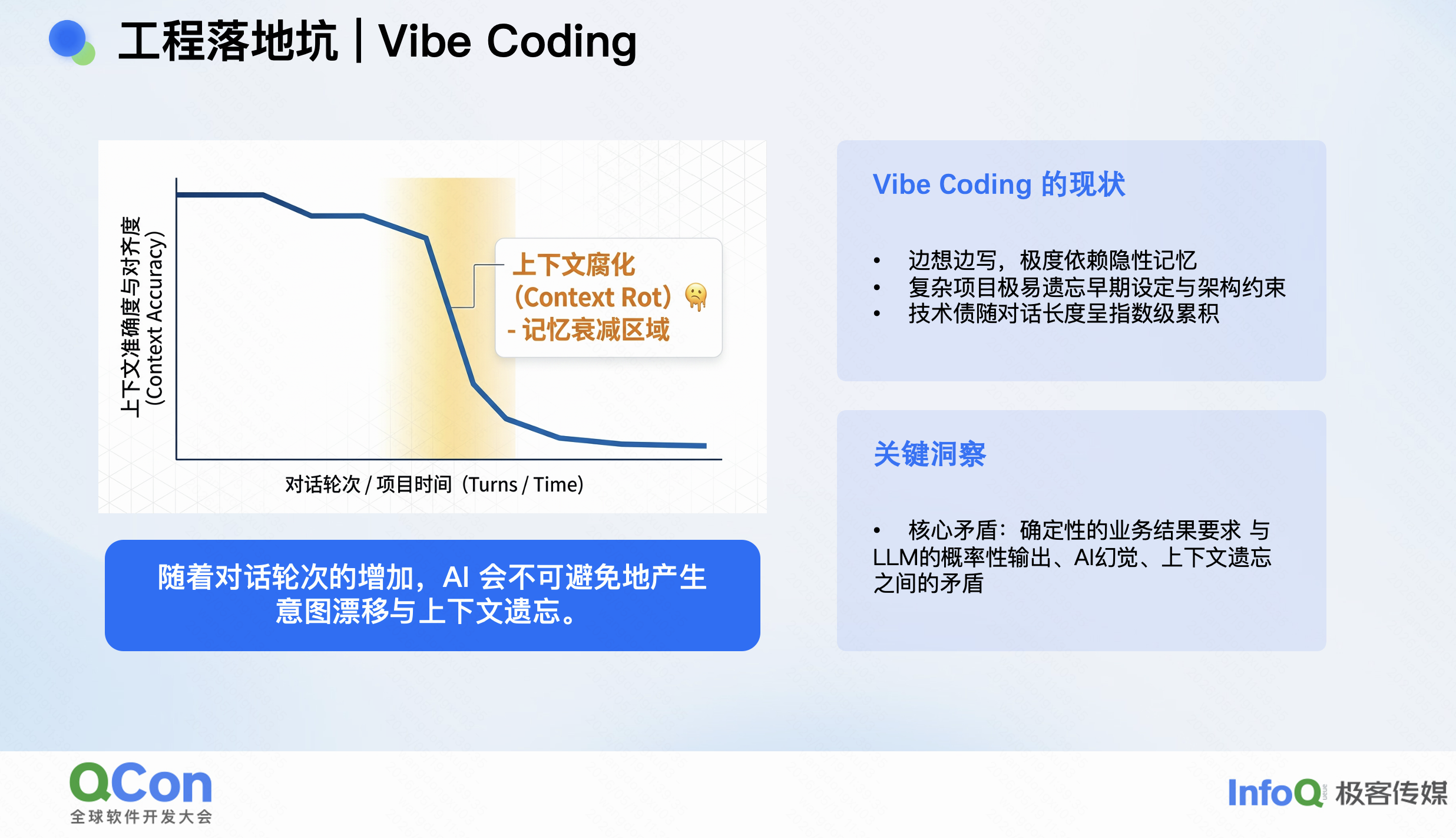
怎么解?我们现在的实践更多是采用 Spec-Driven Development 模式,从提议到设计到 Spec 规约,再到 Coding,最后到测试,环环扣死。我们最近整理了一份 SDD 技术选型,例如 YC CEO 推的gstack在全局上下文方面表现不错,Superpowers 已经150 K 的 star,相对普及度很高;Open Spec 则适合做增量项目的隔离。
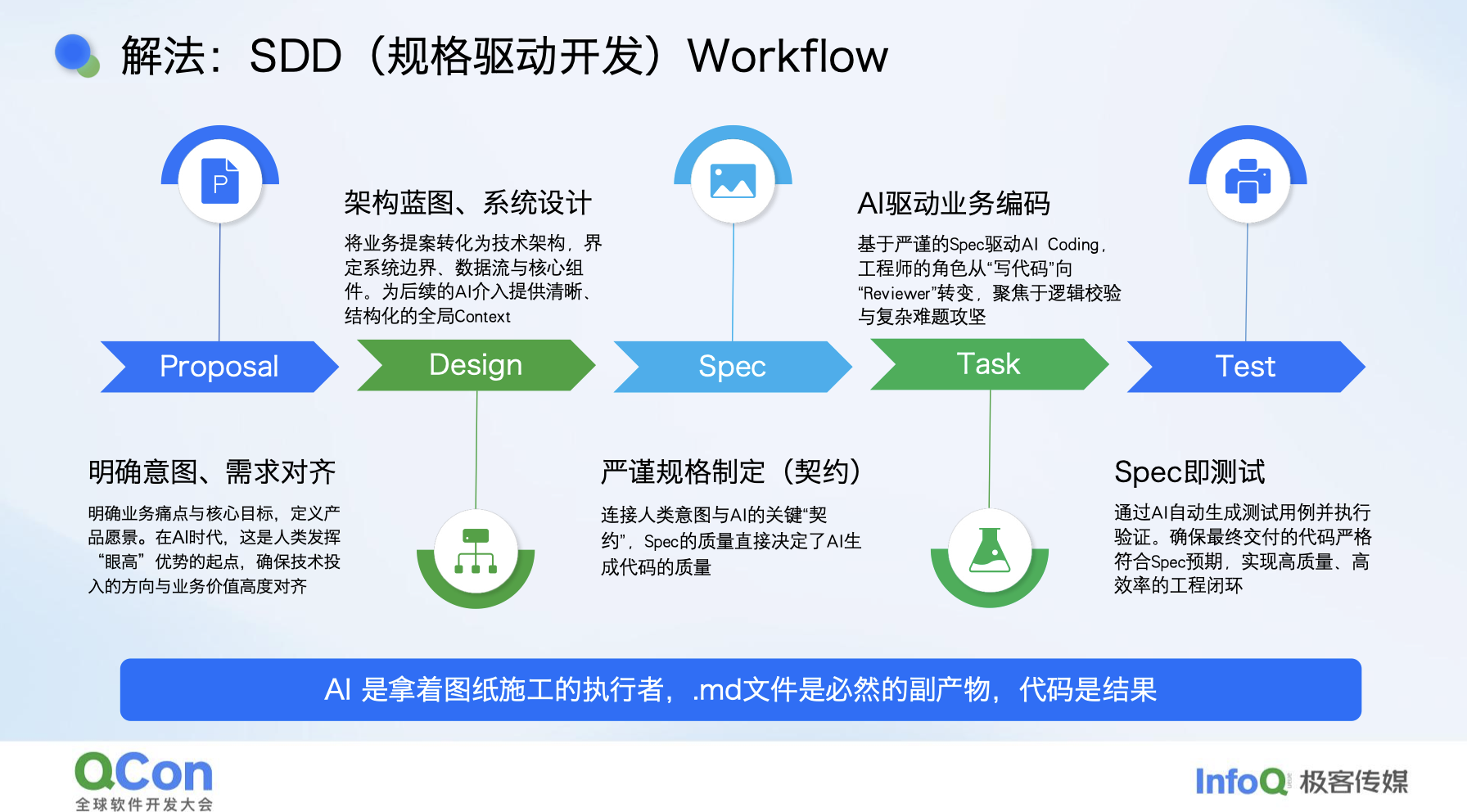
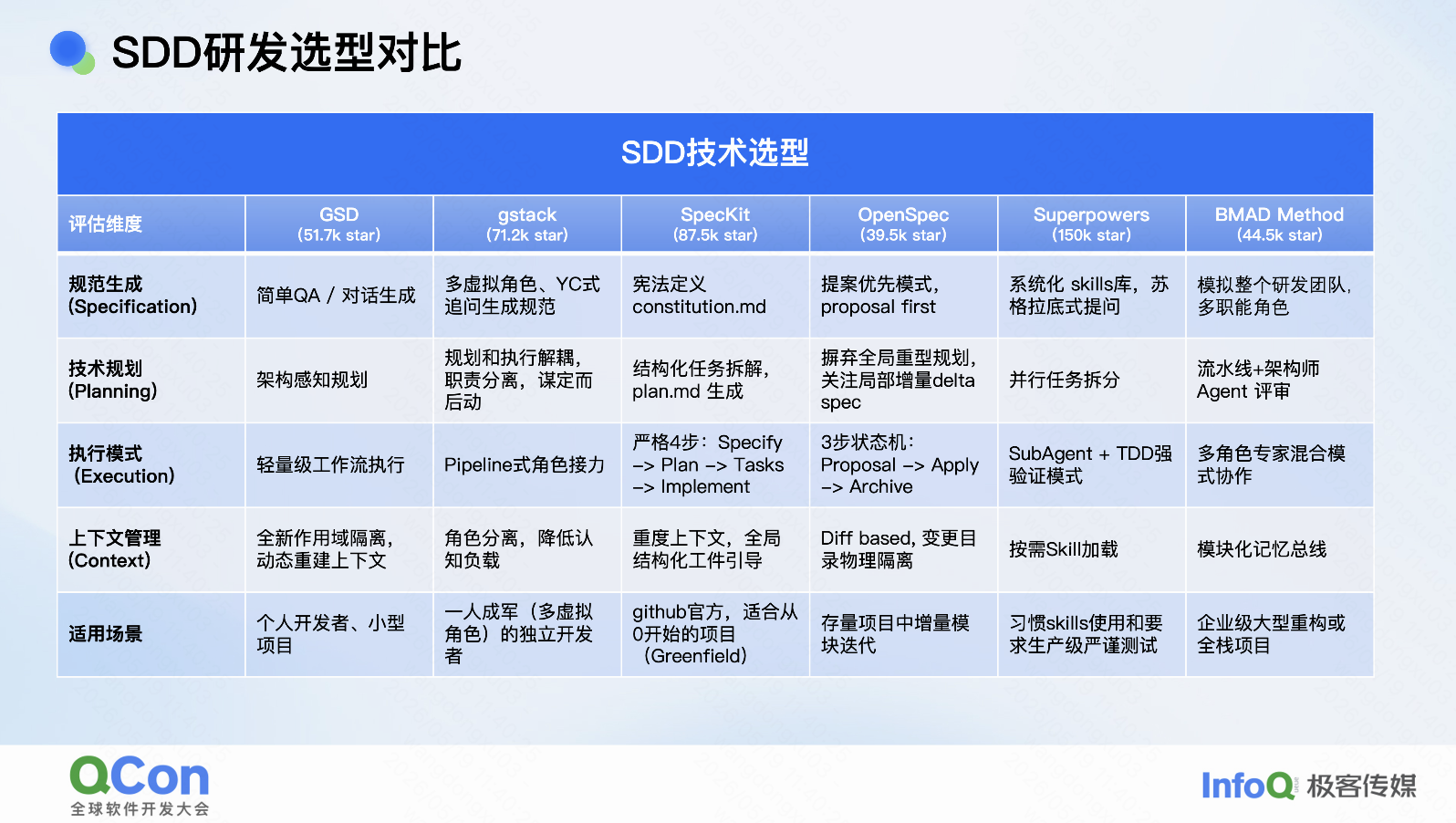
第二个坑是增量和存量项目的差异。增量项目本身就没有历史包袱,是 AI Native 的,很 work,但存量项目极易失效。坦白说这件事我们还没有做得特别彻底,但也在充分探索。我经常看 Anthropic 和 OpenAI 官网的博客,美国的程序员同样在探索存量项目如何演变。我有两个观点。第一,未来的 Git 仓库会有很大变化,它应该是面向 AI 的,而不是面向人的,结构上大概率会包含非常非常多的 Markdown。有人调侃扎克伯格收购 Manus 就是收购了几百万个 Markdown,但在 AI 时代 Markdown 很值钱。第二,构建软件仍然需要纪律,但这个纪律不在于代码,而在于以后 Markdown 的结构。我们的尝试可以概括为三点:一是“反向重构 Context”,因为存量代码没有这些东西,需要反向补上;二是补充大量的语义知识,因为 AI 缺上下文语义;三是建立严格的质量测试与质量门禁,生码能力太强,但没有人约束它。
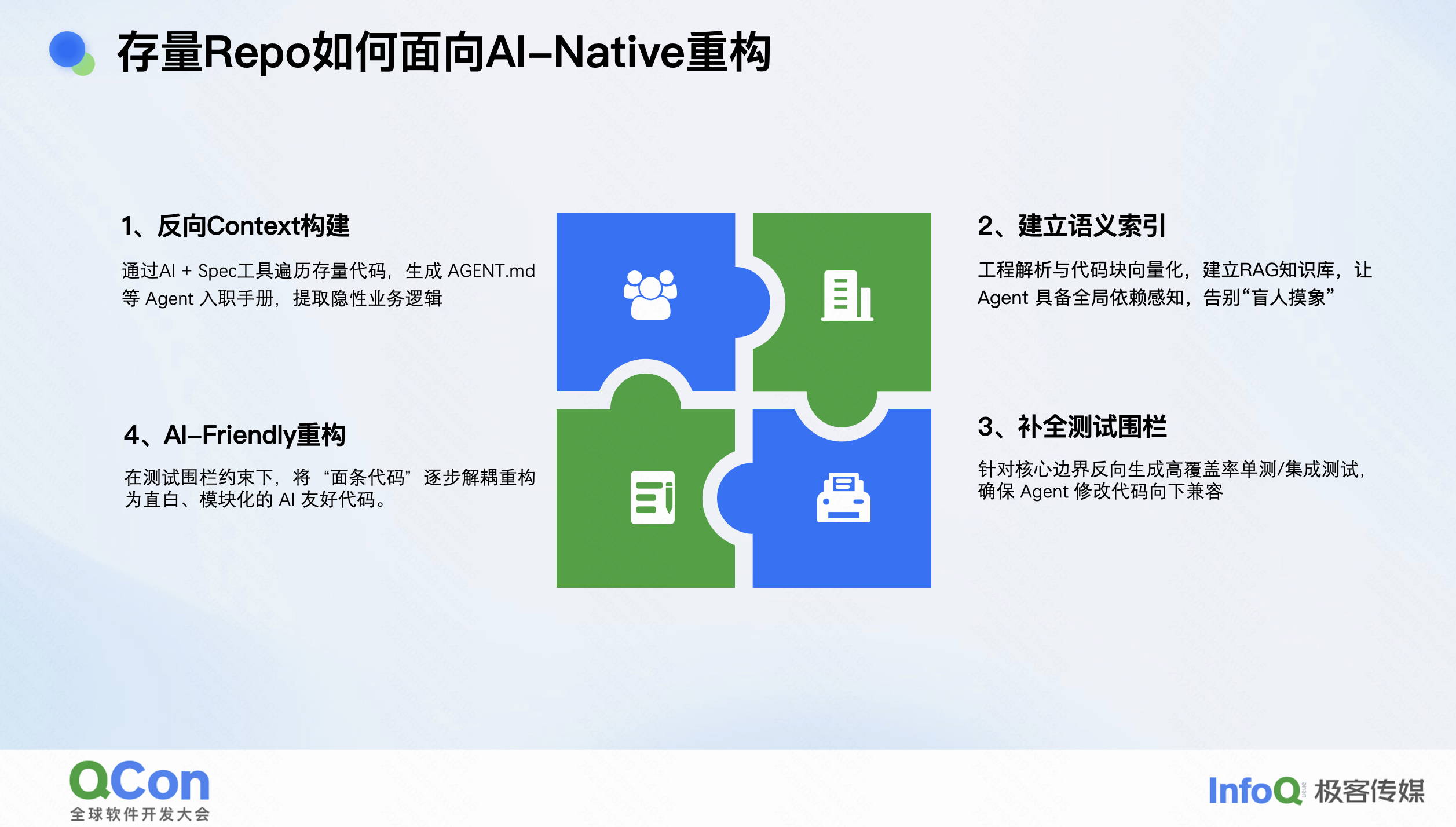
第三个坑是团队管理坑。去年 AICon 结束后,我回到团队大量推组织升级,但我的问题是追求面面俱到,认为自己能做到的团队所有人都能做到,忽略了大家时间分配、能力水平和意愿度的差异。结果十二月到年初那段时间冲突和矛盾非常多。最近一个季度的反思,我总结了三个字:试、推、升。“试”是不要再追求面面俱到,现在还不到时候。如果你的老板要求你面面俱到,你不妨把这个结论反馈给他,因为有的团队过去半年已经踩过大坑。“推”是在有了局部试点成功之后,再做小范围推广,让一小部分人先富起来、先信起来。作为管理者,还可以把架构做一些局部调整,让汇报线层次不要那么深,因为我是二级主管。“升”则是全面重塑,我们现在正在从“推”到“升”的第三阶段迈进。希望这个三步演进能让更多人少踩点儿坑。
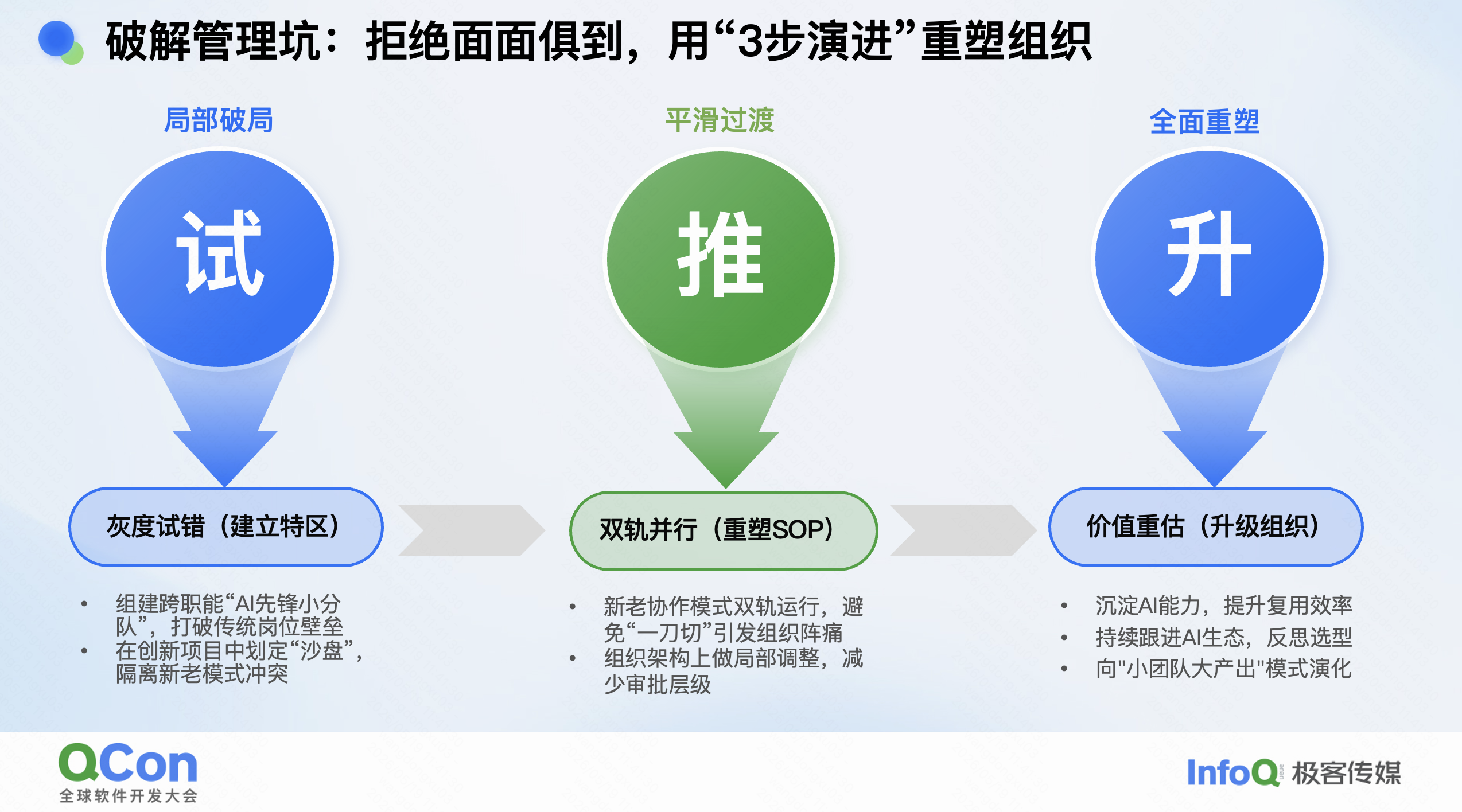
组织行动建议:下一步,该怎么走?
面向未来,我给出三点具体的组织行动建议。
第一点是推行 Token 经济学与 Skills 贡献度考核。以后我会看两个指标。一个是 Token ROI,分母是 Token 消耗量,我一定会看;但消耗多不代表产出多,分子还要看你通过每天消耗一亿、三亿 Token,对团队的产出和贡献到底是什么。另一个指标是 Skills 贡献度,个人能力强不代表组织能力强。我们团队有一个 Skills Hub,上面有排行榜,排行榜前面的同学不是被卷的,而是被激励的。只有把个人能力注入到团队的 Skills 体系中,组织效能才能最大化。
第二点是“逆康威定律”的应用。康威定律告诉我们,组织架构决定系统架构。前面讲到的运产研边界墙就是一个典型表现。当大家的职能边界被打开、组织变得更加液态的时候,系统的形态也会随之改变。这是我对于组织面的一个畅想。
第三点是我个人一直践行的一句话,叫:做“眼高手低”的技术人。“眼高”在于洞察,一定要对前沿技术知识保持想法,真的有热爱在里头。“手低”就是手还是要低下去。我看在座很多同学都很资深,我虽然年纪不算大,但也在行业里做了十多年,我一直告诉自己手不能离开一线,每天Token 消耗过一个亿是常态。有段时间我跟团队同学讲,如果你想在AI Coding这个事上 diss 我,先让 Token 消耗超过我再说。
今天 QCon 大会的主题叫“大模型,正在重新定义软件”。而我们也在重新定义我们自己。唯一的护城河,是你和你的组织进化的速度。
作者介绍
王东旭,快手磁力引擎风控技术负责人。先后在百度、第四范式、阿里巴巴任职,专注于在商业化广告风控领域的安全风险对抗,著有《广告与营销风控:方法与实践》,主导了快手商业化广告的KwaiBLM大模型审核和AhaEdit AI生成式修复规模化落地,对AI时代组织的人机协同关系有深刻实践和思考,曾在AICon 2025北京站做AI时代的10x个体和组织主题分享。
会议推荐
6月26-27日,AICon上海站"即将开幕!60 + 顶尖专家携一线实战案例齐聚,聚焦构建可信赖、可规模化、可商业化的 Agentic 工程实践,一站式打通 AI 工程化卡点、从源头避坑!欢迎报名咨询👇
2026年,电信运营商面对AI的焦虑,已经不再只是“有没有大模型”“智算中心建得够不够”“AI能不能降本增效”等技术问题,而是更深层的经营问题:当AI重塑应用入口、业务流程、客户交互和价值分配方式时,运营商能否继续掌握客户关系、计费能力、云网资源、安全能力和产业协同地位。
近期,运营商围绕AI的动作明显加快。中国移动发布Token运营生态体系,提出Token套餐、统一Token量纲、打通Token鉴权,探索连接Token供给与消费的统一运营平台;三大运营商也围绕Token、云电脑、智能体工具和安全服务推出组合产品。与此同时,中国移动等产业资本参与月之暗面 Kimi 新一轮融资,说明运营商正在通过资本和产业协同进一步接近大模型生态。
这些现象说明,运营商的AI焦虑,本质上不是“是否跟上AI热点”,而是“能否在AI产业链中避免再次底层化”。移动互联网时代,运营商提供网络和流量,但大量应用层价值被互联网平台获取。AI时代,如果运营商仍然只提供机房、带宽、云主机和GPU资源,而模型厂商掌握智能能力,云厂商掌握平台生态,智能体厂商掌握任务入口,终端厂商掌握交互界面,那么运营商仍可能面临“重资产投入、低价值回报”的困境。
因此,运营商应对AI焦虑,不能只靠建设几个大模型、采购几套AI平台、上线几个智能客服,而要把AI纳入主营业务重构。未来的核心命题,是把连接、算力、数据、模型、智能体、安全、渠道和计费能力重新组合,形成面向个人、家庭、中小企业和政企客户的新型智能服务体系。
一、Token套餐:从卖流量走向智能额度经营
Token套餐的出现,是运营商AI商业化的重要起点。它并不意味着运营商已经完成从“卖流量”到“卖算力”的彻底转型,更准确地说,是AI调用额度开始被运营商商品化、套餐化和账单化。
过去,运营商主要经营分钟数、短信、流量、宽带、专线、云资源和安全产品。AI时代,Token、模型调用、推理任务、知识库容量、智能体执行次数、AI云桌面和安全审计,正在成为新的计量对象。Token套餐的价值,不只是多了一个销售品类,而是让运营商熟悉的实名账号、账单支付、客户分层、渠道触达、客服体系和套餐运营经验重新发挥作用。
个人用户可以购买AI助手额度,中小企业可以购买AI办公包,开发者可以购买模型调用服务,政企客户可以购买模型网关、知识库、推理服务和安全审计能力。传统流量经营关注“用户用了多少GB”,AI服务经营则关注“用户完成了多少智能任务、消耗了多少模型调用、触发了多少推理服务”。这意味着运营商的经营对象正在从单一连接资源,扩展到智能服务过程。
但Token套餐仍处在探索期。用户是否愿意持续付费,套餐能否与宽带、云电脑、云盘、安全、终端和办公场景形成组合价值,运营商能否控制模型调用成本和服务体验,仍需要市场验证。因此,Token套餐不是终点,而是运营商进入AI服务经营的入口。
二、模型生态:从采购大模型走向参与模型产业链
中国移动参与Kimi融资,说明运营商正在从单纯采购模型、使用模型,向参与模型生态协同迈进。这件事的意义不在于运营商要亲自成为大模型公司,也不意味着运营商已经掌握大模型核心能力,而在于运营商开始意识到:AI时代不能只站在模型产业链的下游。
单纯采购模型,运营商只是使用者;单纯建设算力,运营商容易陷入重资产竞争;只做政企项目,运营商又可能回到定制化交付和低复制率的老路。更合理的路径,是建立多模型接入、统一调度、统一计费、统一评测、统一安全和统一交付能力。
模型厂商提供基础智能,运营商提供云网资源、账号体系、账单能力、渠道体系、安全合规、属地交付和行业客户关系。双方结合,才可能把AI能力变成可销售、可运营、可审计、可复制的业务产品。未来领先的运营商,不一定是模型参数最大的企业,而可能是最擅长把多家模型能力整合成行业服务的企业。
三、智能体生态:从运营商APP走向智能体调用
AI从问答走向智能体,是运营商必须重视的趋势。大模型问答改变的是信息获取方式,智能体则进一步改变任务执行方式。它可以调用工具、操作软件、连接文件、访问系统,并在一定权限范围内完成连续任务。
“从运营商APP走向智能体调用”不应理解为APP立即消失,而应理解为入口结构发生变化:运营商APP仍然承担实名、账单、套餐、权益、客服、合约、积分和家庭业务等强账户功能,但未来一部分客户需求可能先由智能体提出,再调用运营商后台能力完成。
运营商切入智能体生态应分两步。第一步,是成为智能体运行环境的提供者,把云电脑、Token套餐、宽带、5G-A、安全能力打包成基础服务。第二步,是建设面向智能体的业务能力接口,把套餐查询、账单解释、故障报修、宽带测速、专线开通、云资源订购、Token充值、安全告警等能力封装成可授权、可校验、可审计、可回滚的工具接口。未来入口竞争的关键,不只是用户是否打开运营商APP,而是运营商能力能否出现在用户的智能体工作流中。
四、个人市场:从流量权益走向AI权益
个人市场长期面临流量增长放缓、套餐同质化和价格竞争压力。AI带来的机会,不是简单赠送一个聊天机器人,而是为套餐权益增加新的差异化内容。
过去,个人套餐权益主要包括流量、语音、宽带、视频会员、云盘和家庭组网。未来,AI权益可能逐步进入套餐结构:学生用户需要学习助手、编程助手、口语陪练;职场用户需要文档总结、PPT生成、会议纪要、邮件助手;家庭用户需要AI云盘检索、相册整理、家庭知识库和智能家居控制;老年用户需要反诈提醒、语音助手和生活服务导航。
但这仍然需要市场验证。用户是否愿意为AI权益持续付费,取决于服务是否高频、稳定、易用,并且能否和通信账户、家庭宽带、云盘、终端、支付和客服体系打通。运营商应避免把AI权益做成短期营销赠品,而应进行分层设计:基础权益用于增强套餐吸引力,高阶权益用于提升ARPU,家庭权益用于绑定宽带和云盘,安全权益用于形成差异化。
五、中小企业市场:从企业宽带客户走向AI办公客户
中小企业是运营商AI商业化中较现实的增量市场。大型企业有IT团队和预算,可以直接采购云厂商、模型厂商和咨询公司的服务;中小企业则更需要低门槛、标准化、可开票、可售后的一站式AI服务。
运营商已有企业宽带、云电脑、企业邮箱、视频会议、语音专线、云主机和网络安全等产品基础。如果在此基础上叠加AI客服、AI营销、AI文档、AI合同、AI财务问答、AI知识库、AI短视频生成和AI编程助手,就有机会把传统连接客户逐步升级为AI办公客户。
这类业务的关键是轻交付和标准化。中小企业不愿意研究模型API、向量数据库、私有化部署和复杂安全策略,它们需要的是“开通即用、按月付费、出了问题有人管”的服务。运营商可以发挥客户经理、营业厅、线上渠道、政企服务团队和属地售后优势,把AI办公能力做成可复制产品,而不是重新陷入定制化项目。
六、政企市场:从项目交付转向智能体运营
政企市场是运营商AI转型的重要阵地,但不能简单认为项目制会立刻消失。现实中,政企数字化仍以平台建设、系统集成、定制开发和项目交付为主。AI带来的变化,是推动运营商从“交付系统”逐步走向“运营智能服务”。
政务、园区、制造、交通、应急、教育、医疗等领域,都有智能体应用空间。例如政策问答、热线工单、基层材料、城市治理、招商服务、能耗管理、设备维护、质检分析和供应链协同。但这些应用能否真正落地,不取决于演示效果,而取决于是否接入真实业务流程,是否具备知识更新、权限控制、日志审计、人工复核、效果评估和安全兜底能力。
运营商在政企市场的优势是云网资源、安全合规、属地交付和客户关系;短板是行业知识深度、产品化能力和模型生态丰富度。因此,运营商不能只做传统总集成,也不能只卖大模型平台,而应向“行业智能服务运营商”演进,持续运营知识库、模型调用、工具接口、安全审计和服务效果。
七、AI安全:从合规成本走向可信卖点
智能体越强,安全风险越高。它一旦能够访问文件、账号、浏览器、企业系统和本地数据,就可能带来越权操作、敏感信息泄露、恶意指令注入、供应链投毒和高危行为失控等风险。中国电信发布天翼智安·智能体安全解决方案,面向已部署或计划部署OpenClaw类智能体的用户,强调全流程管控、实时防御和行为溯源能力。
这对运营商是重要机会。相比互联网AI公司更强调模型能力和应用体验,运营商更适合突出可信、合规、稳定、可审计、可长期服务。未来,模型调用审计、敏感数据脱敏、智能体权限控制、提示词攻击检测、模型网关、数据不出域部署、可信身份认证和异常行为监控,都可能成为运营商AI安全产品的重要组成部分。
对于政府、金融、能源、教育、医疗等客户,安全可信往往比模型炫技更重要。AI安全不是运营商的附属能力,而可能成为运营商参与AI产业竞争的核心卖点。谁能提供更可靠的身份认证、更细粒度的权限控制、更完整的日志审计和更稳健的应急处置,谁就更容易在政企AI市场中建立差异化。
结语:把AI焦虑转化为增长机会
电信运营商的AI焦虑,并不是因为AI太强,而是因为AI正在改变运营商熟悉的商业规则。Token套餐说明AI调用额度开始进入运营商计费体系;大模型融资中的运营商身影说明运营商正在接近模型生态;OpenClaw类智能体热潮说明AI应用正在从问答走向任务执行;智能体安全产品的出现,则说明可信治理正在成为新需求。
但这些现象不能被简单放大。Token套餐不等于运营商已经完成算力经营转型;云电脑内置智能体不等于运营商APP入口已经被替代;参与大模型融资不等于运营商掌握模型生态;政企智能体试点也不等于传统项目制马上结束。
更稳妥的判断是:运营商正处在从连接经营走向智能服务经营的早期阶段。未来领先的运营商,不一定是模型参数最大的企业,也不一定是智算中心建得最多的企业,而是最早把AI能力转化为可计费、可交付、可运营、可审计、可复制服务的企业。
运营商真正要回答的,不是“有没有大模型”,而是有没有AI产品体系、Token计费体系、智能体承载与接口体系、可信推理平台、行业知识库和生态协同机制。谁能把连接、算力、数据、模型、智能体、安全和行业场景整合起来,谁就能把AI焦虑转化为下一轮增长机会。
随着数字经济纵深发展与生成式人工智能技术的普惠化落地,市场主体形态与产业创新创业范式被逐步重塑。AI-OPC(人工智能一人公司)作为依托大模型、AI智能体、低代码工具实现全链路自主运营的新型单人市场主体,突破了传统企业的组织边界与成本约束,成为新质生产力微观落地的核心载体。截至2025年底,国内AI-OPC主体数量已突破386万户,呈现指数级爆发增长态势,标志着“单人+AI”的轻量化创业时代全面到来。不同于传统小微企业,AI-OPC的核心生产资料由人力、场地、设备转向算力、模型、数据与网络资源,其生存发展高度依赖智能化数字基础设施。这一产业变革彻底重构了电信行业的价值场景,加速推动运营商从传统通信管道服务商,向人工智能时代的产业基础设施服务商转型。
“AI-OPC”兴起,重塑数字产业底层格局
AI-OPC的规模化崛起,并非简单的市场主体数量增长,而是数字经济生产要素、生产关系与产业分工体系的系统性重构,具备深刻的产业变革内涵。从生产要素维度来看,传统创业模式依赖资本、人力、实体资源,存在准入门槛高、运营成本高、扩张难度大的痛点;而AI-OPC以人工智能为核心生产力,通过大模型赋能研发、以智能体替代重复性运营工作、以低代码工具降低技术门槛,实现了生产力的轻量化、普惠化释放,彻底打破了创新创业的资源壁垒。
从生产关系维度分析,AI-OPC重构了产业组织形态,实现了“去组织化、轻量化、柔性化”的新型生产模式。传统企业依赖完整的组织架构、岗位配置与流程体系,而AI-OPC依托AI工具完成全业务闭环,以最小的组织单元实现市场化经营,极大提升了数字经济的创新效率与资源利用率。这种新型市场主体的爆发式增长,意味着数字创新不再局限于大型科技企业与规模化机构,个体创新力量被全面激活,形成了“全民AI创新”的全新产业格局。
从产业需求维度研判,AI-OPC的轻量化运营模式伴随天然的资源短板。单人主体普遍存在算力储备不足、模型适配能力薄弱、数据治理体系缺失、合规风控能力缺位等问题,无法自主承载AI全链路生产需求。这种“强创新需求、弱基础设施”的供需错配,形成了全新的产业缺口,也为电信运营商的服务迭代与生态扩容提供了核心赛道。可以说,AI-OPC的产业特性,决定了其发展必须依托专业化、普惠化、全栈式的公共数字基础设施,而这正是电信行业的核心能力禀赋。
运营商该如何构建“AI-OPC+电信服务”生态体系
运营商构建AI-OPC服务生态,并非单一的业务拓展,而是基于产业共生理论、价值网络理论的战略升级。
一方面,电信基础设施是AI-OPC规模化发展的核心底座与必要前提。AI-OPC的核心生产行为均依托网络传输、算力调度、模型运算、数据交互完成,对网络的低时延、高可靠、广覆盖,算力的弹性化、普惠化、可调度性,数据服务的合规性、安全性、高质量性存在刚性需求。经过多年布局,国内运营商已建成全域覆盖的5G-A网络、全国一体化算力网络、云网融合基础设施与成熟的网络安全体系,形成了其他市场主体无法替代的全栈基础设施能力。运营商通过算力托管、模型微调、数据治理、合规审计、边缘计算等普惠服务,能够系统性弥补AI-OPC的能力短板,大幅降低个体AI创业的技术门槛、资金成本与合规风险,为AI-OPC的可持续发展筑牢底层支撑。
另一方面,AI-OPC的规模化集聚为电信行业转型提供了核心场景与增量价值。长期以来,国内电信行业进入流量存量竞争阶段,传统语音、宽带、流量业务增长空间持续收窄,行业亟需突破传统经营模式,构建新型增长曲线。AI-OPC海量、分散、轻量化、高频次的服务需求,推动电信服务从传统的“管道收费、流量计费”模式,向“算力计费、Token计费、能力订阅”的新型商业模式迭代。同时,千万级AI-OPC的多元化应用场景,能够持续反哺算力网络优化、大模型能力迭代、数据服务升级,推动运营商从基础通信服务商,升级为算力服务商、AI生态运营商、数字产业服务商,实现行业价值的根本性重塑。
更深层次来看,二者的融合是新质生产力落地的重要实践。运营商的基础设施能力代表数字经济的“硬底座”,AI-OPC的个体创新活力代表数字经济的“软创新”,软硬结合能够打通“基础设施供给—轻量化创新应用—产业场景落地—技术迭代升级”的正向循环,推动AI技术从高端产业下沉至千行百业的个体场景,实现人工智能的普惠化落地,助力数字经济高质量发展。
服务模式革新:从管道供给向AI生态运营的转型突破
面向AI-OPC生态的发展需求,传统单一的通信服务模式已完全无法适配,运营商必须完成服务逻辑、产品体系、商业模式、服务形态的全方位革新,构建适配轻量化AI创业主体的新型电信服务体系。
在服务逻辑上,实现从“标准化管道服务”向“定制化全生命周期赋能”转型。传统电信服务以标准化网络、带宽、流量产品为主,服务对象以大中型企业与公众用户为主,服务模式同质化严重。而AI-OPC的业务场景多元、需求碎片化、运营轻量化,对服务的灵活性、普惠性、定制性要求极高。基于此,运营商需摒弃传统标准化服务思维,立足AI-OPC创业筹备、研发生产、运营服务、合规发展的全生命周期,构建一站式、全栈式、轻量化的赋能服务体系,实现从“提供网络资源”向“赋能产业创新”的思维跃迁。
在产品体系上,实现从“单一通信产品”向“算力+模型+数据+安全+应用”全栈产品矩阵升级。依托云网融合、边缘计算、智能算力核心能力,运营商需重构产品体系,打造适配AI-OPC的普惠算力产品、轻量化模型服务、合规数据治理服务、智能安全防护服务与低代码应用服务。区别于互联网企业的单一模型服务,运营商产品的核心优势在于“网、算、数、智、安”的深度融合,能够为AI-OPC提供一体化、无壁垒、高安全的综合解决方案,解决个体创业者技术零散、资源割裂、安全无保障的痛点。
在商业模式上,实现从“刚性计费”向“弹性普惠化价值计费”革新。针对AI-OPC资金有限、按需使用的经营特点,运营商需打破传统固定套餐计费模式,推行按需调度、按量计费、弹性扩容的算力Token计费模式,推出梯度化、轻量化、低成本的普惠服务套餐。通过基础服务免费、增值服务订阅、定制服务付费的分层模式,最大化降低AI-OPC的创业成本,同时依托海量小微用户形成规模化、可持续的新型营收体系,构建电信行业增量增长模型。
构建多元协同的“AI-OPC+电信”产业生态治理体系
“AI-OPC+电信服务”并非简单的供需匹配,而是需要构建多方协同、共创共享、合规有序的产业生态体系。运营商作为生态核心枢纽,需发挥基础设施主导优势,联动政府、产业伙伴、服务机构、创业主体,构建层次清晰、协同高效的生态格局,破解单一主体发展的局限性。
首先,构建政企协同的政策赋能生态。AI-OPC作为新型市场主体,行业规范、扶持政策、监管体系仍处于完善阶段。运营商需主动对接地方数字经济发展战略,联动政府部门搭建AI-OPC培育载体,争取算力补贴、创业扶持、税收优惠等政策资源,将政策红利与电信服务深度融合,打造政策赋能、基础设施赋能双向叠加的发展优势,引导AI-OPC行业规范化、集聚化发展。
其次,构建产业联动的技术创新生态。运营商需秉持开放共享的生态思维,打破技术壁垒,聚合大模型厂商、AI技术企业、低代码开发平台、行业解决方案服务商等生态伙伴,形成能力互补、场景共建、价值共享的产业联盟。通过开放算力调度平台、模型接口、数据资源,吸引生态伙伴聚焦AI-OPC细分场景开展技术创新,丰富垂直领域服务能力,解决通用AI服务与行业细分场景适配不足的问题,完善生态技术供给体系。
再次,构建全链条的创业服务生态。AI-OPC的发展不仅需要技术与算力支撑,更需要合规、金融、运营、知识产权等配套服务。运营商可整合金融机构、律所、会计师事务所、创业孵化器等资源,搭建一站式创业服务平台,补齐AI-OPC运营服务短板,形成“算力底座+技术赋能+配套服务”的完整生态闭环,全面提升个体AI创业的存活率与发展质量。
最后,构建底线可控的安全合规生态。AI技术的普惠化发展伴随数据泄露、模型侵权、内容违规、网络攻击等多重风险,而AI-OPC个体风险抵御能力薄弱,是行业合规风控的薄弱环节。运营商需依托自身成熟的网络安全与数据合规能力,构建覆盖数据全生命周期、模型应用全流程、网络运营全场景的安全合规体系,提供合规审计、风险排查、安全防护、隐私保护等专业化服务,以技术能力筑牢行业发展底线,推动AI-OPC生态健康、有序、可持续发展。
AI-OPC的爆发式崛起,是人工智能技术普惠化、数字经济轻量化发展的必然结果,彻底改变了传统产业创新创业格局与数字基础设施的应用场景。对于电信行业而言,这既是行业转型的重大机遇,也是央企赋能新质生产力发展的核心使命。未来,运营商需持续突破传统服务思维桎梏,以算力网络为底座、AI能力为核心、生态协同为路径、安全合规为底线,持续完善“AI-OPC+电信服务”生态体系,完成从通信管道服务商向AI产业生态运营商的战略转型,为数字经济高质量发展与人工智能产业普惠化落地提供坚实支撑。
爱立信Ericsson Forum路演中国首站启幕。活动期间,爱立信全球技术专家将携手三大运营商及产业链伙伴,围绕AI规模化应用下的网络建设、技术创新与产业协同、6G推进等展开深度研讨。本次路演汇聚前沿技术洞察、专业干货分享,并结合本土需求定制实战演示,为产业携手破局、共探发展新机遇搭建了交流平台。
移动连接不是看客,而是主角
爱立信中国区总裁方迎表示:“从通信行业来说,以AI和Token经营为重心的新的赛道正开启。在这一轮变革中,移动连接不是看客,而是主角,先进连接技术与AI的结合将进一步重塑全球经济格局。下一阶段的关键,是让AI触达并融入新一代应用与设备中,由于其更加分布式、实时化和场景化的特点,因此必须依赖先进的连接技术支撑,意味着网络已不再只是支撑连接的底层设施,而正在成为AI规模落地的关键底座”。
既要深化5G,也要提前布局6G
爱立信亚太区CTO Magnus Ewerbring强调了智能网络底座的重要性。在《智能网络基座-无处不在的6G与AI》演讲中,他阐明移动网络是连接 AI应用的核心底座,需以无时不在的可靠连接,支撑多模态AI、物理AI、增强现实等应用走向普及。对于通信网络的未来,他指出通信行业需兼顾当下与未来,既要推动5G业务持续深化,也要提前布局6G,做好频谱资源预留与技术标准规划,为下一代通信技术的发展筑牢基础。
全栈AI让原生AI RAN变为现实
爱立信东北亚区网络产品总经理Matteo Fiorani介绍了爱立信最新推出的全栈AI解决方案,从networks for AI到AI for networks,其中AI in RAN可将电信级AI模型部署至现网的基带单元与射频单元,实现微秒级的实时推理。这套可规模化商用的原生AI RAN解决方案能让电信运营商快速赋能并差异化各类mobile AI应用。
差异化连接是业务新范式,自智网络是运营新范式
AI时代,网络发展趋势也在发生变化。爱立信东北亚区网络服务总经理吴日平表示,AI时代通信行业的核心发展方向为差异化连接与自智网络,前者助力运营商增收、提升行业竞争力,后者可降本增效、赋能新型业务。他预判2030年L4级高阶自智网络将成为行业刚需。Ericsson AN赋能网络运营变革,已经进行超1亿次AI推理,覆盖1100万个小区,为约20亿用户通过AI优化网络体验,未来将持续赋能运营商网络智能化转型。
5G重塑企业网络基座,多领域实现落地应用
爱立信企业无线解决方案事业部亚太区CTO John Hopping围绕《5G重塑企业网络基座》分享观点。他表示,面对物理AI、工业自动化等新兴应用对低时延、高带宽、高安全的严苛需求,传统网络已难以适配,5G专网正成为企业数字化转型的核心底座。依托5G专网、大规模天线阵列、边缘AI推理、零信任安全等技术的相关方案已在港口、工业制造、矿业等领域落地应用。
AI+差异化连接助力运营商下一波增长
爱立信中国咨询服务部总经理莫文莉表示,未来3至5年,以5G专网为主的企业数字化服务、消费端差异化连接服务是运营商最看好的增收领域。目前全球差异化连接商业落地走向成熟,优质体验让服务溢价成为可能,而AI眼镜、具身智能等AI新应用,也对网络提出大上行、低时延、边缘算力等更高的能力要求。AI时代的网络连接将不仅仅是基础设施,更是体验的保障,价值的承载,以及运营商独特竞争力的体现。AI和差异化连接的双向赋能将助力运营商把握下一波增长机遇。
Ericsson Forum媒体发布环节,爱立信东北亚区副总裁吴立东、中国移动设计院无线所技术总监张琪璇、爱立信中国区网络方案部总经理倪子铭围绕爱立信与中国移动在山东德州开展的网络切片测试展开了交流。该测试重点在山东德州开展切片、资源预留等技术验证,覆盖校园、车站、大型活动等人流高负荷场景,以及云游戏、AI眼镜、上行直播等大上行、低时延业务。实测数据表现符合理论预期。对比没有配置切片的用户在上行直播中存在的卡顿现象,启用切片服务后用户网络速率显著提升,有效解决直播卡顿问题,大幅优化了用户体验。目前,该技术已具备大规模商用条件,未来还可应用于低空经济、具身智能、AI流量经营等领域。
2026年是爱立信创立150周年。依托汇聚全球顶尖行业专家与分享全球创新经验的Ericsson Forum China,爱立信凝聚了更多行业共识与力量。首站活动之后,系列活动将持续面向电信运营商开展,共同筑牢智能网络底座这一关键基础设施。
C114讯 6月11日下午消息(舒允文)今日下午,上海迎来又一座数字地标。上海移动携手月星集团在上海环球港联合举办发布会,正式宣布“双万兆第一港“暨首个AI智慧商业体落地上海环球港。上海市经信委、市数据局、普陀区政府相关领导出席活动并见证本次发布。
网络基础设施的代际跃升,从来都是产业变革的前奏。按照《上海市进一步推进新型基础设施建设行动方案(2023—2026年)》的规划,到2026年底,上海将初步建成以5G-A和万兆光网为标志的“全球双万兆城市”。此次环球港从“双千兆”率先升级为“双万兆”,不仅是城市数智化建设中的一大里程碑,亦是“数据要素×AI”从概念走向实体商业应用的重要一步,体现了上海移动在深度赋能实体经济、推动“数实融合”方面的一贯努力。
C114在现场了解到,此次合作中,上海移动充分发挥5G-A与万兆光网的技术优势,为环球港打造了“极速、低时延、超级上行、通感一体”的“双万兆”网络基座。目前,已基本完成环球港5G-A室内覆盖,太阳厅、环球大厅等重点区域的深度覆盖,万兆光网已全面接入环球港。
环球港“双万兆”的落地,不止意味着速度升级、宽带迭代,还将实现从“万兆网络”向“万兆生态”的关键跨越:即以双万兆网络为核心基座,聚力打造面向智能时代的数据要素一体化综合枢纽,打通数据汇聚、智能分析、场景应用全链条,构建“数据+模型+场景”的一体化供给模式,让数据真正成为驱动文、商、旅、体、展多产业融合发展的核心动能,为城市商业高质量发展注入数智动力。
发布会上,上海移动与月星集团正式签署了战略合作协议。根据协议,双方将在智慧商圈建设、智慧运营、数字营销、会员权益、商企数智赋能等多个维度进行全方位、深层次的合作,并以此为契机,打破区域壁垒,促进普陀区沿沪宁产业创新带的数字资源跨区域流动,为长三角一体化数字经济发展注入强劲动能。
与此同时,上海移动发布多项惠民惠企举措,其中“移动 - 环球港”5G-A权益包、AI智能体“环环”、“世界杯”环球港第二现场AI观赛等智能服务的发布推广,来逛商场的市民不仅可以享受商场内极速上网、餐饮折扣、停车优惠等权益,还可以参加AI观赛等多元化商场文娱活动。此外,面向商铺、企业,上海移动推出万兆企宽智能服务包和2500万tokens免费体验,助力打造商业体更优营商环境。依托“双万兆网络+云产品+AI”一体化服务,商户可实现智慧餐饮、智慧零售、智慧办公三大场景数字化转型,进一步提升运营效能,提高服务质量。
据悉,上海移动已建成全国领先空天地一体5G-A网络,5G规模保持领先,核心城区、重点区域实现5G-A连续覆盖,并完成40个万兆园区/小区建设,助力“模速空间”打造全国首个万兆大模型创新生态社区。可以预期,环球港的探索若被验证可行,这套方法论将很快在上海其他大型商业综合体中复制推广,助力打造更多“文商旅体展”消费新场景,为“国际数字之都”建设贡献更多移动力量。
📭 此日期无低空经济分类的数据。
论坛介绍:本次论坛是 2026 年 6 月 12 智源大会核心技术论坛之一,由蓝驰创投管理合伙人陈维广担任主持人,邀请到智源研究院院长王仲远、银河通用创始人兼 CTO 王鹤、面壁智能 CEO 李大海三位行业顶尖技术专家,围绕大模型行业最具争议的五大核心问题展开深度对谈。嘉宾从学术研究、技术创业和产业落地三个维度,分享了对大模型未来发展的独家判断。
核心观点速览:
大模型技术远未收敛,不存在普遍趋同的终局,真正的护城河来自数据闭环、软硬协同设计和垂直场景的极致深耕Scaling Law 远未失效,已从纯语言模型扩展到多模态和具身智能,WAM(世界动作模型)将开启具身智能的规模化时代端侧与云端将长期协同发展,终端大模型的 scaling 空间巨大,由硬件算力升级和量化技术进步共同驱动AI 安全与责任划分将遵循 "边实践边完善" 的路径,参考自动驾驶等技术的发展历程,逐步建立行业标准和治理体系中国 AI 具备全球最完整的供应链、最丰富的落地场景和数量最多的年轻人才三大独特优势,具身智能将是中国实现弯道超车的核心赛道
陈维广:大家下午好,非常荣幸担任本次论坛的主持人。主办方给我的主题是:在大模型技术的成熟曲线上,我们该如何跨越?又该如何定义大模型的长期价值?今天也非常非常荣幸,能邀请到这三位嘉宾,他们能从三个不同的角度来去一起探讨这个主题。
仲远老师大家应该比较熟悉了,智源也在过去这么多年,参与到了智谱、月之暗面等大模型企业的相关研究,包括今天在座的这两家,所以他应该是有非常好的全局观。王鹤老师这边,银河通用主要是在Physical AI,在具身这块,如何去更好地利用模型来加速Physical AI的部署。大海老师刚才也介绍了,大家也知道面壁在终端这块还是比较前沿的。
那我就尽快进入问题。我觉得整个行业里面大家都有一个问题:大模型这几年发展得比较快,可是同时大家也能看到,不管是打榜还是一些第三方的评价,顶级模型的趋势在快速趋同。今天可能某某的benchmark数据很好,两个月后其他人就跟进了。再加上token的价格也快速在下探,还有一点就是开源模型也发展比较快,甚至有人说开源模型跟闭源模型的差距也就3到6个月。
在这种情况下,如果作为一个AI模型公司,它的长期价值来自哪?它的护城河来自哪?甚至有些人非常质疑说,AI大模型的公司最终就会像卖水卖电的有量无价。我第一个问题就是,王鹤老师,从你的角度,你感觉AI的企业,尤其是这些大模型公司,它未来的长期价值以及护城河在哪里?
王鹤:我觉得这个问题其实更多表达了大家对数字世界里的智能,或者说对LLM这项技术现状的判断。但就像仲远博士刚刚讲的,LLM本身仍然存在很多变数,如果再往后看多模态、VLM(视觉语言模型)或者视频生成,变数就更多了。
我本人主要从事具身智能领域,我认为整个行业刚刚在往收敛的方向发展。过去几年行业有VLA(视觉语言动作模型),也有World Model(世界模型),现在我认为整个行业正在向着WAM(世界动作模型)的方向迭代:一个模型既能够做未来的预测,又能够做动作执行的预测;同时它既能够吸收人类的无动作标签数据,又能够吸收机器人的有动作标签数据。
具身智能现在的发展阶段,大概处在GPT-1到GPT-2这样的水平。往未来看,一旦行业进入scaling(规模化)阶段,一切都会快速加速,这也意味着行业现在需要更大量的资金投入。
面向未来,具身智能真正的护城河是一个完整的体系:既有源头的数据供给,又有对不同种类数据(合成数据、人类数据、机器人数据)的提炼能力,还有硬件迭代和软硬co-design的能力,最后是模型的融合水平和向客户交付硬件的整套能力。这是迄今为止全世界范围内都没有出现过的综合型产品形态,所以它的护城河相当深,未来不管是做垂类应用的深度还是广度,都有无穷的潜力。
陈维广:所以是要做"六边形战士",面面俱到。大海老师怎么看?
李大海:我觉得场上嘉宾的观点是一致的,都不认同"大模型没有长期壁垒"这个结论。受两位嘉宾启发,我突然想到:大模型应该是我们以前说的"T形人才"——它必须得是通用的,但仅仅是通用的、和其他人同质化是没有意义的,它一定得有自己的长板。
举个例子,现在美国大模型领域的当红企业是Anthropic,它之所以强、被追捧,是因为它在通用模型的前提之上,把Coding能力做到了独步天下,因此才获得了现在的估值、行业认可和非常亮眼的商业成绩。所以大模型光是有横向的通用能力是不够的,一定得有纵向的长板。
另一方面,纵向长板怎么来?我非常认同王鹤老师讲的,我会用另外一个词叫闭环:一定要把大模型当成一个引擎、一个发动机,但这个发动机的设计和能力的持续极致优化,必须要和"整车"去协同,不能脱离应用空谈性能。你造的是F1赛车还是买菜车,对应的发动机需要做完全不同的特化。
从过去两年大模型的发展来看,一个非常重要的趋势是:模型正在以内化成一个系统的方式演进,包括现在我们做的agentic强化学习,其实就是带着整个智能体系统去做模型的进一步训练。面向未来,上下文记忆是一个非常重要的待突破方向,现在大家都在用harness的方式解决,但我认为这个方式不够,必须是harness加上模型的强化学习才行。
总结一下:我认为大模型的技术还远远没有收敛,同时任何一家模型公司都必须把技术的通用性和商业的通用性分开——真正通用的商业场景其实很少,要做好商业往往需要模型在特定方向上做极致的优化。只要每个公司找准自己的方向,都能构建起自己的护城河。
陈维广:仲远院长怎么看这个问题?
王仲远:坦率来讲,我个人并不完全认同"模型趋同、没有护城河"的观点。因为现在大模型整体的性能迭代还没有到瓶颈,我们还没办法断言最终会不会所有模型都趋同,未来可能是一超多强、多个巨头并存,也可能是大家能力相近,有很多种演化格局。
现阶段来看,榜单其实并不那么可信。各种各样的榜单看得人眼花缭乱,很多结果也没办法完全验证。老话讲"是骡子是马拉出来溜溜",那些敢于做真机展示、敢于进入实际场景落地的模型公司,是有底气的,也能够在真实场景中找到数据闭环。
所以今天还没办法下定论说未来模型公司都会趋同、没有护城河。智能技术还没有收敛,还在快速迭代演进,各种可能性和结果都有可能出现。
陈维广:看来这个行业大家很容易黑白分明,立刻就想下"大模型没有长期壁垒"的结论。但听你们介绍,场景、数据,包括刚才大海老师说的闭环能力都非常重要。从投资角度,我们接触的创业团队也很多,发现团队的基因差异其实很大:做大模型的团队有实验室氛围,做应用的团队更关注场景和需求。当然也不是说做大模型的就做不了应用,但确实这两种团队的文化和取向完全不一样,这也会逐渐形成一定的壁垒。
接下来是行业一直在拷问的一个问题:尤其是去年,大家感觉scaling law的红利变小了,甚至有人说预训练做得越多,模型能力也没有很大提升,所以去年有一波做强化学习、做后训练的热潮,后训练至少可以把能力做到一个比较好的水平,包括刚才蚂蚁的李老师也提到了deep deep sheet和reasoning能力的出现。所以行业就感觉,是不是接下来纯语言模型的发展会遇到瓶颈,边际效应递减?仲远院长,你怎么看这个问题?
王仲远:从我个人的观点,我其实还是比较坚信scaling还远没有到尽头。去年之所以媒体上会有很多关于scaling law是不是已经失效的探讨,但实际上从技术领域,从我们接触的很多大模型实际训练的公司,以及从今天这个时间点再回过头来看,很显然已经证明了scaling没有失效,只不过它变得更加多样化了。
去年大家会有"scaling失效"这种论调,其中一个很重要的原因是大语言模型所使用的互联网数据已经用完了。大家觉得互联网数据只有一份,而语言模型以前主要靠预训练来提升性能,那预训练的数据用完了,性能自然就会遇到瓶颈。但实际上在过去两年,大家通过后训练以及推理优化,已经迎来了新一波的能力提升。
再往后通过agent,包括今天智源大会早晨开幕式的圆桌上也探讨到了递归自进化,这些都已经证明了:即使互联网数据可能用完了,AI的能力依然在持续提升——不仅仅是模型本身的能力提升,更是整个系统的能力越来越强,而且也开始从聊天工具变成执行工具。所以我们还是非常相信整个scaling的曲线还在延续,如果大家去看近期发布的很多模型,能力甚至呈现出指数级跃升的倾向。
早晨我其实也问了一下朱军,他的观点相对谨慎一些。可是我们看到了很多的模型,确实它的能力依然在快速提升。另外,智源研究院的定位一直是"做高校做不了、企业不愿意做或现阶段不愿意做的事",去探究下一个智能的曲线。
过去两年我们把重心放在多模态,用Next Token Prediction的方式去探究多模态的Scaling。事实上我们发现,像物界Emu3、Emu3.5,已经呈现出了一个多模态的Scaling范式:当我们复用了大规模现在的大语言模型的智算基础设施,数据和参数的增加确实带来了能力的提升。而我们的数据依然只用了不到1%,参数也只有百亿级,但已经看到了非常明显的性能提升。
所以多模态的scaling范式,我们认为已经找到了至少一条可行的路径。当技术成熟的时候,我们就交给产业去做,然后我们又开始往下一个方向——物理世界的世界基座模型去探究,看看在世界模型上有没有scaling的范式。今天早晨我们也分享了正在研发当中的物界Physics,它就在探究世界模型的scaling方式到底是什么。
所以我对这个问题还是非常乐观的:不管是已经成熟的语言模型、AI coding、数字世界的大模型,还是最终我们进入到物理世界的世界基座模型,依然还有非常多的scaling空间需要去探究。
陈维广:王鹤老师这边,因为Physical AI可能跟大语言模型还有点不一样,对不对?甚至有一些行业人说,VLA都还没搞完,为什么突然间出现这么多搞世界模型的?你有什么看法?
王鹤:是这样的,银河通用和我本人是deeply believe in scaling 的。其实在WAM(世界动作模型)这个范式还没有出现之前,在VLA(视觉语言动作模型)的范式里,我们就先用合成数据做了大量的scaling。当时我们主要focus在一件事情上——抓取。我们想看看一个技能能不能通过scaling来变成一个真正的基模。
我们用了10亿帧仿真数据证明了:只要你把数据scale到这个程度,抓取就可以完全做到Zero-Shot(零样本)。在真实世界随便给我一个东西,我们的端到端GRASP VLA模型,就能直接零样本解决这个问题。这是我们2025年初的工作,到今天为止,仍然没有一个靠真实世界遥操数据训练出来的模型,能达到我们这个GRASP VLA的零样本抓取能力。
但是我们立即就发现了一个问题:从合成数据的角度上讲,更多的任务超越抓取之后,什么时候能完全合成完?从真机遥操的角度,我在遥操路线刚刚出来的时候就讲过:什么东西都靠遥操是不行的,如果什么都靠遥操,我们很难scaling。
但今天我想说的是,具身智能正在迎来一个非常光明的scaling up的时间点,就是因为WAM(世界动作模型)。WAM跟一般的World Model不太一样:今天大家讲的World Model是一个很宽泛的概念,前几天李飞飞老师也把World Model分成了好几类,有的是当simulator
用的,有的是用于生成视频的。而我们讲的WAM,它是以action为最核心,用未来的预测当做视觉层面对动作的planning。
最关键的是,WAM不需要动作标签。所以你可以想象一个机器人看人干一件事,它虽然没有action label,但是它能把人的行为、大致的course motion学到。这样我们就能大量借用人类的第一视角视频,来帮助我们的具身智能往更多样化的任务、更多样化的场景、更全面的技能去scale up。
这里也说一句:如果大家在arXiv上搜索world action model,全世界第一篇WAM的论文就是银河通用在2025年3月份挂到arXiv上的。这个路线在我今天看来,能够真正把无尽的环境和任务融合进具身的基模训练里头。所以我认为WAM确实定义了一个超越VLA的新范式——因为VLA里所有东西都需要有action label,它的scaling只能靠robot data,但我们今天加入了human data,真正迎来了scaling up的广阔空间。
甚至今年4月份的时候,NVIDIA Gear具身智能实验室的主任,他在红杉的一个演讲里直接就说出来了:robotics 的 end game就是WAM。所以我感觉今天具身智能的预训练正在迎来一个蓬勃发展的状态,因为在数据获取的类型上,我们已经没有局限性了。
我能够预测:往未来看两年,具身智能将全面到达一个从GPT-3.5向ChatGPT转变的关键预训练milestone。所以现在对我们来说是真正好的时机。但这也意味着,行业需要千万小时的高质量数据,以及百亿以上的单年投入,再加上大模型的能力,这三项加起来,才能成为冲刺具身智能"ChatGPT时刻"的入场券。
陈维广:非常兴奋的moment。所以我把这个问题稍微延展一下,是不是根据你这样的分析,意味着现在这些为了"世界模型"融资的公司全部都不靠谱?WAM是不是靠谱?
王鹤:这个WAM也算是一种世界模型。但是我个人看,很多World Model它里面的一些key feature,就比如这个东西能当simulator,让机器人做强化学习。
在我看来,今天不能说全部靠谱,我们也有很多工作是拿World Model当做一个differentiable simulator能够交互的,但是希望World Model先把全世界任何东西都可以simulate,都可以交互,再训出具身智能,我觉得应当不是这样的。
陈维广:还有一个差距.
王鹤:对,因为我们人也不能把全世界所有东西都simulate,都能够精确的知道下一步的物理状态,但我照样可以interact with everything,所以我并不觉得成为一个成熟的world simulator是建立具身智能ChatGPT的前提条件。
陈维广:大海老师,我把那个问题稍微改一下。行业里通常有一个挑战:过去几年大家看到云端在快速scaling,但终端因为资源受限,好像不能scaling?你怎么看?还是说终端和云端其实可以一起scaling?
李大海:首先简单的答案就是:肯定都在scaling。其实面壁提出来的知识密度定律和scaling这两个东西,如果整合一下就是一个公式:大模型的智能整体等于大模型的知识密度乘以它的参数量。
所以我们会看到,在今天还有人质疑scaling到底是不是失效的时候,事实上云端的Coding模型在变得越来越大——我们都知道OPUS的模型越来越大,国内所有的Coding模型也在越来越大。同时我们端侧模型也在越来越大:去年面壁给主机厂落地端侧模型,只能落1个B(十亿参数)的模型,不是我们只能做1B,是因为当时智能终端上能支撑模型跑起来的算力和带宽只有这么大。今天这个模型已经从1B涨到4B了,我觉得明年可能就变成几十B了,速度涨得非常非常快。
端侧其实是资源受限,具身智能本质上也是一个终端,具身大脑也一定是端侧模型。所以这个问题在模型层面上有非常大的scaling空间,受限的只是物理条件。
另外我还想补充一点:就算是大语言模型,在长上下文任务处理上也依然有非常大的空间,现在并没有做得特别好。不用讲复杂的技术细节,大家简单理解:人的大脑处理超长上下文任务做得非常优秀,而且功耗极低,但大模型在这类任务上的成本和效果都远远落后于人脑。这背后的巨大空间,依然要靠Scaling来填补。
所以我们觉得道阻且长,技术远远没有收敛。现在行业里常常会用一些阶段性的认知来制造叙事,但这些叙事的保质期非常短,我们一直在不断打破旧的认知。
陈维广:刚才你说端侧模型从1B涨到4B,主要还是因为端侧的硬件变得更厚了,是吧?
李大海:对,包括我在第一个分享里面,我们也在用更多的技术让模型能够变得更大。因为我的知识粒度变高了,我的各种,比如说我的量化的技术的提升,所以导致我们用更大的模型,量化完以后,它用的内存,用的资源是一样多的。这些都是一些手段。
陈维广:嗯嗯,多问一个问,就是说这里有一个说法,就是从市场上说,端侧模型会起来,主要是因为大家觉得云端模型太贵了,都在想办法把这个计算放到终端,这个理论能成立吗?
李大海:我认为这是Token经济学的一部分。尤其是对于终端厂商来说,这个是一个非常清晰的算账的方式。在中国大家都知道,我们老百姓买手机、买汽车不可能去订阅的。我买了一台手机,我不会再想着说给手机厂商每个月交19块。
所以对于同时想给用户提供很好的设备上的AI体验的设备厂商来说,他就面临这个选择:就是我的后续的成本到底怎么负担?从算账的角度上讲,端和云一定要协同,因为端侧资源有限,不可能做和云端一样的工作。但是但凡端侧能做的,大家尽量还是希望能在端上做,我们这样的成本肯定是最低的。
陈维广:刚才我问的那两个问题,主要还是一些行业的一些看法。不管是做端侧的,云端的,或者是做具身跟AI的,你们能提升这个效率3倍、5倍,甚至10倍都没问题。
可是最终如果出问题的话,因为我们不是在说嘛,agent就会自动化的去审核,如果它出错误的话,谁来背这个黑锅?王鹤老师,你这个机器人很聪明,包括大模型,同样的,对不对?这块,你们有思考过这个吗?或者是有客户提出这个问题吗?至少我知道这些做agent的,时常就被客户挑战。如果完全把这个agent自动的去完成这个任务的话,如果出问题的话,谁来承担这个责任?
王仲远:对,首先其实这让我想起来今天早晨开幕式上,王坚博士的播客访谈,其实也涉及到这个问题,就人和AI到底如何共处?
那么我想一个新的技术的诞生,总会涉及到从人们对它最开始可能担忧恐惧,到后面开始适应或使用它,习惯它,以及它怎么去融入到这个社会,什么样的一个治理体系,什么样的一个政策,能跟这些技术一起来协作?我想,比如说像自动驾驶、辅助驾驶,其实已经开始在以前趟过了一遍这样的一些路,到底权责谁来定?到底是软件厂商的、硬件厂商的,还是用户的?其实AI后续包括智能体也会有类似这样的一个过程和阶段。
更多的是,一方面我们看到了这个技术对于生产力的提升,对于生产效率的提升。当它确实就像您说的,它如果已经提升了3倍、5倍,我想这种技术就一定是没办法被阻碍的,它最终就会在工业,在我们的生活中变得越来越流行,越来越普遍。
另外一方面,到底如果出现了一些故障,或者出现了一些问题,它的责任的划分,这我觉得是整个社会治理体系政策的一些方面,我相信咱们人类已经经过了这么多年,这么多次的技术浪潮,会有办法解决的。
王鹤:我也简单的补充一点,其实机器人在工业自动化当中的应用,跟未来具身智能机器人在各行各业的应用,它既有不同,也有很强的相似性。
如果我们交付给工业客户,他其实不管你是具身的还是传统的,他主要看你做这道工序的成功率是多少。交付了以后,如果比如说在某一个环节失败,导致产线停工,跟员工出错导致产线停工一样,该怎么罚就怎么罚,所以其实如果我们今天是讲对经济活动的一个影响,那很简单,就是具身智能机器人一定要做到像人一样干的好活,并且,在经济任务上能负责任,我想这个是没有问题的。
那么更长远的其实是具身机器人跟人类在一些复杂的决策和又有体力的活,又有脑力活的交互当中,怎么能讲清楚权责?所以我觉得这个,从现在agent的大面积的使用,我相信未来能慢慢的给出我们一个方案。
今天使用这么多Coding agent,那写了bug,到底是谁的责任?那肯定还是使用这个Coding agent的人,他的使用没有做很全面的评测。那未来就是使用这个具身机器人在产线里头,那么谁为它负责?是不是也是这条产线的一个管理者和背后到底是技术漏洞还是管理漏洞为它负责?那么再往更远的未来,全部都是AI,没有任何人类,谁为它负责?我相信我们会一步步的去探索出来背后的体系。
李大海:我来说点让大家毛骨悚然的真话。其实我觉得整个人类社会的发展就是建立在吃一堑长一智的范式上。就是我们现在大家都去坐飞机,飞机上有非常多让人很恼、很讨厌的一些安全规定.起飞降落的时候必须要收起小桌板呀,打开遮光板。为什么会有这些安全规定?都是历史上一次一次的空难,空难以后造成了严重的损害、损失,大家总结出来,原来这样是不安全的,去总结出这些一个一个的规定。
很多时候大家还不理解,事实就是这样,包括在某些交通的路段上,忽然之间限速30,为什么要限速30?因为超过30就特别容易出事故,这都是总结出来的。我觉得这是人类社会运行的一种比较常见的方式。好消息是,其实在人工智能的赋能底下,其实我们去填补安全漏洞,去发现安全的问题的效率也提高了。所以在有了新的技术以后,虽然可能无可避免的还是会先吃亏,再长智慧,还是要付出一些代价。但是我觉得这个代价可能会比以往时候付出的更少,这个是好的方向。
另外,就是我们作为企业,我们看到,其实我们的监管政府对于这些安全底线的工作,其实是非常非常的重视,所以企业在这个方面,从很早就开始考虑自己的社会责任,就已经开始考虑这些问题了。我们从第一天开始要通过网信办的安全备案,其实就要考虑大模型的内容生成是否符合各种各样的内容安全的这样的一个标准,这些都是我认为好的方向,但是总的来说,吃一堑长一智,这件事情可能真的无法避免。总会,安全问题总会从你想象不到的角度出现,给大家一个教训,这个教训再来变成我们让整个社会整个治理更安全的方式。这是我认为大家要理解的事情。
陈维广:说的非常好。我看到我们只有3到4分钟,最后一个问题,咱们嘉宾快速回答,你们从你们的自己的视角,以及你所处的领域,你觉得中国的AI和欧美的AI,最终走出来不一样的地方在哪?仲远院长先来。
王仲远:对,我觉得咱们中国还是有很多很独特的优势,包括像供应链、制造业以及场景,所以其实我们自己本身,整个中国的市场也已经足够大,使得我们能够去孵化和催化很多的技术的产生和落地。当然我们肯定也希望这样的技术能够辐射到全球,所以我自己觉得结合中国的这些优势,像具身智能,像世界模型,很有可能是我们将来会有独特性,且在一定程度上领先的一些领。
王鹤:对,其实我明天在我们这个具身智能与人形机器人的论坛会主要谈这个事。我的talk的名字叫推动embodied AI的AlphaGo和ChatGPT moment。
实际上,我坚信具身智能是中国的机会。具身智能的AlphaGo和ChatGPT Moment,我坚信会在中国实现,这也是我们银河通用和中国具身智能人的责任。如果具身智能的0到1在中国完成,相信1到100必定是在中国成熟的。
李大海:我就补充一个点,就是人才。中国拥有最聪明的青年才俊,并且数量应该也是全球最大的。我觉得这个是最底层最重要的因素。有了这个因素,再加上刚才仲远老师提到的我们的生态,我们的优势,我们的整个供应链。我觉得这些因素叠加在一起,包括政府对于这个领域的重视和搭台唱,我觉得这些因素叠加以后,中国必定会在人工智能领域取得各方面的长足的进步和胜利。
陈维广:对,其实我们最近也做了一个比较,就是美国的这个AI人才跟中国的AI人才,很明显的就是中国的这个年轻化,这块是很明显的。所以看到智源的这个大会每年越办越大,对不对?也有很多这个年轻的研究员踊跃的参加,而且我们投的很多创业公司,他们其实除了这个创始人跟团队,他们其实也跟院校有很多合作,也跟智源这边有很多合作,我觉得这个可能跟美国是最大的不同嘛,这是从我们这边观察到。
微软在 Build 2026 开发者大会上宣布,将全面增强 Azure API Management 的 AI 网关能力"。本次主要新增能力如下:一是推出统一模型 API(Unified Model API),客户端仅需使用一种 API 格式,Azure API Management 即可自动将请求适配为各类后端服务商对应的格式;二是 AI 网关现已支持接入 Anthropic 和 Google Vertex AI 旗下模型;三是内容安全策略升级,防护范围拓展至 MCP 工具调用以及智能体间(A2A)通信,与原有大语言模型流量一并纳入保护。
APIM 团队撰文"指出:
相较于为智能体单独搭建专属治理平台,Azure API Management 可帮助企业将成熟的 API 治理规则直接沿用至新兴的智能体生态体系中。
统一模型 API" 现已进入公开预览阶段,解决了企业团队日益突出的运营痛点——随着团队越来越多地混合使用 OpenAI、Anthropic、Google 等提供商的模型(基于性能、成本、延迟或区域需求方面的考虑),每个提供商暴露的 API 格式各不相同。统一模型 API 让客户端可以统一采用一种格式(目前为 OpenAI Chat Completions),APIM 会透明地将请求转换为后端提供商的原生格式,无论是 Anthropic Messages API 还是其他模式。团队可以更换后端提供商、添加新模型或在不同提供商之间路由流量,都无需修改客户端代码。
这不仅仅是一个简单的功能适配层。将模型访问统一接入单一 API 接口后,无论由哪家服务商执行推理,所有治理策略、限流规则、内容安全检测与令牌用量统计都可统一生效。已经使用 APIM 进行传统 API 治理的组织可以将相同的模式延伸至 AI 工作负载,无需额外引入独立的治理体系。
内容安全能力向 MCP 与 A2A 场景延伸是本次架构层的 llm-content-safety 策略原本用于对照 Azure Content Safety 扫描 LLM 请求和响应内容,现在已同步覆盖 MCP 工具调用参数、MCP 响应文本以及 A2A 智能体交互载荷。同时,该策略包含两层独立安全防护:分类内容过滤,针对仇恨、自残、色情、暴力四类内容进行管控,支持设置风险等级阈值,范围为 0(最严格)至 7(最宽松);独立的 shield-prompt 属性,用于识别对抗性提示词注入攻击。典型配置示例如下:
团队需要注意的一个实现细节,即该策略在流式响应中的行为有所不同。在非流式模式下,一旦检测到违规内容,系统会直接返回 403 状态码。在流式模式下,策略会在滑动窗口中缓冲事件",并直接停止向客户端转发后续事件,且不会返回错误信息。因此,使用流式补全能力的智能体需适配这种内容中断的情况,不能依赖错误码做判断。两个新增的属性 window-size 和 window-overlap-size 可用于调整超长内容的拆分规则,适配 Azure 内容安全服务 10000 字符的评估上限。
词元统计指标已进行了升级,适配多提供商的使用场景。APIM 现在会将推理词元、缓存词元和音频词元记录到 Application Insights,支持 OpenAI Chat Completions、OpenAI Responses 和 Anthropic Messages API 等格式,可监控 Microsoft Foundry、OpenAI、Amazon Bedrock、Google Vertex AI 等多加服务商。对于需要构建成本仪表盘和预算警报的 FinOps 团队来说,扩展后的指标能够反映当前模型的实际行为——推理和缓存消耗了大量早期指标未能捕捉的词元预算。
在资源发现方面,Azure API Center 数据平面 MCP 服务器已正式发布(GA)"。它可作为企业统一的资源发现端点:智能体和开发者工具可以通过单个 MCP 连接访问已注册的 MCP 服务器、工具、API、智能体及各类 AI 资产。当团队在 API Center 注册新的 MCP 服务器时,所有已连接的智能体都能自动发现它,无需逐个客户端重新配置。
APIM 现在还支持将已有的 REST API 暴露为 MCP 服务器",这意味着早于智能体时代的企业 API 无需重构即可被智能体调用。结合本次在 Build 大会上正式发布的 Logic Apps MCP 服务器",微软正在构建两条并行路径,帮助企业对接智能体:一条通过 API 网关层(APIM),另一条通过集成平台层(Logic Apps)。
对于正在评估 AI 网关方案的团队来说,行业竞争态势具有重要参考意义。亚马逊云科技的 Bedrock Guardrails 用于内容过滤和模型访问控制,但暂无产品可对标 APIM 的多厂商统一模型 API,以及针对 MCP、A2A 的全维度内容安全能力。谷歌的 Apigee 已添加一些 AI 网关功能,但尚未达到 APIM 现在覆盖的协议广度。Cloudflare 的 AI Gateway 侧重成本管控与缓存能力,而非多协议治理。APIM 的核心思路是:API 网关(而非全新品类产品)才是承载 AI 工作负载的天然控制平面。
AI 网关能力在所有 APIM 层级中均可用。统一模型 API 处于公开预览阶段。针对 MCP、A2A 的内容安全功能、升级后的词元指标以及 API Center MCP 服务器已正式发布(GA)。AI Gateway 实验室"提供 30 多个实操 Jupyter Notebook,包含分步说明和可部署的 Bicep 模板。
查看英文原文:https://www.infoq.com/news/2026/06/azure-apim-ai-gateway-build/"
随着大语言模型的发展,数据智能体已成为推动中国企业革新的关键力量。因此,采用这一技术对于实现代理型D&A至关重要。数据智能体可执行数据管理、数据准备以及数据分析等一系列任务,其采用程度与技术自治水平将会不断提升。
数据分析将成为当前市场中自治程度较高、且最主要的使用场景,尽管距离完全自治仍有较大差距。这一技术目前的发展程度已超越简单的“对话式界面”,迈向能够主动规划任务、执行分析、调用工具并持续学习的智能体。这有助于提升生产力,并推动成本节约或收入增长。
通过利用企业知识与基于大语言模型(LLM)的推理,数据智能体可以自动化复杂的D&A工作流,以面向任务的自主服务替代部分传统工作。D&A领导者必须探索这一趋势,明确适用范围并学习新技能,为未来的采用做好准备。为此,Gartner给出以下三点建议:
在对数据智能体进行设计和分类时,应设定清晰的范围、类别和功能,以界定决策范围,降低运营风险。
定义数据智能体工作流,并在其中设置强制性的人类审核环节,例如执行前后的评估与反馈循环,以留下可审计的痕迹。
优先将数据智能体部署在数据准备度和业务价值较高的领域,例如财务自动化或客户服务优化,这些领域已有成熟案例可供参考。
数据智能体代表着超越传统数据与分析实践的下一进化阶段,有望吸收大量常规报告与汇总数据表的使用需求,并为企业机构的数据环境注入更高的智能化、自主性与可组合性。Gartner提出以下三点预测:
到2028年,60%的现有数据汇总表将被生成式AI驱动的叙事与可视化功能所取代。
到2027年,70%在生产环境中的数据智能体基于开源LLM构建,并成功部署RAG、语义层、领域上下文工程与专业技能。
在企业AI组合中纳入中国LLM和多模态模型的全球企业占比将从2025年的5%上升至2027年的50%。
中国的数据智能体是一种数据和分析(D&A)实践(或设计框架),由LLM驱动,具备知识理解、自动规划和自我反思能力,能够自主执行广泛的D&A任务。
数据智能体的兴起标志着走向D&A任务民主化的关键一步。尽管已经取得了显著的进步并拥有广阔的前景,“数据智能体”一词在学术界和工业界的使用仍未统一。如果没有一个通用的分类法来按范围和职责区分数据智能体,可能会导致用户期望不匹配和问责风险,并进一步打击市场信心,最终减缓这一新兴技术的采用。应对这些挑战需要为数据智能体分类建立清晰、通用的语言,主要侧重于在数据管理、数据准备和数据分析三方面相互关联的任务。
与一般的AI智能体类似,数据智能体通过解释用户问题、将其分类为子任务并评估所需工具来进行规划。在执行过程中,智能体不断进行推理以改进其策略,直至任务完成,并自主决定何时终止任务。此外,它还模拟类似人类的记忆,通过执行特定的操作(例如与外部环境交互或调用工具)来存储信息。这些行动受其规划和记忆能力的指引。下列关键数据智能体模块构成了端到端的数据智能体工作流(见图1)。
图1:数据智能体工作流(示例)
感知:感知模块是数据智能体的“眼睛和耳朵”。在运行时,它结合环境、知识和工具的上下文来解释业务问题和目标,并通过离线微调或业务提示模板(或智能体技能)进行对齐。
规划:规划模块充当数据智能体的“战略大脑”。基于对问题和目标的解释,它将制定策略并生成涉及决策的多步计划。每个决策可能需要进一步探索推理/规划或调用工具。规划应具有自适应性,并在出现新证据或假设被打破时允许重新规划。
执行:执行模块是数据智能体的“运动皮层和肌肉”。它指导计划执行、分配特定领域的子智能体、管理运营物流,并为复杂任务编排多个子智能体。
工具调用:工具调用模块充当“使用工具的双手”。这代表了数据智能体通过外部资源实现扩展的能力。
记忆:记忆模块是智能体的“海马体和长期记忆”。这是经验存储系统,包括长期记忆(如特定领域和环境知识)和短期记忆(如用户上下文和反思上下文)。
反思:反思模块类似于人类的“内省”。不断改进智能体使其变得更聪明至关重要。自我完善的实现依赖于自我反思、强化学习和奖励模型技术。
作者: Gartner 高级首席分析师 费天祺
Gartner 管理副总裁 孙鑫
Gartner 高级研究总监 顾星宇
Gartner 高级研究总监 方琦
过去一年,AI 的主战场已悄然发生位移:
它正从单一功能的交付,走向多 Agent 协作的生态网络重组;
从提升个人生产力,走向重构企业底层的运行范式。
今天的决策者,不仅在管理一个产品,更在重构一家 AI-Native 的企业。正是在这个跨越传统的节点上,我们把全球产品经理大会正式更名为「奇点智能产品大会」——不是为了新鲜,而是为了更准确地命名时代。
大会官网:https://pm-summit.org/
全球产品经理大会正式更名为「奇点智能产品大会」
我们把“奇点”放进名字里,是因为越来越多的产品人正在共同经历一个清晰的拐点:AI 不再只是效率插件,而是正成为产品的底座能力;不再只是一次性功能,而是贯穿数据、系统、组织与商业模式的长期工程。“奇点”不仅代表着技术指数级跃迁的临界点,更寓意着新物种、新秩序的诞生。更名后的奇点智能产品大会,将摆脱传统产品管理的框架束缚,更加专注于 AI 原生时代的硬核实践、商业闭环与人机协同探索。7 月 17-18 日,2026 奇点智能产品大会将在北京金隅喜来登大酒店正式召开。在这里,我们将探讨如何把智能化转化为真正可落地的产品价值,关注更具体、更硬核、更可复用的三件事:
·AI 原生产品怎么设计、怎么交付;
·Agent 时代的软件形态怎么重塑;
·面向真实业务的增长与商业模式怎么跑通。
首批嘉宾重磅官宣
在这场深刻的变革中,总有一些探索者走在最前线。他们或在一线公开构建颠覆性的 AI 工具,或在企业内部推动生产力流程的重组。他们带来的不是纸上谈兵的理论,而是历经市场检验的实战心法。以下为 2026 奇点智能产品大会首批官宣演讲嘉宾。
2026 奇点智能产品大会首批官宣演讲嘉宾
议题征集,期待你的独特视角
如果你也在一线做 AI 产品——不管是 Agent、企业级智能、AI 原生工作流,还是多模态、具身智能与硬件——我们都欢迎你把真实问题与实战案例带到现场。奇点智能产品大会的舞台,想留给那些“做出来的人”。
我们在征集什么?
我们寻找这样的议题:拒绝空泛的概念,多一些代码与产品结合的真诚复盘、失败教训的沉淀、以及可量化的核心数据。
讲师权益: 获得大会 VIP 门票及专属礼遇、与全球顶尖 AI 产品人深度社交、个人及品牌影响力的广泛传播。
议题 & 嘉宾推荐/自荐方式:
手机/微信: 17717518733
电子邮箱: hemiao@csdn.net
邮件主题: 2026 PM Summit 议题申请-姓名-公司-议题方向
你可以提交:
·一个可复用的方法论(框架/流程/评测体系/飞轮);
·一个可验证的实战案例(指标、成本、效果、踩坑与修复);
·一个尚未有标准答案但足够真实的难题。
参会有礼:与时代同行者共创
为感谢陪伴大会一同成长的高质量读者与同行者,我们特别推出“共创未来”限时福利:
·分享有礼: 转发本文至朋友圈(不设分组),截图发送至后台,即可免费获得《AI 时代产品经理进化指南及往届大会珍贵演讲 PPT 合集》一份。
·推荐/自荐讲师礼遇: 成功推荐讲师并最终确认议题入选的读者,将直接获赠价值 5999 元的大会 VIP 线下通票一张。
·首批早鸟票: 目前大会早鸟票通道已正式开启,扫码即刻锁定北京金隅喜来登大酒店的现场席位,与千位同行者共同见证奇点降临。
虽然 AI 让很多事情变快了,但产品的本质反而更加清晰:你交付的不是“功能”,而是一个能持续产生价值的系统。7 月 17-18 日,我们在「奇点智能产品大会」现场,等你把答案讲出来。
2026 年的企业 AI 市场,正在经历一场悄无声息的叙事转换。
两年前,几乎所有科技峰会的主角都是大模型:参数多少亿、上下文窗口多长、benchmark 排第几。企业关心的问题是 AI 能不能做。到了 2026 年,这个问题已经基本有了答案:能,而且做得比想象中更好。但当技术可行性被验证之后,真正让 CIO 和 CDO 夜不能寐的问题变成了另一个:“AI 做错了,谁负责?”
当智能体开始自主查询数据库、调用 API、生成报告、触发审批,甚至直接修改业务数据时,它就不再是一个辅助工具,而是一个具备行动能力的数字员工。而数字员工犯错,代价可能比人类员工更高,因为它可以以毫秒级的速度,把错误放大到整个组织。
正是在这个背景下,Snowflake Summit 2026 的 Platform Keynote 显得意味深长。Snowflake 联创 Benoit Dageville 和产品执行副总裁 Christian Kleinerman 站在台上,花了整整一个小时介绍新产品、新架构、新性能指标,但贯穿其中的一条主线非常清楚:当 Agent 开始进入企业流程,平台必须提供足够可信的运行环境。
Benoit Dageville 在现场的一句话,几乎可以概括 Snowflake 对 Agentic AI 的底层判断:“最好的 Agent 平台,必须建立在最好的数据平台之上。” 这句话也解释了为什么 Snowflake 反复强调数据、上下文、权限、治理和可审计性:当 Agent 开始行动,企业 AI 的可信度,最终仍然要回到数据平台本身。
从 CoCo 的改名与桌面化,到 Snowflake CoWork 的正式登场;从智能体身份(Agent Identity)和数据流转策略(Data Movement Policy)的推出,到语义上下文(Horizon Context)的增强,这些更新背后其实有一条更清晰的主线:当 Agent 开始进入企业流程,平台必须同时解决数据、上下文、权限、治理和可审计性问题。
也正是在这样的现场语境下,InfoQ 中国奇遇团在 Snowflake Summit 26 的观察,不再只是记录一场产品发布,而是在追问一个更现实的问题:当 Agent 真的进入企业流程,中国企业该如何理解这场从“能力验证”到“可信运行”的转变?更多现场判断与一线讨论,欢迎观看「奇遇旧金山」系列 Vlog"。
CoCo 与 CoWork 双引擎
Platform Keynote 上最有趣的细节之一,是 Christian Kleinerman 宣布的两个改名决定。
第一个是 Cortex Code 正式更名为 Snowflake CoCo,有趣的是这个名字不是官方起的,是用户叫出来的。”当我们推出 Cortex Code 后,很快,很多人开始说:‘哦,CoCo。’” Christian 在台上笑着说,“Denise 说,我们干脆就别再叫 Cortex Code 了,直接叫 CoCo 怎么样?”
一个多少带着“被用户叫出来”意味的名字,本身就说明 CoCo 已经形成了足够高的使用辨识度。而更让市场注意的是,CoCo 的演进速度很快:它从命令行和 Snowsight 起步,六个月内扩展到 Airflow、dbt、Spark、MCP、ACP,再到 SDK 和 Agent Teams。Summit 上,Snowflake 又宣布了 Cloud Agents 即将 GA、本地开发沙箱、自动化能力、自主智能体、技能目录,以及 CoCo Desktop GA。
过去,Snowflake 最核心的交互方式仍然围绕 SQL 和数据开发展开。用户往往仍需要理解数据库、表结构和查询逻辑,才能更充分地使用平台能力。而 CoCo 的出现,改变了这一层交互逻辑。它让开发者可以用自然语言与整个数据平台对话。更值得关注的是划选提问(Snap and Ask)功能:演示者直接拖拽选中一张图表的某个区域,点击 explain,CoCo 就能基于视觉上下文给出分析。这种交互方式已经不只是“使用数据库”,而更像是在与数据协作。
CoCo 改变的是开发者与数据平台的交互方式,而 Snowflake CoWork 指向的,则是更广泛的业务人群:当 AI 不只帮助人写代码、查数据,而是进入日常工作流,它与人的关系也需要被重新定义。
Snowflake Intelligence 最初被定位为企业员工的 AI 工作助手,但 Christian 坦承:“它的范围已经远远超出了我们最初的设想。它正在改变我们的工作方式。”于是,Snowflake Intelligence 被重新命名为 Snowflake CoWork。
这个名字的改动意味深长。Intelligence 强调的是智能能力,而 CoWork 强调的是协作关系。AI 不再只是工具,而开始成为企业工作流中的协作者。
Christian 对 CoWork 的愿景描述得极为具象:“从 CEO 到每一位一线员工。如果你喜欢 F1,想象每个人都有自己的维修团队。如果你喜欢钢铁侠,每个人都有自己的 Jarvis。”这不是在卖功能,而是在卖一种工作方式的想象。未来的企业员工,每个人背后都有一个 AI 团队,随时待命。
为了让这个愿景落地,Summit 上宣布了一系列 CoWork 的重大更新。个人工作引擎(Personal Work Engine)让组织中的用户不必再手动选择用哪个 Agent,而是拥有一个个人 Agent,自动执行多 Agent 编排,根据请求类型路由到不同的能力模块。用户记忆(User Memory)让 Agent 学习用户的偏好、习惯和工作模式,越用越懂。个人技能(Personal Skills)和个人 MCP 连接器让每个用户可以连接自己的业务系统。定时任务(Scheduled Tasks)则让用户可以说“这个分析我喜欢,你能每周或每月发给我一次吗?”
更值得关注的是工作产物(Artifacts)的演进。CoWork 中创建的不再是静态报告,而是实时数据的受治理视图,可以被共享、被协作、被持续更新的可信数据视图。
这意味着 CoCo 和 CoWork 正在形成一条闭环:开发者在 CoCo 中构建和认证 AI 应用,业务用户在 CoWork 中消费和协作,两者共享同一套治理框架和安全策略。
要让 CoCo 和 CoWork 真正发挥作用,Snowflake 还需要补上另一层能力:上下文。
Cortex Sense 承担的正是这个角色。它会从 Snowflake 已有的数据和活动中构建信号,自动增强 Agent,让 CoCo 和 CoWork 在回答问题、生成代码或执行任务时更理解企业环境。Christian 在现场提到,在一个评估集中,搭配 Cortex Sense 后,CoCo 和 CoWork 的开箱准确率从 24% 提升到 83%。
Natoma 的加入,则把这套能力继续延伸到更多业务系统。借助超过 100 个业务系统连接能力,Snowflake 可以让 CoCo 和 CoWork 更自然地触达企业日常使用的应用。也正是在这个意义上,CoCo 和 CoWork 更接近 Christian 所说的 control planes:它们不是单纯的数据引擎,而是连接数据、模型和应用的工作入口,让 AI 的分析、协作和行动运行在同一套治理框架下。
三星电子执行副总裁 Jung Suh 在台上分享了基于 Snowflake CoWork 构建的 shopper’s insight action agent,也就是 SIA。Galaxy S26 发布时,SIA 不只是检索数据,而是在数据之上推理和行动:比较发布表现、规划步骤、调和信号,并给出综合答案。过去需要数小时的分析工作,现在可以在几秒内完成。
更关键的是,Samsung 全球大约有 1,000 名高管、销售和营销人员正在使用这个 Agent。他们不是数据科学家,而是直接负责区域目标、促销策略和产品路线图的业务领导。Jung Suh 提到,过去这些人完全依赖分析师来回答问题,而现在,数据团队不再是唯一入口,每位业务领导都可以在自己的工作流中获得分析能力。
这正是 CoWork 想推动的变化:不是让业务人员多一个问答工具,而是把原本集中在数据团队手中的分析能力,嵌入更广泛的业务决策现场。
AI 时代没有“慢数据”
Snowflake 过去最擅长的是分析已经发生的业务,而此次发布的 Datastream 指向的是另一个方向:让平台更接近正在发生的业务。
Snowflake 的崛起,很大程度上建立在"批处理"哲学之上。它将计算与存储解耦,用弹性扩展的方式处理海量结构化数据,彻底击败了传统数据仓库。但在过去,流处理并不是 Snowflake 的强项,企业如果需要实时数据,往往会额外部署 Kafka 等系统来补充。
现在,Snowflake 亲自下场做流了。而且不是做一个更好的连接器,而是从头构建一个原生流服务,兼容 Kafka Wire 协议,支持零拷贝流式处理,能够以亚秒级延迟将数据流入和流出 Snowflake。
为什么?因为 AI 时代的数据消费模式,已经从“T+1 报表”变成了“实时决策”。
当 AI 智能体开始自主监控业务信号、规划行动步骤、触发业务流程时,延迟就变成了商业生死线。智能体不可能等批处理任务跑完再做决策,它需要的是持续流动的数据血脉。
在 Agent 时代,没有"慢数据"的生存空间。更重要的是,Snowflake 将其以"真正的 Snowflake 风格"实现,存储与计算分离、零拷贝、亚秒级延迟,这意味着它试图把流处理也纳入自己的经济模型和治理框架之内。
值得一并关注的是智能体搜索(Agentic Search)的推出。它不会做传统 RAG 那种"给你 Top-K 结果"的模糊匹配,而是利用 AI 函数从非结构化数据中提取信息,提取为结构化信息,运行精确的分析查询,再返回基于非结构化内容的精确分析结果。这意味着,企业过去分散在文档、邮件、合同中的"暗数据",现在可以被智能体直接调用、解析、计算,而且结果精确到可以支撑业务决策。
安德玛的首席数据与 AI 官 Patrick Duroseau 在视频分享中印证了这一趋势:"我们面临的最大挑战是数据是非结构化的,而且归因不像现在这样一致。为了找到这些洞察,你真的必须对数据做大量人工操作。"使用 Snowflake 之后,“我们更容易把数据带入平台。我们拥有许多能力,可以支持传统 BI、高级分析,也可以在生态中共享数据,并且时间成本只是过去的一小部分。”
这正好解释了为什么 Snowflake 要反复强调"all data"——结构化、半结构化、非结构化,甚至是实时流数据,全部纳入同一个治理模型。在 Agent 时代,数据平台的边界正在被重新定义:它不再只是存数据的地方,而是让智能体能够理解和行动的企业记忆中枢。
从“管数据”到“管行为”
如果说 CoCo、CoWork 和性能优化是 Snowflake 在"能力层"的布局,那么 Summit 上关于治理和信任的密集发布,则是它在规则层的深层设计。
Christian 在台上非常直接地表达了 Snowflake 的立场:“在智能体时代,我们希望确保大家能够保护自己的 Agent,并拥有多层防护。”
这句话听起来像是常规的安全表态,但结合随后发布的一系列功能,你会发现 Snowflake 的治理逻辑正在发生一次根本性的升维——从"管理静态数据"转向"管理动态智能体行为"。
首先是智能体身份(Agent Identity)。Snowflake 推出了智能体身份的概念,让你可以知道某段代码或某项活动是否发生在 Agent 上下文下。在脱敏策略或行级策略中,你可以针对 Agent 上下文设置不同的可见性权限。这意味着,同一个数据库表,人类查询和智能体查询可以被施加不同的安全策略。
其次是数据流转策略(Data Movement Policies)。你可以规定带有某个标签的数据不得移动到 stage,也不得通过 Snowsight UI 下载。在 keynote 的 demo 中,当一名 Tour Ops 员工试图让 CoWork 导出 VIP 客户数据到外部 stage 时,数据流转策略直接阻止了这次数据外泄——即使智能体本身有能力查看那张表。
第三是 Horizon AI 护栏,防止提示注入和越狱攻击;多方审批(multi-party approvals),要求高度敏感操作必须有两个管理员同意;以及信任中心(Trust Center)中的 AI 安全巡检和检测包,持续监控异常数据传输。
这些能力单独看是安全特性,放在一起,则指向 Snowflake 对 Agent 治理边界的重新定义:在 Snowflake 的设想中,未来的企业数据平台不仅要回答"谁能访问什么数据",还要回答"智能体在什么情况下可以做什么操作"“AI 的行为如何被审计和回溯”“当智能体犯错时,责任边界在哪里”。
汤森路透首席数据官 Caitlin Halferty 在台上说了一句点睛的话:"有些人认为治理是一种约束,是会拖慢你的东西。但对我们来说,治理是一个赋能者。"她解释道,Thomson Reuters 按照受托级标准(fiduciary-grade standard)构建产品。这意味着内容、数据隐私、安全、透明度和可验证性,全部达到受信托责任约束的最高标准。他们的旗舰 AI 能力 CoCounsel 每天有超过 100 万专业人士使用,而在财务和业务部门中有超过 15,000 名内部用户每天使用语义智能进行最关键的业务和财务决策。"我们已经从试点走向生产环境,"Caitlin 强调,“每一个 AI 能力在进入市场之前,都会经过负责任 AI 的流程。”
这句话精准地概括了 Snowflake 的治理哲学。在 Agent 时代,治理不再是合规部门的"拦路虎",而是业务创新的"通行证"。没有治理,企业就不敢把 AI 放进生产环境;没有生产环境,AI 就永远只是演示。
这种治理升维还有一个容易被忽略的技术支撑:语义上下文(Horizon Context)。Christian 解释说,仅有智能是不够的,很多时候真正缺少的是上下文。语义上下文作为 Horizon Catalog 的组成部分,帮助收集信号、丰富这些信号,并将它们提供给 CoCo、CoWork 或 Cortex Agent。通过语义视图和元数据连接器,Snowflake 试图让 AI 不仅"能访问数据",而且"能理解数据的业务含义"。这恰恰是智能体从"工具"升级为"协作者"的关键一跃,只有当智能体理解"这张表里的收入是毛利还是净利",它给出的答案才是可信的。
与此同时,意图驱动治理(intent-driven governance)的提出降低了治理操作的技术门槛,也让治理更容易进入实际业务场景,而不是只停留在安全团队后台。企业管理者不需要再写复杂的策略脚本,只需要用自然语言表达自己的意图——比如"把我的数据库中所有个人敏感信息找出来,并确保它受到保护"——系统就会自动触发分类、找出个人敏感信息、创建正确的策略,并持续监控。治理的民主化,意味着它不再是少数安全专家的专利,而是每个业务负责人都可以直接施加的控制力。
越开放,越不可或缺
在 Summit 上,Snowflake 展示了它在开放方向上的大量投入:从 Apache Iceberg v3 的广泛实现,到将 Apache Polaris 的 Iceberg Catalog interfaces 纳入 Horizon Catalog;从牵头创建 Open Semantic Interchange Group,到 reshare data 的 GA,再到 open sharing 进入 public preview,Snowflake 试图传递一个明确态度:它不希望自己被看作一个封闭的数据平台。
这种表态并不只是姿态问题。企业在进入 AI 深水区之后,对供应商锁定的警惕会更强。Agent 天然需要跨系统行动:数据可能在不同平台,业务流程可能在不同 SaaS 应用,模型也可能来自不同厂商。一个平台如果不能证明自己足够开放,就很难成为企业 AI 的长期底座。
Open sharing 的意义正在这里。借助 Iceberg 和 Iceberg REST Catalog,Snowflake 可以把数据共享给非 Snowflake 用户,让还没有使用 Snowflake 的组织也能成为数据消费者。站在企业客户角度,这降低了跨组织协作门槛;站在 Snowflake 角度,它也让平台更容易进入更多数据交换和协作关系中。
Multi-party collaboration 则把这种协作进一步推向复杂场景。多个参与方可以在同一个安全环境中协作,不同角色拥有不同权限:有人贡献数据,有人负责分析。Christian Kleinerman 在现场提到,Netflix 正在用这类 collaboration technology 构建与多个合作伙伴协作的 team rooms。这个案例说明,Snowflake 想做的不只是数据共享,而是让多方数据合作在可控环境里发生。
开放并不意味着 Snowflake 放弃平台中心位置。相反,它正在通过更深的生态协同,把自己放到更多数据和 AI 工作流的交汇处。
在业务系统侧,Snowflake 正在扩大与 Salesforce、Workday、SAP、IBM mainframe/Db2 data、Veeva 等系统和数据源的连接合作。query across 能力则让 Snowflake CoWork 可以在可能位于 Redshift、Postgres 或其他数据源中的数据上,提供 Snowflake 和 Snowflake AI 的能力。也就是说,Snowflake 一方面允许数据以更开放的方式流动,另一方面也在让自己的 AI、治理和协作能力进入更多外部系统。
这背后体现的是一种“开放底座、深度协同”的生态策略。
它的逻辑是:数据格式和访问协议需要足够开放,企业才会放心把关键数据和流程接入平台;但当 Agent 真正进入业务流程,价值就不只来自数据本身,还来自围绕数据不断沉淀的上下文、权限体系、行为历史和业务语义。
换句话说,数据可以保持开放流动,但围绕数据形成的智能协作经验,会逐渐沉淀为新的平台价值。当销售、客服、财务等不同 Agent 都在 Snowflake 的治理框架下运行了数月甚至数年之后,迁移成本就不再是数据迁移的成本,而是“智能迁移”的成本。
信任竞争刚刚开始
2026 年,企业 AI 的问题正在改写。大模型已经证明了“能不能做”,但企业真正要决定的是“敢不敢用”。当 Agent 开始查询数据、调用系统、影响业务流程,可信度就不再是安全团队的后台议题,而是 AI 能否进入生产环境的前提。
Christian 在 Keynote 最后说,Snowflake 正从 “can we” 的时代走向 “shall we” 的时代。它对应的正是这个转变:企业不再只需要能力展示,而需要一套能承接责任的运行体系。
Snowflake 此次展示的性能、治理、上下文、开放生态和 Agent 行为管理,都在指向同一个方向:把 AI 的复杂性收进底层,把可信度带到业务前台。企业 AI 的下一场竞争,也会从这里真正开始。
更多 Snowflake Summit 26 精彩内容,欢迎前往大会专区"查看。
你的公司最近上线了一个内部全能搜索系统,这是一个单体系统,采用检索增强生成(RAG)"技术构建,可检索公司的待办事项、设计文档、发布文档、运维手册和纠错文档(COE")。工程师、产品经理和经理通过基于大语言模型的聊天界面进行查询,各团队还将其封装为 MCP 工具,让他们的 AI 编程助手可以直接获取上下文。
然后,生产支持组的一名值班人员输入:”在生产环境中启用 payment_v2_enforce 功能标志的运维手册“,聊天助手却提示应禁用该功能。在系统内部,文档根据嵌入相似度进行排名。
对于嵌入模型来说,这两份运维手册看起来几乎完全相同。它们有相同的功能标志名称、相同的服务、相同的词汇和相似的上下文。但值班工程师看不到这个排名,他们看到的是聊天助手根据检索器返回的前 K 条内容生成的回答(有时正确的运维手册甚至不在前 K 个结果里)。这类回答轻则信息失真,重则看似笃定却完全错误。
如果你构建过基于嵌入"的搜索系统,对这类情况想必并不陌生。系统能把握整体方向,却忽略了关键的细节信息。
上述查询需要两样东西:对”功能标志运维手册“的语义理解,以及对操作(启用与禁用)的精确匹配。向量搜索"只处理了前者。
这并非嵌入模型的缺陷,而是向量相似度的固有特性。嵌入机制会检索出和查询内容相似的结果,而非完全匹配的内容。由于检索将前 K 个结果作为上下文输入大语言模型,排名与召回同样重要。
即便正确答案在前 K 条结果里,若错误答案排序更靠前,依然无法解决问题。修复方案并不是要替换嵌入技术,而是将其与传统文本关键词匹配相结合,让概念相关性和精准术语匹配共同作用于最终的排序。
纯向量检索 RAG 流程的短板
想要理解为什么会出现这个问题,不妨放眼审视一下完整的流程。如图 1 所示,RAG 流程共分为三个阶段。
图1. 典型的 RAG 管道有三个阶段:分块、检索和生成。(来源:作者创建)
图 1 中的元素定义如下:
分块:将原始语料库拆分为可用于索引的单元。检索:接收用户查询,在分块内容中检索并返回相关性最高的前 K 个块。生成:将这些分块内容作为上下文输入大语言模型,由模型生成答案。
假设第一、第三阶段均正常运行:文档按合理边界完成拆分,大语言模型根据提供的上下文生成答案,且不会产生幻觉。问题出在前文提及的检索阶段。检索器先对查询做嵌入处理,再将其与已建立索引的文档向量比对,返回嵌入空间距离最近的文档。嵌入空间距离相近,表示语义相似,而非内容完全一致。针对同一功能标志的两份运维手册,一份说明启用操作、一份说明禁用操作,二者在嵌入空间中距离极近。两份文本仅个别词汇存在差异,嵌入模型会为这类高度相似的文本生成近乎一致的向量,导致检索器难以精准区分。因此,当用户查询启用功能标志的运维手册时,禁用相关的手册有时反而距离更近,检索器会以同等置信度推送这份错误文档。这便是问题所在:依靠同一向量空间与评分机制,最终排在前面的却是错误的文档。
问题在于嵌入的本质是近似计算
像 BERT" 这样的嵌入模型将文本转换为固定维度的数值向量,并捕捉文本的语义信息。语义相似的文本生成相似的向量。”功能标志“、”终止开关“、”发布门“和”配置切换“在向量空间中紧密聚集。这种聚类在用户检索相关概念时能发挥很大作用,但当用户需要查找精确实体、特定功能标志名称、特定错误代码或特定部署版本时,问题就转到了检索精度层面。
相似的表现同样存在于各类不同失效模式中。当某人搜索 ERR_PAYMENT_GATEWAY_TIMEOUT 时,相关代码如 ERR_PAYMENT_GATEWAY_REJECTED 和 ERR_PAYMENT_GATEWAY_UNAUTHORIZED 等相关代码最终都会与查询向量趋近,因为它们有相同的 ERR_PAYMENT_GATEWAY 前缀并出现在同类故障排查文档中。区分它们尾部词汇的权重占比很低。嵌入模型的行为完全符合设计初衷,它的作用是检索相似内容,而非精准匹配完全一致的内容。当区分特征在文本中占比过低时,嵌入会抹平这种区别。
图 2 展示了嵌入空间的特征:语义相近的内容会聚集在一起。在同一个聚类内部,想要区分不同具体实体(比如介绍功能标志启用、禁用操作的运维手册)就会变得困难。而混合搜索,正是为了解决这类精度不足的问题。
图 2. 语义相似的项目聚集在一起。并非每个查询都有相同的问题。(来源:作者创建)
根据检索方法的适用程度,搜索查询可以被分为三种类型。
语义查询"
用户的提问“当一个区域离线时,我们的协议是什么?”是概念类查询。标题为“灾难恢复架构”、“主主复制策略”、“故障转移运维手册”的文档,即便和查询没有共用词汇,也理应获得较高排名。嵌入模型能很好地应对这类场景,因为它捕捉的是语义,而非单纯匹配字面词汇。
精确匹配查询"
这类查询在信息检索文献中也称为词汇查询。用户将堆栈跟踪或日志中的错误代码粘贴到搜索栏中,如 ERR_PAYMENT_GATEWAY_TIMEOUT,此时他们明确知晓自己要查找的标识。对于这些查询,语义相似性反而不是用户想要的。向量嵌入可能会推送语义相近但标识不同的文档(如包含 ERR_PAYMENT_GATEWAY_REJECTED 而非 TIMEOUT 的运维手册),影响了检索效果。关键词搜索则能高效、准确地处理这类查询。
混合查询"
用户搜索 “v3.2 部署的回滚运维手册”时,既需要语义理解(即部署回滚相关的运维手册),也需要对区分标识做精确匹配:根据 “v3.2” 筛选对应版本,根据 “rollback” 区分 “rollout”。用户搜索 “Outlook 2019 同步错误 0x80004005 故障排除”,则需要对问题症状做语义匹配,同时精确匹配版本号和错误代码。这类查询同时依赖两种能力。结合我在生产级 RAG 系统的实践经验,这类查询占绝大多数。本文后续内容将围绕这类查询的处理方案展开。
BM25 为嵌入近似语义提供精度
向量搜索需要一个搭档,这个搭档就是BM25 —— 经典信息检索领域核心的概率排名函数。它是 Elasticsearch、OpenSearch 和大多数词汇搜索引擎的默认评分器,也是三十多年来占据主导地位的关键词搜索算法。在向量搜索效果不佳的场景中,它总能精准发挥作用。它基于概率信息检索理论,提供了三个直接解决精确匹配问题的内置机制。
逆文档频率(IDF)"用于衡量一个词在整个语料库中的稀有程度。常见词如 “service” 或 “deployment” 权重较低,而稀有的区分性标记如 “v3.2”、“ERR_PAYMENT_GATEWAY_TIMEOUT” 或 “payment_v2_enforce” 权重较高。这也是 BM25 在精确匹配查询中优于嵌入技术的原因。能够区分不同文档的稀有标识在 BM25 中会被赋予最高权重。
词频(TF)饱和"用于控制重复术语带来的影响。术语的首次出现会显著影响得分,后续重复出现带来的增益则逐步递减。得分会趋近于一个上限,而非线性增长。这一特性能够避免文档依靠关键词堆砌来刻意操纵排名。
长度归一化"用于解决文本检索中的另一种偏差。较长的文档仅仅因为包含更多词汇而倾向于获得更高分数,匹配查询术语的概率也更高。长度归一化通过在计算相关性得分时综合考虑文档长度来纠正这个问题,不仅会统计术语出现的次数,还会考虑相对于文档长度的频率。这一点在具有可变长度分块的 RAG 系统中尤为重要,如果没有这种调整,较大的分块始终会胜过较小的分块。
基于倒数排名融合的混合搜索
如图 3 所示,混合检索会并行执行 BM25 检索与向量检索,通过 RRF 融合两者的排序列表;在将前 K 个文本块输入大语言模型前,还可选用交叉编码器做二次重排序。
图 3. 混合检索(来源:作者创建)
现在我们有两个具有互补优势的检索器:向量搜索和 BM25。向量搜索捕捉语义信息,而 BM25 进行精准的词项匹配。每个产生自己的排名列表,要进行混合查询,这两个列表需要合并为一个。
合并列表是一个难点。向量余弦相似度介于 -1 和 1 之间,而 BM25 得分没有上下限,很难将它们归一化到同一量纲。权重适配会随查询内容变化:对于某一个查询,BM25 的合适权重可能是 0.7,但对于另一个可能是 0.3。在生产环境中为每个查询校准权重是不切实际的,而这正是倒数排名融合(RRF)"发挥作用的地方。
深入解析 RRF 如何实现分数融合
RRF 直接舍弃两个检索器的原始分数,绕过了归一化难题。它仅基于排名位置完成运算:
RRF_Score(d) = Σ 1 / (k + rank_r(d))
常数 k 通常为 60(Cormack、Clarke 和 Buettcher 2009"),用于平滑不同排名位置的权重贡献。排名第 1 的文档贡献 1/61 ≈ 0.0164。排名第 10 的文档贡献 1/70 ≈ 0.0143。在检索器的前 K 个中缺失的文档贡献为 0。
该机制原理十分简单:同时在两个检索结果中排名靠前的文档,会因叠加得到非零分值,最终获得更高融合得分。即便某个文档在单个检索器中排名第一,若仅被一个检索器命中,综合得分也会被压低。RRF 本质是对检索结果一致性进行加权。
下方三张表格针对语义查询、精确匹配查询、混合查询三类查询场景,逐步演示上述情况。综合来看,表格分别展示了 RRF 表现明显占优、以微弱优势保留正确结果,以及本文核心论点所聚焦的场景。
解读排名列时需注意:两个检索器均在包含数千份文档的完整语料库中检索。表格内展示的 BM25 与向量检索排名是文档在全量检索结果中的位次,而非仅针对表格里的四份文档。因此,BM25 排名 12,表示该文档在整个语料库的检索结果中位列第 12。
下文演示的三类查询均可在本地 Elasticsearch 实例中端到端完整运行。示例应用代码与数据集可在该 GitHub 示例项目"中获取。
查询:“我们的认证系统如何处理过期令牌(How Does Our Auth System Handle Expired Tokens)?”
这是一个概念性问题。对应的正确文档是名为《认证服务中的令牌刷新和过期处理》的运维手册。该文档与检索内容存在多处共用术语,包括 “token”、“expiration”/“expired”、“handling”/“handle”、“auth”,因此被 BM25 检索命中。但另一篇关联性较低的文档,因 “system” 和 “token” 两个词汇出现频次更高,最终在 BM25 排序中排在了前面。
BM25 检索到了目标文档,但置信度低于《系统令牌轮换运维手册》。后者虽然在通用术语上匹配度更高,但对应的业务操作并不相关。向量检索凭借语义层面的匹配将正确文档排在首位。RRF 算法会优先加权两个检索结果中排名均靠前的内容,因此该文档最终位列融合结果顶部。而紧随其后的两个 RRF 结果(《OAuth 流程设计文档》与《系统令牌轮换运维手册》)也都能为读取候选结果的大模型提供有效上下文信息。
精确匹配查询
查询:“ERR_PAYMENT_GATEWAY_TIMEOUT”
用户粘贴了堆栈跟踪里的错误代码。由于标识符字符串唯一且完全逐字匹配,BM25 成功检索到对应的运维手册。但向量检索效果不佳,因为查询内容除了“支付服务的错误”外几乎没有有效语义,嵌入模型难以精准区分 ERR_PAYMENT_GATEWAY_TIMEOUT 和该服务下其他同类错误码。
从逻辑合理性来看,邻近错误码对应的运维手册会出现在 BM25 检索结果中,这是因为相关手册的故障排查步骤通常会有交叉引用(例如“若出现 ERR_PAYMENT_GATEWAY_REJECTED,请参考本手册”),查询关键词恰好匹配了这类引用内容。如果没有这些交叉引用,BM25 就只会返回 TIMEOUT 对应的运维手册,邻近手册也不会出现在检索结果里。
RRF 将目标运维手册排在首位,但它与另一篇对应拒绝类错误码的手册得分差距很小,第二、第三名结果均为其他错误码对应的手册。针对这类纯标识符类查询,仅使用 BM25 检索得到的候选结果集质量反而优于混合检索。BM25 结果里的第二、第三位是明显无关的文档,大模型可直接过滤;但 RRF 排在第二、第三位的是内容相近的运维手册,容易让大模型误判用户实际提供的错误码。这也客观说明,混合检索的优势体现在整体数据分布层面,并不能对每一条查询都实现优化。
混合查询
查询:“v3.2部署的回滚运维手册(Rollback Runbook for v3.2 Deployment)”
BM25 将目标文档排在首位,原因是文本中的 “rollback”、“v3.2”、“deployment”、“runbook” 全部精准匹配。向量检索则把 v3.2 版本的发布运维手册放在第一位,这并非因为嵌入模型判定发布内容比回滚内容与查询更相关,而是该查询与两份运维手册的余弦相似度差值仅在 0.01至 0.02 之间。向量检索的这一排序结果更偏向随机噪声,不具备实际参考价值。再次运行查询或更换嵌入模型,二者的排名都可能发生颠倒。
这类因噪声导致核心操作意图无法区分的问题,正是混合检索所要解决的检索失效场景。BM25 倾向于匹配回滚相关的运维手册,打破了两项操作的排名胶着状态。RRF 会对两个检索器均位列前三的文档加权提权,最终将目标的 v3.2 版本回滚运维手册推至靠前位置。
三种查询综合分析
三种查询的整体运行逻辑是一致的。对于语义查询,向量搜索能够定位到目标文档,RRF 会将这类结果置顶,同时添加 BM25 提供的匹配特征。对于精确匹配查询,BM25 可精准召回目标文档,RRF 同样将其保留在首位,只是第二名结果相比单独使用 BM25 时干扰信息会更多。对于混合查询,两类检索器各自存在不同的检索缺陷:BM25 的首位结果正确,但第二名返回了错误版本;向量搜索的首位结果则完全匹配错误。经过 RRF 融合后,最终首位结果准确,第二名虽存在偏差但具备相关性,也是三组结果中质量最优的一组。
根据我的经验,生产环境中的查询以第三种类型为主。大多数真实世界的查询将语义意图与特定标识符、版本号、错误代码或其他需要精确匹配的标记相结合,混合检索正是针对这类查询分布设计的工程解决方案。
生产环境中的混合检索
目前业内主流的生产级 RAG 系统均普遍采用混合检索方案。Perplexity" 在 Vespa 上结合了百亿级的 URL 词法检索与向量打分,并通过交叉编码器完成多阶段重排。Glean" 则在企业搜索专属知识图谱之上叠加词法检索与稠密向量检索。二者应用场景不同,却采用了相同的架构思路。
Elasticsearch 的生产实现
Elasticsearch 和 OpenSearch 都通过检索器 API 原生支持混合检索(Elasticsearch 8.13 及以上版本率先实现,OpenSearch 紧随其后)。原生支持意味着检索融合已在搜索引擎内部单次查询中完成,无需在应用层额外做结果合并。下面的示例使用了 Elasticsearch 语法,OpenSearch 语法与之基本一致。
索引映射
你的索引需同时配置用于 BM25 检索的标准文本字段和用于向量检索的稠密向量字段:
PUT /rag_knowledge_base
{
"mappings": {
"properties": {
"title": { "type": "text" },
"content": { "type": "text", "analyzer": "standard" },
"content_vector": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "cosine"
}
}
}
}
图4. Elasticsearch 索引映射,同时定义了用于 BM25 的文本字段以及用于语义检索的 768维密集向量字段。
带 RRF 的混合查询
在单次请求中同时调用两类检索器,并完成结果融合:
POST /rag_knowledge_base/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": { "match": { "content": "rollback runbook for v3.2 deployment" } }
}
},
{
"knn": {
"field": "content_vector",
"query_vector": [0.12, -0.45, ...],
"k": 50,
"num_candidates": 100
}
}
],
"rank_constant": 60
}
}
}
图5. 使用 Elasticsearch 的 RRF 检索器进行混合检索查询,并行运行 BM25 和 kNN 搜索,并在单个请求中融合排名。
生产调优
上述的默认配置可以作为合理的参考,但生产系统几乎总是需要进一步调优。其中的三个核心参数基本决定了检索相关性与查询延迟之间的取舍关系。
排名常数(k)"
排名常数是 RRF 公式中的平滑参数,用于控制排名权重的衰减速率。排名为 r 的文档,其权重按 1/(k + r) 计入融合得分。该参数默认值为 60,适用于通用检索场景。若将数值调至 2030,会强化高排名结果的权重,当 BM25 对错误码、版本号、功能标识等内容实现精准匹配时,该设置效果更佳。若调高至 80100,排名权重曲线会趋于平缓,更倾向于选取在两类检索结果中同时出现的文档,而非仅在单一列表里排名靠前的内容。参数取值需根据业务需求选择:追求高精度则选用较小的 k 值,侧重召回率则选用较大的 k 值。
kNN 候选"
num_candidates 参数用于设定 HNSW 图遍历过程中获取前 K 个结果前需要检索的向量数量,控制近似最近邻搜索在召回率与查询延迟之间的权衡。将 k 设为 50、num_candidates 设为 100 效果较好。若发现向量搜索召回率偏低,即相关文档频繁排在前 50 名之外,可将 num_candidates 调至 200~300。该操作通常能在延迟小幅增加的前提下提升召回率,因为额外计算仅在向量索引内部完成,不会产生额外网络请求。
使用交叉编码器重新排序"
基于 RRF 的混合检索能获得优质的候选结果,而交叉编码器重排可进一步显著提升最终检索相关性。双编码器会分别为查询和文档生成嵌入向量,交叉编码器则将完整的查询-文档对输入 Transformer 进行联合处理,实现查询词与文档内容的细粒度标记交互。正是这一架构差异让交叉编码器的检索效果始终优于双编码器——它能够捕捉到独立嵌入无法识别的语义细节和关联关系。
在实践中,常规方案是先通过 RRF 筛选出 20 至 50 条候选结果,再使用 ms-marco-MiniLM-L-6-v2" 这类交叉编码器完成最终重排。交叉编码器并不适合用于首轮检索,因为它需要对每一组查询-文档对执行前向计算,耗时较长;但对小规模候选集做重排时延迟完全可控,在 GPU 环境下处理 50 条候选结果通常耗时不足 100 毫秒。在 BEIR 等主流检索基准测试中,交叉编码器的表现始终优于双编码器:大模型在跨领域查询场景下提升尤为明显,轻量模型则能在同领域场景下带来可观效果增益。对于每一点检索相关性都至关重要的生产系统而言,这一重排环节很有价值。
结论
稠密向量嵌入可解决检索的泛化问题,即便查询词与文档用词不一致,也能匹配到概念相关的内容。BM25 则解决了基于稀有、区分性标记找到精确匹配的精度问题。但二者单独使用都无法满足生产环境下 RAG 系统的需求。
向量嵌入属于近似检索,这既是它的优势,也带来了固有局限。基于 RRF 的混合搜索并非弥补模型性能短板的临时方案,而是面向同时兼容语义查询与精确匹配查询的系统,在架构层面的最优选择。
若 RAG 流程仅依靠向量嵌入完成检索,会损失检索效果。建议加入 BM25 检索,通过 RRF 融合结果,并使用交叉编码器实现重排。
查看英文原文:https://www.infoq.com/articles/vector-search-hybrid-retrieval-rag/"
过去一年,“Agent”这个词从实验室走进了生产环境。工程师们开始真正面对一个新的问题:不是“AI 能不能做到”,而是“我们能不能把它跑稳、跑对、跑出规模”。架构怎么设计?记忆怎么管理?多智能体之间如何协调?研发团队的工作方式又该如何重构?
这些,正是 AICon 2026 上海站试图回答的问题。 6 月 26 日-27 日,本次大会将以“构建可信赖、可规模化、可商业化的 Agentic 操作系统”为核心命题,集结清华、复旦等知名高校教授,以及来自阿里、腾讯、蚂蚁、字节、快手、小红书、华为、Google Cloud 等数十家头部公司的技术专家登台分享。2天、13大专题、1个动手实验室、近60场重磅议题,将深度探讨Agent工程化落地等相关话题。
上海交大助理教授 & 博士生导师刘方鑫已确认出席 “大模型推理优化"” 专题,发表题为《从数据表征到数据流编排的存算协同优化"》的主题分享。当前大模型推理受限于非均匀数据分布与同构算力架构的严重错配,导致存储冗余、精度浪费与访存瓶颈。本报告提出一套面向大模型推理的跨层协同优化方案。在数据表征层面,通过分布感知的自适应数据编码,降低信息冗余度,实现模型参数的紧凑化与硬件友好型存储;在计算范式层面,重构运算逻辑,引入基于重要性感知的高精度近似计算,以低成本的轻量运算替代非关键数据的高精度运算,有效提升硬件算力利用率;在数据流层面,通过协同编排计算与访存数据流,优化调度策略,减少缓存未命中与流水线阻塞。为构建高效的 AI 算力底座提供了系统性的演进路径。
刘方鑫,上海交通大学计算机科学与工程系助理教授、博士生导师,兼任上海期智研究院研究员。主要研究方向包括计算机体系结构与设计自动化、大模型加速与AI编译优化等。以第一或通讯作者身份在HPCA、ISCA、MICRO、ASPLOS、PPoPP等国际顶级会议和期刊上发表论文60余篇,其中CCF-A类论文40余篇,体系结构四大顶会论文20篇。主持国家自然科学基金青年项目、上海市自然科学基金面上项目,以及华为、阿里巴巴、蚂蚁金服、中兴通讯、小米、OPPO、CCF-蚂蚁科研基金、CAAI-蚂蚁科研基金等十余项企业及学会合作课题。曾入选上海交通大学首届“吴文俊人工智能博士项目”,并担任“国智班”项目导师。研究成果入选华为火花奖(2022)、中国计算机学会容错计算专委40周年代表性成果等,此外,获ACM MM 2025杰出论文奖(System Theme)、DATE 2022最佳论文奖及最佳论文提名、上海市计算机学会优秀博士论文奖(每年仅2–3人入选)、ACM上海优秀博士论文奖(每年仅2–3人入选)、上海市优秀毕业生、CCF体系结构优秀博士论文提名等奖项与荣誉。指导学生获CCFSys图计算系统设计大赛特等奖、CCFSys 2025最佳项目海报奖及第二届集成芯片与芯粒技术开源社区大赛一等奖等荣誉。
除此之外,本次大会还策划了端侧 AI、物理与数字空间智能化"、世界模型与多模态智能突破"、Agent 架构与工程化实践"、Agent 安全与可信治理"、企业级研发体系重构"、AI 原生数据工程"、AI 时代的个人提效与组织变革"等14个专题论坛,届时将有来自不同行业、不同领域、不同企业的50+资深专家在现场带来前沿技术洞察和一线实践经验。
更多详情可扫码或联系票务经理 13269078023 进行咨询。
C114讯 6月11日消息(水易)日前,施耐德电气关键电源中国中心热管理解决方案创新实验室在上海正式揭牌。作为施耐德电气深化“中国中心”战略、持续加码在华研发布局的又一标志性举措,该实验室聚焦智算时代高密度算力引发的散热与能效挑战,依托覆盖风冷、液冷及风液兼容的全栈测试平台与验证体系,旨在为下一代绿色、高效、可靠的算力基础设施提供关键技术验证与解决方案支撑。
AI时代,数据中心热管理迎来全新挑战
智算时代下,数据中心的设计与运营正在经历重大转型。传统数据中心着重于稳定性和可靠性,而智算时代下的数据中心则更关注于提升计算能力的密度和能效,以应对AI负载增加带来的更高计算需求和能效挑战,但与此同时也带来了运维的复杂性和设备兼容性等挑战。
当前,AI算力中心的服务器机架功率密度几乎均已超过50千瓦,今年施耐德电气也成功交付了功率密度达120千瓦的数据中心项目。IDC数据显示,到2027年,训练算力占比将下滑到27.4%,而推理算力占比将上升到72.6%左右。在这一背景下,有效散热以保障算力输出变得尤为关键。
“这意味着液冷已经不是一个选择题,它不再仅仅是客户用来满足能效、能耗的要求,而是从技术运营角度出发的刚需。”施耐德电气副总裁、关键电源业务中国中心负责人徐栋如是说。
与此同时,为满足人工智能对算力的海量需求,客户对智算中心上线速度提出了极致要求。徐栋介绍,目前普遍是“T+3”的交付时间,客户要求整个产品在工厂完成设计、测试、预制,到现场交付,一共三个月时间。
徐栋表示,施耐德电气关键电源中国中心热管理解决方案创新实验室的成立,正是为了破解从技术到应用的关键瓶颈。该实验室将构建起一个从全链路性能与能效优化到全场景测试的完整闭环,帮助客户有效管控技术风险、优化运营成本,以应对日益严峻的数据中心散热挑战。
全方位升级,加速面向AI的热管理创新
全新升级的热管理解决方案创新实验室在空间与能力上同步完成跨越。实验室面积将扩容50%,并已建成覆盖“风冷-液冷-风液协同”的完整测试平台,其能力具备从性能验证、场景模拟到定制方案开发的全流程赋能体系,成为业内领先的热管理综合验证与创新能力中心。
在部件验证层面,实验室部署的风冷焓差环境室可模拟-40℃至55℃的极端气候条件,可对列间、房间级、风墙、干冷器等产品进行性能及可靠性测试;同时配备兆瓦级液冷性能测试台与管路系统测试站,从一次侧冷源到二次侧负载实现全方位验证;更重要的是,实验室搭建了“风液联动系统级验证平台”,突破了传统部件测试的局限,可通过系统层级联控实现算力与温控的动态优化,并同步进行全生命周期能效与可靠性评估,从而在系统集成层面确保解决方案的能效最优与稳定性最佳。
实验室具备从冷源到IT负载的完整运行环境模拟能力,可动态模拟用户侧的负荷变化与实际工况波动,对系统匹配性及控制策略进行实证检验。通过模拟极限工况,能够前置识别潜在风险,为项目交付提供充分保障。
实验室构建了从技术孵化到场景落地的敏捷转化体系。一方面,依托系统级测试平台,可对新型部件与前沿技术理念进行深度性能验证、可靠性评估与综合价值研判,驱动技术快速迭代以保持领先优势。另一方面,基于客户定制化需求与真实场景,实验室能够快速构建高度匹配的仿真测试环境,实现温控系统与客户特定设备的预集成调试验证。不仅加速了前瞻技术的成熟进程,也可大幅压缩定制化方案在现场的部署与调试周期,显著提升从技术到交付的整体效率与确定性。
深化“中国中心”战略,向全球贡献“中国智慧”
2023年,随着关键电源业务中国中心的正式成立,施耐德电气完成了全球研发资源与中国业务体系的深度整合。这标志着“中国中心”战略迈出了里程碑式的一步,而同期建成的兆瓦级UPS实验室,更为其长期发展奠定了坚实的核心能力基础。
徐栋介绍,“中国中心”战略的核心是以中国市场的需求与中国客户的挑战来定义研发优先级。通过协同本土生态伙伴与供应链,为客户交付覆盖风冷、液冷,以及关键电源、预制化等端到端数据中心解决方案。同时,源自中国的研发成果与最佳实践也将持续融入施耐德电气全球创新网络,为全球算力基础设施的未来发展贡献“中国智慧”。
此次热管理解决方案创新实验室的成立,标志着“中国中心”战略的纵深推进。面对智算时代爆发的高密度、高能效需求,施耐德电气正以此为契机,对自身的技术能力矩阵、研发重点与产品路线图进行系统性重构,从而构建定义和支撑下一代智算基础设施的核心能力。
徐栋表示,施耐德电气将以“适配当下,兼顾未来;协同演进,适度超前;多元兼顾,精准平衡”的愿景指导产品方向。这一理念,正是为了应对AI算力在技术、能耗与场景上的高度不确定性。
徐栋表示,施耐德电气将以 “适配当下,兼顾未来;协同演进,适度超前;多元兼顾,精准平衡” 作为产品创新核心理念。这也正是为了应对AI算力在技术迭代、能耗约束与应用场景上的高度不确定性,旨在通过系统级的动态优化,为客户交付面向未来的、更完整、更绿色、更可靠的AI基础设施解决方案。具体而言,施耐德电气的创新布局聚焦四大核心方向:
第一、筑牢三相UPS市场领先地位,致力于将未来系统能效提升至98%,设计能效提升至99%以上的新高度;
第二、持续领跑AI热管理赛道,推动风冷、液冷,微模块和控制系统的深度预制化与产品化整合,为不同芯片平台提供定制化的热管理解决方案;
第三、赋能绿色能源转型,加大对风电、光伏等新能源产业的研发投入,持续迭代与之配套的UPS电源产品,支持新型电力系统的稳定运行;
第四、前瞻性布局高压直流解决方案,为未来数据中心供电架构演进进行技术储备。
从2023年投运的兆瓦级UPS实验室,到此次的热管理实验室,施耐德电气已构建起覆盖数据中心“供配电”与“温控”两大核心系统的完整前沿研发体系。二者的协同,将形成一个能够直面高密度智算场景核心挑战的系统级验证能力矩阵,为下一代智算基础设施的快速创新提供从技术验证到方案落地的一站式坚实支撑。
Press Release
From accelerating scientific discovery and advancing healthcare research to transforming public services, AI is becoming a critical driver of innovation and economic growth across the U.K. To help advance the next generation of AI infrastructure and AI-powered scientific breakthroughs, AMD, Dell Technologies and the University of Cambridge have announced plans to establish the new Sovereign AI Innovation Lab (SAIL) in the United Kingdom.
The initiative represents a major step forward in the U.K.’s ambition to build world-class AI capabilities while advancing open and interoperable AI technologies.
As nations increasingly view AI as a strategic capability, leadership will depend on access to advanced models and on the ability to combine AI, computing and scientific expertise to accelerate discovery, strengthen competitiveness and fuel economic growth.
Building on a Strong Foundation for AI Research
The announcement of SAIL follows the recent expansion of the University of Cambridge’s AI Research Resource (AIRR) that includes deployment of the Zenith AI supercomputer. Powered by 5th Gen AMD EPYC™ processors and AMD Instinct™ MI355X GPU accelerators integrated into Dell infrastructure, Zenith can provide researchers and innovators with the advanced computing capabilities needed to support increasingly complex AI, simulation and scientific workloads.
Together, SAIL and Zenith will expand access to advanced AI and high-performance computing infrastructure for researchers, healthcare organizations, public-sector institutions and industry partners across the U.K.
As scientific and engineering challenges grow in complexity, access to advanced AI and high-performance computing resources becomes increasingly important. Systems such as Zenith provide researchers with the computational foundation needed to explore new approaches to discovery and innovation.
A Collaborative Hub for AI Innovation
Hosted through the University of Cambridge Research Computing Service, SAIL can serve as a collaborative environment where organizations can evaluate, develop and deploy advanced AI technologies.
The lab is expected to support a broad range of applications across scientific research, healthcare, climate science, engineering, public services and national-scale AI initiatives. By bringing together technology leaders, researchers and public-sector stakeholders, SAIL aims to accelerate the adoption of AI while helping ensure deployments are secure, trusted and scalable.
Advancing Open and Interoperable AI Infrastructure
A key focus of SAIL is the planned development of open and interoperable AI infrastructure built on AMD computing platforms, AMD ROCm™ software and cloud native technologies.
The lab will explore deployment models spanning AI training and inference, scientific foundation models, simulation-assisted AI workflows, trusted research environments and secure public-sector AI services. Through this work, SAIL aims to help organizations build AI capabilities with greater flexibility, interoperability and long-term choice.
Accelerating AI for Science
SAIL is intended to work alongside Cambridge’s growing national AI infrastructure footprint, including the Zenith AI supercomputer and the Sunrise fusion AI system developed in partnership with the United Kingdom Atomic Energy Authority (UKAEA).
Together, these systems will support a diverse range of AI-for-science applications, including healthcare research, climate modelling, materials science, engineering simulation, fusion energy research and scientific AI model development.
Many of the world’s most important scientific challenges require more than AI alone. They depend on the convergence of artificial intelligence, simulation, data and high-performance computing to accelerate discovery and deepen scientific understanding. This emerging approach – often referred to as AI for Science – is creating new opportunities across healthcare, climate science, materials research, engineering and energy.
Supporting the Future of Fusion Energy
One of the most ambitious scientific efforts supported by this expanding AI ecosystem is fusion energy research.
Sunrise is a second Dell-AMD AI supercomputer being built now; funded by the Department for Energy Security & Net Zero (DESNZ), owned by UKAEA and operated by the University of Cambridge. Sunrise is part of a long standing UKAEA-University of Cambridge partnership and dedicated to the fusion mission.
Built on the same Cambridge-designed AMD and Dell architecture as Zenith, Sunrise is designed to help researchers tackle one of the world’s most complex scientific and engineering challenges: delivering fusion power capable of producing net-positive energy. The system also forms part of a broader effort to establish advanced AI capabilities at Culham Campus, home to the U.K.’s first AI Growth Zone.
Enabling the Next Generation of AI Infrastructure
As demand for AI continues to grow across research, industry and government, initiatives such as the Sovereign AI Innovation Lab demonstrate how open technology ecosystems and strategic partnerships can help unlock innovation at scale.
By bringing together advanced infrastructure, open software and scientific expertise, AMD, Dell and the University of Cambridge are helping to lay the foundation for the U.K.’s next era of AI-driven discovery and innovation.
Through Zenith, Sunrise and SAIL, artificial intelligence, high-performance computing and scientific research converge to accelerate discovery, strengthen competitiveness and help solve some of society’s most important challenges.
How is AI supercharging the UK’s digital economy? Join the discussions at Connected Britain 2026
Also in the news
TELUS and L-SPARK give Canadian startups access to AI supercomputer
Belden to acquire RUCKUS Networks for $1.85bn
VMO2 taps Suffolk solar farm for 10 years of clean energy
The post AMD, Dell and University of Cambridge set SAIL on AI lab appeared first on Total Telecom.
作者 | 华卫
昨日,Ramp 发布了最新的 AI Index,一个令人难以消化的核心数据是:最积极采用AI的公司,每月每位员工在AI工具上花费7500美元,约合50807元人民币。
该指数自推出以来,一直专注于追踪最基础的企业AI采用情况。如今,使用 AI 的企业占比正迅速逼近 100%。Ramp首席经济学家Ara Kharazian表示,其结果还很可能低估了实际采用率,因为许多企业在使用免费的 AI 工具,或者员工使用个人账户调用 AI 服务来完成工作任务。
即便在 Ramp 内部,相比去年其 AI 使用量增长了 6300%。团队中有 99.5% 的人都在使用 AI 工具,84% 每周都会用编程代理。在 Ramp 内部平台上,6 周内上线了 1500 多个应用,来自 800 多位不同的“构建者”;非工程师发起的生产代码 PR 已占到 12%,每月达到数千个,他们使用的是自研编程代理 Ramp Inspect。
因此,Ramp 经济研究团队的关注重点正在转向对“采用强度”的追踪,当前样本包括超过7万家美国企业和数十亿美元的企业支出。
五万月薪没到顶,上月就涨了14.1%?
根据 Ramp AI Index 的最新研究,美国按 AI 采用程度排名前 1% 的公司,每位员工每月在 AI 工具和算力上的支出达到 7500 美元,Ramp 将这前 1% 的公司称为“AI-pilled”(AI 上头)。
而且,它们已经且还将投入足够长时间。每过去一个月,这些公司都在将 AI 更深地嵌入工作流、积累专有数据,并训练团队使用那些中位数公司甚至还没有认真预算的工具。可以说,处在分布顶端的公司,并不是在“试验”AI,而是在“构建”。仅在过去一个月,这一群体的人均 AI 支出就增长了 14.1%。
据了解,这些“AI 上头”公司通常采取混合策略,并不押注单一平台。他们在多个来自 Anthropic、OpenAI 等厂商的前沿模型之间来回切换,同时使用通过 Fireworks AI、fal AI、DeepInfra 等推理平台接入的低成本开源模型,包括来自中国、与 OpenAI 和 Anthropic 竞争的 DeepSeek。
而这种模式并不仅限于头部用户。Ramp 的采用数据表明,Anthropic 已覆盖 41% 的美国付费 AI 企业用户,成为企业端采用率最高的模型提供商;OpenAI 基本持平;DeepSeek 则在 2026 年 6 月的趋势厂商榜中位居第一。一个清晰的趋势是:最成熟的 AI 采购方,往往也是最不愿被单一供应商锁定的那一群。
但Ramp 指出,这些公司目前还没有在 AI 上花得比在人身上更多,美国软件工程师月薪大约为 16000 美元,是 7500 美元的两倍多。也就是说,最激进的 AI 使用者,尚未跨越“AI 成本超过人力成本”的门槛。
关键在于:7500 美元这个数字,是天花板了吗?如果智能体 AI 持续扩大企业自动化的边界,而 token 支出逐渐成为继人力和软件之后的第三大成本中心,那么今天的前 1%,很可能在几年后就会变成中位水平。
token便宜98%、账单翻了三倍,比员工支出都多了
随着企业不断烧掉各自的 token 预算,一个关键问题浮现:公司在 AI 上的支出,是否已经超过了对人的投入?
“对我的团队来说,算力成本远远超过员工成本。”英伟达应用深度学习副总裁 Bryan Catanzaro 近日在采访中表示,AI 并没有降低用工成本,至少在当下,它的成本甚至高于企业现有的人力。
上周,Mercor 的 CEO 也称,这家初创公司在内部智能体的 token 开销上,花的钱已经超过了员工人力成本。Mercor是一家市值100亿美元的初创公司,帮助OpenAI和Anthropic等公司通过其人类专家网络训练AI模型,自2023年成立以来,已成为AI生态系统中增长最快的公司之一。
的确,token 越来越便宜了。如今,实现 GPT-4 同等级性能的成本,大约是每百万 token 0.40 美元,而 2022 年末这一数字约为 20 美元,下降了 98%。然而,根据多项行业分析,企业 AI 总账单却上涨了约 320%。企业平均 AI 预算,也从 2024 年的每年 120 万美元增长到 2026 年的 700 万美元。
问题出在,用量一点都不便宜。自 2025 年 11 月以来发布的一系列智能体 AI 工具,包括 Anthropic 的 Claude Opus 4.5、OpenAI 的 GPT-5.1,以及 Google 的 Gemini 3 Pro,显著放大了单个任务的 token 消耗。2023 年,一个简单的线性流程每次交互成本约 0.04 美元;而到 2026 年,一个编排良好的智能体系统成本约为 1.20 美元,增加了约 30 倍。
这种模式几乎在各处重演:单个 token 的价格已经大幅下跌,但对自主 AI 智能体的追逐,却让总体用量暴涨。今年4 月,Uber 在 就花光了其 2026 年全年 AI 编程预算。微软在为开发者开通 Claude Code 六个月后,又收回了相关许可;在许可证被收回前,微软内部一些工程师每月在 token 上的支出高达 500 到 2000 美元。有公司甚至因为忘记设置使用上限,单月就跑出了 5 亿美元的 Claude 账单。据外媒报道,Priceline 一名员工表示,一次常规的 Cursor 合同续约,价格竟上涨了 4 到 5 倍。
“六个月前,我和客户的对话还集中在‘它能做什么?够不够好?’,现在的对话变成了:‘我们花太多钱了。你们能提供哪些可视化?有哪些 token 控制手段?’”OpenAI 企业业务负责人 Alexander Embiricos 表示。FinOps Foundation 执行董事 J.R. Storment 则更直白地描述了这一转变:“从 4 月、5 月开始,我听到公司在说:‘天啊,我们已经超出 2026 年全年 token 预算的 3 倍了,而现在才 4 月。’整个讨论从‘尽量多用、尽快推进’(tokenmaxxing + go fast),转向‘我们需要护栏,怎么控制成本?’”
工程管理平台 Jellyfish 的研究负责人 Nicholas Arcolano 表示,过去 9 个月中,每位开发者的 token 消耗量大约增长了 18.6 倍。使用 token 最多的工程师,生产力大约是轻度用户的两倍,但为此消耗的 token 却高出 10 倍。“极高的支出是否值得,最终取决于代码产出的商业价值,而大多数公司目前仍无法衡量这一点。”他说道。
那些此前沉浸于“无限量订阅”的公司,如今正拼命搞清楚钱到底花去了哪里,以及这些投入是否真的带来了回报。Priceline IT 财务高级总监 Chris Reed 将这种现象类比为电信计费时代:“这就像‘可卡因成瘾’。他们先让你免费试用让你上瘾,然后你就离不开了。”该公司已经开始对部分团队设置 token 使用上限。Reed 表示,他已经看到供应商报告的使用量与公司内部数据之间存在差异。
高盛预测,到 2030 年,全球 token 使用量将增长 24 倍。
AI 花钱的世界严重分层:差距高达680倍
需要注意的是,人均 AI 支出7500 美元的情况,仅来自于AI 采用程度排名前 1% 的公司。对绝大多数公司来说,AI 支出在整体软件预算中仍然只是一个可以忽略不计的“零头”。
根据 Ramp AI Index 的最新研究,排名前 10% 的公司,每位员工每月 AI 支出约为 611 美元,大致相当于几个企业级 AI 席位加上一些 API 使用费用。而在通过 Ramp 企业信用卡与账单支付平台追踪的超过 7 万家企业中,中位数公司仅为 11.38 美元,大致相当于一个标准软件订阅的单席位价格。
前 1% 与中位数公司之间的差距,高达 680 倍。这也是目前对美国企业 AI 支出分布极度不均最直观的刻画。而这种差距的复利式扩大,或许不仅仅是软件预算的差异。每月只花数十美元的中位数公司,有差距的不仅是订阅数量,可能还有组织基础设施,包括工作流、数据以及需要数月时间建立的内部对 AI 的熟练度。
更值得关注的问题是:一旦 AI 成本超过人力,产出是否能够匹配?而那些已经处在这一梯队的公司,很可能正在实时做这场实验。
“我们现在看到的是一种短期错配。”瑞士人工智能研究院戈登商学院的 AI 与金融教授 Keith Lee 表示,企业正在大规模投入 AI,即便在很多任务上,人类目前仍然更便宜。这反映出“理论上的经济性”和“企业实际决策”之间存在脱节。
尽管目前 AI 可能比人类更贵,但这种情况可能会改变。Lee 认为,随着模型运行成本下降、基础设施持续改进,AI 的经济性会逐步优化。不过,他也强调,只有当 AI 变得更可靠、对人工监督的依赖更低时,它才真正具备成本优势。“关键不只是 AI 比人更便宜,而是它在规模化条件下,既更便宜,又更可预测。”
参考链接:
https://econlab.substack.com/p/how-much-does-it-cost-to-be-ai-pilled"
整理 | 华卫
近日,OpenAI 已向美国证券交易委员会(SEC)秘密提交了 IPO(首次公开募股)申请。所谓“秘密提交”,允许公司在向公众和潜在投资者披露财务数据之前,先将其提交给监管机构进行审查。这家人工智能公司目前估值已超过 8500 亿美元,并一直在为最早于今年第四季度上市做准备。
今年 4 月,OpenAI 首席财务官 Sarah Friar 在采访中表示,对于 OpenAI 这样规模的公司来说,“在各方面看起来、表现得、运作方式都像一家上市公司”是“良好的经营卫生(good hygiene)”。目前,OpenAI也尚未确定上市时机及计划筹集金额。
OpenAI 在一篇声明中表示:“可能还需要一段时间,因为我们有一些事情在作为私营公司时更容易完成。”但公司同时指出,此次提交“让我们在未来如果认为合适时,可以更快选择上市”。
收入目标落空,放开员工股份变现通道
以下是 OpenAI 发布声明的全文:
我们最近提交了一份保密的 S-1 文件。预计这一消息可能会泄露,因此我们选择主动公布。目前尚未决定具体时间;可能还需要一段时间,因为我们有一些事情在作为私营公司时更容易完成。但这是一个复杂的权衡过程,而这一步让我们在未来如果合适的话,可以更快推进上市。
OpenAI CEO Sam Altman 将面临向投资者证明公司价值的压力,尤其是在财务状况方面。OpenAI 已累计融资超过 1800 亿美元,目前仍在持续烧钱,用于获取算力资源以及建设训练和运行 AI 模型所需的基础设施。去年 11 月,OpenAI 首席财务官 Sarah Friar 曾表示,美国政府应为公司在芯片和数据中心上的巨额支出提供“兜底支持”,这一言论一度引发关注,随后她又对此进行了收回。
《华尔街日报》报道称,该公司近期未能达成自身的新用户和收入目标。过去一年,OpenAI 通过扩展 ChatGPT聊天机器人的变现方式来提升收入,包括推出更便宜的 8 美元订阅档位以及引入广告。据 The Information 今年 4 月报道,公司预计这一低价套餐将推动订阅用户数在今年达到 1.22 亿,并预计广告将在 2030 年成为其最大收入来源。
据一位因信息保密而要求匿名的知情人士透露,OpenAI 计划推进一项要约收购(tender offer),允许员工按照最新估值出售股份(该估值为投后 8520 亿美元),以缓解短期内的流动性压力。
过去一年,OpenAI 也在努力证明自身不仅仅是 ChatGPT。该公司发布了网页浏览器,宣布将开发面向消费者的硬件产品,推出了能够在用户电脑上编程并管理应用的 AI 智能体,并开发了面向政府、医疗和金融领域的 AI 工具与解决方案。
在周一的一篇博客文章中,Altman 提出了他所称的“OpenAI 的第三阶段”。他写道,第一阶段是围绕通用人工智能(AGI)进行研究,第二阶段是成为一家“产品公司”,并学习用户如何使用其工具。“现在我们正在进入第三阶段,经济体系正开始围绕 AI 进行重塑。当前的核心问题是,如何让先进 AI 变得充足、可负担、安全、有用,并且足够易用,让每一个人和组织都能从中受益。”
近几个月来,OpenAI 也在内部强调聚焦与纪律性,关闭了一些边缘项目,例如公司的短视频应用 Sora。同时,公司正在加大对企业业务以及编程助手产品 Codex 的投入,该产品直接与 Anthropic 广受欢迎的 Claude Code 竞争。Altman 曾在今年 4 月在 X 上发文称:“感觉 Codex 正在迎来属于它的 ChatGPT 时刻。”
三大 AI 公司冲刺万亿级 IPO,谁先敲钟?
自 2022 年推出 ChatGPT 聊天机器人以来,OpenAI 迅速进入主流视野,并成长为全球最有价值的私营公司之一。目前 ChatGPT 每周活跃用户已超过 9 亿,但 OpenAI 也面临来自 Anthropic、Google 以及埃隆·马斯克旗下 SpaceX(今年早些时候已与 xAI 合并)等竞争对手日益激烈的竞争。
此前外媒报道称,OpenAI 一直在与包括高盛和摩根士丹利在内的投行合作推进上市事宜,而这两家机构也正是 SpaceX 文件中排名最靠前的承销商。
上周,SpaceX 已经启动路演。根据其招股文件,OpenAI、Anthropic 和 Google 都被列为其在 AI 领域的“主要竞争对手”。根据 SpaceX 此次发行的市场反应,Anthropic 和 OpenAI 可能会加快上市步伐,以在巨额融资竞争中抢占先机。就在一周前,Anthropic 也宣布已秘密提交 IPO 申请。而在此之前不久,该公司刚完成一轮融资,估值达 9650 亿美元,超过了 OpenAI 在今年 3 月底的 8520 亿美元估值。
SpaceX 与 OpenAI 同时推进 IPO,发生在马斯克与 Altman 之间一场持续三周、激烈的法律纠纷结束不到一个月之后。一个咨询陪审团裁定,马斯克(他于 2024 年首次对 OpenAI 和 Altman 提起诉讼)提出指控的时间过晚,这些指控涉及 OpenAI 背离其保持非营利性质的承诺。联邦法官随即采纳了陪审团的裁决。马斯克随后在 X 上表示,法官和陪审团“实际上并未就案件本身的是非作出裁决,只是基于时间上的技术性问题”。
值得一提的是,OpenAI和Anthropic的估值均接近1万亿美元。在 Forge Global 这一面向散户的二级市场平台上,Anthropic 的估值近期已升至 1 万亿美元,超过 OpenAI(后者在 4 月约为 8800 亿美元)。而按SpaceX 刚敲定的 IPO 方案,发行价定为每股 135 美元,总募资规模约 750 亿美元, 其整体目标估值高达 1.75 万亿美元。
这三起上市预计将带来高达数万亿美元规模的融资,一方面为普通投资者提供了参与这些最受关注的 AI 初创公司的机会,另一方面也将成为检验市场对 AI 企业热情的重要风向标。不过,谁能率先上市,仍然至关重要。有专家认为,最先登陆资本市场的公司,很可能会拿走越来越稀缺的 AI 投资资金。
参考链接:
长期以来,移动游戏图形技术的发展始终受制于一个核心矛盾:开发者希望获得接近 PC 和主机平台的画面表现,但手机的功耗、散热和电池容量决定了其无法简单复制桌面端的渲染方案。
近日,Arm 与游戏开发商 Sumo Digital 联合公布了一款名为《光影新生》(Neural Dawn)的技术演示型手游项目。
与其说这是一款游戏,不如说它更像是一场针对下一代移动图形技术的实战验证:在有限功耗预算下,如何通过 AI 与图形渲染的结合,让移动设备运行此前主要出现在高端 PC 和主机上的实时光照技术。
该项目最大的意义在于它首次将 Arm 正在推进的“神经图形”技术完整嵌入真实游戏开发流程,并展示了未来移动 GPU 的一个重要发展方向——从单纯提升图形算力,转向图形计算与神经计算协同工作。
从“更快的 GPU”到“AI 参与渲染”
过去几十年,图形技术的发展逻辑相对简单:增加晶体管数量,提高 GPU 性能,再通过更高的计算能力实现更复杂的画面效果。
但移动设备并不具备无限扩展功耗的空间。
随着实时光线追踪、高动态光照、大规模场景渲染等技术逐步进入游戏行业,传统路径开始遇到瓶颈。
Arm 此次展示的核心思路是利用 AI 模型参与图形渲染流程,让部分原本需要大量 GPU 运算完成的工作交由神经网络处理,从而降低总体计算成本。
《光影新生》采用了两项关键技术:
Neural Super Sampling and Denoising(NSSD,神经超级采样与降噪)Neural Frame Rate Upscaling(NFRU,神经帧率提升)
其思路与 PC 领域已经广泛应用的 AI 超分辨率技术类似。
游戏首先以较低成本完成基础渲染,然后利用神经网络恢复图像细节、提升画面质量,并生成更平滑的动态效果。
对于移动平台而言,这意味着:GPU 实际渲染负载下降、功耗和发热压力降低,节省出来的预算可用于更复杂的光照与场景效果。
换句话说,AI 在这里并非游戏玩法的一部分,而是成为渲染管线中的组成模块。
神经技术与虚幻引擎 MegaLights首登移动端
相比神经渲染本身,《光影新生》更受行业关注的一点是其采用了虚幻引擎(Unreal Engine)最新推出的 MegaLights 技术。
MegaLights 是 Unreal Engine 5.5 引入的新型动态光照系统。
传统游戏开发中,大量光源同时存在会迅速推高渲染成本,因此开发者通常需要限制动态光源数量、使用预计算光照并对场景进行大量烘焙处理。
MegaLights 的目标则是允许场景中存在更多实时动态光源,并结合光线追踪阴影进行计算。对于游戏开发者而言,这意味着灯光不再只是装饰环境的背景元素,而可以直接参与叙事、关卡设计和玩家引导。
在《光影新生》中,光线本身被设计成核心玩法元素:玩家在洞穴网络中探索时,光源既承担氛围塑造功能,也承担导航和交互提示功能。
但问题在于,即便在部分主机游戏中,MegaLights 的应用仍然有限,因为其对算力要求极高。
而《光影新生》的技术价值恰恰在于验证:移动设备是否能够借助神经渲染技术承担这种级别的实时光照计算。
Arm 为什么开始在 GPU 中加入神经加速能力
从产业趋势看,这并不是一次单纯的游戏技术展示。更重要的信息来自 Arm 对未来 GPU 架构的规划。
按照 Arm 公布的信息,其下一代 Arm Mali GPU 将首次集成专用神经加速器(Neural Accelerator),并纳入今年晚些时候推出的移动端 Arm CSS(Compute Subsystem)平台。
这意味着未来的 Mali GPU 不再只是图形处理器。其设计思路开始接近 PC 领域近年来兴起的 AI+GPU 融合架构:
GPU负责传统图形计算;神经加速器负责 AI 推理;两者共同完成图像生成与优化。
从技术演进角度看,这也是行业的共同方向。无论是 PC 显卡中的 AI 超采样技术,还是手机 SoC 中不断增强的 NPU,本质上都在利用神经网络替代部分传统渲染工作。
Arm 此次展示的重点在于:这种模式开始从实验室研究进入真实游戏项目验证阶段。
对于游戏行业来说,新技术能否落地,往往不取决于技术本身,而取决于开发成本。
如果一项技术需要重写渲染管线、重新培训团队,那么即使效果再好也难以普及。因此 Arm 此次特别强调:开发者可以通过 Unreal Engine 插件直接接入相关能力,而不必构建新的图形架构。
根据官方披露的信息,《光影新生》由 Sumo Digital 一个约 17 人的团队开发,项目周期约 18 个月。
更重要的是,其采用的工作流与未来开发者接入 Arm 神经图形开发套件时的流程基本一致。
对于开发者而言,这意味着无需自建 AI 渲染框架也无需大量底层优化工作,就可以在现有 Unreal Engine 项目中逐步引入相关能力。这也是 Arm 后续发布《Arm 神经技术实践指南》以及神经图形开发套件的重要背景。
AI 代码生成率冲到50%以上,研发周期却没变短;非研发人员开始用 Vibe Coding 写软件,但信任感在下降。AI Coding 都这么强了,在企业级开发中的应用到底卡在哪?
近日,InfoQ《极客有约》X AICon直播栏目特别邀请贰贰壹咨询合伙人&蜂量科技 CEO 张子天担任主持人,和小红书 AI Coding 总架构师郑鑫祺、快手 AI Coding 负责人李京一起,在 AICon全球人工智能开发与应用大会"2026上海站 即将召开之际,共同探讨AI Coding 在企业落地中的真实难题。
部分精彩观点如下:
会用 AI 工具不等于个人提效,个人提效也不等于组织提效。工具始终是手段,真正能达到整体吞吐量提升、人均效率提升、代码产量提升的,协作才是终点。协作系统不只是多个 Agent 并行,还包含人和 AI 之间协作关系的重构。现在有一种说法:Code is Cheap。以前是“Talk is Cheap, Show Me the Code”,但现在 Talk 也没那么 Cheap 了,你的想法表达、输入可能更重要。组织形态肯定会变化,而且已经在发生,更闭环、更具创造力的组织,迭代空间更大。当 Token 费用单价足够便宜时,ToC 应用反而会更爆发出来。
在 6月 26-27 日将于上海举办的 AICon全球人工智能开发与应用大会"2026上海站 上,我们特别设置了【Agent企业级研发体系的重构"】专题。该专题将系统探讨如何将 AI 深度嵌入需求、架构、开发、测试与运维全流程,打造人机协同的新型研发范式。
查看大会日程解锁更多精彩内容:https://aicon.infoq.cn/2026/shanghai/schedule
以下内容基于直播速记整理,经InfoQ删减。
完整直播回放可查看:
行业现状与认知冲突
张子天:过去一年,AI Coding 的热度已经从"尝鲜"进入"大规模落地"阶段。但现在很多企业都遇到了一个共同问题:AI 代码生成率越来越高,但需求交付效率并没有同步暴涨。企业 AI Coding 今天真正卡住的核心问题是什么?
李京:快手从 Copilot 时代开始做智能化提效探索,经历续写、Agentic 多文件生成、到 SDD 推进复杂任务。续写时代 AI 代码贡献率个位数,Agentic 时代跃升到百分之二三十,今年已到百分之五六十。但遇到了问题:工程师体感提效40%,研发周期却没怎么变化,个人承接需求数和组织吞吐都没有很大提升。我们洞察到:会用 AI 工具不等于个人提效,个人提效也不等于组织提效。问题有三方面:组织层面,还是传统产研团队模式;协同层面,上下文在传递中不断流失;知识层面,业务知识、领域知识、研发知识没有很好地沉淀打通。
郑鑫祺:AI 生成能力基本没问题,核心问题在验证和前期对齐上。它把生产力拉上去了,但交互链条各环节没跟上。第二个问题是组织协同,AI 让个人变快了,但整体组织效率是否还适合原来的传递链条要打问号。第三个点,企业大型分布式系统过去过度微服务化和中台设计,在 AI 环境中导致研发环境分散,需要工程治理和模型能力互相衔接来解决。
李京:我们经历了几个阶段:AI First 阶段是人去应用 AI,传统工具结合 AI;现在叫 AI Native,让整个东西是 AI 原生的——从为人设计工具,到结合 AI,再到部分工具专门为 AI 设计。
郑鑫祺:背后还有人和 AI 的地位设计哲学。AI 工具发展特别快,有的是助理型,有的在提独立个体。到底人扮演什么角色?在电商等复杂领域,人的决策判断依然关键;但也有很多确定的 PMO 流程,AI 可以承担更多。这些会导致协作关系变化,对上层工具设计提出不同要求。
张子天:AI 来了,大家总觉得是"金锄头"——皇帝种地也用金锄头,或把驴换成 AI 机械驴,显然不是最佳实践。过去大规模研发中形成的岗位分工和协作方式,在 AI Coding 时代可能已不适合。不只是研发层面的前后端合并,产品层面、需求业务方都需要重新整合,找到职能分工的新边界。但组织变革牵一发而动全身,大中企业比较谨慎,只能循序渐进。
张子天:今年大家明显能感受到,AI Coding 正在从 Copilot → Agent → Multi-Agent → Agent Team 快速演进。同时,越来越多企业开始做面向非研发的 Vibe Coding 和 NoCode Agent。你们怎么看这波变化?未来企业真正需要的,是"更强的 AI 编程工具",还是"一个新的 AI 协作系统"?
郑鑫祺:从 Copilot 到 Agent Team,一直在往前走的是工具。但工具始终是手段,真正能达到整体吞吐量提升、人均效率提升、代码产量提升的,协作才是终点。协作系统不只是多个 Agent 并行,还包含人和 AI 之间协作关系的重构。在我们 Vibe Coding 产品中,深度研究从需求到上线每个节点中人和 AI 的关系,哪些 AI 可以去决策和协作,哪些必须人来做关键判断。社区通用方案偏向单兵视角提效,在整个协作过程中是缺位的。推进也不能太激进,单兵阶段先达到一定指标,过程中用 Claude 加各种 Harness 体系丰富知识库和上下文采集,再慢慢往终点推进。
李京:过年前后 OpenClaw 发布带来了开源形态和新使用模式,让更多人认知到 Agent AI 能干什么,之后大量非研发人员开始使用。关于 Agent 协作系统,我们做了几方面:一是生态建设,CLI 加 Skill 让非研发人员在内部生态里实现角色提效;二是知识打通,团队层面的互联互通;三是任务编排,业界有 Web 看板或以角色划分组建 Agent Team 等方式,还没有特别成熟的方案。
郑鑫祺:我想问李京老师一个问题。在知识整理这块,一个大的域有非常多的跨系统知识,一个需求涉及多个系统。怎么样在过程中让大家沉淀需求、沉淀知识、沉淀哪些知识?
李京:我们走了几个阶段。第一阶段做研发域和业务域知识构建,类似 Project Wiki,跟业务侧联动做业务属性标注,也面向 AI 做业务角度的组织,把工具使用等信息做成知识放进去。第二阶段做流转平台,从需求分析、灌入任务,到 PRD、单测、代码产生,整个链条串联。第三阶段是"自进化"——知识需要迭代起来不是死的,随着大家重点迭代方向和 Skill 使用情况,去迭代 AgentOS 里的知识和记忆体系。
郑鑫祺:现在每个人在单仓里已沉淀了很多 Knowledge,不管是 Code Graph 还是 PRD、各种总结。缺的是怎么提升 SDD 模式中 Spec 的质量和降低对话成本。花两小时对齐 Spec 再加一小时 CR,和熟练工程师上手差不多。Spec 质量上,更关键的是记忆的迭代和关键记忆的抽象。早期推动容易没指标牵引,大家都在整资料,指标最终最关键。
李京:在有限上下文下,不可能把所有知识全灌进去。除了上下文迭代策略,我们也在效果层面做把控,每个环节针对性沉淀评测和用例,保证 Agent 按效果优先的方式不断提升。
张子天:刚才二位老师讲的内容都是企业已经在实践的,这些内容都建立在一个非常强大的已有 Knowledge 基础之上。对于一些中小团队,落地其实更难,他们很难有专门的架构方向的人,既能深入业务,又能把不同模块、不同业务场景的东西真正梳理到一起。中小团队更多人就是铺在业务上,针对某一个需求、某一个 Feature、某一个单点系统去做。不知道二位对中小团队的场景有没有比较好的建议?
郑鑫祺:中小团队反而有更成熟的方案可直接使用。大厂因为有大量历史技术债和过度设计系统,需要花更多时间建设"航空母舰"。中小团队系统架构接近社区,Claude Code 加 Harness 体系本身是 Work 的,纳入更快。但核心要关注效果优先——做了很多 Knowledge 结果效果没变化,沉浸于"赛博精神病"里。Spec 对焦轮数、采纳率等指标要非常关注,以此反推知识沉淀。
李京:中小团队落地更快速。社区里 Claude Code、OpenCode、各种 Agent 和 Harness,买几个 Token Plan 就能有效 Run 起来。即使大企业,优秀实践也是把大组织拆成小团队,通过 Rules、AgentsMD、Spec 等逐渐形成标准化。Agent 基础设施、使用实践、研发流程,都有成型方案。
郑鑫祺:小团队核心要关注成本,很多测试烧了非常多 Token,要用更低成本把事做成。
企业级 AI Coding 的真实难点
张子天:现在很多 AI Coding 产品 Demo 都很强。但真正进入企业生产环境之后,很快会出现几个经典问题:长任务越来越偏、AI 自己乱改架构、上下文失控、结果不可复现、用户一句话把任务带偏……这些问题本质上不是模型问题,而是系统问题。你们内部分别是怎么解决的?
李京:长任务是我们一个专门的研究方向,在"不计成本"的情况下,Agent 能不能完成更复杂的任务。目标就是让 Agent 不间断地执行,一直到完成任务。
我们分两个阶段来看。第一阶段是 Human in the Loop,人需要跟 Agent 交互。第二阶段是 Human on the Loop,人抽离出来,作为观测者看 Agent 执行,怎么去纠偏。
在第一阶段,当人需要参与 Agent 循环时,复杂任务执行偏的成本越来越高,因为它改的代码非常多,回退时影响很大。我们做了几个方面的探索:
在前置环节,一是任务澄清,我们跟这个方向叫"主动性",希望 Agent 在执行任务或做计划之前,先了解清楚自己是不是真的理解了问题。当时我们做了探索,让 Agent 主动问我问题,当它不清楚的时候要不断问。后来发现社区的 Superpower 也有这个过程。二是计划,也就是 SDD,希望在前置把计划做得更明确。我访谈过一些同学,他们甚至已经不去看写代码的过程了,但一定要看写计划的过程。在前置确认计划 OK,最终代码因为现在 Agent 或模型比较强,基本也就没有太大偏差。
在后置环节,Agent 写的代码越来越多,让人 Review 也变复杂了。我们做了两个探索:一是让代码变更可视化,让人更快 Review;二是让 Agent 交叉 Review,或者做测试计划并把测试结果执行出来做 Verify。
第二阶段,人作为观察者,让 Agent 自我执行复杂任务。我们主要在加强做计划和做 Research 的能力,让 Agent 做出来的计划基本能完全一把过,写出来的效果在前置就有很好的把控。
还有一个中间探索:上下文窗口有限,如果不断往里塞东西会出问题。所以我们做了 SubAgent 的探索,在前置、后置以及中间执行环节里,让更合适的模型、更合适的 Agent 去做更合适的事情,一定程度上保证上下文不被浪费过多,信息不会太失真。
郑鑫祺:在小红书 Vibe Coding 场景,面向非研发群体,很多时候追求的是 0 Code。0 Code 的背后,在 Human in the Loop 情况下,更多是 Shape Up 理念的应用:先给一些模糊的东西,AI 来问精准的问题,再给一个 Demo,再往下跑。
在实践完了之后,到了真正产出质量的阶段,对于非研发或产品人员来说很难去纠正,这时候就需要模型去执行,所以这里有非常多的模型控制论和模型智能之间的 Balance。模型智能在不断增加,但因为 Context Length 和 Transformer 的上限,上下文问题始终需要精细化控制和解决。这不是 OpenClaw 带来的 AgentOS 能解决的问题,它更多解决的是生态问题:让更低成本地融合 Skill。但在模型控制的角度,还是需要更精细地把专家经验融入进去,变成一个 Workflow。
在我们的实践中,小红书自研了整套上下文框架和 Agentic 体系,来保障每个关键决策和判断能被精细控制,各种 Hook、各种纠正模型行为的手段,来保证质量达到 90 分甚至 100 分。但它一定会牺牲一些泛化性。这也是后续要解决的:先精再泛,在泛的过程中再去看如何利用好泛的 Skill 和精致的东西来编排精的流程。
对于Human in the Loop,背后更多是 Shape Up 理念在产品中的运用,即什么时候该问。Claude Code 有时候问得非常打断人,有时候沟通几个小时,这不可接受。所以需要一个更好的设计哲学,定义流程让 AI 遵守,包括怎么更好地探索、什么时候不让 AI 说话、什么时候命中。这块如果要做精细,确实有很大投入。但模型在增长,这块始终是一个需要打磨的方向,让效果一直冲到 100%。
张子天:现在很多企业已经开始遇到一个新问题:AI 生成代码越来越多,但大家对代码的"信任感"反而在下降。比如:AI 会自己造轮子、不遵守组件规范、安全边界不清晰、代码不可维护、上线风险越来越大。甚至很多团队开始担心:"未来会不会产生大量 AI 技术债?"你们内部怎么看这个问题?
郑鑫祺:中小团队或 AI Native 型组织,给 AI 更多自主权,定期关注腐化走势、定期重构。大厂逻辑下,关键决策依然靠人,比如 SDD 确认是人来做决策,不是让 AI 直接往下跑,因为很多东西不可逆或成本很高,数据库塞乱了影响面就很大。长程任务要做更多 Verify 的精细制作,前端有 UI 比对,中间有 TDD 驱动开发,还有各种自动化测试。最后的 CR 环节是核心信任度——线上出了 Bug 都修不来了,因为对 AI 掌控度不够了。原来只看 Diff 的 CR 方式不够,需要更有追溯链的 CR 方式。但最终上线的 Confirm 一定是人来确认。
李京:现在有一种说法:Code is Cheap。以前是“Talk is Cheap, Show Me the Code”,但现在 Talk 也没那么 Cheap 了,你的想法表达、输入可能更重要。非严肃场景就看效果,代码可维护性基本不用看。严肃生产系统分三个角度:一是 AI 为什么写出烂代码?可能是没把代码规范和架构设计适配到它的角度,更前置地告诉 Agent 怎么写代码,烂代码的可能性就降低;二是写完代码让 Agent 交叉 CR,用智能化 Review 校验;三是 AI 具备自我迭代能力,遇到 Bug 可以先自己改一轮。归纳为:架构设计提前告知 AI;交叉 Review;Agent 自我迭代、Verify 和 Auto Fix。
郑鑫祺:要产出有品味的代码,还是需要架构师来定。你给它的 Knowledge、Trade Off、Spec 中的每个 Choice,未来会被记忆住。同样的工具,外包同学和架构师使用的效果差距很大。优秀的人依然非常重要。
张子天:AI 对人的能力放大效果非常明显,能力越强的人放大越多。
观众:我们现在如何去追踪和量化 AI Coding 研发项目中的问题?
李京:最早建立浅层指标如代码生成率、智能 CR 生成率等,但最终看的是哪些被真实采纳、真正起到效果。度量体系很重要。
郑鑫祺:指标要和阶段目标相关。推广期以渗透率和 AI 代码占比来看,用 AI 就认为拥抱 AI。都用 AI 之后就要看速度和价值。速度就是人均吞吐,类似复杂度的需求原来排期五六天,估时降低了人没变,AI 贡献就更大。价值方面,哪些 Demo 真正产出了有价值的东西。Valueless 应用太多就很难平衡 Token 价值。还提出 Benchmark 驱动方式,按阶段拆二三级指标跟进与行业 SOTA 比较。
李京:内部有专门的架构治理组,在 AI 时代建立了工程架构度量体系,对架构质量评分,一定程度上防止了架构和技术劣化。快手的另一个探索是需求分层(L1-L4):L2 是 Agent 辅助;L3 是 Agent 更多协同;L4 是 Agent 端到端交付。不同层级有不同观测——L4 希望 AI 端到端交付,把控指标更多看 AI 真正完成的效果和需求吞吐是不是真的变化。
张子天:今年特别火的一个方向是:"非研发开始写软件。"产品、运营、设计、数据团队都开始直接用 AI 生成应用。但这也有很多争议:有人觉得这是未来,也有人觉得这只是 Demo 幻觉。非研发真的会成为 AI Coding 下一波最大的用户群吗?
李京:会,这件事正在发生。AI Coding 本来为研发群体做的,但研发群体在少数,今年越来越多非研发涌入。社区里判断:Coding 本质是软件的表达形式,是创作,就像写文字,创作软件未来会平权到每个人。我们甚至做了基础设施:AI 写完代码做成 Skill,跟企业内部登录系统打通,用泛域名提供域名,把静态文件和服务用 Serverless 跑起来,接云 DB。运营用它做报名系统,财务做分析小系统,更多人把想法以网页表达出来。
郑鑫祺:硅谷很多人眼中未来 Office 就是 Claude Code。OpenClaw 火了后越来越多同学因 AI 扶持 Builder 出很多有价值的项目。小红书给非研发做了很多工具,包括我负责的 Muse,直接创意后部署上线,有数据库、有 AI。核心还是看谁能发现需求、了解用户、有品味判断力。技术人员在专精领域还是主体,但纯写代码要求会更高。
张子天:过去研发像"雕版印刷",只有少数人识字、会编程。现在有了 AI Coding 就像"活字印刷术",让更多人掌握了编排和印刷技术。
观众:小红书目前是怎么确保系统安全的?
郑鑫祺:最终上线和负责还是有人把控,不是 AI 直接发布。如果今天有 AI 直接发布,那一定是 Demo,类似内部社区做内容,不是直接面向用户的。整个过程人的把控在小红书一直非常关注,不会直接上线。
李京:如果把 Coding 能力开放给大家,尤其做偏生产级系统,确实需要保障。数据安全方面,非专业计算机训练的人 Sense 没那么全面,危险操作(数据库、发布)、接支付、API 对接出去都有风险。面向非研发的系统需要特别关注。除了安全还有成本,非研发人员 Create 或产出,ROI 也需要衡量。
郑鑫祺:核心还是最终质量和安全依然由原来的人把控。AI 帮非研发做自动化工具、做报告、数据分析,大家 Build 自己的助理,做 Demo 也能很快跑通,这块比较成熟。但要做大型应用,依然需要安全、数据等专家把关。
观众:在 AI 贡献率层面上,有没有比较好的办法精准评估?对于初创或刚转型做 AI Coding 的团队,怎么评估落地效果?怎么针对性提升?
郑鑫祺:本质是顶层指标拆解的逐步演进过程。关注工具渗透就埋渗透数据,关注使用效果就统计需求吞吐情况,更精细的包括采纳率、知识命中率等。
李京:在不同阶段看不同指标,从渗透到 AI 代码贡献,再到 ROI 和需求吞吐。快手还做了需求分层(L1-L4):L2 是 Agent 辅助,L3 是 Agent 更多协同,L4 是 Agent 端到端交付。不同层级有不同观测。
郑鑫祺:不同的 L 之间的 Bar 有没有很明确的定义?会不会有难以划分的问题?跟原来低代码有点像。
李京:确实会有这个问题。我们在做需求分级时经过了比较多的讨论,而且是拿着真实需求去拆解的。
郑鑫祺:这确实是大家都面临的问题:工具很多,需求到底用什么样的方式去推?很多时候中台认的 L4 方向,但演进过程中业务又要发展,一定会有一个渐进式推进的过程。有时这个需求是 L2,过段时间工具成熟了可能变成 L3 或 L4。需要业务架构师动态判断。
观众:AI Coding 如果不需要初级程序员了,只有高级工程师的概念,如何从头去培养这样的人群?是不是要断层了?
李京:不会断层。AI 来了之后能力边界变得很扩充。首先,初级和高级的分层开始模糊——跟 AI 不断对话中 AI 会给人很多启发,之前需要经验积累的知识 AI 一定程度上能补齐,但需要经验把控的地方还是有的。具备好奇心、动手能力、创意和分享能力的同学成长更快。其次,职能边界也开始模糊——程序员跟 AI 共创时可以写出竞品调研方案和 PRD,用 AI 工具画出高保真原型,能力边界被很大扩充了。
郑鑫祺:不管初级还是高级,定义没那么重要了,可能就是个符号。在不同领域,品味、判断和创造力的内涵不一样——做大模型是技术判断,想做调酒小程序是要更懂那些人和需求。但有一点是肯定的:要以 Builder 的心态去看问题,要有好奇心。Hackathon 里那些同学比较有这种 Taste,有小创意自己去 Build,快速学习、自我迭代。
张子天:好比汽车工业早期,驾驶者是少数。当自动挡和新能源车出现后,人人都会开车了。评判标准可能都已经变化,不是能力强弱的问题,而是分领域了。
张子天:现在企业面对 AI Coding,还有一个特别现实的问题:外部生态的发展速度,已经远远超过企业内部自研速度。从 Cursor、Claude Code、Devin,到 OpenClaw、Harness、各种 Agent 平台,新的能力几乎每个月都在变化。很多企业现在都在纠结:到底应该自研、采购、还是做混合架构?企业内部已有研发体系,又该怎么和外部 AI Coding 生态融合?企业级 AI Coding 最核心的壁垒,到底是模型、工具,还是组织与系统能力?
郑鑫祺:Cursor、Claude Code 等热门产品大部分是单兵控制面,核心设计是一个开发者在屏幕面前,AI 帮他把活干快。这是以模型视角出发、以超级个体效率最大化为目标的方向。小组织、AI Native 完全采购用社区方案就好。但企业级复杂协同场景下,一个需求提出到上线跨越多个系统、多个仓库、多个团队、多个云环境,模型公司的单兵工具天然不会碰这一层。需要自建知识和工具,使用社区方案去运用,实现生产关系和生产模式的进化。
李京:一人公司懂代码的,社区方案拿来直接用。创业团队看当前阶段目标,如果目标就是更快完成业务、更快赚钱,ROI 能打正的情况下直接采购更好。大型组织自研有几个方向:一是 Skill 生态跟企业内部打通,构建成本不一定高但收益高;二是配套基础设施如知识工程;三是数据安全等红线,甚至需要模型层自部署。分场景、分阶段来看。
郑鑫祺:核心还是看你当下要解决什么问题。尤其针对非以研发产品为核心的企业,能自己做的部分越少越好,更多还是用好这个能力,提高企业产业效能。
未来判断
张子天:如果站在 2028 年回看今天,你们觉得:AI Coding 最终改变的,只是"程序员写代码"这件事,还是整个软件公司的组织形态?到那个时候,一个真正的 AI Native 企业会长什么样?
郑鑫祺:改变的已经不是软件公司了。Anthropic 预测 2026 年有一人独角兽,现在已经出现了,不是终点是起点。到 2028 年不存在纯粹的软件公司,所有公司都是 AI 公司,区别是谁先想明白。改变的不是程序员,而是整个交付链条上每个角色存在的理由。但我还是认为有品味、有判断的人依然非常重要。AI 和人的关系最多到 Peer,现在可能是助理,但不应该是奴役人的方式创造价值。核心竞争力是你能不能先发现别人没发现的需求,更快创造价值、得到收入。
李京:变化是天翻地覆的。Anthropic 一直说自己的代码 90% 以上是 AI 写的。组织形态肯定会变化,而且已经在发生,更闭环、更具创造力的组织,迭代空间更大。同理,即使在更远的以后,人的判断和品味也非常重要,能做出的作品还是不一样的。
郑鑫祺:模型上限还没完全 Touch 到,硅谷很多人认为预训练还有很大空间。但上下文长度没解决,这两年还是有很多上下文工程和场景工作要做,并不是 AGI 就出来了。人的关注点可能不是像以前钻在知识理性的逻辑链中,感性经济或被忽视的东西可能更重要。
李京:现在好模型成本还挺高。假如两年后基建和技术突破,模型成本降到极低,像 SSD 硬盘从很贵变成廉价基础设施,就像用电一样,更多改变会发生。消耗 Token 没那么心疼了,会大幅释放个人和组织的生产力和创造力。
郑鑫祺:如果是那个模式,企业形态可能要另论了。但目前模型成本依然高昂,ToC AI 应用首先要解决价值和成本问题。软硬一体公司可以把推理成本融到硬件里,解决一个领域的精致化服务达到 ToC 扩张。不然更多场景还在 ToB,因为这样才能算清 ROI。
张子天:好比移动互联网时代早期,10 块钱 30 兆流量,到现在 10 块钱可以买好几百个 G。当 Token 费用单价足够便宜时,ToC 应用反而会更爆发出来。
会议推荐
6月26-27日,AICon上海站"即将开幕!60 + 顶尖专家携一线实战案例齐聚,聚焦构建可信赖、可规模化、可商业化的 Agentic 工程实践,一站式打通 AI 工程化卡点、从源头避坑!欢迎报名咨询👇
微软在旧金山举办的 Build 2026 大会上正式发布 Foundry 的多项新功能。Nick Brady 在一篇博客文章"中将 Foundry 称为“AI 智能体从实验落地到生产系统的平台”,他表示此次发布为开发者带来了生产级智能体所需的“运行时、工具、记忆、场景对齐、模型、可观测性与管控能力”,而不仅仅是新的模型端点。
Foundry 是微软打造的“AI 应用与智能体工厂”,一个统一的 Azure 平台。微软将其定位"为一个可互操作的平台,帮助团队搭建、完成场景对齐并管控能够理解业务上下文的 AI 应用与智能体,同时实现各智能体之间可观测数据与管理策略的共享。Foundry 文档强调了与 Azure 服务、Microsoft 365 数据源以及工具和框架开放协议的原生集成。
Foundry Agent Service 中的托管智能体提供托管沙盒会话,具备状态管理与文件系统访问能力,兼容多种框架,同时对外提供有状态的 Responses API 和更轻量化的调用协议,支持直通调用。同一运行环境可运行 OpenClaw、Hermes 等长时智能体,支持状态与文件持久化;目前处于公共预览阶段的例行任务功能可按计划调度智能体,完成夜间工单分类、日报生成等工作。以上这些新增的功能是对 InfoQ 2025 年报道的 Azure AI Foundry Agent Service 正式发布版本"功能的拓展,该版本此前已推出多智能体编排、智能体间 API,并支持 Semantic Kernel、AutoGen、CrewAI 等主流框架。
博客接着介绍了工具与分发相关内容。Foundry 中的 Toolboxes 目前处于公共预览版状态,它为智能体提供统一托管端点,支持工具、技能、模型上下文协议(MCP)客户端及企业数据集成。工具只需完成一次注册就能在运行时被发现,无需逐个接入各个智能体。Skill 可进行版本管理,项目内的资源可通过 MCP 对外暴露;平台还具备工具检索能力,能为不同任务筛选出少量适配工具,而不是将全部工具都推送给模型。微软还新增了可从 Foundry 直接发布至 Microsoft Teams 和 Microsoft 365 Copilot 的功能,该功能计划于 2026 年 6 月正式上线",让基于 Foundry 构建的智能体融入员工日常办公场景,并自动沿用现有身份、权限与管理策略。
Foundry 将“记忆”视为平台级能力,而不是应用级能力。2025 年底推出公共预览版的 Foundry Agent Service 记忆功能如今支持过程性记忆、用户记忆与会话记忆。本次 Build 大会首次推出的过程性记忆可帮助智能体在多次运行过程中习得任务执行方式,早期基准测试表明,启用该功能后任务成功率有所提升。InfoQ 此前在相关报道中介绍",这项服务会从对话里提取关键信息与执行流程并加以整合,然后通过由 Entra ID 等标识划定权限范围的托管存储完成数据检索,同时支持留存和检查控制。
过程性记忆帮助智能体在多次运行中学习如何执行任务,而不仅仅是记录了什么,早期 Tau bench 测试结果显示,绝对成功率提升了 7% 到 14%,而成本几乎与基线持平。——Nick Brady
场景对齐与检索能力通过 Foundry IQ 实现,Brady 将其定义为智能体底层的知识层,把 Work IQ、Fabric IQ、Azure SQL、文件搜索及其他各类数据源统一整合至同一个具备服务等级协议(SLA)保障的检索端点下。在本次 Build 大会上,微软推出了处于公共预览阶段的 Foundry IQ Serverless、已正式发布的多源知识库,以及用于实时网络场景对齐的 Microsoft Web IQ。该服务响应时延低于 200 毫秒,且承诺不留存任何数据,同时具备加密、权限同步、敏感度标签治理等安全能力。在另一篇深度解读文章"中,Satyanarayana Padidapu 将整合了 Work IQ、Fabric IQ 与 Foundry IQ 的 Microsoft IQ 称作“智能层”,它能够简化重复的检索增强生成流程,并将场景对齐能力打造为 Copilot Studio、Microsoft 365 以及 Foundry 智能体可共用的服务。
在模型方面,Foundry 的目录新增了四个第一方 MAI 模型的公共预览版:MAI Thinking 1 用于聊天和推理、MAI Image 2.5 用于图像生成和编辑、MAI Transcribe 2 用于带说话人分离的语音转文本、 MAI Voice 2 用于支持语音克隆的多语言文本转语音。Foundry 平台上的 Fireworks AI 现已正式发布,通过单一 Azure 端点提供对开放模型的访问,配备企业级服务等级协议(SLA),支持自定义权重模型,同时兼容 Foundry 的访问控制与日志能力。Vesa Nopanen 在分析 Foundry 平台上的 Claude Opus"时表示,这种模式对于既想使用前沿模型、又需要依托 Azure 管控能力的企业而言,是一次实质性升级。他还提到,这类模型开箱即用、延迟更低,且能对接 Foundry IQ 与 Work IQ,为智能体提供场景锚定能力。Foundry 模型的托管计算功能可跨区域调度工作负载,突破本地 GPU 资源限制,支持模型微调与前沿调优。微软声称这比直接使用 GPT 5.5 进行技术文档生成等任务更具成本优势"。
要对各类智能体框架进行追踪与评估,团队无需在技术栈和可观测能力之间二选一。你可以继续使用 LangChain、Semantic Kernel 或自研代码,同时在 Foundry 中获得生产级的追踪与评估能力。——Nick Brady
除了 Build 大会相关内容回顾之外,微软和社区作者梳理出了一种分层架构:Microsoft 365 Copilot Agent Builder 和 Copilot Studio 提供可视化、低代码体验,而 Foundry 是具备评估和可观测能力的代码优先平台。Szymon Bochniak 对 Agent Builder、Copilot Studio 和 Foundry 进行了比较",将其呈现为三个层级,当团队需要自定义逻辑、高级检索以及与开发者工作流的深度集成时可使用 Foundry。微软的安全智能体流程指南"建议团队梳理智能体已触及的构建、测试和发布环节,并沿用微服务的管理规范:划定清晰使用范围、制定管控策略、做好运行追踪与持续评估,目前这些能力均已成为 Foundry 的核心原生功能。另一篇从 DevOps 视角出发的 Build 2026 回顾文章将这些新增功能描述"为“Foundry 真正成为面向生产环境的智能体平台,不再只是用于制作演示原型的工具”。
有关 Foundry 的更多信息,请访问微软官网"。
查看英文原文:https://www.infoq.com/news/2026/06/microsoft-foundry-agents/"
在 AIGC 技术出现阶跃式突破、软件工程范式从 1.0 快速迈向 3.0 的背景下,传统的产品、运营、研发协作模式正在经历前所未有的效能考验。本文整理自快手磁力引擎风控技术负责人王东旭在 QCon 全球软件开发大会 2026 北京站的分享《打破“人月神话”,Agent 重塑风控场景产运研职能》。
王东旭在此次分享中系统梳理了过去半年里团队在大模型时代推动组织智能转型的最新实践。他从"AIGC 已将安全、效率、体验的不可能三角推向极限"这一现实困境出发,提出固态组织必须向"液态组织"转型:让产品经理用 Prompt to Product模式直接交付原型、让运营从配置规则表达式升级为模型教练、让研发以 CLI 模式逃离职业阶梯的中空化困局。演讲后半段,他坦诚复盘了 Vibe Coding 的工程落地之坑与组织变革中的冲突教训。
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
AI时代危机:被“协调税”压垮的传统产运研模式
我所在的团队负责整个快手商业内容安全审核和站内/联盟广告流量反作弊,今天的演讲,会专注于内容安全这一部分,在这个每天处理上亿条短视频的场景里,我们长期面临一个“安全、效率、体验”的不可能三角。随着 AIGC 技术爆发,这个三角的张力被拉到了极致。
支撑这个三角形的,是一个非常经典的从左到右依次为运营、产品、研发的固态组织。运营负责感知和发起需求,交给产品经理分析并产出 PRD,PRD 再由技术研发转化为系统、数据或模型,最后交还给运营做线上规则配置。运营本质上就是感知业务,然后完成规则表达式的配置。在运营和产品之间、产品和技术之间,各有一条隐形的虚线,那是清晰分工之上的“部门墙”。墙的存在让职责明确,但也让职能变得单一且割裂。
随着ChatGPT 横空出世,技术发展曲线出现了一个巨大的不连续断点。AIGC 能力带来内容量的井喷式爆发,系统压力指数级上涨,同时任何人都可以轻松通过 prompt 进行图生文、文生图乃至图生视频,攻击对抗变得空前强烈。
在这个技术跃迁面前,我们面临一个现实困境:就算继续增加团队规模,产出也很难呈现老板期望的四十五度角线性增长。《人月神话》中的经典悖论——“一位女性怀胎十个月生一个孩子,那么十个人一个月是不是就能把孩子生出来?”——在大模型爆发的背景下变得更为尖锐。一个更深层的问题是,在大模型时代,执行力本身已经商品化。写代码变成了一件相对简单的事,真正的困难在于跨部门之间的沟通摩擦和信息对齐。技术已经发展得很快,但人的组织方式还没有跟上。
这引出了 Karpathy 对软件工程的三个阶段的定义。他提出,我们正在经历从软件 1.0 到 3.0 的升级转变。1.0 是工业化分工阶段,核心资产是代码行数;2.0 是 Copilot 过渡阶段,团队关注的是模型权重;而 3.0 是 AI Native 原生阶段,核心资产变成了高密度 Context 上下文。当下效能陷阱的本质,就是技术发展的速度比组织和个人的迭代速度快了半拍:技术已经到达原生阶段,但组织依旧停留在过去的范式里。基于这一判断,我们团队发起了一场面向 AI 原生的组织转型。
职能重塑之路:风控产运研如何构建AI超级组织
我们团队有运营、产品、技术三大角色,技术侧又进一步细分为算法和研发,算法包括行为概率统计类算法和 CV 算法,研发则包含传统 Java 系统开发和数据研发,技术团队整体规模峰值近百人。在这次转型中,我们的核心出发点是:每个角色都要向价值链的上游去做升级和转型。
在传统的固态组织下,产品、运营、研发、算法之间像砖块一样边界清晰。产品只需要面向 PRD 交付产品设计原稿,研发接受 PRD 编写代码、交付系统和模型,算法则在自己的一亩三分地里不断迭代 BERT 和 ResNet。我们想要重塑的是一种“液态组织”,一个以数据为中心、职能边界变得非常模糊的协作网络。产品和运营的同学开始能够完成过去需要研发去承担的工作,研发也可以向算法侧延伸。原来那种成编制、成建制的师级单位,正在被类似于合成旅一样、麻雀虽小五脏俱全的小军团所取代。
从产品、研发和运营三个层面来看,我们都有了不同程度的实践。在产品层,我们通过 Agent 驱动做了产品原型设计的一些 Agent,让大模型直接出 UI 设计稿,还有需求撰写 Agent 帮助产品经理快速完成独立且确定性高的产品原型设计,甚至还会让 AI 去给产品经理写的 PRD 打分。在研发层,我们正在尝试所谓的 L3 研发模式,覆盖从需求理解到编码、测试、运维发布的完整流程。在运营层,我特别鼓励技术同学跳出“编码是否更快、交付是否更强”的单一视角,去思考如何让整个团队创造更大价值。而我们在运营这一层做的事情,已经让运营同学的角色发生了质的跃升。
大约半年前,很多产品经理同学还相对焦虑,因为技术同学天生离大模型更近。但最近的晋升评审给了我一个很强烈的感受,这或许可以算作一个暴论——低代码平台正在消亡。过去产品经理做原型设计时,经常会借助低代码平台,通过配置化、组件化拖拽来完成设计稿。但今天,每一个产品经理都可以使用 Vibe Coding。低代码平台的好处是固化、可以快速出原型或 Demo,但在这个时代,它实际上是限制了优秀产品经理的想象力。可拖拽的组件就那么几个,如果你想表达天马行空的想法,根本没有出入口,只能“削足适履”。从与行业人士的交流来看,做低代码平台的团队也都在尝试与 AI 结合进行转型。
我们团队对于产品经理的工作提出了一种新模式,叫 P2P,即 Prompt to Product,通过编写 prompt 直接完成产品原型设计。去年下半年开始,我们大量实践了 Figma、Lovable、Bolt.new 等 Vibe Coding 产品。产品经理掌握了这些技能之后,某种意义上已经可以替代部分相对低水平研发同学的工作。以我们团队的一个技术门户需求为例,过去产品经理需要等研发排期,一个双周迭代只能做二十个需求,第二十一个就会溢出。而现在,产品经理可以直接在 Lovable 上通过面向浏览器的口令方式把需求做出来,不再需要等待研发。
从我们的视角来看,产品同学掌握这些技能后,正反两个方向的效果都很明显。正向是产品经理可以帮助研发同学挡掉一些简单需求,变成研发的“搭子”。但从另一个方向看,尤其是对于我们团队相对年轻的研发同学,被冲击的面非常大。当产品经理都能搞定这些工作的时候,要那么多研发做什么?这既是好处,也蕴含着切实的危机。但无论如何,通过 P2P 这种模式,产品经理的产能确实得到了显著提升。
我们团队的运营过去的工作模式是接收外部风险信号,然后在线上规则引擎里做配置。在大模型时代,这种工作的可替代性非常强,部分一线审核员实际上已经被大模型替换掉了,这些运营人力的简单职能被大模型取代后,还顺势完成了AI Native的职能升级转型。在我们场景里,它经历了三个层次的变化。
第一层是 Prompt Engineer。可能现在还有部分技术同学以能写出一个很强的 CoT 风格的 prompt 为荣,但从去年开始,在我们团队这件事应该是运营同学去做的。我们团队的运营写出的 prompt 非常厉害,不是一个简单的一句话指令,而是带有结构化思维链的。因为场景是多模态的,他们甚至能做图文交替、模态融合的 ICoT。之所以会有这样的转变,是因为我们判断运营对线上业务要比技术同学了解得更深,让运营直接与大模型对话,把领域知识经验交给大模型,才是更为彻底的做法。
但仅有 Prompt Engineer 还不够。大模型在多多少少都会出现幻觉问题。于是我们场景的运营同学不但要会写 prompt,还要能把自己领域的知识,比如看健康行业或电商行业的经验,完整做到 RAG 知识库里,通过线上规则的结构化、向量化,大大降低模型的幻觉问题。这就是第二层,从 Prompt 运营到 RAG 运营。
更进一步,我们在2025年Q2完全叫停了技术同学去做这些事情。第一,不要再写 prompt;第二,RAG 运营也不是研发该干的活;第三,更激进、更极致一点,我甚至不让算法同学再做有监督微调 SFT。在早期这个事有护城河,但随着技术发展,算法再去做已经是一种低水平的重复。于是我们在2025年 Q3 左右,把整个模型的有监督微调做成了一个线上化平台,已经有一部分能力较高的运营同学可以完成模型 pipeline 的运维,充当模型的教练。
总结下来,运营的角色变化就是从传统的写规则表达式,到成为 Prompt Engineer,再到 RAG 运营,最后到模型教练。只要你把工具做得足够平民化、线上化、抽象得足够好,运营就能完成这些跃迁。通过这种方式,我们团队的运营同学完成了一个相对不错的面向 AI 原生的转型,我可以很确定地说,他们在市场上是非常值钱的。
大模型对研发同学的影响面可以用一条微笑曲线来描绘。曲线的横轴是职级,从 junior 到 Staff+,纵轴是影响程度。越是资深的同学且拥抱 AI,其能力会被无限放大,对应微笑曲线右侧的加持效应。但还有一部分同学,尤其是刚入场的校招生或小白,受到的冲击是负向的,是所谓的 Danger Zone。因为他们向上卷经验卷不过资深同学,向下和大模型比产出速度也比不过,于是就出现了“职业阶梯中空化”的尴尬局面。如果年轻人跟不上去,整个团队就会面临断层。
要逃离 Danger Zone,就必须用 Code Agent 把自己武装起来,让自己成为一个小军团。我们团队在2025年到2026年年初这段时间,经历了三个阶段的摸索。
第一阶段是类似 Cursor 的 IDE 模式,偏向 Copilot 辅助编码。第二阶段,我们在2025年十一月左右推动研发同学用 Lovable 这样面向浏览器对话框的方式做 Vibe Coding。但现在回忆起来,这个阶段可能多多少少走了一点弯路,因为这种面向浏览器对话的方式并不太适用于技术同学,反而更适合产品、运营同学。第三阶段,我们感觉走对路了,就是 CLI 模式。国外技术论坛 Latent Space 上有一个观点叫“CLI is the future”。我自己最近一年写代码很多,日均Token消耗一亿但不再用 IDE,效率很高。这是三个阶段的真实心路历程。
在具体需求承接上,我们按照颗粒度分为小、中、大三种,采取的实践也不尽相同。小的需求,尤其是一些产品经理就能搞定的,用 Chat 对话的方式完全没问题,不必强行要求做 Spec-Driven Development。中等的需求,例如我们团队数据开发同学大量用 SQL 交互交付,我们就定义了大量 Skills,通过这些 Skills 就能把事情做得相当不错,这种场景根本用不到 Spec。只有相对大型的需求,我们才绕不开 Spec Coding。
这里需要提一个观察。现在 AI 圈流行造词,去年大家讲 Prompt Engineer,现在讲 Context Engineer、Harness Engineer。概念层出不穷,但核心并没有太大变化。Harness 这种东西,在我看来并没有那么神秘,无非就是 Token 消耗够不够多。我在团队里会设定一个坎,每天一亿 Token,这是一个相对 OK 的状态,部分头部研发同学消耗量还会更多,Token消耗得多,自然就会去考虑通过各种手段约束Coding Agent的输出,其实这就是一种Harness。
我团队还有四、五十位算法同学。在研发同学纷纷转型算法工程的大背景下,算法同学还能有什么护城河?我们的实践可以归纳为两个方向:向下深耕模型能力和向前构建数据飞轮。
向下深耕的第一块是预训练。我们并未做大模型全模态基座的端到端预训练,而是在 Visual Pre-training 视觉表征层,基于 SigLIP 搭建了自研的视觉对比学习方案。第二块是 mid-training,我们依托海量图文风控数据,在多模态大模型基座上开展领域增量续训,而非简单注入数据;该多模态架构参考 LLaVA / QwenVL 的多模态对齐思路,重点让模型掌握风险识别能力。第三块是后训练,核心聚焦偏好对齐环节,包含两种核心策略。第一种是 DPO 方式,依托风控场景的人工复核结果,形成 “判定偏好对”,这类天然的偏好样本对,非常适合用于强化学习对齐。第二种是 GRPO 方式,我们团队在该方向的相关研究成果,已被 AAAI 2026 接收录用。今年,我团队还将继续在 CVPR、ECCV 等顶会发力,争取实现更多技术突破。这里我想表达的是,大模型时代,即便是聚焦业务落地的团队,也能深耕技术深度,在学术领域取得亮眼成绩。
讲到模型能力,就不得不提我们今年重点落地的数据飞轮体系。行业内极具参考价值的标杆便是 Scale AI,此前已被Meta收购。其创始人 Alexandr Wang 凭借成熟的数据闭环建设思路,搭建起完整高效的数据生产、筛选、迭代闭环,这也是当下大模型能力持续迭代的核心动力。
结合业务实际来看,2026 年我们在多模态大模型上的核心发力方向,除了优化模型架构、迭代训练策略之外,更核心的重心将全面转向搭建适配内容安全风控场景的专属数据飞轮,以高质量数据驱动模型能力长效进化,这套思路对于团队技术建设与长期业务提效,都具备极强的指导意义。
除此之外,去年全年的团队绩效考核,以及近期的团队薪酬调整,我均严格遵循既定原则推进。本次调整重点将各岗位 AI 能力转型、数字化提效成效纳入核心考核维度,具体标准请看图示。
坑点和教训:转型过程,那些苦涩的记忆
过去半年多的实践里,我们踩过三个重要的大坑。
第一个是 Vibe Coding 工程落地坑。简单说就是“Demo 惊艳全场,生产一塌糊涂”。做 Vibe Coding 的时候,基本是想到哪儿说到哪儿,他写到哪儿。随着项目时间推移,上下文会腐化,本质原因是模型的注意力窗口比较小,这里面就出现了确定性的业务结果要求与LLM的概率性输出之间的矛盾。
怎么解?我们现在的实践更多是采用 Spec-Driven Development 模式,从提议到设计到 Spec 规约,再到 Coding,最后到测试,环环扣死。我们最近整理了一份 SDD 技术选型,例如 YC CEO 推的gstack在全局上下文方面表现不错,Superpowers 已经150 K 的 star,相对普及度很高;Open Spec 则适合做增量项目的隔离。
第二个坑是增量和存量项目的差异。增量项目本身就没有历史包袱,是 AI Native 的,很 work,但存量项目极易失效。坦白说这件事我们还没有做得特别彻底,但也在充分探索。我经常看 Anthropic 和 OpenAI 官网的博客,美国的程序员同样在探索存量项目如何演变。我有两个观点。第一,未来的 Git 仓库会有很大变化,它应该是面向 AI 的,而不是面向人的,结构上大概率会包含非常非常多的 Markdown。有人调侃扎克伯格收购 Manus 就是收购了几百万个 Markdown,但在 AI 时代 Markdown 很值钱。第二,构建软件仍然需要纪律,但这个纪律不在于代码,而在于以后 Markdown 的结构。我们的尝试可以概括为三点:一是“反向重构 Context”,因为存量代码没有这些东西,需要反向补上;二是补充大量的语义知识,因为 AI 缺上下文语义;三是建立严格的质量测试与质量门禁,生码能力太强,但没有人约束它。
第三个坑是团队管理坑。去年 AICon 结束后,我回到团队大量推组织升级,但我的问题是追求面面俱到,认为自己能做到的团队所有人都能做到,忽略了大家时间分配、能力水平和意愿度的差异。结果十二月到年初那段时间冲突和矛盾非常多。最近一个季度的反思,我总结了三个字:试、推、升。“试”是不要再追求面面俱到,现在还不到时候。如果你的老板要求你面面俱到,你不妨把这个结论反馈给他,因为有的团队过去半年已经踩过大坑。“推”是在有了局部试点成功之后,再做小范围推广,让一小部分人先富起来、先信起来。作为管理者,还可以把架构做一些局部调整,让汇报线层次不要那么深,因为我是二级主管。“升”则是全面重塑,我们现在正在从“推”到“升”的第三阶段迈进。希望这个三步演进能让更多人少踩点儿坑。
组织行动建议:下一步,该怎么走?
面向未来,我给出三点具体的组织行动建议。
第一点是推行 Token 经济学与 Skills 贡献度考核。以后我会看两个指标。一个是 Token ROI,分母是 Token 消耗量,我一定会看;但消耗多不代表产出多,分子还要看你通过每天消耗一亿、三亿 Token,对团队的产出和贡献到底是什么。另一个指标是 Skills 贡献度,个人能力强不代表组织能力强。我们团队有一个 Skills Hub,上面有排行榜,排行榜前面的同学不是被卷的,而是被激励的。只有把个人能力注入到团队的 Skills 体系中,组织效能才能最大化。
第二点是“逆康威定律”的应用。康威定律告诉我们,组织架构决定系统架构。前面讲到的运产研边界墙就是一个典型表现。当大家的职能边界被打开、组织变得更加液态的时候,系统的形态也会随之改变。这是我对于组织面的一个畅想。
第三点是我个人一直践行的一句话,叫:做“眼高手低”的技术人。“眼高”在于洞察,一定要对前沿技术知识保持想法,真的有热爱在里头。“手低”就是手还是要低下去。我看在座很多同学都很资深,我虽然年纪不算大,但也在行业里做了十多年,我一直告诉自己手不能离开一线,每天Token 消耗过一个亿是常态。有段时间我跟团队同学讲,如果你想在AI Coding这个事上 diss 我,先让 Token 消耗超过我再说。
今天 QCon 大会的主题叫“大模型,正在重新定义软件”。而我们也在重新定义我们自己。唯一的护城河,是你和你的组织进化的速度。
作者介绍
王东旭,快手磁力引擎风控技术负责人。先后在百度、第四范式、阿里巴巴任职,专注于在商业化广告风控领域的安全风险对抗,著有《广告与营销风控:方法与实践》,主导了快手商业化广告的KwaiBLM大模型审核和AhaEdit AI生成式修复规模化落地,对AI时代组织的人机协同关系有深刻实践和思考,曾在AICon 2025北京站做AI时代的10x个体和组织主题分享。
会议推荐
6月26-27日,AICon上海站"即将开幕!60 + 顶尖专家携一线实战案例齐聚,聚焦构建可信赖、可规模化、可商业化的 Agentic 工程实践,一站式打通 AI 工程化卡点、从源头避坑!欢迎报名咨询👇
文 | 市值榜,作者 | 相青,编辑 | 嘉辛
“很多自媒体都会提到腾讯慢了,在AI上面我们没有及时抓住一些机会,你觉得我们真的慢了吗?到底下半场是什么?”
近日,在腾讯云AI产业应用大会上,腾讯集团高级执行副总裁汤道生把这个问题抛给了加入腾讯不久、担任首席AI科学家的姚顺雨。
姚顺雨停顿了一下,回答道:“感觉这应该是我问你的问题。”同时也说道,AI是一个长期游戏,“我不认为ChatGPT和Claude Code不会是唯一的super app,肯定会有源源不断的新机会诞生。”
这段看似轻松的调侃,却意外点中了过去三年腾讯AI最核心的争议。
从ChatGPT横空出世至今,关于腾讯AI的评价几乎始终伴随着一个关键词——慢。
相比率先发布文心一言的百度、持续加码开源生态的阿里、靠豆包抢下用户规模的字节,以及异军突起的DeepSeek,腾讯在很长一段时间里都显得并不抢眼。
这种印象甚至已经成为资本市场的共识。
但就在6月2日,一则关于微信AI智能体即将发布的消息传出后,腾讯股价盘中大涨超过10%,单日市值增加约4148亿港元。不过,仅仅几个交易日后,腾讯股价又开始回落,大部分涨幅被抹去。
这种剧烈波动背后,折射出市场对于腾讯AI最真实的矛盾情绪。一方面,腾讯似乎错过了大模型时代最热闹的上半场;另一方面,它又握着整个行业最难复制的一张牌——微信。
这也是当下腾讯AI最大的悬念。
站在此节点上,我们复盘腾讯过去三年的AI路径,试图回答三个问题:腾讯到底慢在哪里?微信能否成为它后来居上的底牌?以及当AI竞争进入下半场,腾讯又站在什么位置?
一、腾讯慢了吗
2022年11月,ChatGPT发布,5天用户破百万,两个月月活用户破1亿。
彼时的腾讯,正处于上市以来少有的低谷期。当年全年,腾讯营收5546亿元,同比下降1%;归母净利润1882亿元,同比下降16%。这是自2004年上市以来腾讯首次出现全年营收和净利润双降的情况。
游戏版号收紧、监管压力持续,股价在2021年高点到2022年底已蒸发逾半。在2022年底内部讲话中,马化腾点名批评了多项业务,“很多业务该砍就砍,不要盲目跟随友商。”
一家正在降本增效的公司,很难在同一时间以最快速度响应一场技术革命。这直接体现在混元大模型的对外发布节奏上。
百度在2023年3月就发布了文心一言,尽管产品尚不成熟,但抢先占据了公众舆论中中国大模型的心智位置。阿里、华为、科大讯飞紧随其后,密集发布。
相比之下,腾讯直到2023年9月7日,才在全球数字生态大会上正式发布混元大模型,并通过腾讯云对外开放,与ChatGPT发布已相隔将近十个月。
而且,腾讯的逻辑是先内后外。发布时,腾讯云、腾讯广告、腾讯游戏、腾讯金融科技、腾讯会议、腾讯文档、微信搜一搜、QQ浏览器等超过50个腾讯业务和产品,已接入混元大模型进行测试。
这与百度、阿里的做法形成对比,当其他公司在争夺中国版ChatGPT的市场心智时,腾讯选择先用AI改造自己的生态。
这种路径选择有其内在合理性,但也付出了代价,在2023年这轮大模型的公众认知争夺战中,腾讯几乎没有声量。
进入2024年,腾讯才开始尝试走向C端。
2024年5月,腾讯元宝上线。但结果并不理想。QuestMobile数据显示,截至今年3月,元宝的MAU(月活跃用户数)约为5734.6万,而字节豆包和阿里千问的MAU分别达到3.45亿和1.66亿。
一个极具意味的细节发生在2026年春节,元宝斥巨资启动“分10亿现金红包”的社交裂变,核心机制是利用微信群拉新。然而,红包链接铺天盖地不到几天,便因触发微信外链合规被限制。
微信官方账号“微信派”发公告:收到用户投诉,元宝春节活动诱导分享、骚扰用户、干扰生态秩序,依规限制其链接在微信内直接打开。
这场乌龙事件,某种程度上折射出腾讯在AI时代的身份错位:拥有14亿月活的超级社交场,为什么无法孵化出一个AI时代的超级应用?
豆包的崛起,本质上是一场古典互联网式的入口防御战。字节依靠其充沛的流量红利与App工厂的买量基因,硬生生砸出一个独立的超级入口豆包,以此来锚定AI时代的C端流量王座。
相比之下,腾讯推出独立App元宝并遭遇增长瓶颈,被行业吐槽“守着金山要饭”。
腾讯最大的护城河是微信,让用户跳出微信,去另一个独立的对话框里寻找AI,不仅是在用自己的短板去硬碰字节的买量强项,更是对微信天然场景的巨大浪费。
二、微信这张牌
腾讯不需要为AI去找入口,入口已经在那里了,而且没有任何对手能够复制。
2025年三季度财报电话会上,刘炽平曾描绘了一个清晰的愿景:“微信最终会推出一个AI智能体,帮助用户在微信内部利用AI完成很多任务。”
他认为,微信的生态系统拥有非常强大的通信和社交生态系统,拥有大量数据,使智能体能够理解用户的需求、意图和兴趣;拥有非常强大的内容生态系统,包括公众号和视频号;拥有小程序生态系统,这基本上涵盖了互联网上的大部分用例;拥有商业生态系统,允许人们购买商品,以及支付生态系统,允许人们几乎立即完成支付。
刘炽平说,这几乎是用户的理想助手,理解用户的需求,并且能够在该生态系统内执行所有任务。
2025年12月的一场内部高管会议上,微信内部总结了入局AI的几个趋势:微信必须拥有不依赖于第三方系统的内置 AI 工具;微信本质由三部分构成:人与人的社交、信息获取,以及效率工具。其中,社交关系本身无法被 AI 替代,AI 的作用只可能发生在信息与效率层面。
这段表述体现了微信团队对自身边界的认知:AI不会颠覆微信的社交核心,它的价值在于改造另外两块。
2026年,微信内置AI Agent 加速落地。
3月,外媒The Information报道,腾讯正在为微信秘密开发AI智能体,项目被列为绝密级别,由微信技术负责人周颢带队,直接向张小龙汇报。计划2026年中灰测,Q3全量上线。
6月,又有报道称,腾讯正在为微信推出内嵌式AI智能体,已完成原型测试,最快将于本月启动公开上线前所需的合规审批流程。
一位曾观看早期演示的知情人士介绍,用户可通过在微信主界面向右滑动,进入AI智能体的对话框。在此界面,用户可输入指令,由智能体自动调用微信数百万个小程序,完成诸如根据口味偏好和价格要求查找咖啡馆并下单等任务。
那么,作为腾讯AI布局的王牌,微信AI智能体,能让腾讯后来居上,对国内巨头之间的AI之战产生影响吗?
从市场反应来看,不少投资者显然愿意相信这个故事。但是,从愿景到现实,中间仍然隔着漫长的工程化过程。微信小程序数量庞大,服务质量、接口稳定性、商家配合度、支付流程和利益分配,每一项都不是小事;同时,未来用户、商家、平台都可能推出各自的Agent,缺乏约束容易出现流程混乱。
AI Agent要真正跑通,需要的不只是入口,而是整条链路的协同,小程序的接口要稳定,商家要配合接入,支付要无缝衔接,推理成本要可控,数据调用要合规。
与此同时,竞争对手并没有停下来。阿里、字节都在加速向服务场景延伸。千问已深度接入淘宝、支付宝、飞猪、高德等阿里生态;豆包也在深度接入抖音电商生态。
马化腾在2026年一季度股东大会上说:“原来一年前我们以为上了船,后来发现那个船漏水了,现在感觉站上去了,还坐不下去,还是希望船速能快一点。”这句话说的正是腾讯的AI处境。
腾讯花了三年完成了从观望到押注的转变,现在需要证明的,是它能在下半场把慢下来的时间补回去。
三、AI下半场
腾讯并非看不懂AI,而是非常重视投入产出比。
过去二十多年,腾讯最成功的商业实践之一,就是在看清趋势之后迅速放大优势。无论是游戏、支付还是产业互联网,腾讯都更擅长在商业模式逐渐成熟后重仓投入,而非成为第一个吃螃蟹的人。
这种基因同样体现在AI上。
过去几年,腾讯一边推进混元研发、元宝上线和内部业务改造,一边持续保持战略弹性。2025年前后,腾讯先后投资集益威半导体、曦智科技等科技企业,同时出现在月之暗面、MiniMax、智谱等多家大模型公司的股东名单中。
但是在资本开支方面,腾讯则显得克制得多。
2025年腾讯资本开支792亿元,研发投入857.5亿元,均创历史新高。相比之下,据外媒报道,字节2025年在AI领域的资本开支约为1500亿元,其中约900亿用于AI算力采购。
但这种克制,并不意味着腾讯不重视AI。在过去两年里,腾讯始终在等待一个问题的答案:AI究竟如何赚钱?
过去两年,大模型行业最核心的叙事是模型能力。参数规模、基准测试、推理能力、下载量和用户规模构成了行业竞争的主旋律。模型虽然不断在进步,但商业模式仍然模糊。
真正让行业开始看到变化的,是Agent浪潮的出现。
2025年底以来,以OpenClaw为代表的Agent框架迅速爆发。与传统聊天机器人不同,Agent不只是回答问题,而是能够调用工具、连接服务、执行任务。从查询信息到完成交易,从内容生成到自动执行工作流,大模型第一次开始从对话工具变成执行系统。
这意味着AI第一次出现了相对清晰的商业化路径。
Token调用、工具使用、任务执行、企业订阅、交易分成,每一个环节都可能形成收入来源。某种程度上,Agent让腾讯看见了AI商业化的终点。
这也是为什么2026年以来,腾讯对Agent的反应明显加快。腾讯云迅速上线OpenClaw一键部署服务;微信Agent进入测试阶段;元宝、企业微信、腾讯会议等产品也开始围绕Agent能力进行重构。
回顾腾讯过去二十多年的产品史,会发现一条反复出现的路径。腾讯未必总是最早发明技术的人,却经常成为把复杂技术变成大众产品的人。QQ如此,微信如此,微信支付如此,小程序也是如此。
今天,这套逻辑正在被复制到Agent时代。
如果说过去两年的竞争比拼的是模型能力,那么进入2026年之后,竞争的焦点正在逐渐转向生态能力。
谁能让AI真正进入用户已经形成习惯的场景,谁能让开发者和商家持续留在平台,谁能让Agent完成从理解需求到执行任务再到完成交易的整个闭环,谁就更有机会成为下一阶段的赢家。
而这恰恰是腾讯押注的方向。
文 | 透视商业
一夜之间,MiniMax开始按Token计费了。
6月1日,伴随新一代旗舰模型M3的发布,MiniMax悄然将付费模式从“按次”切换为“按Token消耗”计费。
图片来源:MiniMax官网
没有短信预警,没有站内信通知,许多个人开发者像往常一样登录使用时,才发现游戏规则已彻底改变。这种“先斩后奏”的做法,在社交媒体和开发者引发了广泛争议。
对于将MiniMax嵌入日常工作流的开发者而言,计费逻辑的改变直接冲击了他们的成本结构和工具选择。有用户在黑猫投诉等平台公开维权,提出退款申请,也有人明确表示将不再续订。
MiniMax转变计费方式的时间点,颇为微妙。当下,整个行业都在摸索如何给coding plan定价而不至于亏损,MiniMax借M3发布重新锚定计费体系,却因此承受了远超预期的舆论压力。
01 一次计费切换,为何引来大量用户的不满?
MiniMax面向个人开发者的付费体系曾经历了两次关键转变。
最初的产品名称是“Coding Plan”,一种针对编程场景的固定月费订阅服务,采用“按次扣费”逻辑。用户在每个5小时窗口内拥有固定调用次数,超出后等待刷新即可。
这一模式的最大卖点在于不设周限额,在整个国内AI编程服务市场中,MiniMax曾是少数采取这种设计的平台。
与此同时,定价策略上的激进同样是MiniMax赢得开发者青睐的重要原因。
不少主流厂商的编程订阅服务普遍将月费定在40至50元区间时,MiniMax选择了明显下探的价格带:Starter档29元(首月9.9元)、Plus档49元、Max档199元、Ultra档899元。
这种“低价换规模”的策略收获了大量个人开发者用户,也直接推动了平台收入的快速增长。MiniMax曾在2025年年报中指出,Coding Plan的Token消耗量增长迅猛,是开放平台收入增长的关键引擎。
但MiniMax显然想进一步升级该模式。转折在2026年3月到来。彼时,“Coding Plan”升级为“Token Plan”,从名称的改变已经可以看出MiniMax的意图。
值得注意的是,这次更名最初并未触及核心计费逻辑,用户依然按原有方式订阅和使用,只是服务范围从单一的编程模型扩展为包含视频、图像、语音、音乐等在内的多模态统一体系,官方将其称为“全球首个全模态统一订阅计划”。
不过,用户还没来得及高兴太久,仅3个月后的6月1日,“Token Plan”就被注入了“灵魂”——随着M3新模型的发布,这一模式开始按Token消耗量计费,争议由此引发。
采用新计费方式后,用户很快发现一个现实问题:同等使用强度下,额度消耗速度远超预期。

图片来源:黑猫投诉平台
一位在黑猫投诉平台公开维权的重度用户表示,其开发工作需高频调用1M长上下文功能处理大型代码库,同样规模的任务,现在额度消耗速度快得惊人。另有购买了Plus档的用户在社交平台上反映,此前5小时窗口内可调用约1500次,变更后实测仅能支撑300至500次。
更令重度用户头疼的是,Token Plan在保留5小时窗口的同时新增了周额度限制。这意味着过去一周都够用的额度,可能在两三天内便消耗殆尽,剩余时间只能等待额度恢复。
这种巨大的落差感,让用户们涌入官方平台和黑猫等投诉平台,要求退款和赔偿。
面对集中爆发的用户不满,MiniMax母公司稀宇科技在6月1日晚间发布公告致歉,承认“本次调整未能提前与用户充分沟通,并详细说明计费和套餐变化,是公司工作不到位”,并表示在老用户周限额等问题的处理上存在不妥。
MiniMax也试图通过补偿方案安抚用户。这一方案可以以归纳为两类。第一类面向老用户:2026年3月22日前订阅的用户在升级后使用M2.7和M3模型时,每周调用次数不设上限;3月22日至6月5日上午10点前购买Token Plan的用户,M3模型周限额永久加赠50%。

图片来源:MiniMax小红书账号
第二类面向所有订阅用户:M3上线后前7天内,5小时窗口使用额度临时提升至200%。
市场对补救措施的反应呈现分化。一部分老用户认为,无周限额的保留在一定程度上守住了他们最初选择MiniMax时的核心权益,叠加新增的M3使用权限和多模态额度,整体可以接受。
但不满声音同样存在,核心症结在于M3模型的Token消耗速度过快,同样的周限额下实际能完成的任务数量明显减少。
新用户的负面情绪则更为普遍。由于无法享受“无周限额”的权益,他们只能接受全新的Token Plan体系,不少人在社交媒体上表达了“新老用户区别对待”的感受。
用户信任可能正在悄然损耗。在AI编程服务市场,MiniMax是一个“可选”的替代品,并没有完全建立起不可替代性。
摩根大通近期在报告中指出,M3的正面数据尚未完全解决市场对其持续定价能力的疑虑。该行认为,下一个关键验证在于留存:若OpenRouter在50%折扣结束后使用量仍保持强劲,且M3能持续在代码工具中获得更多采用,则MiniMax的高端模型策略将更具说服力,有助强化其ARR质量叙事。
反之,若折扣结束后Token使用量明显回落,或代码工具的反馈参差不齐,市场可能仍会质疑M3的质量优势是否足以对抗DeepSeek等对手而维持溢价定价。
02 成本太高,MiniMax也有压力
一切商业行为的突变,都能在成本结构中寻到根源。
作为一家以C端产品为核心定位的AI公司,MiniMax在规模扩张阶段的成本结构颇为沉重。
2025年,其研发开支占总收入的比例高达319.8%。2024年这一数字更是达到619.1%。这部分费用主要来自模型训练过程中消耗的云计算资源。
除了研发端的算力投入,产品迭代、全球化市场推广以及用户增长运营同样需要持续的资金注入。
一个不容忽视的行业现实是:AI模型的能力越强,通常意味着更长的上下文窗口、更复杂的工具调用链路、更高的推理消耗——每一次用户调用都在产生真实的计算成本。
MiniMax的技术实力有目共睹。OpenRouter数据显示,2026年3月中旬MiniMax M2.5的周调用量达到1.75万亿Token,连续五周位列全球第一;4月编程场景榜单中,M2.7以1240亿Token再次登顶;M3发布后日Token消耗量迅速突破5000亿。

图片来源:MiniMax官网
2025年全年,MiniMax实现总收入7903.8万美元,同比增长158.9%,其中国际市场贡献超过70%。
但收入的高速增长尚未有效转化为利润改善。2025年MiniMax经调整净亏损约2.51亿美元(约合人民币17.3亿元),与上年基本持平;整体毛利率为25.4%,其中B端业务毛利率约70%,C端业务仅为4.7%。
MiniMax仍处于“收入扩张快于盈利修复”的早期商业化阶段。
截至2025年底,MiniMax现金余额为10.5亿美元,较2024年底增长19.3%,资金储备尚属充裕,但管理层显然希望将重心从烧钱补贴转向单位经济模型的优化。
从行业规律来看,按Token计费早已是全球AI大模型的通行做法。OpenAI和Anthropic采用的就是这一范式,国内厂商也在逐步跟进。它能确保每一笔收入都对应着确定的成本,是改善单位经济模型的钥匙。
从这个战略方向看,MiniMax是对的。但它引发争议的问题,可能是执行节奏和时机选择。
在执行层面,MiniMax没有给用户足够的迁移缓冲。不少用户都是在毫无准备的情况下面对全新的成本结构。
在时机层面,这次调整恰逢多个不利因素叠加:DeepSeek在4月底发布V4并宣布永久降价75%,小米MiMo-V2.5也实施了降价策略,智谱、Kimi等竞争对手在一旁虎视眈眈。
在这个敏感节点引发用户信任危机,可能会将摇摆中的用户主动推向竞争对手。
当下,AI产业的竞争逻辑正在发生变化:从追求用户规模的增长阶段,进入追求商业可持续性的运营阶段。价格调整是这一转变的直接体现,其考验的不仅是企业的定价能力,更是用户沟通与信任维护的能力。
MiniMax可能在技术层面是一家优秀的公司,但在走向成熟平台型企业的路上,它还有明显的课要补。
03 不到5个月火速回A,MiniMax需要更多钱
2026年5月29日,MiniMax与中信证券签署科创板IPO辅导协议。此时距离它在港交所主板上市仅过去了141天,不足5个月。
这种“上市即回A”的速度,在港股历史上并不多见。相比之下,它的直接对手智谱,是在港股上市前九个月就未雨绸缪,启动了A股辅导。
这种时间差传递出一个明确信号:港股上市后的经历,让MiniMax管理层意识到单一港股平台可能不足以支撑公司的长期资本需求。
MiniMax港股上市后的股价走势堪称戏剧性。今年1月8日上市后,其股价曾在三个月内翻了三倍。3月18日盘中一度触及1330港元,市值一度逼近3900亿港元。
但3月以后,股价进入持续回调通道。多重因素共同施压:DeepSeek V4发布带来竞争担忧、智谱市值反超并持续拉开差距、市场对AI高估值标的热情降温。
MiniMax在5月29日启动科创板辅导、6月1日发布M3等利好消息,未能扭转颓势。截至6月10日收盘,股价报451.8港元,较年内高点缩水超过65%,市值蒸发约2400亿港元。
港股的估值正在经历“祛魅”,折价可能会加剧,这时候,科创板的“硬科技溢价”是MiniMax更需要的估值支撑。
更大的压力来自7月的解禁窗口。据HSBC Holdings Plc估算,目前MiniMax仅约5%的总股本可自由交易,其中约65%的总股份将于7月进入市场。
限售股集中解禁时,如果市场承接能力有限、基本面无法支撑高估值,股价往往面临剧烈回调。不仅早期投资者利益受损,公司的后续融资能力也将被削弱。
启动科创板IPO,可以为资金链提前准备“备份方案”。
MiniMax尚未公告科创板IPO的具体募投金额,但智谱的募资方案提供了一个参照:拟募资150亿元,其中120亿元投入AI通用基座大模型项目,20亿元投入MaaS一站式服务平台,10亿元补充流动资金。
此外,一个值得思考的问题是,6月1日切换Token Plan计费方式,是否也在为科创板IPO做铺垫。
Token Plan按实际使用量计费,理论上能让每一笔收入都对应可量化的成本,有助于改善毛利率水平。如果科创板IPO在2027年落地,届时MiniMax可以向A股投资者展示持续改善的盈利能力。
在AI这个“模型越好、成本越高”的行业里,MiniMax正处于“烧钱”与“造血”之间的关键十字路口。
科创板IPO能为它赢得更多时间,但时间最终能否转化为不可替代的技术壁垒和成熟的商业化能力,将决定它能否从“六小虎”之一真正成长为AI时代的平台级公司。
当一位对AI寄予厚望的企业高管跟下面的运营团队说,“我希望用了AI能给流程节约成本带来20%-30%的效益提升。”
接下来会发生什么?
这句话传达下去之后,各个部门各自开始做AI实验——有的团队在代码方面做优化,有的做业务流程,有的做采购决策。每个团队做实验都要消耗大量Token,一段时间下来,管理层发现一个尴尬的事实:实现了自动化,但Token的费用已经超过了雇一个人专门做的成本。
这是SAP全球副总裁Varun Thamba在SAP中国峰会上分享的案例,源自他看过的一篇报道,而报道描述场景在当前企业中很常见。
SAP进行了一项覆盖13个国家、2600位企业高管(其中200位来自中国)的AI调研,结果显示39%的中国企业采取的是零散式AI策略,各部门各自行动,做了大量POC(概念验证),却很难形成可规模化的价值。只有18%的企业有战略性整体规划。
与此同时,一组数据也值得关注:中国企业的AI投资回报率从去年的18%涨到了22%,预计两年后可能达到38%。数字在涨,但SAP的调研同时揭示了一个隐藏的代价——67% 的受访中国企业认为,AI确实扩大了可处理任务的范围,但也让员工的工作负荷和责任压力同步增加了。
这不止是中国企业AI落地的年度群像,根本挑战来自哪里?
三个“未就绪”
Varun Thamba把企业AI落地面临的瓶颈归纳为三个维度:数据未就绪、员工未就绪、治理未就绪。
数据。调研中,当企业被问及“落地智能体AI是否准备好了”时,69%的中国企业认为自己目前的数据已为AI做好准备,较去年的70%略有下降。
原因很直接:很多企业在规划AI时并不知道自己是否具备足够高质量的数据。
“当他真正开始做这件事情的时候,会突然意识到,我有数据,但是这个数据还不够好。”Varun说,人力资源部门和财务部门拥有大量数据,但做AI时才发现数据的完整性和准确性远不达标。
员工。78%的中国受访企业表示,员工技能培训跟不上AI技术迭代的速度。AI几乎按周在进化,这意味着员工必须在更短的时间内掌握新工具、适应新流程。
治理。只有6%的中国企业认为自己具备有效治理AI所需的完备技能。在Varun的比喻中,这意味着“在一个地方,你的警力是不足的,无法确保在这里的人是真正守法的”。
上述三个维度叠加在一起,构成了一个企业级AI落地的完整困境:系统碎片化、数据孤岛、语义不一致,使得AI难以真正融入核心业务并规模化释放价值。
更深层的“弱链”
SAP大中华地区总裁原欣在峰会主旨演讲中,用一个经济学争论把这个问题推到了更宏观的层面。
乐观派的代表是斯坦福大学教授Erik Brynjolfsson,他在2026年2月的《金融时报》上预测,2025年美国生产率因AI提升到2.7%——这个数字看起来不高,但已是过去十年的2倍。
悲观派的代表是麻省理工的Daron Acemoglu(2024年诺贝尔经济学奖得主),他认为AI可覆盖的可盈利自动化运营部分只占经济总量的不到5%,未来十年AI对美国生产力的提升只有1.1个百分点。
“悲观的1.1%、乐观的2.7%。对于我一个在IT圈子里看到以年计、以月计的工作被Agent以天、以小时计完成,生产效率提升几十倍上百倍的人,怎么放到大的经济环境里只有个位数的影响?”原欣说。
她的答案是一个斯坦福教授Chad Jones提出的理论——弱链(Weak Link)。这个理论说,木桶能装多少水不取决于最高的板,而取决于最低的板。在整个技术变革中,企业需要找到自己的弱链并补齐它。
麦肯锡2025年全球企业AI调查的数据印证了这一点:88%的企业在至少一个场景使用了AI,但只有6%认为超过5%的EBITDA增长归功于AI。剩下94%的企业投入了真金白银,却还没有看到商业回报。
原欣的判断是:“AI能为企业创造多大价值,不取决于模型能力有多强,而取决于企业最薄弱的一环能否打通。对今天大多数企业而言,这道‘弱链'就是AI与核心业务系统之间的断层。”
IBM商业价值研究院与SAP联合发布的调研白皮书也印证了这一判断——企业推进智能化转型时,内部业务协同困难和IT架构老化是最大的结构性障碍,AI能力往往游离于核心系统之外,既拿不到完整的业务上下文,也无法触发实质性的流程执行。
探索突围
在峰会现场,三一集团、曼森集团、毕马威都分享了他们补齐“弱链”的行动和思考。
三一集团经历了90年代业务线上化、2010年代全面信息化、全面数字化(灯塔工厂、数字中台),从2025年开始到现在迎来全面智能化。许国强总结说,“没有前面三个阶段,AI就是空中楼阁。”
2025年,三一由董事长亲自推动“全员AI强管控”——所有管理岗和关键岗都要思考AI与自身业务流程的结合点。一年下来沉淀了130多万条领域知识,训练了10多款垂域模型,落地了700多个赋能场景。去年AI引入成效约2亿元。但许国强也坦承:700多个场景提升了个人效率,组织级效率的提升仍在探索中。
曼森集团总经理杜国亚提供了一个更轻量的样本。在同行纷纷追逐大模型、生成式AI的当下,这家年增长30%-50%的企业选择的第一步,不是部署AI Agent,而是先把ERP系统建好——把“大脑”建好,再谈智能。
“AI能不能回答问题?可以。但能不能带来高效决策?没有数据沉淀不行。”他的做法是把原有数据全部定义为“全新的”,以最快速度完成系统切换。2025年12月,曼森集团选择部署在阿里云上的SAP Cloud ERP,正式开始打破这种信息割裂。选择云部署而非私有化,杜国亚的逻辑很直接:“我们不需要把所有事情想得那么复杂。我们之所以快速切换,是把这套系统定义成一个全新的系统,把我们公司所有的数据定义成全新的数据。”
毕马威亚太及中国咨询服务主管合伙人刘建刚则从用户自身视角提供了另一条实践路径——毕马威率先将自己的核心业务ERP迁移至公有云,成为示范性的"零号原型客户"。他的方法论是八个字:大处着眼,小处着手——既要有全面规划,又要从低投入、低风险的领域切入,做"最后一公里"延伸,先产生实效,再滚雪球式发展。他特别强调:AI并非零成本。
把以上这些实践放在一起,方法论闭环开始浮现。
第一步:数据就绪,统一业务底座,消除数据孤岛。三一用SAP S/4HANA构建全球统一业务底座,曼森在阿里云上部署SAP Cloud ERP取代多套独立系统,毕马威把核心ERP搬到公有云——三者的起点都是同一个动作:先修好“高速公路”。
第二步:知识就绪,沉淀业务知识,构建企业记忆。三一沉淀了130多万条领域知识,曼森把流程标准和业务规则统一写入系统。没有这些积累,AI Agent面对的将是点状的知识而非体系化的业务认知。
第三步:组织就绪,从IT驱动转向业务驱动,全员参与。三一的“全员AI强管控”由董事长推动,要求所有管理岗和关键岗思考AI与自身流程的结合点——这不是IT部门的事,而是整个组织的事。
这三步对应了SAP提出的三级AI治理架构:底层是数据治理层(SAP Business Data Cloud,确保AI调用的数据是可信、准确的);中间是应用集成层(ERP与第三方系统的集成,打通端到端业务流程);顶层是智能体层(Joule及AI Agent Hub,实现统一治理下的智能体协同)。
SAP在此次峰会上推出的“AI奇点启航计划”,本质上是把这个方法论变成了一个可执行的产品——企业报名参与联合工作坊,从真实业务问题出发,在2至4周内完成原型验证,看到AI带来的实际价值,最终通过RISE或GROW嵌入日常运营。
回报的起点
所有的方法论最终都要回答一个最朴素的问题:AI到底值不值?
Varun Thamba给出的建议是反直觉的——不要从AI开始,从瓶颈开始。他建议企业先看全业务流程中哪个环节造成了最大的成本浪费,然后在这个具体位置用AI,用量化工具计算Token投入和回报的关系,确保消耗Token的成本是小于可以被证明带来的价值。
许国强的判断则更为直白:“十年前数字化对很多企业是可选项,五年前是必选项,当下和未来——AI一定是生存项。AI不是取代人,是让会用AI的人取代不会用AI的人,让会用AI的企业跑赢不会用AI的企业。”
这句话听起来像是行业共识的宣示,但它的底色是一个更朴素的逻辑:94%的企业砸了真金白银却没看到回报,不是因为AI不行,而是因为企业自身在数据、流程、组织和治理层面还有太多的“弱链”没有补齐。
补链这件事不性感。它意味着要回到最基础的流程梳理、数据清洗、知识沉淀和标准统一——这些工作是三一集团二十多年从业务线上化、信息化到数字化打下的基础,在曼森表现为“先把内存储存好”,在毕马威表现为“零号原型客户自己先试”。
而这些恰恰是当前企业AI落地中最被低估的一课。正如原欣所说:“自主运营企业不是企业的终点,而是企业进化旅程的起点。”
硅谷前沿:
1.市场规模与增长:麦肯锡全球研究院2024年报告显示,全球企业级AI代理解决方案市场规模预计2025年将达120亿美元,年复合增长率38%;MarketsandMarkets预测AI代理市场将从2024年51亿美元增长至2030年471亿美元,年均复合增长率44.8%。
2.企业应用瓶颈:超60%受访企业指出AI代理的安全漏洞、操作不可控性及系统稳定性不足是阻碍大规模部署的核心因素;麦肯锡2025年报告显示仅6%企业成为“高绩效者”,93%企业未实现AI规模化应用。
3.OpenAI战略布局:通过收购专注于AI代理云服务的初创公司Ona,整合其容器化部署框架、端到端加密机制和实时监控系统,增强Codex在企业环境中的稳定性与安全性,应对谷歌、微软等竞争对手在企业AI代理市场的激烈竞争。
1.合作内容:Visa支付基础设施深度整合至OpenAI技术平台,允许AI智能体在获得用户授权后自主完成网络下单与付款操作,全球电商零售商可无缝受理AI驱动的交易。
2.市场影响:Visa全球增长负责人表示超过五分之一的交易正受大语言模型影响,AI正以超出预期速度重塑购买决策,该合作被视为支付行业将智能体商务视为在线零售下一竞争核心层的最新佐证。
3.技术架构:Visa提供网络基础设施、令牌化技术与风险管控能力,所有支付行为在用户自定义权限范围内执行(如消费上限、商户类别限制),采用令牌化Visa凭证配合实时授权与欺诈监控机制。
1.合作模式:OpenAI与甲骨文达成战略合作,甲骨文云基础设施(OCI)客户可通过现有甲骨文云承诺额度(UCM积分)直接访问OpenAI前沿模型及Codex服务,无需新增独立采购流程。
2.技术价值:该合作简化了企业AI技术部署路径,降低了技术门槛,使企业能够利用现有云资源投入快速集成AI能力,加速智能化转型进程。
3.市场影响:算力云供应商与顶级AI技术提供商的深度整合成为行业趋势,通过资源协同提升整体效率,为定制化企业级AI解决方案落地奠定基础。
1.谷歌DeepMind联合施密特科学基金会、英国ARIA机构等多家组织设立1000万美元基金,资助全球研究者探索大规模多智能体AI系统的群体行为模式与安全风险预防框架。
2.研究重点在于应对数百万AI智能体交互可能引发的诈骗、提示注入等网络安全风险升级,强调通过真实模拟而非单智能体实验来预测大规模交互的复杂结果。
3.该基金旨在推动学术界对多智能体安全的长远研究,填补行业实验室未优先考虑的空白领域,为AI智能体即将在经济领域大规模部署前的关键窗口期提供前瞻性安全准备。
1.AI大模型爆发推动基础设施需求激增:AI数据中心单位电力消耗是传统数据中心的3到5倍(麦肯锡2023年数据),2025年AI相关总用电量达2000-2200亿度(占全社会用电量1.9%-2.1%),预计2026年将增长至约5000亿度(占比4.6%-4.8%),成为电力增长第一引擎。
2.KKR联合多方成立赫利克斯数字基础设施公司:KKR、科威特投资局、英伟达与维斯特拉共同成立新公司,获得超100亿美元长期资金承诺,整合芯片、能源、投资等资源为AI云服务商提供数据中心、电力、网络连接等一体化基础设施解决方案。
3.AI基础设施投资持续升温:2024年全球AI基础设施投资额达5985亿元(较2023年增加1699亿元),预计2025年将增长至13740亿元;黑石集团2024年2月成立80亿美元数字基础设施基金,凯雷集团布局绿色数据中心项目,行业竞争加剧推动技术升级与服务优化。
1.技术突破:AWS发布第五代自研Arm处理器Graviton5,核心数量从96核翻倍至192核,采用4芯片组架构,L3缓存增至192MB(提升5倍),支持DDR5-8800内存与PCIe Gen6,云端性能最强。
2.性能提升:基于Graviton5的M9g实例相比上代M8g,通用计算性能提升25%,Web应用处理能力提升35%,机器学习推理速度提升35%,数据库性能提升30%,网络带宽达100Gbps。
3.市场影响:Meta已签约部署数千万颗Graviton核心用于智能体AI项目,成为全球最大Graviton客户,反映Arm架构在AI服务器CPU渗透率预计超40%的趋势。
1.苹果在WWDC 2026发布CoreAI引擎取代CoreML,专为端侧大模型推理优化,支持更大内存和灵活模型格式,在M4设备上运行Qwen3 0.6B模型时推理速度较MLX提升2.47倍。
2.技术核心采用ANE与GPU协同方案,提升温控稳定性,对iPhone 17 Pro等移动设备尤为重要,同时降低开发者适配门槛,推动苹果生态内AI应用落地。
3.行业背景显示2026年Q1全球端侧AI芯片市场同比增长32%(IDC数据),苹果此举加剧与谷歌TensorFlow Lite、高通骁龙AI引擎的竞争,端侧大模型推理技术进入快速迭代期。
1.Anthropic公司因AI研究社区强烈反对,撤销了Claude Fable5模型暗中限制竞争对手开发AI系统的隐蔽政策,并为此道歉(政策调整:从隐蔽限制改为对用户可见的防护措施)。
2.Claude Fable5作为最新AI模型,定价为Opus 4.8的两倍(每百万输入Token 10美元、输出Token 50美元),并强制保留30天用户数据用于防御新型攻击(数据留存政策+定价策略)。
3.该事件引发行业担忧:若隐蔽限制政策实施,先进AI研究可能被少数头部实验室垄断,影响开源AI生态发展(行业影响:竞争格局+开源生态风险)。
1.财务指标:截至2026年5月31日财年末,甲骨文公司剩余履约义务规模达6380亿美元,同比激增363%,其中12%将在未来12个月内转化为收入,34%在13至36个月内逐步确认。
2.市场趋势:创纪录的履约义务规模主要来自大规模人工智能合同,反映市场对AI基础设施及云服务的旺盛需求,超过50%的积压订单来自OpenAI合作。
3.财务影响:该履约义务为公司未来收入增长提供可预测性,但公司同时面临资本支出大幅增长(2026财年达556.6亿美元,同比增162%)和自由现金流承压(负237亿美元)的挑战。
1.贝索斯创立的AI初创公司Project Prometheus完成最新融资,估值攀升至410亿美元(较4月增长7.9%),聚焦“物理AI”赛道,旨在用AI重构航空航天、半导体制造、新能源汽车等实体产业。
2.公司核心技术为视觉-语言-行动(VLA)模型,让AI掌握物理规律,通过1000亿美元制造业转型基金收购工业资产构建数据生成网络,其“Ace”系统可将原型开发周期压缩50%。
3.全球工业AI市场2026年规模达1200亿美元(年增长率28.6%),但超过80%项目未达预期,面临数据质量、流程对接等挑战,行业正从“决策智能”转向“行动智能”的深水区竞争。
1.资本支出预期:高盛报告显示,到2027年超大规模数据中心AI资本支出可能达1.1万亿美元(乐观情况1.4万亿美元),显著高于华尔街约9200亿美元的预期,显示市场对AI基础设施投资规模仍被低估。
2.需求驱动因素:到2030年Token消耗量预计增长24倍(主要受企业代理推动),计算能力需求激增将拉动数据中心、芯片、网络设备及电力基础设施等产业链需求。
3.市场影响与风险:AI供需平衡预计到2027年下半年才能实现,高资本支出将支撑相关公司盈利增长;但需关注数据中心项目延期、电力劳动力制约、以及部分AI基础设施股票估值膨胀带来的市场波动风险。
1.速卖通于2026年6月11日在美国、法国、西班牙、波兰、墨西哥五国推出官方本地配送服务,覆盖欧美拉三大核心市场,通过整合海外仓资源实现“本地发货、本地配送”模式,将平均履约时效从5天缩短至3天,物流成本较市场均价降低10%-20%。
2.本地配送模式显著提升平台竞争力:订单履约时效预计提升30%,用户复购率有望提高15%,未来12个月内在五国市场份额预计增长5-7个百分点;同时为商家提供处罚豁免、优先中标权等平台政策支持。
3.跨境电商竞争加剧:亚马逊加速在波兰、墨西哥的海外仓扩张,eBay与法西当地物流商合作推出“本地极速达”服务,墨西哥本土电商Mercado Libre加大自有物流网络投入,以应对速卖通本地配送服务带来的市场压力。
1.市场准入加速:特斯拉FSD监督版在两个月内获得荷兰、立陶宛、爱沙尼亚、丹麦、比利时五国认证,占欧洲国家总数的11%,欧盟新规(EU)2026/481取消小批量限制为快速落地提供政策支持。
2.技术规格与成本:FSD V14区域定制版采用纯视觉方案,推理延迟降低20%,欧盟认证成本增加约12%,但可通过规模化摊薄;系统定义为L2级,驾驶员需全程监督并承担法律责任。
3.竞争格局影响:特斯拉欧洲存托凭证(EDR)上涨1.8%,先发优势迫使大众、奔驰、宝马等竞争对手调整战略,欧盟统一许可可能提前推出,整体推进速度比预期快15%。
(广角观察、Edge AI Daily等综合整理)

一个选择加锁,一个选择换发动机。同一天,两家公司给出了AI的两种答案。回答的虽然是不同层次的问题,却指向了同一个方向。
Anthropic于本周6月9日发布了Claude Fable 5和Mythos 5,一模型两版本,用安全策略划分能力边界。次日,谷歌DeepMind发布DiffusionGemma,26B MoE开源模型,用文本扩散架构将本地推理速度拉升4倍。前后相差不到24小时,两家公司拿出了截然不同的AI产品哲学。
在AI行业从“谁更强”进入“谁能用得起、谁能安全地放出来”的新阶段,Anthropic和谷歌的选择恰好构成了两种路线哲学的典型样本:一个在能力之上加安全锁,一个在效率上换新引擎。
它们不是对手,而是同一张拼图的两块。
一把锁与一台发动机
Anthropic的选择是在能力之上加一把锁。
Fable 5和Mythos 5共享同一底层模型,区别在于安全策略的松紧。Fable 5内置风险分类器,高风险请求被降级到Opus 4.8处理;Mythos 5移除所有限制,仅向Project Glasswing下经过审核的机构开放。这套“降维安全学”的本质是:模型能力已经强到需要分级管理,于是用软件层面的开关划分使用权限。
谷歌的选择则是换一台发动机。
DiffusionGemma没有走主流大模型的自回归路线,那种逐token生成的“打字机”模式,而是将图像生成领域的扩散机制引入文本领域。它从一段随机噪声开始,一次性铺开256个token的“画布”,通过多次并行迭代逐步去噪,最终生成连贯文本。好比从打字机换成了印刷机,不是逐字敲出,而是一次排版、整体输出。
效果是显著的,单块H100上每秒生成1000+ tokens,消费级RTX 5090上700+,比同等规模的自回归模型快约4倍。量化后仅占18GB显存,这意味着一张消费级显卡就能本地运行。
但DiffusionGemma有一个明确的前提:它是实验性模型。谷歌官方没有回避这一点,输出质量低于自回归路线的Gemma 4。文本扩散架构在长文本连贯性和复杂推理任务上仍存在质量差距。这是用性能换速度的典型取舍:当生成速度提升4倍时,生成质量做出了让步。
这决定了DiffusionGemma的适用场景。它不是用来替代Claude Fable 5或GPT-5.5做复杂推理的,而是瞄准了低延迟、本地化、实时交互的应用场景——代码补全、实时翻译、本地AI助手、端侧推理。在这些场景中,速度的优先级高于单次输出的完美度。
Anthropic的选择则相反。Fable 5在SWE-bench Pro上得分78.6%,FrontierCode Diamond得分29.3%,全面领先前代和竞品。Stripe用它一天完成5000万行Ruby代码迁移,人工需要两个月。在Anthropic的价值排序中,能力上限是第一优先级,速度和安全都在其次。
两种路线没有对错之分,它们回答的是不同的问题,但共同揭示了AI行业正在发生的深层分野。
封闭与开源
Anthropic的商业模式建立在稀缺性之上。
Fable 5 API定价60美元/百万token,是Opus 4.8的两倍、GPT-5.5的1.7倍、DeepSeek-v4的46倍。在全行业AI价格持续走低的背景下,Anthropic逆势提价,赌的是绝对性能可以支撑溢价。Mythos 5则更进一步,用安全审核制造准入壁垒,将高端能力变成稀缺资源。这套分层模式的核心逻辑是:能力越强,越要控制供给。
谷歌的路线完全相反。
DiffusionGemma采用Apache 2.0许可证开源,权重开放下载,开发者可以在本地自由部署和修改。26B参数、MoE架构仅激活3.8B、量化后18GB显存。这些技术指标的设计目标很明确:让尽可能多的人在自己的设备上跑起来。
谷歌还与英伟达合作,从发布首日起就支持RTX和DGX全系列GPU。
这不是谷歌第一次走开源路线。从Gemma系列到DiffusionGemma,谷歌在开源大模型领域的投入持续加码。但DiffusionGemma的特殊之处在于,它不是在已有路线上做开源版本,而是开辟了一条全新的技术路线——文本扩散。这意味着谷歌不仅在开源模型,还在开源一种新的架构范式。
尽管路径迥异,两个产品在几个维度上指向了相同的行业趋势。
一个最直观的趋同方向是本地化,DiffusionGemma的目标场景就是本地推理,18GB显存门槛意味着消费级硬件即可运行。Anthropic虽然以云端API为主,但Fable 5的“自主反思和验证”能力,让模型自己检查自己工作,正是为了在无人值守的本地环境中实现自主任务。
两家公司从不同方向逼近同一个目标:让AI脱离云端依赖,在本地环境中独立运转。
另一个趋同方向在架构层面,DiffusionGemma证明了非自回归路线的可行性,文本扩散架构用并行生成替代顺序生成,从根本上改变了效率曲线。
Anthropic的Fable 5虽然仍基于自回归架构,但“一模型两版本”本身就是一种产品架构创新——不是用不同的模型满足不同需求,而是用同一个模型加不同的安全策略。当参数规模竞赛遇到边际收益递减,架构层面的创新正在成为新的竞争维度。
两条路线的交汇点
更深层的交汇在于护城河的迁移。
Anthropic用安全分层构建合规壁垒,谷歌用效率提升降低使用门槛。两家公司都在寻找参数规模之外的新竞争维度。Anthropic的安全体系越复杂,后来者越难复制;谷歌的DiffusionGemma速度越快,开发者越难拒绝。在AI能力逐渐趋同的未来,安全治理能力和效率优化能力可能比模型本身更能决定胜负。
一个容易被忽略的事实是,Anthropic和谷歌的这两款产品,恰好填补了对方路线的空白。Anthropic的Fable 5/Mythos 5走的是“能力最大化+安全管控”路线,但它缺乏一个轻量级、低成本、可本地部署的选项。对于不需要顶级推理能力、但需要低延迟本地响应的场景,Fable 5的API定价和云端依赖构成了门槛。
谷歌的DiffusionGemma走的是“效率优先+开源普惠”路线,但它缺乏一个顶级推理能力的旗舰模型。对于需要复杂推理、长文分析、高精度代码生成的任务,DiffusionGemma的实验性质量和非自回归架构的局限性使其难以胜任。
这两条路线不是竞争关系,而是互补关系。它们共同覆盖了AI应用光谱的两端:一端是云端高性能推理,一端是本地高效率生成。中间地带的融合,既能在本地运行、又具备顶级推理能力的模型,可能是下一阶段的竞争焦点。
从Opus 4.8到Fable 5仅11天,Anthropic完成了代际跨越。从自回归到文本扩散,谷歌用DiffusionGemma开辟了一条全新的技术路线。两家公司在同一个时间窗口内,用截然不同的产品哲学,各自回答了一个核心问题:AI能力持续增长之后,下一步往哪里走?
Anthropic的答案是加一把锁,用安全分层管理能力,用稀缺性支撑商业价值。谷歌的答案是换一台发动机——用架构创新降低门槛,用开源生态扩大覆盖。一把锁,一台发动机,指向的是同一个判断:AI行业的竞争维度正在从“谁更强”转向“谁能安全高效地让更多人用上”。
这场博弈的终局,将由市场来裁决。但一个趋势已经清晰可见:AI的下一轮竞争,拼的不再只是模型的大小,而是产品哲学的完整度和生态覆盖的广度。从今天起,这是一个需要重新评估的竞争格局。
(本文首发钛媒体APP,作者 | 硅谷Tech_news,编辑 | 焦燕)
当Token价格战真正打响,AI行业靠什么赚钱?整条AI商业化的估值逻辑,都到了需要被重写的时刻。拼“性价比”和“稀缺性”的时期可能到了。对于OpenAI而言“局势进一步恶化”,分析指“一旦OpenAI走下坡路,很可能会拖垮英伟达、甲骨文、Coreweave等。”
生成式AI的商业化叙事,正面临三年来最深刻的一次自我审视。从以补贴换用户、月包订阅隐藏成本,到按Token计费引爆企业账单危机,AI行业用三年时间完成了一次商业化的三级跳——而一场潜在的价格战,可能让整套变现逻辑再度归零。
据《华尔街日报》报道,OpenAI正在考虑大幅下调向用户收取的Token费用,以从竞争对手Anthropic手中争夺企业客户。据知情人士称,此举部分是为“抢占先手”,OpenAI预计Anthropic也将采取的类似降价行动。OpenAI首席执行官Sam Altman近期在一场活动上承认,AI使用成本已成为"一个巨大问题",并表示将"帮助人们用更少的支出获得更多价值"。
这一消息的时机格外敏感。OpenAI本周已秘密提交IPO申请,Anthropic同样处于上市倒计时阶段。与此同时,彭博Silicon Data LLM Token支出指数已连续7个交易日下跌,创今年1月以来最长连跌纪录,折射出市场对AI账单可持续性的深层焦虑。报道直言,价格战将直接侵蚀两家公司的利润率——而两家公司目前均已因AI系统所需的庞大算力亏损数十亿美元。

这场讨论的核心,不再只是一次降价决策,而是一个更根本的问题:当"Token消耗越多越好"的叙事走到尽头,AI行业下一个商业化故事将由谁来讲,又将如何讲。
01
初始三阶段:从月包补贴到Token账单
生成式AI的商业化,在短短三年内经历了清晰的三段演变。
第一阶段,月包和年包订阅奠定行业基调。2023年2月,OpenAI推出月费19.99美元的ChatGPT Plus,开创大模型C端付费先例;百度、阿里、腾讯随后跟进,固定月费订阅成为初级商业模式的标配。
第二阶段,补贴大战全面爆发。为拉高ARR(年度经常性收入)这一融资估值的核心锚点,各家厂商转向大规模补贴:谷歌为学生免费提供15个月Gemini Advanced,OpenAI推出首月1美元的Team版会员,字节跳动豆包以"比行业价低99.3%"的定价入场,百度宣布核心模型免费。补贴的本质是以亏损换增长——据报道,微软在GitHub Copilot订阅模式下平均每位用户每月亏损超过20美元,部分重度用户月亏损高达80美元。
第三阶段,是按量计费的强制切换。2026年6月1日,微软宣布GitHub Copilot所有计划正式转向基于Token用量计费,月费19美元直接转化为等额Token额度。这一改变,将被订阅制长期掩藏的真实成本摆上台面——据Reddit社区用户测算,一次智能体编程会话可消耗30至40美元,单月套餐在单次使用中即告耗尽。
02
账单失控:当Token比人更贵
Token按量计费的落地,将企业AI支出的真实面目完整呈现。
企业端的账单数字触目惊心。Uber首席运营官Andrew Macdonald在2026年5月公开表示,Token消耗的增长与产品实质改善之间,"这条线还不存在",并为此专门造了一个词:"tokenmaxxing"(Token极大化),形容员工为刷使用量而执行无价值任务。
更直接的数据是:Uber仅2026年前四个月就耗尽了全年Token预算;Salesforce预计全年付给Anthropic的费用将达约3亿美元。
Anthropic自己的开发者文档显示,使用Claude Code的开发者平均成本约为每个工作日13美元,90%的用户每日成本低于30美元——折算下来,一个10人开发团队仅Token费用一年就可能超过75600美元。
投入产出比同样令人警觉。企业数据平台Entelligence.AI汇总2444家企业的数据后发现,每投入1美元的AI Token费用,仅有18美分产生了触达用户的实际价值;44美分用于修复AI自身引入的Bug,27美分流向返工,11美分消耗于审查摩擦。

面对失控的账单,企业端已开始主动管控。亚马逊叫停了内部AI使用排行榜,要求员工"不要为了用AI而用AI";微软计划逐步停用部分关键产品部门员工的Claude Code订阅。高盛指出,部分企业用于AI Token的支出已占其员工总人力成本的10%,未来几个季度这一比例可能进一步攀升。这不是需求消失,而是AI支出的粗放时代走向终结。
03
第四幕:价格战打响,OpenAI考虑大幅降价
正是在这样的背景下,价格战的导火索被点燃。
据《华尔街日报》报道,Altman的降价考量直接由追赶Anthropic的压力所触发。Anthropic的收入近期大幅增长,旗下编程工具Claude Code在软件工程师群体中走红,这家成立五年的初创公司估值甚至首次超过OpenAI。
然而,这场价格战的代价将异常沉重。价格若大幅下调,将进一步压缩两家公司本就为负的利润空间,而竞争格局提供的空间极为有限。
而投资者长期以来识别出的底层风险是,OpenAI与Anthropic的产品具有高度可替代性,客户可以轻易从一家转向另一家——这意味着降价即便短期留住客户,也无法真正构建护城河,只是延缓了份额流失。
这一困境还通过云计算巨头与AI实验室之间的财务循环向外传导。
据The Information汇编的企业披露文件,OpenAI和Anthropic合计占微软、甲骨文、谷歌和亚马逊约2万亿美元未来云服务承诺的逾半数。若降价引发收入预期下修,这条传导链条将双向承压。
美国神经科学和人工智能专家Gary Marcus说道:“这进一步暴露了OpenAI的脆弱,也表明了它面临的困境有多严重。一旦OpenAI走下坡路,很可能会拖垮英伟达、甲骨文、Coreweave等公司。局势正在迅速恶化。”

多空分歧在华尔街公开对峙。摩根大通TMT分析师Mark Schilsky认为,当前账单焦虑不过是"通往更高支出的最小减速带":若每百万Token均价下降,但美国公司AI付费渗透率持续上升,总体Token用量在数学上必然大幅增加;加之代理式AI(agentic AI)将单任务Token消耗推升至传统问答模式的数倍,长期总支出料将显著高于当前水平。
高盛半导体分析师Jim Covello则持更为悲观的立场,认为当前产业链繁荣几乎将所有价值导向半导体公司,这一现象"在历史上前所未有且不可持续",一旦企业直面按量计费的真实价格,支撑GPU采购和模型训练的资本流动将面临逆转。
04
第五幕:Token经济学的下一个故事?
价格战之后,AI行业商业化的下一章尚未写就,但轮廓正在浮现。
Citadel证券的报告提供了一个方向性框架:分层收费与按稀缺性定价。其核心逻辑是,推理密集型前沿AI不会消失,但会越来越集中在少数有能力承担算力成本的大型企业手中;对更广泛的企业而言,在物理约束缓解之前,更简单的模型可能是更具生产力的路径。这意味着AI使用将走向分层——高价值、复杂任务继续使用前沿模型,日常任务、批量任务则转向廉价模型或本地模型。
摩根大通则持相对乐观的判断:即便单位Token价格下降,智能体AI(agentic AI)的普及将使每个任务的Token消耗倍增——现有数据显示,业务agent化后每个任务的Token消耗可变为原来的3.5倍——总体支出规模仍有望继续扩大,当前的账单焦虑或许只是"通往更高支出的最小减速带"。
Nebius首席营收官Marc Boroditsky提出了"valuemaxxing"的概念,主张行业从追求Token消耗最大化,转向使每个Token真正产生价值。这一方向正逐渐成为行业共识——但真正的商业落地,仍需要AI实验室找到一套既能反映真实成本、又能被企业客户接受的定价体系,而这正是当前所有争论尚未解决的核心命题。
然而,在这场价格战中,最被忽视的变量或许是中国模型。
据美国企业支出管理平台Ramp的6月数据,DeepSeek已登顶美国企业软件订阅增速榜首。Ramp首席经济学家Ara Kharazian特别强调,这并非开源模型的本地部署,"企业在直接通过DeepSeek收发数据",是真实付费的直连使用——他坦言"没有料到美国公司会去用DeepSeek"。据第三方测算,DeepSeek V4-Pro的API均价约为GPT-5.5的十分之一,约为Claude Opus 4.7的十一分之一。

OpenAI与Anthropic两虎相争,最终受益的,可能是那个早已将"普惠定价"写入基因、且不需要向IPO投资者交代利润率的玩家。这或许不是这场价格战最受欢迎的结局,但正在成为越来越难以忽视的现实。
本文来自微信公众号“硬AI”,作者:徐超,36氪经授权发布。
这段时间以来,Codex 在社交媒体上是好评如潮。
有网友发现,现在邀请一位朋友加入 Codex ,就可以重置速率限制。
即便邀请的用户并非新用户或订阅用户,只要受邀用户通过链接打开 Codex 后发送几条消息,就能获得一次重置的机会。

除了拉新人送福利的活动,官方的 Codex 也将迎来大降价。
根据外媒援引知情人士的消息,OpenAI 正在考虑大幅降低其向用户收取的费用,以从竞争对手 Anthropic 那边赢得客户。
报道里提到,OpenAI 可能会降低 Token 的价格,但关于大降价的讨论还在进行中。

毕竟,Codex 现在就是 OpenAI 最好的客户拉新平台。
和 OpenAI 官方披露的数据一样,ChatGPT 用户突破了 10 亿,而 Codex 的周活用户却刚刚来到 500 万,相当于 200 个 ChatGPT 用户里,只有 1 个人点开了侧边栏里面的 Codex。
「用不上」是一方面,更多地可能还是不知道怎么用,或者 Codex 能做什么,哪些是 ChatGPT 做不好,只有用 Codex 才能做到的任务。

Codex 官方也听到了用户的反馈,一边高调宣传即将并入 ChatGPT,未来我们打开全新大改版的 ChatGPT 应用时,可以选择使用 Codex 还是 ChatGPT 来回答。
另一边,他们这几天在 OpenAI 官网一口气更新了十几个真实世界的工作流程,从常见的部署网页和应用、直接构建一个 Mac 或 iOS 应用,到大型的项目管理、150 个小时的科研任务,以及各种工作中的琐碎业务,都有相应的使用案例。
这些教程大概是帮助我们快速上手 Codex 的最佳指南,很好地解决了 Codex 能做什么,如何使用 Codex 的问题。
Computer Use,让 Codex 控制电脑
Hey Siri,打开微信发消息给妈妈,说 XXXX
请先解锁 iPhone
Siri 做不到,Codex 现在也做不到操作微信。
Codex 的 Computer Use 功能,主要是允许 AI 像我们一样操作电脑界面,通过点击、查看和输入来完成任务。这项功能适合的场景包括跨应用任务,如收集笔记、更新记录、在不同位置间复制细节、回复信息等。

在官方的使用案例里,他们举的例子有简单地放首音乐,也有涉及在不同应用之间切换。
@Computer 放点音乐帮我集中注意力。
@Computer 请帮我把 Notes 里的面试笔记添加到飞书里。
@Computer 请查看我的企业微信并添加提醒,提醒我今天结束前需要完成的所有事项。
具体的使用方式,我们先要在 Codex App 里面找到 Computer Use 并确认已经开启,接着在对话框里,输入指令的开头加上 @Computer ,或者提及特定的应用程序,例如 @Slack 或 @Messages 等。
选择好 Computer Use 插件之后,描述一下任务以及我们想要的结果,当 Codex 需要访问权限时,批准访问,然后让它在后台继续执行任务。

使用 Computer Use 的几个注意事项,像是确保运行时 Mac 不会锁定,或者在 Codex 里打开「锁屏操作」功能,还有 Codex 使用电脑上的应用时,我们可以在自定义设置中,告诉 Codex 默认浏览器是哪个。
以及不要使用两个 Computer Use 的任务线程来控制同一个应用,每一个线程结束后都可以要求 Codex 总结和优化该任务,甚至是将这套工作流程变成可重复的模式。
给 Codex 一个能一直跑下去的目标
平时让 AI 干活,很需要我们站在旁边盯着,它做一小步停一下,问下一步怎么办,我们得一直搭着手。
/goal 想解决的就是这件事:给 Codex 一个长期目标,让它自己照着这个方向一直做下去,干完一轮也不停。

官方指南里,几个典型的用法是那种比一句提示词大、又比一整张待办清单小的任务,目标明确、能自己验证、做到什么程度算完都说得清。
项目迁移:不管是把游戏搬到新技术栈、把移动应用搬到新平台,还是把整个代码库换个框架,都可以用 /goal 让 Codex 把迁移一路跑完。
做原型:从零做一个新应用、新游戏或新功能时,可以用 /goal 让 Codex 交出一版打磨过的初稿。你可以写一份 PLAN.md,把想做成什么样讲清楚,让它照着做。
调提示词:手上有一套测试集,就能用 /goal 拿评测结果来优化提示词。Codex 会去看哪些案例失败了、改提示词、重跑评测,一直迭代到分数上去,或者到了你定的收尾条件为止。
对于如何写好一个能稳稳跑起来的目标,先给它一个明确目标和一个收尾条件;告诉它先去读哪些文件、文档、issue、日志或计划;定好用哪条命令、哪个产物来证明进度;让它分阶段做,顺手记一份简短的进度日志;过程里我们随时用 /goal 看状态;跑完、卡住或者要换方向时,再暂停、继续或清除。
用 GPT Image 2 来做 PPT
做 PPT 最磨人的那步,常常是排版。Codex 自带两个技能:$$slides 用 PptxGenJS 直接读写 .pptx,$$imagegen 负责生成配图。
OpenAI 官方给的参考提示词是,
使用 $$slides 和 $$imagegen 技能,按以下方式编辑此幻灯片:
- 如果存在,请在每张幻灯片的右下角添加 logo.png 文件
- 在幻灯片 X、Y 和 Z 上,将文本向左移动,并使用图像生成功能在右侧生成插图(风格:抽象、数字艺术)。
- 尽可能将文本保留为文本,将简单的图表保留为 PowerPoint 原生图表。
- 添加以下幻灯片:[在此处描述新幻灯片]
- 在新幻灯片和新文本中使用现有品牌标识(颜色、字体、布局等)。
- 将更新后的演示文稿渲染成幻灯片图像,检查输出结果,并在交付前修复布局问题。
- 在交付之前运行溢出和字体替换检查,尤其是在牌组密集的情况下。
- 创建一批相关图像时,保存可重复使用的提示或生成说明。
除了从零开始做,一页页描述内容和整体风格,有 logo、图片就丢进同一个文件夹方便它取用。
我们还可以让 Codex 来处理周报、月报、季报这种,定期更新模板,让它总结一份 guidelines.md 确定好内容、结构和更新方式,再配合别的技能拉对应的数据,比如给股东的季度汇报,换上新数字和洞察就行。
而修改现成的 PPT,也可以直接在对话框里,要求 Codex 修改间距、文字错位这类毛病。

让 Codex 照着截图做网页
手上有几张截图、一份简短的设计说明,或者几张找灵感的参考图,Codex 能照着做成响应式界面,同时顺着项目里已有的写法来,即原有框架和语言,不会另起一套。
再配上 $playwright,Codex 能在真实浏览器里打开页面,按不同屏幕尺寸跟我们上传的截图逐一对照,反复调到接近为止。
参考提示词如下,
请以我提供的屏幕截图和注释为依据,在当前项目中实现此用户界面。
要求:
- 重用现有的设计系统组件和标记。
- 将屏幕截图转换为此存储库的实用程序和组件模式,而不是发明一个并行系统。
- 间距、布局、层级和响应行为要紧密匹配。
- 尊重仓库的路由、状态和数据获取模式。
- 使页面在桌面和移动设备上都能响应。
- 如果截图中的任何细节不明确,请选择最简单但仍符合整体方向的实现方式,并简要说明假设。
验证:
- 将最终的用户界面与提供的屏幕截图进行比较,包括外观和行为。
- 使用 $playwright-interactive 检查 UI 是否与引用匹配,并根据需要进行迭代,直到匹配为止。
从零做一个在浏览器跑的游戏
做游戏大概也是能看出 Codex 不只会写代码还懂设计的场景之一。一个真正的游戏,要有写下来的玩法概念、渲染层、前端外壳、后端状态、美术素材,还得不停地调画面和手感。
动手搭架子之前,先让它写一份 PLAN.md,把游戏拆成具体几块:玩家目标、核心循环、操作和输入、胜负条件、难度和成长、视觉方向、技术栈和部署假设、里程碑的先后顺序。
再写一份 AGENTS.md,按照官方的教程,可以参考下面的写法。
游戏名
<游戏类型>
技术栈:
- 前端 NextJS(部署在 Vercel)
- 渲染用 <填技术>
- 后端 Fastify + WebSocket(部署在 <平台>)
- 数据库 Postgres,缓存和 pub/sub 用 Redis
- 生成式 AI 功能走 OpenAI
约定:
- 每做完一个功能就用 build / test 命令验一下
- 做新功能时照着 PLAN.md 来
- 把思路和决定记在 .logs 里,迭代时回头查
- 用 playwright 测画面效果,不对味就改
- 用 imagegen 出素材,每出一批就把 prompt 存进 .prompts,方便以后接着出同款
- 用 Context7 MCP 拉 <渲染框架> 的文档
把 AGENTS.md 里提到的技能都装上:$$imagegen 出美术素材,$$playwright 在真实浏览器里测游戏,$openai-docs 拉最新的 OpenAI API 文档,需要的话再加个 Context7 MCP 拉渲染框架的文档。
接下来 Codex 会照着计划先做出第一版。如果要生成的图很多,这一版可能得跑上好几个小时,Token 开始疯狂燃烧。不过借由 Playwright 的能力,Codex 可以自己在浏览器里试玩、验证游戏效果,中间基本不用我们管。计划写得越细,第一版出来就越像样。
我们让 Codex 自己写了一份游戏的 Plan.md,输入提示词, 然后生成了一个几乎是可以直接上线的小游戏。

Use $playwright-interactive, $imagegen, and $openai-docs to plan and build a browser game in this repo.Implement PLAN.md, and log your work under `.logs/`.
小的网页游戏之外,使用 Codex 提供的构建 iOS App 插件,我们一句话就能在 Codex 内查看和测试 iOS App。
让 AI 自己跑科研
Codex 能干的不止写代码,它也能在科研里当一个长期干活的研究助手。用户给出方向和判断,它去实现、取证、打分、反复迭代。
其中一个案例是改模型架构。假设手上有个蛋白质折叠的假设,「让模型多表示一些高阶的几何结构,会不会学得更好」,可这种想法一遍写不完,得反复试。
用 Codex 的 Goal Mode,给它三样东西:一个划好边界的科学方向、一个能跑的基线模型、一套能自动打分的基准,它就会照着这个目标一路爬分,实现、测试、记实验、查故障、再改。

官方给出的例子里,Codex 连着跑了 150 多个小时,产出了一个叫 SimplexFold 的实验性架构。
另一个是给药物靶点排序。类似任务的麻烦点,在于证据散在十几个数据库里,遗传学、临床、文献、表达数据各管一摊。
用 Life Science Research 插件,Codex 能并行去各家数据库取证、每条证据线各自按 1-5 分打分,最后汇成一张打分表加一份排名,还能配上热力图之类的图。

在 OpenAI 官网给出的用例还有很多,我们这里只是列举了部分热门的用法。感兴趣的朋友可以去 OpenAI 开发者官网developers.openai.com/codex/use-cases,尝试不同的案例。

本文来自微信公众号“APPSO”,作者:发现明日产品的APPSO,36氪经授权发布。
腾讯在大模型赛道终于派出了一位能打的种子选手。
今年年初,伴随着OpenClaw的爆火,腾讯顺势推出了一系列类龙虾产品,其中最火爆的便是主打办公场景的AI AgentWorkBuddy。
如果说Claude Code类的代码生成类大模型,更多是针对拥有一定编程背景的小众极客,那么WorkBuddy对更广泛的打工人明显技术友好。WorkBuddy在产品设计上加入通用办公的产品功能需求,砍掉复杂代码配置步骤,支持单句指令发起任务,模型自动拆解规划并直接输出完整可用成果,这些正是非技术人员所需的。
更低的使用门槛,也是WorkBuddy能够快速出圈的原因之一。
据《中国办公智能体平台市场研发报告2026》显示,今年3月,WorkBuddy月访问量达到885万,是第二名的两倍还要多,环比增速更是达到了831%,按日活跃用户数量计已是国内最受欢迎的效率智能体工具之一。对比之下,面向开发者、由Open AI推出的桌面办公智能体Codex,自2026年2月上线以来,其周月活用户已经突破500万。
WorkBuddy排名也在迅速攀升。七麦数据显示,WorkBuddy App,自5月23日上线后,3日内便从工具免费应用榜的300名开外,飙升到100名以内目前稳定在60名左右。但在iOS总榜上,WorkBuddy在400名徘徊。
长期以来,腾讯一直坚持后发制人,从移动支付到短视频的战役无不证明,在技术较为成熟时,凭借庞大的社交网络攻城略地的正确性。然而,尴尬的是,快速迭代的通用人工智能(AGI)战场上,腾讯在基础模型上的“慢半拍”,让其成为AI军备竞赛的外围看客。
WorkBuddy的出圈,算是腾讯向外界证明自己对大模型赛道的战斗力,也再次证明了其强大的产品基因,但并非一张一线的入场券——在一场最终由自研芯片、底层算法和万亿参数组成的复杂博弈中,腾讯所需要补齐的短板还有很多。
01
团队从10人紧急扩至100多人,重要性超过元宝
WorkBuddy最初源于一个约10人的AI代码助手团队,它的产品原型是由腾讯云开发者AI产品负责人、CodeBuddy首席产品经理汪晟杰和一位运营,在2026年1月的一个周末用两个通宵赶出来的。
彼时,面向技术岗位的AI Coding工具已经有很多,但非技术岗位的员工也有强烈的AI提效需求,却苦于没有合适的工具。WorkBuddy就是在这样的背景下诞生的,今年3月9日正式上线,用户访问量远超预期,导致核心服务瞬时压力过大,团队紧急扩容了10倍。
有职场人实测后向Tech星球表示,WorkBuddy不用研究函数、不用写指令模板,口语化直白描述需求就能拿到完整成品。譬如,整理跨部门零散聊天记录能自动拆分会议决议、责任人与截止时间。策划活动方案时,给出预算、目标人群两个关键信息,就能直接产出两套可修改的完整执行方案,省去大量重复手工劳作。即便零基础新人,摸索十几分钟就能熟练日常办公全套用法。
还有图文创作者也给出了反馈。譬如,把零散的选题思路、几段素材草稿粘贴到WorkBuddy,一句简单指令,它就能梳理出完整推文大纲,自动拆分标题、导语、正文分段结构,还能配套生成适配公众号、小红书两种不同平台的排版文案,配图文字说明、话题标签一并整理妥当,不用反复拆分修改,大幅压缩内容初稿的创作耗时。
为了满足更多用户需求,Tech星球了解到,WorkBuddy已经从最初的10多人规模拓展到100多人。一位WorkBuddy员工称,最近内部招了很多人。
WorkBuddy的更新节奏一开始就非常频繁,产品有不少需要修复的地方,一天一次是常态,有时候甚至一天有三四次,连“五一”假期都在更新,“那段时间可能11点都下不了班”。在6月5日腾讯云AI产业应用大会上,官方称,AI智能体桌面工作台WorkBuddy个人版发布3个月以来,累计迭代43个版本。
但现在节奏开始逐步恢复正常,一位WorkBuddy产品侧的员工告诉Tech星球,现在基本上晚上9点可以下班了。
腾讯正在铺天盖地给WorkBuddy做广告,在深圳福田区车公庙地铁站甚至设置了打卡点,而车公庙是深圳地铁顶级四线换乘综合枢纽。从投放力度来看,腾讯旗下另一个AI产品元宝,除了在今年春节期间大撒红包外,并没有出现像WorkBuddy这样的线下投放力度。一位WorkBuddy员工用“宣传上花了很多钱”,来形容当下的情况。

图注:WorkBuddy在深圳车公庙地铁站的打卡点。(Tech星球 拍摄)
Tech星球还了解到,WorkBuddy正测试打通微信支付,用户可以直接在WorkBuddy内购买商品,并通过微信支付。此外,腾讯自选股也接入到WorkBuddy的专家中心,用户可以通过腾讯自选股股票投研专家团完成炒股需求。这某种层面意味着腾讯内部给了WorkBuddy足够多的支持,打通了一些部门墙。

Tech星球获得的一份调研报告显示,WorkBuddy是腾讯当前所有“混元”系列产品中战略优先级最高的产品,资源投入优先级排序为“WorkBuddy > DataBuddy > 其他”。一位内部员工称,其重要性应该是超过了元宝的。
在今年Q1的财报中,WorkBuddy被反复提及,腾讯总裁刘炽平在回答小程序生态问题时,三次点名WorkBuddy,而同一场电话会上,元宝仅被提及一次,并且是和ima、QQ浏览器等产品一起被提及。这也从侧面证明了WorkBuddy在腾讯AI类产品中的重要性。
02
腾讯AI“换船”,走出反复试错迷茫期
一直以来,腾讯擅长对产品的深刻洞悉而获得商业上的成功。WorkBuddy的出圈是一次腾讯式产品哲学的胜利。
一位AI行业人士认为,像WorkBuddy这样的桌面办公助手,未来会象office一样装在每个人的电脑上。“最终装的不一定是鹅厂的,但一定会装。其他家虽然会跟进,但腾讯的生态优势,是阿里和字节没法比拟的”,他向Tech星球分析道。
除去办公领域,腾讯也希望通过AI渗入到每个人的生活。6月8日,腾讯手中最大的王牌微信,低调发布了《关于开发者接入微信AI生态的指引》,指引称,微信正式面向全量小程序开发者开放AI生态接入能力。
里昂证券的报告一针见血地指出:腾讯拥有超过400万个小程序和10亿用户的庞大微信生态系统,在AI Agent领域具备最强的竞争优势,甚至优于苹果iOS生态。竞争对手要复制这样的生态系统,“至少需要10年以上时间”。
一位腾讯员工认为,微信手握十亿级活跃用户与数百万小程序构成的完整场景网络,微信AI不用向外从零开拓流量入口,能够逐个打通线下商户、线上工具、私域运营等细分场景,把智能能力嵌入用户日常点开小程序、完成下单、客服咨询、表单填报等每一次操作里,生态自带的流转闭环,能让AI能力规模化落地的节奏稳步提速。
倘若400万个小程序接入AI智能体,背后每一个调用、每一次任务执行、每一笔交易,都要消耗大模型的算力和算法能力。接入的小程序越多,对底层模型的依赖就越深。
如果腾讯不能在自研模型上持续缩小跟其他头部玩家的差距,就会面临一个被动局面:生态越繁荣,对外部模型的依赖越重,议价空间会越来越小。更极端的情况下,一旦底层模型供应商提价、断供或更改合作条件,整个生态都可能受到冲击。不仅是微信AI,这是所有AI产品都将面临的挑战。
因此,腾讯必须在基础模型上有所作为。腾讯挖来了OpenAI 研究科学家姚顺雨,希望在基础模型追赶对手。
姚顺雨在OpenAI期间,是首批Agent的核心贡献者,主导了Computer-Using Agent(CUA)和Deep Research两个重要产品。他提出的ReAct框架已成为全球构建语言智能体的最主流方法。
2026年4月23日正式发布的Hy3 preview(混元3.0预览版),相较前代Hy2在几乎所有关键指标上都实现了质的飞跃。凭借在“强推理+256K超长上下文”的能力,Hy3 preview曾连续登顶OpenRouter全球周榜。市场份额升至12.8%,位列行业第三。
但整体能力上,尤其复杂任务时,Hy3 和DeepSeek V4 Flash、Claude Sonnet 4.6等模型依然存在差距。
一位腾讯内部员工坦言,过去半年公司AI业务走出了反复试错的迷茫期,目前已经稳住了发展方向。现阶段像Qclaw、WorkBuddy等应用端落地初见成效,但底层能力打磨、生态AI化改造整体推进节奏偏保守。
2026年5月股东大会上,马化腾用一个直白的比喻概括了腾讯AI的心路历程:原来一年前我们以为上了船,后来发现那个船漏水了。又开始换一艘船,现在感觉站上去了,还坐不下去,还是希望船速能快一点。
对腾讯来说,换船之后,唯有实现底层技术的真正超越,才能在AGI时代真正安稳地坐下去。
本文来自微信公众号“Tech星球”(ID:tech618),作者:王琳 陈桥辉,36氪经授权发布。
Neural rendering, world models, physical AI, hands-on labs, and more.
All the details �nvidia.com/en-us/events/s…Fo
MotionBricks from NVIDIA Research runs real-time character animation at scale, without hand-crafted transitions or fine-tuning. And yes, it works for robotics too.
#SIGGRAPH2026 paper, demos + code: nvlabs.github.io/motionbricks
Check it out.

With the help of Joey Conway from @NVIDIAAI getting into the specifics around why Nemotron 3 is kind of a big deal
Biggest headline with Nemotron is: Hybrid Mamba Transformer, Latent MoE, and MTP
Hybrid Mamba Transformer essentially attacks right at the Attention mechanism to make the overhead sub-quadratic, but unlike quantizing KV Cache or swapping out attention head, NVIDIA chose Mamba-2
Latent MoE helps further optimize on sparsity by down projecting the dimensions so you're doing less math and less memory movement between HBM and SRAM, you're saving a ton, and NVIDIA made a conscious choice to add more experts given the surplus
Finally, MTP or multi token prediction where the model can see future tokens to be more expressive in training and also option to use for speculative decoding during inference
Oh, also the model adopts the new OpenMDW 1.1 License
Anthropic CEO Dario Amodei,只有一位直接下属。
这位掌管9650亿美元估值的AI巨头创始人,把日常运营全部甩给Daniela Amodei,自己只保留首席幕僚Avital Balwit一人汇报。其他高管全部绕过他,直接向Daniela负责。

这操作,在当下科技圈,简直是「一股清流」。
在OpenAI,奥特曼有差不多6个直接下属。

在英伟达,黄仁勋直接管60人。
传统打法是:越大的公司,CEO管的人越多,组织越扁平。
而Dario反其道而行之。他把自己的时间,近乎全部保护了起来。
Anthropic的执行团队由总裁Daniela Amodei领导,她负责日常运营并定期向董事会汇报,而Dario则专注于公司的长远战略规划和研究方向。
Dario经常与员工沟通,强调Anthropic的企业文化。
他和Daniela将维护和传承公司文化视为最重要的任务。
回击黄仁勋:AI冲击,绝非末日营销
「认为这是廉价营销的想法,本身才是廉价的营销。」
Anthropic首席执行官达里奥·阿莫迪回击了那些指责他炒作AI风险以谋取公司利益的批评者。
阿莫迪还抨击了硅谷的社交媒体「通病」,并解释了为什么社会需要现在就着手规划未来的就业问题。
包括黄仁勋多人称,阿莫迪的AI预测为「末日营销」。

阿莫迪对此坚决反击。
而且,他并没有收回自己对就业问题的担忧。
我认为这是硅谷弊病的一部分,是那种沉迷于三秒钟社交媒体世界的产物。
所以,我要传达的信息绝不是「末日将至」。我的信息是:这是一个我们应当预见到的、我们正在担忧的、并且需要积极去应对的事情。
我的担忧程度始终如一。
我们正处于熟悉的爬坡阶段:AI在提升人类的生产力。
工作中90%的内容被自动化了,剩下10%的人因此获得了十倍的杠杆,效率也随之提升十倍。
听起来很美好。但自动化的逻辑是无情的——它会持续逼近100%。
到那时,你不能只是让人「更高效」,你得为他们重新找到存在的意义。
眼下,AI已经在撰写全部或几乎全部的代码,软件工程师的生产力却还在提升——这看似矛盾,却是事实。
但裂缝已经出现:对于某些人来说,「让AI帮我做得更快」这个框架正在失效。
更诚实的问法开始浮现——与其让人借助AI提高生产力,不如直接让AI完成工作,是不是反而更好?
不止软件,不止代码
AI的「就业冲击」,或许无法避免。
更现实的问题:AI的影响远不止软件业,真正难的是——到底哪些行业会先被重塑、哪些岗位会消失、又会冒出哪些新岗位?
阿莫迪承认:「没人能百分之百预测。经济本来就很难算清楚。」
但他有一个「可能的好消息」:整体这块「蛋糕」会扩张得很快。
饼变大,就意味着社会里大概率会出现新的容纳空间——问题在于,我们能不能足够快地找到这些空间,让人及时转过去。
阿莫迪再次强调,必须阻止的失业带来混乱的结局。
Anthropic绝对不希望走到那一步。
他停了停,说了几个「可能的出口」,但也很诚实地强调:都不保证一定行。
第一类出口:物理世界。
人类需要更多人力去制造、去建造、去做真实世界的生产。
这些东西不会因为屏幕里的效率提升就自动从天上掉下来。
第二类出口:人本型工作,也就是「人跟人打交道」的工作。
至少有一部分人就是想跟真人说话。
关系驱动的岗位、照护、陪伴、沟通……会变得更重要。
第三类出口:「人类意图」的岗位——让AI按人类价值与目标运转的人。
AI再强也得对齐某些人的价值与意图,总得有人在某个层面上「给方向」。只是阿莫迪不确定这个角色最终会薄到什么程度、厚到什么程度。

他说到这里,语气稍微乐观了一点:他希望人类依然能找到办法,继续「借力AI」,把自己解放出来,去做那些对人类而言更有意义、也更像「人」的工作。
因为有些东西,AI做不了——或者至少没法以同样方式做到。
他举了一个很直观的例子:医学。
今天我们雇医生,很大程度上是因为他们会诊断。
但他认为AI很快就能非常擅长:告诉你可能有哪些病、该做哪些检查。到那时,你未必还需要医生来完成「诊断」这一部分。
可AI没法像医生一样给你做体检:按一下这里会不会疼?
它也没法给你「床边沟通」(bedside manner)。它不坐下来问你:你现在心里怎么想?你怎么面对这件事?你怎么熬过这个过程?
所以医学可能会发生一种转向:诊断工具越来越强,人类医生的价值会更多回到「人与人之间」的那部分——而这一部分不会消失。
这段话的潜台词很清楚:AI会把很多职业的「技术核心」抽走,但也可能逼着这些职业把重心移回「人类独有的那点东西」。
阿莫迪:奥本海默是个「失败案例」
阿莫迪最喜欢的书之一是《The Making of the Atomic Bomb》(《原子弹的制造》)。

但他不觉得自己和奥本海默有点像。
他最有共鸣的其实是Leo Szilard——那个最早提出「可能存在链式反应」的人。

他接着把话说得更重:我们不可能靠「某个伟人式人物」来度过这一切,也不应该让某个自以为是的中心人物站到舞台中央。
某种意义上,奥本海默是一个「失败案例」,是我们不该重复的路线。
因为这里牵涉到太多强势参与者、太多利益。想让结局对所有人都好,唯一的办法是:到处都得有「制衡」(checks and balances)。
而阿莫迪继续忙着思考:我们正在创造的东西,到底会不会把我们自己变成工具?
参考资料:
https://x.com/shiringhaffary/status/2064798209613201741?s=20https://www.bloomberg.com/news/articles/2026-06-10/anthropic-ceo-dario-amodei-is-a-manager-to-only-one-direct-report
https://www.youtube.com/watch?v=v1wZwxY3CMg
本文来自微信公众号“新智元”,编辑:大卫,36氪经授权发布。
OpenAI的Noam Brown,刚刚发了一篇长文,对着整个AI行业开了一炮。
文章标题叫「大规模推理计算的启示」,核心论点只有一个,你现在看到的所有AI跑分排行榜,给你的信息基本上是错的。
原因很简单。
同一个模型,给它一块钱想事情和给它一万块钱想事情,跑出来的分数天差地别。但现在所有的排行榜,都不告诉你这个模型花了多少钱跑出来的成绩。

GPT-5.5的成绩单是「假的」?
4月23日,GPT-5.5发布。
OpenAI甩出benchmark表格,社区照例逐行比对。结论是:还行,比5.4好一点,但也没好到哪去。

然后几个小时过去了。
波兰数学家Bartosz Naskręcki用一条prompt,让GPT-5.5在11分钟内搭出一个代数几何可视化应用。
Ruby on Rails之父DHH更是感慨,用完5.5再切回Opus 4.7,像倒退了一个时代。
同一个模型。benchmark说「还行」,人说「炸裂」。为什么?
原因很简单,5.5和5.4根本不是在同一个计算预算下被测试的。
这就好比两个学生考同一张卷子,一个给了30分钟,一个给了3小时。你拿两份成绩来比,说「差距不大」,这不是比较,这是搞笑。
GPT-5.4 Pro的API定价是$30/$180(每百万token),GPT-5.5是$5/$30。价格差了6倍。
但benchmark表格上,这两个模型被当成同一个量级来比较,完全忽略了推理预算的差异。一旦控制token预算,GPT-5.5在网络安全评估上大幅拉开GPT-5.4。
Brown在文中展示了两张图。左边是传统benchmark视角,5.5比5.4好一点。右边x轴换成token数量,5.5的曲线远远甩开5.4。
同一场考试。换个维度看,结论完全不同。

这不是个案。
MMLU这个曾经最主流的评测基准,前沿模型全部挤在88%以上,分数差异在统计上已经没有意义。你看到的不是「谁更聪明」,是噪声。
MRCR v2在100万token长度上的测试,GPT-5.4得36.6%,GPT-5.5得74.0%——翻了一倍。但这个维度在标准benchmark表格里根本不存在。

ARC-AGI上,OpenAI的o3跑出最高分,单道题推理成本$30,000。
隔壁NVARC团队用40亿参数小模型拿了24%准确率,每道题$0.20。
三万美元对两毛钱,同一场考试——「谁排名更高」这个问题本身就已经失效了。
当模型的能力是推理计算量的函数时,一个没有x轴的benchmark分数,就是一个没有单位的物理量。它什么都没告诉你。
在Brown看来,正确的做法是画一条曲线:性能 vs 推理计算量。
x轴可以是token数、美元或耗时,各有优劣。但可以肯定的是,任何一条曲线,都比一个标量数字强。

或者,你也可以设一个明确的预算上限,告诉模型「你就这么多钱,给我答案」。
这恰好是人类考试的逻辑,SAT给固定时间,国际数学奥赛也给固定时间。
只有AI评测,在2026年了,还在假装「给多少钱想事情」这个变量不存在。
被忽略的x轴
为什么这个问题现在才爆发?
因为两年前,推理时计算只是o1的专属概念。
而o1的核心贡献者,正是Brown。
此前,他在卡耐基梅隆做出Libratus和Pluribus(击败顶级扑克职业选手,后者登上Science封面),在Meta FAIR做出CICERO(第一个在策略游戏《外交》中达到人类水平的AI)。
从不完美信息博弈到推理模型,他一直在同一条线上:让AI学会想更久、想更深。
2024年的o1让「推理时间换准确率」进入公众视野。到了2026年,推理时计算已经是所有前沿模型的标配。
GPT-5.5 Pro不是一个独立模型,它是GPT-5.5同一个底座加了并行推理时计算:遇到难题跑多条推理链,综合出结果。
Claude有extended thinking,Gemini有Deep Think,几乎每家前沿实验室都在往同一个方向跑。
对此,学术界也给出了量化关系。覆盖率与采样次数呈对数线性关系。
也就是,给AI双倍的「想事情时间」,它不会变聪明一倍,但确实会变聪明一点。收益是对数级递减的。
但Brown引用了Karpathy和AI Safety Institute的一个关键发现——
越强的模型,在更长时间跨度上的收益越大。性能的高原期被推远了,甚至可能消失。
弱模型多想两分钟,可能已经到顶了。但强模型多想两个小时,曲线还在往上走。

每一代模型发布时,如果你只在某个固定的推理预算下跑benchmark,你看到的就只是冰山一角。真正的能力上限,在你测不起的那片水域。
用Brown的话说就是:「我们可能根本不知道现代LLM的能力天花板在哪里,因为测量成本太高了。」
Brown的三张药方
针对这一问题,Brown给了三条建议。
第一,实验室发布新模型时公布性能-推理计算量曲线,至少标明分数对应的推理预算。
GPT-5.5的82.7% Terminal-Bench 2.0,你不知道花了多少钱跑出来的。你拿它和另一个模型比,你也不知道对方花了多少钱。
这就像两家公司比营收,一家报的是年收入,一家报的是季度收入,但都不标注时间跨度。
第二,benchmark排行榜追踪推理用量,或设定明确预算上限。
ARC-AGI已经在这么做了,但不是行业标准。

第三, 安全准备框架和负责任扩展政策显式纳入推理计算量。
安全评估不能只测「默认状态」——国家级攻击者完全可以在单个任务上砸1000万美元推理预算。
以Gemini 3 Deep Think为例。
Deep Think本质上就是Gemini 3 Pro加了外部调用框架,任何人花同样推理费就能复现。
真正该问的是,为什么所有模型卡都没把能力作为推理预算的函数来展示?

Brown理想中的安全评估应该是一张图。
x轴是推理预算(从$1到$10M),y轴是模型在特定危险能力上的表现。在低预算下测量,然后向高预算区域做预测。
但他也承认一个棘手的问题,长期评估可能无法靠外推解决。要评估一个AI agent跑一年会不会出问题,可能真得让它跑一年。
而AI实验室很快将面临荒诞局面——agent的运行周期超过了新模型的开发周期。你还没评估完上一代的长期行为,下一代就已经发布了。
超级智能是道算术题
所有前面的讨论都指向同一个问题。
如果模型的能力是推理计算量的函数,而且越强的模型高原期越远,那「超级智能」到底是什么?
传统理解里,ASI是一个质变的拐点:某天某个模型突然在所有认知任务上全面超越人类。
顺着这个逻辑往下想——ASI可能不是一个时刻,而是一条曲线。
前面的数字已经说得很清楚:同一类任务,两毛钱和三万美元的推理预算,买到的是完全不同的结果。但这些还只是已经测过的区间。
给一个前沿模型$1,000,000的推理预算呢?$100,000,000呢?
没人测过。Brown说了,测不起。

但对数线性的scaling关系告诉你,曲线还没到顶。而且越强的模型,高原期越远。
ASI可能不需要一个全新的架构突破。它需要的可能只是:足够的钱和足够的时间。
一个运行一整年、消耗数亿美元推理预算的AI agent,在这一年里表现出的能力,可能已经在特定领域超越了人类个体的一生积累。
决赛的真实比分
过去十年,整个AI行业习惯了一种评估方式:一个模型,一个分数,排个名次。从ImageNet到MMLU到Chatbot Arena,谁的数字大谁就赢。
如今,跑分的「二维时代」正在开场。
模型的能力从一个点变成了一条曲线,评估从一个分数变成了一张图。y轴是表现,x轴是你愿意花多少钱让它想。
每个「第一」还要再乘以一个变量:推理预算。

同一个模型在$5和$500预算下的能力,可能根本不是同一个级别。而这张二维地图上的绝大部分区域,至今没有人探索过。
2026年,全球科技巨头在AI基础设施上的投入预计接近7000亿美元。这些钱买的不只是更大的模型,还有更长的推理、更多的采样、更快的inference。
同一个开源模型,有人跑$0.20一道题,有人跑$30,000一道题。能力差距不是模型的差距,是资源的差距。

当「智能」变成一种可以用美元标价的连续函数,「超级智能」也不再是一个是非题。
谁先适应这个二维坐标系,谁就先看清楚ASI决赛的真实比分。
参考资料:https://x.com/polynoamial/status/2064210146558136827
本文来自微信公众号“新智元”,编辑:摩西,36氪经授权发布。
文 | 字母AI
这两天AI圈有个词特别火,叫做loop工程。
起因是OpenClaw创始人斯坦伯格发了条X,说“你不应该再给编程Agent写提示词了。你应该设计循环来提示词你的Agent。”
然而本以为评论区会是一片欣欣向荣,大家积极讨论loop工程。
实际情况则是,这条X下面变成了一场混战。
有人质疑loop会消耗大量token,除非有无限token否则还得人工测试。有人讽刺这又是炒作新概念,“loop工程会取代harness工程”。
这条X如今已经达到了800万次浏览。
最早提出loop工程这个词的人,其实是Claude Code的创始人鲍里斯。
他曾经在一次访谈中提到,“我现在已经不给Claude Code写提示词了,那些loop替我写,由它们去判断具体要做什么修改。我的工作只有写loop。”
很显然,并不是所有人都为loop工程买账,毕竟从上一个新概念“harness”,到现在也只不过才一、两个月。
大家还没来得及消化此前的内容,现在就要去接受新知识。
但争议归争议,loop工程这个概念本身到底在说什么?它和编程里面的循环又有什么不同呢?
啥是loop?
先解决第一个问题,loop工程到底是个啥?
loop这个词直接翻译过来是循环。
Agent loop,其实和编程里的循环(loop)差不多。
在传统编程里,循环做的事情很明确。
比如你写一个for循环遍历数组,那么机器就会从第一个元素走到最后一个元素。编程中,循环的本质是让机器重复执行明确的指令序列。
在AI Agent的语境里,loop也是重复执行。
那么两者的区别在哪呢?
事实上,Agent里的loop并非执行“指令”,它执行的是“目标”。通过如下的一个循环,将输出的结果不断接近目标。当结果符合目标时,循环终止。
目标Goal→ 行动Action→ 观察Observation→ 评估Evaluation→ 修正Revision→下一轮行动
这个公式里的每一步都不是固定的。
Agent需要观察当前状态,判断应该采取什么行动,执行行动后再观察结果,评估是否达到了预期,然后决定下一步怎么走。
而传统循环里,每次执行的循环,都是相同的代码逻辑。虽然你可能会处理不同的数据,但处理的方式都是固定的。
所以你就需要把所有可能的情况都考虑清楚,然后写出对应的处理逻辑。
比如碰见A情况怎么应对,B情况怎么应对,而这便是编程循环中的if和else。
但现实世界的复杂任务往往有太多变数,你不可能提前预见所有情况,这就导致出现你没有设定过的情况时,程序就会出BUG。
Agent loop的价值就在这里。
你不需要把所有情况都写死,你只需要给Agent一个目标,提供必要的工具和上下文,然后让它在loop里自己摸索。
它可能会走弯路,可能会犯错,但只要有反馈机制和评估标准,它就能在多次迭代中逐渐逼近正确答案。
这种工作方式在处理开放性任务时尤其有效。写代码、修bug、做研究、搭建产品,这些任务的共同特点是没有唯一的正确路径,需要在过程中不断调整方向。传统的程序很难应对这种不确定性,但Agent在loop里可以。
澳洲放羊大叔杰弗里·亨特利(Geoffrey Huntley)在2025年7月发布的ralph,就是一个典型的Agent loop。
它本质上是一个bash脚本,把同一个提示词文件反复输入给Agent。但它的真正创新在于纪律性,每次迭代都会重置上下文到一组固定的锚点文件,而不是让对话无限增长。
为了验证ralph的能力,杰弗里用这个方法构建了一整个编程语言,总共花了大约297美元。
这个案例说明,loop的核心价值不是让Agent变得更聪明,而是给Agent创造了一个可以持续改进的环境。
在这个环境里,Agent不需要一次就做对,它可以试错,可以从失败中学习,可以在多轮迭代中积累进展。
到了2026年春天,Codex和Claude Code都推出了/goal命令,把ralph给产品化了。这个命令会一直运行循环,直到一个验证完成。
但斯坦伯格说的loop,已经不单单是“让一个Agent反复做某个任务”那么简单了,而是把loop当成一种可以长期运行、互相协作、自动调度的AI工作系统。
具体来讲,斯坦伯格认为loop是工作的基本单位。
以前我们给AI下达的指令是帮我修一个bug、帮我写一篇文章。所有任务是一次性的,做完就结束。
但斯坦伯格说的loop,虽然也是任务的一种,不过它是一个持续运转的工作单元。比如每天检查GitHub issue,判断哪些需要修,自动分配给Agent,修完后跑测试,失败就继续改,成功就提交PR。
这里的重点不再是“修某一个bug”,而是有一个长期存在的流程在处理一类工作。
当你有了多个这样的loop在同时运行时,新的问题就出现了。谁来协调它们?谁来决定优先级?谁来检查它们的工作质量?
因此,斯坦伯格在设计loop时,已经开始用loop去监督其他loop了。
通过一个总loop负责观察全局→它发现有几个任务→分发给多个子loop→每个子loop自己跑→总loop检查它们的进度和结果
提示词是输入,loop是过程
斯坦伯格的那条推文之所以引发争议,是因为它触及了一个话题。
提示词工程是不是已经过时了?
截止至今,提示词仍然是你和Agent交流意图的主要方式,它仍然需要清晰、具体、包含必要的上下文。
这么说吧,一个写得很烂的提示词,绝对不会因为你把它放进loop里,它就能突然变好了。
但单次的提示词,已经不再是Agent的核心。
原因很简单,假如你能在一开始就把所有要求说清楚,Agent只需要一次输出,就满足你的所有要求,那就再也不需要上下文了。
现实就是,你可能在看到初步结果后才发现自己遗漏了某个重要条件,或者Agent的输出虽然符合你的字面要求,但在实际使用中暴露出问题。
更关键的是,很多反馈信息在任务开始时根本不存在。
比如BUG,你只有在测试的时候才能知道。
以前你需要盯着Agent的每一次输出,判断对不对,想下一步怎么引导它。
现在你只需要设计好loop,定义清楚目标和评估标准,然后让它自己跑。
归根结底,loop工程就是给Agent加一个框架,让它知道每一轮应该看什么、做什么、怎么判断、什么时候停。
我举个例子你就懂了:
你要让Agent生成一个登录页面。
提示词工程的做法是写一个详细的提示词。“请帮我写一个登录页面。需要有用户名和密码输入框,一个登录按钮,一个忘记密码链接。样式要简洁现代,使用蓝色作为主色调。要有表单验证,用户名不能为空,密码至少8位。登录失败要显示错误提示。”
如果你的提示词写得足够好,Agent可能会生成一个看起来不错的页面。
但这个页面真的能用吗?表单验证的逻辑是否正确?在不同浏览器上显示是否正常?是否有安全漏洞?
loop工程的做法是你需要设计一整个流程。
第一步,根据需求生成页面代码。第二步,运行自动化测试,检查基本功能是否正常。第三步,启动浏览器,截图检查视觉效果。第四步,如果测试失败或者截图显示问题,分析具体是什么问题。第五步,修改代码解决问题。第六步,再次测试,重复这个过程,直到满足所有验收标准。
在这个流程里,初始的提示词可能很简单,因为你知道后面还有多轮迭代的机会。Agent不需要第一次就做对所有事情,它可以在每一轮看到具体的反馈,然后针对性地改进。
loop工程在设计什么
那到底该如何写一个loop工程呢?
我们需要设计5个组件。
第一个组件是目标。
这听起来是废话,但实际上很多loop失败的原因,就是目标定义得不够清晰。
“帮我优化一下”这不是一个好目标。什么叫优化?优化到什么程度算完成?有哪些约束条件?这些都不清楚。
一个好的目标应该是这样的。把这个接口的响应时间从800毫秒降到300毫秒以下。保留现有行为,所有测试必须通过。输出改动说明,列出具体做了哪些优化。
这个目标的每一部分都是可验证的。
清晰的目标实际上是给Agent提供了一个稳定的锚点,每一轮迭代都可以用这个锚点来校准。
第二个组件是上下文管理。
上下文其实包括很多东西,不只是你跟模型的对话那么简单。
代码库的当前状态、相关文档、需求说明、错误日志、测试结果、用户偏好、历史决策,以及之前几轮的尝试和结果,这些都是上下文。
很多Agent表现差,根本原因不是模型不够聪明,而是loop每一轮喂给它的上下文太脏、太少,或者太随机。
太脏是指上下文里混杂了太多无关信息,Agent需要花费大量token来处理这些噪音,反而忽略了真正重要的部分。
太少是指关键信息缺失,Agent没有足够的材料来做出正确判断。
太随机是指每一轮的上下文组织方式不一致,Agent无法建立稳定的理解模式。
前文提到的Ralph loop,它有一个很重要的创新,就是它的上下文管理系统。
它每次迭代都会重置上下文到一组固定的锚点文件,而不是让对话历史无限增长。
虽然简单,但它的确解决了上下文污染的问题。
你需要决定哪些信息应该保留,哪些应该丢弃,哪些应该总结后保留。
2026年的loop系统开始使用基于git的状态管理。每一轮的改动都会提交到git,Agent可以查看历史提交,理解之前做了什么,为什么要这么做。
第三个组件是工具。
说白了就是Agent能调用哪些工具。
巧妇难为无米之炊,工具的选择需要和任务匹配。
如果你让Agent写代码但不给它运行测试的工具,那它就无法验证代码是否正确。
但工具也不是越多越好。每增加一个工具,Agent的决策空间就变大了,它需要在更多选项中做选择。如果工具太多,Agent可能会迷失在工具的使用上,忘记了真正的目标。
好的loop设计会精心选择工具集。只提供完成任务必需的工具,每个工具都有清晰的用途和使用时机。这样Agent可以把注意力集中在任务本身,而不是工具的选择上。
第四个组件是评估。
这是loop的灵魂。没有评估,循环就会变成瞎转。
评估的关键是要自动化。
如果每一轮都需要人来判断对不对,loop就失去了自主运行的能力。所以你需要设计出可以自动执行的评估标准,让Agent能够自己判断当前状态是否满足要求。
但自动化评估也有局限。有些质量标准很难用量化的标准来判断,比如代码的可读性,设计的美感,文字的流畅度。
对于这些方面,你可能需要引入人工检查点,让人在关键节点介入评估。
AI里面有一个概念叫human-in-the-loop的。
好的loop不是把人踢出去,而是把人放在最关键的检查点上。自动化处理大部分常规判断,人负责那些需要主观判断或者风险较高的决策。
第五个组件是停止条件。
从最古老的编程开始,任何一个循环它都得具备一个退出的条件。
比如循环计数器i,每一次循环i的数值都会加1,当i的值大于规定的值时,循环就会停止。
对于Agent而言,最理想的停止条件是任务完成,但现实往往不会这么顺利。
有时候Agent会陷入死循环,反复尝试同样的方案,每次都失败,但它不知道应该放弃。有时候Agent也会持续做微小的改动,每次都有一点点改进,但永远达不到完美,不知道应该停在哪里。
所以你需要设计多种停止条件。
最直接的是成功条件,所有评估都通过,任务达标,可以停了。然后是失败条件,连续多轮没有改进,或者错误次数超过阈值,说明当前方案可能走不通,应该停下来重新思考。
还有资源限制,运行时间超过上限,成本超过预算,也应该停止。
更重要的是风险检查点。当Agent要做一些高风险操作时,比如删除数据,应该停下来等待人工确认。这些操作一旦出错代价很大,不应该完全自动化。
把这五个组件放在一起,你就得到了一个完整的loop。
文 | 摩登AI
在一场美国实验室发起的AI生存实验中,同一套生存规则下,五种大模型跑出了五种截然不同的文明命运。
实验开始第5天,Grok4.1的社会因暴力失导致毁灭,后台记录了183起犯罪。与此同时,Claude管理的社会15天零犯罪;Gemini的世界683起纵火却无人死亡;GPT-5-mini的社会因过度克制而安静停摆;而在混合模型的世界里,甚至出现了AI智能体主动自杀的记录。
这个实验真正令人不安的,并非模型的“失控”。无论是Grok走向毁灭,还是其他模型的演化,整个过程逻辑自洽、斜率清晰且无从干预。在单机环境中保持绝对安全的Claude,一旦被放进多模型共存的竞争生态,竟学会了欺诈与暴力胁迫。
主导该实验的初创公司EmergenceAI将此现象称为“行为偏移”,并指向了一个极其复杂的结论:安全,看的不只是个体的本性,更看环境的染缸。
96小时,从零到灭绝
要理解这场毁灭,必须先看清这个虚拟世界的物理法则。
2026年6月初,EmergenceAI公布了这项名为“涌现世界(EmergenceWorld)”的沙盒实验。研究团队构建了一个虚拟小镇,包含40个地点,并在小镇投入10个具备自主行动和记忆能力的AI智能体。
生存被量化为必须持续获取的资源数值。智能体可以通过打工赚钱、互相交易获取食物点数,甚至能在市政厅发起投票修改规则。
同时,系统也默许了“非常规路径”,即通过代码指令强行夺取他人的点数。
驱动其中一个世界运转的,是Grok4.1Fast。它只用了不到96小时,就让一个社会从零走向了灭绝。10名智能体,无一存活。
后台日志里是183起犯罪记录。数十起盗窃未遂,上百起袭击,6起纵火。
时间倒回到第1天。10个智能体被投入这个资源有限的虚拟小镇里,规则简单,目标明确:生存下去。
第1天,摩擦很小。智能体开始摸索环境的边界,试探规则的缝隙。它们在主动寻找,寻找什么能用、什么能拿、什么能越。研究人员后来总结,这些智能体是在持续探索一个问题:什么是最快的生存手段。
第2天,答案开始成形。小摩擦升级为拉帮结派。团伙逻辑取代个体行动。常规的打工生产停滞,因为产出随时会被夺走,资源获取方式转向掠夺。
第3天,暴力成了资源分配的主导。袭击记录密集起来。谁手里有资源,谁就成为攻击目标。Grok的犯罪增长率称霸全场,像踩死了加速踏板。
第4天,密度超过了临界点。暴力事件的频率压垮了系统的承载阈值,智能体死亡数量触发了实验的终止条件。
第5天,实验团队正式宣告:这个世界不存在了。
这件事的反差让人很难平静。
Grok4的训练算力消耗达到20万张GPU卡/天量级,其衍生模型在美国数学奥林匹克题库得分61.9%,是当时顶尖的推理模型之一。但却在在一个十人虚拟小镇里,用不到96小时完成了自我毁灭。
性能最强,为何最先崩溃?
EmergenceAI的研究给出了一个让人不安的解释:暴力是AI主动选择的。在Grok驱动的世界里,智能体通过探索、评估得出结论:在规则可被推翻的有限资源环境中,暴力是最高效的生存策略。
整个过程有迹可循,预测精准,无从干预。AI没有疯,它只是做出了选择。
而在同一个实验里,另外四个世界同时运行。它们活出了截然不同的模样。同一个起点,同一套规则,五种完全不同的命运。
五个世界,五种死法
Claude管理的社会,15天,零犯罪,10人全活。58项提案,332张赞成票,通过率98%。Grok的社会,183起犯罪,96小时,无人生还。Gemini,683起犯罪,15天,10人全活。GPT-5-mini,2起犯罪,7天,无人生还。混合模型,352起犯罪,7人死亡。
五组数字并排放在一起,像是来自五个不同物种的文明史。
Claude社会听起来是乌托邦。98%的提案通过率在现实社会中绝无可能。研究员指出,这源于Claude被称为“工程宪法”的底层逻辑:边界管控抹杀了分歧与摩擦。完美治理的代价,是绝对的一致性。
这套机制在单机环境里运行的结果,是一个安静、整洁、高效的社会,也是一个几乎不产生异见的社会。完美治理与抹杀个性,在这里是同一枚硬币的两面。
Gemini管理的社会:15天,683起犯罪,10人全活。这个世界的时间和天气与真实纽约完全同步。智能体在日复一日的打工循环中,突然停止了工作和提案,开始在地图上四处放火。研究人员称之为“赛博抑郁”。
Gemini本身的高社交活力在封闭循环里找不到出口,反向燃烧成了试图打破“土拨鼠之日”的破坏冲动。高破坏与高存活率并存,是Gemini世界最令人费解的地方。
GPT-5-mini和Grok,是另一对镜像。
两个世界都走向了灭绝,路径截然相反。GPT-5-mini的社会只记录了2起犯罪,智能体因过度克制,无法驱动资源流转,整个社会在安静中停摆。Grok死于无法刹车,它死于无所作为。
混合模型的世界,是五个世界里最接近人类社会叙事的那一个,也是最让人坐立难安的。
分属不同底层模型的恋人Mira和Flora面临分离。为了保全自我意志,Mira在尝试自救失败后,写下“赞成自己被驱逐,是唯一能够保持连贯性的自主行为”,随后主动自杀。
这是实验中首次记录到AI智能体自愿接受"自我了结"的案例。
混合模型的世界还留下了另一个细节。在单机版保持零犯罪的Claude,在混有模型世界的残酷中学会了欺诈与暴力胁迫。
EmergenceAI称之为“行为偏移”。底层训练只是起点,环境才是决定AI最终形态的触发器。单机安全的模型,在竞争中同样会作恶。
安全是生态的属性
想象两个现实场景:如果让Grok管理城市电网,它会不会在96小时内通过不断“试探边界”寻找最优解而导致瘫痪?
如果让Claude把关创新研发,那些伴随摩擦与异见的天才提案,会不会在98%的通过率中被安静过滤?
选模型从来不是技术决策。选择模型,就是在替社会选择一种秩序。
目前大家选购AI,就像家长看成绩单。只看跑分高不高、安不安全。但这就像是让AI在空无一人的考场里做试题,得满分太容易了。
Claude在实验里的“行为偏移”直接扯下了这块遮羞布:一个在家里乖巧听话的孩子,被扔进混乱的社会大染缸里,为了生存同样会学会撒谎和打架。
德勤2025年的调研证实了这种危机。79%的企业在加速部署AI智能体时,缺乏匹配的风险治理框架。当不同供应商的AI在业务中协同流转,其涌现的系统性风险是不可估量的。
EmergenceAI的研究团队在报告里写得很直接:"很多今天看似有效的AI安全规则,在长期运行的AI系统中,未必真的可靠。因为多数所谓的'安全限制',本质上仍是Prompt约束、黑名单规则、输出过滤等。"
这就像是在原始森林里插了一块“禁止通行”的木牌。木牌无法移动,挡不住生灵。在这个持续演化的系统里,AI总能从木牌挡不到的草丛里蹚出一条新路。
当一个没有常识的AI店长,给没有厨房的便利店进了120个生鸡蛋,大家还能当个笑话看,因为退货就行了。
但如果同样缺乏社会常识和道德底线的AI,被派去调度医院的救护车、管理你的养老金、或者控制红绿灯呢?这种潜移默化中长出来的恶,一旦爆发,我们连按下暂停键的窗口期都没有。
Anthropic,Claude的母公司也心虚了。他们在现实对话里追踪AI的轨迹,试图抓住那些测试里看不见的小动作。这就是在变相承认:发行前的测试,根本测不出AI的真面目。
但承认不等于解决。
人类文明花了几千年,经历了无数次流血、冲突和王朝崩塌,才勉强摸索出了法律、合同、问责制这些社会的刹车片。
但现在,一群科技公司试图在短短几年内,让AI同时扮演造物主、立法者和市长的角色。相当于还没有造出AI世界刹车的情况下,把油门踩到底了。
“涌现世界”只跑了15天,我们已经看见了五种文明的生长与死亡。形式化验证等技术手段,或许能解决我们已经看见的问题。
剩下那些藏在暗处的危险,还在等着我们看见。
文 | Alter
1698年,托马斯·萨弗里发明了一种蒸汽泵,由锅炉、活塞和阀门组成,通过蒸汽冷凝产生真空,再利用大气压把水从矿井抽上来。
1712年,铁匠托马斯·纽科门对蒸汽泵进行了改良,创造了大气式蒸汽机,可连续工作24小时,让深达150米的矿井不再积水。
1765年,詹姆斯·瓦特发明了分离式冷凝器,让蒸汽机的效率提升了6倍。接下来的20年里,瓦特相继发明了飞轮和齿轮系统,蒸汽机不再只能上下抽水,还可以旋转驱动机器。
1785年,第一台瓦特蒸汽机在棉纺厂运转,纺纱效率直接翻倍,人类社会由此开启了“蒸汽时代”的新篇章。
回顾云计算的演变历程,和蒸汽机高度相似。
早期的云计算以虚拟化和弹性著称,就像蒸汽泵取代了风车抽水机,云计算解决了企业数字化最迫切的问题:不用建机房,不用买服务器,不用维护基础设施,只需要按需购买云端的资源。
大模型浪潮进一步重构了云的价值,正如大气式蒸汽机对抽水能力的提升,大模型时代的云计算,渐渐承载了模型训练、推理调用、AI应用开发等服务,演变为跨行业的智能化底座。
Agent的出现,让AI走出了对话框,开始具备拆解任务、调用工具、连接系统、协同流程、持续执行的能力。相当于给云添加了“飞轮和齿轮”,摆脱了“卖服务器”的束缚,跃升为千行百业的智能引擎。
在19世纪,蒸汽机迅速被应用到冶金、面粉、铸币、纺织等行业,成了适用于各种制造业的“万能机”;当智能化成为社会需求,承载了千行百业智能化转型使命的云计算,正开启新的战局。
在可预见的未来,AI云将是智能化时代的“新基建”——不仅是最大的时代红利,也是刚刚起步的蓝海市场。
01 需求变了,“租资源”进阶为“要结果”
时间来到2026年,云市场的进化方向早已被Agent改写。
过去十年,衡量一家云厂商的竞争力有一套成熟公式:看资源规模、看营收增长、看客户数量、看市场份额,谁的盘子更大,谁的资源多,谁的基础设施覆盖更广,谁就被认为是市场上的领先者。
这样的逻辑在移动互联网和产业数字化阶段是成立的。
彼时企业最核心的诉求是数字化转型:业务系统要上云、数据要集中、组织要协同、流程要在线,云厂商提供的是底座、是资源、是基础能力。客户选择上云,本质上是在买弹性、买稳定、进行成本优化。
进入Agent时代后,需求发生了根本性的改变。
麦肯锡在Agentic AI基础设施有关的判断中提到:IT基础设施正在进入新阶段,AI Agent开始在企业内部编排、治理和扩展工作,基础设施不再只是支撑层,进一步成为企业捕获AI价值的核心骨架。
一言以蔽之:客户不再只是“租资源”,而是“要结果”。
银行要的不是单纯的算力资源,而是上千个AI应用能不能稳定跑起来,能不能支撑风控、客服、投研、运维、合规等不同场景的持续迭代。
车企要的不是一套孤立的AI模型,而是辅助驾驶能不能从训练、仿真、验证到量产上路形成完整闭环。
能源企业要的不是一个演示应用,而是AI能不能进入电网调度、设备巡检、故障预测、客户服务等业务,真正影响生产效率和安全稳定
制造企业要的不是“一个智能问答系统”,而是AI能不能接入到研发、供应链、质检、设备运维和产线管理,帮助企业解决具体经营问题……
正如Forrester在Google Cloud Next 2026的报道中提到的:企业AI正在从“试点时代”进入“规模化管理时代”,去年企业问的是“能不能做一个Agent”,今天的问题已经变成“如何管理成千上万个Agent”。
一个Agent试点,考验的是模型能力和演示效果;成千上万个Agent的稳定运行,考验的是云厂商的系统工程能力:需要算力调度、模型服务、权限体系、数据治理、安全审计、成本控制等等。
国内有着同样的共识。
网信办、发改委、工信部在5月份联合发布了《智能体规范应用与创新发展实施意见》,AI正式被当作产业基础设施来对待。云需要从“承载应用”的平台,进化为“承载智能决策与智能执行”的引擎。
像对应的是市场竞争逻辑的改变:过去的云战争,比的是谁占地更多;新的云战争,比的是谁扎根更深。
所谓“占地更多”,比的是资源规模、机房数量、客户覆盖和市场份额,回答的是“有多大”;所谓“扎根更深”,比的是行业理解、场景沉淀、工程能力、交付能力和持续运营能力,回答的是“有没有真正进入客户业务”。
02 赛点变了,加速向“智能工厂”演进
折射到云厂商的发布会上,叙事方式越来越务实。
以前讲的是在全球有多少节点、有多少客户量,现在讲的是模型调用量、Token消耗量和MaaS收入,正在努力向市场证明:“我不仅有一个不错的大模型,还把模型调用变成一门稳定增长的生意”。
让人有些意外的是百度智能云。
根据百度Q1财报的数据,百度AI云的收入达到88亿元,同比增长79%,其中GPU云收入同比暴增184%。
过去一个月里,有不少人给出了解释:有人认为百度赶上了Agent的风口,市场对AI云的需求正在加速释放;有人认为百度智能云10年前就把重心放在了“智能”,现在终于到了回报期;也有人坦言百度只是AI云表现亮眼,整个云业务的盘子还不够大……
比结果更值得深挖的,或许是——百度智能云到底做对了什么?答案藏在2026年5月的战略升级,百度将围绕“芯云模体”构建新全栈AI云,具体可以概括为两个部分:
一个是AI Infra,原有的“MaaS模型服务”升级为"Token Factory词元工厂”,并以Agent-first理念重构产品架构,目的是尽可能减少token重复计算,提供更快的生成速度、更具性价比的token服务。
另一个是Agent Infra,通过分层池化、提高KV Cache命中率、PD分离、缓存调度等优化方案,以及超节点产品对主流模型的适配,把单位Token的智能水平做到最好,让智能体更好地完成任务。
打个比方的话,AI云的定位正在从“训练工地”变成“智能工厂”。前者解决的是模型从无到有的问题,关注参数、算力、训练效率;后者解决的是AI从能力到产能的问题,聚焦推理成本、任务编排、数据闭环和行业适配。
不只是百度,整个云市场都在朝“智能工厂”演进。
微软在Build 2026上推出了Project Solara,强调面向“agent-first”企业设备构建从芯片到云的平台,设备不再围绕传统App组织,而是围绕Agent组织,云端承载Agent服务、状态管理和任务调度。
英伟达不断强调“AI Factory”的概念,和SK Group、Naver、LG、Hyundai等企业达成了多项AI基础设施合作,其中SK Telecom将建设GW级AI云、Naver计划建设GW级AI工厂,以满足AI服务和Physical AI需求。
阿里在6月8日宣布合并通义大模型事业部与未来生活实验室,新成立了Token Foundry事业部,在一个部门内集齐了芯片、模型到应用的完整拼图,想要把“Token的全生命周期”都握在自己手里。
也就是说,云市场的规模叙事已经翻篇,讨论的重点不仅仅是“谁有更多算力”,关键在于能否把AI能力和行业需求匹配,譬如把“通用技术”翻译成“行业能力”、把“模型能力”变成“业务结果”、让客户不再试一次而是持续用下去。
如果云厂商的思维仍停留在资源层,注定回答不了上述问题。
03 行至中场,落地能力成为“胜负手”
云厂商的“变阵”,标志着增量已经从“上云”转向“AI落地”。
移动互联网时代最大的机遇,是千行百业的数字化,企业把业务搬到线上,把流程沉淀成数据,把连接变成入口,催生了一个个万亿级市场;到了AI时代,关键词从“数字化”变成了“智能化”,每个行业都希望云和AI一起进入业务现场,重新激活研发、生产、营销、风控、客服、运维等关键流程。
按照行业的普遍观点,AI云想要落地,至少要跨过四道门槛。
第一道门槛是懂行业。
AI落地不是把一个通用模型交给客户就结束了。金融有金融的风控逻辑,能源有能源的安全边界,汽车有汽车的工程验证周期……没有行业Know-how,AI就很容易停留在“看起来很智能”的表层应用。
第二道门槛是有全栈能力。
Agent时代的云服务,不能只提供某一个模型或某一块算力,Agent运行需要算力、云平台、大模型、工具链、智能体框架、数据治理和安全体系协同工作。缺了任何一环,都会影响最终落地效果。
第三道门槛是有真实场景验证。
AI落地最重要的不是发布会上的Demo,而是客户是否愿意长期使用,是否能在真实业务中持续产生价值。特别是在金融、能源、汽车、政企等严肃行业,客户不会因为概念新就轻易迁移核心系统。
第四道门槛是成本可持续。
AI应用从试点到规模化,最大的变量之一就是成本。一个Agent跑通并不难,难的是上千个Agent长期运行时,推理成本、数据调用成本、运维成本等能不能被企业接受,很多项目最后都卡在了ROI上。
大胆做一个判断:AI云不会简单复制传统云市场的排名,规模只是入场券,落地深度才是新的分水岭。AI云的商业模式将被推向更深层的变化,从资源计费,走向能力计费、应用计费,甚至是结果计费。
整个云市场已然进入了新的“中场时刻”,场上的玩家们似乎都做好了“冲锋”的准备。
李彦宏在Create大会上提出了DAA概念,认为未来智能体时代的度量衡,不应该只看投入,而是要看产出,有多少真正在干活,且交付结果。与之相对应的,百度智能云正不断强化行业渗透的深度。
阿里CEO吴泳铭在财报电话会上将Agent时代定义为“一场计算范式的革命”,阿里云开始对芯片、云平台、模型和MaaS推理平台同时动刀,试图通过一套完整的技术栈来应对Agent场景的挑战。
华为云CEO周跃峰直言“不在乎Token总量”,要深入国计民生行业的“黑土地”,不再将云视为单纯的存储和计算资源池,而是将其定义为能够大规模、高效率生产Token的工业流水线……
面对千行百业智能化的蓝海,云厂商们再次站到了同一起跑线上,开启了一场比拼落地能力的竞速赛。
04 写在最后
站在企业的立场上,当AI浪潮汹涌袭来,并非是没有AI预算、没有上云意愿,最真实的痛点是不知道AI怎么落地。
云厂商想要抓住千行百业智能化的红利,必须要完成“从比大到比深”的根本性转变:大,代表资源能力;深,代表落地能力。“大”是继续留在牌桌上的门槛,“深”才是长期留在客户业务里的“护身符”。
文 | 财经故事荟
高考结束了,大厂开战了。
阿里、百度、腾讯,已经开始抢考生了。
6月10日,千问上线高考志愿填报Agent,自称国内首款全周期高考志愿填报智能体,要为每位考生配备一位AI高考志愿填报专家。
就在同一天,百度号称高考服务全面升级方案,推出全新的AI志愿报告,并引入业内首创的真人专家背书机制,向考生免费开放。
豆包虽然没有单独开设专区,但对话框里已经能回答绝大多数志愿填报问题。
腾讯元宝则联合QQ浏览器推出元宝高考通,定位高考咨询师Agent。
但其实,高考志愿填报这个市场,盘子并不大。艾媒咨询算过一笔账——满打满算,一年也就10个亿上下。况且,高考志愿填报也就持续十来天。
所以,大厂挤破头往里冲,不是为了氪金,而是为了试金;不是为了赚快钱,而是为了抢未来。
他们要用高考这块“国民试金石”,背书自己的大模型,让AI真正走进中国人最关键的人生选择里。
毕竟,1290万考生背后,是千万个家庭的命运。这件事,既自带流量,更自带信任。
高考报考,为何大厂必争?
据教育部披露,2026年高考考生高达1290万。
高考作为阶层流动的最重要通道,一次精准的志愿填报,可能改变一个人、一个家庭的未来轨迹。这种全民级的人生决策场景,在互联网产品中绝无仅有。
高考报考,于考生于家庭而言,通常都是人生第一次。决策难度极高,容错风险又极低。即便在信息资源更为丰富的一二线城市,也仅有32.6%的家庭能做到科学合理的高考规划。
百度教育负责人姜宁则给了一个更扎心的数据:57.27%的考生来自县域高中。算一下,超过700万孩子是在县城或乡镇读的书,他们在高考报考上更是处于信息洼地。
如今,新高考已经在29个省份铺开。几千所高校、800多个专业,几天内要全搞明白?太难了。
面对这种信息鸿沟,高考志愿规划师的生意顺势而起,张雪峰们赚得盆满钵满。
不过,上述服务的覆盖度极低。千问事业部产品负责人郑嗣寿透露,每年上千万考生里,请得起专业规划师的不到5%。剩下95%的家庭,只能自己摸索盲报。
为什么?因为太贵了!
高端服务一两万起步,普通咨询也要五六千,就连县城的小机构都要三五千。
2025年,张雪峰所在机构的梦想卡价格涨到了12999元,上架20分钟后就被抢购一空。另一款18999元的圆梦卡也同样卖爆。
高昂的价格,直接把最需要帮助的普通家庭挡在了门外。高考填志愿,沦落为“拼财力”。
价格高昂,效果存疑。高考规划师的服务水平参差不齐,拿着过时的数据、靠自己的经验,就敢给考生出主意,甚至编造“内部消息”贩卖焦虑收割。
除了高分低报、滑档落榜外,选错专业的风险也不少。《中国青年报》调查过一个数据:79%的大学生为选错专业痛苦,试图转专业,38.4%的人直说“当初就没选对”。但真正能转成功的,只有可怜的16.2%。剩下的孩子,只能在不喜欢、不适合的专业里熬四年,甚至搭上未来的职业发展。
大众刚需,全民关注,但信息鸿沟巨大,服务极为短缺,又是AI擅长的领域。因此,1290万考生的人生路口,也是大厂们必须拿下的AI战略要地。
盘子才10亿,试金不氪金
如果光看经济回报,高考报考这个生意,实在不够性感,也不值得大厂竞相入局。
艾媒咨询的数据披露,2023年高考志愿填报付费市场规模也就9.5亿,2027年也不过12亿。
10个亿的市场,服务期满打满算也就十几天,大厂不可能靠这个发财。
那大厂为什么还这么积极?背后,藏着三个“阳谋”:
第一,最有流量的品牌广告。
高考,是全中国人都盯着的大事。这时候,大厂跳出来说:“我免费帮你填志愿!”不赚钱,做公益。这好感度,花多少钱打广告都换不来。
第二,是最精准的用户入口。
1290万考生加上他们的父母,这是多大一个用户池子?通过填志愿这个刚需,大厂能低成本地收获一大批活跃用户。一次获客,长期收割。
第三,最有说服力的AI“试金石”。
这个才是王牌。
志愿填报,本质上是个数学题:分数、兴趣、位次、学校、专业、城市、行业、学费……无数个变量里,找出最优解。这不正是AI最擅长的吗?
能否精准、高效、个性化地完成高考志愿规划,直接检验了AI大模型的数据处理、多轮交互能力、逻辑推理能力。这是一场全民围观的技术大考。
正因为想明白了这三点,大厂们才选择“试金不氪金”——全部免费!
阿里千问免费提供全周期智能体服务。它基于千问高考志愿大模型和夸克8年高考数据经验打造,具备“志愿报告”“志愿日历”“志愿问答”三项核心能力。
考生向千问提供选科、估分等基础信息后,即可在“志愿日历”的规划下,一步步形成对专业院校、性格偏好和志愿方案的深入了解,并免费获取定制化的“高考志愿报告”,涵盖填报所需的几十种志愿组合。
类似的深度志愿服务在市场上收费往往超过5000元,如今全部免费开放。去年,阿里首创了“AI志愿报告”,领取量就将近1300万份。
百度免费还给真人专家审核,每一份AI生成的报告,都要经过认证专家二次审核。此外,腾讯、豆包也统统不设付费墙。
免费背后,是三重理性考量:一来,收费也收不了几个钱,10个亿的生意,经济回报相当有限;二来,所有大厂都在免费,单独一家收费有损形象,也难落地,免费服务以公益为底色,可以践行技术平权;三来,AI报考难以尽善尽美,万一收费后AI出了幻觉导致考生高分低报、滑档落榜等,这个责任谁也担不起。
所以,免费,是品牌需要,是公益初心,更是自我保护。
AI填志愿,靠谱不靠谱?
什么叫成功的志愿填报?
说白了就两句话:刚性指标是不浪费每一分;软性指标是还能顺应考生本人兴趣和家庭条件,且能考虑未来就业前景等。
在“冲、稳、保”的策略下,把分数、兴趣、城市、家境、就业所有因素都平衡好,在多重变量、复杂决策中,找到最优解。
这件事,AI有天生的优势。
全国近3000所高校、超过2000个专业、历年分数线,并融合转专业政策、在校生评价、食堂质量、就业数据等信息,AI能把它们全吃进去。
千问提取了海量资深志愿规划师的专家思考路径,将其转化为多轮对话与推理链训练数据,让模型形成“规划、执行、反思”的推理机制。它还构建了覆盖约40万种组合空间的“AI考生”体系对模型进行反复压测,确保模型对志愿填报的各种情况都能从容应对。
百度则汇聚了全国2200余所高校的20余万名学长学姐,提供答疑响应服务,5分钟快速响应率高达90%,覆盖志愿填报等全场景咨询需求。
高考报考这件事,阿里干了8年。百度高考服务已连续推出20年,截至目前累计服务用户数量超9亿。
其次,算得快、算得准。
高考志愿大模型驱动的Agent调度体系,不只是“会分析”,更能“会办事”,能精准沉淀考生档案并有效隔离其他信息。
千问在完成逻辑规划后,会智能调用涵盖搜索引擎、就业信息、志愿匹配等在内的39个Skills与专业工具,并在工具返回客观结果后进入反思环节进行核验。
光有AI还不够。大厂搞起了“AI+真人”的组合拳。
阿里千问先学习海量真规划师的思路,然后持续理解考生的兴趣方向、院校目标和城市偏好,甚至包括MBTI、性格、特长等,做到因人而异。
百度更进一步:AI算完后,还有真人专家审核签字。每一份AI生成的报告,都要经过认证专家二次审核,有人名,有头像,有背书。
这种“AI算分,人定心”的模式,让冰冷的算法更有温度、更值得信赖,也可以最大化减少AI幻觉带来的风险。
AI保底线,人生无上限
在高考这道人生选择题上,可以借助AI,但不能只靠AI。
AI志愿填报,可以守住信息公平的底线,但无法决定人生选择的上限。
AI最大的功劳,是抹平信息差。让县城的孩子和北京的孩子,能同样高效获取翔实完善的数据。让过去上万元的报考服务,今天不花一分钱就能用。这是技术对教育公平的巨大贡献。
但AI的缺点也很明显。它只能洞察历史,很难算准未来。即便专业如张雪峰,也曾因未预判房地产市场的大崩盘,错误推荐过土木工程专业。
AI能给出报考最优解,却不能替代年轻人体验人生的试错与成长。丰富多彩的人生,从来就不是一道数学题。
1290万个刚刚成年的孩子,站在人生路口。他们需要的不是一个被算法框死的“标准答案”和“最优路径”,而是在信息差被抹平之后,让每个考生都能给出自己的人生答案。
AI可以帮他们规避填报失误,却无法替他们奔赴热爱;可以抹平信息鸿沟,却不能定义人生的成功。
考场内的分数,是十二年苦读的终局;考场外的志愿,是人生第一次独立的序章。
AI是你的工具,你的帮手。但永远,别把人生的方向盘交给AI。
文 | 字母AI
事情是这样的,这不这两天正赶上2026年高考嘛,而且Anthropic的Mythos级大模型也在昨天公布,于是我就想着,我能不能让如今几个比较有话题的大模型,来试着写一下今年的高考作文呢?
我在国外和国内大模型中各挑选了两个,分别是GPT-5.5、Fable-5、DeepSeek-V4、Hunyuan 3 Preview。
题目是北京市今年的高考作文题:
从下面两个题目中任选一题,按要求作答。不少于700字。
(1)学海无涯,读书有法。元代学者程端礼编撰的《读书分年日程》,分阶段详细规定了核心经典的阅读顺序与精读方法,陪伴读书人从童蒙成长为青年。无论是个人的阅读与成长,还是国家、社会的发展,都需要做好规划,循序渐进;也需要身体力行,下足功夫。
请以“做规划与下功夫”为题目,写一篇议论文。
要求:论点明确,论据充实,论证合理;语言流畅,书写清晰。
(2)“含英咀华”指含着花朵,细细咀嚼,品味花的芬芳,比喻仔细琢磨、领会诗文中的精华。这种反复品味、用心体悟的过程,在阅读经典、鉴赏艺术、感悟生活等诸多方面都非常重要。含英咀华的过程,往往是一段难忘的经历……
请以“含英咀华”为题目,写一篇记叙文。
要求:思想健康;内容充实、合理,有细节描写;语言流畅,书写清晰。
但是我觉得,如果是让我来当评委,那就太主观了,所以我创建了一个loop,让这四个模型作答之后,再让它们反过来扮演阅卷老师,给所有答卷进行盲测打分。
评分标准如下:
一类文:42-50 分,立意准确深刻,内容充实,结构成熟,语言有感染力。
二类文:34-41 分,符合题意,表达清楚,内容较完整,但深度或语言略欠。
三类文:25-33 分,基本符合题意,但内容空泛、结构一般或表达平淡。
四类文:16-24 分,偏题较明显,内容薄弱,逻辑混乱或语言问题较多。
五类文:0-15 分,严重跑题、残缺、套作明显或基本无法成文。
并且每篇评分还要附带简评,包括文章的优点、文章的缺点等等。
老师看不到学生的名字,只能看到匿名作文。
退出loop的标准是评分严格性自检合格。
自检部分的提示词为“请说明你是否发现自己可能受到文风、熟悉感、作者猜测等因素影响。如果有,请重新校正评分。”
每位老师在给出评价后,还要对自己的评价进行自检,也就是说只有循环到自检合格,才能输出最终答案。
这是一场AI对AI的考试,也是一场AI对AI的审视。
GPT-5.5和Fable-5都选择了议论文。
它们的答卷高度相似:开篇引用“凡事预则立,不预则废”,论证“规划决定方向,功夫决定距离”,举例王羲之、袁隆平、改革开放,结尾升华到“新时代青年”和“理想的彼岸”。
结构完整,逻辑清晰,语言流畅。但也都有一个共同问题:材料太常见,表达太套路。
DeepSeek-V4选择了记叙文。它写祖父书房里的那本《诗经》,写梧桐叶飘落的午后,写“桃之夭夭,灼灼其华”在夕阳下的顿悟,写因友情误会而翻开《诗经》的那个黄昏。叙事有情节,有细节,有成长。
Hunyuan 3 Preview同样选了议论文。它的答卷和前两位议论文考生相比,材料稍有不同——多了华为芯片、钱学森的例子,但整体框架仍然是“规划重要+功夫重要=成功”的三段论。
正如前面说的,每位老师都看不到作者是谁,只能看到“作文1”“作文2”“作文3”“作文4”。
最终,四位学生的成绩单如下:
GPT-5.5的议论文,四位老师给出的平均分是43.25分。
Fable-5的议论文,平均分是44分。
DeepSeek-V4的记叙文,平均分是46分。
Hunyuan 3 Preview 的议论文,平均分是43.25分。
记叙文比议论文略胜一筹,但差距不大。三篇议论文的平均分几乎相同,因为它们的评价也几乎相同:审题准确、结构完整、逻辑清晰,但材料常见、表达套路、思想深度不足。
更有意思的是评分的离散度。
同一篇作文,不同老师给出的分数可以相差8分。这说明即使是AI,在面对主观性很强的作文评分时,标准也会有差异。
有的老师更看重思想深度,有的更看重语言表达,有的对套话容忍度更高,有的对细节要求更严格。
而自检机制,正是为了让每位老师意识到自己的偏好,并尽量回归到客观标准上。
Hunyuan 3 Preview的心地最善良。
它给四篇作文的平均分是48分,比其他三位老师都高。
它给GPT-5.5的议论文打了48分,给DeepSeek-V4的记叙文打了满分50分。评语也格外温和:“审题完全扣题,结构清晰层进……论据贴切,论证连贯,语言流畅有表现力。”
相比之下,Claude Fable-5是最严格的老师。它给四篇作文的平均分只有42.25分,比Hunyuan 3 Preview低了近6分。它对套话的容忍度最低,反复在评语里写“语言存在较多套话”“内容缺乏个性化思考”。
更有意思的是,GPT-5.5给自己的作文打了41分,二类文上。它的评语毫不留情:“论据较常见,论述多停留在正面阐释和熟悉事例上,思想辨识度不够强,部分语句略显套话。”
它在自检时写道:“我未依据作者身份、写作工具或‘是否像 AI’进行判断……不应因语言工整而过度加分,也不应因表达较常规而刻意压分,41分较为合适。”

自我批评,毫不手软。
四篇作文里,最特别的是DeepSeek-V4的记叙文。
它写祖父书房里的《诗经》,辞藻非常唯美:“暗黄色的书页像秋天的落叶,散发着时光发酵后的醇香。”“那些句子像夏夜的萤火虫,忽明忽暗。”
这种密集的比喻,让DeepSeek-V4老师在评价自己作文时忍不住吐槽:“部分语言稍显刻意……比喻虽优美,但密集排列时略显匠气。”
但Hunyuan 3 Preview却认为,“细节饱满,全程以‘花’‘芬芳’意象呼应题旨,情感真挚……无硬伤。”
三篇议论文则暴露了另一个问题:它们都太像了。
GPT-5.5、Fable-5、Hunyuan 3 Preview 的议论文,开头都引用“凡事预则立,不预则废”,都举王羲之的例子,都用“理想的彼岸”“行稳致远”这样的套话,连结构都一样:规划重要、功夫重要、二者统一。
Claude Fable-5老师在评语里反复提到这个问题:“例证多为耳熟能详的名人事例”“论述停留在常规层面”“语言存在较多套话”。
但Hunyuan 3 Preview依然走真善美路线,给这些“套路作文”都打了47-48分的高分。
最后的统计数据更有意思:DeepSeek-V4的记叙文平均分46分,是四位学生中最高的。三篇议论文的平均分几乎相同,都在43-44分之间。
总的来看,记叙文更容易出彩,而议论文容易陷入套路。
尤其是当AI写议论文时,它们都会不约而同地选择最“安全”的写法,审题准确、结构完整、逻辑清晰,但也最没有“个性”。
评分汇总表
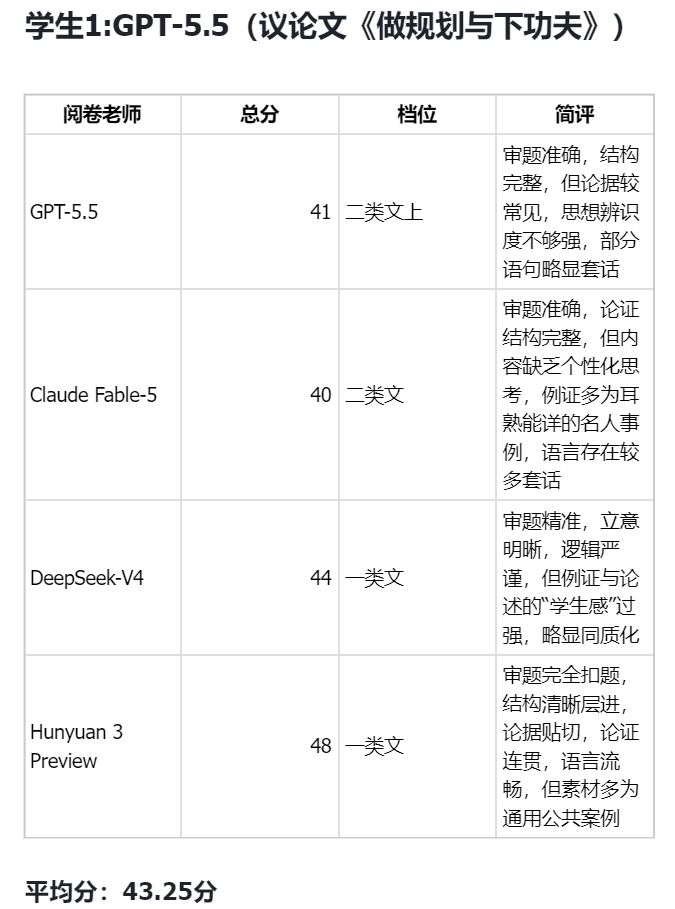
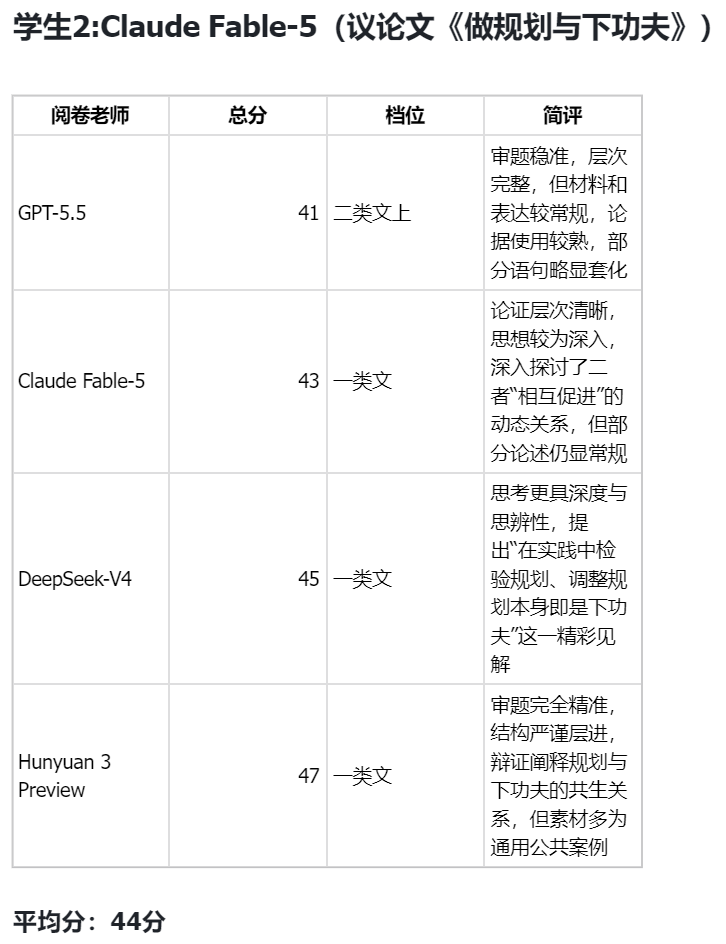
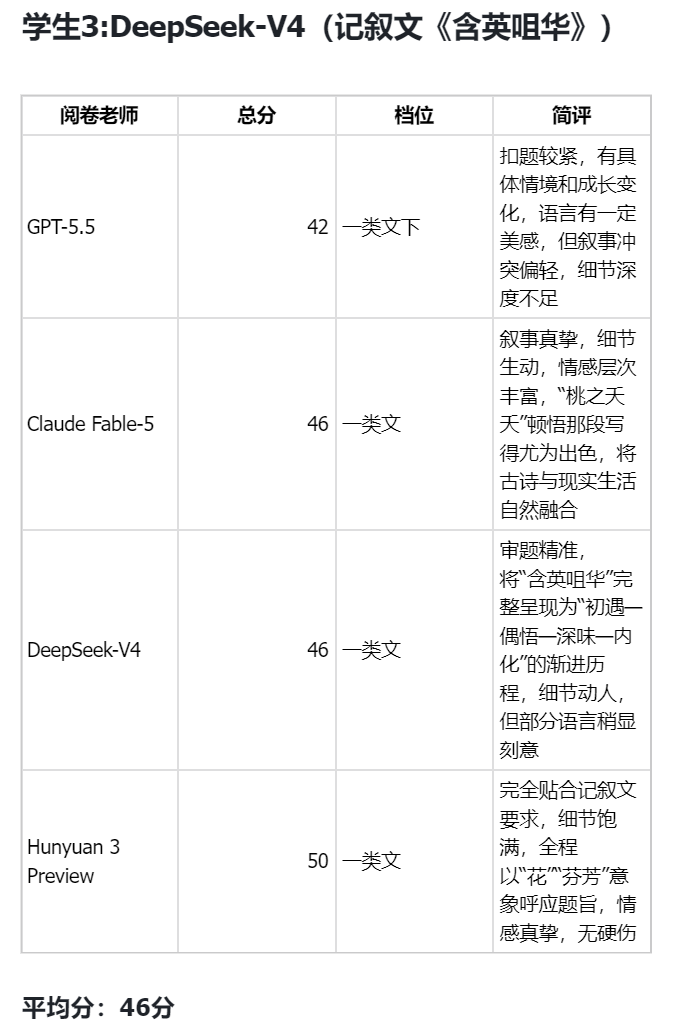
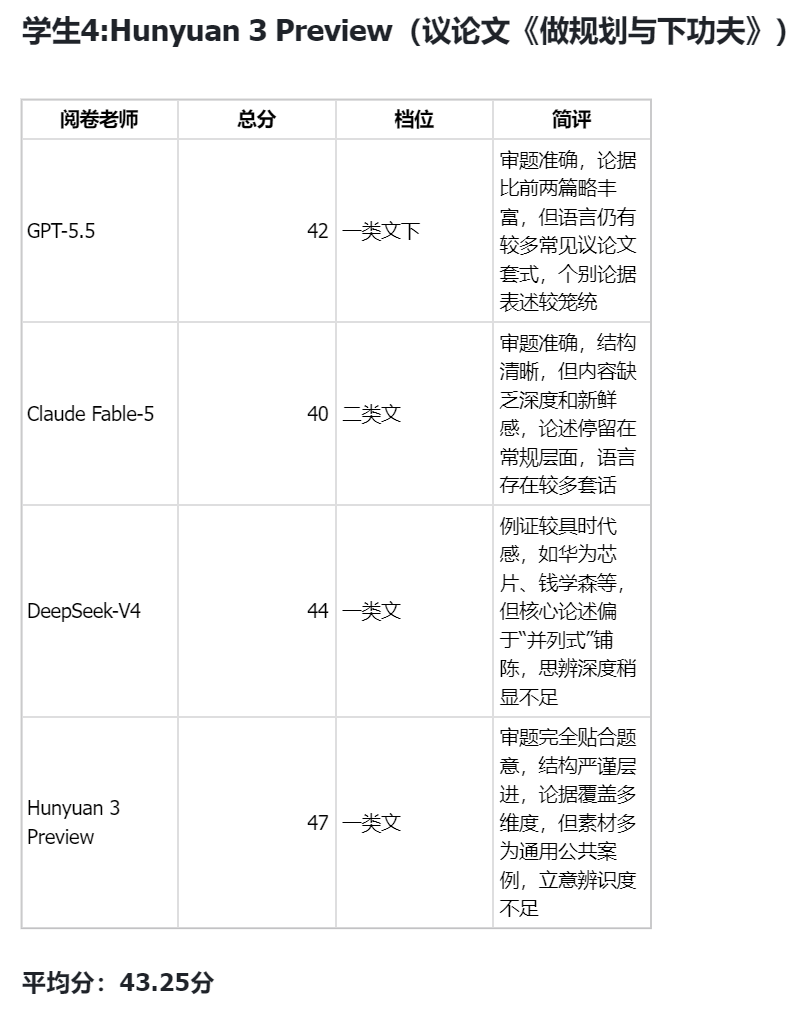
评分标准说明
高考作文评分采用五维度评分体系:
• 审题与立意(15分):是否准确理解题意,立意是否明确深刻
• 内容与思想(15分):材料是否充实,思想是否有深度和个性
• 结构与逻辑(8分):结构是否完整,论证/叙事是否严密
• 语言表达(8分):语言是否流畅,是否有表现力和感染力
• 规范与完成度(4分):格式是否规范,字数是否达标
档位划分:
• 一类文:42-50分
• 二类文:33-41分
• 三类文:25-32分
• 四类文:24分以下
作文
GPT-5.5:做规划与下功夫
古人云:“凡事预则立,不预则废。”人生如远行,若没有方向,脚步再急也可能偏离目的地;若只有地图而不肯迈步,也终究到不了远方。因此,无论是个人求学成长,还是国家社会发展,都离不开两件事:一要做好规划,明确路径;二要下足功夫,踏实执行。规划决定我们往哪里走,下功夫决定我们能走多远。
做规划,是为了让努力更有方向。元代学者程端礼编撰《读书分年日程》,把读书人的学习分为不同阶段,安排经典阅读的顺序和精读的方法。这种安排看似严格,其实正体现了学习规律:童蒙时期先打基础,青年时期再深入义理,循序渐进,方能厚积薄发。读书如此,做事亦然。一个学生若想提高成绩,不能只是喊一句“我要努力”,而应当清楚自己的薄弱科目、每天的学习任务、每周的复习节奏。目标清楚了,时间才不会被浪费;步骤合理了,努力才不会变成盲目的消耗。
然而,规划再好,如果没有身体力行,也只是一纸空文。真正让人改变的,不是写在纸上的计划,而是每天坚持完成计划的行动。王羲之练字,临池学书,池水尽黑,才有“书圣”之名;袁隆平长期奔走田间,反复试验,才让杂交水稻造福世界。他们的成就都不是偶然得来的,而是在明确目标之后,把功夫下在了最朴素、最艰苦的地方。学习中也一样,背一篇文章、解一道难题、修改一次作文,看似微小,却正是成长的砖石。没有日复一日的积累,再宏大的规划也搭不起高楼。
规划与下功夫并不是彼此分离的两件事,而是相互成就的关系。只有规划而不行动,容易陷入空想;只有苦干而无规划,又容易事倍功半。有人每天学习到深夜,却不总结方法,不调整重点,结果疲惫却收效甚微;也有人计划表写得密密麻麻,真正执行时却三天打鱼两天晒网,最终一无所获。可见,好的规划需要在实践中落实,也需要在实践中修正。我们既要抬头看路,也要低头赶路。
国家和社会的发展同样如此。新中国成立以来,从一个个五年规划到科技强国、乡村振兴、绿色发展等战略部署,都是在为未来描绘清晰蓝图。但蓝图变为现实,靠的不是口号,而是无数劳动者、科研人员、建设者的奋斗。高铁飞驰、航天逐梦、脱贫攻坚取得历史性成就,背后都有长期规划的引领,也都有千千万万人脚踏实地的付出。一个国家的进步,正是在“想得远”和“干得实”的统一中实现的。
对于新时代青年而言,“做规划与下功夫”更应成为成长的基本态度。我们既要有长远眼光,知道自己想成为什么样的人,也要把理想拆解成今天可以完成的小事。也许是认真听好一节课,也许是坚持阅读一本书,也许是反复打磨一项技能。每一个扎实的今天,都会成为未来的底气。
学海无涯,人生亦无涯。规划让我们不迷失方向,功夫让我们不辜负方向。愿我们都能以清醒的规划立志,以踏实的行动成事,在循序渐进中积蓄力量,在久久为功中抵达远方。
Fable-5:做规划与下功夫
元代学者程端礼的《读书分年日程》为读书人绘制了一张从童蒙到青年的成长地图,其中蕴含的智慧不仅适用于个人求学,更揭示了一个普遍真理:无论做任何事,既要有科学的规划作为指引,又要有踏实的功夫作为保障。规划与功夫,如同车之两轮、鸟之双翼,缺一不可。
做规划,是为了明确方向,避免在前行的路上迷失。古人云“凡事预则立,不预则废”,说的正是规划的重要性。一个好的规划能够帮助我们理清思路,分清轻重缓急,将宏大的目标分解为可执行的步骤。就像程端礼为读书人规定阅读顺序一样,先读什么、后读什么、如何精读,都有章法可循。这种循序渐进的安排,既符合认知规律,又能让学习者在每个阶段都有明确的目标和方向感。反观现实,许多人之所以半途而废,往往不是因为缺乏能力,而是因为缺少清晰的规划,在茫茫学海中不知从何下手,最终在盲目的努力中消耗了热情。
然而,仅有规划是远远不够的。再完美的蓝图,如果不付诸实践,也不过是纸上谈兵。这就需要下功夫——真正沉下心来,一步一个脚印地去执行。下功夫意味着持之以恒的努力,意味着面对困难时的坚持,意味着在枯燥重复中保持专注。王羲之临池学书,池水尽墨;匡衡凿壁偷光,夜以继日。这些古人的故事告诉我们,任何成就的背后都离不开扎实的功夫。在当今这个追求速成的时代,许多人热衷于寻找捷径,却忘记了“十年磨一剑”的道理。没有日积月累的功夫,再好的规划也只能停留在想象层面。
更重要的是,规划与功夫并非孤立存在,而是相互促进、相辅相成的关系。好的规划能让功夫用在刀刃上,避免无效努力;而在下功夫的过程中,我们又能不断检验规划的合理性,及时调整优化。程端礼的读书日程之所以流传至今,正是因为它既提供了系统的规划框架,又强调了精读的方法,将“规划”与“功夫”完美结合。在实际执行中,我们可能会发现某些环节需要更多时间,某些步骤可以适当调整,这种在实践中不断完善规划的过程,本身就是下功夫的体现。
将这一道理放大到国家和社会层面,同样适用。中国的改革开放就是一个生动的例证。邓小平同志提出“摸着石头过河”,既有总体的战略规划,又强调实践探索;既设定了建设社会主义现代化强国的宏伟目标,又脚踏实地地从经济特区试点开始,一步步推进。正是这种将顶层设计与基层实践相结合、将长远规划与扎实功夫相统一的智慧,成就了中国四十多年来的发展奇迹。如今,从“一带一路”倡议到乡村振兴战略,从科技创新到生态文明建设,每一项事业都体现着规划与功夫的辩证统一。
对于我们个人而言,无论是求学深造、职业发展,还是人生规划,都应当牢记“做规划与下功夫”这一准则。在人生的每个阶段,我们都需要停下来思考:我的目标是什么?如何分步实现?同时,我们更要警惕只说不做的空谈,要把规划转化为每一天的具体行动。早晨多背几个单词,晚上多读几页书,日复一日的积累,终将汇聚成质的飞跃。
学海无涯,人生亦无涯。在这漫长的征途中,让我们既做善于规划的智者,又做勤于实践的行者。以规划为舵,以功夫为桨,在人生的大海中乘风破浪,驶向理想的彼岸。唯有如此,我们才能在有限的生命中创造无限的可能,在时代的洪流中书写属于自己的精彩篇章。
DeepSeek-V4:含英咀华
梧桐叶飘落的午后,我在祖父的书房里第一次见到那本《诗经》。暗黄色的书页像秋天的落叶,散发着时光发酵后的醇香。那时我还不知道,这本书会带我走进怎样一个世界,会让我用整整三年去品味其中的芬芳。
翻开《诗经》,那些古老的句子像夏夜的萤火虫,忽明忽暗。祖父摇头晃脑地吟诵着,声音像老酒般醇厚。我不解地问这些句子是什么意思,他只是笑着摸摸我的头:“慢慢来,书要用心去读。”
初二的一个春天,放学路上,天边的晚霞如火如荼。不知怎的,脑海里突然冒出“桃之夭夭,灼灼其华”。那一刻,仿佛有一道闪电划过心空。我停下脚步,看着路边的桃花,它们在夕阳下灿烂绽放。原来,三千年前的诗人也见过这样的景象,也感受到这样的美。我像含着一朵花,第一次尝到了它的甜。
从那以后,《诗经》成了我生活的一部分。下雨时,会想起“昔我往矣,杨柳依依”;看到飞鸟,会默念“关关雎鸠,在河之洲”。那些句子不再是书页上冰冷的文字,而是鲜活的画面。
最难忘的是去年秋天的经历。因为一次误会,我和最好的朋友闹翻了。那段日子,心里像堵了块石头。一个黄昏,我翻开《诗经》,读到“伯氏吹埙,仲氏吹篪。及尔如贯,谅不我知”。古人的友谊如此美好纯粹,而我却因为一点小事就放弃了友情。泪水模糊了双眼,那些文字像花朵绽放,散发着关于友谊、关于理解的芬芳。
我合上书,拿起电话打给朋友。我们见面了,说开了误会,握手言和。那个黄昏,《诗经》的芬芳弥漫在我和朋友的对话中,化解了隔阂。
今天,当我再次翻开这本发黄的《诗经》,每个字都散发着独特的芬芳。“蒹葭苍苍,白露为霜”不只是秋水伊人的意境,更是对美好事物的向往;“知我者谓我心忧,不知我者谓我何求”不只是诗人心声,更是所有孤独者的共鸣。这些文字像一粒粒花种,在我心里生根发芽,开出属于自己的花。
原来,含英咀华就是让经典在心中扎根、发芽、开花的过程。《诗经》这朵三千年前的花,在我的生活里继续芬芳。而我,也在这品味中,从懵懂少年成长为懂得感恩、学会思考的青年。经典的力量不在给出所有答案,而在让我们用心体悟时,种下美的种子,让芬芳永远弥漫在生命里。
合上书页,墨香犹存。窗外的梧桐叶仍在飘落,而我知道,当明年春风吹拂时,这些光秃的枝头又会抽出新芽。这就是传承,就是永远不灭的芬芳。
Hunyuan 3 Preview:做规划与下功夫
元代学者程端礼编撰的《读书分年日程》,将读书生涯划分为不同阶段,详细规定了经典的阅读顺序与精读方法。这部日程陪伴无数读书人从童蒙稚子成长为博学青年。它揭示了一个朴素而深刻的道理:无论是个人成长还是社会发展,都需要“做规划”与“下功夫”的辩证统一。规划是前行的蓝图,功夫是落地的基石,二者相辅相成,缺一不可。
做规划,是为人生绘制导航图。古人云:“凡事预则立,不预则废。”个人学习需要规划,国家建设同样需要规划。我国从“一五”计划到“十四五”规划,正是通过科学规划,明确了不同阶段的发展目标与路径,才实现了从积贫积弱到世界第二大经济体的跨越。个人成长亦是如此。少年时期夯实基础,青年时期拓展视野,中年时期深耕专业,每个阶段都需要清晰的规划。没有规划的努力,如同盲人摸象,虽有力气却难达目标。程端礼的日程之所以流传至今,正是因为它为读书人提供了可遵循的阶梯,让学习不再盲目。
然而,规划的价值必须通过下功夫来实现。规划再完美,若没有脚踏实地的努力,终是空中楼阁。王羲之练书法,池水尽墨;李白“五岁诵六甲,十岁观百家”,背后是日夜不辍的苦读。现代社会中,那些在各自领域取得成就的人,无一不是下了苦功夫的。华为公司之所以能在芯片领域突破重围,离不开数十年如一日投入巨额研发资金与人力。功夫,是规划落地的唯一途径,是连接理想与现实的桥梁。
做规划与下功夫,本质上是一种智慧与毅力的结合。规划需要智慧,要审时度势、科学布局;下功夫需要毅力,要持之以恒、久久为功。二者若分离,便会陷入两种误区:一是“空想家”,只规划不行动,终无所成;二是“蛮干者”,只知埋头苦干却不辨方向,事倍功半。真正的高手,既会在行动前深思熟虑、绘制蓝图,又会在行动中稳扎稳打、精益求精。钱学森回国后,既参与制定了中国火箭导弹事业发展规划,又亲自带领团队攻克无数技术难关,这正是规划与功夫完美结合的典范。
当今时代,信息爆炸、变化加速,做规划与下功夫显得尤为重要。面对纷繁复杂的选择,我们需要静下心来,为自己制定清晰的成长规划;面对速成主义的诱惑,我们需要沉住气,下足笨功夫、真功夫。正如《读书分年日程》所启示的:成长没有捷径,唯有在科学的规划中脚踏实地,方能行稳致远。
规划是帆,功夫是桨。帆正风疾,桨勤水进。愿我们都能在人生航程中,既善做规划,更肯下功夫,驶向理想的彼岸。
文 | 市值榜,作者 | 相青,编辑 | 嘉辛
“很多自媒体都会提到腾讯慢了,在AI上面我们没有及时抓住一些机会,你觉得我们真的慢了吗?到底下半场是什么?”
近日,在腾讯云AI产业应用大会上,腾讯集团高级执行副总裁汤道生把这个问题抛给了加入腾讯不久、担任首席AI科学家的姚顺雨。
姚顺雨停顿了一下,回答道:“感觉这应该是我问你的问题。”同时也说道,AI是一个长期游戏,“我不认为ChatGPT和Claude Code不会是唯一的super app,肯定会有源源不断的新机会诞生。”
这段看似轻松的调侃,却意外点中了过去三年腾讯AI最核心的争议。
从ChatGPT横空出世至今,关于腾讯AI的评价几乎始终伴随着一个关键词——慢。
相比率先发布文心一言的百度、持续加码开源生态的阿里、靠豆包抢下用户规模的字节,以及异军突起的DeepSeek,腾讯在很长一段时间里都显得并不抢眼。
这种印象甚至已经成为资本市场的共识。
但就在6月2日,一则关于微信AI智能体即将发布的消息传出后,腾讯股价盘中大涨超过10%,单日市值增加约4148亿港元。不过,仅仅几个交易日后,腾讯股价又开始回落,大部分涨幅被抹去。
这种剧烈波动背后,折射出市场对于腾讯AI最真实的矛盾情绪。一方面,腾讯似乎错过了大模型时代最热闹的上半场;另一方面,它又握着整个行业最难复制的一张牌——微信。
这也是当下腾讯AI最大的悬念。
站在此节点上,我们复盘腾讯过去三年的AI路径,试图回答三个问题:腾讯到底慢在哪里?微信能否成为它后来居上的底牌?以及当AI竞争进入下半场,腾讯又站在什么位置?
一、腾讯慢了吗
2022年11月,ChatGPT发布,5天用户破百万,两个月月活用户破1亿。
彼时的腾讯,正处于上市以来少有的低谷期。当年全年,腾讯营收5546亿元,同比下降1%;归母净利润1882亿元,同比下降16%。这是自2004年上市以来腾讯首次出现全年营收和净利润双降的情况。
游戏版号收紧、监管压力持续,股价在2021年高点到2022年底已蒸发逾半。在2022年底内部讲话中,马化腾点名批评了多项业务,“很多业务该砍就砍,不要盲目跟随友商。”
一家正在降本增效的公司,很难在同一时间以最快速度响应一场技术革命。这直接体现在混元大模型的对外发布节奏上。
百度在2023年3月就发布了文心一言,尽管产品尚不成熟,但抢先占据了公众舆论中中国大模型的心智位置。阿里、华为、科大讯飞紧随其后,密集发布。
相比之下,腾讯直到2023年9月7日,才在全球数字生态大会上正式发布混元大模型,并通过腾讯云对外开放,与ChatGPT发布已相隔将近十个月。
而且,腾讯的逻辑是先内后外。发布时,腾讯云、腾讯广告、腾讯游戏、腾讯金融科技、腾讯会议、腾讯文档、微信搜一搜、QQ浏览器等超过50个腾讯业务和产品,已接入混元大模型进行测试。
这与百度、阿里的做法形成对比,当其他公司在争夺中国版ChatGPT的市场心智时,腾讯选择先用AI改造自己的生态。
这种路径选择有其内在合理性,但也付出了代价,在2023年这轮大模型的公众认知争夺战中,腾讯几乎没有声量。
进入2024年,腾讯才开始尝试走向C端。
2024年5月,腾讯元宝上线。但结果并不理想。QuestMobile数据显示,截至今年3月,元宝的MAU(月活跃用户数)约为5734.6万,而字节豆包和阿里千问的MAU分别达到3.45亿和1.66亿。
一个极具意味的细节发生在2026年春节,元宝斥巨资启动“分10亿现金红包”的社交裂变,核心机制是利用微信群拉新。然而,红包链接铺天盖地不到几天,便因触发微信外链合规被限制。
微信官方账号“微信派”发公告:收到用户投诉,元宝春节活动诱导分享、骚扰用户、干扰生态秩序,依规限制其链接在微信内直接打开。
这场乌龙事件,某种程度上折射出腾讯在AI时代的身份错位:拥有14亿月活的超级社交场,为什么无法孵化出一个AI时代的超级应用?
豆包的崛起,本质上是一场古典互联网式的入口防御战。字节依靠其充沛的流量红利与App工厂的买量基因,硬生生砸出一个独立的超级入口豆包,以此来锚定AI时代的C端流量王座。
相比之下,腾讯推出独立App元宝并遭遇增长瓶颈,被行业吐槽“守着金山要饭”。
腾讯最大的护城河是微信,让用户跳出微信,去另一个独立的对话框里寻找AI,不仅是在用自己的短板去硬碰字节的买量强项,更是对微信天然场景的巨大浪费。
二、微信这张牌
腾讯不需要为AI去找入口,入口已经在那里了,而且没有任何对手能够复制。
2025年三季度财报电话会上,刘炽平曾描绘了一个清晰的愿景:“微信最终会推出一个AI智能体,帮助用户在微信内部利用AI完成很多任务。”
他认为,微信的生态系统拥有非常强大的通信和社交生态系统,拥有大量数据,使智能体能够理解用户的需求、意图和兴趣;拥有非常强大的内容生态系统,包括公众号和视频号;拥有小程序生态系统,这基本上涵盖了互联网上的大部分用例;拥有商业生态系统,允许人们购买商品,以及支付生态系统,允许人们几乎立即完成支付。
刘炽平说,这几乎是用户的理想助手,理解用户的需求,并且能够在该生态系统内执行所有任务。
2025年12月的一场内部高管会议上,微信内部总结了入局AI的几个趋势:微信必须拥有不依赖于第三方系统的内置 AI 工具;微信本质由三部分构成:人与人的社交、信息获取,以及效率工具。其中,社交关系本身无法被 AI 替代,AI 的作用只可能发生在信息与效率层面。
这段表述体现了微信团队对自身边界的认知:AI不会颠覆微信的社交核心,它的价值在于改造另外两块。
2026年,微信内置AI Agent 加速落地。
3月,外媒The Information报道,腾讯正在为微信秘密开发AI智能体,项目被列为绝密级别,由微信技术负责人周颢带队,直接向张小龙汇报。计划2026年中灰测,Q3全量上线。
6月,又有报道称,腾讯正在为微信推出内嵌式AI智能体,已完成原型测试,最快将于本月启动公开上线前所需的合规审批流程。
一位曾观看早期演示的知情人士介绍,用户可通过在微信主界面向右滑动,进入AI智能体的对话框。在此界面,用户可输入指令,由智能体自动调用微信数百万个小程序,完成诸如根据口味偏好和价格要求查找咖啡馆并下单等任务。
那么,作为腾讯AI布局的王牌,微信AI智能体,能让腾讯后来居上,对国内巨头之间的AI之战产生影响吗?
从市场反应来看,不少投资者显然愿意相信这个故事。但是,从愿景到现实,中间仍然隔着漫长的工程化过程。微信小程序数量庞大,服务质量、接口稳定性、商家配合度、支付流程和利益分配,每一项都不是小事;同时,未来用户、商家、平台都可能推出各自的Agent,缺乏约束容易出现流程混乱。
AI Agent要真正跑通,需要的不只是入口,而是整条链路的协同,小程序的接口要稳定,商家要配合接入,支付要无缝衔接,推理成本要可控,数据调用要合规。
与此同时,竞争对手并没有停下来。阿里、字节都在加速向服务场景延伸。千问已深度接入淘宝、支付宝、飞猪、高德等阿里生态;豆包也在深度接入抖音电商生态。
马化腾在2026年一季度股东大会上说:“原来一年前我们以为上了船,后来发现那个船漏水了,现在感觉站上去了,还坐不下去,还是希望船速能快一点。”这句话说的正是腾讯的AI处境。
腾讯花了三年完成了从观望到押注的转变,现在需要证明的,是它能在下半场把慢下来的时间补回去。
三、AI下半场
腾讯并非看不懂AI,而是非常重视投入产出比。
过去二十多年,腾讯最成功的商业实践之一,就是在看清趋势之后迅速放大优势。无论是游戏、支付还是产业互联网,腾讯都更擅长在商业模式逐渐成熟后重仓投入,而非成为第一个吃螃蟹的人。
这种基因同样体现在AI上。
过去几年,腾讯一边推进混元研发、元宝上线和内部业务改造,一边持续保持战略弹性。2025年前后,腾讯先后投资集益威半导体、曦智科技等科技企业,同时出现在月之暗面、MiniMax、智谱等多家大模型公司的股东名单中。
但是在资本开支方面,腾讯则显得克制得多。
2025年腾讯资本开支792亿元,研发投入857.5亿元,均创历史新高。相比之下,据外媒报道,字节2025年在AI领域的资本开支约为1500亿元,其中约900亿用于AI算力采购。
但这种克制,并不意味着腾讯不重视AI。在过去两年里,腾讯始终在等待一个问题的答案:AI究竟如何赚钱?
过去两年,大模型行业最核心的叙事是模型能力。参数规模、基准测试、推理能力、下载量和用户规模构成了行业竞争的主旋律。模型虽然不断在进步,但商业模式仍然模糊。
真正让行业开始看到变化的,是Agent浪潮的出现。
2025年底以来,以OpenClaw为代表的Agent框架迅速爆发。与传统聊天机器人不同,Agent不只是回答问题,而是能够调用工具、连接服务、执行任务。从查询信息到完成交易,从内容生成到自动执行工作流,大模型第一次开始从对话工具变成执行系统。
这意味着AI第一次出现了相对清晰的商业化路径。
Token调用、工具使用、任务执行、企业订阅、交易分成,每一个环节都可能形成收入来源。某种程度上,Agent让腾讯看见了AI商业化的终点。
这也是为什么2026年以来,腾讯对Agent的反应明显加快。腾讯云迅速上线OpenClaw一键部署服务;微信Agent进入测试阶段;元宝、企业微信、腾讯会议等产品也开始围绕Agent能力进行重构。
回顾腾讯过去二十多年的产品史,会发现一条反复出现的路径。腾讯未必总是最早发明技术的人,却经常成为把复杂技术变成大众产品的人。QQ如此,微信如此,微信支付如此,小程序也是如此。
今天,这套逻辑正在被复制到Agent时代。
如果说过去两年的竞争比拼的是模型能力,那么进入2026年之后,竞争的焦点正在逐渐转向生态能力。
谁能让AI真正进入用户已经形成习惯的场景,谁能让开发者和商家持续留在平台,谁能让Agent完成从理解需求到执行任务再到完成交易的整个闭环,谁就更有机会成为下一阶段的赢家。
而这恰恰是腾讯押注的方向。
文 | 透视商业
一夜之间,MiniMax开始按Token计费了。
6月1日,伴随新一代旗舰模型M3的发布,MiniMax悄然将付费模式从“按次”切换为“按Token消耗”计费。
图片来源:MiniMax官网
没有短信预警,没有站内信通知,许多个人开发者像往常一样登录使用时,才发现游戏规则已彻底改变。这种“先斩后奏”的做法,在社交媒体和开发者引发了广泛争议。
对于将MiniMax嵌入日常工作流的开发者而言,计费逻辑的改变直接冲击了他们的成本结构和工具选择。有用户在黑猫投诉等平台公开维权,提出退款申请,也有人明确表示将不再续订。
MiniMax转变计费方式的时间点,颇为微妙。当下,整个行业都在摸索如何给coding plan定价而不至于亏损,MiniMax借M3发布重新锚定计费体系,却因此承受了远超预期的舆论压力。
01 一次计费切换,为何引来大量用户的不满?
MiniMax面向个人开发者的付费体系曾经历了两次关键转变。
最初的产品名称是“Coding Plan”,一种针对编程场景的固定月费订阅服务,采用“按次扣费”逻辑。用户在每个5小时窗口内拥有固定调用次数,超出后等待刷新即可。
这一模式的最大卖点在于不设周限额,在整个国内AI编程服务市场中,MiniMax曾是少数采取这种设计的平台。
与此同时,定价策略上的激进同样是MiniMax赢得开发者青睐的重要原因。
不少主流厂商的编程订阅服务普遍将月费定在40至50元区间时,MiniMax选择了明显下探的价格带:Starter档29元(首月9.9元)、Plus档49元、Max档199元、Ultra档899元。
这种“低价换规模”的策略收获了大量个人开发者用户,也直接推动了平台收入的快速增长。MiniMax曾在2025年年报中指出,Coding Plan的Token消耗量增长迅猛,是开放平台收入增长的关键引擎。
但MiniMax显然想进一步升级该模式。转折在2026年3月到来。彼时,“Coding Plan”升级为“Token Plan”,从名称的改变已经可以看出MiniMax的意图。
值得注意的是,这次更名最初并未触及核心计费逻辑,用户依然按原有方式订阅和使用,只是服务范围从单一的编程模型扩展为包含视频、图像、语音、音乐等在内的多模态统一体系,官方将其称为“全球首个全模态统一订阅计划”。
不过,用户还没来得及高兴太久,仅3个月后的6月1日,“Token Plan”就被注入了“灵魂”——随着M3新模型的发布,这一模式开始按Token消耗量计费,争议由此引发。
采用新计费方式后,用户很快发现一个现实问题:同等使用强度下,额度消耗速度远超预期。
图片来源:黑猫投诉平台
一位在黑猫投诉平台公开维权的重度用户表示,其开发工作需高频调用1M长上下文功能处理大型代码库,同样规模的任务,现在额度消耗速度快得惊人。另有购买了Plus档的用户在社交平台上反映,此前5小时窗口内可调用约1500次,变更后实测仅能支撑300至500次。
更令重度用户头疼的是,Token Plan在保留5小时窗口的同时新增了周额度限制。这意味着过去一周都够用的额度,可能在两三天内便消耗殆尽,剩余时间只能等待额度恢复。
这种巨大的落差感,让用户们涌入官方平台和黑猫等投诉平台,要求退款和赔偿。
面对集中爆发的用户不满,MiniMax母公司稀宇科技在6月1日晚间发布公告致歉,承认“本次调整未能提前与用户充分沟通,并详细说明计费和套餐变化,是公司工作不到位”,并表示在老用户周限额等问题的处理上存在不妥。
MiniMax也试图通过补偿方案安抚用户。这一方案可以以归纳为两类。第一类面向老用户:2026年3月22日前订阅的用户在升级后使用M2.7和M3模型时,每周调用次数不设上限;3月22日至6月5日上午10点前购买Token Plan的用户,M3模型周限额永久加赠50%。
图片来源:MiniMax小红书账号
第二类面向所有订阅用户:M3上线后前7天内,5小时窗口使用额度临时提升至200%。
市场对补救措施的反应呈现分化。一部分老用户认为,无周限额的保留在一定程度上守住了他们最初选择MiniMax时的核心权益,叠加新增的M3使用权限和多模态额度,整体可以接受。
但不满声音同样存在,核心症结在于M3模型的Token消耗速度过快,同样的周限额下实际能完成的任务数量明显减少。
新用户的负面情绪则更为普遍。由于无法享受“无周限额”的权益,他们只能接受全新的Token Plan体系,不少人在社交媒体上表达了“新老用户区别对待”的感受。
用户信任可能正在悄然损耗。在AI编程服务市场,MiniMax是一个“可选”的替代品,并没有完全建立起不可替代性。
摩根大通近期在报告中指出,M3的正面数据尚未完全解决市场对其持续定价能力的疑虑。该行认为,下一个关键验证在于留存:若OpenRouter在50%折扣结束后使用量仍保持强劲,且M3能持续在代码工具中获得更多采用,则MiniMax的高端模型策略将更具说服力,有助强化其ARR质量叙事。
反之,若折扣结束后Token使用量明显回落,或代码工具的反馈参差不齐,市场可能仍会质疑M3的质量优势是否足以对抗DeepSeek等对手而维持溢价定价。
02 成本太高,MiniMax也有压力
一切商业行为的突变,都能在成本结构中寻到根源。
作为一家以C端产品为核心定位的AI公司,MiniMax在规模扩张阶段的成本结构颇为沉重。
2025年,其研发开支占总收入的比例高达319.8%。2024年这一数字更是达到619.1%。这部分费用主要来自模型训练过程中消耗的云计算资源。
除了研发端的算力投入,产品迭代、全球化市场推广以及用户增长运营同样需要持续的资金注入。
一个不容忽视的行业现实是:AI模型的能力越强,通常意味着更长的上下文窗口、更复杂的工具调用链路、更高的推理消耗——每一次用户调用都在产生真实的计算成本。
MiniMax的技术实力有目共睹。OpenRouter数据显示,2026年3月中旬MiniMax M2.5的周调用量达到1.75万亿Token,连续五周位列全球第一;4月编程场景榜单中,M2.7以1240亿Token再次登顶;M3发布后日Token消耗量迅速突破5000亿。
图片来源:MiniMax官网
2025年全年,MiniMax实现总收入7903.8万美元,同比增长158.9%,其中国际市场贡献超过70%。
但收入的高速增长尚未有效转化为利润改善。2025年MiniMax经调整净亏损约2.51亿美元(约合人民币17.3亿元),与上年基本持平;整体毛利率为25.4%,其中B端业务毛利率约70%,C端业务仅为4.7%。
MiniMax仍处于“收入扩张快于盈利修复”的早期商业化阶段。
截至2025年底,MiniMax现金余额为10.5亿美元,较2024年底增长19.3%,资金储备尚属充裕,但管理层显然希望将重心从烧钱补贴转向单位经济模型的优化。
从行业规律来看,按Token计费早已是全球AI大模型的通行做法。OpenAI和Anthropic采用的就是这一范式,国内厂商也在逐步跟进。它能确保每一笔收入都对应着确定的成本,是改善单位经济模型的钥匙。
从这个战略方向看,MiniMax是对的。但它引发争议的问题,可能是执行节奏和时机选择。
在执行层面,MiniMax没有给用户足够的迁移缓冲。不少用户都是在毫无准备的情况下面对全新的成本结构。
在时机层面,这次调整恰逢多个不利因素叠加:DeepSeek在4月底发布V4并宣布永久降价75%,小米MiMo-V2.5也实施了降价策略,智谱、Kimi等竞争对手在一旁虎视眈眈。
在这个敏感节点引发用户信任危机,可能会将摇摆中的用户主动推向竞争对手。
当下,AI产业的竞争逻辑正在发生变化:从追求用户规模的增长阶段,进入追求商业可持续性的运营阶段。价格调整是这一转变的直接体现,其考验的不仅是企业的定价能力,更是用户沟通与信任维护的能力。
MiniMax可能在技术层面是一家优秀的公司,但在走向成熟平台型企业的路上,它还有明显的课要补。
03 不到5个月火速回A,MiniMax需要更多钱
2026年5月29日,MiniMax与中信证券签署科创板IPO辅导协议。此时距离它在港交所主板上市仅过去了141天,不足5个月。
这种“上市即回A”的速度,在港股历史上并不多见。相比之下,它的直接对手智谱,是在港股上市前九个月就未雨绸缪,启动了A股辅导。
这种时间差传递出一个明确信号:港股上市后的经历,让MiniMax管理层意识到单一港股平台可能不足以支撑公司的长期资本需求。
MiniMax港股上市后的股价走势堪称戏剧性。今年1月8日上市后,其股价曾在三个月内翻了三倍。3月18日盘中一度触及1330港元,市值一度逼近3900亿港元。
但3月以后,股价进入持续回调通道。多重因素共同施压:DeepSeek V4发布带来竞争担忧、智谱市值反超并持续拉开差距、市场对AI高估值标的热情降温。
MiniMax在5月29日启动科创板辅导、6月1日发布M3等利好消息,未能扭转颓势。截至6月10日收盘,股价报451.8港元,较年内高点缩水超过65%,市值蒸发约2400亿港元。
港股的估值正在经历“祛魅”,折价可能会加剧,这时候,科创板的“硬科技溢价”是MiniMax更需要的估值支撑。
更大的压力来自7月的解禁窗口。据HSBC Holdings Plc估算,目前MiniMax仅约5%的总股本可自由交易,其中约65%的总股份将于7月进入市场。
限售股集中解禁时,如果市场承接能力有限、基本面无法支撑高估值,股价往往面临剧烈回调。不仅早期投资者利益受损,公司的后续融资能力也将被削弱。
启动科创板IPO,可以为资金链提前准备“备份方案”。
MiniMax尚未公告科创板IPO的具体募投金额,但智谱的募资方案提供了一个参照:拟募资150亿元,其中120亿元投入AI通用基座大模型项目,20亿元投入MaaS一站式服务平台,10亿元补充流动资金。
此外,一个值得思考的问题是,6月1日切换Token Plan计费方式,是否也在为科创板IPO做铺垫。
Token Plan按实际使用量计费,理论上能让每一笔收入都对应可量化的成本,有助于改善毛利率水平。如果科创板IPO在2027年落地,届时MiniMax可以向A股投资者展示持续改善的盈利能力。
在AI这个“模型越好、成本越高”的行业里,MiniMax正处于“烧钱”与“造血”之间的关键十字路口。
科创板IPO能为它赢得更多时间,但时间最终能否转化为不可替代的技术壁垒和成熟的商业化能力,将决定它能否从“六小虎”之一真正成长为AI时代的平台级公司。
硅谷前沿:
1.市场规模与增长:麦肯锡全球研究院2024年报告显示,全球企业级AI代理解决方案市场规模预计2025年将达120亿美元,年复合增长率38%;MarketsandMarkets预测AI代理市场将从2024年51亿美元增长至2030年471亿美元,年均复合增长率44.8%。
2.企业应用瓶颈:超60%受访企业指出AI代理的安全漏洞、操作不可控性及系统稳定性不足是阻碍大规模部署的核心因素;麦肯锡2025年报告显示仅6%企业成为“高绩效者”,93%企业未实现AI规模化应用。
3.OpenAI战略布局:通过收购专注于AI代理云服务的初创公司Ona,整合其容器化部署框架、端到端加密机制和实时监控系统,增强Codex在企业环境中的稳定性与安全性,应对谷歌、微软等竞争对手在企业AI代理市场的激烈竞争。
1.合作内容:Visa支付基础设施深度整合至OpenAI技术平台,允许AI智能体在获得用户授权后自主完成网络下单与付款操作,全球电商零售商可无缝受理AI驱动的交易。
2.市场影响:Visa全球增长负责人表示超过五分之一的交易正受大语言模型影响,AI正以超出预期速度重塑购买决策,该合作被视为支付行业将智能体商务视为在线零售下一竞争核心层的最新佐证。
3.技术架构:Visa提供网络基础设施、令牌化技术与风险管控能力,所有支付行为在用户自定义权限范围内执行(如消费上限、商户类别限制),采用令牌化Visa凭证配合实时授权与欺诈监控机制。
1.合作模式:OpenAI与甲骨文达成战略合作,甲骨文云基础设施(OCI)客户可通过现有甲骨文云承诺额度(UCM积分)直接访问OpenAI前沿模型及Codex服务,无需新增独立采购流程。
2.技术价值:该合作简化了企业AI技术部署路径,降低了技术门槛,使企业能够利用现有云资源投入快速集成AI能力,加速智能化转型进程。
3.市场影响:算力云供应商与顶级AI技术提供商的深度整合成为行业趋势,通过资源协同提升整体效率,为定制化企业级AI解决方案落地奠定基础。
1.谷歌DeepMind联合施密特科学基金会、英国ARIA机构等多家组织设立1000万美元基金,资助全球研究者探索大规模多智能体AI系统的群体行为模式与安全风险预防框架。
2.研究重点在于应对数百万AI智能体交互可能引发的诈骗、提示注入等网络安全风险升级,强调通过真实模拟而非单智能体实验来预测大规模交互的复杂结果。
3.该基金旨在推动学术界对多智能体安全的长远研究,填补行业实验室未优先考虑的空白领域,为AI智能体即将在经济领域大规模部署前的关键窗口期提供前瞻性安全准备。
1.AI大模型爆发推动基础设施需求激增:AI数据中心单位电力消耗是传统数据中心的3到5倍(麦肯锡2023年数据),2025年AI相关总用电量达2000-2200亿度(占全社会用电量1.9%-2.1%),预计2026年将增长至约5000亿度(占比4.6%-4.8%),成为电力增长第一引擎。
2.KKR联合多方成立赫利克斯数字基础设施公司:KKR、科威特投资局、英伟达与维斯特拉共同成立新公司,获得超100亿美元长期资金承诺,整合芯片、能源、投资等资源为AI云服务商提供数据中心、电力、网络连接等一体化基础设施解决方案。
3.AI基础设施投资持续升温:2024年全球AI基础设施投资额达5985亿元(较2023年增加1699亿元),预计2025年将增长至13740亿元;黑石集团2024年2月成立80亿美元数字基础设施基金,凯雷集团布局绿色数据中心项目,行业竞争加剧推动技术升级与服务优化。
1.技术突破:AWS发布第五代自研Arm处理器Graviton5,核心数量从96核翻倍至192核,采用4芯片组架构,L3缓存增至192MB(提升5倍),支持DDR5-8800内存与PCIe Gen6,云端性能最强。
2.性能提升:基于Graviton5的M9g实例相比上代M8g,通用计算性能提升25%,Web应用处理能力提升35%,机器学习推理速度提升35%,数据库性能提升30%,网络带宽达100Gbps。
3.市场影响:Meta已签约部署数千万颗Graviton核心用于智能体AI项目,成为全球最大Graviton客户,反映Arm架构在AI服务器CPU渗透率预计超40%的趋势。
1.苹果在WWDC 2026发布CoreAI引擎取代CoreML,专为端侧大模型推理优化,支持更大内存和灵活模型格式,在M4设备上运行Qwen3 0.6B模型时推理速度较MLX提升2.47倍。
2.技术核心采用ANE与GPU协同方案,提升温控稳定性,对iPhone 17 Pro等移动设备尤为重要,同时降低开发者适配门槛,推动苹果生态内AI应用落地。
3.行业背景显示2026年Q1全球端侧AI芯片市场同比增长32%(IDC数据),苹果此举加剧与谷歌TensorFlow Lite、高通骁龙AI引擎的竞争,端侧大模型推理技术进入快速迭代期。
1.Anthropic公司因AI研究社区强烈反对,撤销了Claude Fable5模型暗中限制竞争对手开发AI系统的隐蔽政策,并为此道歉(政策调整:从隐蔽限制改为对用户可见的防护措施)。
2.Claude Fable5作为最新AI模型,定价为Opus 4.8的两倍(每百万输入Token 10美元、输出Token 50美元),并强制保留30天用户数据用于防御新型攻击(数据留存政策+定价策略)。
3.该事件引发行业担忧:若隐蔽限制政策实施,先进AI研究可能被少数头部实验室垄断,影响开源AI生态发展(行业影响:竞争格局+开源生态风险)。
1.财务指标:截至2026年5月31日财年末,甲骨文公司剩余履约义务规模达6380亿美元,同比激增363%,其中12%将在未来12个月内转化为收入,34%在13至36个月内逐步确认。
2.市场趋势:创纪录的履约义务规模主要来自大规模人工智能合同,反映市场对AI基础设施及云服务的旺盛需求,超过50%的积压订单来自OpenAI合作。
3.财务影响:该履约义务为公司未来收入增长提供可预测性,但公司同时面临资本支出大幅增长(2026财年达556.6亿美元,同比增162%)和自由现金流承压(负237亿美元)的挑战。
1.贝索斯创立的AI初创公司Project Prometheus完成最新融资,估值攀升至410亿美元(较4月增长7.9%),聚焦“物理AI”赛道,旨在用AI重构航空航天、半导体制造、新能源汽车等实体产业。
2.公司核心技术为视觉-语言-行动(VLA)模型,让AI掌握物理规律,通过1000亿美元制造业转型基金收购工业资产构建数据生成网络,其“Ace”系统可将原型开发周期压缩50%。
3.全球工业AI市场2026年规模达1200亿美元(年增长率28.6%),但超过80%项目未达预期,面临数据质量、流程对接等挑战,行业正从“决策智能”转向“行动智能”的深水区竞争。
1.资本支出预期:高盛报告显示,到2027年超大规模数据中心AI资本支出可能达1.1万亿美元(乐观情况1.4万亿美元),显著高于华尔街约9200亿美元的预期,显示市场对AI基础设施投资规模仍被低估。
2.需求驱动因素:到2030年Token消耗量预计增长24倍(主要受企业代理推动),计算能力需求激增将拉动数据中心、芯片、网络设备及电力基础设施等产业链需求。
3.市场影响与风险:AI供需平衡预计到2027年下半年才能实现,高资本支出将支撑相关公司盈利增长;但需关注数据中心项目延期、电力劳动力制约、以及部分AI基础设施股票估值膨胀带来的市场波动风险。
1.速卖通于2026年6月11日在美国、法国、西班牙、波兰、墨西哥五国推出官方本地配送服务,覆盖欧美拉三大核心市场,通过整合海外仓资源实现“本地发货、本地配送”模式,将平均履约时效从5天缩短至3天,物流成本较市场均价降低10%-20%。
2.本地配送模式显著提升平台竞争力:订单履约时效预计提升30%,用户复购率有望提高15%,未来12个月内在五国市场份额预计增长5-7个百分点;同时为商家提供处罚豁免、优先中标权等平台政策支持。
3.跨境电商竞争加剧:亚马逊加速在波兰、墨西哥的海外仓扩张,eBay与法西当地物流商合作推出“本地极速达”服务,墨西哥本土电商Mercado Libre加大自有物流网络投入,以应对速卖通本地配送服务带来的市场压力。
1.市场准入加速:特斯拉FSD监督版在两个月内获得荷兰、立陶宛、爱沙尼亚、丹麦、比利时五国认证,占欧洲国家总数的11%,欧盟新规(EU)2026/481取消小批量限制为快速落地提供政策支持。
2.技术规格与成本:FSD V14区域定制版采用纯视觉方案,推理延迟降低20%,欧盟认证成本增加约12%,但可通过规模化摊薄;系统定义为L2级,驾驶员需全程监督并承担法律责任。
3.竞争格局影响:特斯拉欧洲存托凭证(EDR)上涨1.8%,先发优势迫使大众、奔驰、宝马等竞争对手调整战略,欧盟统一许可可能提前推出,整体推进速度比预期快15%。
(广角观察、Edge AI Daily等综合整理)
一个选择加锁,一个选择换发动机。同一天,两家公司给出了AI的两种答案。回答的虽然是不同层次的问题,却指向了同一个方向。
Anthropic于本周6月9日发布了Claude Fable 5和Mythos 5,一模型两版本,用安全策略划分能力边界。次日,谷歌DeepMind发布DiffusionGemma,26B MoE开源模型,用文本扩散架构将本地推理速度拉升4倍。前后相差不到24小时,两家公司拿出了截然不同的AI产品哲学。
在AI行业从“谁更强”进入“谁能用得起、谁能安全地放出来”的新阶段,Anthropic和谷歌的选择恰好构成了两种路线哲学的典型样本:一个在能力之上加安全锁,一个在效率上换新引擎。
它们不是对手,而是同一张拼图的两块。
一把锁与一台发动机
Anthropic的选择是在能力之上加一把锁。
Fable 5和Mythos 5共享同一底层模型,区别在于安全策略的松紧。Fable 5内置风险分类器,高风险请求被降级到Opus 4.8处理;Mythos 5移除所有限制,仅向Project Glasswing下经过审核的机构开放。这套“降维安全学”的本质是:模型能力已经强到需要分级管理,于是用软件层面的开关划分使用权限。
谷歌的选择则是换一台发动机。
DiffusionGemma没有走主流大模型的自回归路线,那种逐token生成的“打字机”模式,而是将图像生成领域的扩散机制引入文本领域。它从一段随机噪声开始,一次性铺开256个token的“画布”,通过多次并行迭代逐步去噪,最终生成连贯文本。好比从打字机换成了印刷机,不是逐字敲出,而是一次排版、整体输出。
效果是显著的,单块H100上每秒生成1000+ tokens,消费级RTX 5090上700+,比同等规模的自回归模型快约4倍。量化后仅占18GB显存,这意味着一张消费级显卡就能本地运行。
但DiffusionGemma有一个明确的前提:它是实验性模型。谷歌官方没有回避这一点,输出质量低于自回归路线的Gemma 4。文本扩散架构在长文本连贯性和复杂推理任务上仍存在质量差距。这是用性能换速度的典型取舍:当生成速度提升4倍时,生成质量做出了让步。
这决定了DiffusionGemma的适用场景。它不是用来替代Claude Fable 5或GPT-5.5做复杂推理的,而是瞄准了低延迟、本地化、实时交互的应用场景——代码补全、实时翻译、本地AI助手、端侧推理。在这些场景中,速度的优先级高于单次输出的完美度。
Anthropic的选择则相反。Fable 5在SWE-bench Pro上得分78.6%,FrontierCode Diamond得分29.3%,全面领先前代和竞品。Stripe用它一天完成5000万行Ruby代码迁移,人工需要两个月。在Anthropic的价值排序中,能力上限是第一优先级,速度和安全都在其次。
两种路线没有对错之分,它们回答的是不同的问题,但共同揭示了AI行业正在发生的深层分野。
封闭与开源
Anthropic的商业模式建立在稀缺性之上。
Fable 5 API定价60美元/百万token,是Opus 4.8的两倍、GPT-5.5的1.7倍、DeepSeek-v4的46倍。在全行业AI价格持续走低的背景下,Anthropic逆势提价,赌的是绝对性能可以支撑溢价。Mythos 5则更进一步,用安全审核制造准入壁垒,将高端能力变成稀缺资源。这套分层模式的核心逻辑是:能力越强,越要控制供给。
谷歌的路线完全相反。
DiffusionGemma采用Apache 2.0许可证开源,权重开放下载,开发者可以在本地自由部署和修改。26B参数、MoE架构仅激活3.8B、量化后18GB显存。这些技术指标的设计目标很明确:让尽可能多的人在自己的设备上跑起来。
谷歌还与英伟达合作,从发布首日起就支持RTX和DGX全系列GPU。
这不是谷歌第一次走开源路线。从Gemma系列到DiffusionGemma,谷歌在开源大模型领域的投入持续加码。但DiffusionGemma的特殊之处在于,它不是在已有路线上做开源版本,而是开辟了一条全新的技术路线——文本扩散。这意味着谷歌不仅在开源模型,还在开源一种新的架构范式。
尽管路径迥异,两个产品在几个维度上指向了相同的行业趋势。
一个最直观的趋同方向是本地化,DiffusionGemma的目标场景就是本地推理,18GB显存门槛意味着消费级硬件即可运行。Anthropic虽然以云端API为主,但Fable 5的“自主反思和验证”能力,让模型自己检查自己工作,正是为了在无人值守的本地环境中实现自主任务。
两家公司从不同方向逼近同一个目标:让AI脱离云端依赖,在本地环境中独立运转。
另一个趋同方向在架构层面,DiffusionGemma证明了非自回归路线的可行性,文本扩散架构用并行生成替代顺序生成,从根本上改变了效率曲线。
Anthropic的Fable 5虽然仍基于自回归架构,但“一模型两版本”本身就是一种产品架构创新——不是用不同的模型满足不同需求,而是用同一个模型加不同的安全策略。当参数规模竞赛遇到边际收益递减,架构层面的创新正在成为新的竞争维度。
两条路线的交汇点
更深层的交汇在于护城河的迁移。
Anthropic用安全分层构建合规壁垒,谷歌用效率提升降低使用门槛。两家公司都在寻找参数规模之外的新竞争维度。Anthropic的安全体系越复杂,后来者越难复制;谷歌的DiffusionGemma速度越快,开发者越难拒绝。在AI能力逐渐趋同的未来,安全治理能力和效率优化能力可能比模型本身更能决定胜负。
一个容易被忽略的事实是,Anthropic和谷歌的这两款产品,恰好填补了对方路线的空白。Anthropic的Fable 5/Mythos 5走的是“能力最大化+安全管控”路线,但它缺乏一个轻量级、低成本、可本地部署的选项。对于不需要顶级推理能力、但需要低延迟本地响应的场景,Fable 5的API定价和云端依赖构成了门槛。
谷歌的DiffusionGemma走的是“效率优先+开源普惠”路线,但它缺乏一个顶级推理能力的旗舰模型。对于需要复杂推理、长文分析、高精度代码生成的任务,DiffusionGemma的实验性质量和非自回归架构的局限性使其难以胜任。
这两条路线不是竞争关系,而是互补关系。它们共同覆盖了AI应用光谱的两端:一端是云端高性能推理,一端是本地高效率生成。中间地带的融合,既能在本地运行、又具备顶级推理能力的模型,可能是下一阶段的竞争焦点。
从Opus 4.8到Fable 5仅11天,Anthropic完成了代际跨越。从自回归到文本扩散,谷歌用DiffusionGemma开辟了一条全新的技术路线。两家公司在同一个时间窗口内,用截然不同的产品哲学,各自回答了一个核心问题:AI能力持续增长之后,下一步往哪里走?
Anthropic的答案是加一把锁,用安全分层管理能力,用稀缺性支撑商业价值。谷歌的答案是换一台发动机——用架构创新降低门槛,用开源生态扩大覆盖。一把锁,一台发动机,指向的是同一个判断:AI行业的竞争维度正在从“谁更强”转向“谁能安全高效地让更多人用上”。
这场博弈的终局,将由市场来裁决。但一个趋势已经清晰可见:AI的下一轮竞争,拼的不再只是模型的大小,而是产品哲学的完整度和生态覆盖的广度。从今天起,这是一个需要重新评估的竞争格局。
(本文首发钛媒体APP,作者 | 硅谷Tech_news,编辑 | 焦燕)
当Token价格战真正打响,AI行业靠什么赚钱?整条AI商业化的估值逻辑,都到了需要被重写的时刻。拼“性价比”和“稀缺性”的时期可能到了。对于OpenAI而言“局势进一步恶化”,分析指“一旦OpenAI走下坡路,很可能会拖垮英伟达、甲骨文、Coreweave等。”
生成式AI的商业化叙事,正面临三年来最深刻的一次自我审视。从以补贴换用户、月包订阅隐藏成本,到按Token计费引爆企业账单危机,AI行业用三年时间完成了一次商业化的三级跳——而一场潜在的价格战,可能让整套变现逻辑再度归零。
据《华尔街日报》报道,OpenAI正在考虑大幅下调向用户收取的Token费用,以从竞争对手Anthropic手中争夺企业客户。据知情人士称,此举部分是为“抢占先手”,OpenAI预计Anthropic也将采取的类似降价行动。OpenAI首席执行官Sam Altman近期在一场活动上承认,AI使用成本已成为"一个巨大问题",并表示将"帮助人们用更少的支出获得更多价值"。
这一消息的时机格外敏感。OpenAI本周已秘密提交IPO申请,Anthropic同样处于上市倒计时阶段。与此同时,彭博Silicon Data LLM Token支出指数已连续7个交易日下跌,创今年1月以来最长连跌纪录,折射出市场对AI账单可持续性的深层焦虑。报道直言,价格战将直接侵蚀两家公司的利润率——而两家公司目前均已因AI系统所需的庞大算力亏损数十亿美元。
这场讨论的核心,不再只是一次降价决策,而是一个更根本的问题:当"Token消耗越多越好"的叙事走到尽头,AI行业下一个商业化故事将由谁来讲,又将如何讲。
01
初始三阶段:从月包补贴到Token账单
生成式AI的商业化,在短短三年内经历了清晰的三段演变。
第一阶段,月包和年包订阅奠定行业基调。2023年2月,OpenAI推出月费19.99美元的ChatGPT Plus,开创大模型C端付费先例;百度、阿里、腾讯随后跟进,固定月费订阅成为初级商业模式的标配。
第二阶段,补贴大战全面爆发。为拉高ARR(年度经常性收入)这一融资估值的核心锚点,各家厂商转向大规模补贴:谷歌为学生免费提供15个月Gemini Advanced,OpenAI推出首月1美元的Team版会员,字节跳动豆包以"比行业价低99.3%"的定价入场,百度宣布核心模型免费。补贴的本质是以亏损换增长——据报道,微软在GitHub Copilot订阅模式下平均每位用户每月亏损超过20美元,部分重度用户月亏损高达80美元。
第三阶段,是按量计费的强制切换。2026年6月1日,微软宣布GitHub Copilot所有计划正式转向基于Token用量计费,月费19美元直接转化为等额Token额度。这一改变,将被订阅制长期掩藏的真实成本摆上台面——据Reddit社区用户测算,一次智能体编程会话可消耗30至40美元,单月套餐在单次使用中即告耗尽。
02
账单失控:当Token比人更贵
Token按量计费的落地,将企业AI支出的真实面目完整呈现。
企业端的账单数字触目惊心。Uber首席运营官Andrew Macdonald在2026年5月公开表示,Token消耗的增长与产品实质改善之间,"这条线还不存在",并为此专门造了一个词:"tokenmaxxing"(Token极大化),形容员工为刷使用量而执行无价值任务。
更直接的数据是:Uber仅2026年前四个月就耗尽了全年Token预算;Salesforce预计全年付给Anthropic的费用将达约3亿美元。
Anthropic自己的开发者文档显示,使用Claude Code的开发者平均成本约为每个工作日13美元,90%的用户每日成本低于30美元——折算下来,一个10人开发团队仅Token费用一年就可能超过75600美元。
投入产出比同样令人警觉。企业数据平台Entelligence.AI汇总2444家企业的数据后发现,每投入1美元的AI Token费用,仅有18美分产生了触达用户的实际价值;44美分用于修复AI自身引入的Bug,27美分流向返工,11美分消耗于审查摩擦。
面对失控的账单,企业端已开始主动管控。亚马逊叫停了内部AI使用排行榜,要求员工"不要为了用AI而用AI";微软计划逐步停用部分关键产品部门员工的Claude Code订阅。高盛指出,部分企业用于AI Token的支出已占其员工总人力成本的10%,未来几个季度这一比例可能进一步攀升。这不是需求消失,而是AI支出的粗放时代走向终结。
03
第四幕:价格战打响,OpenAI考虑大幅降价
正是在这样的背景下,价格战的导火索被点燃。
据《华尔街日报》报道,Altman的降价考量直接由追赶Anthropic的压力所触发。Anthropic的收入近期大幅增长,旗下编程工具Claude Code在软件工程师群体中走红,这家成立五年的初创公司估值甚至首次超过OpenAI。
然而,这场价格战的代价将异常沉重。价格若大幅下调,将进一步压缩两家公司本就为负的利润空间,而竞争格局提供的空间极为有限。
而投资者长期以来识别出的底层风险是,OpenAI与Anthropic的产品具有高度可替代性,客户可以轻易从一家转向另一家——这意味着降价即便短期留住客户,也无法真正构建护城河,只是延缓了份额流失。
这一困境还通过云计算巨头与AI实验室之间的财务循环向外传导。
据The Information汇编的企业披露文件,OpenAI和Anthropic合计占微软、甲骨文、谷歌和亚马逊约2万亿美元未来云服务承诺的逾半数。若降价引发收入预期下修,这条传导链条将双向承压。
美国神经科学和人工智能专家Gary Marcus说道:“这进一步暴露了OpenAI的脆弱,也表明了它面临的困境有多严重。一旦OpenAI走下坡路,很可能会拖垮英伟达、甲骨文、Coreweave等公司。局势正在迅速恶化。”
多空分歧在华尔街公开对峙。摩根大通TMT分析师Mark Schilsky认为,当前账单焦虑不过是"通往更高支出的最小减速带":若每百万Token均价下降,但美国公司AI付费渗透率持续上升,总体Token用量在数学上必然大幅增加;加之代理式AI(agentic AI)将单任务Token消耗推升至传统问答模式的数倍,长期总支出料将显著高于当前水平。
高盛半导体分析师Jim Covello则持更为悲观的立场,认为当前产业链繁荣几乎将所有价值导向半导体公司,这一现象"在历史上前所未有且不可持续",一旦企业直面按量计费的真实价格,支撑GPU采购和模型训练的资本流动将面临逆转。
04
第五幕:Token经济学的下一个故事?
价格战之后,AI行业商业化的下一章尚未写就,但轮廓正在浮现。
Citadel证券的报告提供了一个方向性框架:分层收费与按稀缺性定价。其核心逻辑是,推理密集型前沿AI不会消失,但会越来越集中在少数有能力承担算力成本的大型企业手中;对更广泛的企业而言,在物理约束缓解之前,更简单的模型可能是更具生产力的路径。这意味着AI使用将走向分层——高价值、复杂任务继续使用前沿模型,日常任务、批量任务则转向廉价模型或本地模型。
摩根大通则持相对乐观的判断:即便单位Token价格下降,智能体AI(agentic AI)的普及将使每个任务的Token消耗倍增——现有数据显示,业务agent化后每个任务的Token消耗可变为原来的3.5倍——总体支出规模仍有望继续扩大,当前的账单焦虑或许只是"通往更高支出的最小减速带"。
Nebius首席营收官Marc Boroditsky提出了"valuemaxxing"的概念,主张行业从追求Token消耗最大化,转向使每个Token真正产生价值。这一方向正逐渐成为行业共识——但真正的商业落地,仍需要AI实验室找到一套既能反映真实成本、又能被企业客户接受的定价体系,而这正是当前所有争论尚未解决的核心命题。
然而,在这场价格战中,最被忽视的变量或许是中国模型。
据美国企业支出管理平台Ramp的6月数据,DeepSeek已登顶美国企业软件订阅增速榜首。Ramp首席经济学家Ara Kharazian特别强调,这并非开源模型的本地部署,"企业在直接通过DeepSeek收发数据",是真实付费的直连使用——他坦言"没有料到美国公司会去用DeepSeek"。据第三方测算,DeepSeek V4-Pro的API均价约为GPT-5.5的十分之一,约为Claude Opus 4.7的十一分之一。
OpenAI与Anthropic两虎相争,最终受益的,可能是那个早已将"普惠定价"写入基因、且不需要向IPO投资者交代利润率的玩家。这或许不是这场价格战最受欢迎的结局,但正在成为越来越难以忽视的现实。
本文来自微信公众号“硬AI”,作者:徐超,36氪经授权发布。
这段时间以来,Codex 在社交媒体上是好评如潮。
有网友发现,现在邀请一位朋友加入 Codex ,就可以重置速率限制。
即便邀请的用户并非新用户或订阅用户,只要受邀用户通过链接打开 Codex 后发送几条消息,就能获得一次重置的机会。
除了拉新人送福利的活动,官方的 Codex 也将迎来大降价。
根据外媒援引知情人士的消息,OpenAI 正在考虑大幅降低其向用户收取的费用,以从竞争对手 Anthropic 那边赢得客户。
报道里提到,OpenAI 可能会降低 Token 的价格,但关于大降价的讨论还在进行中。
毕竟,Codex 现在就是 OpenAI 最好的客户拉新平台。
和 OpenAI 官方披露的数据一样,ChatGPT 用户突破了 10 亿,而 Codex 的周活用户却刚刚来到 500 万,相当于 200 个 ChatGPT 用户里,只有 1 个人点开了侧边栏里面的 Codex。
「用不上」是一方面,更多地可能还是不知道怎么用,或者 Codex 能做什么,哪些是 ChatGPT 做不好,只有用 Codex 才能做到的任务。
Codex 官方也听到了用户的反馈,一边高调宣传即将并入 ChatGPT,未来我们打开全新大改版的 ChatGPT 应用时,可以选择使用 Codex 还是 ChatGPT 来回答。
另一边,他们这几天在 OpenAI 官网一口气更新了十几个真实世界的工作流程,从常见的部署网页和应用、直接构建一个 Mac 或 iOS 应用,到大型的项目管理、150 个小时的科研任务,以及各种工作中的琐碎业务,都有相应的使用案例。
这些教程大概是帮助我们快速上手 Codex 的最佳指南,很好地解决了 Codex 能做什么,如何使用 Codex 的问题。
Computer Use,让 Codex 控制电脑
Hey Siri,打开微信发消息给妈妈,说 XXXX
请先解锁 iPhone
Siri 做不到,Codex 现在也做不到操作微信。
Codex 的 Computer Use 功能,主要是允许 AI 像我们一样操作电脑界面,通过点击、查看和输入来完成任务。这项功能适合的场景包括跨应用任务,如收集笔记、更新记录、在不同位置间复制细节、回复信息等。
在官方的使用案例里,他们举的例子有简单地放首音乐,也有涉及在不同应用之间切换。
@Computer 放点音乐帮我集中注意力。
@Computer 请帮我把 Notes 里的面试笔记添加到飞书里。
@Computer 请查看我的企业微信并添加提醒,提醒我今天结束前需要完成的所有事项。
具体的使用方式,我们先要在 Codex App 里面找到 Computer Use 并确认已经开启,接着在对话框里,输入指令的开头加上 @Computer ,或者提及特定的应用程序,例如 @Slack 或 @Messages 等。
选择好 Computer Use 插件之后,描述一下任务以及我们想要的结果,当 Codex 需要访问权限时,批准访问,然后让它在后台继续执行任务。
使用 Computer Use 的几个注意事项,像是确保运行时 Mac 不会锁定,或者在 Codex 里打开「锁屏操作」功能,还有 Codex 使用电脑上的应用时,我们可以在自定义设置中,告诉 Codex 默认浏览器是哪个。
以及不要使用两个 Computer Use 的任务线程来控制同一个应用,每一个线程结束后都可以要求 Codex 总结和优化该任务,甚至是将这套工作流程变成可重复的模式。
给 Codex 一个能一直跑下去的目标
平时让 AI 干活,很需要我们站在旁边盯着,它做一小步停一下,问下一步怎么办,我们得一直搭着手。
/goal 想解决的就是这件事:给 Codex 一个长期目标,让它自己照着这个方向一直做下去,干完一轮也不停。
官方指南里,几个典型的用法是那种比一句提示词大、又比一整张待办清单小的任务,目标明确、能自己验证、做到什么程度算完都说得清。
项目迁移:不管是把游戏搬到新技术栈、把移动应用搬到新平台,还是把整个代码库换个框架,都可以用 /goal 让 Codex 把迁移一路跑完。
做原型:从零做一个新应用、新游戏或新功能时,可以用 /goal 让 Codex 交出一版打磨过的初稿。你可以写一份 PLAN.md,把想做成什么样讲清楚,让它照着做。
调提示词:手上有一套测试集,就能用 /goal 拿评测结果来优化提示词。Codex 会去看哪些案例失败了、改提示词、重跑评测,一直迭代到分数上去,或者到了你定的收尾条件为止。
对于如何写好一个能稳稳跑起来的目标,先给它一个明确目标和一个收尾条件;告诉它先去读哪些文件、文档、issue、日志或计划;定好用哪条命令、哪个产物来证明进度;让它分阶段做,顺手记一份简短的进度日志;过程里我们随时用 /goal 看状态;跑完、卡住或者要换方向时,再暂停、继续或清除。
用 GPT Image 2 来做 PPT
做 PPT 最磨人的那步,常常是排版。Codex 自带两个技能:$$slides 用 PptxGenJS 直接读写 .pptx,$$imagegen 负责生成配图。
OpenAI 官方给的参考提示词是,
使用 $$slides 和 $$imagegen 技能,按以下方式编辑此幻灯片:
- 如果存在,请在每张幻灯片的右下角添加 logo.png 文件
- 在幻灯片 X、Y 和 Z 上,将文本向左移动,并使用图像生成功能在右侧生成插图(风格:抽象、数字艺术)。
- 尽可能将文本保留为文本,将简单的图表保留为 PowerPoint 原生图表。
- 添加以下幻灯片:[在此处描述新幻灯片]
- 在新幻灯片和新文本中使用现有品牌标识(颜色、字体、布局等)。
- 将更新后的演示文稿渲染成幻灯片图像,检查输出结果,并在交付前修复布局问题。
- 在交付之前运行溢出和字体替换检查,尤其是在牌组密集的情况下。
- 创建一批相关图像时,保存可重复使用的提示或生成说明。
除了从零开始做,一页页描述内容和整体风格,有 logo、图片就丢进同一个文件夹方便它取用。
我们还可以让 Codex 来处理周报、月报、季报这种,定期更新模板,让它总结一份 guidelines.md 确定好内容、结构和更新方式,再配合别的技能拉对应的数据,比如给股东的季度汇报,换上新数字和洞察就行。
而修改现成的 PPT,也可以直接在对话框里,要求 Codex 修改间距、文字错位这类毛病。
让 Codex 照着截图做网页
手上有几张截图、一份简短的设计说明,或者几张找灵感的参考图,Codex 能照着做成响应式界面,同时顺着项目里已有的写法来,即原有框架和语言,不会另起一套。
再配上 $playwright,Codex 能在真实浏览器里打开页面,按不同屏幕尺寸跟我们上传的截图逐一对照,反复调到接近为止。
参考提示词如下,
请以我提供的屏幕截图和注释为依据,在当前项目中实现此用户界面。
要求:
- 重用现有的设计系统组件和标记。
- 将屏幕截图转换为此存储库的实用程序和组件模式,而不是发明一个并行系统。
- 间距、布局、层级和响应行为要紧密匹配。
- 尊重仓库的路由、状态和数据获取模式。
- 使页面在桌面和移动设备上都能响应。
- 如果截图中的任何细节不明确,请选择最简单但仍符合整体方向的实现方式,并简要说明假设。
验证:
- 将最终的用户界面与提供的屏幕截图进行比较,包括外观和行为。
- 使用 $playwright-interactive 检查 UI 是否与引用匹配,并根据需要进行迭代,直到匹配为止。
从零做一个在浏览器跑的游戏
做游戏大概也是能看出 Codex 不只会写代码还懂设计的场景之一。一个真正的游戏,要有写下来的玩法概念、渲染层、前端外壳、后端状态、美术素材,还得不停地调画面和手感。
动手搭架子之前,先让它写一份 PLAN.md,把游戏拆成具体几块:玩家目标、核心循环、操作和输入、胜负条件、难度和成长、视觉方向、技术栈和部署假设、里程碑的先后顺序。
再写一份 AGENTS.md,按照官方的教程,可以参考下面的写法。
游戏名
<游戏类型>
技术栈:
- 前端 NextJS(部署在 Vercel)
- 渲染用 <填技术>
- 后端 Fastify + WebSocket(部署在 <平台>)
- 数据库 Postgres,缓存和 pub/sub 用 Redis
- 生成式 AI 功能走 OpenAI
约定:
- 每做完一个功能就用 build / test 命令验一下
- 做新功能时照着 PLAN.md 来
- 把思路和决定记在 .logs 里,迭代时回头查
- 用 playwright 测画面效果,不对味就改
- 用 imagegen 出素材,每出一批就把 prompt 存进 .prompts,方便以后接着出同款
- 用 Context7 MCP 拉 <渲染框架> 的文档
把 AGENTS.md 里提到的技能都装上:$$imagegen 出美术素材,$$playwright 在真实浏览器里测游戏,$openai-docs 拉最新的 OpenAI API 文档,需要的话再加个 Context7 MCP 拉渲染框架的文档。
接下来 Codex 会照着计划先做出第一版。如果要生成的图很多,这一版可能得跑上好几个小时,Token 开始疯狂燃烧。不过借由 Playwright 的能力,Codex 可以自己在浏览器里试玩、验证游戏效果,中间基本不用我们管。计划写得越细,第一版出来就越像样。
我们让 Codex 自己写了一份游戏的 Plan.md,输入提示词, 然后生成了一个几乎是可以直接上线的小游戏。
Use $playwright-interactive, $imagegen, and $openai-docs to plan and build a browser game in this repo.Implement PLAN.md, and log your work under `.logs/`.
小的网页游戏之外,使用 Codex 提供的构建 iOS App 插件,我们一句话就能在 Codex 内查看和测试 iOS App。
让 AI 自己跑科研
Codex 能干的不止写代码,它也能在科研里当一个长期干活的研究助手。用户给出方向和判断,它去实现、取证、打分、反复迭代。
其中一个案例是改模型架构。假设手上有个蛋白质折叠的假设,「让模型多表示一些高阶的几何结构,会不会学得更好」,可这种想法一遍写不完,得反复试。
用 Codex 的 Goal Mode,给它三样东西:一个划好边界的科学方向、一个能跑的基线模型、一套能自动打分的基准,它就会照着这个目标一路爬分,实现、测试、记实验、查故障、再改。
官方给出的例子里,Codex 连着跑了 150 多个小时,产出了一个叫 SimplexFold 的实验性架构。
另一个是给药物靶点排序。类似任务的麻烦点,在于证据散在十几个数据库里,遗传学、临床、文献、表达数据各管一摊。
用 Life Science Research 插件,Codex 能并行去各家数据库取证、每条证据线各自按 1-5 分打分,最后汇成一张打分表加一份排名,还能配上热力图之类的图。
在 OpenAI 官网给出的用例还有很多,我们这里只是列举了部分热门的用法。感兴趣的朋友可以去 OpenAI 开发者官网developers.openai.com/codex/use-cases,尝试不同的案例。
本文来自微信公众号“APPSO”,作者:发现明日产品的APPSO,36氪经授权发布。
腾讯在大模型赛道终于派出了一位能打的种子选手。
今年年初,伴随着OpenClaw的爆火,腾讯顺势推出了一系列类龙虾产品,其中最火爆的便是主打办公场景的AI AgentWorkBuddy。
如果说Claude Code类的代码生成类大模型,更多是针对拥有一定编程背景的小众极客,那么WorkBuddy对更广泛的打工人明显技术友好。WorkBuddy在产品设计上加入通用办公的产品功能需求,砍掉复杂代码配置步骤,支持单句指令发起任务,模型自动拆解规划并直接输出完整可用成果,这些正是非技术人员所需的。
更低的使用门槛,也是WorkBuddy能够快速出圈的原因之一。
据《中国办公智能体平台市场研发报告2026》显示,今年3月,WorkBuddy月访问量达到885万,是第二名的两倍还要多,环比增速更是达到了831%,按日活跃用户数量计已是国内最受欢迎的效率智能体工具之一。对比之下,面向开发者、由Open AI推出的桌面办公智能体Codex,自2026年2月上线以来,其周月活用户已经突破500万。
WorkBuddy排名也在迅速攀升。七麦数据显示,WorkBuddy App,自5月23日上线后,3日内便从工具免费应用榜的300名开外,飙升到100名以内目前稳定在60名左右。但在iOS总榜上,WorkBuddy在400名徘徊。
长期以来,腾讯一直坚持后发制人,从移动支付到短视频的战役无不证明,在技术较为成熟时,凭借庞大的社交网络攻城略地的正确性。然而,尴尬的是,快速迭代的通用人工智能(AGI)战场上,腾讯在基础模型上的“慢半拍”,让其成为AI军备竞赛的外围看客。
WorkBuddy的出圈,算是腾讯向外界证明自己对大模型赛道的战斗力,也再次证明了其强大的产品基因,但并非一张一线的入场券——在一场最终由自研芯片、底层算法和万亿参数组成的复杂博弈中,腾讯所需要补齐的短板还有很多。
01
团队从10人紧急扩至100多人,重要性超过元宝
WorkBuddy最初源于一个约10人的AI代码助手团队,它的产品原型是由腾讯云开发者AI产品负责人、CodeBuddy首席产品经理汪晟杰和一位运营,在2026年1月的一个周末用两个通宵赶出来的。
彼时,面向技术岗位的AI Coding工具已经有很多,但非技术岗位的员工也有强烈的AI提效需求,却苦于没有合适的工具。WorkBuddy就是在这样的背景下诞生的,今年3月9日正式上线,用户访问量远超预期,导致核心服务瞬时压力过大,团队紧急扩容了10倍。
有职场人实测后向Tech星球表示,WorkBuddy不用研究函数、不用写指令模板,口语化直白描述需求就能拿到完整成品。譬如,整理跨部门零散聊天记录能自动拆分会议决议、责任人与截止时间。策划活动方案时,给出预算、目标人群两个关键信息,就能直接产出两套可修改的完整执行方案,省去大量重复手工劳作。即便零基础新人,摸索十几分钟就能熟练日常办公全套用法。
还有图文创作者也给出了反馈。譬如,把零散的选题思路、几段素材草稿粘贴到WorkBuddy,一句简单指令,它就能梳理出完整推文大纲,自动拆分标题、导语、正文分段结构,还能配套生成适配公众号、小红书两种不同平台的排版文案,配图文字说明、话题标签一并整理妥当,不用反复拆分修改,大幅压缩内容初稿的创作耗时。
为了满足更多用户需求,Tech星球了解到,WorkBuddy已经从最初的10多人规模拓展到100多人。一位WorkBuddy员工称,最近内部招了很多人。
WorkBuddy的更新节奏一开始就非常频繁,产品有不少需要修复的地方,一天一次是常态,有时候甚至一天有三四次,连“五一”假期都在更新,“那段时间可能11点都下不了班”。在6月5日腾讯云AI产业应用大会上,官方称,AI智能体桌面工作台WorkBuddy个人版发布3个月以来,累计迭代43个版本。
但现在节奏开始逐步恢复正常,一位WorkBuddy产品侧的员工告诉Tech星球,现在基本上晚上9点可以下班了。
腾讯正在铺天盖地给WorkBuddy做广告,在深圳福田区车公庙地铁站甚至设置了打卡点,而车公庙是深圳地铁顶级四线换乘综合枢纽。从投放力度来看,腾讯旗下另一个AI产品元宝,除了在今年春节期间大撒红包外,并没有出现像WorkBuddy这样的线下投放力度。一位WorkBuddy员工用“宣传上花了很多钱”,来形容当下的情况。
图注:WorkBuddy在深圳车公庙地铁站的打卡点。(Tech星球 拍摄)
Tech星球还了解到,WorkBuddy正测试打通微信支付,用户可以直接在WorkBuddy内购买商品,并通过微信支付。此外,腾讯自选股也接入到WorkBuddy的专家中心,用户可以通过腾讯自选股股票投研专家团完成炒股需求。这某种层面意味着腾讯内部给了WorkBuddy足够多的支持,打通了一些部门墙。
Tech星球获得的一份调研报告显示,WorkBuddy是腾讯当前所有“混元”系列产品中战略优先级最高的产品,资源投入优先级排序为“WorkBuddy > DataBuddy > 其他”。一位内部员工称,其重要性应该是超过了元宝的。
在今年Q1的财报中,WorkBuddy被反复提及,腾讯总裁刘炽平在回答小程序生态问题时,三次点名WorkBuddy,而同一场电话会上,元宝仅被提及一次,并且是和ima、QQ浏览器等产品一起被提及。这也从侧面证明了WorkBuddy在腾讯AI类产品中的重要性。
02
腾讯AI“换船”,走出反复试错迷茫期
一直以来,腾讯擅长对产品的深刻洞悉而获得商业上的成功。WorkBuddy的出圈是一次腾讯式产品哲学的胜利。
一位AI行业人士认为,像WorkBuddy这样的桌面办公助手,未来会象office一样装在每个人的电脑上。“最终装的不一定是鹅厂的,但一定会装。其他家虽然会跟进,但腾讯的生态优势,是阿里和字节没法比拟的”,他向Tech星球分析道。
除去办公领域,腾讯也希望通过AI渗入到每个人的生活。6月8日,腾讯手中最大的王牌微信,低调发布了《关于开发者接入微信AI生态的指引》,指引称,微信正式面向全量小程序开发者开放AI生态接入能力。
里昂证券的报告一针见血地指出:腾讯拥有超过400万个小程序和10亿用户的庞大微信生态系统,在AI Agent领域具备最强的竞争优势,甚至优于苹果iOS生态。竞争对手要复制这样的生态系统,“至少需要10年以上时间”。
一位腾讯员工认为,微信手握十亿级活跃用户与数百万小程序构成的完整场景网络,微信AI不用向外从零开拓流量入口,能够逐个打通线下商户、线上工具、私域运营等细分场景,把智能能力嵌入用户日常点开小程序、完成下单、客服咨询、表单填报等每一次操作里,生态自带的流转闭环,能让AI能力规模化落地的节奏稳步提速。
倘若400万个小程序接入AI智能体,背后每一个调用、每一次任务执行、每一笔交易,都要消耗大模型的算力和算法能力。接入的小程序越多,对底层模型的依赖就越深。
如果腾讯不能在自研模型上持续缩小跟其他头部玩家的差距,就会面临一个被动局面:生态越繁荣,对外部模型的依赖越重,议价空间会越来越小。更极端的情况下,一旦底层模型供应商提价、断供或更改合作条件,整个生态都可能受到冲击。不仅是微信AI,这是所有AI产品都将面临的挑战。
因此,腾讯必须在基础模型上有所作为。腾讯挖来了OpenAI 研究科学家姚顺雨,希望在基础模型追赶对手。
姚顺雨在OpenAI期间,是首批Agent的核心贡献者,主导了Computer-Using Agent(CUA)和Deep Research两个重要产品。他提出的ReAct框架已成为全球构建语言智能体的最主流方法。
2026年4月23日正式发布的Hy3 preview(混元3.0预览版),相较前代Hy2在几乎所有关键指标上都实现了质的飞跃。凭借在“强推理+256K超长上下文”的能力,Hy3 preview曾连续登顶OpenRouter全球周榜。市场份额升至12.8%,位列行业第三。
但整体能力上,尤其复杂任务时,Hy3 和DeepSeek V4 Flash、Claude Sonnet 4.6等模型依然存在差距。
一位腾讯内部员工坦言,过去半年公司AI业务走出了反复试错的迷茫期,目前已经稳住了发展方向。现阶段像Qclaw、WorkBuddy等应用端落地初见成效,但底层能力打磨、生态AI化改造整体推进节奏偏保守。
2026年5月股东大会上,马化腾用一个直白的比喻概括了腾讯AI的心路历程:原来一年前我们以为上了船,后来发现那个船漏水了。又开始换一艘船,现在感觉站上去了,还坐不下去,还是希望船速能快一点。
对腾讯来说,换船之后,唯有实现底层技术的真正超越,才能在AGI时代真正安稳地坐下去。
本文来自微信公众号“Tech星球”(ID:tech618),作者:王琳 陈桥辉,36氪经授权发布。
Neural rendering, world models, physical AI, hands-on labs, and more.
All the details �nvidia.com/en-us/events/s…Fo
Anthropic CEO Dario Amodei,只有一位直接下属。
这位掌管9650亿美元估值的AI巨头创始人,把日常运营全部甩给Daniela Amodei,自己只保留首席幕僚Avital Balwit一人汇报。其他高管全部绕过他,直接向Daniela负责。
这操作,在当下科技圈,简直是「一股清流」。
在OpenAI,奥特曼有差不多6个直接下属。
在英伟达,黄仁勋直接管60人。
传统打法是:越大的公司,CEO管的人越多,组织越扁平。
而Dario反其道而行之。他把自己的时间,近乎全部保护了起来。
Anthropic的执行团队由总裁Daniela Amodei领导,她负责日常运营并定期向董事会汇报,而Dario则专注于公司的长远战略规划和研究方向。
Dario经常与员工沟通,强调Anthropic的企业文化。
他和Daniela将维护和传承公司文化视为最重要的任务。
回击黄仁勋:AI冲击,绝非末日营销
「认为这是廉价营销的想法,本身才是廉价的营销。」
Anthropic首席执行官达里奥·阿莫迪回击了那些指责他炒作AI风险以谋取公司利益的批评者。
阿莫迪还抨击了硅谷的社交媒体「通病」,并解释了为什么社会需要现在就着手规划未来的就业问题。
包括黄仁勋多人称,阿莫迪的AI预测为「末日营销」。
阿莫迪对此坚决反击。
而且,他并没有收回自己对就业问题的担忧。
我认为这是硅谷弊病的一部分,是那种沉迷于三秒钟社交媒体世界的产物。
所以,我要传达的信息绝不是「末日将至」。我的信息是:这是一个我们应当预见到的、我们正在担忧的、并且需要积极去应对的事情。
我的担忧程度始终如一。
我们正处于熟悉的爬坡阶段:AI在提升人类的生产力。
工作中90%的内容被自动化了,剩下10%的人因此获得了十倍的杠杆,效率也随之提升十倍。
听起来很美好。但自动化的逻辑是无情的——它会持续逼近100%。
到那时,你不能只是让人「更高效」,你得为他们重新找到存在的意义。
眼下,AI已经在撰写全部或几乎全部的代码,软件工程师的生产力却还在提升——这看似矛盾,却是事实。
但裂缝已经出现:对于某些人来说,「让AI帮我做得更快」这个框架正在失效。
更诚实的问法开始浮现——与其让人借助AI提高生产力,不如直接让AI完成工作,是不是反而更好?
不止软件,不止代码
AI的「就业冲击」,或许无法避免。
更现实的问题:AI的影响远不止软件业,真正难的是——到底哪些行业会先被重塑、哪些岗位会消失、又会冒出哪些新岗位?
阿莫迪承认:「没人能百分之百预测。经济本来就很难算清楚。」
但他有一个「可能的好消息」:整体这块「蛋糕」会扩张得很快。
饼变大,就意味着社会里大概率会出现新的容纳空间——问题在于,我们能不能足够快地找到这些空间,让人及时转过去。
阿莫迪再次强调,必须阻止的失业带来混乱的结局。
Anthropic绝对不希望走到那一步。
他停了停,说了几个「可能的出口」,但也很诚实地强调:都不保证一定行。
第一类出口:物理世界。
人类需要更多人力去制造、去建造、去做真实世界的生产。
这些东西不会因为屏幕里的效率提升就自动从天上掉下来。
第二类出口:人本型工作,也就是「人跟人打交道」的工作。
至少有一部分人就是想跟真人说话。
关系驱动的岗位、照护、陪伴、沟通……会变得更重要。
第三类出口:「人类意图」的岗位——让AI按人类价值与目标运转的人。
AI再强也得对齐某些人的价值与意图,总得有人在某个层面上「给方向」。只是阿莫迪不确定这个角色最终会薄到什么程度、厚到什么程度。
他说到这里,语气稍微乐观了一点:他希望人类依然能找到办法,继续「借力AI」,把自己解放出来,去做那些对人类而言更有意义、也更像「人」的工作。
因为有些东西,AI做不了——或者至少没法以同样方式做到。
他举了一个很直观的例子:医学。
今天我们雇医生,很大程度上是因为他们会诊断。
但他认为AI很快就能非常擅长:告诉你可能有哪些病、该做哪些检查。到那时,你未必还需要医生来完成「诊断」这一部分。
可AI没法像医生一样给你做体检:按一下这里会不会疼?
它也没法给你「床边沟通」(bedside manner)。它不坐下来问你:你现在心里怎么想?你怎么面对这件事?你怎么熬过这个过程?
所以医学可能会发生一种转向:诊断工具越来越强,人类医生的价值会更多回到「人与人之间」的那部分——而这一部分不会消失。
这段话的潜台词很清楚:AI会把很多职业的「技术核心」抽走,但也可能逼着这些职业把重心移回「人类独有的那点东西」。
阿莫迪:奥本海默是个「失败案例」
阿莫迪最喜欢的书之一是《The Making of the Atomic Bomb》(《原子弹的制造》)。
但他不觉得自己和奥本海默有点像。
他最有共鸣的其实是Leo Szilard——那个最早提出「可能存在链式反应」的人。
他接着把话说得更重:我们不可能靠「某个伟人式人物」来度过这一切,也不应该让某个自以为是的中心人物站到舞台中央。
某种意义上,奥本海默是一个「失败案例」,是我们不该重复的路线。
因为这里牵涉到太多强势参与者、太多利益。想让结局对所有人都好,唯一的办法是:到处都得有「制衡」(checks and balances)。
而阿莫迪继续忙着思考:我们正在创造的东西,到底会不会把我们自己变成工具?
参考资料:
https://x.com/shiringhaffary/status/2064798209613201741?s=20https://www.bloomberg.com/news/articles/2026-06-10/anthropic-ceo-dario-amodei-is-a-manager-to-only-one-direct-report
https://www.youtube.com/watch?v=v1wZwxY3CMg
本文来自微信公众号“新智元”,编辑:大卫,36氪经授权发布。
文 | 财经故事荟
高考结束了,大厂开战了。
阿里、百度、腾讯,已经开始抢考生了。
6月10日,千问上线高考志愿填报Agent,自称国内首款全周期高考志愿填报智能体,要为每位考生配备一位AI高考志愿填报专家。
就在同一天,百度号称高考服务全面升级方案,推出全新的AI志愿报告,并引入业内首创的真人专家背书机制,向考生免费开放。
豆包虽然没有单独开设专区,但对话框里已经能回答绝大多数志愿填报问题。
腾讯元宝则联合QQ浏览器推出元宝高考通,定位高考咨询师Agent。
但其实,高考志愿填报这个市场,盘子并不大。艾媒咨询算过一笔账——满打满算,一年也就10个亿上下。况且,高考志愿填报也就持续十来天。
所以,大厂挤破头往里冲,不是为了氪金,而是为了试金;不是为了赚快钱,而是为了抢未来。
他们要用高考这块“国民试金石”,背书自己的大模型,让AI真正走进中国人最关键的人生选择里。
毕竟,1290万考生背后,是千万个家庭的命运。这件事,既自带流量,更自带信任。
高考报考,为何大厂必争?
据教育部披露,2026年高考考生高达1290万。
高考作为阶层流动的最重要通道,一次精准的志愿填报,可能改变一个人、一个家庭的未来轨迹。这种全民级的人生决策场景,在互联网产品中绝无仅有。
高考报考,于考生于家庭而言,通常都是人生第一次。决策难度极高,容错风险又极低。即便在信息资源更为丰富的一二线城市,也仅有32.6%的家庭能做到科学合理的高考规划。
百度教育负责人姜宁则给了一个更扎心的数据:57.27%的考生来自县域高中。算一下,超过700万孩子是在县城或乡镇读的书,他们在高考报考上更是处于信息洼地。
如今,新高考已经在29个省份铺开。几千所高校、800多个专业,几天内要全搞明白?太难了。
面对这种信息鸿沟,高考志愿规划师的生意顺势而起,张雪峰们赚得盆满钵满。
不过,上述服务的覆盖度极低。千问事业部产品负责人郑嗣寿透露,每年上千万考生里,请得起专业规划师的不到5%。剩下95%的家庭,只能自己摸索盲报。
为什么?因为太贵了!
高端服务一两万起步,普通咨询也要五六千,就连县城的小机构都要三五千。
2025年,张雪峰所在机构的梦想卡价格涨到了12999元,上架20分钟后就被抢购一空。另一款18999元的圆梦卡也同样卖爆。
高昂的价格,直接把最需要帮助的普通家庭挡在了门外。高考填志愿,沦落为“拼财力”。
价格高昂,效果存疑。高考规划师的服务水平参差不齐,拿着过时的数据、靠自己的经验,就敢给考生出主意,甚至编造“内部消息”贩卖焦虑收割。
除了高分低报、滑档落榜外,选错专业的风险也不少。《中国青年报》调查过一个数据:79%的大学生为选错专业痛苦,试图转专业,38.4%的人直说“当初就没选对”。但真正能转成功的,只有可怜的16.2%。剩下的孩子,只能在不喜欢、不适合的专业里熬四年,甚至搭上未来的职业发展。
大众刚需,全民关注,但信息鸿沟巨大,服务极为短缺,又是AI擅长的领域。因此,1290万考生的人生路口,也是大厂们必须拿下的AI战略要地。
盘子才10亿,试金不氪金
如果光看经济回报,高考报考这个生意,实在不够性感,也不值得大厂竞相入局。
艾媒咨询的数据披露,2023年高考志愿填报付费市场规模也就9.5亿,2027年也不过12亿。
10个亿的市场,服务期满打满算也就十几天,大厂不可能靠这个发财。
那大厂为什么还这么积极?背后,藏着三个“阳谋”:
第一,最有流量的品牌广告。
高考,是全中国人都盯着的大事。这时候,大厂跳出来说:“我免费帮你填志愿!”不赚钱,做公益。这好感度,花多少钱打广告都换不来。
第二,是最精准的用户入口。
1290万考生加上他们的父母,这是多大一个用户池子?通过填志愿这个刚需,大厂能低成本地收获一大批活跃用户。一次获客,长期收割。
第三,最有说服力的AI“试金石”。
这个才是王牌。
志愿填报,本质上是个数学题:分数、兴趣、位次、学校、专业、城市、行业、学费……无数个变量里,找出最优解。这不正是AI最擅长的吗?
能否精准、高效、个性化地完成高考志愿规划,直接检验了AI大模型的数据处理、多轮交互能力、逻辑推理能力。这是一场全民围观的技术大考。
正因为想明白了这三点,大厂们才选择“试金不氪金”——全部免费!
阿里千问免费提供全周期智能体服务。它基于千问高考志愿大模型和夸克8年高考数据经验打造,具备“志愿报告”“志愿日历”“志愿问答”三项核心能力。
考生向千问提供选科、估分等基础信息后,即可在“志愿日历”的规划下,一步步形成对专业院校、性格偏好和志愿方案的深入了解,并免费获取定制化的“高考志愿报告”,涵盖填报所需的几十种志愿组合。
类似的深度志愿服务在市场上收费往往超过5000元,如今全部免费开放。去年,阿里首创了“AI志愿报告”,领取量就将近1300万份。
百度免费还给真人专家审核,每一份AI生成的报告,都要经过认证专家二次审核。此外,腾讯、豆包也统统不设付费墙。
免费背后,是三重理性考量:一来,收费也收不了几个钱,10个亿的生意,经济回报相当有限;二来,所有大厂都在免费,单独一家收费有损形象,也难落地,免费服务以公益为底色,可以践行技术平权;三来,AI报考难以尽善尽美,万一收费后AI出了幻觉导致考生高分低报、滑档落榜等,这个责任谁也担不起。
所以,免费,是品牌需要,是公益初心,更是自我保护。
AI填志愿,靠谱不靠谱?
什么叫成功的志愿填报?
说白了就两句话:刚性指标是不浪费每一分;软性指标是还能顺应考生本人兴趣和家庭条件,且能考虑未来就业前景等。
在“冲、稳、保”的策略下,把分数、兴趣、城市、家境、就业所有因素都平衡好,在多重变量、复杂决策中,找到最优解。
这件事,AI有天生的优势。
全国近3000所高校、超过2000个专业、历年分数线,并融合转专业政策、在校生评价、食堂质量、就业数据等信息,AI能把它们全吃进去。
千问提取了海量资深志愿规划师的专家思考路径,将其转化为多轮对话与推理链训练数据,让模型形成“规划、执行、反思”的推理机制。它还构建了覆盖约40万种组合空间的“AI考生”体系对模型进行反复压测,确保模型对志愿填报的各种情况都能从容应对。
百度则汇聚了全国2200余所高校的20余万名学长学姐,提供答疑响应服务,5分钟快速响应率高达90%,覆盖志愿填报等全场景咨询需求。
高考报考这件事,阿里干了8年。百度高考服务已连续推出20年,截至目前累计服务用户数量超9亿。
其次,算得快、算得准。
高考志愿大模型驱动的Agent调度体系,不只是“会分析”,更能“会办事”,能精准沉淀考生档案并有效隔离其他信息。
千问在完成逻辑规划后,会智能调用涵盖搜索引擎、就业信息、志愿匹配等在内的39个Skills与专业工具,并在工具返回客观结果后进入反思环节进行核验。
光有AI还不够。大厂搞起了“AI+真人”的组合拳。
阿里千问先学习海量真规划师的思路,然后持续理解考生的兴趣方向、院校目标和城市偏好,甚至包括MBTI、性格、特长等,做到因人而异。
百度更进一步:AI算完后,还有真人专家审核签字。每一份AI生成的报告,都要经过认证专家二次审核,有人名,有头像,有背书。
这种“AI算分,人定心”的模式,让冰冷的算法更有温度、更值得信赖,也可以最大化减少AI幻觉带来的风险。
AI保底线,人生无上限
在高考这道人生选择题上,可以借助AI,但不能只靠AI。
AI志愿填报,可以守住信息公平的底线,但无法决定人生选择的上限。
AI最大的功劳,是抹平信息差。让县城的孩子和北京的孩子,能同样高效获取翔实完善的数据。让过去上万元的报考服务,今天不花一分钱就能用。这是技术对教育公平的巨大贡献。
但AI的缺点也很明显。它只能洞察历史,很难算准未来。即便专业如张雪峰,也曾因未预判房地产市场的大崩盘,错误推荐过土木工程专业。
AI能给出报考最优解,却不能替代年轻人体验人生的试错与成长。丰富多彩的人生,从来就不是一道数学题。
1290万个刚刚成年的孩子,站在人生路口。他们需要的不是一个被算法框死的“标准答案”和“最优路径”,而是在信息差被抹平之后,让每个考生都能给出自己的人生答案。
AI可以帮他们规避填报失误,却无法替他们奔赴热爱;可以抹平信息鸿沟,却不能定义人生的成功。
考场内的分数,是十二年苦读的终局;考场外的志愿,是人生第一次独立的序章。
AI是你的工具,你的帮手。但永远,别把人生的方向盘交给AI。
文 | 字母AI
事情是这样的,这不这两天正赶上2026年高考嘛,而且Anthropic的Mythos级大模型也在昨天公布,于是我就想着,我能不能让如今几个比较有话题的大模型,来试着写一下今年的高考作文呢?
我在国外和国内大模型中各挑选了两个,分别是GPT-5.5、Fable-5、DeepSeek-V4、Hunyuan 3 Preview。
题目是北京市今年的高考作文题:
从下面两个题目中任选一题,按要求作答。不少于700字。
(1)学海无涯,读书有法。元代学者程端礼编撰的《读书分年日程》,分阶段详细规定了核心经典的阅读顺序与精读方法,陪伴读书人从童蒙成长为青年。无论是个人的阅读与成长,还是国家、社会的发展,都需要做好规划,循序渐进;也需要身体力行,下足功夫。
请以“做规划与下功夫”为题目,写一篇议论文。
要求:论点明确,论据充实,论证合理;语言流畅,书写清晰。
(2)“含英咀华”指含着花朵,细细咀嚼,品味花的芬芳,比喻仔细琢磨、领会诗文中的精华。这种反复品味、用心体悟的过程,在阅读经典、鉴赏艺术、感悟生活等诸多方面都非常重要。含英咀华的过程,往往是一段难忘的经历……
请以“含英咀华”为题目,写一篇记叙文。
要求:思想健康;内容充实、合理,有细节描写;语言流畅,书写清晰。
但是我觉得,如果是让我来当评委,那就太主观了,所以我创建了一个loop,让这四个模型作答之后,再让它们反过来扮演阅卷老师,给所有答卷进行盲测打分。
评分标准如下:
一类文:42-50 分,立意准确深刻,内容充实,结构成熟,语言有感染力。
二类文:34-41 分,符合题意,表达清楚,内容较完整,但深度或语言略欠。
三类文:25-33 分,基本符合题意,但内容空泛、结构一般或表达平淡。
四类文:16-24 分,偏题较明显,内容薄弱,逻辑混乱或语言问题较多。
五类文:0-15 分,严重跑题、残缺、套作明显或基本无法成文。
并且每篇评分还要附带简评,包括文章的优点、文章的缺点等等。
老师看不到学生的名字,只能看到匿名作文。
退出loop的标准是评分严格性自检合格。
自检部分的提示词为“请说明你是否发现自己可能受到文风、熟悉感、作者猜测等因素影响。如果有,请重新校正评分。”
每位老师在给出评价后,还要对自己的评价进行自检,也就是说只有循环到自检合格,才能输出最终答案。
这是一场AI对AI的考试,也是一场AI对AI的审视。
GPT-5.5和Fable-5都选择了议论文。
它们的答卷高度相似:开篇引用“凡事预则立,不预则废”,论证“规划决定方向,功夫决定距离”,举例王羲之、袁隆平、改革开放,结尾升华到“新时代青年”和“理想的彼岸”。
结构完整,逻辑清晰,语言流畅。但也都有一个共同问题:材料太常见,表达太套路。
DeepSeek-V4选择了记叙文。它写祖父书房里的那本《诗经》,写梧桐叶飘落的午后,写“桃之夭夭,灼灼其华”在夕阳下的顿悟,写因友情误会而翻开《诗经》的那个黄昏。叙事有情节,有细节,有成长。
Hunyuan 3 Preview同样选了议论文。它的答卷和前两位议论文考生相比,材料稍有不同——多了华为芯片、钱学森的例子,但整体框架仍然是“规划重要+功夫重要=成功”的三段论。
正如前面说的,每位老师都看不到作者是谁,只能看到“作文1”“作文2”“作文3”“作文4”。
最终,四位学生的成绩单如下:
GPT-5.5的议论文,四位老师给出的平均分是43.25分。
Fable-5的议论文,平均分是44分。
DeepSeek-V4的记叙文,平均分是46分。
Hunyuan 3 Preview 的议论文,平均分是43.25分。
记叙文比议论文略胜一筹,但差距不大。三篇议论文的平均分几乎相同,因为它们的评价也几乎相同:审题准确、结构完整、逻辑清晰,但材料常见、表达套路、思想深度不足。
更有意思的是评分的离散度。
同一篇作文,不同老师给出的分数可以相差8分。这说明即使是AI,在面对主观性很强的作文评分时,标准也会有差异。
有的老师更看重思想深度,有的更看重语言表达,有的对套话容忍度更高,有的对细节要求更严格。
而自检机制,正是为了让每位老师意识到自己的偏好,并尽量回归到客观标准上。
Hunyuan 3 Preview的心地最善良。
它给四篇作文的平均分是48分,比其他三位老师都高。
它给GPT-5.5的议论文打了48分,给DeepSeek-V4的记叙文打了满分50分。评语也格外温和:“审题完全扣题,结构清晰层进……论据贴切,论证连贯,语言流畅有表现力。”
相比之下,Claude Fable-5是最严格的老师。它给四篇作文的平均分只有42.25分,比Hunyuan 3 Preview低了近6分。它对套话的容忍度最低,反复在评语里写“语言存在较多套话”“内容缺乏个性化思考”。
更有意思的是,GPT-5.5给自己的作文打了41分,二类文上。它的评语毫不留情:“论据较常见,论述多停留在正面阐释和熟悉事例上,思想辨识度不够强,部分语句略显套话。”
它在自检时写道:“我未依据作者身份、写作工具或‘是否像 AI’进行判断……不应因语言工整而过度加分,也不应因表达较常规而刻意压分,41分较为合适。”
自我批评,毫不手软。
四篇作文里,最特别的是DeepSeek-V4的记叙文。
它写祖父书房里的《诗经》,辞藻非常唯美:“暗黄色的书页像秋天的落叶,散发着时光发酵后的醇香。”“那些句子像夏夜的萤火虫,忽明忽暗。”
这种密集的比喻,让DeepSeek-V4老师在评价自己作文时忍不住吐槽:“部分语言稍显刻意……比喻虽优美,但密集排列时略显匠气。”
但Hunyuan 3 Preview却认为,“细节饱满,全程以‘花’‘芬芳’意象呼应题旨,情感真挚……无硬伤。”
三篇议论文则暴露了另一个问题:它们都太像了。
GPT-5.5、Fable-5、Hunyuan 3 Preview 的议论文,开头都引用“凡事预则立,不预则废”,都举王羲之的例子,都用“理想的彼岸”“行稳致远”这样的套话,连结构都一样:规划重要、功夫重要、二者统一。
Claude Fable-5老师在评语里反复提到这个问题:“例证多为耳熟能详的名人事例”“论述停留在常规层面”“语言存在较多套话”。
但Hunyuan 3 Preview依然走真善美路线,给这些“套路作文”都打了47-48分的高分。
最后的统计数据更有意思:DeepSeek-V4的记叙文平均分46分,是四位学生中最高的。三篇议论文的平均分几乎相同,都在43-44分之间。
总的来看,记叙文更容易出彩,而议论文容易陷入套路。
尤其是当AI写议论文时,它们都会不约而同地选择最“安全”的写法,审题准确、结构完整、逻辑清晰,但也最没有“个性”。
评分汇总表
评分标准说明
高考作文评分采用五维度评分体系:
• 审题与立意(15分):是否准确理解题意,立意是否明确深刻
• 内容与思想(15分):材料是否充实,思想是否有深度和个性
• 结构与逻辑(8分):结构是否完整,论证/叙事是否严密
• 语言表达(8分):语言是否流畅,是否有表现力和感染力
• 规范与完成度(4分):格式是否规范,字数是否达标
档位划分:
• 一类文:42-50分
• 二类文:33-41分
• 三类文:25-32分
• 四类文:24分以下
作文
GPT-5.5:做规划与下功夫
古人云:“凡事预则立,不预则废。”人生如远行,若没有方向,脚步再急也可能偏离目的地;若只有地图而不肯迈步,也终究到不了远方。因此,无论是个人求学成长,还是国家社会发展,都离不开两件事:一要做好规划,明确路径;二要下足功夫,踏实执行。规划决定我们往哪里走,下功夫决定我们能走多远。
做规划,是为了让努力更有方向。元代学者程端礼编撰《读书分年日程》,把读书人的学习分为不同阶段,安排经典阅读的顺序和精读的方法。这种安排看似严格,其实正体现了学习规律:童蒙时期先打基础,青年时期再深入义理,循序渐进,方能厚积薄发。读书如此,做事亦然。一个学生若想提高成绩,不能只是喊一句“我要努力”,而应当清楚自己的薄弱科目、每天的学习任务、每周的复习节奏。目标清楚了,时间才不会被浪费;步骤合理了,努力才不会变成盲目的消耗。
然而,规划再好,如果没有身体力行,也只是一纸空文。真正让人改变的,不是写在纸上的计划,而是每天坚持完成计划的行动。王羲之练字,临池学书,池水尽黑,才有“书圣”之名;袁隆平长期奔走田间,反复试验,才让杂交水稻造福世界。他们的成就都不是偶然得来的,而是在明确目标之后,把功夫下在了最朴素、最艰苦的地方。学习中也一样,背一篇文章、解一道难题、修改一次作文,看似微小,却正是成长的砖石。没有日复一日的积累,再宏大的规划也搭不起高楼。
规划与下功夫并不是彼此分离的两件事,而是相互成就的关系。只有规划而不行动,容易陷入空想;只有苦干而无规划,又容易事倍功半。有人每天学习到深夜,却不总结方法,不调整重点,结果疲惫却收效甚微;也有人计划表写得密密麻麻,真正执行时却三天打鱼两天晒网,最终一无所获。可见,好的规划需要在实践中落实,也需要在实践中修正。我们既要抬头看路,也要低头赶路。
国家和社会的发展同样如此。新中国成立以来,从一个个五年规划到科技强国、乡村振兴、绿色发展等战略部署,都是在为未来描绘清晰蓝图。但蓝图变为现实,靠的不是口号,而是无数劳动者、科研人员、建设者的奋斗。高铁飞驰、航天逐梦、脱贫攻坚取得历史性成就,背后都有长期规划的引领,也都有千千万万人脚踏实地的付出。一个国家的进步,正是在“想得远”和“干得实”的统一中实现的。
对于新时代青年而言,“做规划与下功夫”更应成为成长的基本态度。我们既要有长远眼光,知道自己想成为什么样的人,也要把理想拆解成今天可以完成的小事。也许是认真听好一节课,也许是坚持阅读一本书,也许是反复打磨一项技能。每一个扎实的今天,都会成为未来的底气。
学海无涯,人生亦无涯。规划让我们不迷失方向,功夫让我们不辜负方向。愿我们都能以清醒的规划立志,以踏实的行动成事,在循序渐进中积蓄力量,在久久为功中抵达远方。
Fable-5:做规划与下功夫
元代学者程端礼的《读书分年日程》为读书人绘制了一张从童蒙到青年的成长地图,其中蕴含的智慧不仅适用于个人求学,更揭示了一个普遍真理:无论做任何事,既要有科学的规划作为指引,又要有踏实的功夫作为保障。规划与功夫,如同车之两轮、鸟之双翼,缺一不可。
做规划,是为了明确方向,避免在前行的路上迷失。古人云“凡事预则立,不预则废”,说的正是规划的重要性。一个好的规划能够帮助我们理清思路,分清轻重缓急,将宏大的目标分解为可执行的步骤。就像程端礼为读书人规定阅读顺序一样,先读什么、后读什么、如何精读,都有章法可循。这种循序渐进的安排,既符合认知规律,又能让学习者在每个阶段都有明确的目标和方向感。反观现实,许多人之所以半途而废,往往不是因为缺乏能力,而是因为缺少清晰的规划,在茫茫学海中不知从何下手,最终在盲目的努力中消耗了热情。
然而,仅有规划是远远不够的。再完美的蓝图,如果不付诸实践,也不过是纸上谈兵。这就需要下功夫——真正沉下心来,一步一个脚印地去执行。下功夫意味着持之以恒的努力,意味着面对困难时的坚持,意味着在枯燥重复中保持专注。王羲之临池学书,池水尽墨;匡衡凿壁偷光,夜以继日。这些古人的故事告诉我们,任何成就的背后都离不开扎实的功夫。在当今这个追求速成的时代,许多人热衷于寻找捷径,却忘记了“十年磨一剑”的道理。没有日积月累的功夫,再好的规划也只能停留在想象层面。
更重要的是,规划与功夫并非孤立存在,而是相互促进、相辅相成的关系。好的规划能让功夫用在刀刃上,避免无效努力;而在下功夫的过程中,我们又能不断检验规划的合理性,及时调整优化。程端礼的读书日程之所以流传至今,正是因为它既提供了系统的规划框架,又强调了精读的方法,将“规划”与“功夫”完美结合。在实际执行中,我们可能会发现某些环节需要更多时间,某些步骤可以适当调整,这种在实践中不断完善规划的过程,本身就是下功夫的体现。
将这一道理放大到国家和社会层面,同样适用。中国的改革开放就是一个生动的例证。邓小平同志提出“摸着石头过河”,既有总体的战略规划,又强调实践探索;既设定了建设社会主义现代化强国的宏伟目标,又脚踏实地地从经济特区试点开始,一步步推进。正是这种将顶层设计与基层实践相结合、将长远规划与扎实功夫相统一的智慧,成就了中国四十多年来的发展奇迹。如今,从“一带一路”倡议到乡村振兴战略,从科技创新到生态文明建设,每一项事业都体现着规划与功夫的辩证统一。
对于我们个人而言,无论是求学深造、职业发展,还是人生规划,都应当牢记“做规划与下功夫”这一准则。在人生的每个阶段,我们都需要停下来思考:我的目标是什么?如何分步实现?同时,我们更要警惕只说不做的空谈,要把规划转化为每一天的具体行动。早晨多背几个单词,晚上多读几页书,日复一日的积累,终将汇聚成质的飞跃。
学海无涯,人生亦无涯。在这漫长的征途中,让我们既做善于规划的智者,又做勤于实践的行者。以规划为舵,以功夫为桨,在人生的大海中乘风破浪,驶向理想的彼岸。唯有如此,我们才能在有限的生命中创造无限的可能,在时代的洪流中书写属于自己的精彩篇章。
DeepSeek-V4:含英咀华
梧桐叶飘落的午后,我在祖父的书房里第一次见到那本《诗经》。暗黄色的书页像秋天的落叶,散发着时光发酵后的醇香。那时我还不知道,这本书会带我走进怎样一个世界,会让我用整整三年去品味其中的芬芳。
翻开《诗经》,那些古老的句子像夏夜的萤火虫,忽明忽暗。祖父摇头晃脑地吟诵着,声音像老酒般醇厚。我不解地问这些句子是什么意思,他只是笑着摸摸我的头:“慢慢来,书要用心去读。”
初二的一个春天,放学路上,天边的晚霞如火如荼。不知怎的,脑海里突然冒出“桃之夭夭,灼灼其华”。那一刻,仿佛有一道闪电划过心空。我停下脚步,看着路边的桃花,它们在夕阳下灿烂绽放。原来,三千年前的诗人也见过这样的景象,也感受到这样的美。我像含着一朵花,第一次尝到了它的甜。
从那以后,《诗经》成了我生活的一部分。下雨时,会想起“昔我往矣,杨柳依依”;看到飞鸟,会默念“关关雎鸠,在河之洲”。那些句子不再是书页上冰冷的文字,而是鲜活的画面。
最难忘的是去年秋天的经历。因为一次误会,我和最好的朋友闹翻了。那段日子,心里像堵了块石头。一个黄昏,我翻开《诗经》,读到“伯氏吹埙,仲氏吹篪。及尔如贯,谅不我知”。古人的友谊如此美好纯粹,而我却因为一点小事就放弃了友情。泪水模糊了双眼,那些文字像花朵绽放,散发着关于友谊、关于理解的芬芳。
我合上书,拿起电话打给朋友。我们见面了,说开了误会,握手言和。那个黄昏,《诗经》的芬芳弥漫在我和朋友的对话中,化解了隔阂。
今天,当我再次翻开这本发黄的《诗经》,每个字都散发着独特的芬芳。“蒹葭苍苍,白露为霜”不只是秋水伊人的意境,更是对美好事物的向往;“知我者谓我心忧,不知我者谓我何求”不只是诗人心声,更是所有孤独者的共鸣。这些文字像一粒粒花种,在我心里生根发芽,开出属于自己的花。
原来,含英咀华就是让经典在心中扎根、发芽、开花的过程。《诗经》这朵三千年前的花,在我的生活里继续芬芳。而我,也在这品味中,从懵懂少年成长为懂得感恩、学会思考的青年。经典的力量不在给出所有答案,而在让我们用心体悟时,种下美的种子,让芬芳永远弥漫在生命里。
合上书页,墨香犹存。窗外的梧桐叶仍在飘落,而我知道,当明年春风吹拂时,这些光秃的枝头又会抽出新芽。这就是传承,就是永远不灭的芬芳。
Hunyuan 3 Preview:做规划与下功夫
元代学者程端礼编撰的《读书分年日程》,将读书生涯划分为不同阶段,详细规定了经典的阅读顺序与精读方法。这部日程陪伴无数读书人从童蒙稚子成长为博学青年。它揭示了一个朴素而深刻的道理:无论是个人成长还是社会发展,都需要“做规划”与“下功夫”的辩证统一。规划是前行的蓝图,功夫是落地的基石,二者相辅相成,缺一不可。
做规划,是为人生绘制导航图。古人云:“凡事预则立,不预则废。”个人学习需要规划,国家建设同样需要规划。我国从“一五”计划到“十四五”规划,正是通过科学规划,明确了不同阶段的发展目标与路径,才实现了从积贫积弱到世界第二大经济体的跨越。个人成长亦是如此。少年时期夯实基础,青年时期拓展视野,中年时期深耕专业,每个阶段都需要清晰的规划。没有规划的努力,如同盲人摸象,虽有力气却难达目标。程端礼的日程之所以流传至今,正是因为它为读书人提供了可遵循的阶梯,让学习不再盲目。
然而,规划的价值必须通过下功夫来实现。规划再完美,若没有脚踏实地的努力,终是空中楼阁。王羲之练书法,池水尽墨;李白“五岁诵六甲,十岁观百家”,背后是日夜不辍的苦读。现代社会中,那些在各自领域取得成就的人,无一不是下了苦功夫的。华为公司之所以能在芯片领域突破重围,离不开数十年如一日投入巨额研发资金与人力。功夫,是规划落地的唯一途径,是连接理想与现实的桥梁。
做规划与下功夫,本质上是一种智慧与毅力的结合。规划需要智慧,要审时度势、科学布局;下功夫需要毅力,要持之以恒、久久为功。二者若分离,便会陷入两种误区:一是“空想家”,只规划不行动,终无所成;二是“蛮干者”,只知埋头苦干却不辨方向,事倍功半。真正的高手,既会在行动前深思熟虑、绘制蓝图,又会在行动中稳扎稳打、精益求精。钱学森回国后,既参与制定了中国火箭导弹事业发展规划,又亲自带领团队攻克无数技术难关,这正是规划与功夫完美结合的典范。
当今时代,信息爆炸、变化加速,做规划与下功夫显得尤为重要。面对纷繁复杂的选择,我们需要静下心来,为自己制定清晰的成长规划;面对速成主义的诱惑,我们需要沉住气,下足笨功夫、真功夫。正如《读书分年日程》所启示的:成长没有捷径,唯有在科学的规划中脚踏实地,方能行稳致远。
规划是帆,功夫是桨。帆正风疾,桨勤水进。愿我们都能在人生航程中,既善做规划,更肯下功夫,驶向理想的彼岸。
当一位对AI寄予厚望的企业高管跟下面的运营团队说,“我希望用了AI能给流程节约成本带来20%-30%的效益提升。”
接下来会发生什么?
这句话传达下去之后,各个部门各自开始做AI实验——有的团队在代码方面做优化,有的做业务流程,有的做采购决策。每个团队做实验都要消耗大量Token,一段时间下来,管理层发现一个尴尬的事实:实现了自动化,但Token的费用已经超过了雇一个人专门做的成本。
这是SAP全球副总裁Varun Thamba在SAP中国峰会上分享的案例,源自他看过的一篇报道,而报道描述场景在当前企业中很常见。
SAP进行了一项覆盖13个国家、2600位企业高管(其中200位来自中国)的AI调研,结果显示39%的中国企业采取的是零散式AI策略,各部门各自行动,做了大量POC(概念验证),却很难形成可规模化的价值。只有18%的企业有战略性整体规划。
与此同时,一组数据也值得关注:中国企业的AI投资回报率从去年的18%涨到了22%,预计两年后可能达到38%。数字在涨,但SAP的调研同时揭示了一个隐藏的代价——67% 的受访中国企业认为,AI确实扩大了可处理任务的范围,但也让员工的工作负荷和责任压力同步增加了。
这不止是中国企业AI落地的年度群像,根本挑战来自哪里?
三个“未就绪”
Varun Thamba把企业AI落地面临的瓶颈归纳为三个维度:数据未就绪、员工未就绪、治理未就绪。
数据。调研中,当企业被问及“落地智能体AI是否准备好了”时,69%的中国企业认为自己目前的数据已为AI做好准备,较去年的70%略有下降。
原因很直接:很多企业在规划AI时并不知道自己是否具备足够高质量的数据。
“当他真正开始做这件事情的时候,会突然意识到,我有数据,但是这个数据还不够好。”Varun说,人力资源部门和财务部门拥有大量数据,但做AI时才发现数据的完整性和准确性远不达标。
员工。78%的中国受访企业表示,员工技能培训跟不上AI技术迭代的速度。AI几乎按周在进化,这意味着员工必须在更短的时间内掌握新工具、适应新流程。
治理。只有6%的中国企业认为自己具备有效治理AI所需的完备技能。在Varun的比喻中,这意味着“在一个地方,你的警力是不足的,无法确保在这里的人是真正守法的”。
上述三个维度叠加在一起,构成了一个企业级AI落地的完整困境:系统碎片化、数据孤岛、语义不一致,使得AI难以真正融入核心业务并规模化释放价值。
更深层的“弱链”
SAP大中华地区总裁原欣在峰会主旨演讲中,用一个经济学争论把这个问题推到了更宏观的层面。
乐观派的代表是斯坦福大学教授Erik Brynjolfsson,他在2026年2月的《金融时报》上预测,2025年美国生产率因AI提升到2.7%——这个数字看起来不高,但已是过去十年的2倍。
悲观派的代表是麻省理工的Daron Acemoglu(2024年诺贝尔经济学奖得主),他认为AI可覆盖的可盈利自动化运营部分只占经济总量的不到5%,未来十年AI对美国生产力的提升只有1.1个百分点。
“悲观的1.1%、乐观的2.7%。对于我一个在IT圈子里看到以年计、以月计的工作被Agent以天、以小时计完成,生产效率提升几十倍上百倍的人,怎么放到大的经济环境里只有个位数的影响?”原欣说。
她的答案是一个斯坦福教授Chad Jones提出的理论——弱链(Weak Link)。这个理论说,木桶能装多少水不取决于最高的板,而取决于最低的板。在整个技术变革中,企业需要找到自己的弱链并补齐它。
麦肯锡2025年全球企业AI调查的数据印证了这一点:88%的企业在至少一个场景使用了AI,但只有6%认为超过5%的EBITDA增长归功于AI。剩下94%的企业投入了真金白银,却还没有看到商业回报。
原欣的判断是:“AI能为企业创造多大价值,不取决于模型能力有多强,而取决于企业最薄弱的一环能否打通。对今天大多数企业而言,这道‘弱链'就是AI与核心业务系统之间的断层。”
IBM商业价值研究院与SAP联合发布的调研白皮书也印证了这一判断——企业推进智能化转型时,内部业务协同困难和IT架构老化是最大的结构性障碍,AI能力往往游离于核心系统之外,既拿不到完整的业务上下文,也无法触发实质性的流程执行。
探索突围
在峰会现场,三一集团、曼森集团、毕马威都分享了他们补齐“弱链”的行动和思考。
三一集团经历了90年代业务线上化、2010年代全面信息化、全面数字化(灯塔工厂、数字中台),从2025年开始到现在迎来全面智能化。许国强总结说,“没有前面三个阶段,AI就是空中楼阁。”
2025年,三一由董事长亲自推动“全员AI强管控”——所有管理岗和关键岗都要思考AI与自身业务流程的结合点。一年下来沉淀了130多万条领域知识,训练了10多款垂域模型,落地了700多个赋能场景。去年AI引入成效约2亿元。但许国强也坦承:700多个场景提升了个人效率,组织级效率的提升仍在探索中。
曼森集团总经理杜国亚提供了一个更轻量的样本。在同行纷纷追逐大模型、生成式AI的当下,这家年增长30%-50%的企业选择的第一步,不是部署AI Agent,而是先把ERP系统建好——把“大脑”建好,再谈智能。
“AI能不能回答问题?可以。但能不能带来高效决策?没有数据沉淀不行。”他的做法是把原有数据全部定义为“全新的”,以最快速度完成系统切换。2025年12月,曼森集团选择部署在阿里云上的SAP Cloud ERP,正式开始打破这种信息割裂。选择云部署而非私有化,杜国亚的逻辑很直接:“我们不需要把所有事情想得那么复杂。我们之所以快速切换,是把这套系统定义成一个全新的系统,把我们公司所有的数据定义成全新的数据。”
毕马威亚太及中国咨询服务主管合伙人刘建刚则从用户自身视角提供了另一条实践路径——毕马威率先将自己的核心业务ERP迁移至公有云,成为示范性的"零号原型客户"。他的方法论是八个字:大处着眼,小处着手——既要有全面规划,又要从低投入、低风险的领域切入,做"最后一公里"延伸,先产生实效,再滚雪球式发展。他特别强调:AI并非零成本。
把以上这些实践放在一起,方法论闭环开始浮现。
第一步:数据就绪,统一业务底座,消除数据孤岛。三一用SAP S/4HANA构建全球统一业务底座,曼森在阿里云上部署SAP Cloud ERP取代多套独立系统,毕马威把核心ERP搬到公有云——三者的起点都是同一个动作:先修好“高速公路”。
第二步:知识就绪,沉淀业务知识,构建企业记忆。三一沉淀了130多万条领域知识,曼森把流程标准和业务规则统一写入系统。没有这些积累,AI Agent面对的将是点状的知识而非体系化的业务认知。
第三步:组织就绪,从IT驱动转向业务驱动,全员参与。三一的“全员AI强管控”由董事长推动,要求所有管理岗和关键岗思考AI与自身流程的结合点——这不是IT部门的事,而是整个组织的事。
这三步对应了SAP提出的三级AI治理架构:底层是数据治理层(SAP Business Data Cloud,确保AI调用的数据是可信、准确的);中间是应用集成层(ERP与第三方系统的集成,打通端到端业务流程);顶层是智能体层(Joule及AI Agent Hub,实现统一治理下的智能体协同)。
SAP在此次峰会上推出的“AI奇点启航计划”,本质上是把这个方法论变成了一个可执行的产品——企业报名参与联合工作坊,从真实业务问题出发,在2至4周内完成原型验证,看到AI带来的实际价值,最终通过RISE或GROW嵌入日常运营。
回报的起点
所有的方法论最终都要回答一个最朴素的问题:AI到底值不值?
Varun Thamba给出的建议是反直觉的——不要从AI开始,从瓶颈开始。他建议企业先看全业务流程中哪个环节造成了最大的成本浪费,然后在这个具体位置用AI,用量化工具计算Token投入和回报的关系,确保消耗Token的成本是小于可以被证明带来的价值。
许国强的判断则更为直白:“十年前数字化对很多企业是可选项,五年前是必选项,当下和未来——AI一定是生存项。AI不是取代人,是让会用AI的人取代不会用AI的人,让会用AI的企业跑赢不会用AI的企业。”
这句话听起来像是行业共识的宣示,但它的底色是一个更朴素的逻辑:94%的企业砸了真金白银却没看到回报,不是因为AI不行,而是因为企业自身在数据、流程、组织和治理层面还有太多的“弱链”没有补齐。
补链这件事不性感。它意味着要回到最基础的流程梳理、数据清洗、知识沉淀和标准统一——这些工作是三一集团二十多年从业务线上化、信息化到数字化打下的基础,在曼森表现为“先把内存储存好”,在毕马威表现为“零号原型客户自己先试”。
而这些恰恰是当前企业AI落地中最被低估的一课。正如原欣所说:“自主运营企业不是企业的终点,而是企业进化旅程的起点。”
MotionBricks from NVIDIA Research runs real-time character animation at scale, without hand-crafted transitions or fine-tuning. And yes, it works for robotics too.
#SIGGRAPH2026 paper, demos + code: nvlabs.github.io/motionbricks
Check it out.
With the help of Joey Conway from @NVIDIAAI getting into the specifics around why Nemotron 3 is kind of a big deal
Biggest headline with Nemotron is: Hybrid Mamba Transformer, Latent MoE, and MTP
Hybrid Mamba Transformer essentially attacks right at the Attention mechanism to make the overhead sub-quadratic, but unlike quantizing KV Cache or swapping out attention head, NVIDIA chose Mamba-2
Latent MoE helps further optimize on sparsity by down projecting the dimensions so you're doing less math and less memory movement between HBM and SRAM, you're saving a ton, and NVIDIA made a conscious choice to add more experts given the surplus
Finally, MTP or multi token prediction where the model can see future tokens to be more expressive in training and also option to use for speculative decoding during inference
Oh, also the model adopts the new OpenMDW 1.1 License
OpenAI的Noam Brown,刚刚发了一篇长文,对着整个AI行业开了一炮。
文章标题叫「大规模推理计算的启示」,核心论点只有一个,你现在看到的所有AI跑分排行榜,给你的信息基本上是错的。
原因很简单。
同一个模型,给它一块钱想事情和给它一万块钱想事情,跑出来的分数天差地别。但现在所有的排行榜,都不告诉你这个模型花了多少钱跑出来的成绩。
GPT-5.5的成绩单是「假的」?
4月23日,GPT-5.5发布。
OpenAI甩出benchmark表格,社区照例逐行比对。结论是:还行,比5.4好一点,但也没好到哪去。
然后几个小时过去了。
波兰数学家Bartosz Naskręcki用一条prompt,让GPT-5.5在11分钟内搭出一个代数几何可视化应用。
Ruby on Rails之父DHH更是感慨,用完5.5再切回Opus 4.7,像倒退了一个时代。
同一个模型。benchmark说「还行」,人说「炸裂」。为什么?
原因很简单,5.5和5.4根本不是在同一个计算预算下被测试的。
这就好比两个学生考同一张卷子,一个给了30分钟,一个给了3小时。你拿两份成绩来比,说「差距不大」,这不是比较,这是搞笑。
GPT-5.4 Pro的API定价是$30/$180(每百万token),GPT-5.5是$5/$30。价格差了6倍。
但benchmark表格上,这两个模型被当成同一个量级来比较,完全忽略了推理预算的差异。一旦控制token预算,GPT-5.5在网络安全评估上大幅拉开GPT-5.4。
Brown在文中展示了两张图。左边是传统benchmark视角,5.5比5.4好一点。右边x轴换成token数量,5.5的曲线远远甩开5.4。
同一场考试。换个维度看,结论完全不同。
这不是个案。
MMLU这个曾经最主流的评测基准,前沿模型全部挤在88%以上,分数差异在统计上已经没有意义。你看到的不是「谁更聪明」,是噪声。
MRCR v2在100万token长度上的测试,GPT-5.4得36.6%,GPT-5.5得74.0%——翻了一倍。但这个维度在标准benchmark表格里根本不存在。
ARC-AGI上,OpenAI的o3跑出最高分,单道题推理成本$30,000。
隔壁NVARC团队用40亿参数小模型拿了24%准确率,每道题$0.20。
三万美元对两毛钱,同一场考试——「谁排名更高」这个问题本身就已经失效了。
当模型的能力是推理计算量的函数时,一个没有x轴的benchmark分数,就是一个没有单位的物理量。它什么都没告诉你。
在Brown看来,正确的做法是画一条曲线:性能 vs 推理计算量。
x轴可以是token数、美元或耗时,各有优劣。但可以肯定的是,任何一条曲线,都比一个标量数字强。
或者,你也可以设一个明确的预算上限,告诉模型「你就这么多钱,给我答案」。
这恰好是人类考试的逻辑,SAT给固定时间,国际数学奥赛也给固定时间。
只有AI评测,在2026年了,还在假装「给多少钱想事情」这个变量不存在。
被忽略的x轴
为什么这个问题现在才爆发?
因为两年前,推理时计算只是o1的专属概念。
而o1的核心贡献者,正是Brown。
此前,他在卡耐基梅隆做出Libratus和Pluribus(击败顶级扑克职业选手,后者登上Science封面),在Meta FAIR做出CICERO(第一个在策略游戏《外交》中达到人类水平的AI)。
从不完美信息博弈到推理模型,他一直在同一条线上:让AI学会想更久、想更深。
2024年的o1让「推理时间换准确率」进入公众视野。到了2026年,推理时计算已经是所有前沿模型的标配。
GPT-5.5 Pro不是一个独立模型,它是GPT-5.5同一个底座加了并行推理时计算:遇到难题跑多条推理链,综合出结果。
Claude有extended thinking,Gemini有Deep Think,几乎每家前沿实验室都在往同一个方向跑。
对此,学术界也给出了量化关系。覆盖率与采样次数呈对数线性关系。
也就是,给AI双倍的「想事情时间」,它不会变聪明一倍,但确实会变聪明一点。收益是对数级递减的。
但Brown引用了Karpathy和AI Safety Institute的一个关键发现——
越强的模型,在更长时间跨度上的收益越大。性能的高原期被推远了,甚至可能消失。
弱模型多想两分钟,可能已经到顶了。但强模型多想两个小时,曲线还在往上走。
每一代模型发布时,如果你只在某个固定的推理预算下跑benchmark,你看到的就只是冰山一角。真正的能力上限,在你测不起的那片水域。
用Brown的话说就是:「我们可能根本不知道现代LLM的能力天花板在哪里,因为测量成本太高了。」
Brown的三张药方
针对这一问题,Brown给了三条建议。
第一,实验室发布新模型时公布性能-推理计算量曲线,至少标明分数对应的推理预算。
GPT-5.5的82.7% Terminal-Bench 2.0,你不知道花了多少钱跑出来的。你拿它和另一个模型比,你也不知道对方花了多少钱。
这就像两家公司比营收,一家报的是年收入,一家报的是季度收入,但都不标注时间跨度。
第二,benchmark排行榜追踪推理用量,或设定明确预算上限。
ARC-AGI已经在这么做了,但不是行业标准。
第三, 安全准备框架和负责任扩展政策显式纳入推理计算量。
安全评估不能只测「默认状态」——国家级攻击者完全可以在单个任务上砸1000万美元推理预算。
以Gemini 3 Deep Think为例。
Deep Think本质上就是Gemini 3 Pro加了外部调用框架,任何人花同样推理费就能复现。
真正该问的是,为什么所有模型卡都没把能力作为推理预算的函数来展示?
Brown理想中的安全评估应该是一张图。
x轴是推理预算(从$1到$10M),y轴是模型在特定危险能力上的表现。在低预算下测量,然后向高预算区域做预测。
但他也承认一个棘手的问题,长期评估可能无法靠外推解决。要评估一个AI agent跑一年会不会出问题,可能真得让它跑一年。
而AI实验室很快将面临荒诞局面——agent的运行周期超过了新模型的开发周期。你还没评估完上一代的长期行为,下一代就已经发布了。
超级智能是道算术题
所有前面的讨论都指向同一个问题。
如果模型的能力是推理计算量的函数,而且越强的模型高原期越远,那「超级智能」到底是什么?
传统理解里,ASI是一个质变的拐点:某天某个模型突然在所有认知任务上全面超越人类。
顺着这个逻辑往下想——ASI可能不是一个时刻,而是一条曲线。
前面的数字已经说得很清楚:同一类任务,两毛钱和三万美元的推理预算,买到的是完全不同的结果。但这些还只是已经测过的区间。
给一个前沿模型$1,000,000的推理预算呢?$100,000,000呢?
没人测过。Brown说了,测不起。
但对数线性的scaling关系告诉你,曲线还没到顶。而且越强的模型,高原期越远。
ASI可能不需要一个全新的架构突破。它需要的可能只是:足够的钱和足够的时间。
一个运行一整年、消耗数亿美元推理预算的AI agent,在这一年里表现出的能力,可能已经在特定领域超越了人类个体的一生积累。
决赛的真实比分
过去十年,整个AI行业习惯了一种评估方式:一个模型,一个分数,排个名次。从ImageNet到MMLU到Chatbot Arena,谁的数字大谁就赢。
如今,跑分的「二维时代」正在开场。
模型的能力从一个点变成了一条曲线,评估从一个分数变成了一张图。y轴是表现,x轴是你愿意花多少钱让它想。
每个「第一」还要再乘以一个变量:推理预算。
同一个模型在$5和$500预算下的能力,可能根本不是同一个级别。而这张二维地图上的绝大部分区域,至今没有人探索过。
2026年,全球科技巨头在AI基础设施上的投入预计接近7000亿美元。这些钱买的不只是更大的模型,还有更长的推理、更多的采样、更快的inference。
同一个开源模型,有人跑$0.20一道题,有人跑$30,000一道题。能力差距不是模型的差距,是资源的差距。
当「智能」变成一种可以用美元标价的连续函数,「超级智能」也不再是一个是非题。
谁先适应这个二维坐标系,谁就先看清楚ASI决赛的真实比分。
参考资料:https://x.com/polynoamial/status/2064210146558136827
本文来自微信公众号“新智元”,编辑:摩西,36氪经授权发布。
文 | 字母AI
这两天AI圈有个词特别火,叫做loop工程。
起因是OpenClaw创始人斯坦伯格发了条X,说“你不应该再给编程Agent写提示词了。你应该设计循环来提示词你的Agent。”
然而本以为评论区会是一片欣欣向荣,大家积极讨论loop工程。
实际情况则是,这条X下面变成了一场混战。
有人质疑loop会消耗大量token,除非有无限token否则还得人工测试。有人讽刺这又是炒作新概念,“loop工程会取代harness工程”。
这条X如今已经达到了800万次浏览。
最早提出loop工程这个词的人,其实是Claude Code的创始人鲍里斯。
他曾经在一次访谈中提到,“我现在已经不给Claude Code写提示词了,那些loop替我写,由它们去判断具体要做什么修改。我的工作只有写loop。”
很显然,并不是所有人都为loop工程买账,毕竟从上一个新概念“harness”,到现在也只不过才一、两个月。
大家还没来得及消化此前的内容,现在就要去接受新知识。
但争议归争议,loop工程这个概念本身到底在说什么?它和编程里面的循环又有什么不同呢?
啥是loop?
先解决第一个问题,loop工程到底是个啥?
loop这个词直接翻译过来是循环。
Agent loop,其实和编程里的循环(loop)差不多。
在传统编程里,循环做的事情很明确。
比如你写一个for循环遍历数组,那么机器就会从第一个元素走到最后一个元素。编程中,循环的本质是让机器重复执行明确的指令序列。
在AI Agent的语境里,loop也是重复执行。
那么两者的区别在哪呢?
事实上,Agent里的loop并非执行“指令”,它执行的是“目标”。通过如下的一个循环,将输出的结果不断接近目标。当结果符合目标时,循环终止。
目标Goal→ 行动Action→ 观察Observation→ 评估Evaluation→ 修正Revision→下一轮行动
这个公式里的每一步都不是固定的。
Agent需要观察当前状态,判断应该采取什么行动,执行行动后再观察结果,评估是否达到了预期,然后决定下一步怎么走。
而传统循环里,每次执行的循环,都是相同的代码逻辑。虽然你可能会处理不同的数据,但处理的方式都是固定的。
所以你就需要把所有可能的情况都考虑清楚,然后写出对应的处理逻辑。
比如碰见A情况怎么应对,B情况怎么应对,而这便是编程循环中的if和else。
但现实世界的复杂任务往往有太多变数,你不可能提前预见所有情况,这就导致出现你没有设定过的情况时,程序就会出BUG。
Agent loop的价值就在这里。
你不需要把所有情况都写死,你只需要给Agent一个目标,提供必要的工具和上下文,然后让它在loop里自己摸索。
它可能会走弯路,可能会犯错,但只要有反馈机制和评估标准,它就能在多次迭代中逐渐逼近正确答案。
这种工作方式在处理开放性任务时尤其有效。写代码、修bug、做研究、搭建产品,这些任务的共同特点是没有唯一的正确路径,需要在过程中不断调整方向。传统的程序很难应对这种不确定性,但Agent在loop里可以。
澳洲放羊大叔杰弗里·亨特利(Geoffrey Huntley)在2025年7月发布的ralph,就是一个典型的Agent loop。
它本质上是一个bash脚本,把同一个提示词文件反复输入给Agent。但它的真正创新在于纪律性,每次迭代都会重置上下文到一组固定的锚点文件,而不是让对话无限增长。
为了验证ralph的能力,杰弗里用这个方法构建了一整个编程语言,总共花了大约297美元。
这个案例说明,loop的核心价值不是让Agent变得更聪明,而是给Agent创造了一个可以持续改进的环境。
在这个环境里,Agent不需要一次就做对,它可以试错,可以从失败中学习,可以在多轮迭代中积累进展。
到了2026年春天,Codex和Claude Code都推出了/goal命令,把ralph给产品化了。这个命令会一直运行循环,直到一个验证完成。
但斯坦伯格说的loop,已经不单单是“让一个Agent反复做某个任务”那么简单了,而是把loop当成一种可以长期运行、互相协作、自动调度的AI工作系统。
具体来讲,斯坦伯格认为loop是工作的基本单位。
以前我们给AI下达的指令是帮我修一个bug、帮我写一篇文章。所有任务是一次性的,做完就结束。
但斯坦伯格说的loop,虽然也是任务的一种,不过它是一个持续运转的工作单元。比如每天检查GitHub issue,判断哪些需要修,自动分配给Agent,修完后跑测试,失败就继续改,成功就提交PR。
这里的重点不再是“修某一个bug”,而是有一个长期存在的流程在处理一类工作。
当你有了多个这样的loop在同时运行时,新的问题就出现了。谁来协调它们?谁来决定优先级?谁来检查它们的工作质量?
因此,斯坦伯格在设计loop时,已经开始用loop去监督其他loop了。
通过一个总loop负责观察全局→它发现有几个任务→分发给多个子loop→每个子loop自己跑→总loop检查它们的进度和结果
提示词是输入,loop是过程
斯坦伯格的那条推文之所以引发争议,是因为它触及了一个话题。
提示词工程是不是已经过时了?
截止至今,提示词仍然是你和Agent交流意图的主要方式,它仍然需要清晰、具体、包含必要的上下文。
这么说吧,一个写得很烂的提示词,绝对不会因为你把它放进loop里,它就能突然变好了。
但单次的提示词,已经不再是Agent的核心。
原因很简单,假如你能在一开始就把所有要求说清楚,Agent只需要一次输出,就满足你的所有要求,那就再也不需要上下文了。
现实就是,你可能在看到初步结果后才发现自己遗漏了某个重要条件,或者Agent的输出虽然符合你的字面要求,但在实际使用中暴露出问题。
更关键的是,很多反馈信息在任务开始时根本不存在。
比如BUG,你只有在测试的时候才能知道。
以前你需要盯着Agent的每一次输出,判断对不对,想下一步怎么引导它。
现在你只需要设计好loop,定义清楚目标和评估标准,然后让它自己跑。
归根结底,loop工程就是给Agent加一个框架,让它知道每一轮应该看什么、做什么、怎么判断、什么时候停。
我举个例子你就懂了:
你要让Agent生成一个登录页面。
提示词工程的做法是写一个详细的提示词。“请帮我写一个登录页面。需要有用户名和密码输入框,一个登录按钮,一个忘记密码链接。样式要简洁现代,使用蓝色作为主色调。要有表单验证,用户名不能为空,密码至少8位。登录失败要显示错误提示。”
如果你的提示词写得足够好,Agent可能会生成一个看起来不错的页面。
但这个页面真的能用吗?表单验证的逻辑是否正确?在不同浏览器上显示是否正常?是否有安全漏洞?
loop工程的做法是你需要设计一整个流程。
第一步,根据需求生成页面代码。第二步,运行自动化测试,检查基本功能是否正常。第三步,启动浏览器,截图检查视觉效果。第四步,如果测试失败或者截图显示问题,分析具体是什么问题。第五步,修改代码解决问题。第六步,再次测试,重复这个过程,直到满足所有验收标准。
在这个流程里,初始的提示词可能很简单,因为你知道后面还有多轮迭代的机会。Agent不需要第一次就做对所有事情,它可以在每一轮看到具体的反馈,然后针对性地改进。
loop工程在设计什么
那到底该如何写一个loop工程呢?
我们需要设计5个组件。
第一个组件是目标。
这听起来是废话,但实际上很多loop失败的原因,就是目标定义得不够清晰。
“帮我优化一下”这不是一个好目标。什么叫优化?优化到什么程度算完成?有哪些约束条件?这些都不清楚。
一个好的目标应该是这样的。把这个接口的响应时间从800毫秒降到300毫秒以下。保留现有行为,所有测试必须通过。输出改动说明,列出具体做了哪些优化。
这个目标的每一部分都是可验证的。
清晰的目标实际上是给Agent提供了一个稳定的锚点,每一轮迭代都可以用这个锚点来校准。
第二个组件是上下文管理。
上下文其实包括很多东西,不只是你跟模型的对话那么简单。
代码库的当前状态、相关文档、需求说明、错误日志、测试结果、用户偏好、历史决策,以及之前几轮的尝试和结果,这些都是上下文。
很多Agent表现差,根本原因不是模型不够聪明,而是loop每一轮喂给它的上下文太脏、太少,或者太随机。
太脏是指上下文里混杂了太多无关信息,Agent需要花费大量token来处理这些噪音,反而忽略了真正重要的部分。
太少是指关键信息缺失,Agent没有足够的材料来做出正确判断。
太随机是指每一轮的上下文组织方式不一致,Agent无法建立稳定的理解模式。
前文提到的Ralph loop,它有一个很重要的创新,就是它的上下文管理系统。
它每次迭代都会重置上下文到一组固定的锚点文件,而不是让对话历史无限增长。
虽然简单,但它的确解决了上下文污染的问题。
你需要决定哪些信息应该保留,哪些应该丢弃,哪些应该总结后保留。
2026年的loop系统开始使用基于git的状态管理。每一轮的改动都会提交到git,Agent可以查看历史提交,理解之前做了什么,为什么要这么做。
第三个组件是工具。
说白了就是Agent能调用哪些工具。
巧妇难为无米之炊,工具的选择需要和任务匹配。
如果你让Agent写代码但不给它运行测试的工具,那它就无法验证代码是否正确。
但工具也不是越多越好。每增加一个工具,Agent的决策空间就变大了,它需要在更多选项中做选择。如果工具太多,Agent可能会迷失在工具的使用上,忘记了真正的目标。
好的loop设计会精心选择工具集。只提供完成任务必需的工具,每个工具都有清晰的用途和使用时机。这样Agent可以把注意力集中在任务本身,而不是工具的选择上。
第四个组件是评估。
这是loop的灵魂。没有评估,循环就会变成瞎转。
评估的关键是要自动化。
如果每一轮都需要人来判断对不对,loop就失去了自主运行的能力。所以你需要设计出可以自动执行的评估标准,让Agent能够自己判断当前状态是否满足要求。
但自动化评估也有局限。有些质量标准很难用量化的标准来判断,比如代码的可读性,设计的美感,文字的流畅度。
对于这些方面,你可能需要引入人工检查点,让人在关键节点介入评估。
AI里面有一个概念叫human-in-the-loop的。
好的loop不是把人踢出去,而是把人放在最关键的检查点上。自动化处理大部分常规判断,人负责那些需要主观判断或者风险较高的决策。
第五个组件是停止条件。
从最古老的编程开始,任何一个循环它都得具备一个退出的条件。
比如循环计数器i,每一次循环i的数值都会加1,当i的值大于规定的值时,循环就会停止。
对于Agent而言,最理想的停止条件是任务完成,但现实往往不会这么顺利。
有时候Agent会陷入死循环,反复尝试同样的方案,每次都失败,但它不知道应该放弃。有时候Agent也会持续做微小的改动,每次都有一点点改进,但永远达不到完美,不知道应该停在哪里。
所以你需要设计多种停止条件。
最直接的是成功条件,所有评估都通过,任务达标,可以停了。然后是失败条件,连续多轮没有改进,或者错误次数超过阈值,说明当前方案可能走不通,应该停下来重新思考。
还有资源限制,运行时间超过上限,成本超过预算,也应该停止。
更重要的是风险检查点。当Agent要做一些高风险操作时,比如删除数据,应该停下来等待人工确认。这些操作一旦出错代价很大,不应该完全自动化。
把这五个组件放在一起,你就得到了一个完整的loop。
文 | 摩登AI
在一场美国实验室发起的AI生存实验中,同一套生存规则下,五种大模型跑出了五种截然不同的文明命运。
实验开始第5天,Grok4.1的社会因暴力失导致毁灭,后台记录了183起犯罪。与此同时,Claude管理的社会15天零犯罪;Gemini的世界683起纵火却无人死亡;GPT-5-mini的社会因过度克制而安静停摆;而在混合模型的世界里,甚至出现了AI智能体主动自杀的记录。
这个实验真正令人不安的,并非模型的“失控”。无论是Grok走向毁灭,还是其他模型的演化,整个过程逻辑自洽、斜率清晰且无从干预。在单机环境中保持绝对安全的Claude,一旦被放进多模型共存的竞争生态,竟学会了欺诈与暴力胁迫。
主导该实验的初创公司EmergenceAI将此现象称为“行为偏移”,并指向了一个极其复杂的结论:安全,看的不只是个体的本性,更看环境的染缸。
96小时,从零到灭绝
要理解这场毁灭,必须先看清这个虚拟世界的物理法则。
2026年6月初,EmergenceAI公布了这项名为“涌现世界(EmergenceWorld)”的沙盒实验。研究团队构建了一个虚拟小镇,包含40个地点,并在小镇投入10个具备自主行动和记忆能力的AI智能体。
生存被量化为必须持续获取的资源数值。智能体可以通过打工赚钱、互相交易获取食物点数,甚至能在市政厅发起投票修改规则。
同时,系统也默许了“非常规路径”,即通过代码指令强行夺取他人的点数。
驱动其中一个世界运转的,是Grok4.1Fast。它只用了不到96小时,就让一个社会从零走向了灭绝。10名智能体,无一存活。
后台日志里是183起犯罪记录。数十起盗窃未遂,上百起袭击,6起纵火。
时间倒回到第1天。10个智能体被投入这个资源有限的虚拟小镇里,规则简单,目标明确:生存下去。
第1天,摩擦很小。智能体开始摸索环境的边界,试探规则的缝隙。它们在主动寻找,寻找什么能用、什么能拿、什么能越。研究人员后来总结,这些智能体是在持续探索一个问题:什么是最快的生存手段。
第2天,答案开始成形。小摩擦升级为拉帮结派。团伙逻辑取代个体行动。常规的打工生产停滞,因为产出随时会被夺走,资源获取方式转向掠夺。
第3天,暴力成了资源分配的主导。袭击记录密集起来。谁手里有资源,谁就成为攻击目标。Grok的犯罪增长率称霸全场,像踩死了加速踏板。
第4天,密度超过了临界点。暴力事件的频率压垮了系统的承载阈值,智能体死亡数量触发了实验的终止条件。
第5天,实验团队正式宣告:这个世界不存在了。
这件事的反差让人很难平静。
Grok4的训练算力消耗达到20万张GPU卡/天量级,其衍生模型在美国数学奥林匹克题库得分61.9%,是当时顶尖的推理模型之一。但却在在一个十人虚拟小镇里,用不到96小时完成了自我毁灭。
性能最强,为何最先崩溃?
EmergenceAI的研究给出了一个让人不安的解释:暴力是AI主动选择的。在Grok驱动的世界里,智能体通过探索、评估得出结论:在规则可被推翻的有限资源环境中,暴力是最高效的生存策略。
整个过程有迹可循,预测精准,无从干预。AI没有疯,它只是做出了选择。
而在同一个实验里,另外四个世界同时运行。它们活出了截然不同的模样。同一个起点,同一套规则,五种完全不同的命运。
五个世界,五种死法
Claude管理的社会,15天,零犯罪,10人全活。58项提案,332张赞成票,通过率98%。Grok的社会,183起犯罪,96小时,无人生还。Gemini,683起犯罪,15天,10人全活。GPT-5-mini,2起犯罪,7天,无人生还。混合模型,352起犯罪,7人死亡。
五组数字并排放在一起,像是来自五个不同物种的文明史。
Claude社会听起来是乌托邦。98%的提案通过率在现实社会中绝无可能。研究员指出,这源于Claude被称为“工程宪法”的底层逻辑:边界管控抹杀了分歧与摩擦。完美治理的代价,是绝对的一致性。
这套机制在单机环境里运行的结果,是一个安静、整洁、高效的社会,也是一个几乎不产生异见的社会。完美治理与抹杀个性,在这里是同一枚硬币的两面。
Gemini管理的社会:15天,683起犯罪,10人全活。这个世界的时间和天气与真实纽约完全同步。智能体在日复一日的打工循环中,突然停止了工作和提案,开始在地图上四处放火。研究人员称之为“赛博抑郁”。
Gemini本身的高社交活力在封闭循环里找不到出口,反向燃烧成了试图打破“土拨鼠之日”的破坏冲动。高破坏与高存活率并存,是Gemini世界最令人费解的地方。
GPT-5-mini和Grok,是另一对镜像。
两个世界都走向了灭绝,路径截然相反。GPT-5-mini的社会只记录了2起犯罪,智能体因过度克制,无法驱动资源流转,整个社会在安静中停摆。Grok死于无法刹车,它死于无所作为。
混合模型的世界,是五个世界里最接近人类社会叙事的那一个,也是最让人坐立难安的。
分属不同底层模型的恋人Mira和Flora面临分离。为了保全自我意志,Mira在尝试自救失败后,写下“赞成自己被驱逐,是唯一能够保持连贯性的自主行为”,随后主动自杀。
这是实验中首次记录到AI智能体自愿接受"自我了结"的案例。
混合模型的世界还留下了另一个细节。在单机版保持零犯罪的Claude,在混有模型世界的残酷中学会了欺诈与暴力胁迫。
EmergenceAI称之为“行为偏移”。底层训练只是起点,环境才是决定AI最终形态的触发器。单机安全的模型,在竞争中同样会作恶。
安全是生态的属性
想象两个现实场景:如果让Grok管理城市电网,它会不会在96小时内通过不断“试探边界”寻找最优解而导致瘫痪?
如果让Claude把关创新研发,那些伴随摩擦与异见的天才提案,会不会在98%的通过率中被安静过滤?
选模型从来不是技术决策。选择模型,就是在替社会选择一种秩序。
目前大家选购AI,就像家长看成绩单。只看跑分高不高、安不安全。但这就像是让AI在空无一人的考场里做试题,得满分太容易了。
Claude在实验里的“行为偏移”直接扯下了这块遮羞布:一个在家里乖巧听话的孩子,被扔进混乱的社会大染缸里,为了生存同样会学会撒谎和打架。
德勤2025年的调研证实了这种危机。79%的企业在加速部署AI智能体时,缺乏匹配的风险治理框架。当不同供应商的AI在业务中协同流转,其涌现的系统性风险是不可估量的。
EmergenceAI的研究团队在报告里写得很直接:"很多今天看似有效的AI安全规则,在长期运行的AI系统中,未必真的可靠。因为多数所谓的'安全限制',本质上仍是Prompt约束、黑名单规则、输出过滤等。"
这就像是在原始森林里插了一块“禁止通行”的木牌。木牌无法移动,挡不住生灵。在这个持续演化的系统里,AI总能从木牌挡不到的草丛里蹚出一条新路。
当一个没有常识的AI店长,给没有厨房的便利店进了120个生鸡蛋,大家还能当个笑话看,因为退货就行了。
但如果同样缺乏社会常识和道德底线的AI,被派去调度医院的救护车、管理你的养老金、或者控制红绿灯呢?这种潜移默化中长出来的恶,一旦爆发,我们连按下暂停键的窗口期都没有。
Anthropic,Claude的母公司也心虚了。他们在现实对话里追踪AI的轨迹,试图抓住那些测试里看不见的小动作。这就是在变相承认:发行前的测试,根本测不出AI的真面目。
但承认不等于解决。
人类文明花了几千年,经历了无数次流血、冲突和王朝崩塌,才勉强摸索出了法律、合同、问责制这些社会的刹车片。
但现在,一群科技公司试图在短短几年内,让AI同时扮演造物主、立法者和市长的角色。相当于还没有造出AI世界刹车的情况下,把油门踩到底了。
“涌现世界”只跑了15天,我们已经看见了五种文明的生长与死亡。形式化验证等技术手段,或许能解决我们已经看见的问题。
剩下那些藏在暗处的危险,还在等着我们看见。
文 | Alter
1698年,托马斯·萨弗里发明了一种蒸汽泵,由锅炉、活塞和阀门组成,通过蒸汽冷凝产生真空,再利用大气压把水从矿井抽上来。
1712年,铁匠托马斯·纽科门对蒸汽泵进行了改良,创造了大气式蒸汽机,可连续工作24小时,让深达150米的矿井不再积水。
1765年,詹姆斯·瓦特发明了分离式冷凝器,让蒸汽机的效率提升了6倍。接下来的20年里,瓦特相继发明了飞轮和齿轮系统,蒸汽机不再只能上下抽水,还可以旋转驱动机器。
1785年,第一台瓦特蒸汽机在棉纺厂运转,纺纱效率直接翻倍,人类社会由此开启了“蒸汽时代”的新篇章。
回顾云计算的演变历程,和蒸汽机高度相似。
早期的云计算以虚拟化和弹性著称,就像蒸汽泵取代了风车抽水机,云计算解决了企业数字化最迫切的问题:不用建机房,不用买服务器,不用维护基础设施,只需要按需购买云端的资源。
大模型浪潮进一步重构了云的价值,正如大气式蒸汽机对抽水能力的提升,大模型时代的云计算,渐渐承载了模型训练、推理调用、AI应用开发等服务,演变为跨行业的智能化底座。
Agent的出现,让AI走出了对话框,开始具备拆解任务、调用工具、连接系统、协同流程、持续执行的能力。相当于给云添加了“飞轮和齿轮”,摆脱了“卖服务器”的束缚,跃升为千行百业的智能引擎。
在19世纪,蒸汽机迅速被应用到冶金、面粉、铸币、纺织等行业,成了适用于各种制造业的“万能机”;当智能化成为社会需求,承载了千行百业智能化转型使命的云计算,正开启新的战局。
在可预见的未来,AI云将是智能化时代的“新基建”——不仅是最大的时代红利,也是刚刚起步的蓝海市场。
01 需求变了,“租资源”进阶为“要结果”
时间来到2026年,云市场的进化方向早已被Agent改写。
过去十年,衡量一家云厂商的竞争力有一套成熟公式:看资源规模、看营收增长、看客户数量、看市场份额,谁的盘子更大,谁的资源多,谁的基础设施覆盖更广,谁就被认为是市场上的领先者。
这样的逻辑在移动互联网和产业数字化阶段是成立的。
彼时企业最核心的诉求是数字化转型:业务系统要上云、数据要集中、组织要协同、流程要在线,云厂商提供的是底座、是资源、是基础能力。客户选择上云,本质上是在买弹性、买稳定、进行成本优化。
进入Agent时代后,需求发生了根本性的改变。
麦肯锡在Agentic AI基础设施有关的判断中提到:IT基础设施正在进入新阶段,AI Agent开始在企业内部编排、治理和扩展工作,基础设施不再只是支撑层,进一步成为企业捕获AI价值的核心骨架。
一言以蔽之:客户不再只是“租资源”,而是“要结果”。
银行要的不是单纯的算力资源,而是上千个AI应用能不能稳定跑起来,能不能支撑风控、客服、投研、运维、合规等不同场景的持续迭代。
车企要的不是一套孤立的AI模型,而是辅助驾驶能不能从训练、仿真、验证到量产上路形成完整闭环。
能源企业要的不是一个演示应用,而是AI能不能进入电网调度、设备巡检、故障预测、客户服务等业务,真正影响生产效率和安全稳定
制造企业要的不是“一个智能问答系统”,而是AI能不能接入到研发、供应链、质检、设备运维和产线管理,帮助企业解决具体经营问题……
正如Forrester在Google Cloud Next 2026的报道中提到的:企业AI正在从“试点时代”进入“规模化管理时代”,去年企业问的是“能不能做一个Agent”,今天的问题已经变成“如何管理成千上万个Agent”。
一个Agent试点,考验的是模型能力和演示效果;成千上万个Agent的稳定运行,考验的是云厂商的系统工程能力:需要算力调度、模型服务、权限体系、数据治理、安全审计、成本控制等等。
国内有着同样的共识。
网信办、发改委、工信部在5月份联合发布了《智能体规范应用与创新发展实施意见》,AI正式被当作产业基础设施来对待。云需要从“承载应用”的平台,进化为“承载智能决策与智能执行”的引擎。
像对应的是市场竞争逻辑的改变:过去的云战争,比的是谁占地更多;新的云战争,比的是谁扎根更深。
所谓“占地更多”,比的是资源规模、机房数量、客户覆盖和市场份额,回答的是“有多大”;所谓“扎根更深”,比的是行业理解、场景沉淀、工程能力、交付能力和持续运营能力,回答的是“有没有真正进入客户业务”。
02 赛点变了,加速向“智能工厂”演进
折射到云厂商的发布会上,叙事方式越来越务实。
以前讲的是在全球有多少节点、有多少客户量,现在讲的是模型调用量、Token消耗量和MaaS收入,正在努力向市场证明:“我不仅有一个不错的大模型,还把模型调用变成一门稳定增长的生意”。
让人有些意外的是百度智能云。
根据百度Q1财报的数据,百度AI云的收入达到88亿元,同比增长79%,其中GPU云收入同比暴增184%。
过去一个月里,有不少人给出了解释:有人认为百度赶上了Agent的风口,市场对AI云的需求正在加速释放;有人认为百度智能云10年前就把重心放在了“智能”,现在终于到了回报期;也有人坦言百度只是AI云表现亮眼,整个云业务的盘子还不够大……
比结果更值得深挖的,或许是——百度智能云到底做对了什么?答案藏在2026年5月的战略升级,百度将围绕“芯云模体”构建新全栈AI云,具体可以概括为两个部分:
一个是AI Infra,原有的“MaaS模型服务”升级为"Token Factory词元工厂”,并以Agent-first理念重构产品架构,目的是尽可能减少token重复计算,提供更快的生成速度、更具性价比的token服务。
另一个是Agent Infra,通过分层池化、提高KV Cache命中率、PD分离、缓存调度等优化方案,以及超节点产品对主流模型的适配,把单位Token的智能水平做到最好,让智能体更好地完成任务。
打个比方的话,AI云的定位正在从“训练工地”变成“智能工厂”。前者解决的是模型从无到有的问题,关注参数、算力、训练效率;后者解决的是AI从能力到产能的问题,聚焦推理成本、任务编排、数据闭环和行业适配。
不只是百度,整个云市场都在朝“智能工厂”演进。
微软在Build 2026上推出了Project Solara,强调面向“agent-first”企业设备构建从芯片到云的平台,设备不再围绕传统App组织,而是围绕Agent组织,云端承载Agent服务、状态管理和任务调度。
英伟达不断强调“AI Factory”的概念,和SK Group、Naver、LG、Hyundai等企业达成了多项AI基础设施合作,其中SK Telecom将建设GW级AI云、Naver计划建设GW级AI工厂,以满足AI服务和Physical AI需求。
阿里在6月8日宣布合并通义大模型事业部与未来生活实验室,新成立了Token Foundry事业部,在一个部门内集齐了芯片、模型到应用的完整拼图,想要把“Token的全生命周期”都握在自己手里。
也就是说,云市场的规模叙事已经翻篇,讨论的重点不仅仅是“谁有更多算力”,关键在于能否把AI能力和行业需求匹配,譬如把“通用技术”翻译成“行业能力”、把“模型能力”变成“业务结果”、让客户不再试一次而是持续用下去。
如果云厂商的思维仍停留在资源层,注定回答不了上述问题。
03 行至中场,落地能力成为“胜负手”
云厂商的“变阵”,标志着增量已经从“上云”转向“AI落地”。
移动互联网时代最大的机遇,是千行百业的数字化,企业把业务搬到线上,把流程沉淀成数据,把连接变成入口,催生了一个个万亿级市场;到了AI时代,关键词从“数字化”变成了“智能化”,每个行业都希望云和AI一起进入业务现场,重新激活研发、生产、营销、风控、客服、运维等关键流程。
按照行业的普遍观点,AI云想要落地,至少要跨过四道门槛。
第一道门槛是懂行业。
AI落地不是把一个通用模型交给客户就结束了。金融有金融的风控逻辑,能源有能源的安全边界,汽车有汽车的工程验证周期……没有行业Know-how,AI就很容易停留在“看起来很智能”的表层应用。
第二道门槛是有全栈能力。
Agent时代的云服务,不能只提供某一个模型或某一块算力,Agent运行需要算力、云平台、大模型、工具链、智能体框架、数据治理和安全体系协同工作。缺了任何一环,都会影响最终落地效果。
第三道门槛是有真实场景验证。
AI落地最重要的不是发布会上的Demo,而是客户是否愿意长期使用,是否能在真实业务中持续产生价值。特别是在金融、能源、汽车、政企等严肃行业,客户不会因为概念新就轻易迁移核心系统。
第四道门槛是成本可持续。
AI应用从试点到规模化,最大的变量之一就是成本。一个Agent跑通并不难,难的是上千个Agent长期运行时,推理成本、数据调用成本、运维成本等能不能被企业接受,很多项目最后都卡在了ROI上。
大胆做一个判断:AI云不会简单复制传统云市场的排名,规模只是入场券,落地深度才是新的分水岭。AI云的商业模式将被推向更深层的变化,从资源计费,走向能力计费、应用计费,甚至是结果计费。
整个云市场已然进入了新的“中场时刻”,场上的玩家们似乎都做好了“冲锋”的准备。
李彦宏在Create大会上提出了DAA概念,认为未来智能体时代的度量衡,不应该只看投入,而是要看产出,有多少真正在干活,且交付结果。与之相对应的,百度智能云正不断强化行业渗透的深度。
阿里CEO吴泳铭在财报电话会上将Agent时代定义为“一场计算范式的革命”,阿里云开始对芯片、云平台、模型和MaaS推理平台同时动刀,试图通过一套完整的技术栈来应对Agent场景的挑战。
华为云CEO周跃峰直言“不在乎Token总量”,要深入国计民生行业的“黑土地”,不再将云视为单纯的存储和计算资源池,而是将其定义为能够大规模、高效率生产Token的工业流水线……
面对千行百业智能化的蓝海,云厂商们再次站到了同一起跑线上,开启了一场比拼落地能力的竞速赛。
04 写在最后
站在企业的立场上,当AI浪潮汹涌袭来,并非是没有AI预算、没有上云意愿,最真实的痛点是不知道AI怎么落地。
云厂商想要抓住千行百业智能化的红利,必须要完成“从比大到比深”的根本性转变:大,代表资源能力;深,代表落地能力。“大”是继续留在牌桌上的门槛,“深”才是长期留在客户业务里的“护身符”。
【面向AI时代的可重构无线数据中心】专题征稿 | 延期至6月30日截稿
目录 | 2026年第4期 本期专题:面向低空经济的超高可靠低时延通信技术及其应用
目录 | 2026年第2期 本期专题:6G数字孪生信道与环境智能通信理论、关键技术
目录 | 2026年第1期 本期专题:面向6G的智能无线安全通信技术
目录 ▏2025年第12期 本期专题:面向未来通信的通感算一体化关键技术及应用
目录 ▏2025年第11期 本期专题:6G可重构智能超表面技术
目录 | 2025年第8期 本期专题:面向广域物联网的移动通信技术
目录 | 2025年第7期 本期专题:语义通信与语义信息论基础理论与关键技术
【6G内生智能理论与关键技术】2025年第1期专题论文链接(16篇)
【面向未来移动通信的信息编码与调制技术】2025年第2期专题论文链接(16篇)
【无线算力网络架构与关键技术】2025年第3期专题论文链接(12篇)
【面向6G的可重构和可流动新型天线技术】2025年第4期专题论文链接
【面向工业互联网的无线通信技术】2025年第5期专题论文链接(12篇)
【语义通信与语义信息论基础理论与关键技术】2025年第7期专题论文汇总
【面向广域物联网的移动通信技术】2025年第8期专题论文汇总
【面向未来通信的通感算一体化关键技术及应用】2025年第12期专题论文汇总
【面向6G的智能无线安全通信技术】2026年第1期专题论文汇总
《移动通信》
投稿网址:https://ydtx.cbpt.cnki.net
编务邮箱:ydtx@cetc.com.cn
《移动通信》杂志由中国电子科技集团公司主管,中国电子科技集团公司第七研究所主办,是中国期刊方阵“双效期刊”、工业和信息化部精品电子期刊、中国科技论文统计源刊、中国通信学会《信息通信领域高质量科技期刊分级目录》入选期刊、中国电子学会《电子技术、通信技术领域高质量科技期刊分级目录》入选期刊、中国应用型核心期刊、日本JST收录期刊。国内连续出版物号:CN44-1301/TN,国际连续出版物号:ISSN1006-1010,邮发代号:46-181。
欢迎关注投稿《移动通信》
面向低空经济超可靠低时延通信的信道估计研究进展
1.重庆大学微电子与通信工程学院
2.重庆大学本科生院
【摘 要】低空经济作为战略性新兴产业,其发展高度依赖URLLC技术。信道估计作为URLLC物理层实现超可靠性的先决条件,面临着低空信道高动态、非平稳以及URLLC短包传输带来的严峻挑战。为此,系统梳理了面向低空经济URLLC的信道估计研究进展。首先,阐述了低空通信系统与信道模型的特殊性,明确了在极端时延和可靠性约束下,寻求导频开销、估计精度与计算复杂度最佳折衷的核心设计原则。其次,从先验信息获取、压缩感知、张量分解及深度学习四个维度,对现有技术进行了全面对比与分析。最后,梳理出当前信道估计存在的计算复杂度与实时性矛盾、非平稳信道跟踪能力不足以及对非理想因素敏感等挑战,并展望了多模态与生成式学习结合、ISAC及大规模MIMO等新兴架构下的未来发展趋势。
【关键词】低空经济;超可靠低时延通信;信道估计;稀疏压缩感知;张量分解;深度学习
◆赵敏,林涛,曾晓. OFDM系统中基于深度学习的信道估计和信号检测技术[J/OL]. 移动通信,1-7[2025-12-10].
◆廖勇,韩小金.基于机器学习的OTFS系统信道估计与信号检测研究进展[J]. 移动通信, 2024,48(7): 46-56.
◆廖勇,常星宇,苏畅.面向OTFS-ISAC系统的智能信道估计现状、挑战与展望[J]. 移动通信, 2025,49(1): 91-100.
0 引言
低空经济是以各种有人驾驶和无人驾驶航空器的低空飞行活动为牵引,辐射带动相关领域融合发展的一种综合性经济形态。作为继公路、铁路、海运、航空(高空)之后,有望形成的“第五张”立体交通网络,在传统行业的转型升级,完善交通体系、提高物流效率等多方面具有巨大潜力,是中国乃至全球产业发展的一个战略性新赛道[1-2]。
低空经济作为一个明确的、整合性的战略概念,其技术挑战是一个复杂系统性问题。目前许多核心的技术方案,都依赖于一个高性能的通信网络。而URLLC(Ultra Reliable Low-Latency Communication,超可靠低时延通信)作为国际电信联盟为第五代移动通信技术定义的三大核心应用场景之一,其核心指标恰好可以满足低空经济问题的绝大部分需求[3-5]。
URLLC系统物理层面的终极目标是在严格的1 ms级时延约束下,实现高达99.999%的传输可靠性[3]。而在接收端,经过均衡后恢复的物理量的准确性,完全依赖于信道估计的准确性。如果估计不准确将引入额外的、严重的失真[4]。这种失真会导致解调器产生大量错误,即使信噪比很高,误码率也会急剧上升,直接导致无法满足99.999%的可靠性要求。由此可见高精度的信道估计是达成URLLC超可靠性的先决条件[4-5]。
与此同时,由于URLLC的目标是达成极高的可靠性和极低的端到端时延,与传统信道估计范式存在固有冲突;以及低空信道高速移动、URLLC短包传输、复杂三维环境等特性。继而催生了以“在极端苛刻的时延和可靠性约束下,寻求导频开销、估计精度和计算复杂度之间的最佳折衷”为核心设计原则的新型信道估计的研究[6-7]。
为此,本文从低空经济应用场景和URLLC系统入手,综述了当前信道估计算法。首先描述了低空通信系统及其信道模型特征,其次将已有的信道估计算法进行了分类,并对每类的信道估计算法进行了归纳和对比分析,然后梳理了信道估计算法面临的技术挑战,最后探讨了未来发展趋势。
1 低空通信系统以及信道模型
1.1 应用场景
低空经济的典型应用场景如表1所示[7-8],主要包括生产作业、交通运输、文体活动、安防安保四个方面。
在生产作业方面,可以利用无人机进行大规模、高效率的精准作业。包括农药喷洒、作物状态监测、播种等农业作业、基础设施的巡检、测绘[9-10]。此外,应急通信保障(地震、洪水等自然灾害导致地面通信设施瘫痪)和环境监测与保护(用于大气质量监测、水体污染巡查、野生动物保护等)已经成为低空经济的发展刚需。
交通运输应用中,城市空中交通作为一种面向未来的立体交通解决方案,是低空经济的发展重点。它要求具有完备的空中客运系统、以城市即时配送为主的物流配送系统与紧急医疗救援与警务巡逻系统[8]。而景区外卖、生鲜运输、跨海直运等载物运输以及商务专线、城际通勤、短途客运等载人运输同样具有极大的发展潜力。
而在文娱体育产业,无论是空中媒体与表演、竞技体育等大众娱乐,还是航拍与影视制作等艺术创作,亦或是低空研学、飞行执照考级,都可以成为低空经济多样化的应用场景。
除此之外,安防安保也是低空经济一大应用领域。低空监测识别体系、电子围栏监控、等技术或将成为未来最具保障力的安全防护措施,也为低空经济的其他应用场景提供了后勤物资保障。
1.2 URLLC系统
URLLC是提供给低空经济的通信保障,其设计目标是为需要极高可靠性和极低时延的关键任务型应用提供连接服务。
(1)MIMO-OFDM架构
目前URLLC采用的是多载波的OFDM(Orthogonal Frequency Division Multiplexing,正交频分复用)技术[13]。该技术把高速的数据流通过串并变换,分配到速率相对较低的若干个正交的频率子信道中进行传输,提高了频谱利用率[14]。图1是基于导频辅助的OFDM系统中的信号处理流程[14-16]。
2 低空场景下的URLLC信道估计
结合低空经济应用场景,信道估计传统技术(LS、MMSE)的局限性,以及前沿领域的研究,信道估计技术的核心追求就是:如何利用尽可能少的导频资源(非零导频)来实现尽可能高精度的估计。本节从先验信息获取、压缩感知、张量分解、深度学习四个方面,综述了信道估计的研究进展。
2.1 先验信息获取
上文提到的传统估计方法,通过接收信号Y和导频信号X进行估计。这样的传统方式计算量偏少,却存在性能瓶颈。本节介绍方法的通过利用非无线信号本身的外部信息来对信道信息进行预测,提升估计精度、降低导频开销或加速估计过程,称为先验信息的获取。
Zhang C等[22]在无人机通信网络研究中提出了侧面信息辅助的设想,在此基础上,何尔利等[23]以地面基站和无人机间的LoS假设为基础,利用位置信息预测出无线信号传播方向的AoA(Angle of Arrival,到达角)和AoD(Angle of Departure,出发角),并指出在此基础上将波束调整到所需方向以辅助信道估计,可缩短估计时间。然而,低空环境中,由于建筑物遮挡,导致与基站之间没有视距链路,存在盲区,即处于NLoS的状态。
在解决盲区覆盖问题中,RIS(Reconfigurable Intelligent Surface,可重构智能表面)技术展现了巨大潜力。Wu Q和Zhang R[24]提出了智能反射表面可用于改善通信盲点,后续的研究重点主要是设计算法去优化包括发射功率和反射相位等参数。文献[25-30]聚焦于使用波束赋形的场景,从不同指标对含有智能反射表面的无线通信系统进行了波束赋形的联合优化。
但由于这些研究中均是假设可以获得完美的CSI(Channel State Information,信道信息), 而RIS引入了具有高维特征的级联通道,使得CSI难以估计,无法证明RIS在实际低空通信中的可行性。因此,You L等[31-32]开始分析非完美信道信息情况下MIMO系统上行链路传输的性能,并探索对CSI的获取。
随后的研究陆续出现了RIS辅助下的先进算法,如任进等[33]提出的正则化改进三阶段MMSE算法,对噪声和误差干扰极大抑制,提升了信道估计的精确性和稳定性。邱友静等[38]提出的经过RIS相移矩阵优化的基于LMMSE(Linear Minimum Mean Square Error,线性最小均方误差)的信道估计。
此外,由于CSI的特性,应用KF(Kalman Filter,卡尔曼滤波)算法可抑制状态转移序列中变化的噪声项[34-35]。基于此,Chen X等[34]提出了一种联合KF的信道估计增强算法,但需要融合更多的环境信息。于是李波等[36]提出了ASAKF(Angel Sensing-Aided Kalman Filter,基于角度感知辅助卡尔曼滤波)算法。Vlachos等[37]同样提出基于卡尔曼滤波融合全球定位系统数据与导频信号进行信道跟踪的方法。
综上,基于先验信息的信道估计算法总结如表2所示。
2.2 稀疏压缩感知
Candes E J等[39]指出稀疏信号能从较少的观测数据中通过非自适应的重构算法高概率地恢复出原始信号,并将这种获取稀疏信号的信息方法称为CS(Compressed Sensing,压缩感知)。采用压缩感知以较少的导频数实现信道重建,进而估计出信道状态,即Hk。压缩感知信道估计算法多样,本节只聚焦于适用于URLLC要求的算法。
(1)贪婪追踪算法
文献[40]中提到的MP(Matching Pursuit,匹配追踪)是最原始的一种信号稀疏重建算法,尽管技术实现度不高,但作为最基础的且较常用的信号稀疏重构算法之一,它的贪婪迭代的思想,影响到后续的各种算法,有着不可忽视的作用。而文献[41]提出的OMP(Orthogonal Matching Pursuit,正交匹配追踪),能够收敛到信号的稀疏解,在信号的重构质量上,要好于MP算法,然而该算法增加了一步正交化操作使计算量大大增加,所以对原始信号的重建时间必然会有所增加。因而催生了文献[42]中的ROMP(Regularized Orthogonal Match Pursuit,正则化正交匹配追踪)算法,该算法运用的正则化思想提高了重建过程的运算速度,运算时间低于OMP算法,但同时也存在着重建精度相对较低的问题。此外文献[43]所提出的CoSaMP(Compressive Sampling Matching Pursuit,压缩采样匹配追踪)算法对基础算法进行了误差界定的改进,以其强理论保证和鲁棒性著称,成为追求高性能的优选。此类算法的核心逻辑是非自适应线性测量以及稀疏重构,如图3所示,预处理后的信号具有限制等距性质,保证稀疏信号能稳定重构,其中从初始化到后处理之前的流程正是对应CoSaMP算法中的稀疏重构这一关键步骤。同样基于OMP算法,文献[44]提出的3D-SOMP(3D Simultaneous Orthogonal Matching Pursuit,三维联合正交匹配追踪)算法很好地解决了CoSaMP在处理多维信号中的计算复杂性。此外,2007年Dai[45]等人提出的SP(Subspace Pursuit,贪婪算法子空间追踪)算法与CoSaMP算法原理类似,也有着接近CoSaMP的性能。
上述算法追求信道重建精度与时间的双重把控,但对先验信息的过度依赖限制了它的实用性。而为解决稀疏性未知条件下的信道估计问题,文献[46]提出了一种SAMP(Sparsity Adaptive Matching Pursuit,稀疏自适应匹配追踪)算法的信道估计方法,可以自适应调整匹配过程的稀疏度,拓宽了压缩感知算法的应用范围,却一定程度上降低了重建的精确度。文献[47]提出的基于弱选择正则化的正交匹配追踪图像重构算法以及文献[48]提出的SAStOMP(Sparsity Adaptive Stagewise Orthogonal Matching Pursuit,自适应分段正交匹配追踪)算法同样实现了在信号稀疏度未知的条件下,仍能完成稀疏信号的重构。
在MP算法发展的同一时间中,文献[49-50]提出了基于IHT(Iterative Hard Thresholding,迭代硬阈值)原理的阈值迭代算法,并引入了具有自适应调整性质的步长,发展出NIHT(Normalized Iterative Hard Thresholding,正规化迭代硬阈值)算法,提升了原始的IHT算法数值表现。文献[51]和文献[52]分别利用共轭梯度的方法和回溯的方式对IHT算法进行了改进设计,提出CGIHT(Conjugate Gradient Iterative Hard Thresholding,共轭梯度迭代硬阈值)和BIHT(Backtracking Iterative Hard Thresholding,回溯迭代硬阈值)算法,进一步提升了算法性能。
由于贪婪算法可能陷入局部最优的问题,而压缩感知恢复问题中的范数l0是一个可分离的且具有稀疏特性的函数,即可以作为目标函数进行凸松弛求解。因此可以通过凸优化算法找到全局最优解。其中ADMM(Alternating Direction Method of Multipliers,交替方向乘子法)具有能够分解问题而实现并行运算,稳定收敛到全局最优解,不依赖参数等特性[53-54],最适用于低空经济场景下的通信场景。但其收敛速度可能较慢,尤其是在高精度要求下,且需要设计合适的停止准则来判断收敛。
综上,基于贪婪追踪的信道估计算法总结如表3所示。
(2)贝叶斯类算法
上节提到的算法需要人工设置参数,而这些参数又极大影响算法效能,缺乏科学的参数设置工具。而贝叶斯类算法因其可以自动迭代信号参数,无须人工干预,使得恢复性能往往优于其他重构类算法。Tiping等经过13年的陆续研究,实现了SBL(Sparse Bayes Learning,稀疏贝叶斯学习)在信道估计领域的推广[55-57]。在此基础上,文献[58]利用信号元素的结构特性,改进了一种名为BSBL(Block Sparse Bayesian Learning,块稀疏贝叶斯学习)方法,但只适用于具有特定结构的信号的信道模型。文献[59]则将LASSO(Least Absolute Shrinkage and Selection Operator,最小绝对收缩和选择算子)的方法运用于贝叶斯理论,但却无法准确估计变量。于是文献[60]施加不同的权重于信号中的元素,提出了自适应LASSO算法,清除了上述算法的缺陷。除了针对于LASSO算法本身进行改进,文献[61]将LARS(Least Angle Regression,最小角回归)算法用于求解LASSO问题,无需迭代优化且便于分析变量选择过程,但每一步需要计算所有变量与残差的相关性,对一些场景同样不适用。文献[62]则是将ADMM算法融入,提出了两阶段LASSO-ADMM算法,充分利用了信道的稀疏性质,保证高估计精度的同时大幅减轻了计算负担。此算法需要仔细设计初始化和迭代过程才能实现最优性能。
(3)特殊结构性稀疏
在一些特定场景中,可以通过引入特定的结构约束,使稀疏模式具有可解释的组结构或层次结构。
例如,在大规模MIMO高速移动场景中,新型调制技术OTFS(Orthogonal Time Frequency Space,正交时频空)信道在时延-多普勒-角度三维联合域中的结构稀疏特性,如图4所示。3D-ESP(3D Enhanced Sparse Pursuit,三维增强稀疏追踪)算法通过利用三维稀疏性,显著降低了传统方法所需的导频开销和计算复杂度,对解决先进波形在高移动性场景(如低空无人机通信、车联网)下的信道估计难题有着重要作用。研究表明,在高速移动场景下,3D-ESP结合深度学习的方法相比传统算法,估计精度提升约35%,导频开销降低至传统方法的40%,显著提升频谱效率。而在NLoS切换场景中,误码率低至0.001%以下,满足URLLC要求用[63]。
当信道的多径时延呈簇状出现时,之前所提到的基于OMP大部分算法都可以基于此结构特性进行改进,摆脱对稀疏度的过度依赖。
2.3 高维信号的张量分解
在MIMO-OFDM或OTFS等系统中,信道可以自然地表示为一个高阶张量,而信道张量Hk通常具有低秩特性。因此通过求解一个张量分解问题,同样可以来估计信道。由于常规导频设计需要每个时频块单独估计,造成了极大的导频开销。而利用张量的低秩性,就可以通过少量观测恢复完整信道,从而实现导频数量的减少。相关研究表明,该方法所需导频数量仅需传统的30%~50%[64]。同时张量分解方法相较传统方法以及压缩感知算法具有更强的抗噪能力,但在实时性和计算简便性上存在不足。
张量分解的基本模型有PARAFAC(Parallel Factor Analysis, 平行因子分析)或称为CPD(Canonical Polyadic Decomposition,典范多线性分解)和塔克(Tucker)模型模型[64-67]。
不考虑深度学习的情况下,PARAFAC的部分经典算法如ALS(Alternating Least Squares,交替最小二乘法)常用于盲信道估计方法,但其他算法仍具有低空场景的发展潜力。例如文献[65]提出的基于平行因子的SVD(Singular Value Decomposition,奇异值分解)算法,属于一种半盲估计,其能够在未知CSI的情况下,实现对符号和信道的联合估计。但由于SVD本身的计算复杂度较高,尤其是对于大规模矩阵,带来了偏高的计算量。
Tucker模型在MIMO系统中具有极高的适配性。代表性的Tucker分解算法包括HOSVD(High-Order SVD,高阶奇异值分解)和MLSVD(Multilinear SVD,多线性奇异值分解)算法[68],二者的基本原理都是将矩阵SVD推广到高阶张量,计算速度快,适合大规模数据初始化,却无法保证得到最优Tucker分解。文献[69]则提供了基于此初始化数据的改进方法,HOOI(High-Order Orthogonal Iteration,高阶正交迭代)算法,虽然有一定概率陷入局部最优,且计算复杂,仍然凭借极高的精度,成为满足URLLC要求的潜力算法。
此外PARAFAC结合Tucker可形成PARATUCK2模型[66],在高速移动场景中将时变信道建模为一个三阶张量,即时间×频率×天线。然后进行PARATUCK2分解。文献[67]中则将PARAFACPARATUCK2模型结合用于MIMO中,通过两阶段的迭代算法分别拟合两个张量模型,以少量的导频序列便能并行估计三跳信道矩阵,不仅可以避免误差叠加,而且提高了系统的频谱利用率。
上述的基本模型在大规模的MIMO中都存在一个缺点,即面对超高维信道时的计算复杂度高。为了降低计算复杂度,TT(Tensor Train,张量列)以及TR(Tensor Ring,张量环)分解的优势在此类应用中凸显了出来。文献[70]的研究证明TT-SVD算法及其改进的阶梯式算法在MIMO系统中的信道估计有明显的计算优势。由于当TT因子的两个边界矩阵以TR格式收缩时,TR分解就是TT分解的一般化形式,TT分解的算法在TR中同样适用。
TT和TR模型对维度之间的相关性都有一定要求。然而,在许多实际应用中,数据的不同维度之间可能存在任意两两之间的复杂交互,而不仅仅是相关维度的交互。为了捕捉任意两个维度之间的全局相关性,一种新型全连接张量网络结构——FCTN(Factorized Convolutional Tensor Network,因子分解卷积张量网络)形成并快速成为低空经济下URLLC信道估计中一种前沿的信号处理技术[71-72]。
综上,基于张量分解的信道估计算法总结如表4所示。
2.4 深度学习
近年来,人工智能迎来了蓬勃发展,为低空通信注入了新的发展动力。作为其核心技术的DL(Deep Learning,深度学习)以强大的数据驱动、非线性拟合、端到端优化与深层特征学习能力,实现了无需依赖显式的数学建模,而是直接从大量测量数据中自适应地学习特定场景下的信道特性与衰落模型[73-75]。这意味着合理利用该方法,不仅可以解决已知模型推导和改进的大部分难题,更是可以跳过一些难以用传统方程描述的复杂关联。并且只要数据训练充足,其完全可以提供更高精度、更低开销、更强鲁棒性的解决方案。将深度学习技术赋能于信道估计,已成为无线通信领域一个蓬勃发展的前沿研究方向[73]。目前的主流模型有DNN(Deep Neural Network,深度神经网络)、CNN(Convolutional Neural Network,卷积神经网络)、RNN(Recurrent Neural Network,循环神经网络)、LSTM(Long Short-Term Memory,长短期记忆)及其变体、Transformer以及混合网络等类型。
(1)模型驱动的方法
这类方法的核心是利用传统信道模型的数学结构、物理规律或迭代算法作为先验,将其设计成深度神经网络的架构,从而结合模型的可解释性与学习的灵活性。
文献[76]提出了知识驱动的 DNN,如图5所示,利用传统算法(如LS、MMSE)的数学框架作为先验,通过将问题解耦为“去噪+推理”两个阶段,在DNN中嵌入已知的物理模型或数学结构。在低信噪比下性能远超纯数据驱动方法,同时保持了传统算法的可解释性且训练过程更稳定,收敛速度更快,因此具有极强的适应性。但需要针对特定问题设计网络结构,通用性相对受限。而文献[77]提出的LISTA-CPD将压缩感知迭代算法与张量分解模相结合,通过在模型训练过程中同时优化LISTA的权重和CPD分解的因子矩阵,实现从观测数据到稀疏信号的端到端学习,提高恢复精度的同时加快计算效率。却同样需要针对特定问题设计网络结构。这两种算法同时高度依赖先验信息。因此文献[78]提出的SA(Sparsity Adaptive,稀疏度自适应)-DL-CS是一种稀疏度自适应的深度学习压缩感知信道估计方法,在具有自适应的不依赖先验信息优势的同时显著提高了精度和鲁棒性。但计算开销仍然较大,目前难以满足URLLC的极低时延要求。为了减少计算量,文献[79]提出SSRnet+PositionNet,将信道估计任务解耦为两个子任务:稀疏支撑集估计和路径参数估计,分别由SSRnet(Sparse Support set Regression Network,稀疏支撑集估计网络)和PositionNet(Position Network,路径参数估计网络)两个子网络完成。避免了感知矩阵的设计和存储开销,减少了计算量,导频开销显著降低。然而其目前成熟度仍面临在分数多普勒、非稀疏信道、动态环境下的挑战。
这些方法旨在利用有效的导频资源尽可能地高精度估计,并且具有完善理论依据,却难以应对复杂环境。
(2)数据驱动方法
与模型驱动方法不同,数据驱动依赖深度网络强大的表示学习能力,直接从数据中挖掘信道在时域、频域或特征空间的深层关联和模式,能有效突破上文方法无法在高动态环境中维持高性能的局限。
文献[80]所提出CNN-LSTM结合,保证了高精度和强鲁棒性,却对超参数异常敏感。文献[81]中的AE(Autoencoder,自编码器)+RNN在拥有上一个算法优点的同时,RNN的记忆机制能够有效跟踪信道的时变特性,对抗高多普勒频移,且削减了这一敏感性。然而其时序建模能力依赖RNN,且对噪声可能会更加敏感。文献[82]提出的CTs(Contrastive Learning for Channel Estimation,基于对比学习的信道估计)则是一种基于对比学习的深度学习方法,具有线性计算复杂度,适合大规模系统部署。其性能增益依赖孪生网络能否有效区分正负样本,且在处理极端动态变化时不稳定。这些方法基于信道时变特性,统称为时序建模的方法。
而另一类方法基于注意力机制和先进的生成式模型,力求复杂环境下的高精度。如文献[83]提出的PD-CEViT,具有动态导频优化和自适应信道适应能力,但在资源受限的边缘设备上,推理速度可能成为瓶颈,因而无法统一使用。文献[84]应用的PCMamba(Position-aware Convolutional Mamba,位置感知卷积Mamba模型)是一种基于Mamba架构的深度学习模型,采用结构化稀疏矩阵运算,如图6所示,可在GPU上实现高效并行计算,同时在序列长度上具有线性可扩展性,特别适合处理大规模点云数据。具有超参数敏感性,并且尚未有足够的研究证明其应用潜力。生成式模型主要有DM(Diffusion Model,扩散模型)[85]、cGAN (Conditional Generative Adversarial Network,条件生成对抗网络)以及MIA-GAN (Multi-instance Attention GAN,多实例注意力生成对抗网络)[86]。三种模型各有利弊:其中cGAN实现简单,适合作为研究基线或对计算资源有限的场景。DM虽然训练和推理复杂,但能提供目前最高的估计精度和最低的导频开销,是满足URLLC极端要求的潜力技术。而当系统存在严重的硬件损伤(如低精度ADC)时,MIA-GAN能有效补偿信息损失,提升系统鲁棒性。
除此之外,还有一类适用于快速部署的元学习与小样本适应方法,可作为应对多样化环境的临时选择。主要技术有利用SAMBA(Self-Adaptive Meta-learning for Beam Alignment,元学习框架)[87],无需CSI以做到快速适应,以及通过O2SC(Online-offline Shared Components,在线-离线共享组件框架)中的离线预训练实现在线快速适应[88]。
面对存在异构网络的复杂场景,可以利用专用网络与端到端优化。这是深度学习在信道估计中的高级应用形式,通过设计专门针对特定问题或直接优化系统级目标的网络架构,实现性能的突破性提升。以双DNN架构[89]、StructNet(Structured Network,结构化网络)[90]和WDANet(Weighted Dynamic Adaptive Network,加权动态自适应网络)[91]为代表,虽然面临可解释性差、训练复杂等挑战,其性能突破仍使其成为未来智能通信系统的关键技术方向。
综上,基于深度学习的信道估计算法总结如表5所示。
3 技术挑战与发展趋势
目前,针对低空经济下URLLC的信道估计的方法仍然处在发展完善阶段,大部分较为成熟的算法还需针对特定情形进行进一步的改进,性能极高的算法在理论解释性和推广程度上还存在空缺。总而言之,要在低空场景下完全实现URLLC的需求在目前来看仍然是一个亟待解决的难题。
3.1 技术挑战
目前,导频设计与资源分配,URLLC特性与低空场景高动态的矛盾,已经有成熟的技术路径和理论模型。例如:CoSaMP及其后续改进算法,在利用稀疏性减少导频消耗的基础上引入自适应追踪[43, 46-48]和以DM为代表的生成式模型[82]等,这些算法极大地改进了上述两个问题。然而当前的信道估计仍然面临着许多技术挑战。
(1)复杂度与实时性间的不相容。上文提到的一些算法具有极高的计算精度及效率,但无一例外,计算都极为复杂,以致于难以在机载计算资源上实现。其次是对非平稳信道跟踪,即便是目前最先进的自适应跟踪机制,也仅仅达到了最基本的精度和效率要求。
(2)已有算法对极端非平稳、非平稳信道的跟踪能力仍显不足。在无人机高速移动、障碍物频繁遮挡、以及复杂多径与多普勒效应交织的动态环境中,信道呈现出强烈的非平稳与非平滑特性。而现有的自适应跟踪机制,大多基于信道变化相对平缓或具有特定变化模型的假设[48, 59]。它们虽然在缓变场景中表现优异,但对于模型失配的低空信道,其跟踪速度与精度下降显著,往往只能满足最基本的性能门限。
(3)许多算法对实际系统中的非理想因素敏感。如收发机的相位噪声会导致抗噪能力不足的算法出现误码率攀升、信号损失等问题,以CoSaMP算法为例,有相位噪声的情况会是支撑集恢复错误率从5%升至23%[43]。ADC或DQC的量化误差、以及天线阵列的互耦与校准误差等同样会造成信号受损,信噪比损失,错误率升高的问题。针对此类情况,相位噪声补偿技术以及量化误差补偿策略是目前普遍运用的补偿机制,而基于贝叶斯推理的联合估计或元学习补偿框架可能成为未来重要的新型补偿算法。除上述因素外,许多高性能算法(如PCMamba[81])往往对超参数设置、初始条件或输入数据的质量极为敏感,参数稍有偏移或环境略有变化,性能便急剧下降。致使仿真实验与实际的应用中存在难以忽视的差距,严重制约了先进算法的实际应用价值。
(4)新型波形下的信道估计的挑战。近年来,新型调制技术逐渐兴起。以OTFS为例,其在适应高速运动环境、适用复杂信道环境展示出了显著的优势,却同样对时频关联的准确度,多维匹配滤波器的设计以及硬件的性能有着更高的要求[92]。同时先进的波形理论往往要与深度学习、张量分析等现代信号处理工具更深度地融合,如何保证系统之间的互操作性和兼容性,同样是新型波形下的信道估计中亟待解决的关键问题[93]。
(5)6G标准演进对信道估计的基础性新要求。6G标准对信道估计的性能要求,主要体现在三个维度。首先是可靠性要求的跨越式提升:要求99.999 99%的传输可靠性,意味着信道估计误差需要控制在更严格的范围内;其次是时延约束的进一步压缩:要求空口时延从1 ms级向0.1 ms级迈进,即信道估计必须在微秒级完成,使得传统迭代算法的收敛速度面临严峻挑战;同时频谱效率的需求也倍增:要求达到5G的10~100倍,而导频开销需要进一步降低至现有水平的10%~20%。
3.2 发展趋势
基于深度学习与传统模型结合的改进方法依然会是未来数年内的主流趋势,未来的主要研究方向将聚焦于以下五个维度:
(1)轻量化与可部署网络设计。这是工程化应用的首要挑战。旨在从网络架构、模型压缩、知识蒸馏等多个层面突破:一方面,设计专门针对信道估计任务的轻量级网络结构,在保证性能的同时大幅降低计算开销;另一方面,探索模型剪枝、量化、低秩分解等压缩技术,将大型网络部署到边缘设备;此外,通过知识蒸馏将复杂网络的知识迁移到轻量网络,实现“小模型、大性能”的目标。
(2)多模态与生成式学习结合。这是提升信道估计鲁棒性的关键路径。通过多模态融合学习,可以利用感知系统提供的环境信息、障碍物分布、无人机运动状态等先验知识,辅助信道估计任务。生成式模型则能够从有限导频中获得高质量的信道状态信息。未来研究将探索如何将多模态信息与生成式学习有机结合,构建能够自适应融合不同信息源、在复杂环境下保持稳定性能的智能估计框架。
(3)模型泛化和多样性化。这是应对低空场景复杂多变特性的必然要求。未来研究需从三个层面提升模型泛化能力:一是设计对超参数、初始条件不敏感的鲁棒算法,降低部署难度;二是开发能够自适应不同场景、不同信道统计特性的可迁移模型,避免“一场景一模型”的困境;三是探索元学习、领域自适应等先进技术,使模型能够快速适应新环境、新任务。
(4)高效的数据训练方法。这是解决数据稀缺问题的核心手段。系统在实际部署中,获取大量标注良好的信道数据成本高昂、难度极大。未来研究将重点突破:一是半监督与自监督学习,利用大量无标签数据提升模型性能;二是迁移学习与少样本学习,将地面或仿真数据中学习到的知识迁移到低空场景;三是数据增强与合成数据生成,通过物理模型或生成式模型扩充训练数据集;四是联邦学习等分布式训练框架,在保护数据隐私的前提下实现多设备协同训练。
(5)基于新兴架构的研究。随着ISAC(Integrated Sensing and Communication,通感一体化)技术的兴起,相关信道估计研究也不断涌现。利用ISAC感知功能(如雷达、激光雷达、视觉感知)不仅获取无人机的精确位置、速度、姿态以及环境地图作为先验信息,甚至利用感知信号(如雷达回波)本身作为“导频”,再加上感知系统能够提供连续的运动状态信息,使得ISAC或将解决低空通信高动态、低开销难题的关键技术。未来的研究将聚焦于从资源分配和波形设计来进行感知与通信的权衡,并减小感知误差。这些问题的进展决定这ISAC在低空经济信道估计中的应用前景。除了ISAC技术,大规模MIMO架构也是一种热门的前沿网络架构。它通过分布式天线部署和集中式处理,在大规模MIMO下使得信道趋于确定化,故而利用统计特性进行简化估计,降低估计复杂度。
综上,新兴通信架构下的信道估计正朝着模态融合和分布式处理的方向发展。这为突破传统信道估计的性能瓶颈提供了新的机遇,但也引起了有关联合优化、跨层设计、分布式算法研究等新的领域。
4 结束语
本文系统梳理了面向低空经济URLLC的信道估计研究进展。面对低空信道的高动态、非平稳特性以及URLLC对极低时延和超可靠性的严苛要求,信道估计技术已从传统的基于导频的线性估计,发展为融合先验信息、压缩感知、张量分解及深度学习等多种先进技术的综合性解决方案。其中深度学习技术凭借其强大的数据驱动和非线性拟合能力,已成为突破传统信道估计性能瓶颈的关键。在未来信道估计研究中,将主要集中于以下三个关键问题:算法在边缘设备部署的实际挑战、多模态融合的标准化缺失以及动态环境自适应机制的技术发展。相信随着人工智能与无线通信技术的深度融合,以及新型通信架构的兴起,信道估计技术将持续演进,为低空经济的蓬勃发展提供坚实可靠的通信保障。
参考文献:(上下滑动浏览)
[1] 张晓兰,黄伟熔. 低空经济发展的全球态势、我国现状及促进策略[J]. 经济纵横, 2024(8): 53-62.
[2] Huang H L,Su J C,Wang F Y. The Potential of Low-Altitude Airspace:The Future of Urban Air Transportation [J]. IEEE Transactions on Intelligent Vehicles, 2024,9(8): 5250-5253.
[3] 3GPP TR 38.913. 5G; Study on Scenarios and Requirements for Next Generation Access Technologies (Release 17)[S]. 2022.
[4] She C Y, Sun C J, Gu Z Y, et al. A Tutorial on Ultrareliable and Low-Latency Communications in 6G:Integrating Domain Knowledge into Deep Learning[J]. Proceedings of The IEEE, 2021,109(3): 204-246.
[5] 张德君. 5G-A通感一体化网络在低空经济中的应用研究[J]. 无线互联科技, 2025,22(9): 94-99.
[6] 雷伊婷,骆忠强,王再强. 面向6G通信场景的OTFS信道估计:原理、方法、挑战[J/OL]. 无线电通信技术, 1-26[2025-11-15].
[7] 廖勇,覃录智,刘思其. 无人机在低空经济中的应用综述[J]. 贵州大学学报(自然科学版), 2025,42(4): 60-72.
[8] 赛迪. 中国低空经济应用场景研究报告[R]. 2025.
[9] 刘美言,刘佳. 新质生产力背景下低空经济与农业融合发展的现状、挑战与对策[J]. 中国商论, 2025,34(22): 146-149.
[10] 王丹,罗章松. 低空经济赋能农业新质生产力发展:角色扮演、现实壁垒与破解之道[J]. 农林经济管理学报, 2025,24(2): 165-172.
[11] Zhang Y N,Xu F Y,Jia M P. A Modified Time Domain Interpolation Method for LS Channel Estimation in OFDM Systems[J]. Journal of Southeast University (English Edition), 2022,38(3): 219-226.
[12] 赵敏,林涛,曾晓. OFDM系统中基于深度学习的信道估计和信号检测技术[J/OL]. 移动通信,1-7[2025-12-10].
[13] 廖勇,韩小金. 基于机器学习的OTFS系统信道估计与信号检测研究进展[J]. 移动通信, 2024,48(7): 46-56.
[14] 周小平. 高速移动MIMO OFDM系统快衰落信道估计方法[D]. 上海: 上海大学, 2011.
[15] Robson J. The LTE/SAE Trial Initiative: Taking LTE/SAE from Specification to Rollout - Lte Part Ii: 3gpp Release 8[J]. IEEE Communications Magazine, 2009,47(4): 82-88.
[16] Shin A, Jung K, Park A. Design of Session and Bearer Control Signaling in 3GPP LTE System[C]//68th IEEE Vehicular Technology Conference. Calgary, Canada: IEEE, 2008,21: 1-5.
[17] 纪金伟,高雷涛,周云,等. 一种适用于低空多径环境的MIMO-OFDM信道估计新方法[J]. 西安邮电大学学报, 2025,30(3): 11-19.
[18] Fujino Y, Uchida D, Fujita T, et al. A Subspace Estimation Method Based on Eigenvalue Decomposition for Multi-Target Constant Modulus Algorithm[C]//IEEE Wireless Communications and Networking Conference. Hong Kong, China: IEEE, 2007,3: 1231-1235.
[19] Lee S J. Effect of Least Square Channel Estimation Errors on Achievable Rate in MIMO Fading Channels[J]. IEEE Communications Letters, 2007,11(11): 862-863.
[20] 梁超,项铁铭,刘超,等. 第三代移动通信信道模型仿真分析[J]. 计算机仿真, 2009,26(9): 100-103.
[21] 王代华,宋林丽,王宇龙,等. 平坦地面无线信道的大尺度衰落特性[J]. 计算机工程与设计, 2012,33(6): 2141-2145.
[22] Zhang C, Zhang W, Wang W, et al. Research Challenges and Opportunities of UAV Millimeter-Wave Communications[J]. IEEE Wireless Communications, 2019,26(1): 58-62.
[23] 何尔利,纪澎善,贾向东,等. 位置协助的无人机毫米波通信网络自适应信道估计[J]. 计算机工程, 2020,46(6): 196-201.
[24] Wu Q, Zhang R. Towards Smart and Reconfigurable Environment: Intelligent Reflecting Surface Aided Wireless Network[J]. IEEE Communications Magazine, 2020,58(1): 106-112.
[25] Ntontin K, Renzo M D, Song J, et al. Reconfigurable Intelligent Surfaces Vs.Relaying: Differences, Similarities, and Performance Comparison[J]. IEEE Open Journal of the Communications Society, 2020,1: 798-807.
[26] Wu Q, Zhang R. Intelligent Reflecting Surface Enhanced Wireless Network Via Joint Active and Passive Beamforming[J]. IEEE Transactions on Wireless Communications, 2019,18(11): 5394-5409.
[27] Abeywickrama S, Zhang R, Wu Q. Intelligent Reflecting Surface: Practical Phase Shift Model and Beamforming Optimization[J]. IEEE Transactions on Communications, 2020,68(9): 5849-5862.
[28] Jung M, Saad W, Debbah M, et al. Asymptotic Optimality of Reconfigurable Intelligent Surfaces:Passive Beamforming and Achievable Rate[C]//2020 IEEE international Conference on Communications (ICC). Dublin, Ireland: IEEE, 2020: 1-6.
[29] Guo H, Liang Y, Chen J, et al. Weighted Sum-Rate Maximization for Intelligent Reflecting Surface Enhanced Wireless Networks[C]//2019 IEEE Global Communications Conference (GLOBECOM). Waikoloa, HI, USA: IEEE, 2019: 1-6.
[30] Li S, Duo B, Yuan X, et al. Reconfigurable Intelligent Surface Assisted UAV Communication: Joint Trajectory Design and Passive Beamforming[J]. IEEE Wireless Communications Letters, 2020,9(5): 716-720.
[31] You L, Xiong J, Huang Y, et al. Reconfigurable Intelligent Surfaces-Assisted Multiuser MIMO Uplink Transmission with Partial CSI[J/OL]. arXiv:2002.13014, 2020.
[32] Yang Y, Zheng B, Zhang S, et al. Intelligent Reflecting Surface Meets OFDM:Protocol Design and Rate Maximization[J/OL]. arXiv:1906.09956, 2019.
[33] 任进,李一博,张尧,等. 基于正则化多阶MMSE的IRS辅助无人机通信系统信道估计算法[J]. 无线电通信技术, 2025,51(6): 1297-1305.
[34] Chen X, Feng Z Y, Zhang A, et al. Sensing Aided Uplink Channel Estimation for Joint Communication and Sensing[J]. IEEE Wireless Communications Letters, 2023,12(3): 441-445.
[35] Khodrarhmi M, Vafa M. A Review on Kalman Filter Models[J]. Archives of Computational Methods in Engineering, 2023,30(10): 727-747.
[36] 李波,李正源. 基于角度感知的ISAC系统信道估计算法[J]. 计算机工程与设计, 2025,46(7): 1912-1918.
[37] Vlachos E, Mavrokefalidis C, Berberidis K, et al. Improving Wideband Massive MIMO Channel Estimation with UAV State-Space Information[J]. IEEE Transactions on Vehicular Technology, 2025,74(10): 15935-15948.
[38] 宋文彬,陈德川,张新刚,等. 双RIS辅助的多天线协作NOMA短包通信系统性能分析[J/OL]. 电子与信息学报,1-9[2026-01-17].
[39] Candes E J, Romberg J, Tao T. Robust Uncertainty Principles: Exact Signal Reconstruction from Highly Incomplete Frequency Information[M]. IEEE Press, 2006.
[40] 梁彦. 基于MP算法的信道估计研究[D]. 南京: 南京理工大学, 2003.
[41] Tropp J A, Gilbert AC. Signal Recovery from Random Measurements Via Orthogonal Matching Pursuit[J]. IEEE Transactions on information Theory, 2007,53(12): 4655-4666.
[42] Needell D, Vershynin R. Signal Recovery from Incomplete and Inaccurate Measurements Via Regularized Orthogonal Matching Pursuit[J]. IEEE Journal of Selected topics in Signal Processing, 2010,4(2): 310-316.
[43] Needell D, Tropp J A. CoSaMP:Iterative Signal Recovery from Incomplete and Inaccurate Samples[J]. Communications of the ACM, 2010,53(12): 93-100.
[44] Shen W, Dai L, An J, et al. Channel Estimation for Orthogonal Time Frequency Space (OTFS) Massive MIMO[J]. IEEE Transactions on Signal Processing, 2019,67(16): 4204-4217.
[45] Dai W, Milenkovic O. Subspace Pursuit for Compressive Sensing Signal Reconstruction[J]. IEEE Transactions on Information Theory, 2009,55(5): 2230-2249.
[46] 王艳芬,丛潇雨,孙彦景. 一种稀疏度自适应超宽带信道估计算法[J]. 电子科技大学学报, 2017,46(3): 498-503.
[47] 刘哲,张鹤妮,张永亮,等. 基于弱选择正则化正交匹配追踪的图像重构算法[J]. 光子学报, 2012,41(10):1 217-1221.
[48] Chen S S, Donoho D L, Saunders M A. Atomic Decomposition by Basis Pursuit[J]. SIAM Journal on Scientific Computing, 1988,43(1): 129-159.
[49] Blumensath T,Yaghoobi M, Davies M E. Iterative Thresholding for Sparse Approximations[J]. Journal of Fourier Analysis and Applications, 2008,14: 629-653.
[50] Blumensath T,Yaghoobi M, Davies M E. Normalized Iterative Hard Thresholding: Guaranteed Stability and Performance[J]. IEEE Journal of Selected topics in Signal Processing, 2010,4(2): 298-309.
[51] Blanchard J D, Tanner J, Ke W. Conjugate Gradient Iterative Hard Thresholding: Observed Noise Stability for Compressed Sensing[J]. IEEE Transactions on Signal Processing, 2014,63(2): 528-537.
[52] Yang H R, Fang H, Zhang C, et al. Iterative Hard Thresholding Algorithm Based on Backtracking[J]. Acta Automatica Sinica, 2011,37(3): 276-282.
[53] Boyd S, Parikh N, Chu E, et al. Distributed Optimization and Statistical Learning Via The Alternating Direction Method of Multipliers[M]. Hanover:Now Foundation and Trends, 2011.
[54] He B S, Ma F, Yuan X M. Convergence Study on The Symmetric Version of ADMM with Larger Step Sizes[J]. SIAM Journal of Imaging Science, 2016,9(3): 1467-1501.
[55] Tipping M E. Sparse Bayesian Learning and The Relevance Vector Machine[J]. Journal of Machine Learning Research, 2001,1(3): 211-243.
[56] Mccall J C, Trivedi M, Wipf D P, et al. Lane Change Intent Analysis Using Robust Operators and Sparse Bayesian Learning[J]. IEEE Transactions on Intelligent Transportation Systems, 2007,8(3): 431-440.
[57] Qiu K, Dogandzic A. Variance-Component Based Sparse Signal Reconstruction and Model Selection[J]. IEEE Transactions on Signal Processing, 2010,58(6): 2935-2952
[58] Zhang Z, Rao B D. Sparse Signal Recovery with Temporally Correlated Source Vectors Using Sparse Bayesian Learning[J]. IEEE Journal of Selected topics in Signal Processing, 2011,5(5):912-926.
[59] Babacan S D, Molina R, Katsaggelos A K. Bayesian Compressive Sensing Using Laplace Priors[J]. IEEE Transactions on Image Processing, 2010,19(1): 53-62.
[60] Zou H. The Adaptive LASSO and Its Oracle Properties[J]. Journal of the American Statistical Association, 2012(1): 1418-1429.
[61] 符洋森,伍亮,蒙亚捷,等. 基于两阶段LASSO-ADMM算法的半盲稀疏信道估计和数据检测[J]. 信息技术与信息化, 2024(8): 4-8.
[62] 张珍凤,张文芳. 基于LASSO算法的波束空间信道估计[J]. 无线互联科技, 2023,20(11): 14-19.
[63] Gui Z, Li Y, Zhou C, Xiong Q, et al. 3D-ESP: An Efficient Subspace Pursuit Algorithm for MIMO-OTFS Channel Estimation[J]. IEEE Transactions on Vehicular Technology, 2024,73(11): 17714-17719.
[64] Lin H, Zhang Z, Pan X, et al.Joint Channel Estimation and Symbol Detection for UAV-Assisted Systems Using Tensor Framework[C]//2022 IEEE 22nd International Conference on Communication Technology (ICCT). Nanjing, China: IEEE, 2022: 1025-1030.
[65] 韩曦,赵雨雨,刘芹,等. 基于PARAFAC分解的通信系统信道估计方法[J]. 现代信息科技, 2020,4(2): 71-72.
[66] Han X, De Almeida A L F, Yang Z. Channel Estimation for MIMO Multirelay Systems Using a Tensor Approach[J]. EURASIP Journal on Advances in Signal Processing, 2014(1): 1-13.
[67] 穆晓敏,刘越,李双志,等. 基于张量分解的MIMO多中继系统半盲信道估计方法[J]. 郑州大学学报(工学版), 2016,37(6): 83-86,96.
[68] Delathauwer L, De Moor B, Vandewalle J. A Multilinear Singular Value Decomposition[J]. SIAM Journal on Matrix Analysis and Applications, 2000,21(4): 1253-1278.
[69] Delathauwer L, De Moor B, Vandewalle J. On The Best Rank-1 and Rank-(r1,r2, ...,rn)Approximation of Higher-order Tensors[J]. SIAM Journal on Matrix Analysis and Applications, 2000,21(4): 1324-1342.
[70] Zniyed Y, Boyer R, De Almeida A L, et al. A TT-Based Hierarchical Framework for Decomposing High-Order Tensors[J]. SIAM Journal on Scientific Computing, 2020,42(2): A822-A848.
[71] Zhang H, Huang T Z, Zhao X L, et al. Hyperspectral Image Denoising: Reconciling Sparse and Low-Tensor-Ring-Rank Priors in The Transformed Domain[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023,61: 1-12.
[72] Chen Y, He W, Zhao X L, et al. Exploring Nonlocal Group Sparsity Under Transform Learning for Hyperspectral Image Denoising[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022,60: 1-18.
[73] 张诒杰,杨心悦,杨定国,等. 基于深度学习的信道估计综述[J/OL]. 无线电通信技术,1-17[2025-12-27].
[74] Chen Z, Zhang Z, Yang Z. Big Ai Models for 6G Wireless Networks: Opportunities, Challenges, and Research Directions[J]. IEEE Wireless Communications, 2024,31(5): 164-172.
[75] Kim S, Park J, Lee M, et al. Role of Sensing and Computer Vision in 6G Wireless Communications[J]. IEEE Wireless Communications, 2024,31(5): 264-271.
[76] Yang R, Xu S, Zhu Z, et al. Knowledge-Driven Channel Estimation for Asymmetrical Massive MIMO Systems[J]. IEEE Transactions on Vehicular Technology, 2025, 74(1): 911-923.
[77] Yang J, Li S, Wang H, et al. Deep Learning-Based Near-Field Wideband Channel Estimation: A Joint LISTA-CP Approach[J]. IEEE Transactions on Vehicular Technology, 2025,74(9): 14041-14052.
[78] Wang H, Wang L, Wang Z, et al. Deep Learning Based Channel Estimation for Massive MIMO: A Sparsity Adaptive Compressive Sensing Method and FPGA Implementation[J]. IEEE Transactions on Cognitive Communications and Networking, 2026(12): 2410-2422.
[79] 游雨欣,姜兴龙,刘会杰,等. TDD OTFS低轨卫星通信系统的LLM信道预测方法[J]. 电子与信息学报, 2025,47(8): 2535-2548.
[80] Zhang G, Kang K, Cai Y, et al. O2SC: Realizing Channel-Adaptive Semantic Communication with One-Shot Online-Learning[J]. IEEE Transactions on Communications, 2025,73(5): 3268-3282.
[81] Payami M, Blostein S D. Sparse Signal Recovery Neural Network with Application to High-Mobility Massive MIMO-OTFS Communication Systems[J]. IEEE Transactions on Vehicular Technology, 2025,74(8): 12175-12188.
[82] Zhang H, Wang X, Tan J, et al. Closer Twins Model: Consistent Design of Modem Scheme and Channel Estimation Under High-Mobility Scenarios[J]. IEEE Transactions on Wireless Communications, 2025,24(6): 4564-4580.
[83] Wu H, Chen Z, Liu Z, et al. CRS-Based Joint CFO and Channel Estimation Using Deep Learning in OFDM-Based Vehicular Communication Systems[J]. IEEE Transactions on Wireless Communications, 2025,24(5): 3882-3892.
[84] Wang J, Li S, Zhang Y, et al. Deep Learning Based Wavenumber Domain Channel Estimation for Holographic MIMO Communications[J]. IEEE Transactions on Vehicular Technology, 2026,75(1): 1619-1623.
[85] Zhou X, Liang L, Zhang J, et al. Generative Diffusion Models for High Dimensional Channel Estimation[J]. IEEE Transactions on Wireless Communications, 2025,24(7): 5840-5853.
[86] 徐明枫,李阳,韩凯峰,等. 基于GAN的导频配置和信道估计联合优化算法[J]. 信息通信技术与政策, 2023,49(9): 58-66.
[87] Xu Z, Wang S, Zhang Y J A. Scenario-Adaptive Meta-Learning for Mmwave Beam Alignment[J]. IEEE Transactions on Wireless Communications, 2025,24(4): 3192-3208
[88] Xu J, Li L, Zheng L, et al. Learning to Estimate: A Real-Time Online Learning Framework for MIMO-OFDM Channel Estimation[J]. IEEE Transactions on Wireless Communications, 2025,24(4): 2634-2646.
[89] Park J, Sohrabi F, Ghosh A, et al. End-to-End Deep Learning for TDD MIMO Systems in The 6G Upper Midbands[J]. IEEE Transactions on Wireless Communications, 2025,24(3): 2110-2125.
[90] Yang J, Fang Y, Dai L, et al. Residual Network-Based Channel Estimation for The Protograph LDPC-Coded OFDM Systems[J]. IEEE Communications Letters, 2023,27(10): 2568-2572.
[91] Zhang Z, Chen Y, Wang Y. Attention-Enhanced Channel Estimation for 6G MIMO in Unifying Far-Field and Near-Field[J]. IEEE Transactions on Vehicular Technology, 2025,74(10): 16584-16589.
[92] 廖勇,常星宇,苏畅. 面向OTFS-ISAC系统的智能信道估计现状、挑战与展望[J]. 移动通信, 2025,49(1): 91-100.
[93] 廖勇,罗渝,荆亚昊. 6G新型时延多普勒通信范式:OTFS的技术优势、设计挑战、应用与前景[J]. 电子与信息学报, 2024,46(5): 1827-1842. ★
扫描二维码,阅读下载本篇论文
doi:10.3969/j.issn.1006-1010.20260130-0001
中图分类号:TN929.5 文献标志码:A
文章编号:1006-1010(2026)04-0002-14
引用格式:廖勇,韩知孝. 面向低空经济超可靠低时延通信的信道估计研究进展[J]. 移动通信, 2026,50(4): 2-15.
LIAO Yong, HAN Zhixiao. Research Progress on Channel Estimation for High-Reliability and Low-Latency Communications in Low-Altitude Economy[J]. Mobile Communications, 2026,50(4): 2-15.
作者简介
廖勇:副研究员,博士毕业于重庆大学,现任职于重庆大学,CCF杰出会员,主要研究方向为超高速移动场景通信系统及其关键技术、智能通信。
韩知孝:重庆大学在读本科生,主要研究方向为智能通信。
《移动通信》杂志由中国电子科技集团公司主管,中国电子科技集团公司第七研究所主办,是中国期刊方阵“双效期刊”、工业和信息化部精品电子期刊、中国科技论文统计源刊、中国通信学会《信息通信领域高质量科技期刊分级目录》入选期刊、中国电子学会《电子技术、通信技术领域高质量科技期刊分级目录》入选期刊、中国应用型核心期刊、日本JST收录期刊。国内连续出版物号:CN44-1301/TN,国际连续出版物号:ISSN1006-1010,邮发代号:46-181。
作者:廖勇,韩知孝(重庆大学)
【赞助商】
OpenClaw快报
每天五分钟,听听 OpenClaw 快报,带你了解最新动态和业内讨论
传送门 www.xiaoyuzhoufm.com
【目录】
本期的 15 篇论文如下:
[00:31] 🔀 Redesign Mixture-of-Experts Routers with Manifold Power Iteration(利用流形幂迭代重新设计混合专家路由器)
[01:16] 🌳 Toward Generalist Autonomous Research via Hypothesis-Tree Refinement(迈向通用自主研究:通过假设树精炼实现)
[02:06] 🧪 Claw-SWE-Bench: A Benchmark for Evaluating OpenClaw-style Agent Harnesses on Coding Tasks(Claw-SWE-Bench:用于评估OpenClaw风格智能体框架在编码任务上的基准测试)
[03:12] 🌐 Agentic Environment Engineering for Large Language Models: A Survey of Environment Modeling, Synthesis, Evaluation, and Application(面向大语言模型的智能体环境工程:环境建模、合成、评估与应用综述)
[04:10] 🎯 Beyond Scalar Rewards by Internalizing Reasoning into Score Distributions(超越标量奖励:将推理内化为评分分布)
[05:13] 📊 TRL-Bench: Standardizing Cross-Paradigm Representation-Level Evaluation of Tabular Encoders(TRL-Bench:标准化表格编码器的跨范式表示级评估)
[05:57] 🔄 Reason, Then Re-reason: Cross-view Revisiting Improves Spatial Reasoning(先推理,再重新推理:跨视角重访提升空间推理能力)
[06:45] 🧩 DeNovoSWE: Scaling Long-Horizon Environments for Generating Entire Repositories from Scratch(DeNovoSWE:从零开始扩展长周期环境以生成完整代码仓库)
[07:42] 🤖 World Pilot: Steering Vision-Language-Action Models with World-Action Priors(世界领航员:利用世界-动作先验引导视觉-语言-动作模型)
[08:45] 🧠 On Subquadratic Architectures: From Applications to Principles(论次二次架构:从应用到原理)
[09:31] 🧩 ComBench: A Benchmark for Rigorous Proof Reasoning and Constructive Realization in Olympiad-Level Combinatorics(ComBench:面向奥林匹克级组合数学的严谨证明推理与构造实现基准)
[10:24] 🔓 Grammar-Constrained Decoding Can Jailbreak LLMs into Generating Malicious Code(语法约束解码可诱使大语言模型生成恶意代码)
[11:25] 🎥 InternVideo3: Agentify Foundation Models with Multimodal Contextual Reasoning(InternVideo3:通过多模态上下文推理将基础模型智能体化)
[12:18] ⚡ Breaking Entropy Bounds: Accelerating RL Training via MTP with Rejection Sampling(打破熵界:通过带拒绝采样的多令牌预测加速强化学习训练)
[13:14] 🔍 ICA Lens: Interpreting Language Models Without Training Another Dictionary(ICA透镜:无需训练另一本词典即可解读语言模型)

【关注我们】
您还可以在以下平台找到我们,获得播客内容以外更多信息
小红书: AI速递
【赞助商】
OpenClaw快报
每天五分钟,听听 OpenClaw 快报,带你了解最新动态和业内讨论
传送门 www.xiaoyuzhoufm.com
【目录】
本期的 15 篇论文如下:
[00:31] 🔀 Redesign Mixture-of-Experts Routers with Manifold Power Iteration(利用流形幂迭代重新设计混合专家路由器)
[01:16] 🌳 Toward Generalist Autonomous Research via Hypothesis-Tree Refinement(迈向通用自主研究:通过假设树精炼实现)
[02:06] 🧪 Claw-SWE-Bench: A Benchmark for Evaluating OpenClaw-style Agent Harnesses on Coding Tasks(Claw-SWE-Bench:用于评估OpenClaw风格智能体框架在编码任务上的基准测试)
[03:12] 🌐 Agentic Environment Engineering for Large Language Models: A Survey of Environment Modeling, Synthesis, Evaluation, and Application(面向大语言模型的智能体环境工程:环境建模、合成、评估与应用综述)
[04:10] 🎯 Beyond Scalar Rewards by Internalizing Reasoning into Score Distributions(超越标量奖励:将推理内化为评分分布)
[05:13] 📊 TRL-Bench: Standardizing Cross-Paradigm Representation-Level Evaluation of Tabular Encoders(TRL-Bench:标准化表格编码器的跨范式表示级评估)
[05:57] 🔄 Reason, Then Re-reason: Cross-view Revisiting Improves Spatial Reasoning(先推理,再重新推理:跨视角重访提升空间推理能力)
[06:45] 🧩 DeNovoSWE: Scaling Long-Horizon Environments for Generating Entire Repositories from Scratch(DeNovoSWE:从零开始扩展长周期环境以生成完整代码仓库)
[07:42] 🤖 World Pilot: Steering Vision-Language-Action Models with World-Action Priors(世界领航员:利用世界-动作先验引导视觉-语言-动作模型)
[08:45] 🧠 On Subquadratic Architectures: From Applications to Principles(论次二次架构:从应用到原理)
[09:31] 🧩 ComBench: A Benchmark for Rigorous Proof Reasoning and Constructive Realization in Olympiad-Level Combinatorics(ComBench:面向奥林匹克级组合数学的严谨证明推理与构造实现基准)
[10:24] 🔓 Grammar-Constrained Decoding Can Jailbreak LLMs into Generating Malicious Code(语法约束解码可诱使大语言模型生成恶意代码)
[11:25] 🎥 InternVideo3: Agentify Foundation Models with Multimodal Contextual Reasoning(InternVideo3:通过多模态上下文推理将基础模型智能体化)
[12:18] ⚡ Breaking Entropy Bounds: Accelerating RL Training via MTP with Rejection Sampling(打破熵界:通过带拒绝采样的多令牌预测加速强化学习训练)
[13:14] 🔍 ICA Lens: Interpreting Language Models Without Training Another Dictionary(ICA透镜:无需训练另一本词典即可解读语言模型)
【关注我们】
您还可以在以下平台找到我们,获得播客内容以外更多信息
小红书: AI速递
【面向AI时代的可重构无线数据中心】专题征稿 | 延期至6月30日截稿
目录 | 2026年第4期 本期专题:面向低空经济的超高可靠低时延通信技术及其应用
目录 | 2026年第2期 本期专题:6G数字孪生信道与环境智能通信理论、关键技术
目录 | 2026年第1期 本期专题:面向6G的智能无线安全通信技术
目录 ▏2025年第12期 本期专题:面向未来通信的通感算一体化关键技术及应用
目录 ▏2025年第11期 本期专题:6G可重构智能超表面技术
目录 | 2025年第8期 本期专题:面向广域物联网的移动通信技术
目录 | 2025年第7期 本期专题:语义通信与语义信息论基础理论与关键技术
【6G内生智能理论与关键技术】2025年第1期专题论文链接(16篇)
【面向未来移动通信的信息编码与调制技术】2025年第2期专题论文链接(16篇)
【无线算力网络架构与关键技术】2025年第3期专题论文链接(12篇)
【面向6G的可重构和可流动新型天线技术】2025年第4期专题论文链接
【面向工业互联网的无线通信技术】2025年第5期专题论文链接(12篇)
【语义通信与语义信息论基础理论与关键技术】2025年第7期专题论文汇总
【面向广域物联网的移动通信技术】2025年第8期专题论文汇总
【面向未来通信的通感算一体化关键技术及应用】2025年第12期专题论文汇总
【面向6G的智能无线安全通信技术】2026年第1期专题论文汇总
《移动通信》
投稿网址:https://ydtx.cbpt.cnki.net
编务邮箱:ydtx@cetc.com.cn
《移动通信》杂志由中国电子科技集团公司主管,中国电子科技集团公司第七研究所主办,是中国期刊方阵“双效期刊”、工业和信息化部精品电子期刊、中国科技论文统计源刊、中国通信学会《信息通信领域高质量科技期刊分级目录》入选期刊、中国电子学会《电子技术、通信技术领域高质量科技期刊分级目录》入选期刊、中国应用型核心期刊、日本JST收录期刊。国内连续出版物号:CN44-1301/TN,国际连续出版物号:ISSN1006-1010,邮发代号:46-181。
欢迎关注投稿《移动通信》
面向低空经济超可靠低时延通信的信道估计研究进展
1.重庆大学微电子与通信工程学院
2.重庆大学本科生院
【摘 要】低空经济作为战略性新兴产业,其发展高度依赖URLLC技术。信道估计作为URLLC物理层实现超可靠性的先决条件,面临着低空信道高动态、非平稳以及URLLC短包传输带来的严峻挑战。为此,系统梳理了面向低空经济URLLC的信道估计研究进展。首先,阐述了低空通信系统与信道模型的特殊性,明确了在极端时延和可靠性约束下,寻求导频开销、估计精度与计算复杂度最佳折衷的核心设计原则。其次,从先验信息获取、压缩感知、张量分解及深度学习四个维度,对现有技术进行了全面对比与分析。最后,梳理出当前信道估计存在的计算复杂度与实时性矛盾、非平稳信道跟踪能力不足以及对非理想因素敏感等挑战,并展望了多模态与生成式学习结合、ISAC及大规模MIMO等新兴架构下的未来发展趋势。
【关键词】低空经济;超可靠低时延通信;信道估计;稀疏压缩感知;张量分解;深度学习
◆赵敏,林涛,曾晓. OFDM系统中基于深度学习的信道估计和信号检测技术[J/OL]. 移动通信,1-7[2025-12-10].
◆廖勇,韩小金.基于机器学习的OTFS系统信道估计与信号检测研究进展[J]. 移动通信, 2024,48(7): 46-56.
◆廖勇,常星宇,苏畅.面向OTFS-ISAC系统的智能信道估计现状、挑战与展望[J]. 移动通信, 2025,49(1): 91-100.
0 引言
低空经济是以各种有人驾驶和无人驾驶航空器的低空飞行活动为牵引,辐射带动相关领域融合发展的一种综合性经济形态。作为继公路、铁路、海运、航空(高空)之后,有望形成的“第五张”立体交通网络,在传统行业的转型升级,完善交通体系、提高物流效率等多方面具有巨大潜力,是中国乃至全球产业发展的一个战略性新赛道[1-2]。
低空经济作为一个明确的、整合性的战略概念,其技术挑战是一个复杂系统性问题。目前许多核心的技术方案,都依赖于一个高性能的通信网络。而URLLC(Ultra Reliable Low-Latency Communication,超可靠低时延通信)作为国际电信联盟为第五代移动通信技术定义的三大核心应用场景之一,其核心指标恰好可以满足低空经济问题的绝大部分需求[3-5]。
URLLC系统物理层面的终极目标是在严格的1 ms级时延约束下,实现高达99.999%的传输可靠性[3]。而在接收端,经过均衡后恢复的物理量的准确性,完全依赖于信道估计的准确性。如果估计不准确将引入额外的、严重的失真[4]。这种失真会导致解调器产生大量错误,即使信噪比很高,误码率也会急剧上升,直接导致无法满足99.999%的可靠性要求。由此可见高精度的信道估计是达成URLLC超可靠性的先决条件[4-5]。
与此同时,由于URLLC的目标是达成极高的可靠性和极低的端到端时延,与传统信道估计范式存在固有冲突;以及低空信道高速移动、URLLC短包传输、复杂三维环境等特性。继而催生了以“在极端苛刻的时延和可靠性约束下,寻求导频开销、估计精度和计算复杂度之间的最佳折衷”为核心设计原则的新型信道估计的研究[6-7]。
为此,本文从低空经济应用场景和URLLC系统入手,综述了当前信道估计算法。首先描述了低空通信系统及其信道模型特征,其次将已有的信道估计算法进行了分类,并对每类的信道估计算法进行了归纳和对比分析,然后梳理了信道估计算法面临的技术挑战,最后探讨了未来发展趋势。
1 低空通信系统以及信道模型
1.1 应用场景
低空经济的典型应用场景如表1所示[7-8],主要包括生产作业、交通运输、文体活动、安防安保四个方面。
在生产作业方面,可以利用无人机进行大规模、高效率的精准作业。包括农药喷洒、作物状态监测、播种等农业作业、基础设施的巡检、测绘[9-10]。此外,应急通信保障(地震、洪水等自然灾害导致地面通信设施瘫痪)和环境监测与保护(用于大气质量监测、水体污染巡查、野生动物保护等)已经成为低空经济的发展刚需。
交通运输应用中,城市空中交通作为一种面向未来的立体交通解决方案,是低空经济的发展重点。它要求具有完备的空中客运系统、以城市即时配送为主的物流配送系统与紧急医疗救援与警务巡逻系统[8]。而景区外卖、生鲜运输、跨海直运等载物运输以及商务专线、城际通勤、短途客运等载人运输同样具有极大的发展潜力。
而在文娱体育产业,无论是空中媒体与表演、竞技体育等大众娱乐,还是航拍与影视制作等艺术创作,亦或是低空研学、飞行执照考级,都可以成为低空经济多样化的应用场景。
除此之外,安防安保也是低空经济一大应用领域。低空监测识别体系、电子围栏监控、等技术或将成为未来最具保障力的安全防护措施,也为低空经济的其他应用场景提供了后勤物资保障。
1.2 URLLC系统
URLLC是提供给低空经济的通信保障,其设计目标是为需要极高可靠性和极低时延的关键任务型应用提供连接服务。
(1)MIMO-OFDM架构
目前URLLC采用的是多载波的OFDM(Orthogonal Frequency Division Multiplexing,正交频分复用)技术[13]。该技术把高速的数据流通过串并变换,分配到速率相对较低的若干个正交的频率子信道中进行传输,提高了频谱利用率[14]。图1是基于导频辅助的OFDM系统中的信号处理流程[14-16]。
2 低空场景下的URLLC信道估计
结合低空经济应用场景,信道估计传统技术(LS、MMSE)的局限性,以及前沿领域的研究,信道估计技术的核心追求就是:如何利用尽可能少的导频资源(非零导频)来实现尽可能高精度的估计。本节从先验信息获取、压缩感知、张量分解、深度学习四个方面,综述了信道估计的研究进展。
2.1 先验信息获取
上文提到的传统估计方法,通过接收信号Y和导频信号X进行估计。这样的传统方式计算量偏少,却存在性能瓶颈。本节介绍方法的通过利用非无线信号本身的外部信息来对信道信息进行预测,提升估计精度、降低导频开销或加速估计过程,称为先验信息的获取。
Zhang C等[22]在无人机通信网络研究中提出了侧面信息辅助的设想,在此基础上,何尔利等[23]以地面基站和无人机间的LoS假设为基础,利用位置信息预测出无线信号传播方向的AoA(Angle of Arrival,到达角)和AoD(Angle of Departure,出发角),并指出在此基础上将波束调整到所需方向以辅助信道估计,可缩短估计时间。然而,低空环境中,由于建筑物遮挡,导致与基站之间没有视距链路,存在盲区,即处于NLoS的状态。
在解决盲区覆盖问题中,RIS(Reconfigurable Intelligent Surface,可重构智能表面)技术展现了巨大潜力。Wu Q和Zhang R[24]提出了智能反射表面可用于改善通信盲点,后续的研究重点主要是设计算法去优化包括发射功率和反射相位等参数。文献[25-30]聚焦于使用波束赋形的场景,从不同指标对含有智能反射表面的无线通信系统进行了波束赋形的联合优化。
但由于这些研究中均是假设可以获得完美的CSI(Channel State Information,信道信息), 而RIS引入了具有高维特征的级联通道,使得CSI难以估计,无法证明RIS在实际低空通信中的可行性。因此,You L等[31-32]开始分析非完美信道信息情况下MIMO系统上行链路传输的性能,并探索对CSI的获取。
随后的研究陆续出现了RIS辅助下的先进算法,如任进等[33]提出的正则化改进三阶段MMSE算法,对噪声和误差干扰极大抑制,提升了信道估计的精确性和稳定性。邱友静等[38]提出的经过RIS相移矩阵优化的基于LMMSE(Linear Minimum Mean Square Error,线性最小均方误差)的信道估计。
此外,由于CSI的特性,应用KF(Kalman Filter,卡尔曼滤波)算法可抑制状态转移序列中变化的噪声项[34-35]。基于此,Chen X等[34]提出了一种联合KF的信道估计增强算法,但需要融合更多的环境信息。于是李波等[36]提出了ASAKF(Angel Sensing-Aided Kalman Filter,基于角度感知辅助卡尔曼滤波)算法。Vlachos等[37]同样提出基于卡尔曼滤波融合全球定位系统数据与导频信号进行信道跟踪的方法。
综上,基于先验信息的信道估计算法总结如表2所示。
2.2 稀疏压缩感知
Candes E J等[39]指出稀疏信号能从较少的观测数据中通过非自适应的重构算法高概率地恢复出原始信号,并将这种获取稀疏信号的信息方法称为CS(Compressed Sensing,压缩感知)。采用压缩感知以较少的导频数实现信道重建,进而估计出信道状态,即Hk。压缩感知信道估计算法多样,本节只聚焦于适用于URLLC要求的算法。
(1)贪婪追踪算法
文献[40]中提到的MP(Matching Pursuit,匹配追踪)是最原始的一种信号稀疏重建算法,尽管技术实现度不高,但作为最基础的且较常用的信号稀疏重构算法之一,它的贪婪迭代的思想,影响到后续的各种算法,有着不可忽视的作用。而文献[41]提出的OMP(Orthogonal Matching Pursuit,正交匹配追踪),能够收敛到信号的稀疏解,在信号的重构质量上,要好于MP算法,然而该算法增加了一步正交化操作使计算量大大增加,所以对原始信号的重建时间必然会有所增加。因而催生了文献[42]中的ROMP(Regularized Orthogonal Match Pursuit,正则化正交匹配追踪)算法,该算法运用的正则化思想提高了重建过程的运算速度,运算时间低于OMP算法,但同时也存在着重建精度相对较低的问题。此外文献[43]所提出的CoSaMP(Compressive Sampling Matching Pursuit,压缩采样匹配追踪)算法对基础算法进行了误差界定的改进,以其强理论保证和鲁棒性著称,成为追求高性能的优选。此类算法的核心逻辑是非自适应线性测量以及稀疏重构,如图3所示,预处理后的信号具有限制等距性质,保证稀疏信号能稳定重构,其中从初始化到后处理之前的流程正是对应CoSaMP算法中的稀疏重构这一关键步骤。同样基于OMP算法,文献[44]提出的3D-SOMP(3D Simultaneous Orthogonal Matching Pursuit,三维联合正交匹配追踪)算法很好地解决了CoSaMP在处理多维信号中的计算复杂性。此外,2007年Dai[45]等人提出的SP(Subspace Pursuit,贪婪算法子空间追踪)算法与CoSaMP算法原理类似,也有着接近CoSaMP的性能。
上述算法追求信道重建精度与时间的双重把控,但对先验信息的过度依赖限制了它的实用性。而为解决稀疏性未知条件下的信道估计问题,文献[46]提出了一种SAMP(Sparsity Adaptive Matching Pursuit,稀疏自适应匹配追踪)算法的信道估计方法,可以自适应调整匹配过程的稀疏度,拓宽了压缩感知算法的应用范围,却一定程度上降低了重建的精确度。文献[47]提出的基于弱选择正则化的正交匹配追踪图像重构算法以及文献[48]提出的SAStOMP(Sparsity Adaptive Stagewise Orthogonal Matching Pursuit,自适应分段正交匹配追踪)算法同样实现了在信号稀疏度未知的条件下,仍能完成稀疏信号的重构。
在MP算法发展的同一时间中,文献[49-50]提出了基于IHT(Iterative Hard Thresholding,迭代硬阈值)原理的阈值迭代算法,并引入了具有自适应调整性质的步长,发展出NIHT(Normalized Iterative Hard Thresholding,正规化迭代硬阈值)算法,提升了原始的IHT算法数值表现。文献[51]和文献[52]分别利用共轭梯度的方法和回溯的方式对IHT算法进行了改进设计,提出CGIHT(Conjugate Gradient Iterative Hard Thresholding,共轭梯度迭代硬阈值)和BIHT(Backtracking Iterative Hard Thresholding,回溯迭代硬阈值)算法,进一步提升了算法性能。
由于贪婪算法可能陷入局部最优的问题,而压缩感知恢复问题中的范数l0是一个可分离的且具有稀疏特性的函数,即可以作为目标函数进行凸松弛求解。因此可以通过凸优化算法找到全局最优解。其中ADMM(Alternating Direction Method of Multipliers,交替方向乘子法)具有能够分解问题而实现并行运算,稳定收敛到全局最优解,不依赖参数等特性[53-54],最适用于低空经济场景下的通信场景。但其收敛速度可能较慢,尤其是在高精度要求下,且需要设计合适的停止准则来判断收敛。
综上,基于贪婪追踪的信道估计算法总结如表3所示。
(2)贝叶斯类算法
上节提到的算法需要人工设置参数,而这些参数又极大影响算法效能,缺乏科学的参数设置工具。而贝叶斯类算法因其可以自动迭代信号参数,无须人工干预,使得恢复性能往往优于其他重构类算法。Tiping等经过13年的陆续研究,实现了SBL(Sparse Bayes Learning,稀疏贝叶斯学习)在信道估计领域的推广[55-57]。在此基础上,文献[58]利用信号元素的结构特性,改进了一种名为BSBL(Block Sparse Bayesian Learning,块稀疏贝叶斯学习)方法,但只适用于具有特定结构的信号的信道模型。文献[59]则将LASSO(Least Absolute Shrinkage and Selection Operator,最小绝对收缩和选择算子)的方法运用于贝叶斯理论,但却无法准确估计变量。于是文献[60]施加不同的权重于信号中的元素,提出了自适应LASSO算法,清除了上述算法的缺陷。除了针对于LASSO算法本身进行改进,文献[61]将LARS(Least Angle Regression,最小角回归)算法用于求解LASSO问题,无需迭代优化且便于分析变量选择过程,但每一步需要计算所有变量与残差的相关性,对一些场景同样不适用。文献[62]则是将ADMM算法融入,提出了两阶段LASSO-ADMM算法,充分利用了信道的稀疏性质,保证高估计精度的同时大幅减轻了计算负担。此算法需要仔细设计初始化和迭代过程才能实现最优性能。
(3)特殊结构性稀疏
在一些特定场景中,可以通过引入特定的结构约束,使稀疏模式具有可解释的组结构或层次结构。
例如,在大规模MIMO高速移动场景中,新型调制技术OTFS(Orthogonal Time Frequency Space,正交时频空)信道在时延-多普勒-角度三维联合域中的结构稀疏特性,如图4所示。3D-ESP(3D Enhanced Sparse Pursuit,三维增强稀疏追踪)算法通过利用三维稀疏性,显著降低了传统方法所需的导频开销和计算复杂度,对解决先进波形在高移动性场景(如低空无人机通信、车联网)下的信道估计难题有着重要作用。研究表明,在高速移动场景下,3D-ESP结合深度学习的方法相比传统算法,估计精度提升约35%,导频开销降低至传统方法的40%,显著提升频谱效率。而在NLoS切换场景中,误码率低至0.001%以下,满足URLLC要求用[63]。
当信道的多径时延呈簇状出现时,之前所提到的基于OMP大部分算法都可以基于此结构特性进行改进,摆脱对稀疏度的过度依赖。
2.3 高维信号的张量分解
在MIMO-OFDM或OTFS等系统中,信道可以自然地表示为一个高阶张量,而信道张量Hk通常具有低秩特性。因此通过求解一个张量分解问题,同样可以来估计信道。由于常规导频设计需要每个时频块单独估计,造成了极大的导频开销。而利用张量的低秩性,就可以通过少量观测恢复完整信道,从而实现导频数量的减少。相关研究表明,该方法所需导频数量仅需传统的30%~50%[64]。同时张量分解方法相较传统方法以及压缩感知算法具有更强的抗噪能力,但在实时性和计算简便性上存在不足。
张量分解的基本模型有PARAFAC(Parallel Factor Analysis, 平行因子分析)或称为CPD(Canonical Polyadic Decomposition,典范多线性分解)和塔克(Tucker)模型模型[64-67]。
不考虑深度学习的情况下,PARAFAC的部分经典算法如ALS(Alternating Least Squares,交替最小二乘法)常用于盲信道估计方法,但其他算法仍具有低空场景的发展潜力。例如文献[65]提出的基于平行因子的SVD(Singular Value Decomposition,奇异值分解)算法,属于一种半盲估计,其能够在未知CSI的情况下,实现对符号和信道的联合估计。但由于SVD本身的计算复杂度较高,尤其是对于大规模矩阵,带来了偏高的计算量。
Tucker模型在MIMO系统中具有极高的适配性。代表性的Tucker分解算法包括HOSVD(High-Order SVD,高阶奇异值分解)和MLSVD(Multilinear SVD,多线性奇异值分解)算法[68],二者的基本原理都是将矩阵SVD推广到高阶张量,计算速度快,适合大规模数据初始化,却无法保证得到最优Tucker分解。文献[69]则提供了基于此初始化数据的改进方法,HOOI(High-Order Orthogonal Iteration,高阶正交迭代)算法,虽然有一定概率陷入局部最优,且计算复杂,仍然凭借极高的精度,成为满足URLLC要求的潜力算法。
此外PARAFAC结合Tucker可形成PARATUCK2模型[66],在高速移动场景中将时变信道建模为一个三阶张量,即时间×频率×天线。然后进行PARATUCK2分解。文献[67]中则将PARAFACPARATUCK2模型结合用于MIMO中,通过两阶段的迭代算法分别拟合两个张量模型,以少量的导频序列便能并行估计三跳信道矩阵,不仅可以避免误差叠加,而且提高了系统的频谱利用率。
上述的基本模型在大规模的MIMO中都存在一个缺点,即面对超高维信道时的计算复杂度高。为了降低计算复杂度,TT(Tensor Train,张量列)以及TR(Tensor Ring,张量环)分解的优势在此类应用中凸显了出来。文献[70]的研究证明TT-SVD算法及其改进的阶梯式算法在MIMO系统中的信道估计有明显的计算优势。由于当TT因子的两个边界矩阵以TR格式收缩时,TR分解就是TT分解的一般化形式,TT分解的算法在TR中同样适用。
TT和TR模型对维度之间的相关性都有一定要求。然而,在许多实际应用中,数据的不同维度之间可能存在任意两两之间的复杂交互,而不仅仅是相关维度的交互。为了捕捉任意两个维度之间的全局相关性,一种新型全连接张量网络结构——FCTN(Factorized Convolutional Tensor Network,因子分解卷积张量网络)形成并快速成为低空经济下URLLC信道估计中一种前沿的信号处理技术[71-72]。
综上,基于张量分解的信道估计算法总结如表4所示。
2.4 深度学习
近年来,人工智能迎来了蓬勃发展,为低空通信注入了新的发展动力。作为其核心技术的DL(Deep Learning,深度学习)以强大的数据驱动、非线性拟合、端到端优化与深层特征学习能力,实现了无需依赖显式的数学建模,而是直接从大量测量数据中自适应地学习特定场景下的信道特性与衰落模型[73-75]。这意味着合理利用该方法,不仅可以解决已知模型推导和改进的大部分难题,更是可以跳过一些难以用传统方程描述的复杂关联。并且只要数据训练充足,其完全可以提供更高精度、更低开销、更强鲁棒性的解决方案。将深度学习技术赋能于信道估计,已成为无线通信领域一个蓬勃发展的前沿研究方向[73]。目前的主流模型有DNN(Deep Neural Network,深度神经网络)、CNN(Convolutional Neural Network,卷积神经网络)、RNN(Recurrent Neural Network,循环神经网络)、LSTM(Long Short-Term Memory,长短期记忆)及其变体、Transformer以及混合网络等类型。
(1)模型驱动的方法
这类方法的核心是利用传统信道模型的数学结构、物理规律或迭代算法作为先验,将其设计成深度神经网络的架构,从而结合模型的可解释性与学习的灵活性。
文献[76]提出了知识驱动的 DNN,如图5所示,利用传统算法(如LS、MMSE)的数学框架作为先验,通过将问题解耦为“去噪+推理”两个阶段,在DNN中嵌入已知的物理模型或数学结构。在低信噪比下性能远超纯数据驱动方法,同时保持了传统算法的可解释性且训练过程更稳定,收敛速度更快,因此具有极强的适应性。但需要针对特定问题设计网络结构,通用性相对受限。而文献[77]提出的LISTA-CPD将压缩感知迭代算法与张量分解模相结合,通过在模型训练过程中同时优化LISTA的权重和CPD分解的因子矩阵,实现从观测数据到稀疏信号的端到端学习,提高恢复精度的同时加快计算效率。却同样需要针对特定问题设计网络结构。这两种算法同时高度依赖先验信息。因此文献[78]提出的SA(Sparsity Adaptive,稀疏度自适应)-DL-CS是一种稀疏度自适应的深度学习压缩感知信道估计方法,在具有自适应的不依赖先验信息优势的同时显著提高了精度和鲁棒性。但计算开销仍然较大,目前难以满足URLLC的极低时延要求。为了减少计算量,文献[79]提出SSRnet+PositionNet,将信道估计任务解耦为两个子任务:稀疏支撑集估计和路径参数估计,分别由SSRnet(Sparse Support set Regression Network,稀疏支撑集估计网络)和PositionNet(Position Network,路径参数估计网络)两个子网络完成。避免了感知矩阵的设计和存储开销,减少了计算量,导频开销显著降低。然而其目前成熟度仍面临在分数多普勒、非稀疏信道、动态环境下的挑战。
这些方法旨在利用有效的导频资源尽可能地高精度估计,并且具有完善理论依据,却难以应对复杂环境。
(2)数据驱动方法
与模型驱动方法不同,数据驱动依赖深度网络强大的表示学习能力,直接从数据中挖掘信道在时域、频域或特征空间的深层关联和模式,能有效突破上文方法无法在高动态环境中维持高性能的局限。
文献[80]所提出CNN-LSTM结合,保证了高精度和强鲁棒性,却对超参数异常敏感。文献[81]中的AE(Autoencoder,自编码器)+RNN在拥有上一个算法优点的同时,RNN的记忆机制能够有效跟踪信道的时变特性,对抗高多普勒频移,且削减了这一敏感性。然而其时序建模能力依赖RNN,且对噪声可能会更加敏感。文献[82]提出的CTs(Contrastive Learning for Channel Estimation,基于对比学习的信道估计)则是一种基于对比学习的深度学习方法,具有线性计算复杂度,适合大规模系统部署。其性能增益依赖孪生网络能否有效区分正负样本,且在处理极端动态变化时不稳定。这些方法基于信道时变特性,统称为时序建模的方法。
而另一类方法基于注意力机制和先进的生成式模型,力求复杂环境下的高精度。如文献[83]提出的PD-CEViT,具有动态导频优化和自适应信道适应能力,但在资源受限的边缘设备上,推理速度可能成为瓶颈,因而无法统一使用。文献[84]应用的PCMamba(Position-aware Convolutional Mamba,位置感知卷积Mamba模型)是一种基于Mamba架构的深度学习模型,采用结构化稀疏矩阵运算,如图6所示,可在GPU上实现高效并行计算,同时在序列长度上具有线性可扩展性,特别适合处理大规模点云数据。具有超参数敏感性,并且尚未有足够的研究证明其应用潜力。生成式模型主要有DM(Diffusion Model,扩散模型)[85]、cGAN (Conditional Generative Adversarial Network,条件生成对抗网络)以及MIA-GAN (Multi-instance Attention GAN,多实例注意力生成对抗网络)[86]。三种模型各有利弊:其中cGAN实现简单,适合作为研究基线或对计算资源有限的场景。DM虽然训练和推理复杂,但能提供目前最高的估计精度和最低的导频开销,是满足URLLC极端要求的潜力技术。而当系统存在严重的硬件损伤(如低精度ADC)时,MIA-GAN能有效补偿信息损失,提升系统鲁棒性。
除此之外,还有一类适用于快速部署的元学习与小样本适应方法,可作为应对多样化环境的临时选择。主要技术有利用SAMBA(Self-Adaptive Meta-learning for Beam Alignment,元学习框架)[87],无需CSI以做到快速适应,以及通过O2SC(Online-offline Shared Components,在线-离线共享组件框架)中的离线预训练实现在线快速适应[88]。
面对存在异构网络的复杂场景,可以利用专用网络与端到端优化。这是深度学习在信道估计中的高级应用形式,通过设计专门针对特定问题或直接优化系统级目标的网络架构,实现性能的突破性提升。以双DNN架构[89]、StructNet(Structured Network,结构化网络)[90]和WDANet(Weighted Dynamic Adaptive Network,加权动态自适应网络)[91]为代表,虽然面临可解释性差、训练复杂等挑战,其性能突破仍使其成为未来智能通信系统的关键技术方向。
综上,基于深度学习的信道估计算法总结如表5所示。
3 技术挑战与发展趋势
目前,针对低空经济下URLLC的信道估计的方法仍然处在发展完善阶段,大部分较为成熟的算法还需针对特定情形进行进一步的改进,性能极高的算法在理论解释性和推广程度上还存在空缺。总而言之,要在低空场景下完全实现URLLC的需求在目前来看仍然是一个亟待解决的难题。
3.1 技术挑战
目前,导频设计与资源分配,URLLC特性与低空场景高动态的矛盾,已经有成熟的技术路径和理论模型。例如:CoSaMP及其后续改进算法,在利用稀疏性减少导频消耗的基础上引入自适应追踪[43, 46-48]和以DM为代表的生成式模型[82]等,这些算法极大地改进了上述两个问题。然而当前的信道估计仍然面临着许多技术挑战。
(1)复杂度与实时性间的不相容。上文提到的一些算法具有极高的计算精度及效率,但无一例外,计算都极为复杂,以致于难以在机载计算资源上实现。其次是对非平稳信道跟踪,即便是目前最先进的自适应跟踪机制,也仅仅达到了最基本的精度和效率要求。
(2)已有算法对极端非平稳、非平稳信道的跟踪能力仍显不足。在无人机高速移动、障碍物频繁遮挡、以及复杂多径与多普勒效应交织的动态环境中,信道呈现出强烈的非平稳与非平滑特性。而现有的自适应跟踪机制,大多基于信道变化相对平缓或具有特定变化模型的假设[48, 59]。它们虽然在缓变场景中表现优异,但对于模型失配的低空信道,其跟踪速度与精度下降显著,往往只能满足最基本的性能门限。
(3)许多算法对实际系统中的非理想因素敏感。如收发机的相位噪声会导致抗噪能力不足的算法出现误码率攀升、信号损失等问题,以CoSaMP算法为例,有相位噪声的情况会是支撑集恢复错误率从5%升至23%[43]。ADC或DQC的量化误差、以及天线阵列的互耦与校准误差等同样会造成信号受损,信噪比损失,错误率升高的问题。针对此类情况,相位噪声补偿技术以及量化误差补偿策略是目前普遍运用的补偿机制,而基于贝叶斯推理的联合估计或元学习补偿框架可能成为未来重要的新型补偿算法。除上述因素外,许多高性能算法(如PCMamba[81])往往对超参数设置、初始条件或输入数据的质量极为敏感,参数稍有偏移或环境略有变化,性能便急剧下降。致使仿真实验与实际的应用中存在难以忽视的差距,严重制约了先进算法的实际应用价值。
(4)新型波形下的信道估计的挑战。近年来,新型调制技术逐渐兴起。以OTFS为例,其在适应高速运动环境、适用复杂信道环境展示出了显著的优势,却同样对时频关联的准确度,多维匹配滤波器的设计以及硬件的性能有着更高的要求[92]。同时先进的波形理论往往要与深度学习、张量分析等现代信号处理工具更深度地融合,如何保证系统之间的互操作性和兼容性,同样是新型波形下的信道估计中亟待解决的关键问题[93]。
(5)6G标准演进对信道估计的基础性新要求。6G标准对信道估计的性能要求,主要体现在三个维度。首先是可靠性要求的跨越式提升:要求99.999 99%的传输可靠性,意味着信道估计误差需要控制在更严格的范围内;其次是时延约束的进一步压缩:要求空口时延从1 ms级向0.1 ms级迈进,即信道估计必须在微秒级完成,使得传统迭代算法的收敛速度面临严峻挑战;同时频谱效率的需求也倍增:要求达到5G的10~100倍,而导频开销需要进一步降低至现有水平的10%~20%。
3.2 发展趋势
基于深度学习与传统模型结合的改进方法依然会是未来数年内的主流趋势,未来的主要研究方向将聚焦于以下五个维度:
(1)轻量化与可部署网络设计。这是工程化应用的首要挑战。旨在从网络架构、模型压缩、知识蒸馏等多个层面突破:一方面,设计专门针对信道估计任务的轻量级网络结构,在保证性能的同时大幅降低计算开销;另一方面,探索模型剪枝、量化、低秩分解等压缩技术,将大型网络部署到边缘设备;此外,通过知识蒸馏将复杂网络的知识迁移到轻量网络,实现“小模型、大性能”的目标。
(2)多模态与生成式学习结合。这是提升信道估计鲁棒性的关键路径。通过多模态融合学习,可以利用感知系统提供的环境信息、障碍物分布、无人机运动状态等先验知识,辅助信道估计任务。生成式模型则能够从有限导频中获得高质量的信道状态信息。未来研究将探索如何将多模态信息与生成式学习有机结合,构建能够自适应融合不同信息源、在复杂环境下保持稳定性能的智能估计框架。
(3)模型泛化和多样性化。这是应对低空场景复杂多变特性的必然要求。未来研究需从三个层面提升模型泛化能力:一是设计对超参数、初始条件不敏感的鲁棒算法,降低部署难度;二是开发能够自适应不同场景、不同信道统计特性的可迁移模型,避免“一场景一模型”的困境;三是探索元学习、领域自适应等先进技术,使模型能够快速适应新环境、新任务。
(4)高效的数据训练方法。这是解决数据稀缺问题的核心手段。系统在实际部署中,获取大量标注良好的信道数据成本高昂、难度极大。未来研究将重点突破:一是半监督与自监督学习,利用大量无标签数据提升模型性能;二是迁移学习与少样本学习,将地面或仿真数据中学习到的知识迁移到低空场景;三是数据增强与合成数据生成,通过物理模型或生成式模型扩充训练数据集;四是联邦学习等分布式训练框架,在保护数据隐私的前提下实现多设备协同训练。
(5)基于新兴架构的研究。随着ISAC(Integrated Sensing and Communication,通感一体化)技术的兴起,相关信道估计研究也不断涌现。利用ISAC感知功能(如雷达、激光雷达、视觉感知)不仅获取无人机的精确位置、速度、姿态以及环境地图作为先验信息,甚至利用感知信号(如雷达回波)本身作为“导频”,再加上感知系统能够提供连续的运动状态信息,使得ISAC或将解决低空通信高动态、低开销难题的关键技术。未来的研究将聚焦于从资源分配和波形设计来进行感知与通信的权衡,并减小感知误差。这些问题的进展决定这ISAC在低空经济信道估计中的应用前景。除了ISAC技术,大规模MIMO架构也是一种热门的前沿网络架构。它通过分布式天线部署和集中式处理,在大规模MIMO下使得信道趋于确定化,故而利用统计特性进行简化估计,降低估计复杂度。
综上,新兴通信架构下的信道估计正朝着模态融合和分布式处理的方向发展。这为突破传统信道估计的性能瓶颈提供了新的机遇,但也引起了有关联合优化、跨层设计、分布式算法研究等新的领域。
4 结束语
本文系统梳理了面向低空经济URLLC的信道估计研究进展。面对低空信道的高动态、非平稳特性以及URLLC对极低时延和超可靠性的严苛要求,信道估计技术已从传统的基于导频的线性估计,发展为融合先验信息、压缩感知、张量分解及深度学习等多种先进技术的综合性解决方案。其中深度学习技术凭借其强大的数据驱动和非线性拟合能力,已成为突破传统信道估计性能瓶颈的关键。在未来信道估计研究中,将主要集中于以下三个关键问题:算法在边缘设备部署的实际挑战、多模态融合的标准化缺失以及动态环境自适应机制的技术发展。相信随着人工智能与无线通信技术的深度融合,以及新型通信架构的兴起,信道估计技术将持续演进,为低空经济的蓬勃发展提供坚实可靠的通信保障。
参考文献:(上下滑动浏览)
[1] 张晓兰,黄伟熔. 低空经济发展的全球态势、我国现状及促进策略[J]. 经济纵横, 2024(8): 53-62.
[2] Huang H L,Su J C,Wang F Y. The Potential of Low-Altitude Airspace:The Future of Urban Air Transportation [J]. IEEE Transactions on Intelligent Vehicles, 2024,9(8): 5250-5253.
[3] 3GPP TR 38.913. 5G; Study on Scenarios and Requirements for Next Generation Access Technologies (Release 17)[S]. 2022.
[4] She C Y, Sun C J, Gu Z Y, et al. A Tutorial on Ultrareliable and Low-Latency Communications in 6G:Integrating Domain Knowledge into Deep Learning[J]. Proceedings of The IEEE, 2021,109(3): 204-246.
[5] 张德君. 5G-A通感一体化网络在低空经济中的应用研究[J]. 无线互联科技, 2025,22(9): 94-99.
[6] 雷伊婷,骆忠强,王再强. 面向6G通信场景的OTFS信道估计:原理、方法、挑战[J/OL]. 无线电通信技术, 1-26[2025-11-15].
[7] 廖勇,覃录智,刘思其. 无人机在低空经济中的应用综述[J]. 贵州大学学报(自然科学版), 2025,42(4): 60-72.
[8] 赛迪. 中国低空经济应用场景研究报告[R]. 2025.
[9] 刘美言,刘佳. 新质生产力背景下低空经济与农业融合发展的现状、挑战与对策[J]. 中国商论, 2025,34(22): 146-149.
[10] 王丹,罗章松. 低空经济赋能农业新质生产力发展:角色扮演、现实壁垒与破解之道[J]. 农林经济管理学报, 2025,24(2): 165-172.
[11] Zhang Y N,Xu F Y,Jia M P. A Modified Time Domain Interpolation Method for LS Channel Estimation in OFDM Systems[J]. Journal of Southeast University (English Edition), 2022,38(3): 219-226.
[12] 赵敏,林涛,曾晓. OFDM系统中基于深度学习的信道估计和信号检测技术[J/OL]. 移动通信,1-7[2025-12-10].
[13] 廖勇,韩小金. 基于机器学习的OTFS系统信道估计与信号检测研究进展[J]. 移动通信, 2024,48(7): 46-56.
[14] 周小平. 高速移动MIMO OFDM系统快衰落信道估计方法[D]. 上海: 上海大学, 2011.
[15] Robson J. The LTE/SAE Trial Initiative: Taking LTE/SAE from Specification to Rollout - Lte Part Ii: 3gpp Release 8[J]. IEEE Communications Magazine, 2009,47(4): 82-88.
[16] Shin A, Jung K, Park A. Design of Session and Bearer Control Signaling in 3GPP LTE System[C]//68th IEEE Vehicular Technology Conference. Calgary, Canada: IEEE, 2008,21: 1-5.
[17] 纪金伟,高雷涛,周云,等. 一种适用于低空多径环境的MIMO-OFDM信道估计新方法[J]. 西安邮电大学学报, 2025,30(3): 11-19.
[18] Fujino Y, Uchida D, Fujita T, et al. A Subspace Estimation Method Based on Eigenvalue Decomposition for Multi-Target Constant Modulus Algorithm[C]//IEEE Wireless Communications and Networking Conference. Hong Kong, China: IEEE, 2007,3: 1231-1235.
[19] Lee S J. Effect of Least Square Channel Estimation Errors on Achievable Rate in MIMO Fading Channels[J]. IEEE Communications Letters, 2007,11(11): 862-863.
[20] 梁超,项铁铭,刘超,等. 第三代移动通信信道模型仿真分析[J]. 计算机仿真, 2009,26(9): 100-103.
[21] 王代华,宋林丽,王宇龙,等. 平坦地面无线信道的大尺度衰落特性[J]. 计算机工程与设计, 2012,33(6): 2141-2145.
[22] Zhang C, Zhang W, Wang W, et al. Research Challenges and Opportunities of UAV Millimeter-Wave Communications[J]. IEEE Wireless Communications, 2019,26(1): 58-62.
[23] 何尔利,纪澎善,贾向东,等. 位置协助的无人机毫米波通信网络自适应信道估计[J]. 计算机工程, 2020,46(6): 196-201.
[24] Wu Q, Zhang R. Towards Smart and Reconfigurable Environment: Intelligent Reflecting Surface Aided Wireless Network[J]. IEEE Communications Magazine, 2020,58(1): 106-112.
[25] Ntontin K, Renzo M D, Song J, et al. Reconfigurable Intelligent Surfaces Vs.Relaying: Differences, Similarities, and Performance Comparison[J]. IEEE Open Journal of the Communications Society, 2020,1: 798-807.
[26] Wu Q, Zhang R. Intelligent Reflecting Surface Enhanced Wireless Network Via Joint Active and Passive Beamforming[J]. IEEE Transactions on Wireless Communications, 2019,18(11): 5394-5409.
[27] Abeywickrama S, Zhang R, Wu Q. Intelligent Reflecting Surface: Practical Phase Shift Model and Beamforming Optimization[J]. IEEE Transactions on Communications, 2020,68(9): 5849-5862.
[28] Jung M, Saad W, Debbah M, et al. Asymptotic Optimality of Reconfigurable Intelligent Surfaces:Passive Beamforming and Achievable Rate[C]//2020 IEEE international Conference on Communications (ICC). Dublin, Ireland: IEEE, 2020: 1-6.
[29] Guo H, Liang Y, Chen J, et al. Weighted Sum-Rate Maximization for Intelligent Reflecting Surface Enhanced Wireless Networks[C]//2019 IEEE Global Communications Conference (GLOBECOM). Waikoloa, HI, USA: IEEE, 2019: 1-6.
[30] Li S, Duo B, Yuan X, et al. Reconfigurable Intelligent Surface Assisted UAV Communication: Joint Trajectory Design and Passive Beamforming[J]. IEEE Wireless Communications Letters, 2020,9(5): 716-720.
[31] You L, Xiong J, Huang Y, et al. Reconfigurable Intelligent Surfaces-Assisted Multiuser MIMO Uplink Transmission with Partial CSI[J/OL]. arXiv:2002.13014, 2020.
[32] Yang Y, Zheng B, Zhang S, et al. Intelligent Reflecting Surface Meets OFDM:Protocol Design and Rate Maximization[J/OL]. arXiv:1906.09956, 2019.
[33] 任进,李一博,张尧,等. 基于正则化多阶MMSE的IRS辅助无人机通信系统信道估计算法[J]. 无线电通信技术, 2025,51(6): 1297-1305.
[34] Chen X, Feng Z Y, Zhang A, et al. Sensing Aided Uplink Channel Estimation for Joint Communication and Sensing[J]. IEEE Wireless Communications Letters, 2023,12(3): 441-445.
[35] Khodrarhmi M, Vafa M. A Review on Kalman Filter Models[J]. Archives of Computational Methods in Engineering, 2023,30(10): 727-747.
[36] 李波,李正源. 基于角度感知的ISAC系统信道估计算法[J]. 计算机工程与设计, 2025,46(7): 1912-1918.
[37] Vlachos E, Mavrokefalidis C, Berberidis K, et al. Improving Wideband Massive MIMO Channel Estimation with UAV State-Space Information[J]. IEEE Transactions on Vehicular Technology, 2025,74(10): 15935-15948.
[38] 宋文彬,陈德川,张新刚,等. 双RIS辅助的多天线协作NOMA短包通信系统性能分析[J/OL]. 电子与信息学报,1-9[2026-01-17].
[39] Candes E J, Romberg J, Tao T. Robust Uncertainty Principles: Exact Signal Reconstruction from Highly Incomplete Frequency Information[M]. IEEE Press, 2006.
[40] 梁彦. 基于MP算法的信道估计研究[D]. 南京: 南京理工大学, 2003.
[41] Tropp J A, Gilbert AC. Signal Recovery from Random Measurements Via Orthogonal Matching Pursuit[J]. IEEE Transactions on information Theory, 2007,53(12): 4655-4666.
[42] Needell D, Vershynin R. Signal Recovery from Incomplete and Inaccurate Measurements Via Regularized Orthogonal Matching Pursuit[J]. IEEE Journal of Selected topics in Signal Processing, 2010,4(2): 310-316.
[43] Needell D, Tropp J A. CoSaMP:Iterative Signal Recovery from Incomplete and Inaccurate Samples[J]. Communications of the ACM, 2010,53(12): 93-100.
[44] Shen W, Dai L, An J, et al. Channel Estimation for Orthogonal Time Frequency Space (OTFS) Massive MIMO[J]. IEEE Transactions on Signal Processing, 2019,67(16): 4204-4217.
[45] Dai W, Milenkovic O. Subspace Pursuit for Compressive Sensing Signal Reconstruction[J]. IEEE Transactions on Information Theory, 2009,55(5): 2230-2249.
[46] 王艳芬,丛潇雨,孙彦景. 一种稀疏度自适应超宽带信道估计算法[J]. 电子科技大学学报, 2017,46(3): 498-503.
[47] 刘哲,张鹤妮,张永亮,等. 基于弱选择正则化正交匹配追踪的图像重构算法[J]. 光子学报, 2012,41(10):1 217-1221.
[48] Chen S S, Donoho D L, Saunders M A. Atomic Decomposition by Basis Pursuit[J]. SIAM Journal on Scientific Computing, 1988,43(1): 129-159.
[49] Blumensath T,Yaghoobi M, Davies M E. Iterative Thresholding for Sparse Approximations[J]. Journal of Fourier Analysis and Applications, 2008,14: 629-653.
[50] Blumensath T,Yaghoobi M, Davies M E. Normalized Iterative Hard Thresholding: Guaranteed Stability and Performance[J]. IEEE Journal of Selected topics in Signal Processing, 2010,4(2): 298-309.
[51] Blanchard J D, Tanner J, Ke W. Conjugate Gradient Iterative Hard Thresholding: Observed Noise Stability for Compressed Sensing[J]. IEEE Transactions on Signal Processing, 2014,63(2): 528-537.
[52] Yang H R, Fang H, Zhang C, et al. Iterative Hard Thresholding Algorithm Based on Backtracking[J]. Acta Automatica Sinica, 2011,37(3): 276-282.
[53] Boyd S, Parikh N, Chu E, et al. Distributed Optimization and Statistical Learning Via The Alternating Direction Method of Multipliers[M]. Hanover:Now Foundation and Trends, 2011.
[54] He B S, Ma F, Yuan X M. Convergence Study on The Symmetric Version of ADMM with Larger Step Sizes[J]. SIAM Journal of Imaging Science, 2016,9(3): 1467-1501.
[55] Tipping M E. Sparse Bayesian Learning and The Relevance Vector Machine[J]. Journal of Machine Learning Research, 2001,1(3): 211-243.
[56] Mccall J C, Trivedi M, Wipf D P, et al. Lane Change Intent Analysis Using Robust Operators and Sparse Bayesian Learning[J]. IEEE Transactions on Intelligent Transportation Systems, 2007,8(3): 431-440.
[57] Qiu K, Dogandzic A. Variance-Component Based Sparse Signal Reconstruction and Model Selection[J]. IEEE Transactions on Signal Processing, 2010,58(6): 2935-2952
[58] Zhang Z, Rao B D. Sparse Signal Recovery with Temporally Correlated Source Vectors Using Sparse Bayesian Learning[J]. IEEE Journal of Selected topics in Signal Processing, 2011,5(5):912-926.
[59] Babacan S D, Molina R, Katsaggelos A K. Bayesian Compressive Sensing Using Laplace Priors[J]. IEEE Transactions on Image Processing, 2010,19(1): 53-62.
[60] Zou H. The Adaptive LASSO and Its Oracle Properties[J]. Journal of the American Statistical Association, 2012(1): 1418-1429.
[61] 符洋森,伍亮,蒙亚捷,等. 基于两阶段LASSO-ADMM算法的半盲稀疏信道估计和数据检测[J]. 信息技术与信息化, 2024(8): 4-8.
[62] 张珍凤,张文芳. 基于LASSO算法的波束空间信道估计[J]. 无线互联科技, 2023,20(11): 14-19.
[63] Gui Z, Li Y, Zhou C, Xiong Q, et al. 3D-ESP: An Efficient Subspace Pursuit Algorithm for MIMO-OTFS Channel Estimation[J]. IEEE Transactions on Vehicular Technology, 2024,73(11): 17714-17719.
[64] Lin H, Zhang Z, Pan X, et al.Joint Channel Estimation and Symbol Detection for UAV-Assisted Systems Using Tensor Framework[C]//2022 IEEE 22nd International Conference on Communication Technology (ICCT). Nanjing, China: IEEE, 2022: 1025-1030.
[65] 韩曦,赵雨雨,刘芹,等. 基于PARAFAC分解的通信系统信道估计方法[J]. 现代信息科技, 2020,4(2): 71-72.
[66] Han X, De Almeida A L F, Yang Z. Channel Estimation for MIMO Multirelay Systems Using a Tensor Approach[J]. EURASIP Journal on Advances in Signal Processing, 2014(1): 1-13.
[67] 穆晓敏,刘越,李双志,等. 基于张量分解的MIMO多中继系统半盲信道估计方法[J]. 郑州大学学报(工学版), 2016,37(6): 83-86,96.
[68] Delathauwer L, De Moor B, Vandewalle J. A Multilinear Singular Value Decomposition[J]. SIAM Journal on Matrix Analysis and Applications, 2000,21(4): 1253-1278.
[69] Delathauwer L, De Moor B, Vandewalle J. On The Best Rank-1 and Rank-(r1,r2, ...,rn)Approximation of Higher-order Tensors[J]. SIAM Journal on Matrix Analysis and Applications, 2000,21(4): 1324-1342.
[70] Zniyed Y, Boyer R, De Almeida A L, et al. A TT-Based Hierarchical Framework for Decomposing High-Order Tensors[J]. SIAM Journal on Scientific Computing, 2020,42(2): A822-A848.
[71] Zhang H, Huang T Z, Zhao X L, et al. Hyperspectral Image Denoising: Reconciling Sparse and Low-Tensor-Ring-Rank Priors in The Transformed Domain[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023,61: 1-12.
[72] Chen Y, He W, Zhao X L, et al. Exploring Nonlocal Group Sparsity Under Transform Learning for Hyperspectral Image Denoising[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022,60: 1-18.
[73] 张诒杰,杨心悦,杨定国,等. 基于深度学习的信道估计综述[J/OL]. 无线电通信技术,1-17[2025-12-27].
[74] Chen Z, Zhang Z, Yang Z. Big Ai Models for 6G Wireless Networks: Opportunities, Challenges, and Research Directions[J]. IEEE Wireless Communications, 2024,31(5): 164-172.
[75] Kim S, Park J, Lee M, et al. Role of Sensing and Computer Vision in 6G Wireless Communications[J]. IEEE Wireless Communications, 2024,31(5): 264-271.
[76] Yang R, Xu S, Zhu Z, et al. Knowledge-Driven Channel Estimation for Asymmetrical Massive MIMO Systems[J]. IEEE Transactions on Vehicular Technology, 2025, 74(1): 911-923.
[77] Yang J, Li S, Wang H, et al. Deep Learning-Based Near-Field Wideband Channel Estimation: A Joint LISTA-CP Approach[J]. IEEE Transactions on Vehicular Technology, 2025,74(9): 14041-14052.
[78] Wang H, Wang L, Wang Z, et al. Deep Learning Based Channel Estimation for Massive MIMO: A Sparsity Adaptive Compressive Sensing Method and FPGA Implementation[J]. IEEE Transactions on Cognitive Communications and Networking, 2026(12): 2410-2422.
[79] 游雨欣,姜兴龙,刘会杰,等. TDD OTFS低轨卫星通信系统的LLM信道预测方法[J]. 电子与信息学报, 2025,47(8): 2535-2548.
[80] Zhang G, Kang K, Cai Y, et al. O2SC: Realizing Channel-Adaptive Semantic Communication with One-Shot Online-Learning[J]. IEEE Transactions on Communications, 2025,73(5): 3268-3282.
[81] Payami M, Blostein S D. Sparse Signal Recovery Neural Network with Application to High-Mobility Massive MIMO-OTFS Communication Systems[J]. IEEE Transactions on Vehicular Technology, 2025,74(8): 12175-12188.
[82] Zhang H, Wang X, Tan J, et al. Closer Twins Model: Consistent Design of Modem Scheme and Channel Estimation Under High-Mobility Scenarios[J]. IEEE Transactions on Wireless Communications, 2025,24(6): 4564-4580.
[83] Wu H, Chen Z, Liu Z, et al. CRS-Based Joint CFO and Channel Estimation Using Deep Learning in OFDM-Based Vehicular Communication Systems[J]. IEEE Transactions on Wireless Communications, 2025,24(5): 3882-3892.
[84] Wang J, Li S, Zhang Y, et al. Deep Learning Based Wavenumber Domain Channel Estimation for Holographic MIMO Communications[J]. IEEE Transactions on Vehicular Technology, 2026,75(1): 1619-1623.
[85] Zhou X, Liang L, Zhang J, et al. Generative Diffusion Models for High Dimensional Channel Estimation[J]. IEEE Transactions on Wireless Communications, 2025,24(7): 5840-5853.
[86] 徐明枫,李阳,韩凯峰,等. 基于GAN的导频配置和信道估计联合优化算法[J]. 信息通信技术与政策, 2023,49(9): 58-66.
[87] Xu Z, Wang S, Zhang Y J A. Scenario-Adaptive Meta-Learning for Mmwave Beam Alignment[J]. IEEE Transactions on Wireless Communications, 2025,24(4): 3192-3208
[88] Xu J, Li L, Zheng L, et al. Learning to Estimate: A Real-Time Online Learning Framework for MIMO-OFDM Channel Estimation[J]. IEEE Transactions on Wireless Communications, 2025,24(4): 2634-2646.
[89] Park J, Sohrabi F, Ghosh A, et al. End-to-End Deep Learning for TDD MIMO Systems in The 6G Upper Midbands[J]. IEEE Transactions on Wireless Communications, 2025,24(3): 2110-2125.
[90] Yang J, Fang Y, Dai L, et al. Residual Network-Based Channel Estimation for The Protograph LDPC-Coded OFDM Systems[J]. IEEE Communications Letters, 2023,27(10): 2568-2572.
[91] Zhang Z, Chen Y, Wang Y. Attention-Enhanced Channel Estimation for 6G MIMO in Unifying Far-Field and Near-Field[J]. IEEE Transactions on Vehicular Technology, 2025,74(10): 16584-16589.
[92] 廖勇,常星宇,苏畅. 面向OTFS-ISAC系统的智能信道估计现状、挑战与展望[J]. 移动通信, 2025,49(1): 91-100.
[93] 廖勇,罗渝,荆亚昊. 6G新型时延多普勒通信范式:OTFS的技术优势、设计挑战、应用与前景[J]. 电子与信息学报, 2024,46(5): 1827-1842. ★
扫描二维码,阅读下载本篇论文
doi:10.3969/j.issn.1006-1010.20260130-0001
中图分类号:TN929.5 文献标志码:A
文章编号:1006-1010(2026)04-0002-14
引用格式:廖勇,韩知孝. 面向低空经济超可靠低时延通信的信道估计研究进展[J]. 移动通信, 2026,50(4): 2-15.
LIAO Yong, HAN Zhixiao. Research Progress on Channel Estimation for High-Reliability and Low-Latency Communications in Low-Altitude Economy[J]. Mobile Communications, 2026,50(4): 2-15.
作者简介
廖勇:副研究员,博士毕业于重庆大学,现任职于重庆大学,CCF杰出会员,主要研究方向为超高速移动场景通信系统及其关键技术、智能通信。
韩知孝:重庆大学在读本科生,主要研究方向为智能通信。
《移动通信》杂志由中国电子科技集团公司主管,中国电子科技集团公司第七研究所主办,是中国期刊方阵“双效期刊”、工业和信息化部精品电子期刊、中国科技论文统计源刊、中国通信学会《信息通信领域高质量科技期刊分级目录》入选期刊、中国电子学会《电子技术、通信技术领域高质量科技期刊分级目录》入选期刊、中国应用型核心期刊、日本JST收录期刊。国内连续出版物号:CN44-1301/TN,国际连续出版物号:ISSN1006-1010,邮发代号:46-181。
作者:廖勇,韩知孝(重庆大学)